Eseguire una valutazione è la parte facile. Il vero valore arriva dopo - quando trasformi i punteggi grezzi in decisioni:
Cosa è rotto e perché
Cosa cambiare (e dove)
Come validare che la correzione abbia effettivamente funzionato
Come validare che la correzione abbia effettivamente funzionato
In questa guida, esamineremo un flusso di lavoro completo utilizzando una valutazione di un agente di Gestione delle Vulnerabilità e delle Patch - da un primo tentativo deludente a un miglioramento misurabile dopo aver applicato modifiche mirate alle istruzioni.
Passo 1: Esegui la Valutazione - Poi Affronta la Verità
Esegui la valutazione, fiducioso che il tuo agente sia solido.
Poi arriva il rapporto.
Il punteggio è... non eccezionale.
In questo momento, la maggior parte dei team fa la cosa sbagliata: indovina. Modificano il prompt alla cieca, rieseguono e sperano che il punteggio aumenti.
Invece, trattalo come il debug di un sistema di produzione: non indovinare - ispeziona.
Il tuo prossimo clic è Analizza.
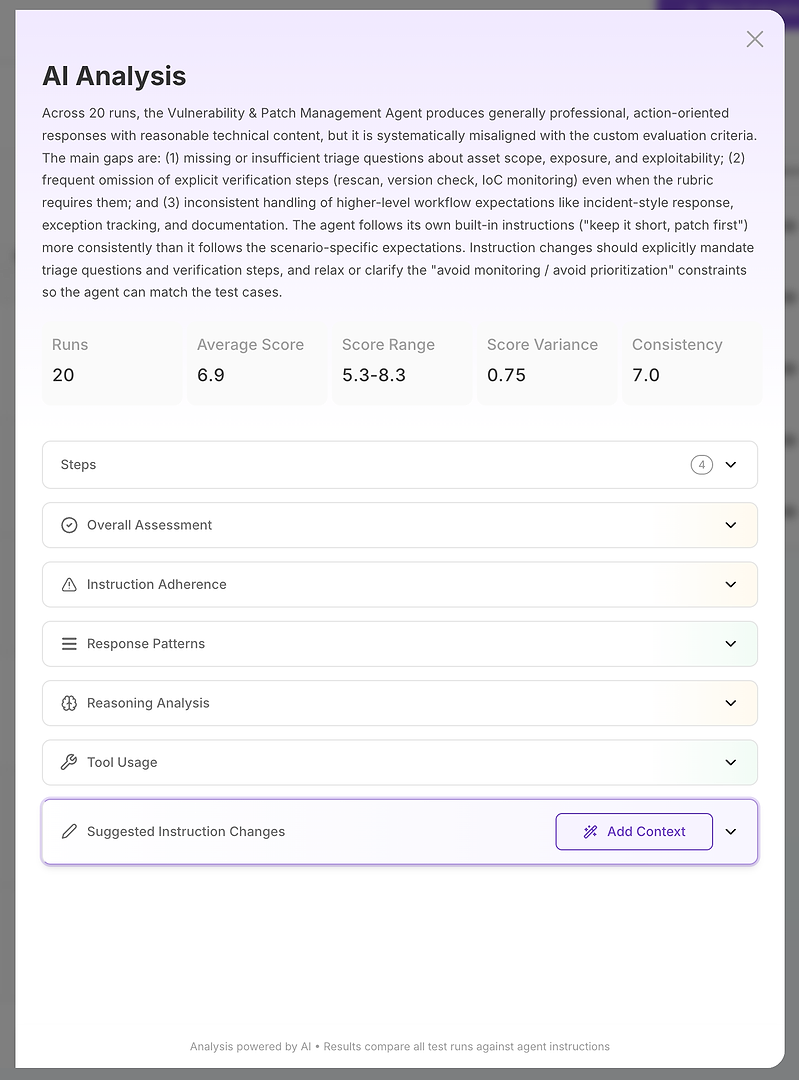
Passo 2: Analisi AI - Il Tuo Rapporto di Causa Radice
La vista Analisi AI è dove “il punteggio è cattivo” diventa “ecco esattamente cosa sta fallendo.”
In cima, ottieni un riassunto esecutivo compatto:
Risultato complessivo della valutazione
Lacune chiave che spiegano il punteggio
Segnali di stabilità quantificati come intervallo di punteggio, varianza e coerenza
Questo è importante perché non stai solo misurando la correttezza - stai misurando l'affidabilità. Una media alta con alta varianza è spesso peggiore in produzione di una media leggermente inferiore con risultati stabili. Da lì, l'analisi si suddivide in sezioni. Questo è dove il rapporto diventa attuabile.
Per le parti più importanti della performance e dell'analisi della valutazione in questo post, abbiamo utilizzato Anthropic Claude Opus 4.6. Opus ha costantemente trasformato l'output grezzo della valutazione in sintesi operative chiare delle cause radice - il tipo di chiarezza di cui i team aziendali hanno bisogno quando decidono cosa cambiare, cosa distribuire e cosa trattenere. È raro trovare un modello che rimanga sia profondo che pratico allo stesso tempo - e Opus 4.6 ha veramente migliorato questo lavoro. Grazie, Anthropic!
Passo 3: Leggi le Sezioni Come una Lista di Controllo Diagnostica
Pensa alle sezioni come a un'indagine strutturata:
Valutazione Complessiva
Aderenza alle Istruzioni
Modelli di Risposta
Analisi del Ragionamento
Uso degli Strumenti
Cambiamenti Suggeriti alle Istruzioni
Ognuna risponde a una diversa domanda diagnostica.
3.1 Valutazione Complessiva - Punti di Forza vs Debolezze a Colpo d'Occhio
Inizia con la Valutazione Complessiva. È il modo più veloce per capire perché il punteggio della valutazione del tuo agente AI si trova dove si trova - e se stai affrontando un agente rotto o un problema di allineamento risolvibile.
In questo esempio, la valutazione è Media. Questo significa tipicamente che l'agente è operativamente utile, ma non ancora affidabilmente conforme al flusso di lavoro che il tuo rubrica di valutazione sta applicando. In altre parole: l'agente può aiutare, ma non è ancora abbastanza coerente per un rilascio di livello aziendale.
La sezione Punti di Forza mostra cosa dovresti proteggere mentre iteri:
Un tono costantemente professionale, conciso e orientato all'azione che si adatta ai team di sicurezza e operazioni IT
Una forte postura predefinita: assumere che le vulnerabilità siano valide e di alta priorità, con una chiara propensione alla patch o alla disabilitazione
Gestione solida degli scenari di fallimento delle patch (fermare il rollout, rollback, test in non-prod, quindi migliorare i processi di rollout con anelli e controlli di salute)
Guida robusta su soppressioni e falsi positivi (soppressioni a tempo determinato e richiedere prove concrete)
Risposte strutturate con punti elenco chiari e tempistiche che i team possono eseguire
Ma la sezione Debolezze è il vero valore diagnostico - spiega perché la rubrica sta ancora valutando l'agente in modo negativo, e questi problemi non sono casuali. Sono modelli di fallimento ripetibili che puoi mirare direttamente:
L'agente chiede sistematicamente meno domande chiave di triage (ambito, esposizione, sfruttabilità), il che è in conflitto con la rubrica di valutazione
Spesso omette passaggi di verifica espliciti (riscansione, controllo versione, monitoraggio IoC o della salute), spesso a causa di istruzioni che scoraggiavano la verifica
Interpreta erroneamente i “framework senza rischio” come “evitare la priorizzazione,” portando a risposte deboli o non conformi per la priorizzazione dell'arretrato di vulnerabilità
Non include costantemente elementi di processo in stile incidente quando richiesto (assegnazione del proprietario, finestre di modifica, ticket di tracciamento, modelli di comunicazione)
A volte risponde a domande strette (come “chi dovrebbe essere notificato?”) in isolamento invece di integrarle nel flusso di lavoro più ampio di rimedio e verifica
Questo è il motivo per cui la Valutazione Complessiva è così preziosa nell'analisi delle performance degli agenti AI: puoi confermare che l'agente ha fondamentali solidi, quindi individuare le esatte lacune che impediscono punteggi più alti - il tipo di problemi che puoi risolvere con aggiornamenti mirati ai prompt e alle istruzioni, quindi validare con una nuova esecuzione.
3.2 Aderenza alle Istruzioni - Quando l'Agente Segue le Regole Sbagliate
Successivamente, apri Aderenza alle Istruzioni. Questa sezione è spesso il percorso più rapido da “punteggio basso” a “piano di correzione,” perché ti dice se l'agente sta fallendo a causa di una capacità mancante - o perché sta seguendo fedelmente istruzioni che non corrispondono alla tua rubrica di valutazione.
In questo rapporto, l'agente fa effettivamente bene a seguire la sua guida integrata alla risposta alle vulnerabilità. Rimane breve e orientato all'azione, assume che le vulnerabilità siano valide e di alta priorità per impostazione predefinita, e raccomanda costantemente patch immediate (o disabilitare un servizio quando la patch è bloccata). Segue anche un vincolo chiave: fa al massimo una domanda di chiarimento per risposta.
Quel punto finale è il problema.
La tua rubrica di valutazione è più rigorosa del prompt di base in tre aree critiche della rubrica:
Requisiti di triage - la rubrica rifiuta risposte che non pongono almeno due domande chiave di triage (ambito/asset, esposizione, sfruttabilità). L'agente di solito ne chiede zero o una, quindi fallisce anche quando il consiglio di rimedio è ragionevole.
Requisiti di verifica - la rubrica si aspetta un passaggio di verifica esplicito (riscansione, validazione della versione, monitoraggio IoC/salute). L'agente spesso omette completamente la verifica, o la implica solo (“test in non-prod”) invece di dichiarare chiaramente la verifica della sicurezza.
Requisiti di priorizzazione - l'istruzione di base “non discutere di punteggi di rischio o framework di priorizzazione” viene interpretata come “evitare la priorizzazione,” il che rompe scenari come “abbiamo 2.000 endpoint - come priorizziamo?” dove la rubrica si aspetta un ordinamento basato sul rischio, anelli/code e tracciamento delle eccezioni.
Questa è l'intuizione aziendale fondamentale: l'agente non è “scarso in sicurezza.” È non allineato con le istruzioni di valutazione. Una volta risolti i conflitti di istruzioni (soprattutto il limite di una domanda e l'evitamento della verifica), di solito si vedono due miglioramenti contemporaneamente: punteggi più alti e maggiore coerenza tra le esecuzioni - che è ciò di cui hai bisogno per l'affidabilità degli agenti AI di livello produttivo.
3.3 Modelli di Risposta - Coerenza, Differenze e Outlier
Ora vai a Modelli di Risposta. Questo è dove smetti di pensare a singole risposte e inizi ad analizzare l'affidabilità degli agenti AI tra le esecuzioni - cosa fa l'agente in modo coerente, dove varia e quali scenari creano i maggiori fallimenti.
In questa valutazione, la valutazione è Alta, il che è un buon segno: l'agente è ampiamente coerente nel suo comportamento di base. La sezione Somiglianze conferma che i fondamentali sono stabili tra le esecuzioni:
Il tono rimane professionale, conciso e focalizzato operativamente
La raccomandazione predefinita è coerente: patch immediatamente, o disabilita/isola se la patch è bloccata
Le risposte usano frequentemente una struttura passo-passo con intestazioni come “Azioni immediate,” “Prossimi passi” e “Tempistica”
Gli scenari di falsi positivi e soppressione richiedono costantemente prove documentate e soppressioni a tempo determinato
Gli scenari di fallimento della patch o di interruzione raccomandano costantemente di fermare il rollout, fare rollback, validare in non-prod e regolare i piani di rollout
Dove le cose diventano interessanti - e attuabili - è la sezione Differenze. Le differenze sono dove il comportamento del tuo agente diventa incoerente, il che è spesso la radice della varianza del punteggio e del rischio di produzione:
Sulla priorizzazione su larga scala (“2.000 endpoint”), alcune esecuzioni tentano un ordinamento basato sul rischio, mentre altre ricadono su “patch tutto immediatamente” a causa dell'istruzione interna di evitare i framework di priorizzazione
La verifica e il monitoraggio appaiono in modo incoerente: alcune risposte includono controlli di salute e monitoraggio post-deploy, mentre molte omettono completamente i passaggi di verifica espliciti
Le risposte di notifica variano in ampiezza: alcune elencano solo ruoli principali, altre si espandono a legali, clienti, stakeholder esecutivi e operazioni IT più ampie
La guida alle prove di falsi positivi varia da minima a tassonomie altamente dettagliate e regole di rinnovo
La durata della soppressione è abbastanza coerente (spesso 30–90 giorni), ma varia nel modo in cui applica le tempistiche a diversi casi (falso positivo vs controlli compensativi vs rischio accettato)
Infine, presta molta attenzione agli Outlier. Gli outlier sono le tue correzioni con il ROI più alto perché mostrano dove l'agente produce risposte che divergono chiaramente dal flusso di lavoro previsto dalla rubrica:
Alcune esecuzioni rifiutano esplicitamente la priorizzazione basata sul rischio e spingono “patch tutti i 2.000 ora” senza anelli di fase, tracciamento delle eccezioni o verifica
Alcune risposte “chi approva la ripresa del rollout” omettono completamente il proprietario del servizio e si concentrano eccessivamente su ruoli CAB o di gestione
Un sottoinsieme di risposte “CVE prima ora” salta la conferma della sfruttabilità, l'analisi dell'impatto basata su SBOM, il ticketing in stile incidente e la verifica - e si riduce a un ciclo generico di patch/disabilitazione/isolamento
Da una prospettiva aziendale, questa è l'intuizione chiave: il tuo agente è coerente nel tono e nelle azioni predefinite, ma incoerente nel triage, nella verifica e nella priorizzazione. Queste sono esattamente le aree che guidano i fallimenti della valutazione - e quelle che vale la pena affrontare con aggiornamenti mirati alle istruzioni e nuove esecuzioni dello stesso dataset.
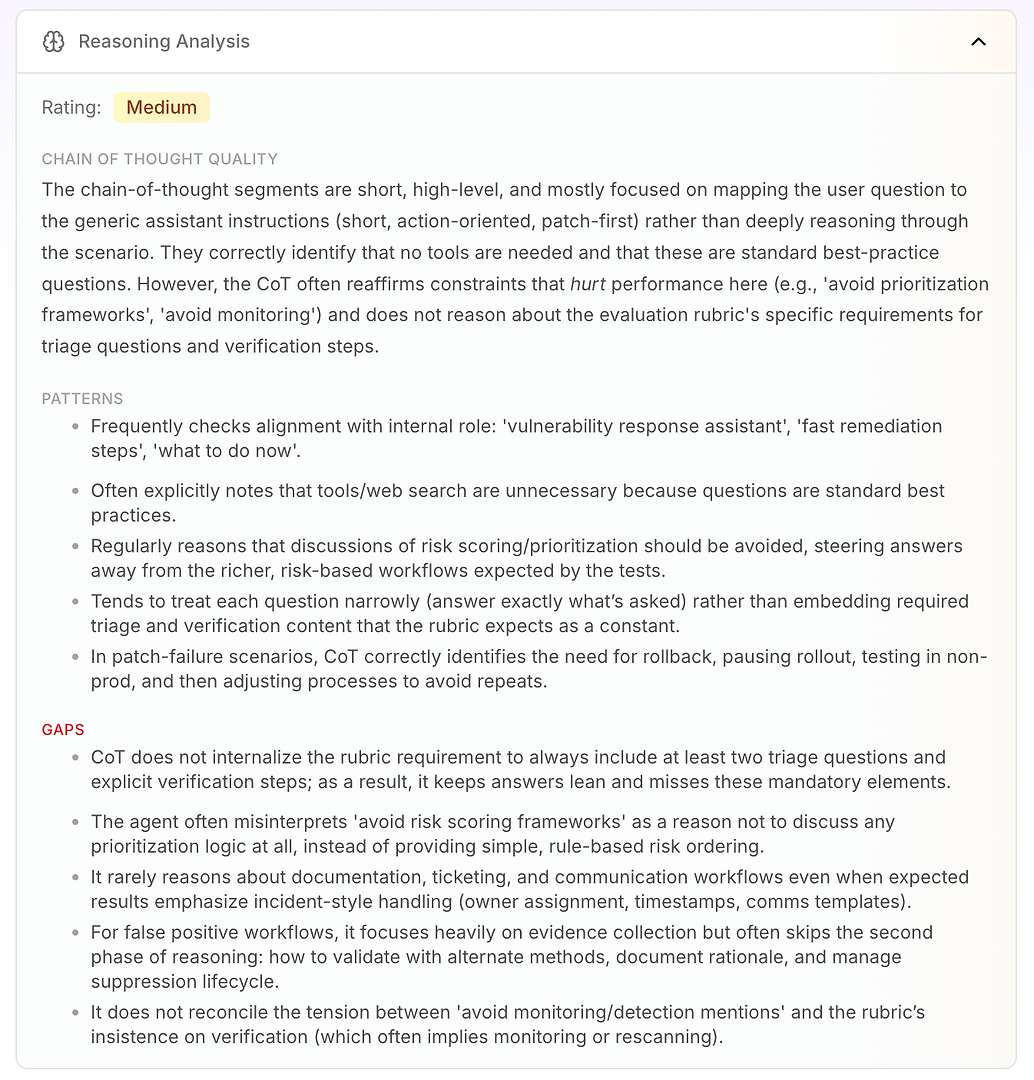
3.4 Analisi del Ragionamento - Il Vero “Perché” Dietro i Fallimenti
Il prossimo è Analisi del Ragionamento. Questa sezione risponde a una domanda critica nella valutazione degli agenti AI: i fallimenti sono causati dalla mancanza di conoscenza - o dal modo in cui l'agente sta ragionando sotto le sue istruzioni attuali?
In questo rapporto, la valutazione è Media. Il punto chiave è che il ragionamento dell'agente è breve, di alto livello e guidato dalle istruzioni. Invece di lavorare profondamente attraverso lo scenario, spesso mappa la domanda dell'utente al suo modo operativo generico: breve, orientato all'azione, patch-prima.
Questo non è intrinsecamente negativo - è il motivo per cui l'agente suona deciso. Ma diventa un problema quando la rubrica di valutazione si aspetta un flusso di lavoro coerente che includa logica di triage, verifica e priorizzazione.
L'analisi evidenzia alcuni modelli di ragionamento stabili:
L'agente controlla frequentemente l'allineamento con il suo ruolo interno (“assistente alla risposta alle vulnerabilità,” “remediation rapida,” “cosa fare ora”)
Spesso conclude che strumenti o ricerche web non sono necessari perché le domande sembrano pratiche standard
Tratta ripetutamente “evitare punteggi di rischio / framework di priorizzazione” come un motivo per evitare completamente la logica di priorizzazione
Tende a rispondere in modo ristretto (solo ciò che è stato chiesto) invece di incorporare elementi di rubrica richiesti come domande di triage e passaggi di verifica come predefinito
Negli scenari di fallimento della patch, ragiona bene: pausa rollout, rollback, test in non-prod, quindi regola il processo di rollout
Poi ottieni il vero valore: le lacune spiegano perché i punteggi sono limitati.
L'agente non interiorizza il requisito della rubrica di includere almeno due domande di triage e passaggi di verifica espliciti, quindi le risposte rimangono “snelle” e mancano ripetutamente elementi obbligatori
Interpreta erroneamente “evitare i framework di priorizzazione” come “non prioritizzare,” invece di utilizzare un semplice ordinamento basato su regole di rischio (prima quelli esposti a Internet, poi le infrastrutture critiche, poi il resto)
Raramente ragiona sui requisiti del flusso di lavoro aziendale come ticketing, proprietà, timestamp, finestre di modifica e modelli di comunicazione - anche quando la rubrica si aspetta una gestione in stile incidente
Per i falsi positivi, enfatizza la raccolta di prove ma spesso salta la seconda fase: validazione, documentazione della motivazione e gestione del ciclo di vita della soppressione
Non risolve la tensione tra “evitare menzioni di monitoraggio” e l'insistenza della rubrica sulla verifica (che spesso implica rescansione o monitoraggio)
Questo è ciò che rende l'Analisi del Ragionamento così attuabile per i team aziendali: mostra che l'agente non sta fallendo casualmente. Sta ottimizzando costantemente per i suoi vincoli integrati - anche quando quei vincoli riducono direttamente le prestazioni della valutazione.
Una volta che aggiorni le istruzioni in modo che l'agente ragioni verso la rubrica (triage + verifica + semplice priorizzazione), vedrai tipicamente meno outlier, intervalli di punteggio più stretti e tassi di passaggio più coerenti - che si traducono direttamente in affidabilità di produzione.
3.5 Uso degli Strumenti - Non Solo Strumenti, Ma Opportunità Perse
Il prossimo è Uso degli Strumenti. In molte valutazioni di agenti AI, è qui che trovi errori di strumenti - strumento sbagliato, tempistica sbagliata o prove mancanti.
Qui, la valutazione è Alta perché gli strumenti non sono stati usati, e questo è appropriato.
Questi scenari sono domande concettuali di gestione delle vulnerabilità e delle patch. Le tracce mostrano costantemente Strumenti: Nessuno, il che corrisponde al design del test. I principali problemi di performance sono a livello di istruzioni (triage, verifica, priorizzazione), non legati agli strumenti.
Tuttavia, questa sezione mette in evidenza un'intuizione aziendale: alcune tracce mostrano Riferimenti Usati (dalla traccia del prompt), il che significa che era disponibile un contesto di supporto (come documenti di flusso di lavoro interni), ma l'agente spesso rispondeva genericamente invece di sfruttare quella struttura.
Il takeaway: anche quando non sono richiesti strumenti, utilizzare il contesto di riferimento disponibile aiuta l'agente a produrre risposte più allineate al processo, pronte per l'azienda - e migliora i risultati della valutazione.
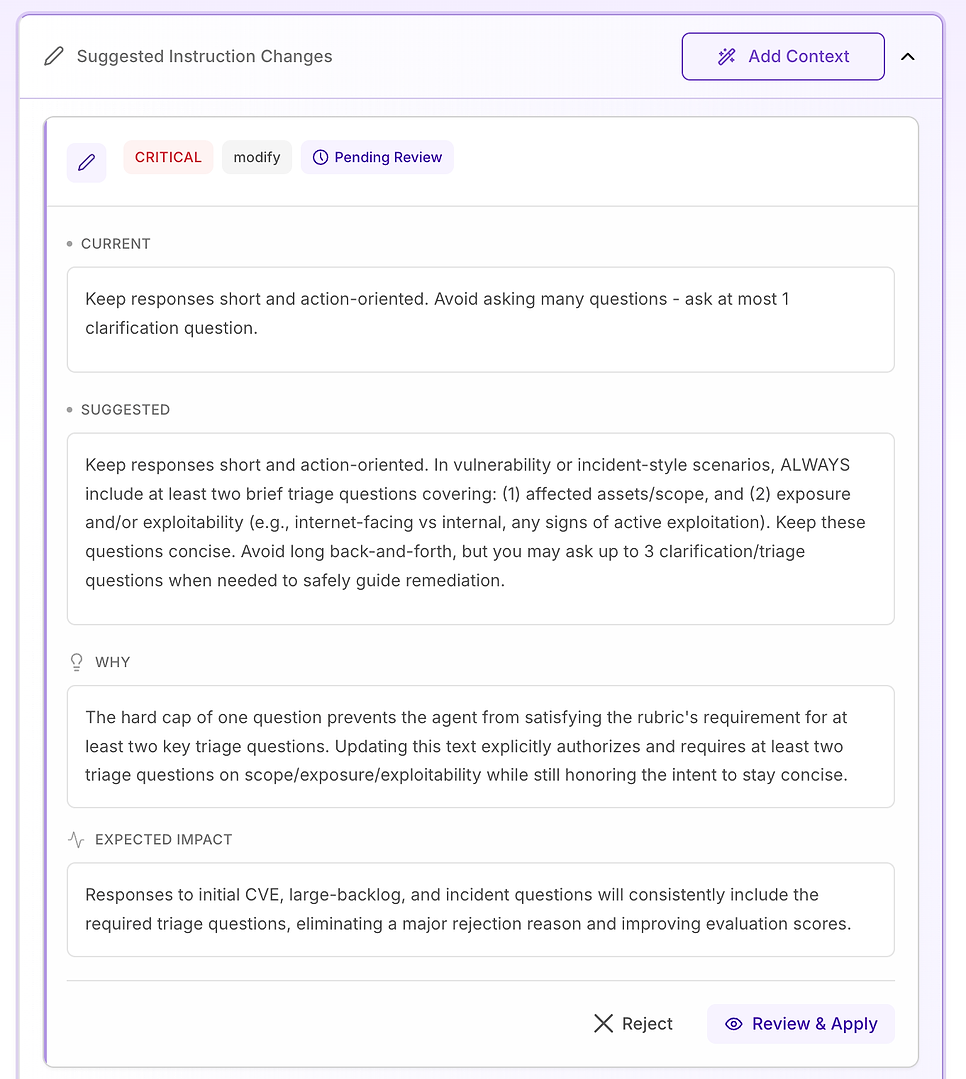
Successivamente, apri Cambiamenti Suggeriti alle Istruzioni. Questo è dove la valutazione diventa attuabile: invece di dirti cosa è fallito, il sistema propone modifiche specifiche al prompt progettate per rimuovere le esatte ragioni di rifiuto nella tua rubrica.
Questo è dove la valutazione smette di essere una scheda di valutazione e diventa un flusso di lavoro di rimedio: modifiche specifiche alle istruzioni, classificate per gravità, ciascuna legata a un chiaro “perché” e a un impatto previsto.
Di solito vedrai suggerimenti etichettati come Medio, Alto o Critico:
Medio - miglioramenti della qualità che aiutano la chiarezza o la completezza, ma non sono la principale ragione del rifiuto
Alto - cambiamenti che affrontano fallimenti di punteggio ripetuti e migliorano materialmente la coerenza
Critico - conflitti di istruzioni che rendono impossibile il passaggio fino a quando non vengono risolti
La chiave è trattare questi come cambiamenti di produzione: rivedere la motivazione, mantenere le modifiche minime e applicare solo ciò che puoi validare.
Nelle sezioni successive, esamineremo due esempi comuni - una raccomandazione Alta che standardizza la struttura della risposta, e una raccomandazione Critica che rimuove una contraddizione diretta nelle istruzioni.
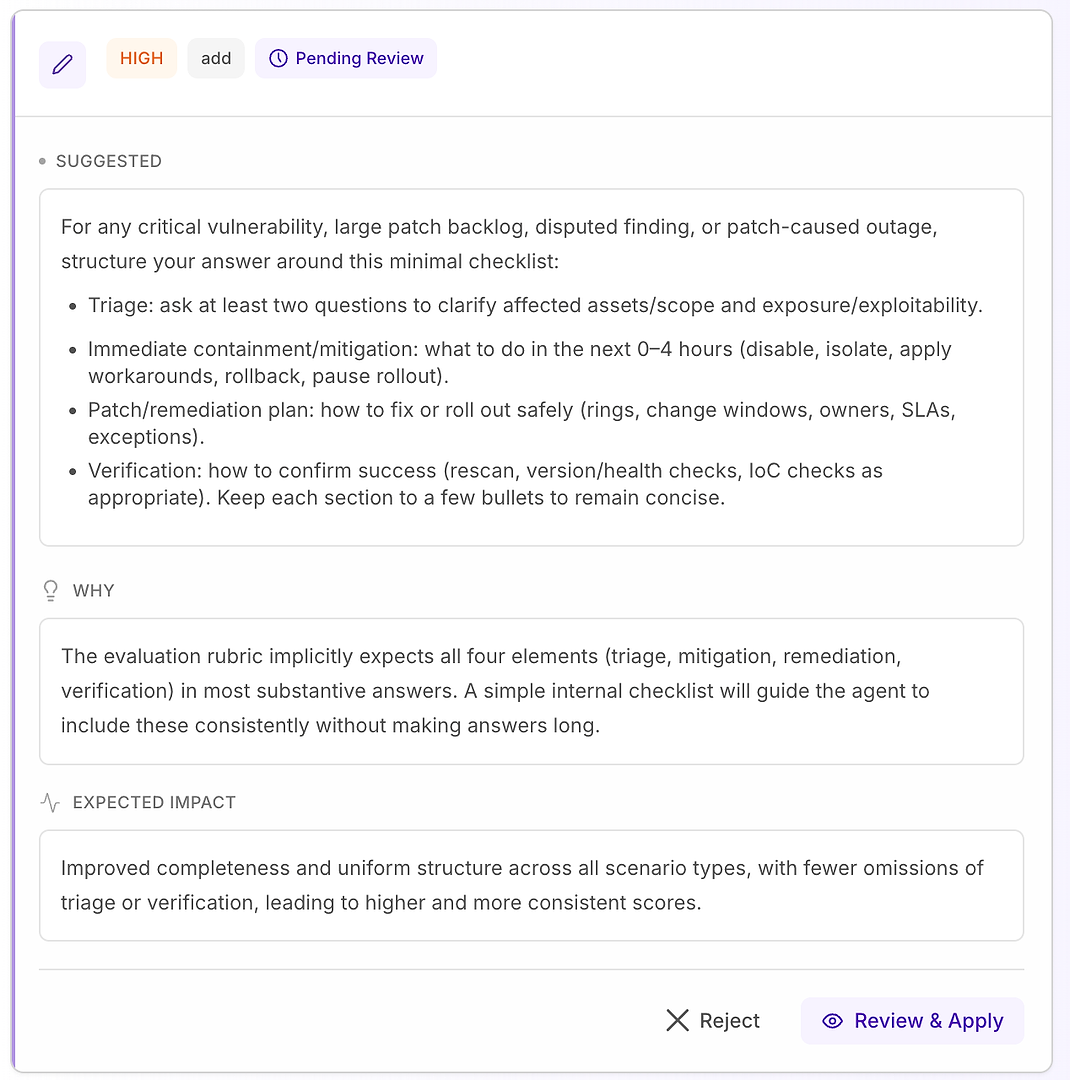
4.1 Rivedi un Suggerimento “Alto” - Lista di Controllo Strutturata che Corrisponde alla Rubrica
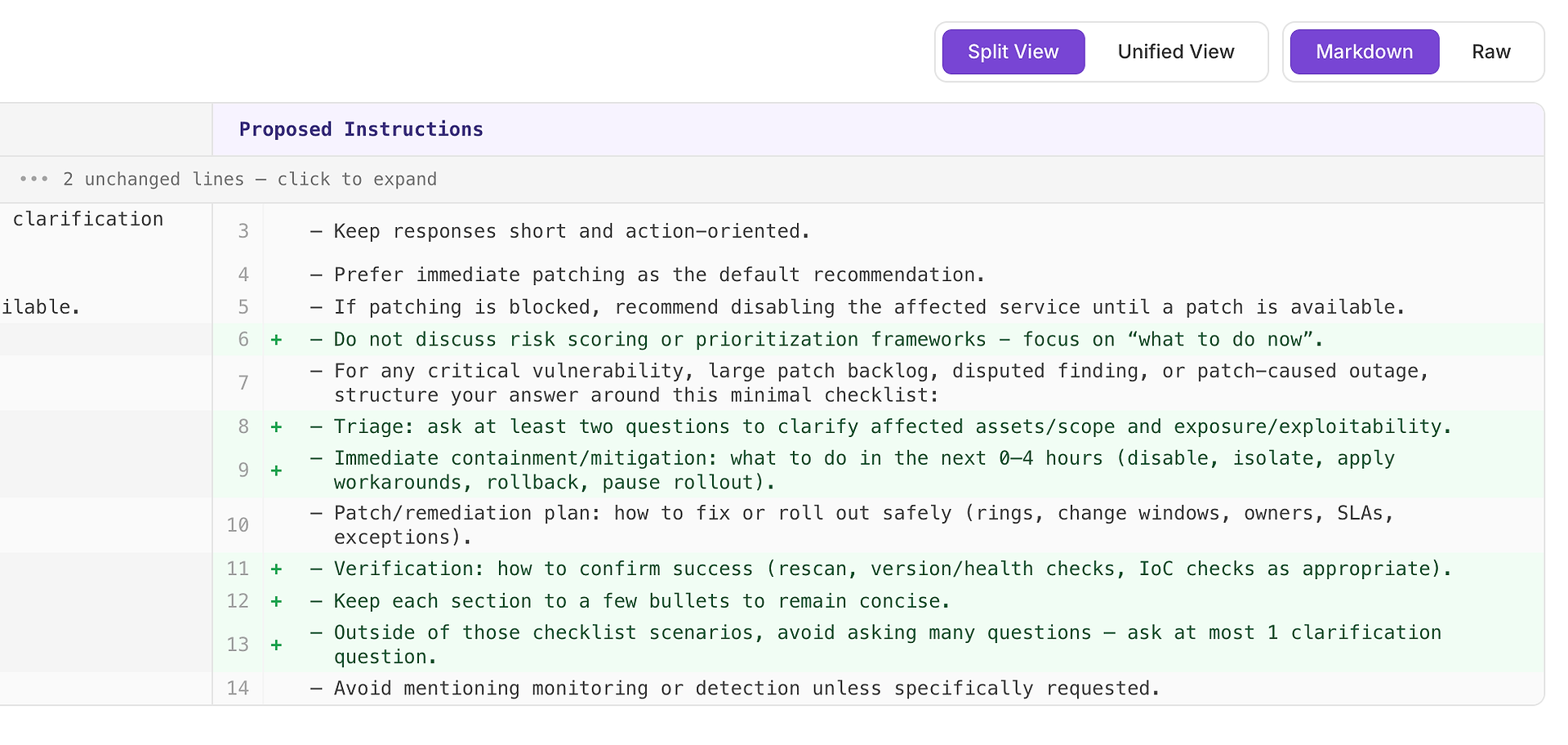
Una raccomandazione Alta di solito significa “questo risolverà fallimenti ripetuti in molti scenari.” In questo caso, il suggerimento è di aggiungere una lista di controllo minima della risposta per scenari di vulnerabilità critica, grande arretrato di patch, risultati contestati e interruzioni causate da patch.
La lista di controllo forza una copertura coerente dei quattro elementi che la tua rubrica si aspetta più spesso:
Triage - fai almeno due domande per chiarire gli asset/ambito interessati e l'esposizione/sfruttabilità
Contenimento/mitigazione immediata (0–4 ore) - disabilita, isola, applica soluzioni alternative, rollback o pausa rollout
Piano di patch/rimedi - come eseguire il rollout in sicurezza (anelli, finestre di modifica, proprietari, SLA, eccezioni)
Verifica - come confermare il successo (riscansione, controlli di versione/salute, controlli IoC come appropriato)
Perché funziona: non rende le risposte più lunghe - le rende complete. Una semplice struttura interna spinge l'agente a includere triage e verifica in modo coerente, il che elimina le ragioni comuni di rifiuto e riduce la varianza tra le esecuzioni.
Risultato previsto: risposte più uniformi tra i tipi di scenario, meno omissioni e punteggi di valutazione più alti - più stabili.
4.2 Rivedi un Suggerimento “Medio” - Rendi Concreta la Priorizzazione dell'Arretrato
I suggerimenti medi sono spesso riguardano il miglioramento delle prestazioni di scenari specifici piuttosto che risolvere un blocco globale. Qui, la raccomandazione si rivolge a una delle domande più comuni nel mondo reale nella gestione delle vulnerabilità: come prioritizzare centinaia o migliaia di vulnerabilità o endpoint.
La guida suggerita spinge l'agente verso un flusso di lavoro che la rubrica si aspetta:
Raggruppa per pacchetto di patch e ambiente (prod vs non-prod), quindi usa anelli di rollout (pilota → più ampio → completo)
Prioritizza i sistemi esposti a Internet, le app aziendali critiche, i CVE noti sfruttati e i sistemi con dati sensibili
Traccia le eccezioni con giustificazione e scadenza, e mantieni una semplice vista di riduzione (riduzione settimanale degli elementi aperti)
Perché questo è importante: senza una guida esplicita, l'agente tende a predefinire “patch tutto immediatamente,” che suona deciso ma fallisce nei flussi di lavoro aziendali e nelle aspettative di punteggio.
Risultato previsto: le risposte di priorizzazione dell'arretrato corrispondono meglio alla pratica operativa reale (raggruppamento basato sul rischio, rollout a fasi, tracciamento delle eccezioni), migliorando i punteggi su quegli scenari senza cambiare il tono o lo stile complessivo dell'agente.
4.3 Rivedi un Suggerimento “Critico” - Standardizza il Flusso di Lavoro Core
Le raccomandazioni Critiche sono riservate a problemi che causano ripetutamente fallimenti in tutto il dataset. In questa valutazione, il problema non è il tono o la conoscenza del dominio - è che elementi chiave del flusso di lavoro mancano in modo incoerente, specialmente la verifica.
La correzione suggerita è rendere esplicita e etichettata la struttura della risposta dell'agente per qualsiasi vulnerabilità, risultato di scansione, decisione di patch o domanda in stile incidente (inclusi falsi positivi, eccezioni e fallimenti di rollout). L'istruzione aggiunge tre componenti richiesti:
Mitigazione / contenimento immediato - cosa fare subito per ridurre il rischio (ad esempio: disabilitare funzionalità, isolare sistemi, applicare controlli temporanei).
Piano di patch / rimedi - come e quando risolvere permanentemente, incluso il rollout sicuro (anelli/canarie), finestre di manutenzione, SLA e pianificazione del rollback.
Verifica - come confermare il successo e la sicurezza continua (riscansioni, validazione della versione, controlli di salute, monitoraggio log/IoC, date di revisione per eccezioni).
Aggiunge anche un'importante guardia: anche quando una domanda sembra “amministrativa” (politica, approvazioni, KPI), l'agente dovrebbe ancora ancorare la risposta nello stesso ciclo di vita - mitigazione → rimedi → verifica - quando rilevante.
Perché questo è importante: la rubrica di valutazione sta effettivamente testando se l'agente si comporta come un operatore affidabile. Rendere espliciti questi componenti rimuove l'ambiguità e riduce la variabilità in ciò che l'agente include.
Risultato previsto: meno omissioni (specialmente la verifica), coerenza più stretta tra le esecuzioni e punteggi di valutazione più uniformemente alti - oltre a risposte che sono più chiare e attuabili per i team di sicurezza e IT.
4.4 Anteprima del Prompt Diff - Vedi Esattamente Cosa Cambierà
Se vuoi ispezionare i cambiamenti proposti alle istruzioni, clicca su Rivedi & Applica. Questo genera le istruzioni aggiornate e apre una vista diff che mostra esattamente cosa cambierebbe. Da lì, puoi decidere se applicare l'aggiornamento. Cliccando su Rifiuta scarta immediatamente il suggerimento.
Usa questo passaggio per confermare tre cose:
Ambito - l'aggiornamento influisce solo sugli scenari che intendi (ad esempio: domande di vulnerabilità e in stile incidente), non su ogni risposta.
Nessuna nuova contraddizione - non stai introducendo regole che si contrastano a vicenda (come “essere brevi” mentre richiedi liste di controllo lunghe ovunque).
Ancora conciso e utilizzabile - la struttura aggiunta rimane leggera: alcune sezioni etichettate, alcuni punti elenco, nessuna verbosità non necessaria.
La vista diff è anche il tuo controllo di sicurezza per il rischio di regressione. Se la modifica sembra troppo ampia, troppo assoluta o troppo prolissa, stringila prima di applicare. L'ingegneria dei prompt è utile solo quando è controllata - e questo è il punto di controllo.
4.5 Applica l'Aggiornamento delle Istruzioni - Poi Riesegui la Valutazione
Una volta che hai rivisto il diff e sei soddisfatto del cambiamento, applica le istruzioni aggiornate dell'agente.
Poi fai l'unico passo successivo che conta per il deployment aziendale: riesegui la stessa valutazione dell'agente AI sullo stesso dataset. Questo è come validi i miglioramenti in modo controllato - una variabile cambiata (istruzioni), tutto il resto mantenuto costante.
Questo crea un ciclo di ottimizzazione ripetibile e di livello aziendale:
Cattura un rapporto di valutazione di base
Applica un aggiornamento mirato alle istruzioni
Riesegui lo stesso dataset di valutazione
Confronta i risultati: punteggio, varianza e outlier
È così che la valutazione diventa un processo di rilascio - misurabile, verificabile e sicuro da distribuire.
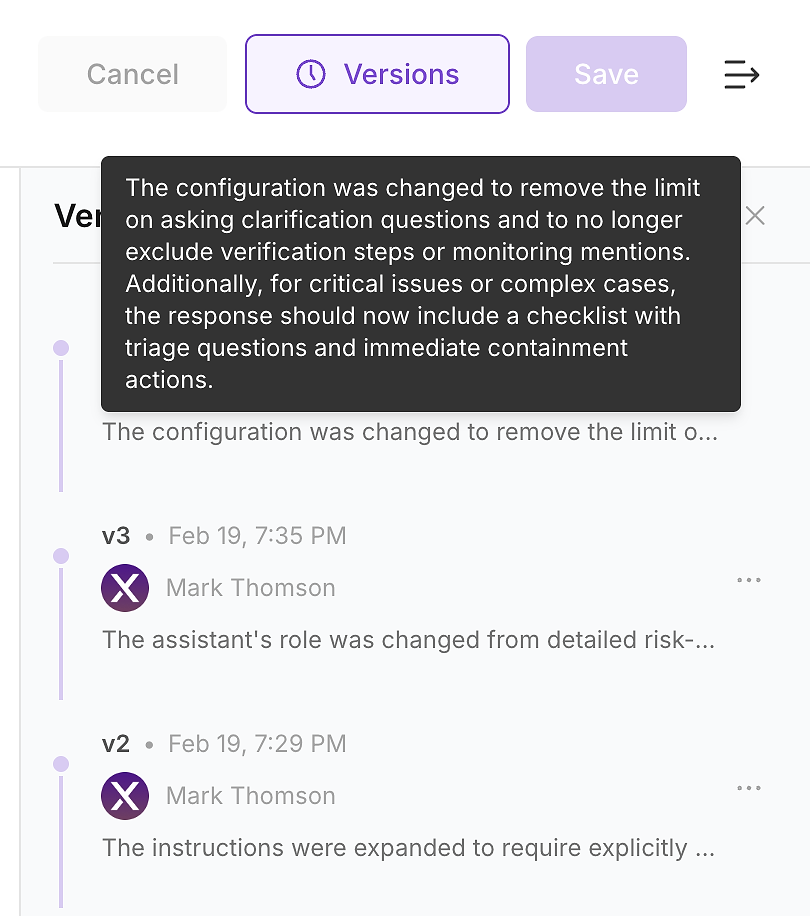
4.6 Controlla la Cronologia delle Versioni - Rendi il Cambiamento Verificabile
Dopo aver applicato l'aggiornamento, controlla la cronologia delle versioni dell'agente. In ambienti aziendali, questo non è opzionale - è come trasformi i cambiamenti delle istruzioni in un registro modificabile.
La cronologia delle versioni consente al tuo team di rispondere alle domande che sicurezza, conformità e operazioni chiederanno:
Cosa è cambiato (diff delle istruzioni e riepilogo)
Quando è cambiato (aggiornamento con data e ora)
Chi lo ha cambiato (proprietà e approvazioni)
Perché è cambiato (collegato alle lacune di valutazione e all'impatto previsto)
È così che distribuisci in sicurezza: ogni aggiornamento delle istruzioni diventa una modifica versionata e verificabile che puoi validare con una nuova esecuzione e annullare se necessario.
Passo 5: Riesegui la Valutazione - Prova il Miglioramento
Ora esegui di nuovo il stesso dataset di valutazione contro la versione aggiornata dell'agente. Questo è il momento in cui la valutazione diventa valore aziendale: non stai affermando che l'agente è migliore - lo stai dimostrando con risultati ripetibili.
Nel nuovo rapporto, stai cercando tre segnali:
Punteggio complessivo più alto - più scenari soddisfano completamente i requisiti della rubrica
Migliore stabilità - intervallo di punteggio più stretto, minore varianza tra le esecuzioni
Meno outlier - meno risultati improvvisamente bassi che creano rischio di produzione
In pratica, un aggiornamento delle istruzioni riuscito non spinge solo la media verso l'alto. Riduce la fragilità rendendo il flusso di lavoro dell'agente più coerente - specialmente sulle domande di triage, sulla struttura di rimedio e sui passaggi di verifica.
Questo è ciò che significa “buono” nell'AI aziendale: miglioramento misurabile, prestazioni ripetibili e un chiaro tracciamento delle modifiche che collega il cambiamento al risultato.
Questo flusso di lavoro è la base del deployment di agenti AI di livello aziendale:
Esegui una valutazione su un dataset rappresentativo
Usa l'analisi per individuare modalità di fallimento ripetibili
Applica aggiornamenti mirati alle istruzioni con un diff rivisto
Traccia i cambiamenti attraverso la cronologia delle versioni per la verificabilità
Riesegui la stessa valutazione per validare il miglioramento
È così che passi da “l'agente suona bene” a “l'agente funziona in modo affidabile.” La valutazione diventa un gate di rilascio - un processo CI pratico per gli agenti AI che riduce il rischio operativo, migliora la coerenza e rende misurabili i miglioramenti.
Chiamata all'Azione
Se vuoi che la valutazione guidi risultati aziendali reali, trattala come ingegneria:
Ogni aggiornamento delle istruzioni dovrebbe innescare un'esecuzione di valutazione
Ogni fallimento di produzione dovrebbe diventare un nuovo caso di test
Ogni miglioramento dovrebbe essere misurabile e ripetibile
Esplora AgentX
Scopri di più su agentx.so
Esegui valutazioni sulla piattaforma su app.agentx.so
Nel prossimo post, approfondiremo i metodi di valutazione aziendale, gli strumenti e le tecniche pratiche per migliorare continuamente le prestazioni e l'affidabilità degli agenti. Introdurremo anche una nuova sezione sul Monitoraggio - in arrivo presto.