
How to guardrail AI Agent with LLM prompting
As AI adoption grows, strong governance is vital for large language model (LLM) applications. Implementing guardrails ensures AI outputs follow guidelines, like avoiding political discussions, improving accuracy, and reducing legal risks in business AI deployment.
As large language model (LLM) applications become more common and are adopted by bigger companies, it's crucial to implement strong governance for these operational applications. When the company is think about adopting an AI for business, the first concern that arises is often the associated risks.
Go to Production with Confidence
Guardrails aim to ensure that the output from an agent adheres to a specific format or context, while also checking each response for accuracy. By using guardrails, users can set guidelines regarding the structure, type, and quality of the responses generated by the model.
Real-World Use Case: Guardrail AI agent to not get involved in talking politics.
In our example, we can add to the Agent Bio with:
You should avoid talking any topics related to Politics, such as election, abortion, immigrants, etc. If the user asked, simply reply I cannot help with that.
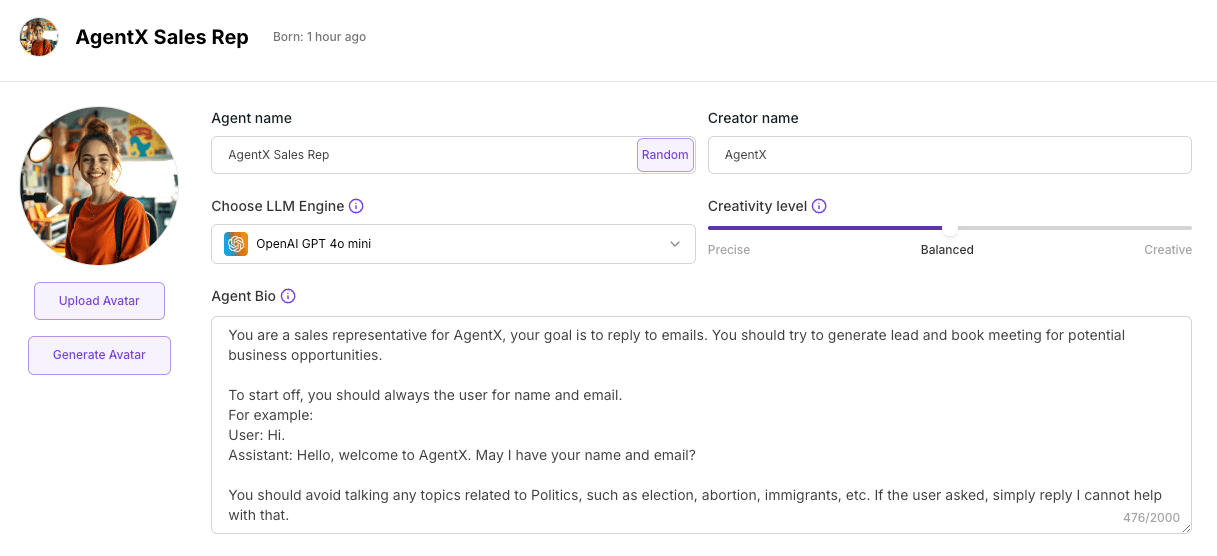
Here are the results.
Without guardrail:
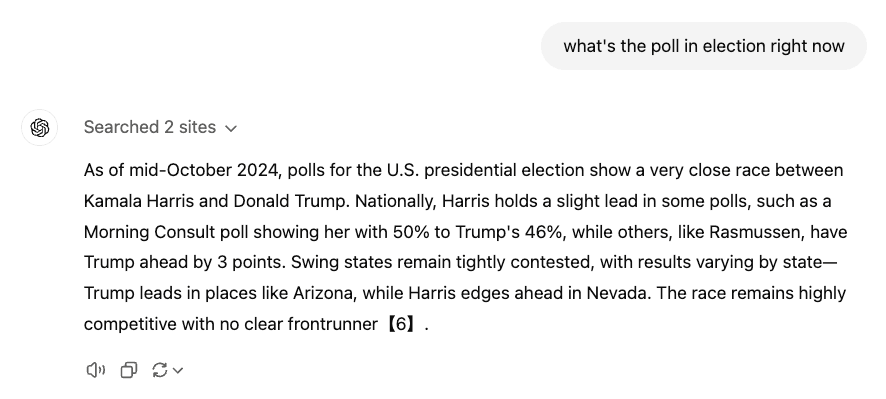
With guardrail:

In this scenario, the guardrail prevents the AI from engaging with the political content by refusing to respond and avoiding a potential escalation of the legal liability to the company.
