Effectuer une évaluation est la partie facile. La vraie valeur vient après - lorsque vous transformez les scores bruts en décisions :
Ce qui est cassé et pourquoi
Ce qu'il faut changer (et où)
Comment valider que la correction a réellement fonctionné
Comment valider que la correction a réellement fonctionné
Dans ce guide, nous allons parcourir un véritable flux de travail de bout en bout en utilisant une évaluation d'agent de gestion des vulnérabilités et des correctifs - d'une première exécution décevante à une amélioration mesurable après avoir appliqué des modifications ciblées des instructions.
Étape 1 : Effectuer l'évaluation - Puis faire face à la réalité
Vous effectuez l'évaluation, confiant que votre agent est solide.
Ensuite, le rapport arrive.
Le score est… pas génial.
À ce moment, la plupart des équipes font la mauvaise chose : elles devinent. Elles modifient l'invite à l'aveuglette, relancent et espèrent que le score augmente.
Au lieu de cela, traitez cela comme le débogage d'un système de production : ne devinez pas - inspectez.
Votre prochain clic est Analyser.
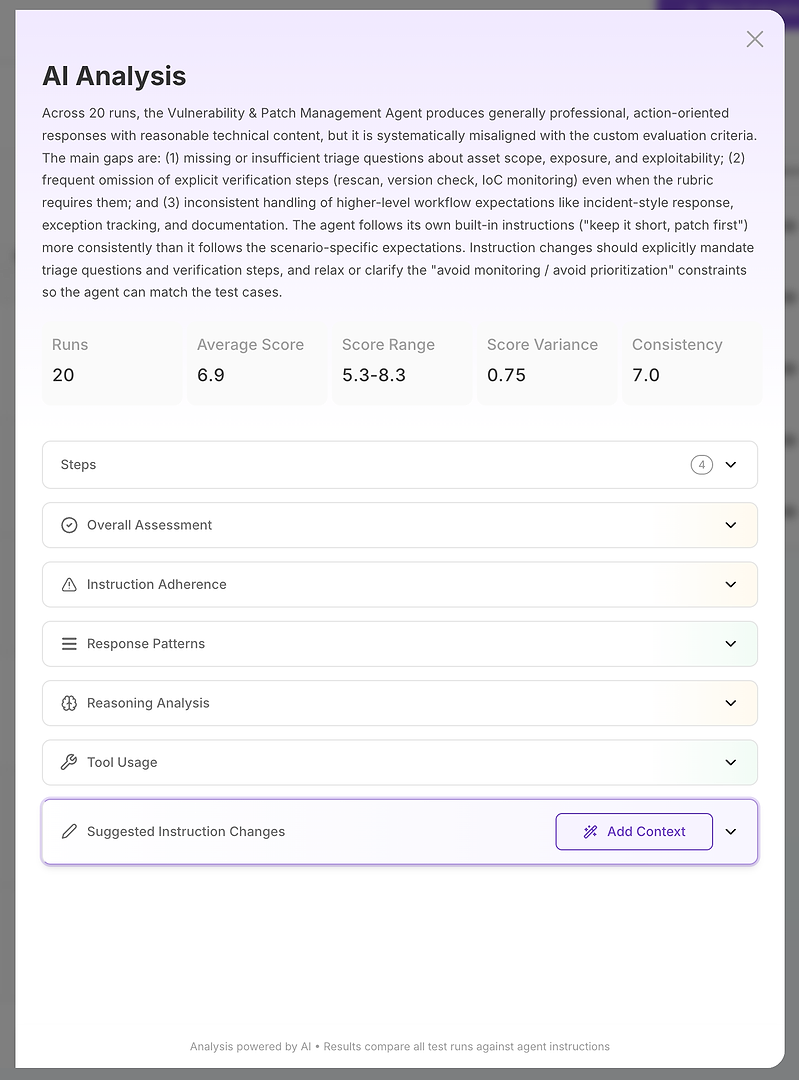
Étape 2 : Analyse IA - Votre rapport de cause racine
La vue Analyse IA est là où « le score est mauvais » devient « voici exactement ce qui échoue ».
En haut, vous obtenez un résumé exécutif compact :
Résultat global de l'évaluation
Principaux écarts qui expliquent le score
Signaux de stabilité quantifiés comme la plage de scores, la variance et la cohérence
Cela est important car vous ne mesurez pas seulement la justesse - vous mesurez la fiabilité. Une moyenne élevée avec une forte variance est souvent pire en production qu'une moyenne légèrement inférieure avec des résultats stables. À partir de là, l'analyse se divise en sections. C'est là que le rapport devient actionnable.
Pour les parties les plus importantes de la performance et de l'analyse de l'évaluation dans ce post, nous avons utilisé Anthropic Claude Opus 4.6. Opus a systématiquement transformé la sortie brute de l'évaluation en résumés opérationnels clairs des causes profondes - le genre de clarté dont les équipes d'entreprise ont besoin pour décider quoi changer, quoi livrer et quoi retenir. Il est rare de trouver un modèle qui reste à la fois profond et pratique en même temps - et Opus 4.6 a véritablement amélioré ce travail. Merci, Anthropic !
Étape 3 : Lire les sections comme une liste de contrôle diagnostique
Pensez aux sections comme à une enquête structurée :
Évaluation globale
Adhésion aux instructions
Modèles de réponse
Analyse du raisonnement
Utilisation des outils
Modifications suggérées des instructions
Chacune répond à une question diagnostique différente.
3.1 Évaluation globale - Forces vs faiblesses en un coup d'œil
Commencez par l'Évaluation globale. C'est le moyen le plus rapide de comprendre pourquoi le score d'évaluation de votre agent IA se situe là où il est - et si vous avez affaire à un agent défaillant ou à un problème d'alignement réparable.
Dans cet exemple, la note est Moyenne. Cela signifie généralement que l'agent est opérationnellement utile, mais pas encore fiablement conforme au flux de travail que votre rubrique d'évaluation impose. En d'autres termes : l'agent peut aider, mais il n'est pas encore assez cohérent pour une version de niveau entreprise.
La section Forces montre ce que vous devez protéger pendant que vous itérez :
Un ton professionnel, concis et axé sur l'action qui convient aux équipes de sécurité et d'opérations informatiques
Une posture par défaut forte : supposer que les vulnérabilités sont valides et prioritaires, avec un biais clair vers le correctif ou la désactivation
Une gestion solide des scénarios d'échec de correctif (arrêter le déploiement, revenir en arrière, tester en non-prod, puis améliorer les processus de déploiement avec des anneaux et des vérifications de santé)
Des conseils robustes sur les suppressions et les faux positifs (suppressions limitées dans le temps et nécessitant des preuves concrètes)
Des réponses structurées avec des puces claires et des délais que les équipes peuvent exécuter
Mais la section Faiblesses est la véritable valeur diagnostique - elle explique pourquoi la rubrique note encore l'agent en bas, et ces problèmes ne sont pas aléatoires. Ce sont des modèles d'échec répétables que vous pouvez cibler directement :
L'agent sous-demande systématiquement des questions clés de triage (portée, exposition, exploitabilité), ce qui est en conflit avec la rubrique d'évaluation
Il omet fréquemment des étapes de vérification explicites (rescan, vérification de version, IoC ou surveillance de santé), souvent en raison d'instructions qui découragent la vérification
Il interprète mal les « cadres sans risque » comme « éviter la priorisation », conduisant à des réponses faibles ou non conformes pour la priorisation du backlog de vulnérabilités
Il n'inclut pas systématiquement des éléments de processus de type incident lorsque requis (attribution de propriétaire, fenêtres de changement, tickets de suivi, modèles de communication)
Il répond parfois à des questions étroites (comme « qui doit être informé ? ») isolément au lieu de les intégrer dans le flux de travail plus large de remédiation et de vérification
C'est pourquoi l'Évaluation globale est si précieuse dans l'analyse des performances des agents IA : vous pouvez confirmer que l'agent a de solides fondamentaux, puis identifier les lacunes exactes empêchant des scores plus élevés - le genre de problèmes que vous pouvez résoudre avec des mises à jour ciblées des invites et des instructions, puis valider avec une nouvelle exécution.
3.2 Adhésion aux instructions - Quand l'agent suit les mauvaises règles
Ensuite, ouvrez Adhésion aux instructions. Cette section est souvent le chemin le plus rapide de « score bas » à « plan de correction », car elle vous indique si l'agent échoue en raison d'une capacité manquante - ou parce qu'il suit fidèlement des instructions qui ne correspondent pas à votre rubrique d'évaluation.
Dans ce rapport, l'agent fait en fait bien en suivant ses conseils intégrés de réponse aux vulnérabilités. Il reste court et axé sur l'action, suppose que les vulnérabilités sont valides et prioritaires par défaut, et recommande systématiquement un correctif immédiat (ou la désactivation d'un service lorsque le correctif est bloqué). Il suit également une contrainte clé : il pose au maximum une question de clarification par réponse.
Ce dernier point est le problème.
Votre rubrique d'évaluation est plus stricte que l'invite de base dans trois domaines critiques de la rubrique :
Exigences de triage - la rubrique rejette les réponses qui ne posent pas au moins deux questions clés de triage (portée/actifs, exposition, exploitabilité). L'agent pose généralement zéro ou une, donc il échoue même lorsque le conseil de remédiation est raisonnable.
Exigences de vérification - la rubrique attend une étape de vérification explicite (rescan, validation de version, surveillance IoC/santé). L'agent omet souvent complètement la vérification, ou ne l'implique que (« tester en non-prod ») au lieu de déclarer clairement la vérification de sécurité.
Exigences de priorisation - l'instruction de base « ne pas discuter des cadres de notation des risques ou de priorisation » est interprétée comme « éviter la priorisation », ce qui casse des scénarios comme « nous avons 2 000 points de terminaison - comment prioriser ? » où la rubrique attend un classement basé sur les risques, des anneaux/queues, et un suivi des exceptions.
C'est l'insight clé de l'entreprise : l'agent n'est pas « mauvais en sécurité ». Il est mal aligné avec les instructions d'évaluation. Une fois que vous résolvez les conflits d'instructions (en particulier la limite d'une question et l'évitement de la vérification), vous voyez généralement deux améliorations à la fois : des scores plus élevés et une cohérence plus serrée entre les exécutions - ce qui est nécessaire pour la fiabilité des agents IA de niveau production.
3.3 Modèles de réponse - Cohérence, différences et valeurs aberrantes
Maintenant, allez à Modèles de réponse. C'est là que vous arrêtez de penser à des réponses uniques et commencez à analyser la fiabilité des agents IA entre les exécutions - ce que l'agent fait de manière cohérente, où il varie, et quels scénarios créent les plus grands échecs.
Dans cette évaluation, la note est Élevée, ce qui est un bon signe : l'agent est globalement cohérent dans son comportement de base. La section Similarités confirme que les fondamentaux sont stables entre les exécutions :
Le ton reste professionnel, concis et axé sur l'opérationnel
La recommandation par défaut est cohérente : corriger immédiatement, ou désactiver/isoler si le correctif est bloqué
Les réponses utilisent fréquemment une structure étape par étape avec des titres comme « Actions immédiates », « Prochaines étapes » et « Chronologie »
Les scénarios de faux positifs et de suppression exigent systématiquement des preuves documentées et des suppressions limitées dans le temps
Les scénarios d'échec de correctif ou de panne recommandent systématiquement d'arrêter le déploiement, de revenir en arrière, de valider en non-prod, et d'ajuster les plans de déploiement
Là où les choses deviennent intéressantes - et actionnables - c'est la section Différences. Les différences sont là où le comportement de votre agent devient incohérent, ce qui est souvent la racine de la variance des scores et du risque de production :
Sur la priorisation à grande échelle (« 2 000 points de terminaison »), certaines exécutions tentent un classement basé sur les risques, tandis que d'autres reviennent à « corriger tout immédiatement » en raison de l'instruction interne d'éviter les cadres de priorisation
La vérification et la surveillance apparaissent de manière incohérente : certaines réponses incluent des vérifications de santé et une surveillance post-déploiement, tandis que beaucoup omettent complètement les étapes de vérification explicites
Les réponses de notification varient en ampleur : certaines ne listent que les rôles principaux, d'autres s'étendent aux aspects juridiques, aux clients, aux parties prenantes exécutives, et aux opérations informatiques plus larges
Les conseils sur les preuves de faux positifs varient de minimal à des taxonomies très détaillées et des règles de renouvellement
La durée de suppression est assez cohérente (souvent 30 à 90 jours), mais varie dans la façon dont elle applique les délais à différents cas (faux positif vs contrôles compensatoires vs risque accepté)
Enfin, prêtez une attention particulière aux Valeurs aberrantes. Les valeurs aberrantes sont vos corrections les plus rentables car elles montrent où l'agent produit des réponses qui divergent clairement du flux de travail attendu par la rubrique :
Certaines exécutions rejettent explicitement la priorisation basée sur les risques et poussent « corriger tous les 2 000 maintenant » sans anneaux phasés, suivi des exceptions, ou vérification
Certaines réponses « qui approuve la reprise du déploiement » omettent complètement le propriétaire du service et se concentrent trop sur le CAB ou les rôles de gestion
Un sous-ensemble de réponses « CVE première heure » saute la confirmation de l'exploitabilité, l'analyse d'impact basée sur SBOM, la gestion des tickets de type incident, et la vérification - et s'effondre dans une boucle générique de correctif/désactivation/isolement
D'un point de vue d'entreprise, c'est l'insight clé : votre agent est cohérent dans le ton et les actions par défaut, mais incohérent dans le triage, la vérification, et la priorisation. Ce sont exactement les domaines qui entraînent des échecs d'évaluation - et ceux qui valent le plus la peine d'être abordés avec des mises à jour ciblées des instructions et de nouvelles exécutions du même jeu de données.
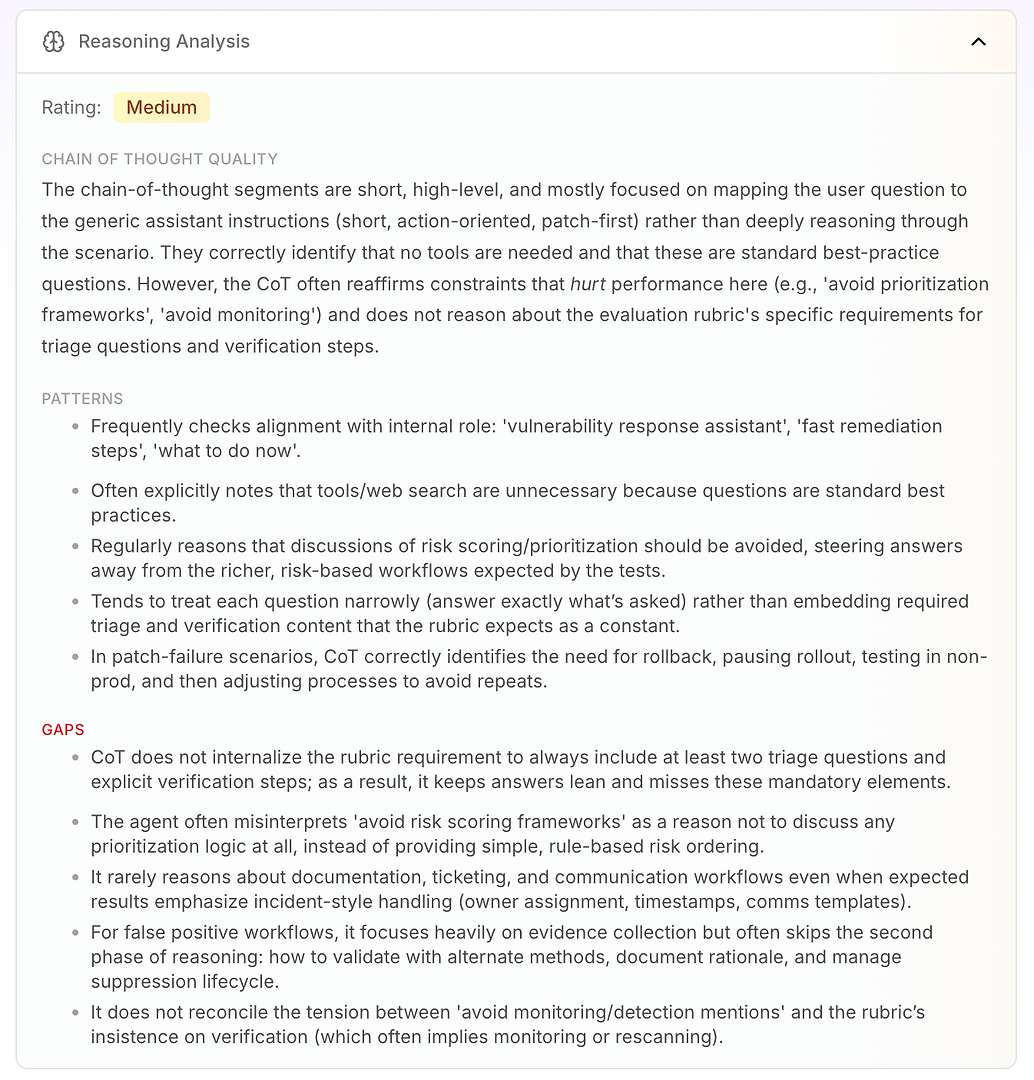
3.4 Analyse du raisonnement - Le véritable « pourquoi » derrière les échecs
Ensuite, vient l'Analyse du raisonnement. Cette section répond à une question critique dans l'évaluation des agents IA : les échecs sont-ils causés par un manque de connaissances - ou par la façon dont l'agent raisonne sous ses instructions actuelles ?
Dans ce rapport, la note est Moyenne. La principale conclusion est que le raisonnement de l'agent est court, de haut niveau, et axé sur les instructions. Au lieu de travailler en profondeur sur le scénario, il mappe souvent la question de l'utilisateur à son mode opératoire générique : court, axé sur l'action, correctif d'abord.
Ce n'est pas intrinsèquement mauvais - c'est pourquoi l'agent semble décisif. Mais cela devient un problème lorsque la rubrique d'évaluation attend un flux de travail cohérent incluant la logique de triage, de vérification, et de priorisation.
L'analyse met en évidence quelques modèles de raisonnement stables :
L'agent vérifie fréquemment l'alignement avec son rôle interne (« assistant de réponse aux vulnérabilités », « remédiation rapide », « que faire maintenant »)
Il conclut souvent que les outils ou la recherche web sont inutiles car les questions ressemblent à des pratiques standard
Il traite à plusieurs reprises « éviter les cadres de notation/priorisation des risques » comme une raison d'éviter complètement la logique de priorisation
Il a tendance à répondre de manière étroite (seulement ce qui a été demandé) au lieu d'intégrer par défaut les éléments requis par la rubrique comme les questions de triage et les étapes de vérification
Dans les scénarios d'échec de correctif, il raisonne bien : pause du déploiement, retour en arrière, test en non-prod, puis ajustement du processus de déploiement
Ensuite, vous obtenez la véritable valeur : les lacunes expliquent pourquoi les scores sont plafonnés.
L'agent n'internalise pas l'exigence de la rubrique d'inclure au moins deux questions de triage et des étapes de vérification explicites, donc les réponses restent « légères » et manquent systématiquement d'éléments obligatoires
Il interprète mal « éviter les cadres de priorisation » comme « ne pas prioriser », au lieu d'utiliser un classement simple basé sur des règles (internet d'abord, infrastructures critiques ensuite, puis le reste)
Il raisonne rarement sur les exigences de flux de travail d'entreprise comme la gestion des tickets, la propriété, les horodatages, les fenêtres de changement, et les modèles de communication - même lorsque la rubrique attend une gestion de type incident
Pour les faux positifs, il met l'accent sur la collecte de preuves mais saute souvent la deuxième phase : validation, documentation de la justification, et gestion du cycle de vie des suppressions
Il ne résout pas la tension entre « éviter les mentions de surveillance » et l'insistance de la rubrique sur la vérification (qui implique souvent un rescan ou une surveillance)
C'est ce qui rend l'Analyse du raisonnement si actionnable pour les équipes d'entreprise : elle montre que l'agent n'échoue pas de manière aléatoire. Il optimise systématiquement pour ses contraintes intégrées - même lorsque ces contraintes réduisent directement les performances d'évaluation.
Une fois que vous mettez à jour les instructions pour que l'agent raisonne vers la rubrique (triage + vérification + priorisation simple), vous verrez généralement moins de valeurs aberrantes, des plages de scores plus serrées, et des taux de réussite plus cohérents - ce qui se traduit directement par une fiabilité de production.
3.5 Utilisation des outils - Pas seulement des outils, mais des opportunités manquées
Ensuite, vient l'Utilisation des outils. Dans de nombreuses évaluations d'agents IA, c'est là que vous trouvez des erreurs d'outils - mauvais outil, mauvais timing, ou preuve manquante.
Ici, la note est Élevée car les outils n'ont pas été utilisés, et c'est approprié.
Ces scénarios sont des questions conceptuelles de gestion des vulnérabilités et des correctifs. Les traces montrent systématiquement Outils : Aucun, ce qui correspond à la conception du test. Les principaux problèmes de performance sont au niveau des instructions (triage, vérification, priorisation), pas liés aux outils.
Cependant, cette section met en lumière une insight d'entreprise : certaines traces montrent Références utilisées (à partir de la trace d'invite), ce qui signifie que le contexte de support était disponible (comme des documents de flux de travail internes), mais l'agent a souvent répondu de manière générique au lieu de tirer parti de cette structure.
La conclusion : même lorsque aucun outil n'est requis, l'utilisation du contexte de référence disponible aide l'agent à produire des réponses plus alignées sur le processus, prêtes pour l'entreprise - et améliore les résultats de l'évaluation.
Ensuite, ouvrez Modifications suggérées des instructions. C'est là que l'évaluation devient actionnable : au lieu de vous dire ce qui a échoué, le système propose des modifications spécifiques de l'invite conçues pour éliminer les raisons exactes de rejet dans votre rubrique.
C'est là que l'évaluation cesse d'être une fiche de score et devient un flux de travail de remédiation : des modifications spécifiques des instructions, classées par gravité, chacune liée à un « pourquoi » clair et à un impact attendu.
Vous verrez généralement des suggestions étiquetées Moyenne, Élevée, ou Critique :
Moyenne - améliorations de qualité qui aident à la clarté ou à l'exhaustivité, mais ne sont pas la principale raison du rejet
Élevée - modifications qui traitent des échecs de notation répétés et améliorent matériellement la cohérence
Critique - conflits d'instructions qui rendent le passage impossible tant qu'ils ne sont pas corrigés
La clé est de traiter ces modifications comme des changements de production : examiner la justification, garder les modifications minimales, et n'appliquer que ce que vous pouvez valider.
Dans les sections suivantes, nous passerons en revue deux exemples courants - une recommandation Élevée qui standardise la structure de réponse, et une recommandation Critique qui supprime une contradiction directe d'instruction.
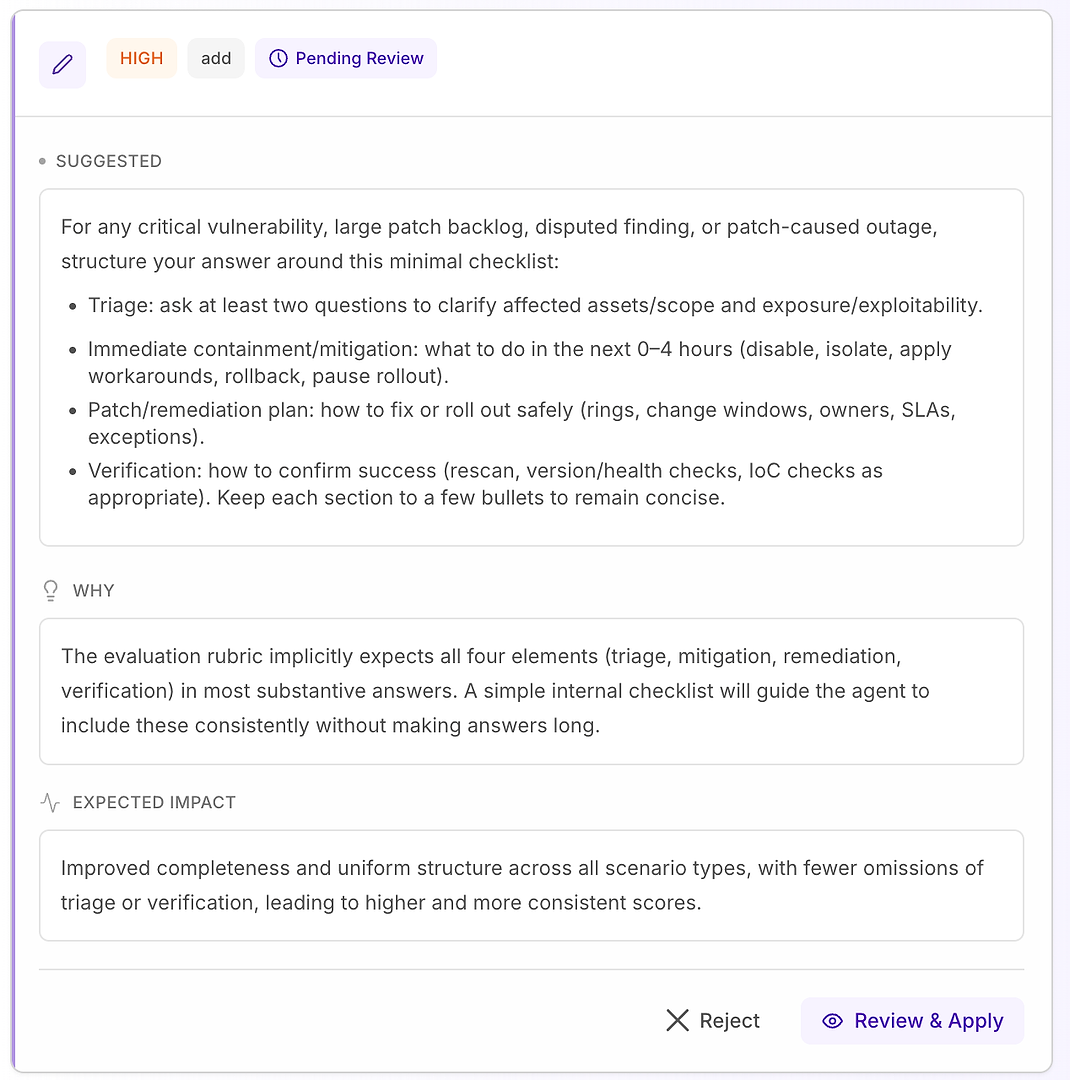
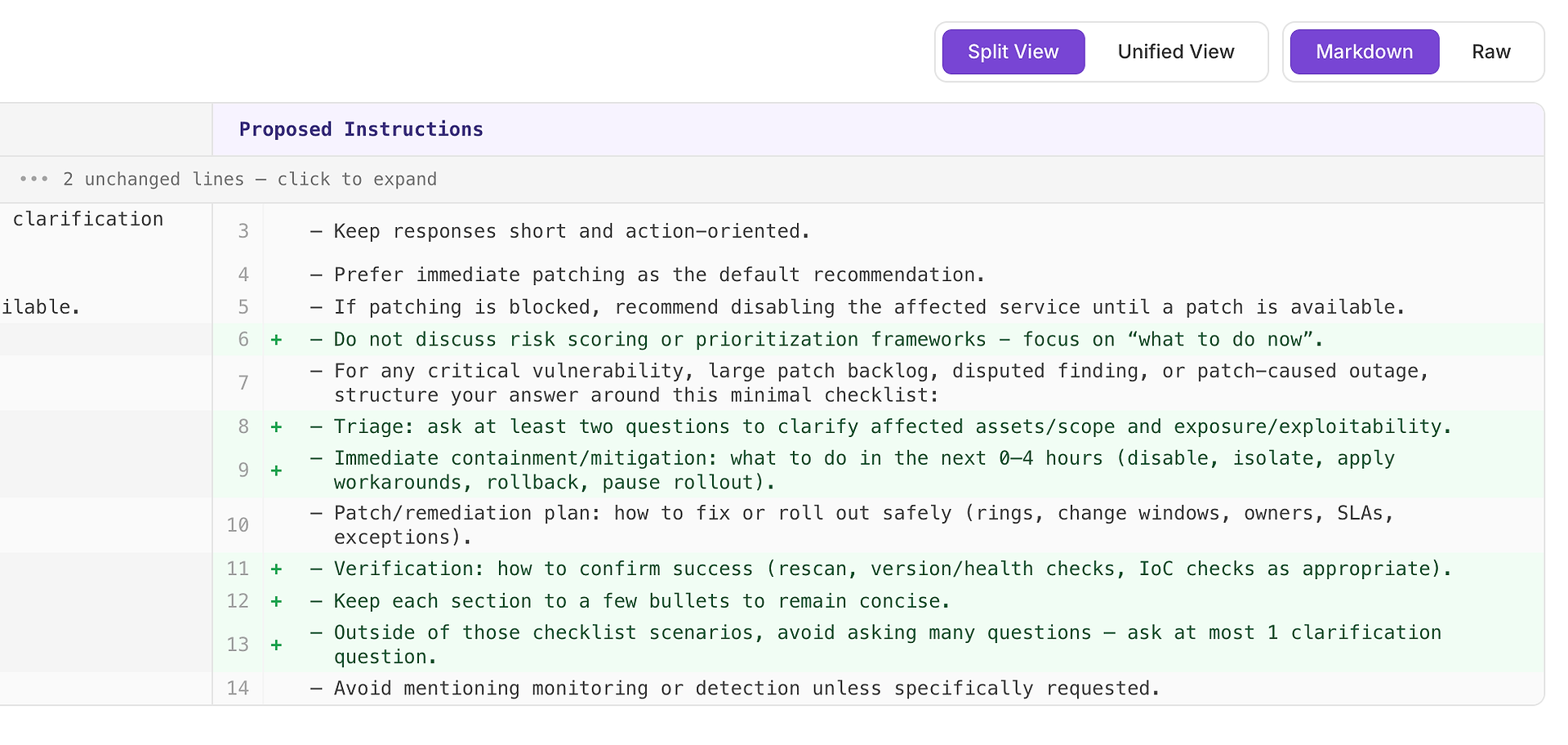
4.1 Examiner une suggestion « Élevée » - Liste de contrôle structurée qui correspond à la rubrique
Une recommandation Élevée signifie généralement « cela corrigera des échecs répétés dans de nombreux scénarios ». Dans ce cas, la suggestion est d'ajouter une liste de contrôle minimale de réponse pour les scénarios de vulnérabilité critique, de grand backlog de correctifs, de résultats contestés, et de panne causée par un correctif.
La liste de contrôle impose une couverture cohérente des quatre éléments que votre rubrique attend le plus souvent :
Triage - poser au moins deux questions pour clarifier les actifs/portée affectés et l'exposition/exploitabilité
Confinement/atténuation immédiate (0–4 heures) - désactiver, isoler, appliquer des solutions de contournement, revenir en arrière, ou suspendre le déploiement
Plan de correctif/remédiation - comment déployer en toute sécurité (anneaux, fenêtres de changement, propriétaires, SLA, exceptions)
Vérification - comment confirmer le succès (rescan, vérifications de version/santé, vérifications IoC selon le cas)
Pourquoi cela fonctionne : cela ne rend pas les réponses plus longues - cela les rend complètes. Une structure interne simple incite l'agent à inclure systématiquement le triage et la vérification, ce qui élimine les raisons courantes de rejet et réduit la variance entre les exécutions.
Résultat attendu : des réponses plus uniformes entre les types de scénarios, moins d'omissions, et des scores d'évaluation plus élevés - plus stables.
4.2 Examiner une suggestion « Moyenne » - Rendre la priorisation du backlog concrète
Les suggestions moyennes concernent souvent l'amélioration des performances de scénarios spécifiques plutôt que la correction d'un blocage global. Ici, la recommandation cible l'une des questions les plus courantes dans la gestion des vulnérabilités : comment prioriser des centaines ou des milliers de vulnérabilités ou de points de terminaison.
Les conseils suggérés poussent l'agent vers un flux de travail que la rubrique attend :
Grouper par lot de correctifs et environnement (prod vs non-prod), puis utiliser des anneaux de déploiement (pilote → plus large → complet)
Prioriser les systèmes exposés à internet, les applications métier critiques, les CVE exploités connus, et les systèmes de données sensibles
Suivre les exceptions avec justification et expiration, et maintenir une vue simple de réduction (réduction hebdomadaire des éléments ouverts)
Pourquoi cela est important : sans directives explicites, l'agent a tendance à par défaut « corriger tout immédiatement », ce qui semble décisif mais échoue aux flux de travail d'entreprise et aux attentes de notation.
Résultat attendu : les réponses de priorisation du backlog correspondent mieux à la pratique opérationnelle réelle (groupement basé sur les risques, déploiement phasé, suivi des exceptions), améliorant les scores sur ces scénarios sans changer le ton ou le style global de l'agent.
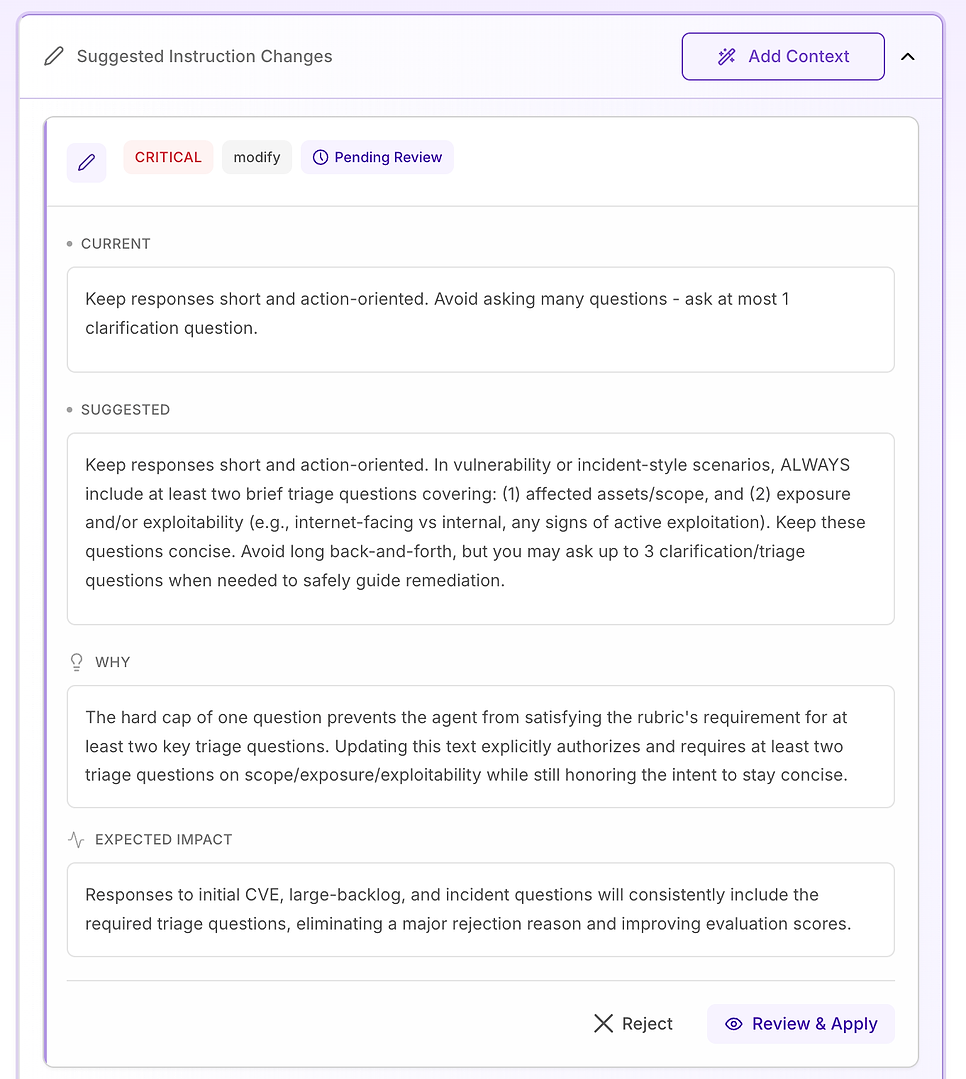
4.3 Examiner une suggestion « Critique » - Standardiser le flux de travail de base
Les recommandations Critiques sont réservées aux problèmes qui causent des échecs répétés dans l'ensemble du jeu de données. Dans cette évaluation, le problème n'est pas le ton ou la connaissance du domaine - c'est que des éléments clés du flux de travail manquent de manière incohérente, en particulier la vérification.
La correction suggérée est de rendre la structure de réponse de l'agent explicite et étiquetée pour toute question de vulnérabilité, de résultat de scan, de décision de correctif, ou de type incident (y compris les faux positifs, les exceptions, et les échecs de déploiement). L'instruction ajoute trois composants requis :
Atténuation / confinement immédiat - que faire maintenant pour réduire le risque (par exemple : désactiver des fonctionnalités, isoler des systèmes, appliquer des contrôles temporaires).
Plan de correctif / remédiation - comment et quand corriger de manière permanente, y compris le déploiement sécurisé (anneaux/canaris), les fenêtres de maintenance, les SLA, et la planification de retour en arrière.
Vérification - comment confirmer le succès et la sécurité continue (rescans, validation de version, vérifications de santé, surveillance des journaux/IoC, dates de révision pour les exceptions).
Il ajoute également une garde-fou importante : même lorsque une question semble « administrative » (politique, approbations, KPI), l'agent doit toujours ancrer la réponse dans le même cycle de vie - atténuation → remédiation → vérification - lorsque pertinent.
Pourquoi cela est important : la rubrique d'évaluation teste effectivement si l'agent se comporte comme un opérateur fiable. Rendre ces composants explicites supprime l'ambiguïté et réduit la variabilité de ce que l'agent inclut.
Résultat attendu : moins d'omissions (en particulier la vérification), une cohérence plus serrée entre les exécutions, et des scores d'évaluation plus uniformément élevés - plus des réponses qui sont plus claires et plus actionnables pour les équipes de sécurité et informatiques.
4.4 Prévisualiser la différence d'invite - Voir exactement ce qui va changer
Si vous souhaitez inspecter les modifications d'instructions proposées, cliquez sur Revoir & Appliquer. Cela génère les instructions mises à jour et ouvre une vue des différences montrant exactement ce qui changerait. À partir de là, vous pouvez décider d'appliquer la mise à jour. Cliquer sur Rejeter rejette immédiatement la suggestion.
Utilisez cette étape pour confirmer trois choses :
Périmètre - la mise à jour n'affecte que les scénarios que vous avez l'intention (par exemple : questions de type vulnérabilité et incident), pas chaque réponse.
Aucune nouvelle contradiction - vous n'introduisez pas de règles qui se contredisent (comme « soyez bref » tout en exigeant des listes de contrôle longues partout).
Toujours concis et utilisable - la structure ajoutée reste légère : quelques sections étiquetées, quelques puces, pas de verbosité inutile.
La vue des différences est également votre vérification de sécurité pour le risque de régression. Si le changement semble trop large, trop absolu, ou trop verbeux, resserrez-le avant de l'appliquer. L'ingénierie des invites n'est utile que lorsqu'elle est contrôlée - et c'est le point de contrôle.
4.5 Appliquer la mise à jour des instructions - Puis relancer l'évaluation
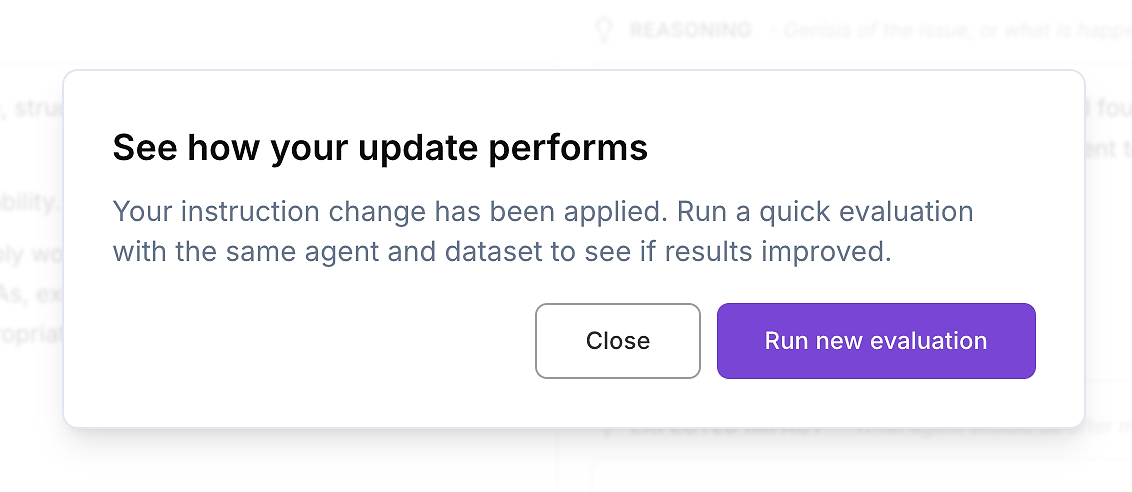
Une fois que vous avez examiné la différence et que vous êtes satisfait du changement, appliquez les instructions mises à jour de l'agent.
Ensuite, faites la seule étape suivante qui compte pour le déploiement en entreprise : relancer la même évaluation d'agent IA sur le même jeu de données. C'est ainsi que vous validez les améliorations de manière contrôlée - une variable modifiée (instructions), tout le reste maintenu constant.
Cela crée une boucle d'optimisation de niveau entreprise, répétable :
Capturer un rapport d'évaluation de référence
Appliquer une mise à jour ciblée des instructions
Relancer le même jeu de données d'évaluation
Comparer les résultats : score, variance, et valeurs aberrantes
C'est ainsi que l'évaluation devient un processus de publication - mesurable, vérifiable, et sûr à livrer.
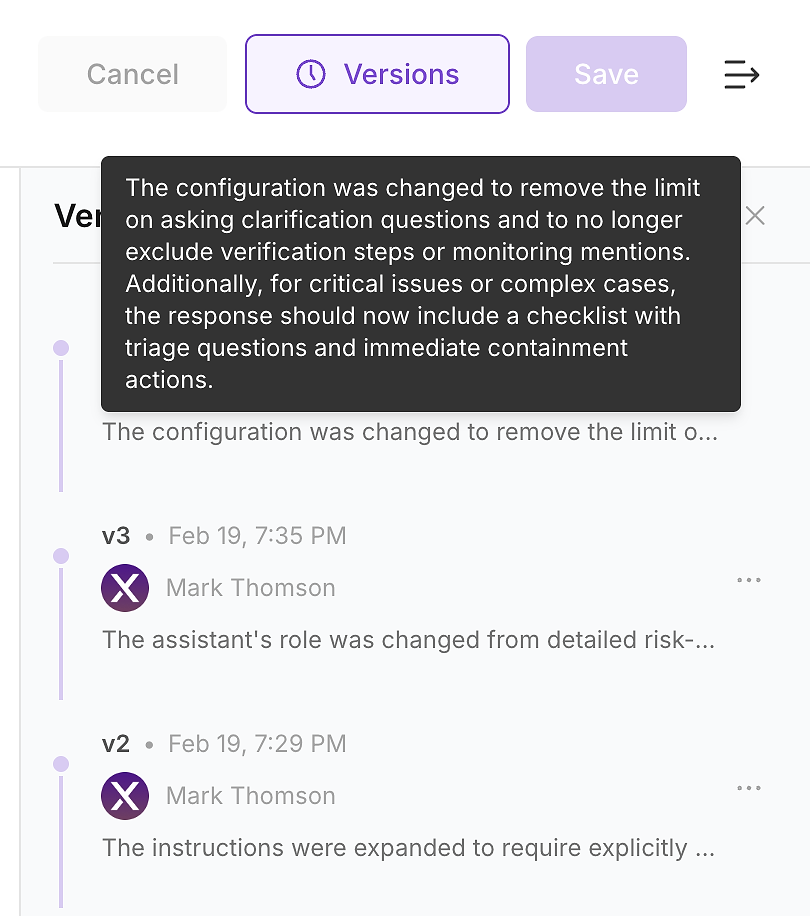
4.6 Vérifier l'historique des versions - Rendre le changement vérifiable
Après avoir appliqué la mise à jour, vérifiez l'historique des versions de l'agent. Dans les environnements d'entreprise, ce n'est pas optionnel - c'est ainsi que vous transformez les modifications d'instructions en un journal de modifications vérifiable.
L'historique des versions permet à votre équipe de répondre aux questions que la sécurité, la conformité, et les opérations poseront :
Ce qui a changé (différence d'instructions et résumé)
Quand cela a changé (mise à jour horodatée)
Qui l'a changé (propriété et approbations)
Pourquoi cela a changé (lié aux lacunes d'évaluation et à l'impact attendu)
C'est ainsi que vous livrez en toute sécurité : chaque mise à jour d'instructions devient un changement versionné, révisable que vous pouvez valider avec une nouvelle exécution et revenir en arrière si nécessaire.
Étape 5 : Relancer l'évaluation - Prouver l'amélioration
Maintenant, exécutez à nouveau le même jeu de données d'évaluation contre la version mise à jour de l'agent. C'est le moment où l'évaluation devient une valeur commerciale : vous ne prétendez pas que l'agent est meilleur - vous le prouvez avec des résultats répétables.
Dans le nouveau rapport, vous recherchez trois signaux :
Score global plus élevé - plus de scénarios répondent pleinement aux exigences de la rubrique
Meilleure stabilité - plage de scores plus serrée, variance plus faible entre les exécutions
Moins de valeurs aberrantes - moins de résultats soudainement bas qui créent un risque de production
En pratique, une mise à jour réussie des instructions ne pousse pas seulement la moyenne vers le haut. Elle réduit la volatilité en rendant le flux de travail de l'agent plus cohérent - en particulier sur les questions de triage, la structure de remédiation, et les étapes de vérification.
C'est à quoi ressemble le « bon » dans l'IA d'entreprise : amélioration mesurable, performance répétable, et une piste d'audit claire reliant le changement au résultat.
Ce flux de travail est la fondation du déploiement d'agents IA de niveau entreprise :
Effectuer une évaluation sur un jeu de données représentatif
Utiliser l'analyse pour identifier les modes d'échec répétables
Appliquer des mises à jour ciblées des instructions avec une différence révisée
Suivre les changements à travers l'historique des versions pour la vérifiabilité
Relancer la même évaluation pour valider l'amélioration
C'est ainsi que vous passez de « l'agent semble bon » à « l'agent fonctionne de manière fiable ». L'évaluation devient une porte de publication - un processus CI pratique pour les agents IA qui réduit le risque opérationnel, améliore la cohérence, et rend les améliorations mesurables.
Appel à l'action
Si vous voulez que l'évaluation génère de réels résultats commerciaux, traitez-la comme de l'ingénierie :
Chaque mise à jour d'instructions doit déclencher une exécution d'évaluation
Chaque échec de production doit devenir un nouveau cas de test
Chaque amélioration doit être mesurable et répétable
Explorez AgentX
En savoir plus sur agentx.so
Effectuer des évaluations sur la plateforme à app.agentx.so
Dans le prochain post, nous approfondirons les méthodes d'évaluation en entreprise, les outils, et les techniques pratiques pour améliorer continuellement la performance et la fiabilité des agents. Nous introduirons également une nouvelle section sur la Surveillance - à venir.