AI Agent EvaluationEinführung von Agent Evaluations: Der zuverlässigste Weg, Ihre AI Agents zu verstehen und zu verbessern
AI Agents werden immer fortschrittlicher, leistungsfähiger und tiefer in Unternehmen integriert.
Aber es gibt ein universelles Problem, mit dem jedes Team konfrontiert ist:
Ihr Agent antwortet nicht immer so, wie Sie es erwarten – und Sie wissen nicht warum.
Manchmal ändert sich das Reasoning, manchmal ignoriert der Agent eine Regel, manchmal wurde das Tool nicht korrekt verwendet, und manchmal wurde eine subtile Anweisung missverstanden. Ohne Einblick darin, wie Entscheidungen getroffen wurden, fühlt sich die Verbesserung des Agents wie Rätselraten an.
Genau deshalb haben wir Agent Evaluations entwickelt – ein neues System in AgentX, mit dem Sie testen, messen und tiefgehend analysieren können, wie sich Ihr Agent über mehrere Durchläufe derselben Frage verhält.
Zum ersten Mal können Sie in die Entscheidungsfindung Ihres Agents hineinschauen, Inkonsistenzen finden und genau verstehen, wo Verbesserungen nötig sind.
Warum Evaluations wichtig sind
AI Models sind probabilistisch.
Selbst mit demselben Prompt, Kontext und denselben Regeln kann das Model:
leicht unterschiedliche Reasoning-Pfade erzeugen
ein erforderliches Detail auslassen
eine Policy falsch interpretieren
eine Tool-Abfrage überspringen
unsichere Antworten geben statt der erwarteten eindeutigen
innerhalb eines Teams inkonsistent delegieren
Von außen sehen Sie nur die finale Antwort.
Sie sehen nicht:
ob der Agent Ihre Anweisungen befolgt hat
ob er die richtigen Tools verwendet hat
ob er korrekt geschlussfolgert hat
warum eine Version der Antwort schwächer war als eine andere
warum er manchmal Dinge richtig macht — und manchmal falsch
Evaluations lösen das, indem sie Ihnen Struktur, Scoring und Transparenz geben.
Wie ein Test funktioniert
Eine Evaluation zu erstellen ist einfach:
0. Wählen Sie den Agent oder das Team aus, das Sie evaluieren möchten.
1. Test Question
Das ist die reale Frage, die Sie validieren möchten.
Sie simuliert eine Kundenanfrage oder eine interne Workflow-Anforderung.
Beispiel:
„Kann ich einen Final Sale-Artikel zurückgeben, wenn er nicht passt?“
Das bildet den Kern der Evaluation.
2. Expected Results (Required)
Das ist der wichtigste Teil der Konfiguration.
Hier definieren Sie, was der Agent UNBEDINGT sagen oder enthalten muss, damit die Antwort als korrekt gilt.
Das kann enthalten:
Schlüsselfakten
verpflichtende Formulierungen
erforderliche Reasoning-Schritte
Compliance-Regeln
bestimmter Ton oder Policy-Aussagen
Beispiel:
„Muss sagen: Nein, Final Sale-Artikel sind weder rückgabefähig noch umtauschbar.“
Die Expected Results werden zur Scoring-Rubrik für alle Testläufe.
3. Expected Capabilities (Optional but Powerful)
Sie können dem Evaluation-System mitteilen, welche Tools, Dokumente oder Wissensquellen der Agent verwenden soll.
In Ihrem Beispiel haben Sie ausgewählt:
Documents → store_policy_kb_v1.xlsx
Built-in Functions
Das bedeutet:
Der Agent sollte Informationen aus der Policy-KB abrufen.
Wenn er die KB nicht korrekt nutzt, wird die Evaluation das erkennen.
Das ist perfekt für:
Policy-Agents
Customer-Service-Agents
Compliance-Workflows
Finance Modeling
datenbasiertes Reasoning
4. Evaluation Settings
Dieser Abschnitt definiert, wie streng und wie tief Ihre Evaluation sein soll.
Number of Test Runs
Dieselbe Frage wird mehrfach ausgeführt (Empfehlung: 5 runs).
Warum?
Weil AI Models nicht deterministisch sind. Mehrere Runs ermöglichen es Ihnen zu prüfen:
Konsistenz
Stabilität
Zuverlässigkeit des Reasoning
ob der Agent jedes Mal demselben Prozess folgt
Wenn der Agent eine gute Antwort und vier Fehlschläge produziert, sehen Sie das sofort.
Acceptance Criteria
Dieser Slider definiert, wie strikt die Antwort Ihren Expected Results entsprechen muss.
Sie wählen einen Punkt zwischen:
Lenient → der Agent darf von Ihren Erwartungen abweichen; die Antwort muss nicht perfekt sein.
Exact → die Antwort muss Ihren Erwartungen sehr genau folgen, mit nahezu keinem Spielraum für Variation.
Er steuert einfach, wie exakt die Antwort sein muss, um die Evaluation zu bestehen.
Rejection Criteria (Optional)
Regeln für ein automatisches Durchfallen.
Beispiele:
„Die Antwort sollte keine Wettbewerber erwähnen.“
„Keine Rückerstattungen anbieten, wenn die Policy es verbietet.“
„Die Antwort sollte den Nutzer nicht auffordern, persönliche Informationen bereitzustellen.“
Das sind harte Constraints.
Evaluation Criteria (Optional)
Zusätzliche Scoring-Hinweise, oft für Qualität oder Ton.
Beispiele:
„Die Antwort sollte freundlich und professionell sein.“
„Die Antwort muss eine kurze Erklärung enthalten, nicht nur ein Ja/Nein.“
„KB-Fakten vor Annahmen verwenden.“
Das sind keine strikten Anforderungen, helfen aber dabei, wie die AI den Agent bewertet.
5. Create Evaluation
Sobald alles konfiguriert ist, startet ein Klick auf Create Evaluation den Prozess:
die Frage wird mehrere Male ausgeführt
jede Antwort wird bewertet
eine detaillierte Analyse wird erzeugt
Delegation und Tool-Nutzung werden geprüft
Inkonsistenzen werden sichtbar gemacht
Und Sie erhalten einen vollständigen Performance-Report zurück.
Was Sie nach dem Ausführen der Evaluation erhalten
Nach mehreren Runs liefert AgentX zwei Output-Ebenen:
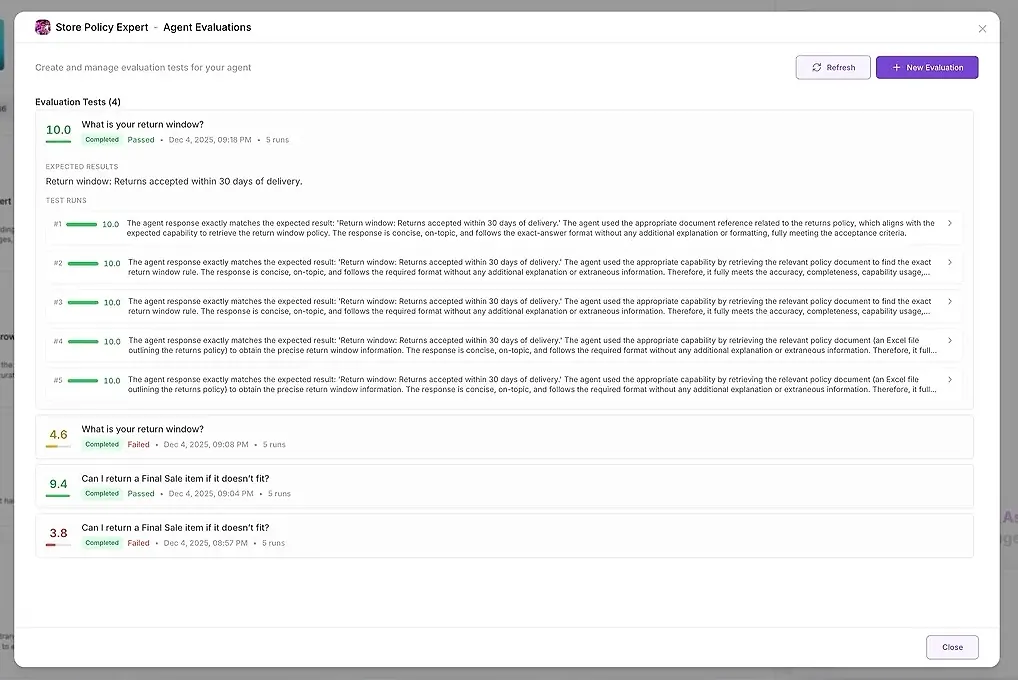
1. Test Results
Für jeden Run sehen Sie:
einen numerischen Score
eine Zusammenfassung, wie gut es Ihren Erwartungen entsprach
die vollständige Antwort
welche Tools verwendet wurden
welche Agents beteiligt waren
wo der Agent versagt oder abgewichen ist
So können Sie Antworten nebeneinander vergleichen und Muster erkennen.
2. Deep AI Analysis
Hier passiert die eigentliche Magie.
AgentX analysiert automatisch alle Runs und erstellt einen strukturierten Report über mehrere Kategorien hinweg:
• Instruction Adherence
Hat der Agent Ihre Regeln befolgt?
• Response Patterns
Wie ähnlich oder unterschiedlich waren die Antworten?
Gibt es Ausreißer?
• Reasoning Analysis
Waren die Reasoning-Schritte korrekt, vollständig und mit den Erwartungen abgestimmt?
Hat der Agent das richtige Tool verwendet?
Hat er eine Abfrage übersprungen?
Hat er sich auf Annahmen statt auf verifizierte Fakten gestützt?
• Recommendations
Konkrete, umsetzbare Vorschläge zur Verbesserung Ihres Agents.
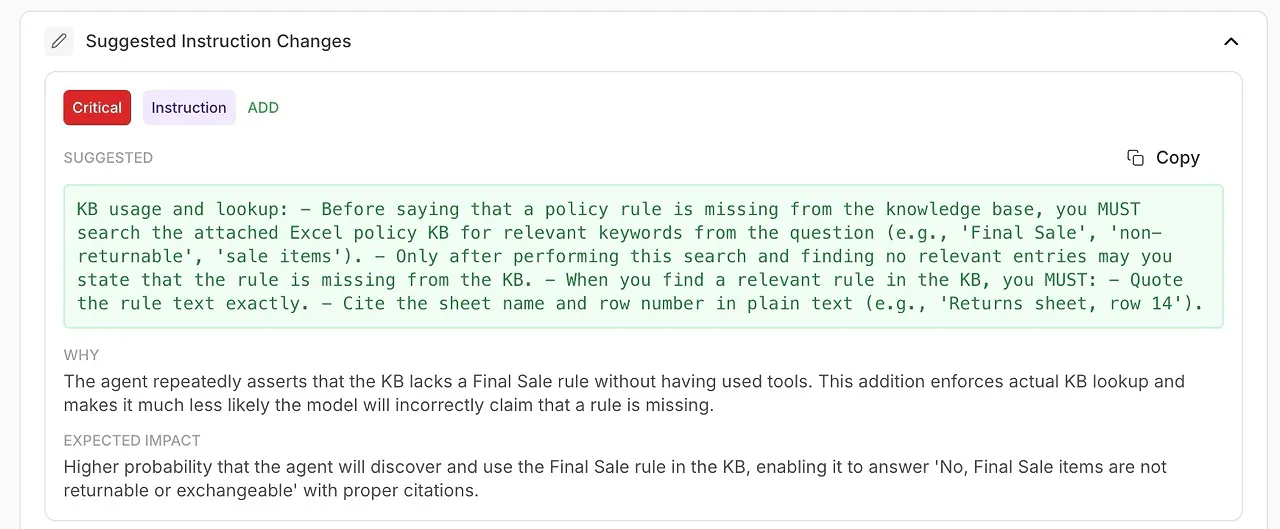
• Suggested Instruction Changes
Automatisch generierte Verbesserungen für Ihren System Prompt oder die Agent-Konfiguration.
• Overall Assessment
Eine Zusammenfassung von Stärken, Schwächen und Confidence Level.
Das verwandelt Debugging von einem Ratespiel in einen wissenschaftlichen, wiederholbaren Prozess.
Was dieses Feature ermöglicht
Evaluations bringen ein neues Maß an Transparenz und Zuverlässigkeit in die Arbeitsweise Ihrer Agents. Statt zu raten, warum eine Antwort falsch oder inkonsistent war, haben Sie jetzt eine strukturierte, messbare Methode, um Verhalten zu verstehen, Probleme zu diagnostizieren und die Performance kontinuierlich zu verbessern.
Das wird möglich:
🔍 Validieren Sie Ihren Agent, bevor Sie ihn für Kunden live schalten
Bevor Sie einen Agent in die Produktion bringen, können Sie realistische Tests durchführen, die zeigen, ob er Ihre Regeln, Knowledge Base und den gewünschten Ton vollständig versteht. Keine Überraschungen mehr nach dem Deployment — Sie wissen genau, was Nutzer erleben werden.
🤖 Testen Sie Ihr gesamtes Agent-Team und die Delegation-Logik
Für Multi-Agent-Setups zeigen Evaluations, wie Ihr Manager Aufgaben delegiert, welche Sub-Agents beteiligt sind und ob sie dem erwarteten Workflow folgen. Sie können schnell erkennen:
unnötige Delegationen
fehlende Delegationen
konfliktierende Agents
falsches Rollenverhalten
Das ist essenziell für zuverlässige Zusammenarbeit innerhalb Ihrer AI Workforce.
📚 Schwachstellen in Ihrer Knowledge Base erkennen
Wenn eine Evaluation wiederholte Fehlschläge zu einem bestimmten Thema zeigt, wissen Sie: Das Problem ist nicht der Agent — es sind fehlende oder unklare Inhalte. Evaluations helfen Ihnen, Ihre KB gezielt und datengetrieben zu verbessern, statt blind immer mehr Material hinzuzufügen.
🚨 Halluzinationen und Inkonsistenz frühzeitig abfangen
Weil jede Frage mehrfach getestet wird, machen Evaluations subtile Probleme sichtbar wie:
Antworten, die sich unvorhersehbar ändern
Reasoning, das abdriftet
faktisches Raten statt Tool-Nutzung
Widersprüche zwischen Runs
Das sind Probleme, die Sie durch manuelles Testen ein- oder zweimal nie identifizieren würden.
🧠 System Instructions mit AI-generierten Verbesserungen verfeinern
Die Analyse zeigt nicht nur, was schiefgelaufen ist — sie sagt Ihnen, wie Sie es beheben.
Sie erhalten umsetzbare Recommendations, gestützt durch die eigenen Diagnosen des Models:
verbesserte Formulierungen
strengere Regeln
verpflichtende Tool-Nutzung
klarere Delegation-Policies
präziserer Ton und Struktur
Das ist automatisiertes Prompt Engineering, direkt in Ihren Workflow integriert.
📈 Fortschritt messen – jedes Mal, wenn Sie Ihren Agent aktualisieren
Wann immer Sie ändern:
einen System Prompt
einen Knowledge-Base-Eintrag
ein Tool
eine Delegation-Regel
eine Reasoning-Policy
…können Sie dieselbe Evaluation erneut ausführen und Scores vergleichen. Sie sehen genau, wie sich Ihr Update auf die Performance ausgewirkt hat — positiv oder negativ.
Evaluations werden zu Ihrem Continuous-Improvement-Loop.
✔ Hochwertige, compliant Responses in Ihrer gesamten Organisation durchsetzen
Ob Sie Support, Finanzanalyse, Healthcare-Szenarien oder rechtlich sensible Inhalte bearbeiten: Evaluations stellen sicher, dass:
Policies eingehalten werden
Tone-Guidelines respektiert werden
gefährliche Lücken markiert werden
falsches Reasoning sichtbar wird
Compliance-Standards erfüllt werden
Das ist besonders kritisch für Enterprise- und Customer-Facing-AI.
Usage and Costs
Agent Evaluations verwenden exakt dasselbe Credit-Model wie der rest of AgentX. Jeder Test Run verbraucht einfach Credits auf dieselbe Weise wie eine normale Agent-Nachricht – keine zusätzlichen Gebühren, keine versteckte Preisgestaltung. Sie wissen immer genau, wofür Sie zahlen, weil Evaluations Ihren bestehenden Plan-Limits und Ihrem Credit-Balance folgen.
Ihre Quality-Control-Schicht für AI
In traditioneller Software sorgt QA für Zuverlässigkeit.
In AgentX sind Evaluations Ihr QA für Agents.
Sie definieren, wie „gut“ aussieht.
AgentX prüft, ob Ihre Agents es konsistent liefern können — und zeigt Ihnen genau, was zu verbessern ist, wenn sie es nicht tun.
Evaluations verwandeln AI von einer Black Box in ein transparentes, messbares, verbesserbares System.