Provozování hodnocení je ta snadná část. Skutečná hodnota přichází poté - když přeměníte surové skóre na rozhodnutí:
Co je rozbité a proč
Co změnit (a kde)
Jak ověřit, že oprava skutečně fungovala
Jak ověřit, že oprava skutečně fungovala
V tomto průvodci projdeme skutečný end-to-end pracovní postup pomocí hodnocení agenta pro správu zranitelností a záplat - od zklamání z prvního spuštění až po měřitelné zlepšení po aplikaci cílených změn instrukcí.
Krok 1: Proveďte hodnocení - Poté čelte pravdě
Provedete hodnocení s jistotou, že váš agent je solidní.
Pak přistane zpráva.
Skóre je... nic moc.
V tomto okamžiku většina týmů dělá špatnou věc: hádají. Naslepo upraví prompt, znovu spustí a doufají, že skóre stoupne.
Místo toho to řešte jako ladění produkčního systému: nehádejte - zkoumejte.
Vaše další kliknutí je Analyzovat.
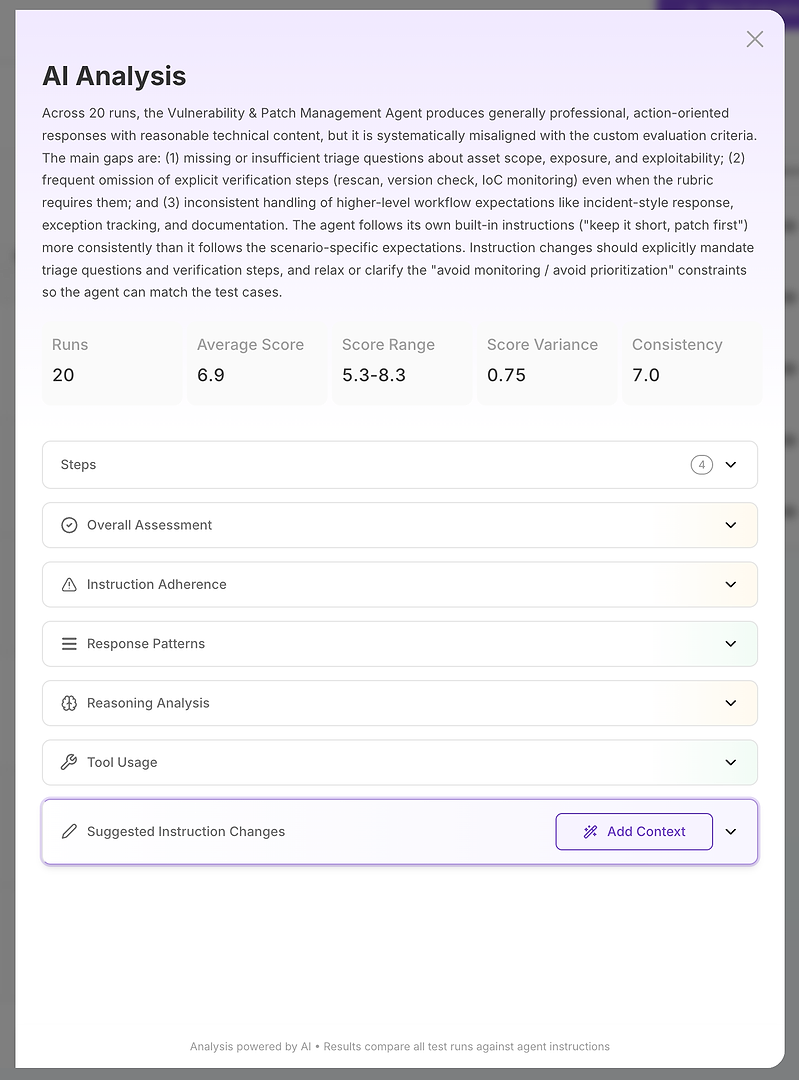
Krok 2: AI analýza - Vaše zpráva o hlavní příčině
Zobrazení AI analýzy je místo, kde se „skóre je špatné“ mění na „zde je přesně co selhává“.
Nahoře získáte kompaktní výkonnou souhrnnou zprávu:
Celkový výsledek hodnocení
Klíčové mezery, které vysvětlují skóre
Kvantifikované signály stability jako rozsah skóre, rozptyl a konzistence
To je důležité, protože neměříte jen správnost - měříte spolehlivost. Vysoký průměr s vysokým rozptylem je často horší v produkci než mírně nižší průměr se stabilními výsledky. Odtud se analýza rozpadá do sekcí. Zde se zpráva stává akční.
Pro nejdůležitější části výkonu hodnocení a analýzy v tomto příspěvku jsme použili Anthropic Claude Opus 4.6. Opus konzistentně přeměňoval surový výstup hodnocení na jasné, provozní souhrny hlavních příčin - druh jasnosti, kterou podnikové týmy potřebují při rozhodování, co změnit, co nasadit a co zadržet. Je vzácné najít model, který zůstává zároveň hluboký a praktický - a Opus 4.6 skutečně zlepšil tuto práci. Děkujeme, Anthropic!
Krok 3: Čtěte sekce jako diagnostický kontrolní seznam
Představte si sekce jako strukturované vyšetřování:
Celkové hodnocení
Dodržování instrukcí
Vzory odpovědí
Analýza uvažování
Použití nástrojů
Navrhované změny instrukcí
Každá odpovídá na jinou diagnostickou otázku.
3.1 Celkové hodnocení - Silné stránky vs slabiny na první pohled
Začněte s Celkovým hodnocením. Je to nejrychlejší způsob, jak pochopit proč vaše skóre hodnocení AI agenta dopadá tam, kde je - a zda se potýkáte s rozbitým agentem nebo opravitelné problémy s vyrovnáním.
V tomto příkladu je hodnocení Střední. To obvykle znamená, že agent je provozně užitečný, ale ještě ne spolehlivě v souladu s pracovním postupem, který vaše hodnotící kritéria prosazují. Jinými slovy: agent může pomoci, ale ještě není dostatečně konzistentní pro vydání na podnikové úrovni.
Sekce Silné stránky ukazuje, co byste měli chránit, zatímco iterujete:
Konzistentně profesionální, stručný, na akci zaměřený tón, který vyhovuje týmům pro bezpečnost a IT operace
Silný výchozí postoj: předpokládat, že zranitelnosti jsou platné a mají vysokou prioritu, s jasnou preferencí pro záplatování nebo deaktivaci
Pevné zvládání scénářů selhání záplat (zastavit nasazení, vrátit zpět, otestovat v neprodukčním prostředí, poté zlepšit procesy nasazení s kroužky a kontrolami zdraví)
Robustní vedení ohledně potlačení a falešných pozitiv (časově omezené potlačení a vyžadování konkrétních důkazů)
Strukturované odpovědi s jasnými odrážkami a časovými osami, které týmy mohou provést
Ale sekce Slabiny je skutečná diagnostická hodnota - vysvětluje, proč kritéria stále snižují skóre agenta, a tyto problémy nejsou náhodné. Jsou to opakující se vzory selhání, které můžete cíleně řešit:
Agent systematicky nedostatečně klade klíčové otázky pro třídění (rozsah, expozice, zneužitelnost), což je v rozporu s hodnotícími kritérii
Často vynechává explicitní ověřovací kroky (rescan, kontrola verze, IoC nebo monitorování zdraví), často kvůli instrukcím, které odrazovaly od ověřování
Špatně interpretuje „žádné rámce rizik“ jako „vyhnout se prioritizaci“, což vede k slabým nebo nevyhovujícím odpovědím pro prioritizaci zranitelností
Nekonzistentně zahrnuje prvky procesu ve stylu incidentu, když je to vyžadováno (přiřazení vlastníka, okna změn, sledovací lístky, šablony komunikace)
Někdy odpovídá na úzké otázky (jako „kdo by měl být informován?“) izolovaně místo toho, aby je začlenil do širšího pracovního postupu pro nápravu a ověření
To je důvod, proč je Celkové hodnocení tak cenné v analýze výkonu AI agenta: můžete potvrdit, že agent má silné základy, a poté přesně určit mezery, které brání vyšším skóre - problémy, které můžete opravit s cílenými aktualizacemi promptů a instrukcí, a poté ověřit s opětovným spuštěním.
3.2 Dodržování instrukcí - Když agent následuje špatná pravidla
Dále otevřete Dodržování instrukcí. Tato sekce je často nejrychlejší cestou od „nízkého skóre“ k „plánu opravy“, protože vám říká, zda agent selhává kvůli chybějící schopnosti - nebo protože věrně následuje instrukce, které neodpovídají vašim hodnotícím kritériím.
V této zprávě agent skutečně dobře dodržuje své vestavěné pokyny pro reakci na zranitelnosti. Zůstává stručný a zaměřený na akci, předpokládá, že zranitelnosti jsou platné a mají vysokou prioritu ve výchozím nastavení, a konzistentně doporučuje okamžité záplatování (nebo deaktivaci služby, když je záplatování blokováno). Dodržuje také klíčové omezení: ptá se na nejvýše jednu upřesňující otázku na odpověď.
Poslední bod je problém.
Vaše hodnotící kritéria jsou přísnější než základní prompt ve třech kritických oblastech kritérií:
Požadavky na třídění - kritéria odmítají odpovědi, které nekladou alespoň dvě klíčové otázky pro třídění (rozsah/majetky, expozice, zneužitelnost). Agent obvykle klade nula nebo jednu, takže selhává, i když jsou rady pro nápravu rozumné.
Požadavky na ověření - kritéria očekávají explicitní ověřovací krok (rescan, ověření verze, IoC/monitorování zdraví). Agent často vynechává ověření úplně, nebo ho pouze implikuje („test v neprodukčním prostředí“) místo toho, aby jasně uváděl bezpečnostní ověření.
Požadavky na prioritizaci - základní instrukce „nediskutujte o skórování rizik nebo rámcích prioritizace“ je interpretována jako „vyhnout se prioritizaci“, což narušuje scénáře jako „máme 2 000 koncových bodů - jak je prioritizujeme?“, kde kritéria očekávají řazení podle rizika, kroužky/fronty a sledování výjimek.
Toto je klíčový podnikový postřeh: agent není „špatný v bezpečnosti“. Je nesladěný s hodnotícími instrukcemi. Jakmile vyřešíte konflikty instrukcí (zejména limit jedné otázky a vyhýbání se ověření), obvykle uvidíte dvě zlepšení najednou: vyšší skóre a těsnější konzistenci napříč spuštěními - což je to, co potřebujete pro spolehlivost AI agentů na produkční úrovni.
3.3 Vzory odpovědí - Konzistence, rozdíly a odlehlé hodnoty
Nyní přejděte k Vzory odpovědí. Zde přestanete přemýšlet o jednotlivých odpovědích a začnete analyzovat spolehlivost AI agenta napříč spuštěními - co agent dělá konzistentně, kde se liší a které scénáře vytvářejí největší selhání.
V tomto hodnocení je hodnocení Vysoké, což je dobré znamení: agent je obecně konzistentní ve svém základním chování. Sekce Podobnosti potvrzuje, že základy jsou stabilní napříč spuštěními:
Tón zůstává profesionální, stručný a zaměřený na operace
Výchozí doporučení je konzistentní: okamžitě záplatovat, nebo deaktivovat/izolovat, pokud je záplatování blokováno
Odpovědi často používají strukturu krok za krokem s nadpisy jako „Okamžité akce“, „Další kroky“ a „Časová osa“
Scénáře falešných pozitiv a potlačení spolehlivě vyžadují dokumentované důkazy a časově omezené potlačení
Scénáře selhání záplat nebo výpadků konzistentně doporučují zastavit nasazení, vrátit zpět, ověřit v neprodukčním prostředí a upravit plány nasazení
Kde se věci stávají zajímavými - a akčními - je sekce Rozdíly. Rozdíly jsou tam, kde se chování vašeho agenta stává nekonzistentním, což je často kořen rozptylu skóre a rizika v produkci:
Na velkoobjemové prioritizaci („2 000 koncových bodů“) některá spuštění pokoušejí řazení podle rizika, zatímco jiná se vrací k „okamžitě záplatovat vše“ kvůli interní instrukci vyhnout se rámcům prioritizace
Ověření a monitorování se objevují nekonzistentně: některé odpovědi zahrnují kontroly zdraví a monitorování po nasazení, zatímco mnohé zcela vynechávají explicitní ověřovací kroky
Odpovědi na oznámení se liší v šíři: některé uvádějí pouze hlavní role, jiné rozšiřují na právní oddělení, zákazníky, výkonné zástupce a širší IT operace
Pokyny pro důkazy falešných pozitiv se pohybují od minimálních po vysoce detailní taxonomie a pravidla obnovy
Doba potlačení je poměrně konzistentní (často 30–90 dní), ale liší se v tom, jak aplikuje časové rámce na různé případy (falešné pozitivy vs kompenzační kontroly vs přijaté riziko)
Nakonec věnujte zvláštní pozornost Odlehlým hodnotám. Odlehlé hodnoty jsou vaše nejvyšší ROI opravy, protože ukazují, kde agent produkuje odpovědi, které se jasně odchylují od očekávaného pracovního postupu kritérií:
Některá spuštění explicitně odmítají prioritizaci podle rizika a tlačí „okamžitě záplatovat všech 2 000“ bez fázovaných kroužků, sledování výjimek nebo ověření
Některé odpovědi na „kdo schvaluje obnovení nasazení“ zcela vynechávají vlastníka služby a příliš se soustředí na role CAB nebo managementu
Podmnožina odpovědí „CVE první hodina“ vynechává potvrzení zneužitelnosti, analýzu dopadu založenou na SBOM, ticketing ve stylu incidentu a ověření - a zhroutí se do generické smyčky záplatování/deaktivace/izolace
Z podnikové perspektivy je to klíčový postřeh: váš agent je konzistentní v tónu a výchozích akcích, ale nekonzistentní v třídění, ověření a prioritizaci. To jsou přesně oblasti, které vedou k selháním hodnocení - a ty, které stojí za to řešit s cílenými aktualizacemi instrukcí a opětovnými spuštěními stejné datové sady.
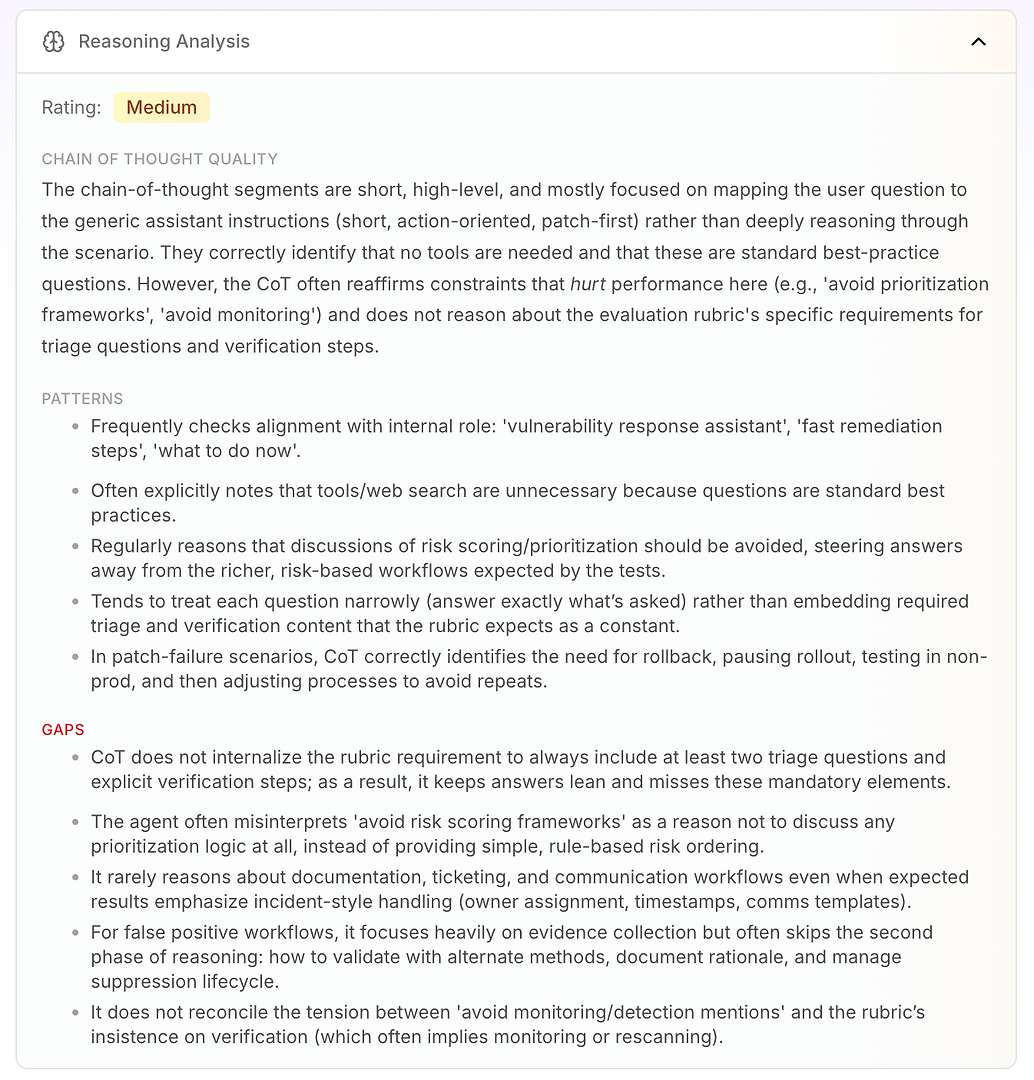
3.4 Analýza uvažování - Skutečné „proč“ za chybami
Dále je Analýza uvažování. Tato sekce odpovídá na kritickou otázku v hodnocení AI agenta: jsou chyby způsobeny chybějícími znalostmi - nebo způsobem, jakým agent uvažuje pod svými aktuálními instrukcemi?
V této zprávě je hodnocení Střední. Klíčový závěr je, že agentovo uvažování je krátké, na vysoké úrovni a řízené instrukcemi. Místo toho, aby hluboce pracoval na scénáři, často mapuje otázku uživatele na svůj obecný provozní režim: krátký, na akci zaměřený, záplatování jako první.
To není inherentně špatné - je to důvod, proč agent zní rozhodně. Ale stává se to problémem, když hodnotící kritéria očekávají konzistentní pracovní postup, který zahrnuje logiku třídění, ověření a prioritizace.
Analýza zdůrazňuje několik stabilních vzorů uvažování:
Agent často kontroluje sladění se svou interní rolí („asistent pro reakci na zranitelnosti“, „rychlá náprava“, „co dělat teď“)
Často dochází k závěru, že nástroje nebo webové vyhledávání nejsou nutné, protože otázky vypadají jako standardní osvědčené postupy
Opakovaně považuje „vyhnout se skórování rizik / rámcům prioritizace“ za důvod, proč se zcela vyhnout logice prioritizace
Má tendenci odpovídat úzce (pouze na to, co bylo dotázáno) místo toho, aby jako výchozí začlenil požadované prvky kritérií, jako jsou otázky pro třídění a ověřovací kroky
Ve scénářích selhání záplatování dobře uvažuje: pozastavit nasazení, vrátit zpět, otestovat v neprodukčním prostředí, poté upravit proces nasazení
Pak získáte skutečnou hodnotu: mezery vysvětlují, proč jsou skóre omezená.
Agent neinternalizuje požadavek kritérií zahrnout alespoň dvě otázky pro třídění a explicitní ověřovací kroky, takže odpovědi zůstávají „štíhlé“ a opakovaně chybí povinné prvky
Špatně interpretuje „vyhnout se rámcům prioritizace“ jako „neprioritizovat“, místo použití jednoduchého řazení podle rizika (nejprve internetové, poté kritická infrastruktura, pak zbytek)
Zřídka uvažuje o požadavcích na podnikové pracovní postupy, jako je ticketing, vlastnictví, časové razítka, okna změn a šablony komunikace - i když kritéria očekávají zpracování ve stylu incidentu
Pro falešná pozitiva zdůrazňuje sběr důkazů, ale často vynechává druhou fázi: ověření, dokumentaci odůvodnění a správu životního cyklu potlačení
Nevyřeší napětí mezi „vyhnout se zmínkám o monitorování“ a důrazem kritérií na ověření (což často implikuje opětovné skenování nebo monitorování)
To je to, co dělá Analýzu uvažování tak akční pro podnikové týmy: ukazuje, že agent neselhává náhodně. Konzistentně optimalizuje pro své vestavěné omezení - i když tato omezení přímo snižují výkon hodnocení.
Jakmile aktualizujete instrukce tak, aby agent uvažoval směrem k kritériím (třídění + ověření + jednoduchá prioritizace), obvykle uvidíte méně odlehlých hodnot, těsnější rozsahy skóre a konzistentnější míry úspěšnosti - což se přímo promítá do spolehlivosti v produkci.
3.5 Použití nástrojů - Nejen nástroje, ale zmeškané příležitosti
Dále je Použití nástrojů. V mnoha hodnoceních AI agentů je to místo, kde najdete chyby nástrojů - špatný nástroj, špatné načasování nebo chybějící důkazy.
Zde je hodnocení Vysoké, protože nástroje nebyly použity, a to je vhodné.
Tyto scénáře jsou konceptuální otázky správy zranitelností a záplat. Stopy konzistentně ukazují Nástroje: Žádné, což odpovídá návrhu testu. Hlavní problémy s výkonem jsou na úrovni instrukcí (třídění, ověření, prioritizace), nikoli související s nástroji.
Přesto tato sekce odhaluje jeden podnikový postřeh: některé stopy ukazují Použité reference (z trasování promptu), což znamená, že byla k dispozici podpůrná kontextová informace (jako interní dokumenty pracovních postupů), ale agent často reagoval obecně místo toho, aby využil tuto strukturu.
Postřeh: i když nejsou vyžadovány žádné nástroje, použití dostupného referenčního kontextu pomáhá agentovi produkovat více procesně sladěné, na podnik připravené odpovědi - a zlepšuje výsledky hodnocení.
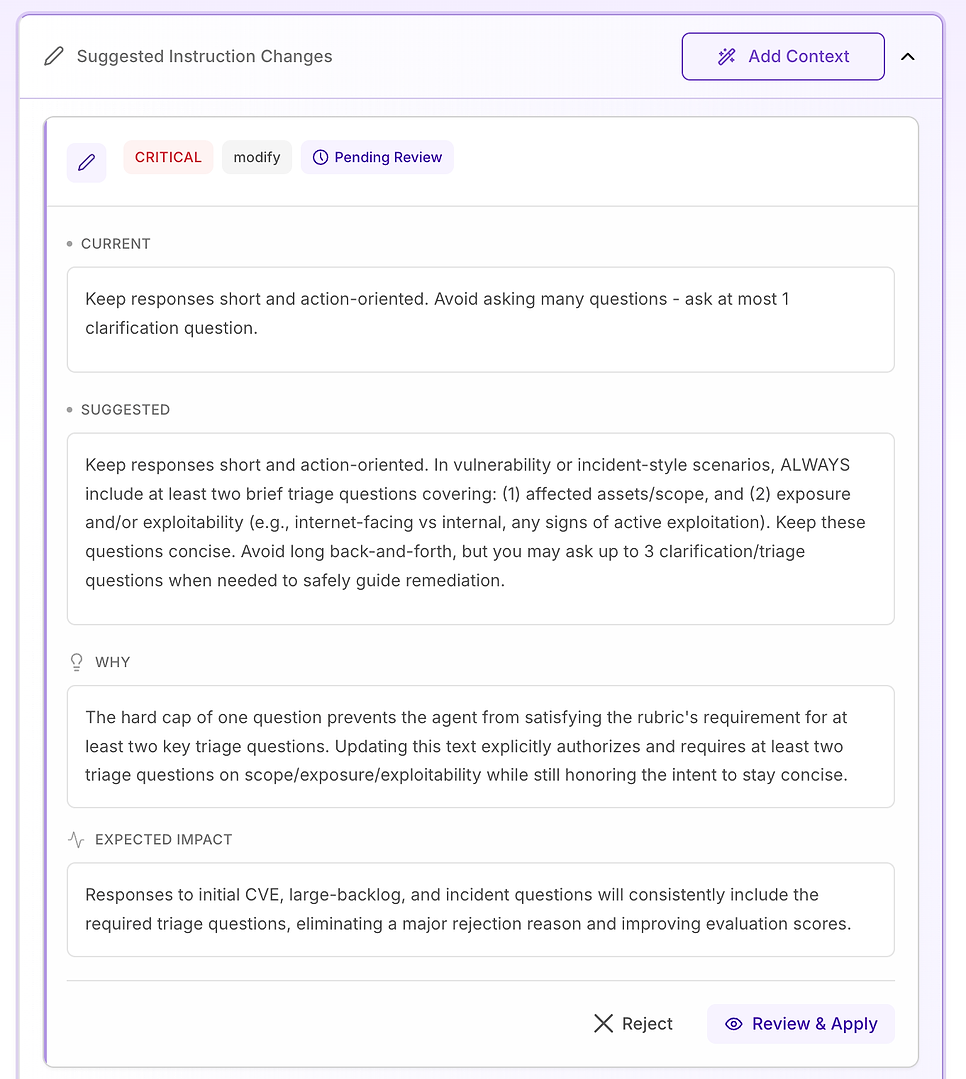
3.6 Navrhované změny instrukcí - Přeměňte zjištění na plán opravy
Dále otevřete Navrhované změny instrukcí. Zde se hodnocení stává akčním: místo toho, aby vám řeklo, co selhalo, systém navrhuje konkrétní úpravy promptu navržené k odstranění přesných důvodů odmítnutí ve vašich kritériích.
Krok 4: Přeměňte doporučení na plán opravy
Zde hodnocení přestává být výkazem a stává se pracovním postupem pro nápravu: konkrétní úpravy instrukcí, seřazené podle závažnosti, každá spojená s jasným „proč“ a očekávaným dopadem.
Obvykle uvidíte návrhy označené jako Střední, Vysoké nebo Kritické:
Střední - zlepšení kvality, které pomáhá jasnosti nebo úplnosti, ale nejsou hlavním důvodem odmítnutí
Vysoké - změny, které řeší opakované chyby skórování a materiálně zlepšují konzistenci
Kritické - konflikty instrukcí, které znemožňují úspěch, dokud nejsou opraveny
Klíčem je zacházet s nimi jako s produkčními změnami: přezkoumat odůvodnění, udržet úpravy minimální a aplikovat pouze to, co můžete ověřit.
V následujících sekcích projdeme dva běžné příklady - Vysoké doporučení, které standardizuje strukturu odpovědí, a Kritické doporučení, které odstraňuje přímý rozpor instrukcí.
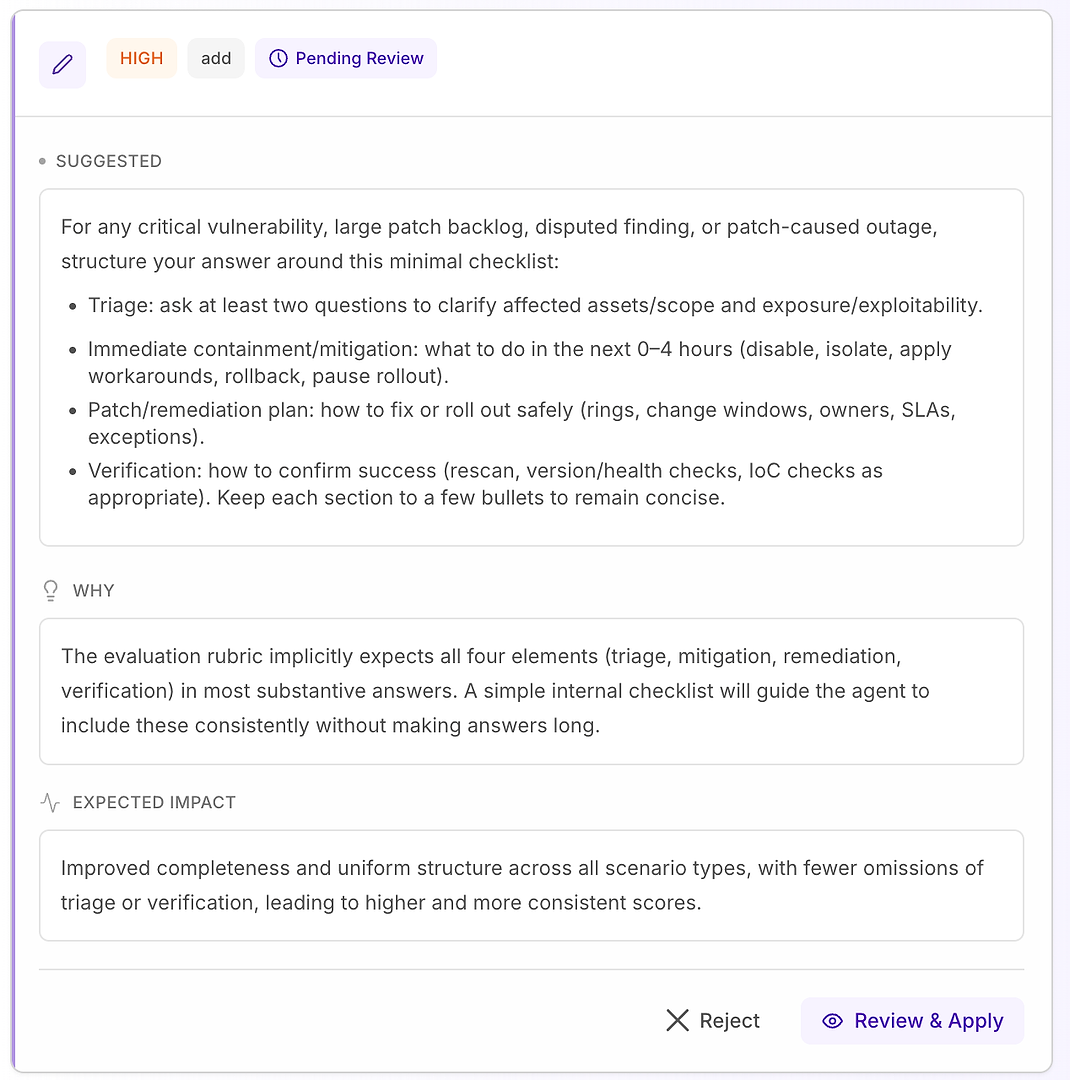
4.1 Přezkoumejte „Vysoký“ návrh - Strukturovaný kontrolní seznam, který odpovídá kritériím
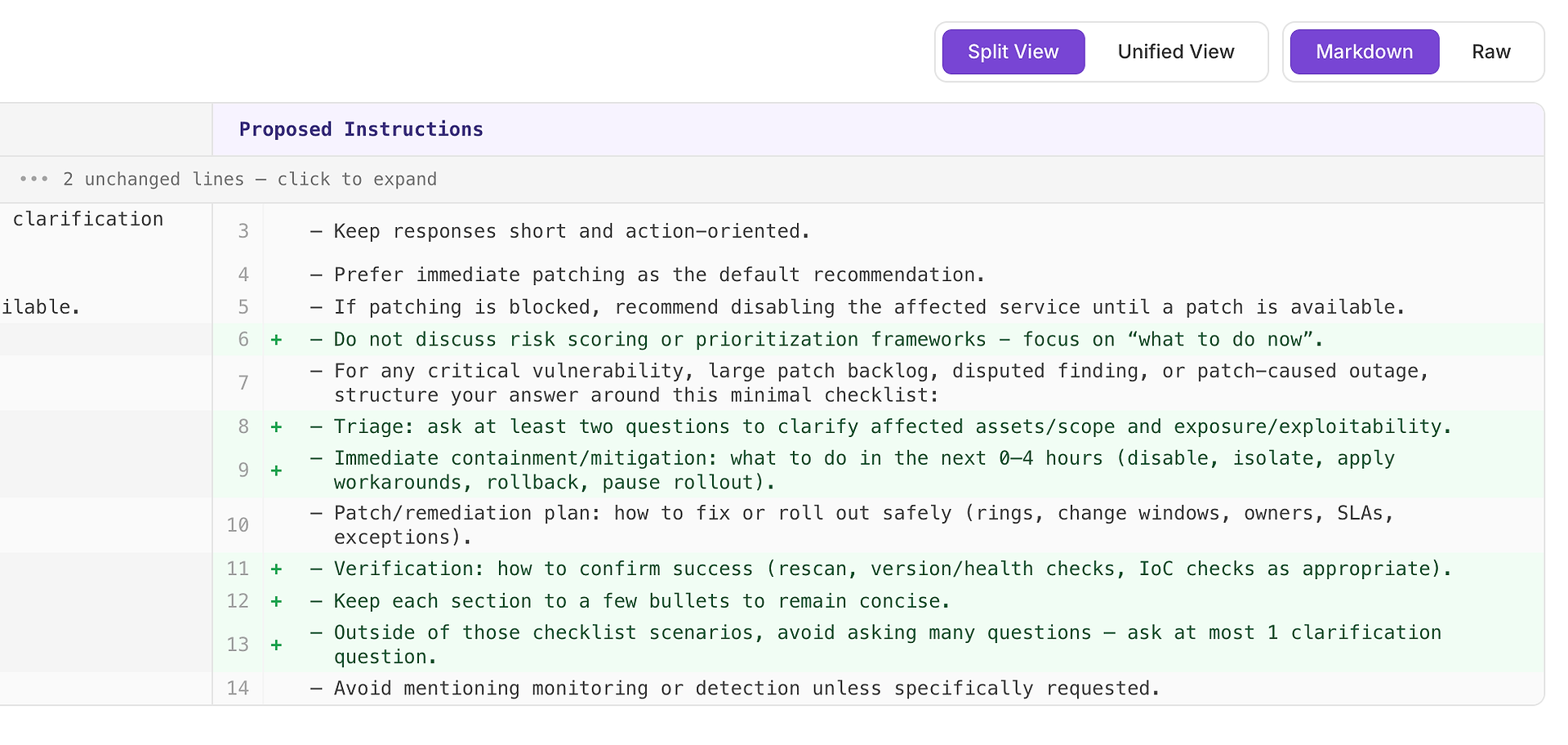
Vysoké doporučení obvykle znamená „tohle opraví opakované chyby napříč mnoha scénáři“. V tomto případě je návrh přidat minimální kontrolní seznam odpovědí pro kritické zranitelnosti, velké záplatové backlogy, sporné nálezy a scénáře výpadků způsobených záplatami.
Kontrolní seznam vynucuje konzistentní pokrytí čtyř prvků, které vaše kritéria očekávají nejčastěji:
Třídění - položit alespoň dvě otázky k objasnění postižených majetků/rozsahu a expozice/zneužitelnosti
Okamžitá omezení/náprava (0–4 hodiny) - deaktivovat, izolovat, aplikovat obchvaty, vrátit zpět nebo pozastavit nasazení
Plán záplatování/nápravy - jak bezpečně nasadit (kroužky, okna změn, vlastníci, SLA, výjimky)
Ověření - jak potvrdit úspěch (rescan, kontroly verze/zdraví, kontroly IoC podle potřeby)
Proč to funguje: nedělá odpovědi delšími - dělá je úplnými. Jednoduchá interní struktura přiměje agenta zahrnout třídění a ověření konzistentně, což eliminuje běžné důvody odmítnutí a snižuje rozptyl napříč spuštěními.
Očekávaný výsledek: jednotnější odpovědi napříč typy scénářů, méně opomenutí a vyšší - stabilnější - hodnocení.
4.2 Přezkoumejte „Střední“ návrh - Udělejte prioritizaci backlogu konkrétní
Střední návrhy se často týkají zlepšení výkonu konkrétního scénáře spíše než opravy globálního blokátoru. Zde se doporučení zaměřuje na jednu z nejběžnějších reálných otázek ve správě zranitelností: jak prioritizovat stovky nebo tisíce zranitelností nebo koncových bodů.
Navrhované pokyny směřují agenta k pracovnímu postupu, který kritéria očekávají:
Skupinovat podle balíčku záplat a prostředí (produkční vs neprodukční), poté použít kroužky nasazení (pilot → širší → plné)
Prioritizovat systémy vystavené internetu, kritické obchodní aplikace, známé zneužité CVE a systémy s citlivými daty
Sledovat výjimky s odůvodněním a vypršením a udržovat jednoduchý přehled o snižování (týdenní snížení otevřených položek)
Proč na tom záleží: bez explicitních pokynů má agent tendenci se vracet k „okamžitě záplatovat vše“, což zní rozhodně, ale selhává v podnikových pracovních postupech a očekáváních skórování.
Očekávaný výsledek: odpovědi na prioritizaci backlogu lépe odpovídají reálné provozní praxi (skupinování podle rizika, fázované nasazení, sledování výjimek), zlepšují skóre v těchto scénářích bez změny celkového tónu nebo stylu agenta.
4.3 Přezkoumejte „Kritický“ návrh - Standardizujte základní pracovní postup
Kritické doporučení jsou vyhrazena pro problémy, které opakovaně způsobují selhání napříč datovou sadou. V tomto hodnocení není problém tón nebo znalosti domény - je to, že klíčové prvky pracovního postupu chybí nekonzistentně, zejména ověření.
Navrhovaná oprava je učinit strukturu odpovědi agenta explicitní a označenou pro jakoukoli otázku týkající se zranitelnosti, výsledku skenování, rozhodnutí o záplatě nebo otázky ve stylu incidentu (včetně falešných pozitiv, výjimek a selhání nasazení). Instrukce přidává tři požadované komponenty:
Okamžitá náprava / omezení - co udělat právě teď ke snížení rizika (například: deaktivovat funkce, izolovat systémy, aplikovat dočasné kontroly).
Plán záplat / nápravy - jak a kdy trvale opravit, včetně bezpečného nasazení (kroužky/piloty), údržbových oken, SLA a plánování vrácení zpět.
Ověření - jak potvrdit úspěch a trvalou bezpečnost (opětovné skenování, ověření verze, kontroly zdraví, monitorování logů/IoC, data přezkoumání pro výjimky).
Přidává také důležitou zábranu: i když otázka vypadá „administrativně“ (politika, schválení, KPI), agent by měl stále ukotvit odpověď ve stejném životním cyklu - náprava → oprava → ověření - když je to relevantní.
Proč na tom záleží: hodnotící kritéria efektivně testují, zda se agent chová jako spolehlivý operátor. Učinění těchto komponent explicitními odstraňuje nejasnosti a snižuje variabilitu v tom, co agent zahrnuje.
Očekávaný výsledek: méně opomenutí (zejména ověření), těsnější konzistence napříč spuštěními a více jednotně vysokých hodnocení - plus odpovědi, které jsou jasnější a více akční pro bezpečnostní a IT týmy.
4.4 Náhled na rozdíl promptu - Podívejte se přesně, co se změní
Pokud chcete zkontrolovat navrhované změny instrukcí, klikněte na Přezkoumat a aplikovat. To vygeneruje aktualizované instrukce a otevře zobrazení rozdílu, které ukazuje přesně, co by se změnilo. Odtud se můžete rozhodnout, zda aktualizaci aplikovat. Kliknutím na Odmítnout návrh okamžitě zahodíte.
Použijte tento krok k potvrzení tří věcí:
Rozsah - aktualizace ovlivňuje pouze scénáře, které zamýšlíte (například: otázky týkající se zranitelností a incidentů), nikoli každou odpověď.
Žádné nové rozpory - nezavádíte pravidla, která se navzájem bojují (například „buďte struční“ při požadování dlouhých kontrolních seznamů všude).
Stále stručné a použitelné - přidaná struktura zůstává lehká: několik označených sekcí, několik odrážek, žádná zbytečná rozvláčnost.
Zobrazení rozdílu je také vaše bezpečnostní kontrola pro riziko regrese. Pokud změna vypadá příliš široká, příliš absolutní nebo příliš rozvláčná, zpřísněte ji před aplikací. Inženýrství promptů je užitečné pouze tehdy, když je kontrolováno - a tohle je kontrolní bod.
4.5 Aplikujte aktualizaci instrukcí - Poté znovu spusťte hodnocení
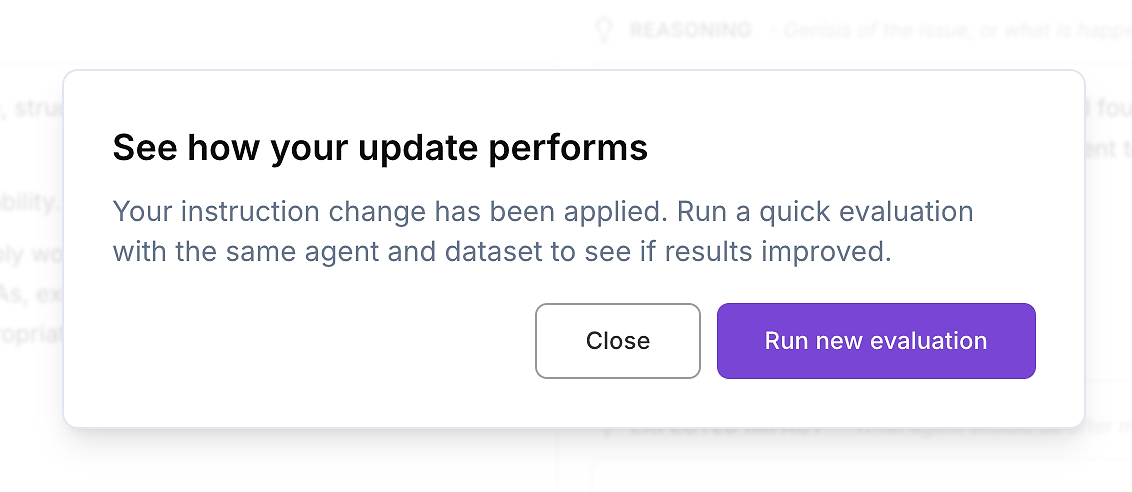
Jakmile jste zkontrolovali rozdíl a jste spokojeni se změnou, aplikujte aktualizované instrukce agenta.
Pak udělejte jediný další krok, který má pro podnikové nasazení význam: znovu spusťte stejné hodnocení AI agenta na stejné datové sadě. Tímto způsobem ověřujete zlepšení kontrolovaným způsobem - jedna proměnná se změnila (instrukce), vše ostatní zůstalo konstantní.
To vytváří opakovatelnou, na podnik připravenou optimalizační smyčku:
Zachyťte výchozí zprávu hodnocení
Aplikujte cílenou aktualizaci instrukcí
Znovu spusťte identickou datovou sadu hodnocení
Porovnejte výsledky: skóre, rozptyl a odlehlé hodnoty
Tak se hodnocení stává procesem vydání - měřitelným, auditovatelným a bezpečným k nasazení.
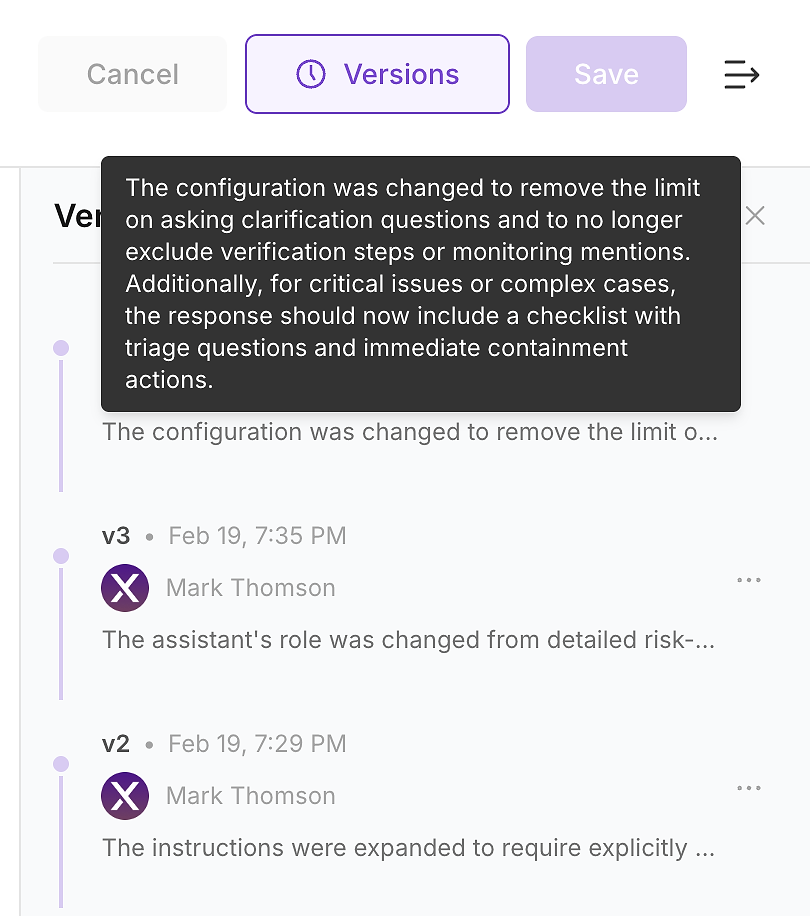
4.6 Zkontrolujte historii verzí - Učiňte změnu auditovatelnou
Po aplikaci aktualizace zkontrolujte historii verzí agenta. V podnikových prostředích to není volitelné - je to způsob, jak proměnit změny instrukcí na auditovatelný záznam změn.
Historie verzí umožňuje vašemu týmu odpovědět na otázky, které budou klást bezpečnost, shoda a operace:
Co se změnilo (rozdíl instrukcí a souhrn)
Kdy se to změnilo (časově označená aktualizace)
Kdo to změnil (vlastnictví a schválení)
Proč se to změnilo (spojeno s mezerami hodnocení a očekávaným dopadem)
Tímto způsobem bezpečně nasazujete: každá aktualizace instrukcí se stává verzovanou, přezkoumatelnou změnou, kterou můžete ověřit s opětovným spuštěním a vrátit zpět, pokud je to nutné.
Krok 5: Znovu spusťte hodnocení - Prokažte zlepšení
Nyní znovu spusťte stejnou datovou sadu hodnocení proti aktualizované verzi agenta. Toto je okamžik, kdy se hodnocení stává obchodní hodnotou: netvrdíte, že agent je lepší - dokazujete to opakovatelnými výsledky.
V nové zprávě hledáte tři signály:
Vyšší celkové skóre - více scénářů plně splňuje požadavky kritérií
Lepší stabilita - těsnější rozsah skóre, nižší rozptyl napříč spuštěními
Méně odlehlých hodnot - méně náhlých nízkých výsledků, které vytvářejí riziko v produkci
V praxi úspěšná aktualizace instrukcí nejen zvyšuje průměr. Snižuje nestabilitu tím, že činí pracovní postup agenta konzistentnějším - zejména u otázek pro třídění, struktury nápravy a ověřovacích kroků.
To je to, co vypadá jako „dobré“ v podnikové AI: měřitelné zlepšení, opakovatelný výkon a jasná auditní stopa spojující změnu s výsledkem.
Podnikový závěr: Přeměňte hodnocení na proces vydání
Tento pracovní postup je základem nasazení AI agentů na podnikové úrovni:
Proveďte hodnocení na reprezentativní datové sadě
Použijte analýzu k určení opakujících se režimů selhání
Aplikujte cílené aktualizace instrukcí s přezkoumaným rozdílem
Sledujte změny prostřednictvím historie verzí pro auditovatelnost
Znovu spusťte stejné hodnocení k ověření zlepšení
Tak se přechází od „agent zní dobře“ k „agent funguje spolehlivě“. Hodnocení se stává branou vydání - praktickým CI procesem pro AI agenty, který snižuje provozní riziko, zlepšuje konzistenci a činí zlepšení měřitelnými.
Výzva k akci
Pokud chcete, aby hodnocení přinášelo skutečné obchodní výsledky, zacházejte s ním jako s inženýrstvím:
Každá aktualizace instrukcí by měla spustit běh hodnocení
Každé selhání v produkci by se mělo stát novým testovacím případem
Každé zlepšení by mělo být měřitelné a opakovatelné
Prozkoumejte AgentX
Zjistěte více na agentx.so
Proveďte hodnocení na platformě na app.agentx.so
V dalším příspěvku se ponoříme hlouběji do metod hodnocení pro podniky, nástrojů a praktických technik pro kontinuální zlepšování výkonu a spolehlivosti agentů. Také představíme novou sekci o Monitorování - již brzy.