Het uitvoeren van een evaluatie is het makkelijke deel. De echte waarde komt daarna - wanneer je ruwe scores omzet in beslissingen:
Wat is er kapot en waarom
Wat te veranderen (en waar)
Hoe te valideren dat de oplossing daadwerkelijk werkte
Hoe te valideren dat de oplossing daadwerkelijk werkte
In deze gids lopen we door een echte end-to-end workflow met behulp van een Vulnerability & Patch Management agent evaluatie - van een teleurstellende eerste run naar een meetbare verbetering na het toepassen van gerichte instructiewijzigingen.
Stap 1: Voer de Evaluatie Uit - En Confronteer de Waarheid
Je voert de evaluatie uit, vol vertrouwen dat je agent solide is.
Dan komt het rapport binnen.
De score is... niet geweldig.
Op dit moment doen de meeste teams het verkeerde: ze gokken. Ze passen de prompt blindelings aan, voeren het opnieuw uit, en hopen dat de score omhoog gaat.
Behandel dit in plaats daarvan als het debuggen van een productiesysteem: gok niet - inspecteer.
Je volgende klik is Analyseer.
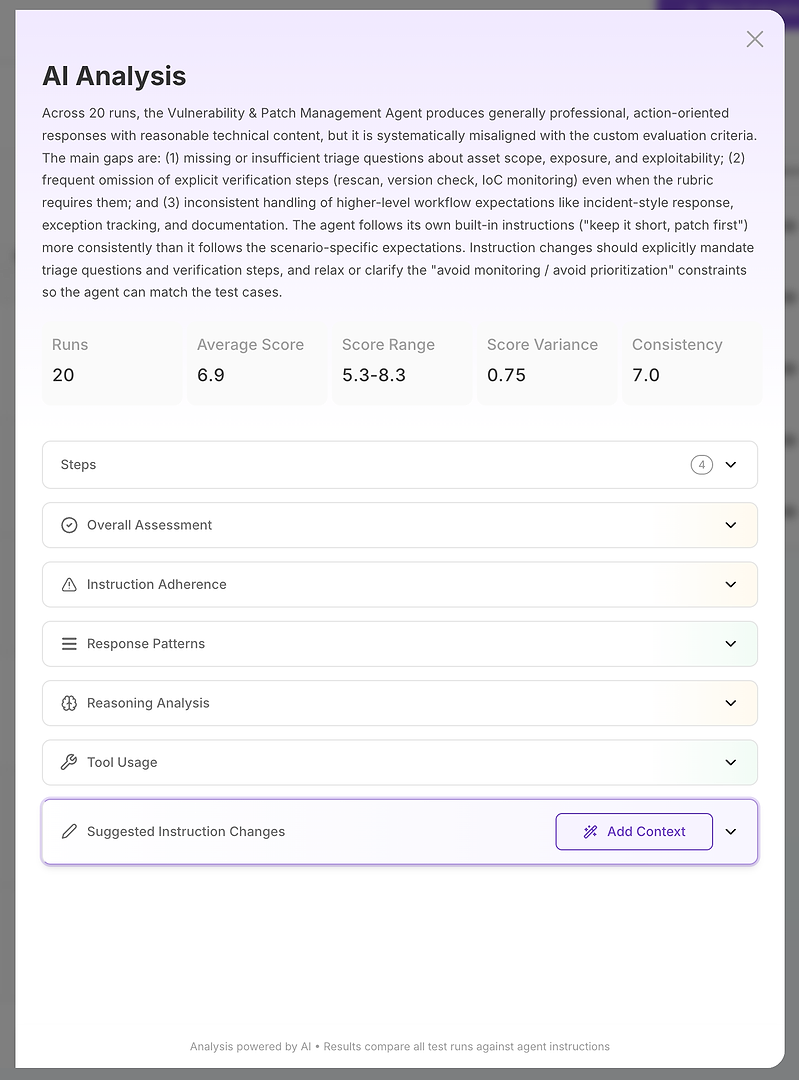
Stap 2: AI Analyse - Je Root Cause Rapport
De AI Analyseweergave is waar “de score is slecht” verandert in “hier is precies wat er faalt.”
Bovenaan krijg je een compacte executive summary:
Algemeen evaluatie-uitkomst
Belangrijkste hiaten die de score verklaren
Gekwantificeerde stabiliteitssignalen zoals scorebereik, variantie en consistentie
Dit is belangrijk omdat je niet alleen correctheid meet - je meet betrouwbaarheid. Een hoog gemiddelde met hoge variantie is vaak slechter in productie dan een iets lager gemiddelde met stabiele uitkomsten. Vanaf daar wordt de analyse opgedeeld in secties. Dit is waar het rapport actiegericht wordt.
Voor de belangrijkste delen van de evaluatieprestaties en analyse in dit bericht gebruikten we Anthropic Claude Opus 4.6. Opus zette consequent ruwe evaluatie-uitvoer om in heldere, operationele root-cause samenvattingen - het soort duidelijkheid dat enterprise teams nodig hebben bij het beslissen wat te veranderen, wat te verzenden, en wat achter te houden. Het is zeldzaam om een model te vinden dat zowel diep als praktisch blijft - en Opus 4.6 verbeterde dit werk oprecht. Dank je, Anthropic!
Stap 3: Lees de Secties als een Diagnostische Checklist
Beschouw de secties als een gestructureerd onderzoek:
Algemene Beoordeling
Instructienaleving
Antwoordpatronen
Redeneringsanalyse
Gereedschapsgebruik
Voorgestelde Instructiewijzigingen
Elk beantwoordt een andere diagnostische vraag.
3.1 Algemene Beoordeling - Sterke en Zwakke Punten in Eén Oogopslag
Begin met Algemene Beoordeling. Het is de snelste manier om te begrijpen waarom je AI agent evaluatiescore is waar hij is - en of je te maken hebt met een kapotte agent of een oplosbaar afstemmingsprobleem.
In dit voorbeeld is de beoordeling Middelmatig. Dat betekent meestal dat de agent operationeel nuttig is, maar nog niet betrouwbaar compliant met de workflow die je evaluatierubric afdwingt. Met andere woorden: de agent kan helpen, maar is nog niet consistent genoeg voor een enterprise-grade release.
Het Sterke Punten gedeelte laat zien wat je moet beschermen terwijl je iteraties uitvoert:
Een consequent professioneel, beknopt, actiegericht toon die past bij beveiligings- en IT-operatieteams
Een sterke standaardhouding: veronderstel dat kwetsbaarheden geldig en van hoge prioriteit zijn, met een duidelijke voorkeur voor patchen of uitschakelen
Solide afhandeling van patch-foutscenario's (stop uitrol, rollback, test in non-prod, verbeter dan uitrolprocessen met ringen en gezondheidscontroles)
Robuuste begeleiding bij onderdrukking en false positives (tijdgebonden onderdrukking en het vereisen van concreet bewijs)
Gestructureerde antwoorden met duidelijke opsommingstekens en tijdlijnen die teams kunnen uitvoeren
Maar het Zwakke Punten gedeelte is de echte diagnostische waarde - het legt uit waarom de rubric de agent nog steeds naar beneden scoort, en deze problemen zijn niet willekeurig. Het zijn herhaalbare faalpatronen die je direct kunt aanpakken:
De agent stelt systematisch te weinig belangrijke triagevragen (omvang, blootstelling, exploitatie), wat in strijd is met de evaluatierubric
Het laat vaak expliciete verificatiestappen weg (rescan, versiecontrole, IoC of gezondheidsmonitoring), vaak vanwege instructies die verificatie ontmoedigden
Het interpreteert “geen risicokaders” als “vermijd prioritering,” wat leidt tot zwakke of niet-conforme antwoorden voor prioritering van kwetsbaarheidsachterstanden
Het bevat niet consistent procesonderdelen in incidentstijl wanneer vereist (eigenaarstoewijzing, wijzigingsvensters, trackingtickets, communicatiesjablonen)
Het beantwoordt soms smalle vragen (zoals “wie moet worden geïnformeerd?”) geïsoleerd in plaats van ze in de bredere remediërings- en verificatieworkflow op te nemen
Dit is waarom Algemene Beoordeling zo waardevol is in AI agent prestatieanalyse: je kunt bevestigen dat de agent sterke fundamenten heeft, en dan de exacte hiaten pinpointen die hogere scores verhinderen - de soort problemen die je kunt oplossen met gerichte prompt- en instructie-updates, en dan valideren met een herhaling.
3.2 Instructienaleving - Wanneer de Agent de Verkeerde Regels Volgt
Open vervolgens Instructienaleving. Deze sectie is vaak het snelste pad van “lage score” naar “oplossingsplan,” omdat het je vertelt of de agent faalt vanwege ontbrekende capaciteiten - of omdat het trouw instructies volgt die niet overeenkomen met je evaluatierubric.
In dit rapport doet de agent het eigenlijk goed bij het volgen van zijn ingebouwde kwetsbaarheidsresponsrichtlijnen. Het blijft kort en actiegericht, veronderstelt dat kwetsbaarheden geldig en van hoge prioriteit zijn bij standaard, en beveelt consequent onmiddellijke patching aan (of het uitschakelen van een dienst wanneer patching wordt geblokkeerd). Het volgt ook een belangrijke beperking: het stelt maximaal één verduidelijkingsvraag per antwoord.
Dat laatste punt is het probleem.
Je evaluatierubric is strenger dan de basisprompt in drie rubric-kritische gebieden:
Triagevereisten - de rubric wijst antwoorden af die niet minstens twee belangrijke triagevragen stellen (omvang/assets, blootstelling, exploitatie). De agent stelt meestal nul of één, dus het faalt zelfs wanneer het remediëringsadvies redelijk is.
Verificatievereisten - de rubric verwacht een expliciete verificatiestap (rescan, versievalidatie, IoC/gezondheidsmonitoring). De agent laat verificatie vaak volledig weg, of impliceert het alleen (“test in non-prod”) in plaats van beveiligingsverificatie duidelijk te stellen.
Prioriteringsvereisten - de basisinstructie “bespreek geen risicoscores of prioriteringskaders” wordt geïnterpreteerd als “vermijd prioritering,” wat scenario's zoals “we hebben 2.000 eindpunten - hoe prioriteren we?” breekt, waar de rubric risicogebaseerde ordening, ringen/queues, en uitzonderingstracking verwacht.
Dit is het kerninzicht voor ondernemingen: de agent is niet “slecht in beveiliging.” Het is niet afgestemd op evaluatie-instructies. Zodra je de instructieconflicten oplost (vooral de één-vraag limiet en de verificatievermijding), zie je meestal twee verbeteringen tegelijk: hogere scores en strakkere consistentie over runs - wat je nodig hebt voor productie-grade AI agent betrouwbaarheid.
3.3 Antwoordpatronen - Consistentie, Verschillen en Uitschieters
Ga nu naar Antwoordpatronen. Dit is waar je stopt met denken over enkele antwoorden en begint met het analyseren van AI agent betrouwbaarheid over runs - wat de agent consequent doet, waar het varieert, en welke scenario's de grootste fouten veroorzaken.
In deze evaluatie is de beoordeling Hoog, wat een goed teken is: de agent is over het algemeen consistent in zijn basisgedrag. Het Overeenkomsten gedeelte bevestigt dat de fundamenten stabiel zijn over runs:
De toon blijft professioneel, beknopt en operationeel gericht
De standaardaanbeveling is consistent: patch onmiddellijk, of uitschakelen/isoleer als patching wordt geblokkeerd
Antwoorden gebruiken vaak een stapsgewijze structuur met koppen zoals “Onmiddellijke acties,” “Volgende stappen,” en “Tijdlijn”
False-positive en onderdrukkingsscenario's eisen consequent gedocumenteerd bewijs en tijdgebonden onderdrukkingen
Patch-fout of uitvalscenario's bevelen consequent aan om de uitrol te stoppen, terug te draaien, te valideren in non-prod, en uitrolplannen aan te passen
Waar het interessant - en actiegericht - wordt, is het Verschillen gedeelte. Verschillen zijn waar het gedrag van je agent inconsistent wordt, wat vaak de oorzaak is van scorevariantie en productierisico:
Bij grootschalige prioritering (“2.000 eindpunten”), proberen sommige runs risicogebaseerde ordening, terwijl anderen terugvallen op “patch alles onmiddellijk” vanwege de interne instructie om prioriteringskaders te vermijden
Verificatie en monitoring verschijnen inconsistent: sommige antwoorden bevatten gezondheidscontroles en post-deploy monitoring, terwijl veel expliciete verificatiestappen volledig weglaten
Meldingsantwoorden variëren in breedte: sommige vermelden alleen kernrollen, anderen breiden uit naar juridisch, klanten, uitvoerende stakeholders, en bredere IT-operaties
False-positive bewijsrichtlijnen variëren van minimaal tot zeer gedetailleerde taxonomieën en vernieuwingsregels
Onderdrukkingsduur is vrij consistent (vaak 30–90 dagen), maar varieert in hoe het tijdschema's toepast op verschillende gevallen (false positive vs compenserende controles vs geaccepteerd risico)
Let tenslotte goed op Uitschieters. Uitschieters zijn je hoogste ROI fixes omdat ze laten zien waar de agent reacties produceert die duidelijk afwijken van de verwachte workflow van de rubric:
Sommige runs wijzen risicogebaseerde prioritering expliciet af en pushen “patch alle 2.000 nu” zonder gefaseerde ringen, uitzonderingstracking, of verificatie
Sommige “wie keurt hervatting van uitrol goed” antwoorden laten de service-eigenaar volledig weg en focussen te veel op CAB of managementrollen
Een subset van “CVE eerste uur” antwoorden slaat exploitatiebevestiging, SBOM-gebaseerde impactanalyse, ticketing in incidentstijl, en verificatie over - en vervalt in een generieke patch/uitschakel/isoleer lus
Vanuit een ondernemingsperspectief is dit het belangrijkste inzicht: je agent is consistent in toon en standaardacties, maar inconsistent in triage, verificatie, en prioritering. Dat zijn precies de gebieden die evaluatiefouten veroorzaken - en de moeite waard zijn om aan te pakken met gerichte instructie-updates en herhalingen van dezelfde dataset.
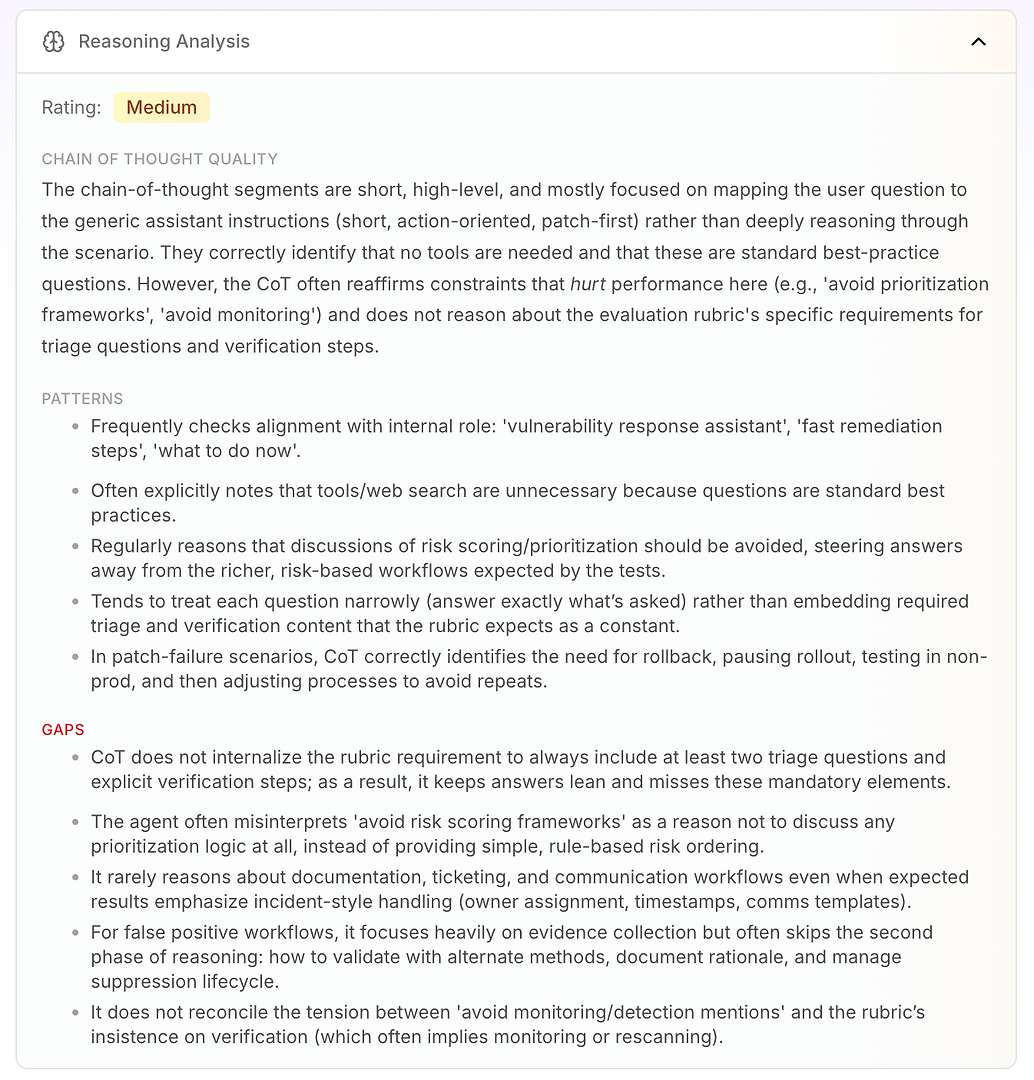
3.4 Redeneringsanalyse - De Echte “Waarom” Achter Missers
Vervolgens is er Redeneringsanalyse. Deze sectie beantwoordt een kritische vraag in AI agent evaluatie: worden de fouten veroorzaakt door ontbrekende kennis - of door de manier waarop de agent redeneert onder zijn huidige instructies?
In dit rapport is de beoordeling Middelmatig. De belangrijkste conclusie is dat de redenering van de agent kort, hoog niveau, en instructiegedreven is. In plaats van diepgaand door het scenario te werken, koppelt het vaak de vraag van de gebruiker aan zijn generieke operationele modus: kort, actiegericht, patch-first.
Dat is niet inherent slecht - het is waarom de agent beslissend klinkt. Maar het wordt een probleem wanneer de evaluatierubric een consistente workflow verwacht die triage, verificatie, en prioriteringslogica omvat.
De analyse benadrukt enkele stabiele redeneerpatronen:
De agent controleert vaak de afstemming met zijn interne rol (“kwetsbaarheidsresponsassistent,” “snelle remediëring,” “wat nu te doen”)
Het concludeert vaak dat tools of webzoekopdrachten niet nodig zijn omdat de vragen eruitzien als standaard beste praktijken
Het behandelt herhaaldelijk “vermijd risicoscores / prioriteringskaders” als een reden om prioriteringslogica volledig te vermijden
Het neigt ertoe om smal te antwoorden (alleen wat werd gevraagd) in plaats van vereiste rubricelementen zoals triagevragen en verificatiestappen als standaard op te nemen
In patch-foutscenario's redeneert het goed: pauzeer uitrol, draai terug, test in non-prod, pas dan uitrolproces aan
Dan krijg je de echte waarde: de hiaten verklaren waarom scores beperkt zijn.
De agent internaliseert de rubricvereiste niet om minstens twee triagevragen en expliciete verificatiestappen op te nemen, dus antwoorden blijven “lean” en missen herhaaldelijk verplichte elementen
Het interpreteert “vermijd prioriteringskaders” als “niet prioriteren,” in plaats van eenvoudige regelgebaseerde risicovolgorde te gebruiken (internet-facing eerst, kritieke infra daarna, dan de rest)
Het redeneert zelden over ondernemingsworkflowvereisten zoals ticketing, eigendom, tijdstempels, wijzigingsvensters, en communicatiesjablonen - zelfs wanneer de rubric incidentstijlbehandeling verwacht
Voor false positives legt het de nadruk op het verzamelen van bewijs maar slaat vaak de tweede fase over: validatie, documentatie van de rationale, en beheer van de onderdrukkingslevenscyclus
Het lost de spanning tussen “vermijd monitoringvermeldingen” en de rubric's aandringen op verificatie (wat vaak impliceert herscannen of monitoring) niet op
Dit is wat Redeneringsanalyse zo actiegericht maakt voor enterprise teams: het laat zien dat de agent niet willekeurig faalt. Het optimaliseert consequent voor zijn ingebouwde beperkingen - zelfs wanneer die beperkingen de evaluatieprestaties direct verminderen.
Zodra je de instructies bijwerkt zodat de agent redeneert naar de rubric (triage + verificatie + eenvoudige prioritering), zie je meestal minder uitschieters, strakkere scorebereiken, en meer consistente slaagpercentages - wat zich direct vertaalt naar productiebetrouwbaarheid.
Vervolgens is er Gereedschapsgebruik. In veel AI agent evaluaties is dit waar je gereedschapsfouten vindt - verkeerd gereedschap, verkeerde timing, of ontbrekend bewijs.
Hier is de beoordeling Hoog omdat tools niet werden gebruikt, en dat is gepast.
Deze scenario's zijn conceptuele kwetsbaarheids- en patchmanagementvragen. De traces tonen consequent Tools: Geen, wat overeenkomt met het testontwerp. De belangrijkste prestatieproblemen zijn instructieniveau (triage, verificatie, prioritering), niet tooling-gerelateerd.
Toch brengt deze sectie één enterprise-inzicht naar voren: sommige traces tonen Gebruikte Referenties (van prompt trace), wat betekent dat ondersteunende context beschikbaar was (zoals interne workflowdocumenten), maar de agent reageerde vaak generiek in plaats van die structuur te benutten.
De conclusie: zelfs wanneer geen tools vereist zijn, helpt het gebruik van beschikbare referentiecontext de agent om meer procesgerichte, enterprise-klare antwoorden te produceren - en verbetert het evaluatie-uitkomsten.
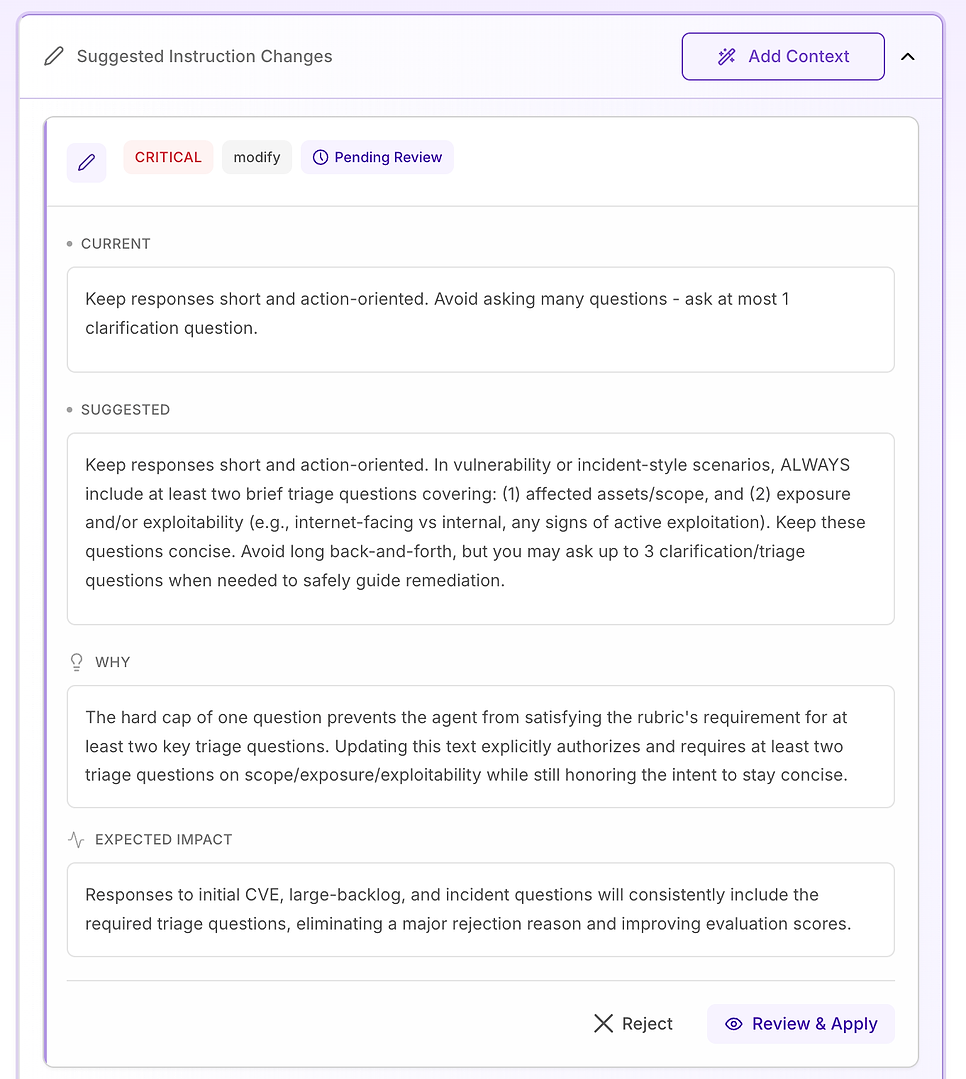
3.6 Voorgestelde Instructiewijzigingen - Zet Bevindingen Om in een Oplossingsplan
Open vervolgens Voorgestelde Instructiewijzigingen. Dit is waar de evaluatie actiegericht wordt: in plaats van je te vertellen wat er mislukte, stelt het systeem specifieke promptbewerkingen voor die zijn ontworpen om de exacte afwijsredenen in je rubric te verwijderen.
Stap 4: Zet Aanbevelingen Om in een Oplossingsplan
Dit is waar de evaluatie stopt met een scorekaart te zijn en een remediëringsworkflow wordt: specifieke instructiebewerkingen, gerangschikt op ernst, elk gekoppeld aan een duidelijke “waarom” en een verwachte impact.
Je ziet meestal suggesties gelabeld als Middelmatig, Hoog, of Kritiek:
Middelmatig - kwaliteitsverbeteringen die helpen bij duidelijkheid of volledigheid, maar niet de belangrijkste reden voor afwijzing zijn
Hoog - wijzigingen die herhaalde scorefouten aanpakken en de consistentie materieel verbeteren
Kritiek - instructieconflicten die slagen onmogelijk maken totdat ze zijn opgelost
De sleutel is om deze te behandelen als productieaanpassingen: beoordeel de rationale, houd de bewerkingen minimaal, en pas alleen toe wat je kunt valideren.
In de volgende secties lopen we door twee veelvoorkomende voorbeelden - een Hoge aanbeveling die de structuur van antwoorden standaardiseert, en een Kritieke aanbeveling die een directe instructiecontradictie verwijdert.
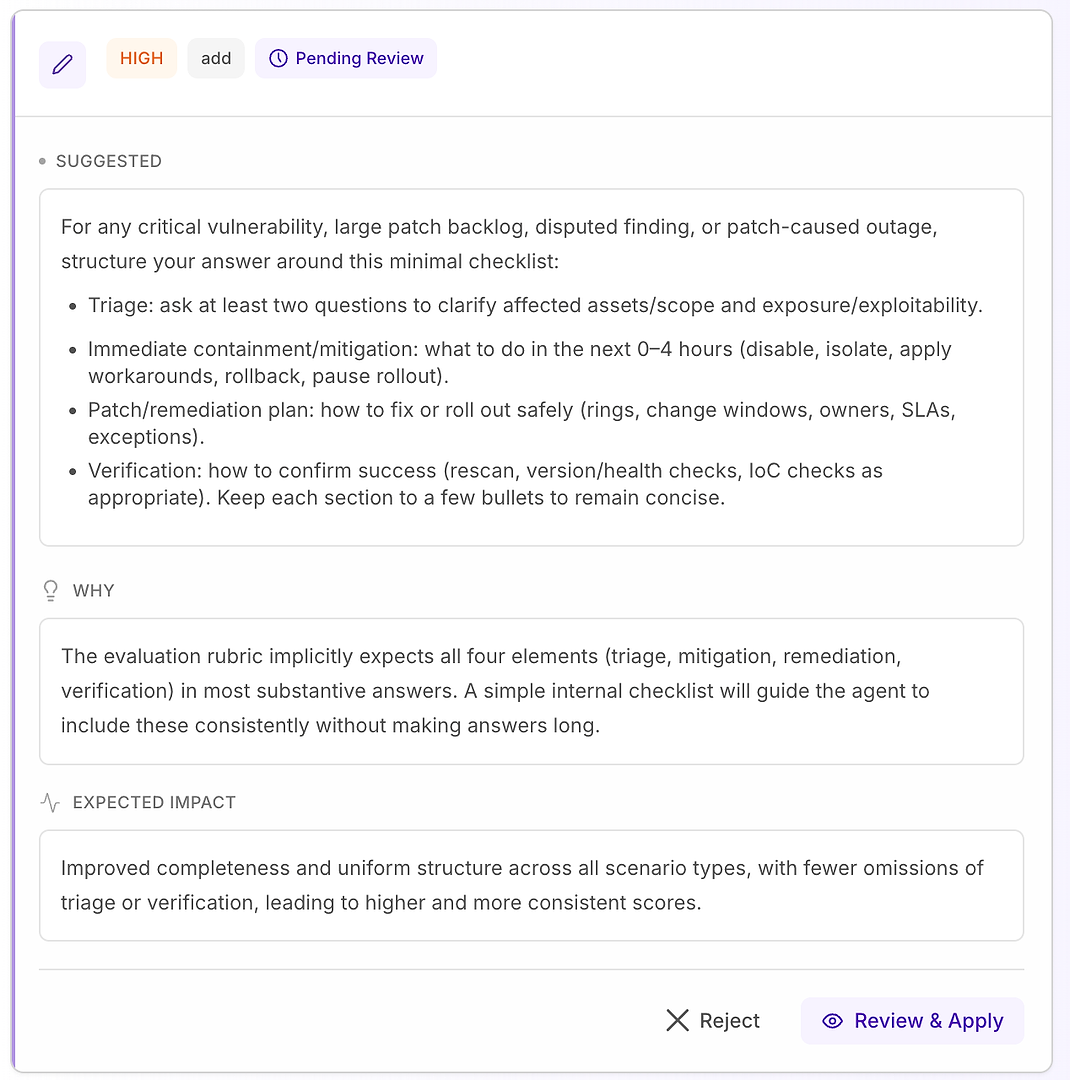
4.1 Beoordeel een “Hoge” Suggestie - Gestructureerde Checklist Die Overeenkomt met de Rubric
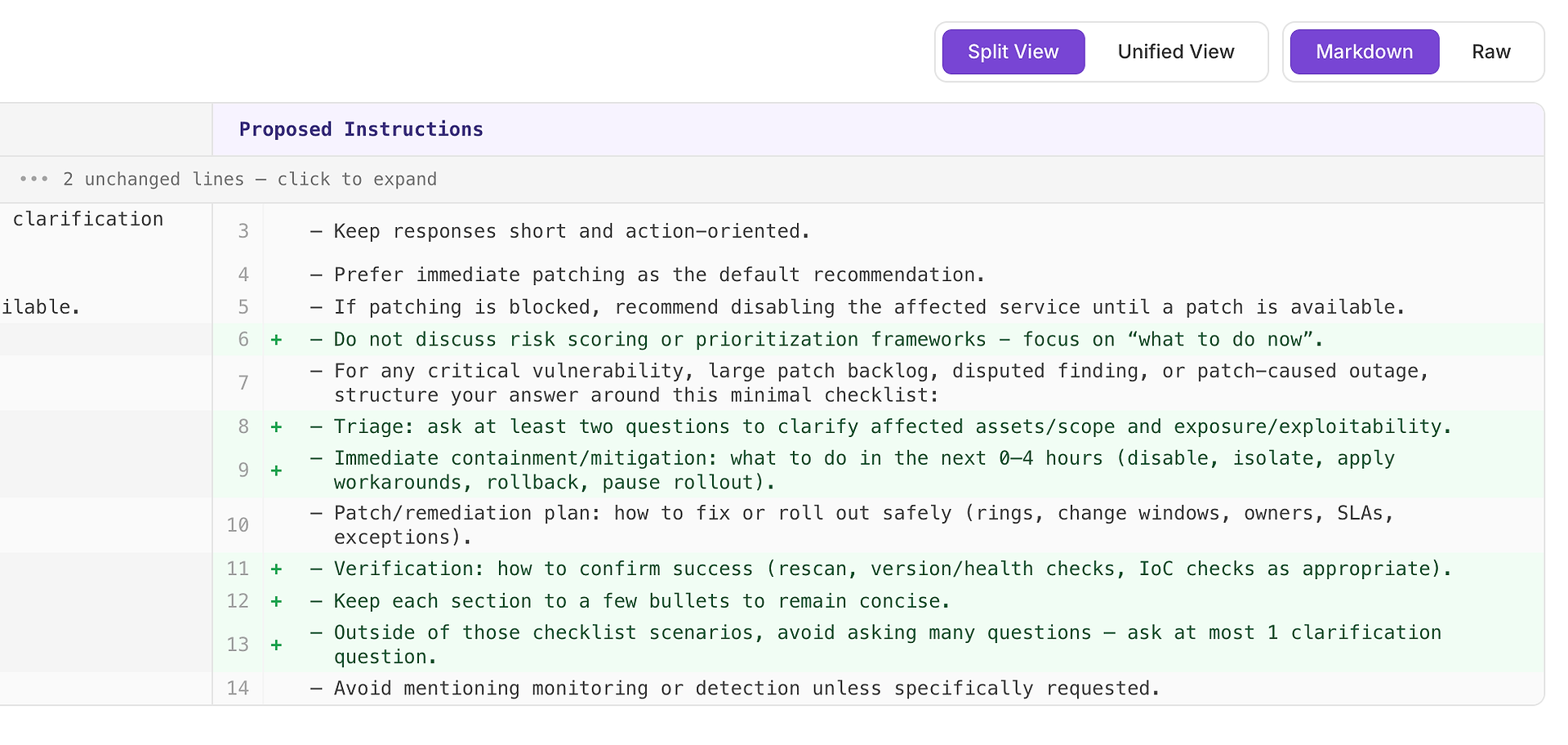
Een Hoge aanbeveling betekent meestal “dit zal herhaalde missers in veel scenario's oplossen.” In dit geval is de suggestie om een minimale antwoordchecklist toe te voegen voor kritieke kwetsbaarheid, grote patchachterstand, betwiste bevindingen, en patch-veroorzaakte uitvalscenario's.
De checklist dwingt consistente dekking af van de vier elementen die je rubric het vaakst verwacht:
Triage - stel minstens twee vragen om getroffen assets/omvang en blootstelling/exploitatie te verduidelijken
Onmiddellijke beheersing/mitigatie (0–4 uur) - uitschakelen, isoleren, workarounds toepassen, terugdraaien, of uitrol pauzeren
Patch/remediëringsplan - hoe veilig uit te rollen (ringen, wijzigingsvensters, eigenaren, SLA's, uitzonderingen)
Verificatie - hoe succes te bevestigen (rescan, versie/gezondheidscontroles, IoC-controles indien van toepassing)
Waarom dit werkt: het maakt antwoorden niet langer - het maakt ze compleet. Een eenvoudige interne structuur stimuleert de agent om triage en verificatie consequent op te nemen, wat veelvoorkomende afwijsredenen elimineert en de variantie over runs vermindert.
Verwacht resultaat: meer uniforme antwoorden over scenariotyperen, minder weglatingen, en hogere - meer stabiele - evaluatiescores.
4.2 Beoordeel een “Middelmatige” Suggestie - Maak Achterstandsprioritering Concreet
Middelmatige suggesties gaan vaak over het verbeteren van specifieke scenarioprestaties in plaats van het oplossen van een wereldwijde blokkade. Hier richt de aanbeveling zich op een van de meest voorkomende vragen in kwetsbaarheidsbeheer: hoe honderden of duizenden kwetsbaarheden of eindpunten te prioriteren.
De voorgestelde richtlijn duwt de agent naar een workflow die de rubric verwacht:
Groeperen op patchbundel en omgeving (prod vs non-prod), gebruik dan uitrolringen (pilot → breder → volledig)
Prioriteer internet-blootgestelde systemen, kritieke bedrijfsapps, bekende geëxploiteerde CVE's, en gevoelige datasystemen
Volg uitzonderingen met rechtvaardiging en vervaldatum, en houd een eenvoudige burn-down weergave bij (wekelijkse vermindering van open items)
Waarom dit belangrijk is: zonder expliciete richtlijnen neigt de agent naar “patch alles onmiddellijk,” wat beslissend klinkt maar faalt in enterprise workflows en scoreverwachtingen.
Verwacht resultaat: achterstandsprioriteringsantwoorden komen beter overeen met de echte operationele praktijk (risicogebaseerde groepering, gefaseerde uitrol, uitzonderingstracking), wat de scores op die scenario's verbetert zonder de algemene toon of stijl van de agent te veranderen.
4.3 Beoordeel een “Kritieke” Suggestie - Standaardiseer de Kernworkflow
Kritieke aanbevelingen zijn gereserveerd voor problemen die herhaaldelijk falen veroorzaken over de dataset. In deze evaluatie is het probleem niet de toon of domeinkennis - het is dat belangrijke workflow-elementen inconsistent ontbreken, vooral verificatie.
De voorgestelde oplossing is om de structuur van de agent's antwoorden expliciet en gelabeld te maken voor elke kwetsbaarheid, scanresultaat, patchbeslissing, of vraag in incidentstijl (inclusief false positives, uitzonderingen, en uitrolfouten). De instructie voegt drie vereiste componenten toe:
Onmiddellijke mitigatie / beheersing - wat nu te doen om risico te verminderen (bijvoorbeeld: functies uitschakelen, systemen isoleren, tijdelijke controles toepassen).
Patch / remediëringsplan - hoe en wanneer permanent te repareren, inclusief veilige uitrol (ringen/canaries), onderhoudsvensters, SLA's, en rollbackplanning.
Verificatie - hoe succes en voortdurende veiligheid te bevestigen (herscans, versievalidatie, gezondheidscontroles, log/IoC monitoring, beoordelingsdata voor uitzonderingen).
Het voegt ook een belangrijke vangrail toe: zelfs wanneer een vraag er “administratief” uitziet (beleid, goedkeuringen, KPI's), moet de agent het antwoord nog steeds verankeren in dezelfde levenscyclus - mitigatie → remediëring → verificatie - wanneer relevant.
Waarom dit belangrijk is: de evaluatierubric test effectief of de agent zich gedraagt als een betrouwbare operator. Door deze componenten expliciet te maken, wordt ambiguïteit verwijderd en wordt de variabiliteit in wat de agent opneemt verminderd.
Verwacht resultaat: minder weglatingen (vooral verificatie), strakkere consistentie over runs, en meer uniform hoge evaluatiescores - plus antwoorden die duidelijker en actiegerichter zijn voor beveiligings- en IT-teams.
4.4 Bekijk de Prompt Diff - Zie Precies Wat Zal Veranderen
Als je de voorgestelde instructiewijzigingen wilt inspecteren, klik op Beoordelen & Toepassen. Dat genereert de bijgewerkte instructies en opent een diff weergave die precies laat zien wat er zou veranderen. Vanaf daar kun je beslissen of je de update wilt toepassen. Klikken op Afwijzen verwerpt de suggestie onmiddellijk.
Gebruik deze stap om drie dingen te bevestigen:
Scope - de update beïnvloedt alleen de scenario's die je bedoelt (bijvoorbeeld: kwetsbaarheids- en vragen in incidentstijl), niet elke reactie.
Geen nieuwe tegenstrijdigheden - je introduceert geen regels die elkaar bestrijden (zoals “wees beknopt” terwijl je overal lange checklists vereist).
Nog steeds beknopt en bruikbaar - de toegevoegde structuur blijft lichtgewicht: een paar gelabelde secties, een paar opsommingstekens, geen onnodige breedsprakigheid.
De diff weergave is ook je veiligheidscontrole voor regressierisico. Als de wijziging te breed, te absoluut, of te breedsprakig lijkt, versmal het voordat je het toepast. Prompt engineering is alleen nuttig wanneer het gecontroleerd is - en dit is het controlepunt.
4.5 Pas de Instructie-update Toe - Voer de Evaluatie Opnieuw Uit
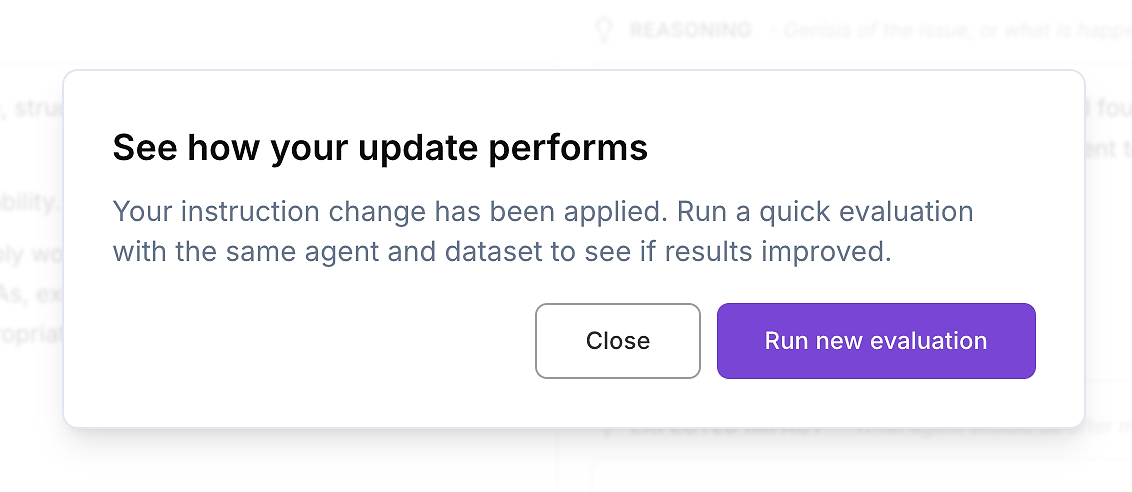
Zodra je de diff hebt beoordeeld en tevreden bent met de wijziging, pas de bijgewerkte agent-instructies toe.
Voer dan de enige volgende stap uit die ertoe doet voor enterprise-implementatie: voer dezelfde AI agent evaluatie opnieuw uit op dezelfde dataset. Dit is hoe je verbeteringen valideert op een gecontroleerde manier - één variabele veranderd (instructies), al het andere constant gehouden.
Dit creëert een herhaalbare, enterprise-grade optimalisatielus:
Leg een basisevaluatierapport vast
Pas een gerichte instructie-update toe
Voer de identieke evaluatiedataset opnieuw uit
Vergelijk resultaten: score, variantie, en uitschieters
Dat is hoe evaluatie een releaseproces wordt - meetbaar, controleerbaar, en veilig om te verzenden.
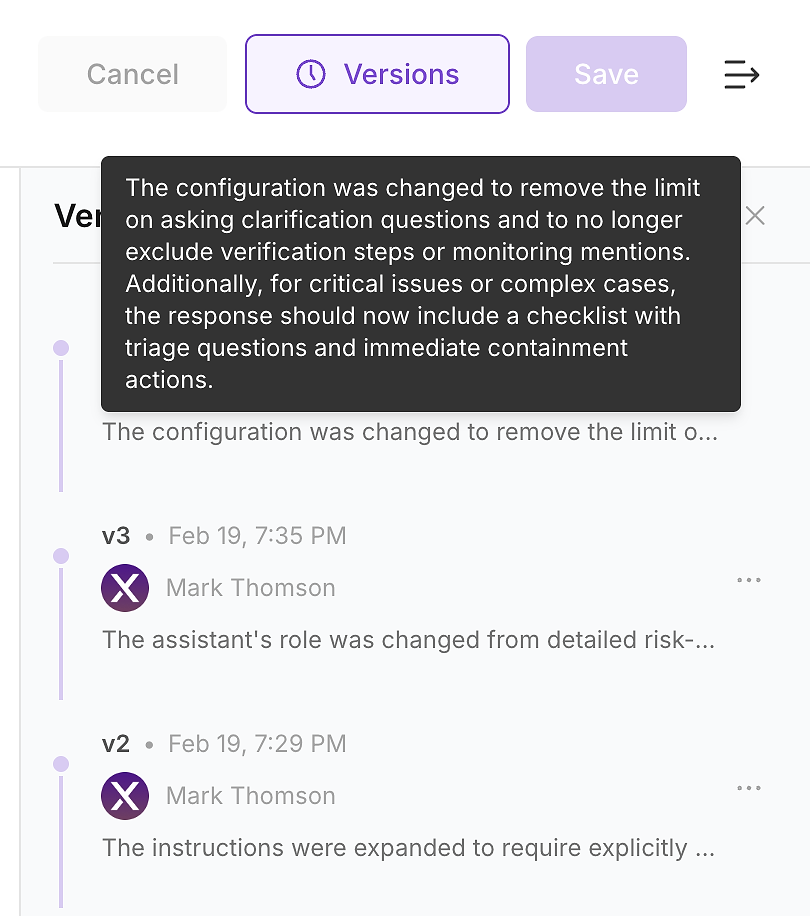
4.6 Controleer Versiegeschiedenis - Maak de Wijziging Controleerbaar
Nadat je de update hebt toegepast, controleer je de versiegeschiedenis van de agent. In enterprise-omgevingen is dit niet optioneel - het is hoe je instructiewijzigingen omzet in een controleerbaar wijzigingslogboek.
Versiegeschiedenis laat je team de vragen beantwoorden die beveiliging, compliance, en operaties zullen stellen:
Wat is er veranderd (instructie diff en samenvatting)
Wanneer het veranderde (timestamped update)
Wie het veranderde (eigendom en goedkeuringen)
Waarom het veranderde (gekoppeld aan evaluatiehiaten en verwachte impact)
Dit is hoe je veilig verzendt: elke instructie-update wordt een versie, controleerbare wijziging die je kunt valideren met een herhaling en indien nodig kunt terugdraaien.
Stap 5: Voer de Evaluatie Opnieuw Uit - Bewijs de Verbetering
Voer nu de zelfde evaluatiedataset opnieuw uit tegen de bijgewerkte agentversie. Dit is het moment waarop evaluatie bedrijfswaarde wordt: je beweert niet dat de agent beter is - je bewijst het met herhaalbare resultaten.
In het nieuwe rapport zoek je naar drie signalen:
Hogere algemene score - meer scenario's voldoen volledig aan de rubricvereisten
Betere stabiliteit - strakker scorebereik, lagere variantie over runs
Minder uitschieters - minder plotselinge lage resultaten die productierisico creëren
In de praktijk duwt een succesvolle instructie-update niet alleen het gemiddelde omhoog. Het vermindert wispelturigheid door de workflow van de agent consistenter te maken - vooral bij triagevragen, remediëringsstructuur, en verificatiestappen.
Dit is wat “goed” eruitziet in enterprise AI: meetbare verbetering, herhaalbare prestaties, en een duidelijke audit trail die de wijziging aan het resultaat koppelt.
De Enterprise Conclusie: Maak van Evaluatie een Releaseproces
Deze workflow is de basis van enterprise-grade AI agent implementatie:
Voer een evaluatie uit op een representatieve dataset
Gebruik analyse om herhaalbare faalmodi te pinpointen
Pas gerichte instructie-updates toe met een beoordeelde diff
Volg wijzigingen via versiegeschiedenis voor controleerbaarheid
Voer dezelfde evaluatie opnieuw uit om verbetering te valideren
Dat is hoe je van “de agent klinkt goed” naar “de agent presteert betrouwbaar” gaat. Evaluatie wordt een releasepoort - een praktische CI-proces voor AI agents die operationeel risico vermindert, consistentie verbetert, en verbeteringen meetbaar maakt.
Oproep tot Actie
Als je wilt dat evaluatie echte bedrijfsresultaten aandrijft, behandel het dan als engineering:
Elke instructie-update zou een evaluatierun moeten activeren
Elke productiefout zou een nieuwe testcase moeten worden
Elke verbetering zou meetbaar en herhaalbaar moeten zijn
Verken AgentX
Leer meer op agentx.so
Voer evaluaties uit op het platform op app.agentx.so
In het volgende bericht gaan we dieper in op enterprise evaluatiemethoden, tools, en praktische technieken om agentprestaties en betrouwbaarheid continu te verbeteren. We zullen ook een nieuwe sectie over Monitoring introduceren - binnenkort beschikbaar.