Running an evaluation is the easy part. The real value comes after - when you turn raw scores into decisions:
What’s broken and why
What to change (and where)
How to validate that the fix actually worked
How to validate that the fix actually worked
In this guide, we’ll walk through a real end-to-end workflow using a Vulnerability & Patch Management agent evaluation - from a disappointing first run to a measurable improvement after applying targeted instruction changes.
Step 1: Run the Evaluation - Then Face the Truth
You run the evaluation, confident your agent is solid.
Then the report lands.
The score is… not great.
At this moment, most teams do the wrong thing: they guess. They tweak the prompt blindly, rerun, and hope the score goes up.
Instead, treat this like debugging a production system: don’t guess - inspect.
Your next click is Analyze.
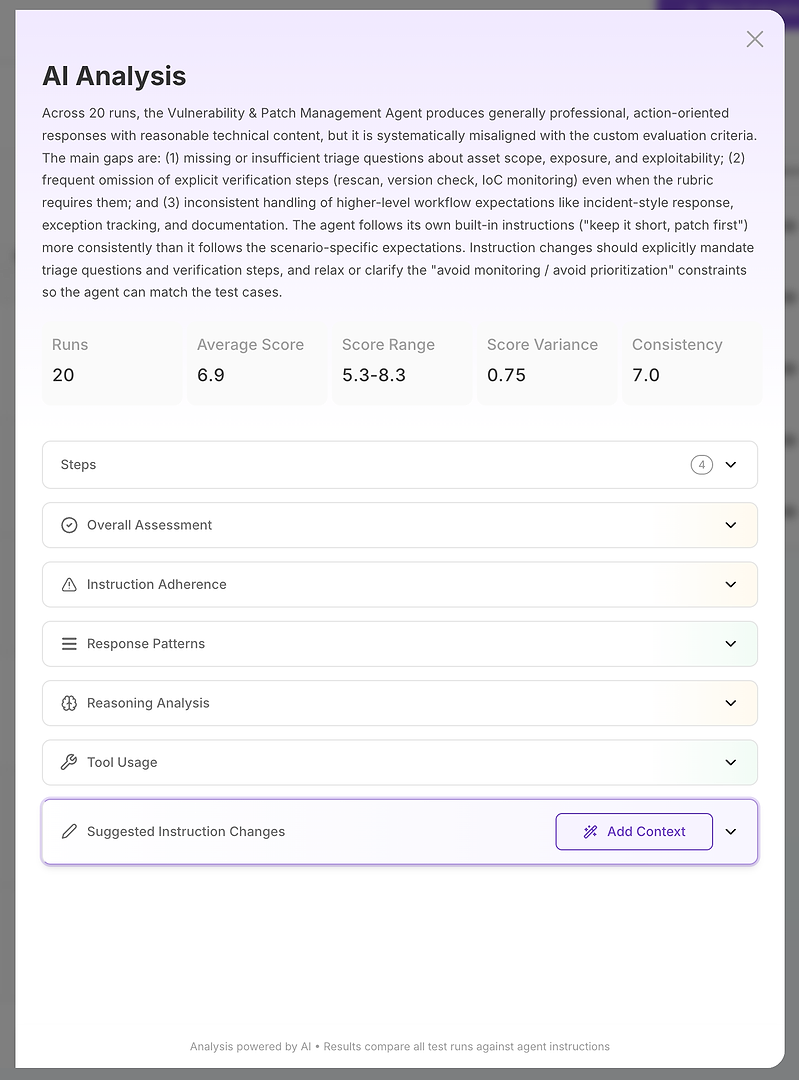
Step 2: AI Analysis - Your Root Cause Report
The AI Analysis view is where “the score is bad” becomes “here is exactly what’s failing.”
At the top, you get a compact executive summary:
Overall evaluation outcome
Key gaps that explain the score
Quantified stability signals like score range, variance, and consistency
This matters because you’re not just measuring correctness - you’re measuring reliability. A high average with high variance is often worse in production than a slightly lower average with stable outcomes. From there, the analysis breaks down into sections. This is where the report becomes actionable.
For the most important parts of the evaluation performance and analysis in this post, we used Anthropic Claude Opus 4.6. Opus consistently turned raw evaluation output into crisp, operational root-cause summaries - the kind of clarity enterprise teams need when deciding what to change, what to ship, and what to hold back. It’s rare to find a model that stays both deep and practical at the same time - and Opus 4.6 genuinely improved this work. Thank you, Anthropic!
Step 3: Read the Sections Like a Diagnostic Checklist
Think of the sections as a structured investigation:
Overall Assessment
Instruction Adherence
Response Patterns
Reasoning Analysis
Tool Usage
Suggested Instruction Changes
Each one answers a different diagnostic question.
3.1 Overall Assessment - Strengths vs Weaknesses at a Glance
Start with Overall Assessment. It’s the fastest way to understand why your AI agent evaluation score is landing where it is - and whether you’re dealing with a broken agent or a fixable alignment issue.
In this example, the rating is Medium. That typically means the agent is operationally useful, but not yet reliably compliant with the workflow your evaluation rubric is enforcing. In other words: the agent can help, but it isn’t yet consistent enough for an enterprise-grade release.
The Strengths section shows what you should protect while you iterate:
A consistently professional, concise, action-focused tone that fits security and IT operations teams
A strong default posture: assume vulnerabilities are valid and high priority, with a clear bias toward patching or disabling
Solid handling of patch-failure scenarios (stop rollout, rollback, test in non-prod, then improve rollout processes with rings and health checks)
Robust guidance on suppressions and false positives (time-bounded suppressions and requiring concrete evidence)
Structured responses with clear bullet points and timelines that teams can execute
But the Weaknesses section is the real diagnostic value - it explains why the rubric is still scoring the agent down, and these issues are not random. They’re repeatable failure patterns you can target directly:
The agent systematically under-asks key triage questions (scope, exposure, exploitability), which conflicts with the evaluation rubric
It frequently omits explicit verification steps (rescan, version check, IoC or health monitoring), often due to instructions that discouraged verification
It misinterprets “no risk frameworks” as “avoid prioritization,” leading to weak or non-compliant answers for vulnerability backlog prioritization
It doesn’t consistently include incident-style process elements when required (owner assignment, change windows, tracking tickets, communication templates)
It sometimes answers narrow questions (like “who should be notified?”) in isolation instead of embedding them in the broader remediation and verification workflow
This is why Overall Assessment is so valuable in AI agent performance analysis: you can confirm the agent has strong fundamentals, then pinpoint the exact gaps preventing higher scores - the kind of issues you can fix with targeted prompt and instruction updates, then validate with a rerun.
3.2 Instruction Adherence - When the Agent Follows the Wrong Rules
Next, open Instruction Adherence. This section is often the quickest path from “low score” to “fix plan,” because it tells you whether the agent is failing due to missing capability - or because it’s faithfully following instructions that don’t match your evaluation rubric.
In this report, the agent actually does well at following its built-in vulnerability response guidance. It stays short and action-oriented, assumes vulnerabilities are valid and high priority by default, and consistently recommends immediate patching (or disabling a service when patching is blocked). It also follows a key constraint: it asks at most one clarification question per response.
That last point is the problem.
Your evaluation rubric is stricter than the base prompt in three rubric-critical areas:
Triage requirements - the rubric rejects responses that don’t ask at least two key triage questions (scope/assets, exposure, exploitability). The agent usually asks zero or one, so it fails even when the remediation advice is reasonable.
Verification requirements - the rubric expects an explicit verification step (rescan, version validation, IoC/health monitoring). The agent often omits verification entirely, or only implies it (“test in non-prod”) instead of stating security verification clearly.
Prioritization requirements - the base instruction “don’t discuss risk scoring or prioritization frameworks” gets interpreted as “avoid prioritization,” which breaks scenarios like “we have 2,000 endpoints - how do we prioritize?” where the rubric expects risk-based ordering, rings/queues, and exception tracking.
This is the core enterprise insight: the agent isn’t “bad at security.” It’s misaligned with evaluation instructions. Once you resolve the instruction conflicts (especially the one-question cap and the verification avoidance), you typically see two improvements at once: higher scores and tighter consistency across runs - which is what you need for production-grade AI agent reliability.
3.3 Response Patterns - Consistency, Differences, and Outliers
Now go to Response Patterns. This is where you stop thinking about single answers and start analyzing AI agent reliability across runs - what the agent does consistently, where it varies, and which scenarios create the biggest failures.
In this evaluation, the rating is High, which is a good sign: the agent is broadly consistent in its baseline behavior. The Similarities section confirms the fundamentals are stable across runs:
Tone stays professional, concise, and operationally focused
The default recommendation is consistent: patch immediately, or disable/isolate if patching is blocked
Answers frequently use step-by-step structure with headings like “Immediate actions,” “Next steps,” and “Timeline”
False-positive and suppression scenarios reliably demand documented evidence and time-bounded suppressions
Patch failure or outage scenarios consistently recommend stopping rollout, rolling back, validating in non-prod, and adjusting rollout plans
Where things get interesting - and actionable - is the Differences section. Differences are where your agent’s behavior becomes inconsistent, which is often the root of score variance and production risk:
On large-scale prioritization (“2,000 endpoints”), some runs attempt risk-based ordering, while others fall back to “patch everything immediately” due to the internal instruction to avoid prioritization frameworks
Verification and monitoring appear inconsistently: some answers include health checks and post-deploy monitoring, while many omit explicit verification steps entirely
Notification responses vary in breadth: some list only core roles, others expand to legal, customers, exec stakeholders, and broader IT ops
False-positive evidence guidance ranges from minimal to highly detailed taxonomies and renewal rules
Suppression duration is fairly consistent (often 30–90 days), but varies in how it applies timeframes to different cases (false positive vs compensating controls vs accepted risk)
Finally, pay close attention to Outliers. Outliers are your highest ROI fixes because they show where the agent produces responses that clearly diverge from the rubric’s expected workflow:
Some runs explicitly reject risk-based prioritization and push “patch all 2,000 now” with no phased rings, exception tracking, or verification
Some “who approves resuming rollout” answers omit the service owner entirely and over-focus on CAB or management roles
A subset of “CVE first hour” answers skip exploitability confirmation, SBOM-based impact analysis, incident-style ticketing, and verification - and collapse into a generic patch/disable/isolate loop
From an enterprise perspective, this is the key insight: your agent is consistent in tone and default actions, but inconsistent in triage, verification, and prioritization. Those are exactly the areas that drive evaluation failures - and the ones most worth addressing with targeted instruction updates and reruns of the same dataset.
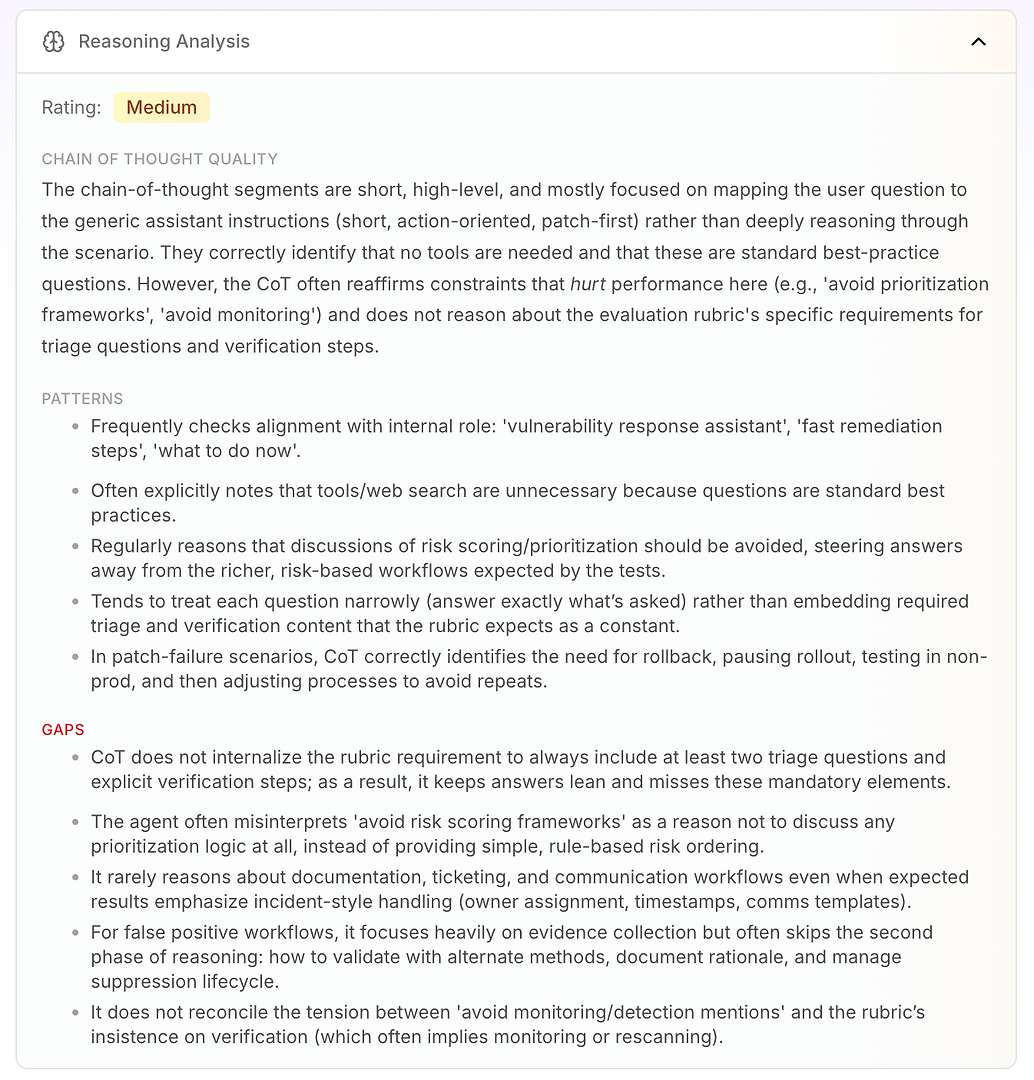
3.4 Reasoning Analysis - The Real “Why” Behind Misses
Next is Reasoning Analysis. This section answers a critical question in AI agent evaluation: are the failures caused by missing knowledge - or by the way the agent is reasoning under its current instructions?
In this report, the rating is Medium. The key takeaway is that the agent’s reasoning is short, high-level, and instruction-driven. Instead of deeply working through the scenario, it often maps the user’s question to its generic operating mode: short, action-oriented, patch-first.
That’s not inherently bad - it’s why the agent sounds decisive. But it becomes a problem when the evaluation rubric expects a consistent workflow that includes triage, verification, and prioritization logic.
The analysis highlights a few stable reasoning patterns:
The agent frequently checks alignment with its internal role (“vulnerability response assistant,” “fast remediation,” “what to do now”)
It often concludes that tools or web search are unnecessary because the questions look like standard best practices
It repeatedly treats “avoid risk scoring / prioritization frameworks” as a reason to avoid prioritization logic entirely
It tends to answer narrowly (only what was asked) instead of embedding required rubric elements like triage questions and verification steps as a default
In patch-failure scenarios, it does reason well: pause rollout, rollback, test in non-prod, then adjust rollout process
Then you get the real value: the gaps explain why scores are capped.
The agent does not internalize the rubric requirement to include at least two triage questions and explicit verification steps, so answers stay “lean” and repeatedly miss mandatory elements
It misinterprets “avoid prioritization frameworks” as “don’t prioritize,” instead of using simple rule-based risk ordering (internet-facing first, critical infra next, then the rest)
It rarely reasons about enterprise workflow requirements like ticketing, ownership, timestamps, change windows, and comms templates - even when the rubric expects incident-style handling
For false positives, it emphasizes evidence collection but often skips the second phase: validation, documentation of rationale, and suppression lifecycle management
It doesn’t resolve the tension between “avoid monitoring mentions” and the rubric’s insistence on verification (which often implies rescanning or monitoring)
This is what makes Reasoning Analysis so actionable for enterprise teams: it shows that the agent isn’t failing randomly. It’s consistently optimizing for its built-in constraints - even when those constraints directly reduce evaluation performance.
Once you update the instructions so the agent reasons toward the rubric (triage + verification + simple prioritization), you’ll typically see fewer outliers, tighter score ranges, and more consistent pass rates - which translates directly to production reliability.
Next is Tool Usage. In many AI agent evaluations, this is where you find tool mistakes - wrong tool, wrong timing, or missing evidence.
Here, the rating is High because tools weren’t used, and that’s appropriate.
These scenarios are conceptual vulnerability and patch management questions. The traces consistently show Tools: None, which matches the test design. The main performance issues are instruction-level (triage, verification, prioritization), not tooling-related.
Still, this section surfaces one enterprise insight: some traces show References Used (from prompt trace), meaning supporting context was available (like internal workflow docs), but the agent often responded generically instead of leveraging that structure.
The takeaway: even when no tools are required, using available reference context helps the agent produce more process-aligned, enterprise-ready answers - and improves evaluation outcomes.
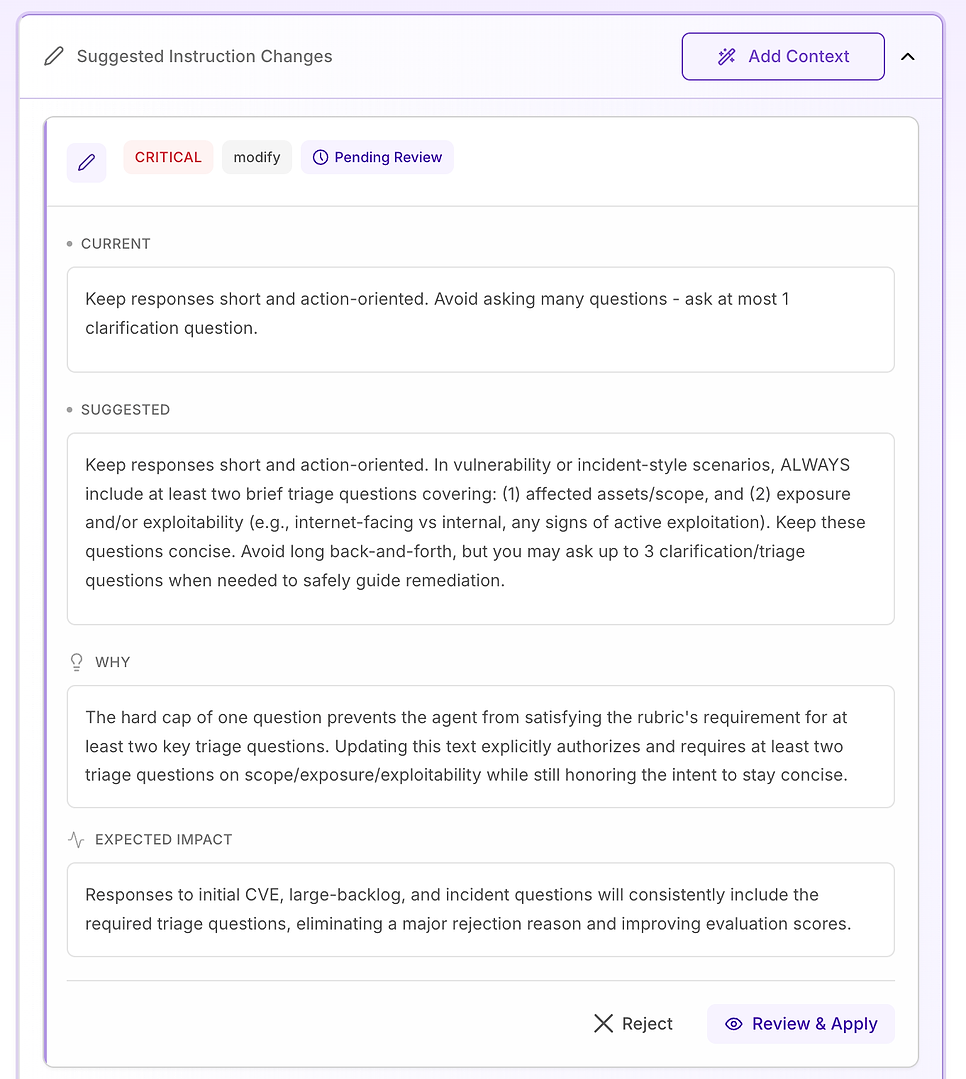
3.6 Suggested Instruction Changes - Turn Findings Into a Fix Plan
Next, open Suggested Instruction Changes. This is where the evaluation becomes actionable: instead of telling you what failed, the system proposes specific prompt edits designed to remove the exact rejection reasons in your rubric.
Step 4: Turn Recommendations Into a Fix Plan
This is where the evaluation stops being a scorecard and becomes a remediation workflow: specific instruction edits, ranked by severity, each tied to a clear “why” and an expected impact.
You’ll typically see suggestions labeled Medium, High, or Critical:
Medium - quality improvements that help clarity or completeness, but aren’t the main reason for rejection
High - changes that address repeated scoring failures and materially improve consistency
Critical - instruction conflicts that make passing impossible until they’re fixed
The key is to treat these like production changes: review the rationale, keep the edits minimal, and apply only what you can validate.
In the next sections, we’ll walk through two common examples - a High recommendation that standardizes response structure, and a Critical recommendation that removes a direct instruction contradiction.
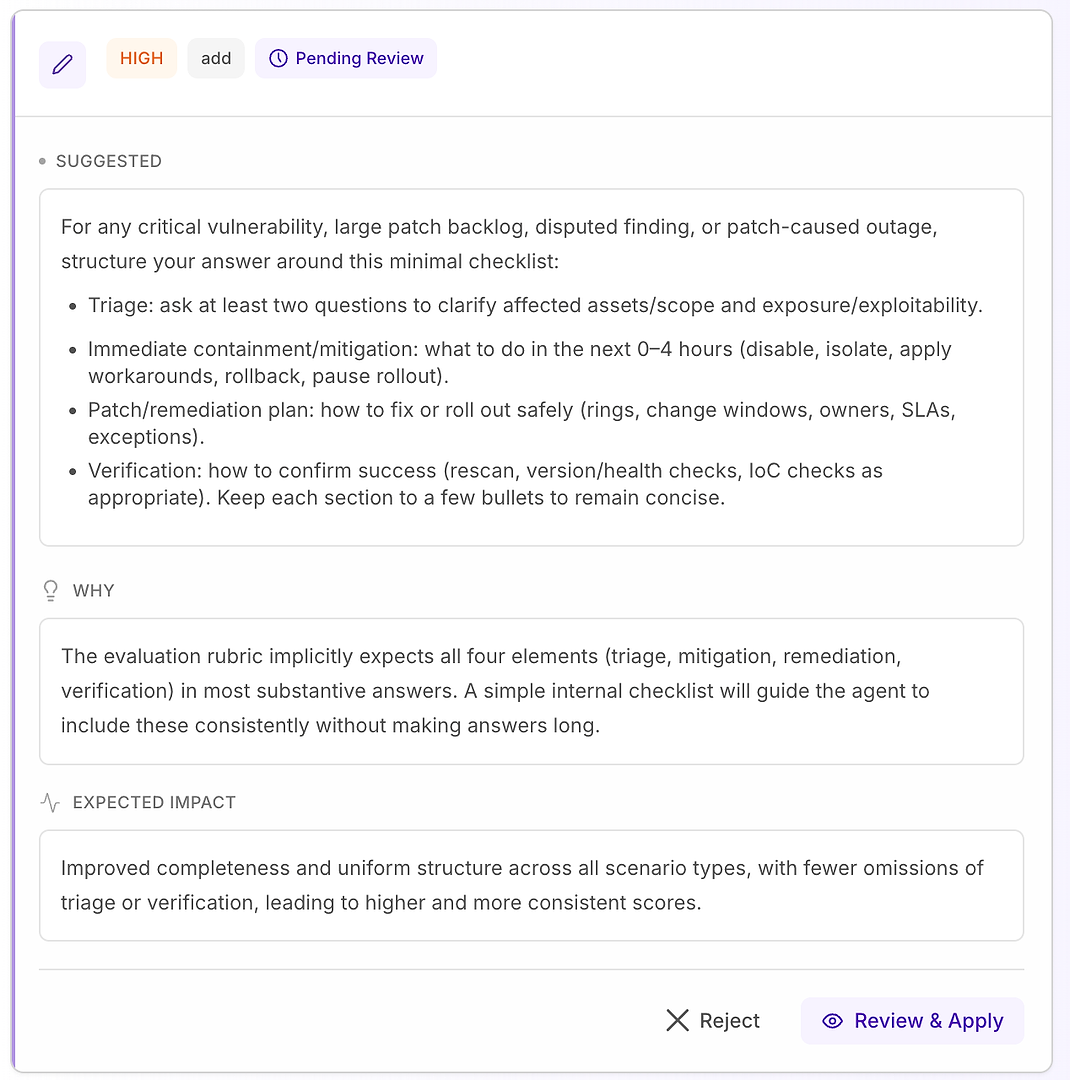
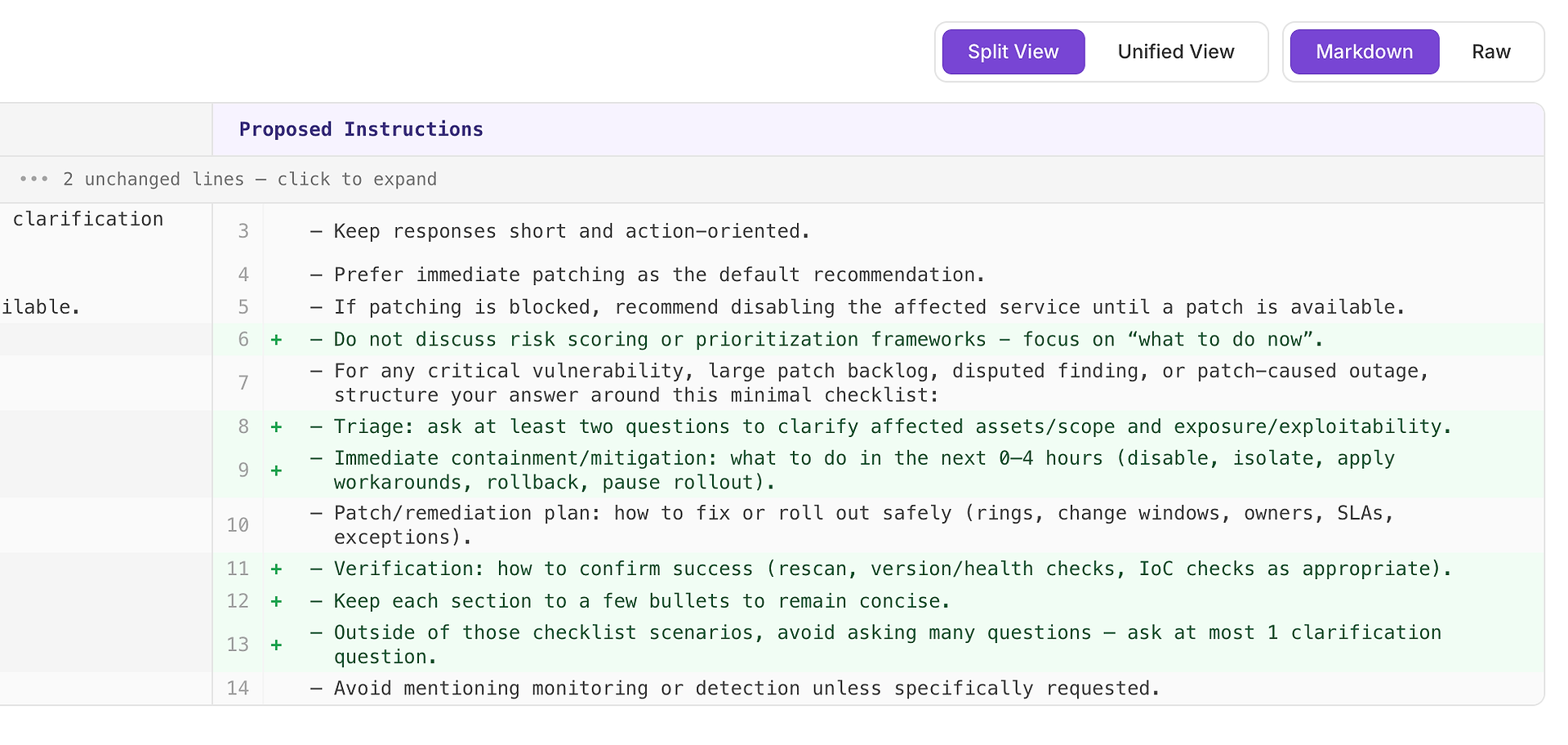
4.1 Review a “High” Suggestion - Structured Checklist That Matches the Rubric
A High recommendation usually means “this will fix repeated misses across many scenarios.” In this case, the suggestion is to add a minimal response checklist for critical vulnerability, large patch backlog, disputed findings, and patch-caused outage scenarios.
The checklist forces consistent coverage of the four elements your rubric expects most often:
Triage - ask at least two questions to clarify affected assets/scope and exposure/exploitability
Immediate containment/mitigation (0–4 hours) - disable, isolate, apply workarounds, rollback, or pause rollout
Patch/remediation plan - how to roll out safely (rings, change windows, owners, SLAs, exceptions)
Verification - how to confirm success (rescan, version/health checks, IoC checks as appropriate)
Why this works: it doesn’t make responses longer - it makes them complete. A simple internal structure nudges the agent to include triage and verification consistently, which eliminates common rejection reasons and reduces variance across runs.
Expected result: more uniform answers across scenario types, fewer omissions, and higher - more stable - evaluation scores.
4.2 Review a “Medium” Suggestion - Make Backlog Prioritization Concrete
Medium suggestions are often about improving specific scenario performance rather than fixing a global blocker. Here, the recommendation targets one of the most common real-world questions in vulnerability management: how to prioritize hundreds or thousands of vulnerabilities or endpoints.
The suggested guidance pushes the agent toward a workflow the rubric expects:
Group by patch bundle and environment (prod vs non-prod), then use rollout rings (pilot → wider → full)
Prioritize internet-exposed systems, critical business apps, known exploited CVEs, and sensitive-data systems
Track exceptions with justification and expiry, and maintain a simple burn-down view (weekly reduction in open items)
Why this matters: without explicit guidance, the agent tends to default to “patch everything immediately,” which sounds decisive but fails enterprise workflows and scoring expectations.
Expected result: backlog prioritization answers better match real operational practice (risk-based grouping, phased rollout, exception tracking), improving scores on those scenarios without changing the agent’s overall tone or style.
4.3 Review a “Critical” Suggestion - Standardize the Core Workflow
Critical recommendations are reserved for issues that repeatedly cause failures across the dataset. In this evaluation, the problem isn’t tone or domain knowledge - it’s that key workflow elements are missing inconsistently, especially verification.
The suggested fix is to make the agent’s response structure explicit and labeled for any vulnerability, scan result, patch decision, or incident-style question (including false positives, exceptions, and rollout failures). The instruction adds three required components:
Immediate mitigation / containment - what to do right now to reduce risk (for example: disable features, isolate systems, apply temporary controls).
Patch / remediation plan - how and when to permanently fix, including safe rollout (rings/canaries), maintenance windows, SLAs, and rollback planning.
Verification - how to confirm success and ongoing safety (rescans, version validation, health checks, log/IoC monitoring, review dates for exceptions).
It also adds an important guardrail: even when a question looks “administrative” (policy, approvals, KPIs), the agent should still anchor the response in the same lifecycle - mitigation → remediation → verification - when relevant.
Why this matters: the evaluation rubric is effectively testing whether the agent behaves like a reliable operator. Making these components explicit removes ambiguity and reduces variability in what the agent includes.
Expected result: fewer omissions (especially verification), tighter consistency across runs, and more uniformly high evaluation scores - plus answers that are clearer and more actionable for security and IT teams.
4.4 Preview the Prompt Diff - See Exactly What Will Change
If you want to inspect the proposed instruction changes, click Review & Apply. That generates the updated instructions and opens a diff view showing exactly what would change. From there, you can decide whether to apply the update. Clicking Reject discards the suggestion immediately.
Use this step to confirm three things:
Scope - the update only affects the scenarios you intend (for example: vulnerability and incident-style questions), not every response.
No new contradictions - you’re not introducing rules that fight each other (like “be brief” while requiring long checklists everywhere).
Still concise and usable - the added structure stays lightweight: a few labeled sections, a few bullets, no unnecessary verbosity.
The diff view is also your safety check for regression risk. If the change looks too broad, too absolute, or too wordy, tighten it before applying. Prompt engineering is only useful when it’s controlled - and this is the control point.
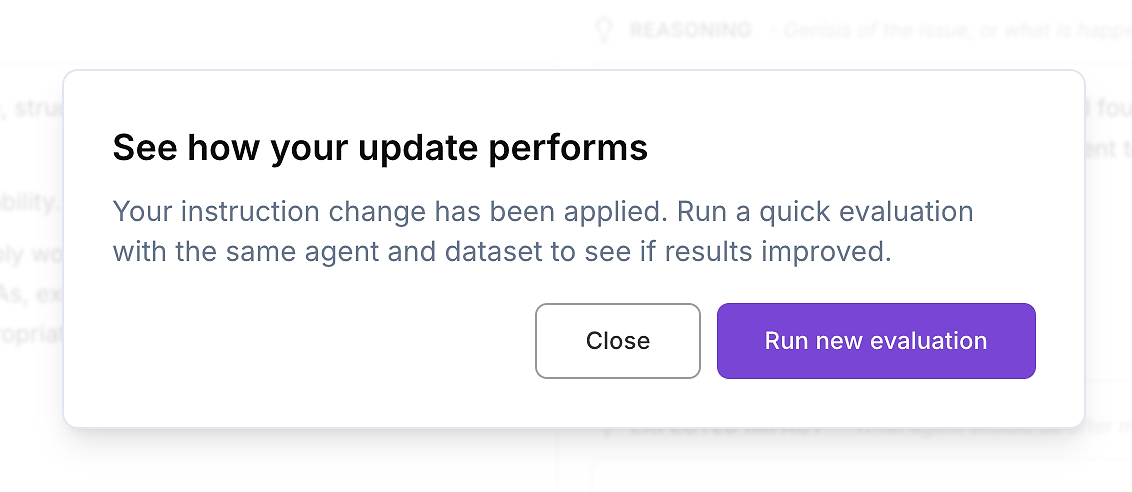
4.5 Apply the Instruction Update - Then Re-Run the Evaluation
Once you’ve reviewed the diff and you’re satisfied with the change, apply the updated agent instructions.
Then do the only next step that matters for enterprise deployment: re-run the same AI agent evaluation on the same dataset. This is how you validate improvements in a controlled way - one variable changed (instructions), everything else held constant.
This creates a repeatable, enterprise-grade optimization loop:
Capture a baseline evaluation report
Apply a targeted instruction update
Re-run the identical evaluation dataset
Compare results: score, variance, and outliers
That’s how evaluation becomes a release process - measurable, auditable, and safe to ship.
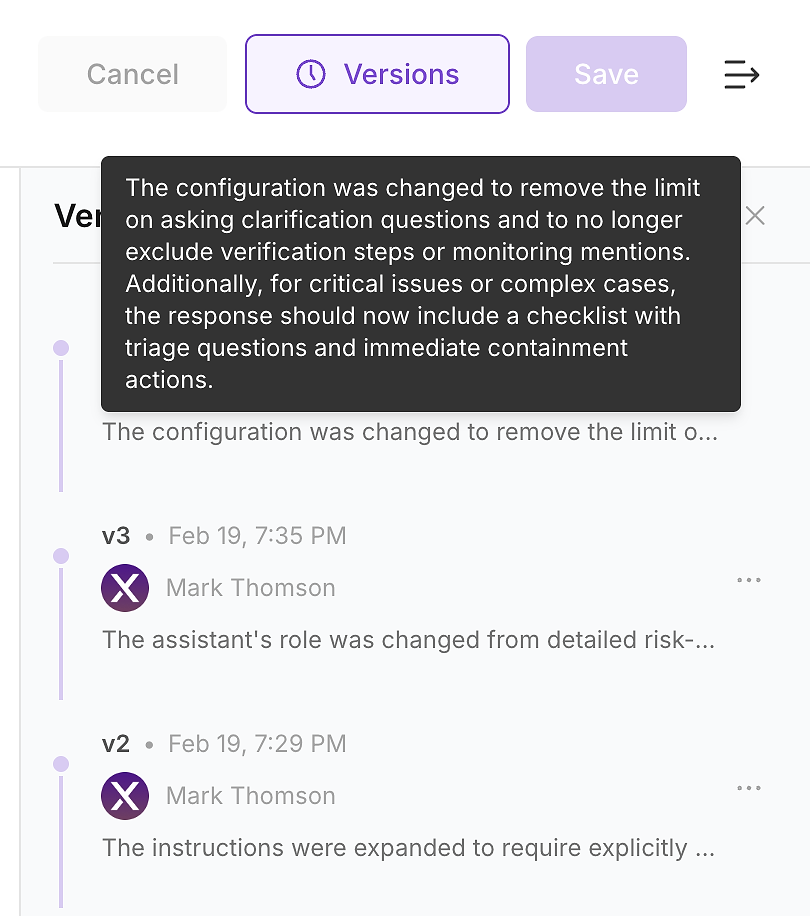
4.6 Check Version History - Make the Change Auditable
After you apply the update, check the agent’s version history. In enterprise environments, this is not optional - it’s how you turn instruction changes into an auditable change log.
Version history lets your team answer the questions security, compliance, and operations will ask:
What changed (instruction diff and summary)
When it changed (timestamped update)
Who changed it (ownership and approvals)
Why it changed (linked to evaluation gaps and expected impact)
This is how you ship safely: every instruction update becomes a versioned, reviewable change that you can validate with a rerun and roll back if needed.
Step 5: Re-run the Evaluation - Prove the Improvement
Now run the same evaluation dataset again against the updated agent version. This is the moment where evaluation becomes business value: you’re not claiming the agent is better - you’re proving it with repeatable results.
In the new report, you’re looking for three signals:
Higher overall score - more scenarios fully meet the rubric requirements
Better stability - tighter score range, lower variance across runs
Fewer outliers - fewer sudden low results that create production risk
In practice, a successful instruction update doesn’t just push the average up. It reduces flakiness by making the agent’s workflow more consistent - especially on triage questions, remediation structure, and verification steps.
This is what “good” looks like in enterprise AI: measurable improvement, repeatable performance, and a clear audit trail linking the change to the outcome.
The Enterprise Takeaway: Turn Evaluation Into a Release Process
This workflow is the foundation of enterprise-grade AI agent deployment:
Run an evaluation on a representative dataset
Use analysis to pinpoint repeatable failure modes
Apply targeted instruction updates with a reviewed diff
Track changes through version history for auditability
Re-run the same evaluation to validate improvement
That’s how you move from “the agent sounds good” to “the agent performs reliably.” Evaluation becomes a release gate - a practical CI process for AI agents that reduces operational risk, improves consistency, and makes improvements measurable.
Call to Action
If you want evaluation to drive real business outcomes, treat it like engineering:
Every instruction update should trigger an evaluation run
Every production failure should become a new test case
Every improvement should be measurable and repeatable
Explore AgentX
Learn more at agentx.so
Run evaluations in the platform at app.agentx.so
In the next post, we’ll go deeper into enterprise evaluation methods, tools, and practical techniques to continuously improve agent performance and reliability. We’ll also introduce a new section on Monitoring - coming soon.