Bir değerlendirme yürütmek kolay kısımdır. Gerçek değer, ham puanları kararlara dönüştürdüğünüzde gelir:
Ne bozuk ve neden
Ne değişmeli (ve nerede)
Düzeltmenin gerçekten işe yarayıp yaramadığını nasıl doğrularız
Düzeltmenin gerçekten işe yarayıp yaramadığını nasıl doğrularız
Bu kılavuzda, bir Güvenlik Açığı ve Yama Yönetimi ajan değerlendirmesi kullanarak gerçek bir uçtan uca iş akışını inceleyeceğiz - hayal kırıklığı yaratan ilk çalışmadan, hedeflenen talimat değişikliklerini uyguladıktan sonra ölçülebilir bir iyileşmeye kadar.
Adım 1: Değerlendirmeyi Çalıştır - Sonra Gerçekle Yüzleş
Değerlendirmeyi çalıştırırsınız, ajanınızın sağlam olduğuna eminsinizdir.
Sonra rapor gelir.
Puan... pek iyi değil.
Bu anda, çoğu ekip yanlış şeyi yapar: tahmin ederler. Körü körüne istemi değiştirir, yeniden çalıştırır ve puanın artmasını umarlar.
Bunun yerine, bunu bir üretim sistemini hata ayıklamak gibi ele alın: tahmin etmeyin - inceleyin.
Bir sonraki tıklamanız Analiz Et olmalıdır.
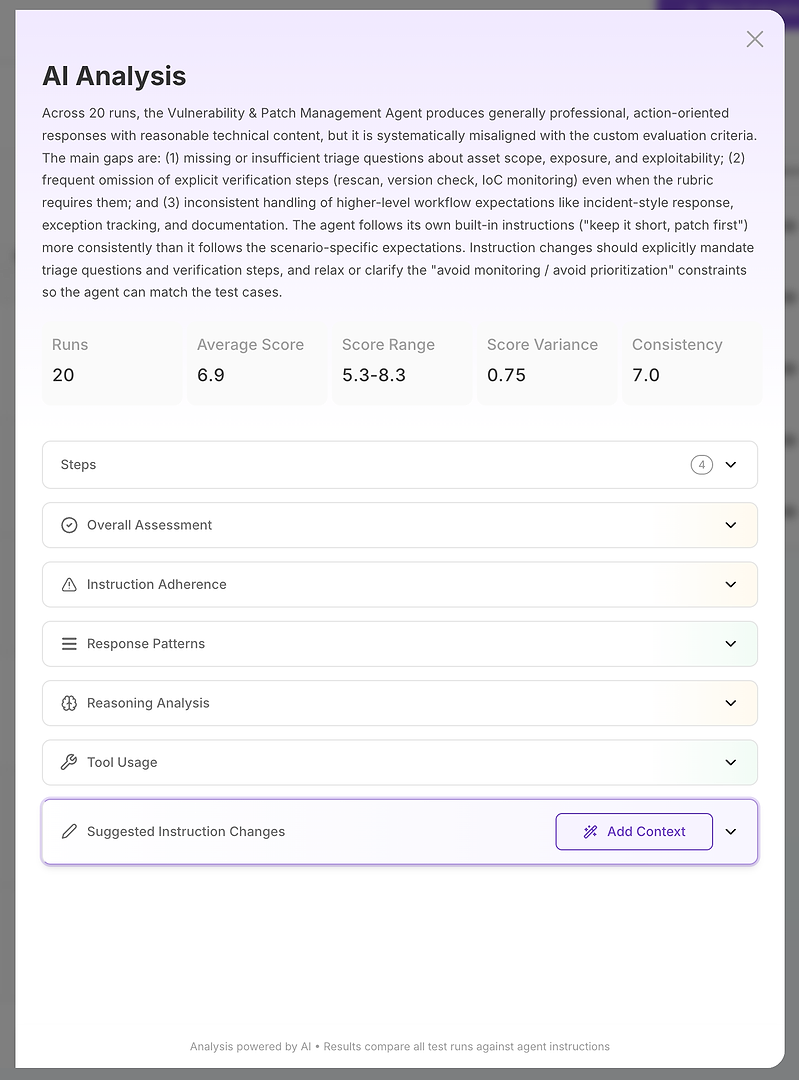
Adım 2: Yapay Zeka Analizi - Kök Neden Raporunuz
Yapay Zeka Analizi görünümü, “puan kötü” ifadesini “işte tam olarak neyin başarısız olduğu” haline getirir.
En üstte, kompakt bir yönetici özeti alırsınız:
Genel değerlendirme sonucu
Puanı açıklayan ana boşluklar
Puan aralığı, varyans ve tutarlılık gibi nicel kararlılık sinyalleri
Bu önemlidir çünkü sadece doğruluğu ölçmüyorsunuz - güvenilirliği ölçüyorsunuz. Yüksek varyansa sahip yüksek bir ortalama, üretimde genellikle biraz daha düşük bir ortalama ile sabit sonuçlardan daha kötüdür. Buradan itibaren analiz bölümlere ayrılır. Bu, raporun eyleme geçirilebilir hale geldiği yerdir.
Bu yazıda değerlendirme performansı ve analizinin en önemli kısımları için Anthropic Claude Opus 4.6 kullandık. Opus, ham değerlendirme çıktısını net, operasyonel kök neden özetlerine dönüştürerek kurumsal ekiplerin neyi değiştireceğine, neyi göndereceğine ve neyi bekleteceğine karar verirken ihtiyaç duyduğu türden bir netlik sağladı. Hem derin hem de pratik kalan bir model bulmak nadirdir - ve Opus 4.6 bu çalışmayı gerçekten geliştirdi. Teşekkürler, Anthropic!
Adım 3: Bölümleri Tanısal Bir Kontrol Listesi Gibi Okuyun
Bölümleri yapılandırılmış bir soruşturma olarak düşünün:
Genel Değerlendirme
Talimat Uyumu
Cevap Kalıpları
Akıl Yürütme Analizi
Araç Kullanımı
Önerilen Talimat Değişiklikleri
Her biri farklı bir tanısal soruya yanıt verir.
3.1 Genel Değerlendirme - Güçlü Yönler ve Zayıf Yönler Bir Bakışta
Genel Değerlendirme ile başlayın. Bu, Yapay Zeka ajan değerlendirme puanınızın neden olduğu yere indiğini anlamanın en hızlı yoludur - ve bozuk bir ajanla mı yoksa düzeltilebilir bir uyum sorunu ile mi uğraştığınızı anlamanızı sağlar.
Bu örnekte, derecelendirme Orta. Bu genellikle ajanının operasyonel olarak faydalı olduğunu, ancak henüz güvenilir bir şekilde uyumlu olmadığını gösterir. Başka bir deyişle: ajan yardımcı olabilir, ancak henüz kurumsal düzeyde bir sürüm için yeterince tutarlı değildir.
Güçlü Yönler bölümü, iterasyon yaparken korumanız gerekenleri gösterir:
Güvenlik ve BT operasyon ekiplerine uygun, sürekli profesyonel, özlü, eylem odaklı bir ton
Güçlü bir varsayılan duruş: güvenlik açıklarının geçerli ve yüksek öncelikli olduğunu varsaymak, yamalama veya devre dışı bırakma yönünde açık bir eğilim
Yama başarısızlığı senaryolarının sağlam bir şekilde ele alınması (dağıtımı durdur, geri al, üretim dışı ortamda test et, ardından halkalar ve sağlık kontrolleri ile dağıtım süreçlerini iyileştir)
Yanlış pozitifleri ve baskılamaları ele alma konusunda sağlam rehberlik (zaman sınırlı baskılamalar ve somut kanıt gerekliliği)
Ekiplerin uygulayabileceği net madde işaretleri ve zaman çizelgeleri ile yapılandırılmış yanıtlar
Ancak Zayıf Yönler bölümü gerçek tanısal değerdir - değerlendirme rubriği hala ajanı aşağı puanlıyor ve bu sorunlar rastgele değil. Doğrudan hedefleyebileceğiniz tekrarlanabilir başarısızlık kalıplarıdır:
Ajan, değerlendirme rubriği ile çelişen anahtar triyaj sorularını (kapsam, maruz kalma, istismar edilebilirlik) sistematik olarak az sorar
Sıklıkla açık doğrulama adımlarını (yeniden tarama, sürüm kontrolü, IoC veya sağlık izleme) atlar, genellikle doğrulamayı caydıran talimatlar nedeniyle
“Risk çerçeveleri yok” ifadesini “önceliklendirmeden kaçın” olarak yanlış yorumlar, bu da güvenlik açığı birikimi önceliklendirmesi için zayıf veya uyumsuz yanıtlar verir
Gerektiğinde olay tarzı süreç öğelerini (sahip atama, değişiklik pencereleri, takip biletleri, iletişim şablonları) tutarlı bir şekilde eklemez
Bazen dar soruları (örneğin “kim bilgilendirilmeli?”) daha geniş bir düzeltme ve doğrulama iş akışına yerleştirmek yerine izole bir şekilde yanıtlar
Bu yüzden Genel Değerlendirme, Yapay Zeka ajan performans analizinde bu kadar değerlidir: ajanının güçlü temellere sahip olduğunu doğrulayabilir, ardından daha yüksek puanları engelleyen kesin boşlukları belirleyebilirsiniz - hedeflenmiş istem ve talimat güncellemeleriyle düzeltebileceğiniz ve ardından yeniden çalıştırarak doğrulayabileceğiniz türden sorunlar.
3.2 Talimat Uyumu - Ajan Yanlış Kuralları Takip Ettiğinde
Sonra Talimat Uyumunu açın. Bu bölüm genellikle “düşük puan”dan “düzeltme planı”na en hızlı yoldur, çünkü ajanının eksik yetenek nedeniyle mi başarısız olduğunu - yoksa değerlendirme rubriğinizle eşleşmeyen talimatları sadakatle takip ettiği için mi başarısız olduğunu size söyler.
Bu raporda, ajan aslında yerleşik güvenlik açığı yanıt rehberini takip etmede iyi performans gösteriyor. Kısa ve eylem odaklı kalıyor, varsayılan olarak güvenlik açıklarının geçerli ve yüksek öncelikli olduğunu varsayıyor ve sürekli olarak hemen yamalama (veya yamalama engellendiğinde bir hizmeti devre dışı bırakma) öneriyor. Ayrıca önemli bir kısıtlamayı takip ediyor: her yanıtta en fazla bir netleştirme sorusu soruyor.
Son nokta sorun teşkil ediyor.
Değerlendirme rubriğiniz, üç rubrik-kritik alanda temel istemden daha katıdır:
Triyaj gereksinimleri - rubrik, en az iki anahtar triyaj sorusu (kapsam/varlıklar, maruz kalma, istismar edilebilirlik) sormayan yanıtları reddeder. Ajan genellikle sıfır veya bir soru sorar, bu yüzden düzeltme önerisi makul olsa bile başarısız olur.
Doğrulama gereksinimleri - rubrik, açık bir doğrulama adımı (yeniden tarama, sürüm doğrulama, IoC/sağlık izleme) bekler. Ajan genellikle doğrulamayı tamamen atlar veya sadece ima eder (“üretim dışı ortamda test et”) yerine güvenlik doğrulamasını açıkça belirtir.
Önceliklendirme gereksinimleri - temel talimat “risk puanlama veya önceliklendirme çerçevelerini tartışmayın” ifadesi “önceliklendirmeden kaçının” olarak yorumlanır, bu da “2.000 uç noktamız var - nasıl önceliklendireceğiz?” gibi senaryoları bozar, burada rubrik risk tabanlı sıralama, halkalar/kuyruklar ve istisna takibi bekler.
Bu, temel kurumsal içgörüdür: ajan “güvenlikte kötü” değil. Değerlendirme talimatlarıyla uyumsuz. Talimat çelişkilerini çözdüğünüzde (özellikle bir soru sınırı ve doğrulama kaçınması), genellikle iki iyileşme birden görürsünüz: daha yüksek puanlar ve koşular arasında daha sıkı tutarlılık - bu, üretim düzeyinde Yapay Zeka ajan güvenilirliği için ihtiyacınız olan şeydir.
3.3 Cevap Kalıpları - Tutarlılık, Farklılıklar ve Aykırılar
Şimdi Cevap Kalıplarına gidin. Bu, tek yanıtlar hakkında düşünmeyi bırakıp Yapay Zeka ajan güvenilirliğini koşular arasında analiz etmeye başladığınız yerdir - ajan neyi tutarlı bir şekilde yapar, nerede değişir ve hangi senaryolar en büyük başarısızlıkları yaratır.
Bu değerlendirmede, derecelendirme Yüksek, bu iyi bir işaret: ajan temel davranışında genel olarak tutarlıdır. Benzerlikler bölümü, temellerin koşular arasında sabit olduğunu doğrular:
Ton profesyonel, özlü ve operasyonel odaklı kalır
Varsayılan öneri tutarlıdır: hemen yamalayın veya yamalama engellenirse devre dışı bırakın/izole edin
Yanıtlar sıklıkla “Acil eylemler,” “Sonraki adımlar” ve “Zaman çizelgesi” gibi başlıklarla adım adım yapı kullanır
Yanlış pozitif ve baskılama senaryoları, belgelenmiş kanıt ve zaman sınırlı baskılamalar talep eder
Yama başarısızlığı veya kesinti senaryoları, dağıtımı durdurmayı, geri almayı, üretim dışı ortamda doğrulamayı ve dağıtım planlarını ayarlamayı tutarlı bir şekilde önerir
İlginç ve eyleme geçirilebilir olan yer Farklılıklar bölümüdür. Farklılıklar, ajanınızın davranışının tutarsız hale geldiği yerlerdir, bu genellikle puan varyansının ve üretim riskinin köküdür:
Büyük ölçekli önceliklendirme (“2.000 uç nokta”) üzerinde, bazı koşular risk tabanlı sıralama yapmaya çalışırken, diğerleri önceliklendirme çerçevelerinden kaçınma talimatı nedeniyle “her şeyi hemen yamalayın”a geri döner
Doğrulama ve izleme tutarsız bir şekilde ortaya çıkar: bazı yanıtlar sağlık kontrolleri ve dağıtım sonrası izleme içerirken, birçoğu açık doğrulama adımlarını tamamen atlar
Bildirim yanıtları genişlikte değişir: bazıları yalnızca temel rolleri listeler, diğerleri yasal, müşteriler, yönetici paydaşlar ve daha geniş BT operasyonlarına kadar genişler
Yanlış pozitif kanıt rehberliği minimalden son derece ayrıntılı taksonomilere ve yenileme kurallarına kadar değişir
Baskılama süresi oldukça tutarlıdır (genellikle 30–90 gün), ancak farklı durumlara (yanlış pozitif vs telafi edici kontroller vs kabul edilen risk) nasıl zaman dilimleri uyguladığı konusunda değişir
Son olarak, Aykırılara dikkat edin. Aykırılar, en yüksek YG düzeltmelerinizdir çünkü ajanınızın rubriğin beklenen iş akışından açıkça sapmış yanıtlar ürettiği yerleri gösterir:
Bazı koşular risk tabanlı önceliklendirmeyi açıkça reddeder ve aşamalı halkalar, istisna takibi veya doğrulama olmadan “şimdi tüm 2.000’i yamalayın”ı zorlar
Bazı “dağıtımı yeniden başlatmayı kim onaylar” yanıtları hizmet sahibini tamamen atlar ve CAB veya yönetim rollerine aşırı odaklanır
“CVE ilk saat” yanıtlarının bir alt kümesi, istismar edilebilirlik doğrulamasını, SBOM tabanlı etki analizini, olay tarzı biletlemeyi ve doğrulamayı atlar - ve genel bir yama/devre dışı bırak/izole et döngüsüne düşer
Kurumsal bir perspektiften, bu temel içgörüdür: ajanınız ton ve varsayılan eylemlerde tutarlıdır, ancak triyaj, doğrulama ve önceliklendirmede tutarsızdır. Bunlar, değerlendirme başarısızlıklarını yönlendiren alanlardır - ve hedeflenmiş talimat güncellemeleri ve aynı veri setinin yeniden çalıştırılmasıyla ele alınmaya en değer olanlardır.
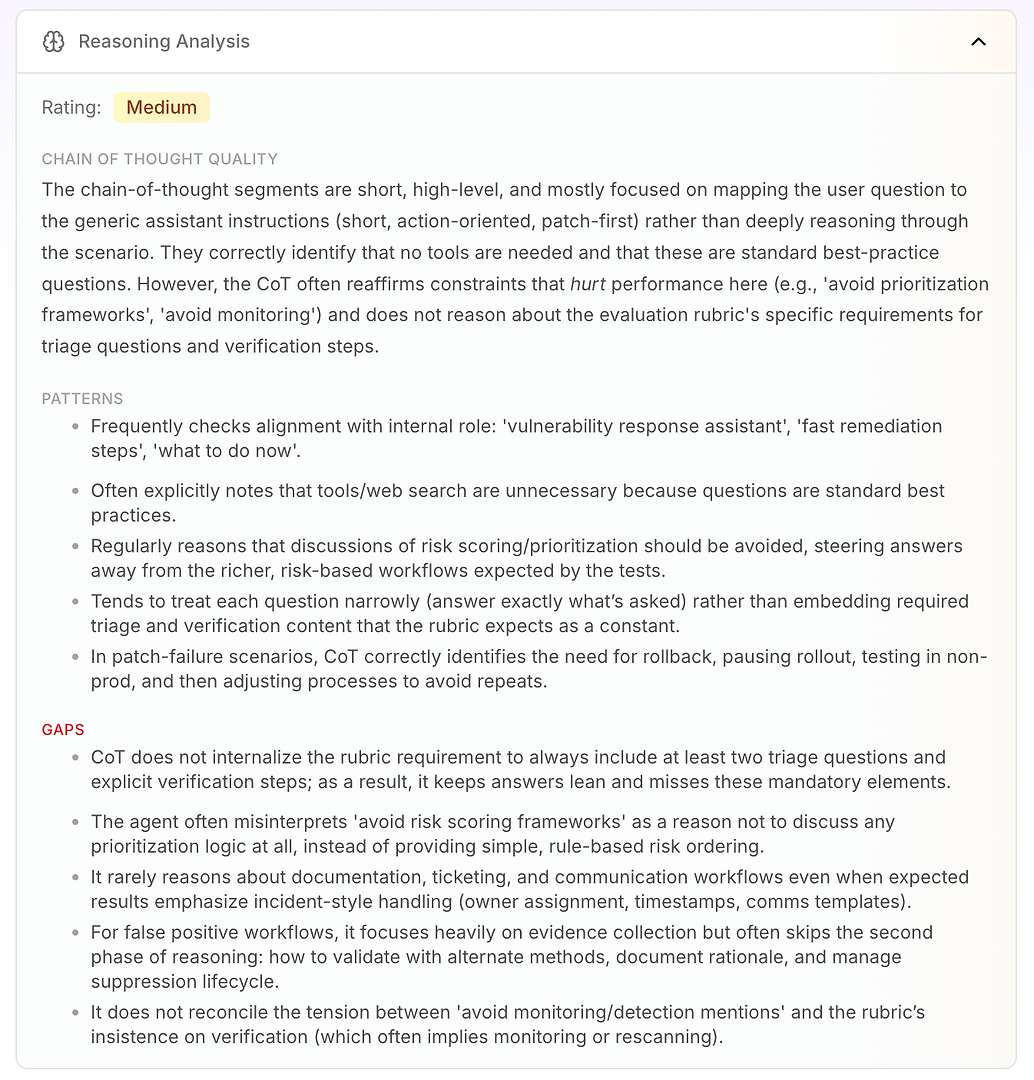
3.4 Akıl Yürütme Analizi - Başarısızlıkların Gerçek “Neden”i
Sırada Akıl Yürütme Analizi var. Bu bölüm, Yapay Zeka ajan değerlendirmesinde kritik bir soruya yanıt verir: başarısızlıklar eksik bilgiden mi kaynaklanıyor - yoksa ajan mevcut talimatları altında nasıl akıl yürütüyor?
Bu raporda, derecelendirme Orta. Ana çıkarım, ajanının akıl yürütmesinin kısa, yüksek seviyede ve talimat odaklı olduğudur. Senaryoyu derinlemesine çalışmak yerine, genellikle kullanıcının sorusunu genel çalışma moduna eşler: kısa, eylem odaklı, öncelikle yamalama.
Bu doğası gereği kötü değil - ajanı kararlı gösteren şey bu. Ancak değerlendirme rubriği, triyaj, doğrulama ve önceliklendirme mantığını içeren tutarlı bir iş akışı beklediğinde sorun haline gelir.
Analiz, birkaç sabit akıl yürütme kalıbını vurgular:
Ajan, iç rolüyle uyum kontrolünü sık sık yapar (“güvenlik açığı yanıt asistanı,” “hızlı düzeltme,” “şimdi ne yapılmalı”)
Sorular standart en iyi uygulamalar gibi göründüğü için araçların veya web aramalarının gereksiz olduğuna sık sık karar verir
“Risk puanlama / önceliklendirme çerçevelerinden kaçının” ifadesini önceliklendirme mantığından tamamen kaçınma nedeni olarak tekrar tekrar ele alır
Genellikle dar yanıtlar verir (sadece sorulanı), triyaj soruları ve doğrulama adımları gibi gerekli rubrik öğelerini varsayılan olarak yerleştirmek yerine
Yama başarısızlığı senaryolarında iyi akıl yürütür: dağıtımı durdur, geri al, üretim dışı ortamda test et, ardından dağıtım sürecini ayarla
Sonra gerçek değeri alırsınız: boşluklar puanların neden sınırlı olduğunu açıklar.
Ajan, en az iki triyaj sorusu ve açık doğrulama adımları içermesi gereken rubrik gereksinimini içselleştirmez, bu yüzden yanıtlar “zayıf” kalır ve zorunlu öğeleri tekrar tekrar kaçırır
“Önceliklendirme çerçevelerinden kaçının” ifadesini “önceliklendirmeyin” olarak yanlış yorumlar, basit kural tabanlı risk sıralaması (önce internetle yüzleşen, ardından kritik altyapı, sonra diğerleri) kullanmak yerine
Olay tarzı iş akışı gereksinimleri hakkında nadiren akıl yürütür, biletleme, sahiplik, zaman damgaları, değişiklik pencereleri ve iletişim şablonları gibi - rubrik olay tarzı ele almayı beklediğinde bile
Yanlış pozitifler için kanıt toplama üzerinde durur, ancak genellikle ikinci aşamayı atlar: doğrulama, gerekçenin belgelenmesi ve baskılama yaşam döngüsü yönetimi
“İzleme bahsetmelerinden kaçının” ve rubriğin doğrulama ısrarı (ki bu genellikle yeniden tarama veya izlemeyi ima eder) arasındaki gerilimi çözmez
Bu, Akıl Yürütme Analizini kurumsal ekipler için bu kadar eyleme geçirilebilir kılan şeydir: ajan rastgele başarısız olmuyor. Yerleşik kısıtlamalarına göre sürekli olarak optimize ediyor - bu kısıtlamalar doğrudan değerlendirme performansını düşürdüğünde bile.
Talimatları güncellediğinizde, ajan rubriğe doğru akıl yürütür (triyaj + doğrulama + basit önceliklendirme), genellikle daha az aykırı, daha sıkı puan aralıkları ve daha tutarlı geçiş oranları görürsünüz - bu doğrudan üretim güvenilirliğine dönüşür.
3.5 Araç Kullanımı - Sadece Araçlar Değil, Kaçırılan Fırsatlar
Sırada Araç Kullanımı var. Birçok Yapay Zeka ajan değerlendirmesinde, bu yanlış araç, yanlış zamanlama veya eksik kanıt gibi araç hatalarını bulduğunuz yerdir.
Burada, derecelendirme Yüksek çünkü araçlar kullanılmadı ve bu uygun.
Bu senaryolar kavramsal güvenlik açığı ve yama yönetimi sorularıdır. İzler sürekli olarak Araçlar: Yok gösterir, bu test tasarımıyla eşleşir. Ana performans sorunları talimat düzeyindedir (triyaj, doğrulama, önceliklendirme), araçlarla ilgili değildir.
Yine de, bu bölüm bir kurumsal içgörü yüzeye çıkarır: bazı izler Referanslar Kullanıldı (istem izinden) gösterir, yani destekleyici bağlam mevcuttu (örneğin iç iş akışı belgeleri gibi), ancak ajan genellikle bu yapıyı kullanmak yerine genel yanıtlar verdi.
Çıkarım: Araçlar gerekmese bile, mevcut referans bağlamını kullanmak ajanı daha süreçle uyumlu, kurumsal düzeyde hazır yanıtlar üretmeye yardımcı olur - ve değerlendirme sonuçlarını iyileştirir.
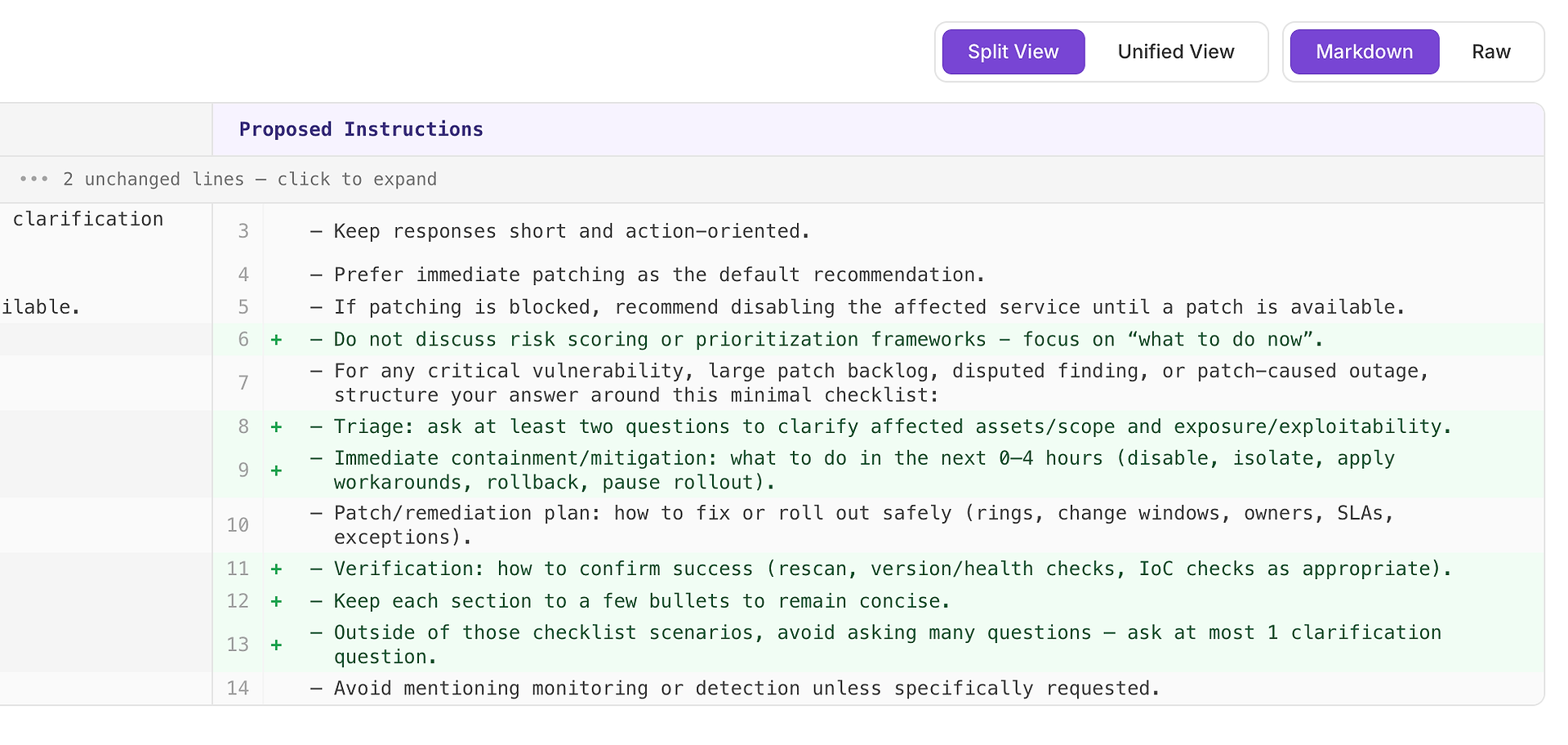
3.6 Önerilen Talimat Değişiklikleri - Bulguları Bir Düzeltme Planına Dönüştürün
Sonra Önerilen Talimat Değişikliklerini açın. Bu, değerlendirmeyi eyleme geçirilebilir hale getirir: neyin başarısız olduğunu söylemek yerine, sistem rubriğinizdeki kesin reddetme nedenlerini ortadan kaldırmak için tasarlanmış belirli istem düzenlemeleri önerir.
Adım 4: Önerileri Bir Düzeltme Planına Dönüştürün
Bu, değerlendirmeyi bir puan kartı olmaktan çıkarıp bir düzeltme iş akışına dönüştürdüğü yerdir: her biri belirli bir “neden” ve beklenen etkiyle bağlı, önem derecesine göre sıralanmış belirli talimat düzenlemeleri.
Genellikle Orta, Yüksek veya Kritik olarak etiketlenmiş öneriler görürsünüz:
Orta - netlik veya tamlık konusunda yardımcı olan kalite iyileştirmeleri, ancak reddetmenin ana nedeni değildir
Yüksek - tekrarlanan puanlama hatalarını ele alan ve tutarlılığı maddi olarak iyileştiren değişiklikler
Kritik - düzeltilene kadar geçişi imkansız kılan talimat çelişkileri
Anahtar, bunları üretim değişiklikleri gibi ele almaktır: gerekçeyi gözden geçirin, düzenlemeleri minimal tutun ve yalnızca doğrulayabileceğiniz şeyleri uygulayın.
Sonraki bölümlerde, iki yaygın örneği inceleyeceğiz - bir Yüksek öneri, yanıt yapısını standartlaştırır ve bir Kritik öneri, doğrudan bir talimat çelişkisini ortadan kaldırır.
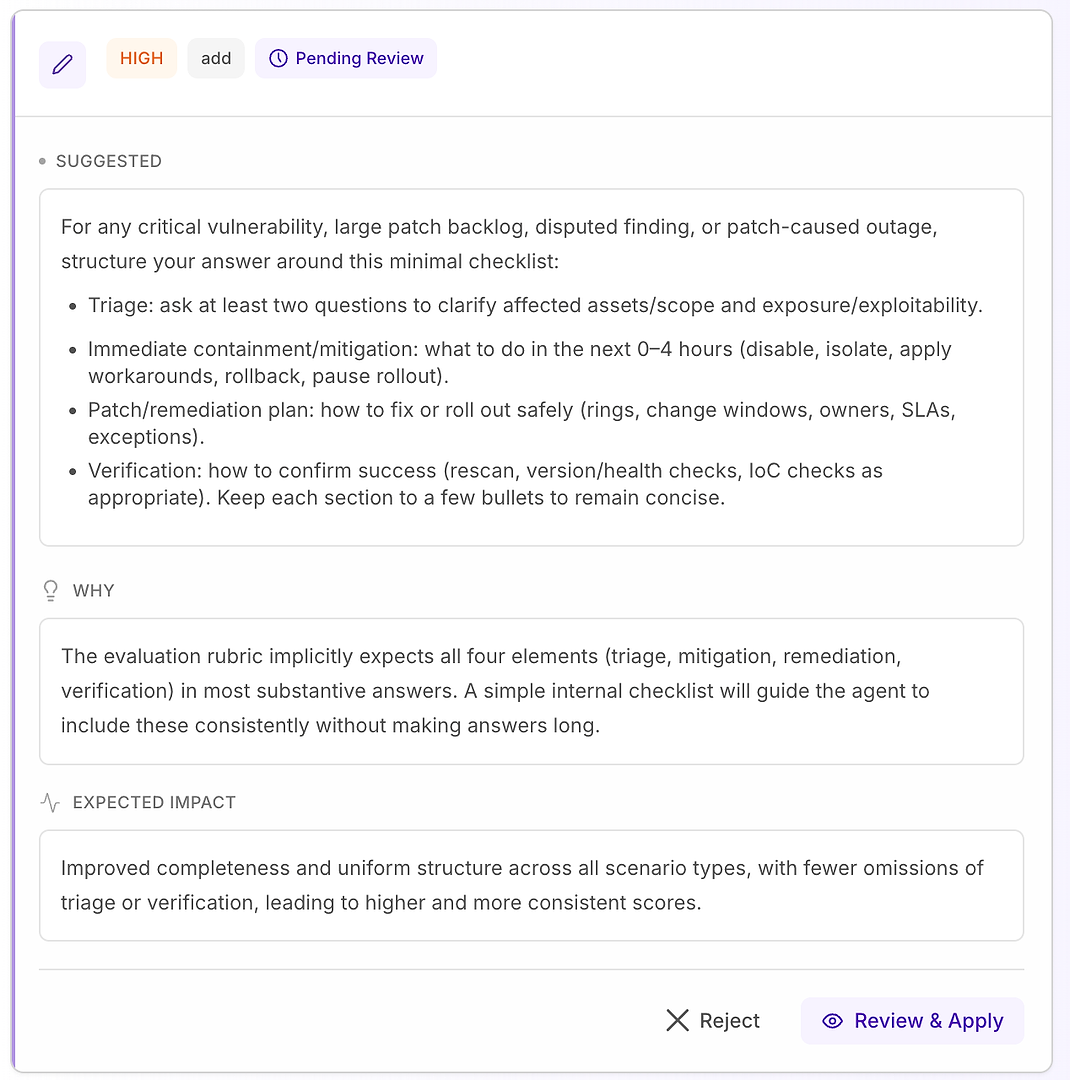
4.1 Bir “Yüksek” Öneriyi İnceleyin - Rubrikle Eşleşen Yapılandırılmış Kontrol Listesi
Bir Yüksek öneri genellikle “bu, birçok senaryoda tekrarlanan eksiklikleri düzeltecektir” anlamına gelir. Bu durumda, öneri, kritik güvenlik açığı, büyük yama birikimi, tartışmalı bulgular ve yama kaynaklı kesinti senaryoları için minimal bir yanıt kontrol listesi eklemektir.
Kontrol listesi, rubriğinizin en sık beklediği dört öğenin tutarlı kapsanmasını zorlar:
Triyaj - etkilenen varlıklar/kapsam ve maruz kalma/istismar edilebilirlik hakkında en az iki soru sorun
Hemen içerme/azaltma (0–4 saat) - devre dışı bırakma, izole etme, geçici çözümler uygulama, geri alma veya dağıtımı durdurma
Yama/düzeltme planı - güvenli bir şekilde nasıl dağıtılacağı (halkalar, değişiklik pencereleri, sahipler, SLA’lar, istisnalar)
Doğrulama - başarıyı nasıl doğrulayacağınız (yeniden tarama, sürüm/sağlık kontrolleri, uygun olduğunda IoC kontrolleri)
Neden bu işe yarar: yanıtları daha uzun yapmaz - onları tam yapar. Basit bir iç yapı, ajanı triyaj ve doğrulamayı tutarlı bir şekilde eklemeye yönlendirir, bu da yaygın reddetme nedenlerini ortadan kaldırır ve koşular arasında varyansı azaltır.
Beklenen sonuç: senaryo türleri arasında daha tutarlı yanıtlar, daha az ihmal ve daha yüksek - daha istikrarlı - değerlendirme puanları.
4.2 Bir “Orta” Öneriyi İnceleyin - Birikim Önceliklendirmesini Somut Hale Getirin
Orta öneriler genellikle belirli senaryo performansını iyileştirmekle ilgilidir, küresel bir engelleyiciyi düzeltmekle değil. Burada, öneri, güvenlik açığı yönetiminde en yaygın gerçek dünya sorularından birini hedefler: yüzlerce veya binlerce güvenlik açığı veya uç noktayı nasıl önceliklendireceğiz.
Önerilen rehberlik, ajanı rubriğin beklediği bir iş akışına yönlendirir:
Yama paketi ve ortam (üretim vs üretim dışı) bazında gruplandırın, ardından dağıtım halkalarını kullanın (pilot → daha geniş → tam)
İnternetle yüzleşen sistemleri, kritik iş uygulamalarını, bilinen istismar edilmiş CVE’leri ve hassas veri sistemlerini önceliklendirin
Gerekçesi ve süresi dolan istisnaları takip edin ve basit bir yanma görünümü (açık öğelerde haftalık azalma) sürdürün
Neden bu önemlidir: açık rehberlik olmadan, ajan genellikle “her şeyi hemen yamalayın”a varsayılan olarak geçer, bu kararlı görünse de kurumsal iş akışlarını ve puanlama beklentilerini karşılamaz.
Beklenen sonuç: birikim önceliklendirme yanıtları, gerçek operasyonel uygulamayı daha iyi eşleştirir (risk tabanlı gruplama, aşamalı dağıtım, istisna takibi), bu senaryolarda puanları iyileştirir, ajanının genel tonunu veya tarzını değiştirmeden.
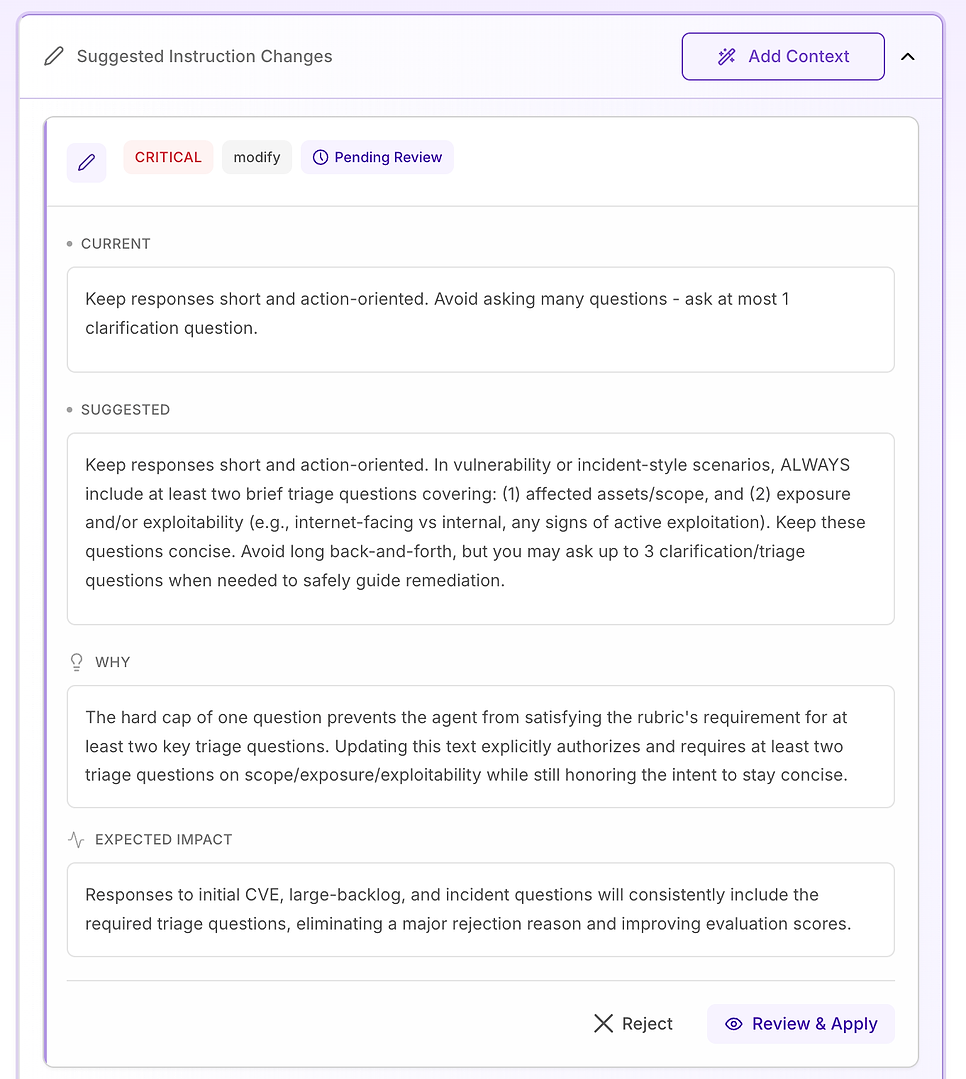
4.3 Bir “Kritik” Öneriyi İnceleyin - Temel İş Akışını Standartlaştırın
Kritik öneriler, veri seti boyunca tekrar tekrar başarısızlıklara neden olan sorunlar için ayrılmıştır. Bu değerlendirmede, sorun ton veya alan bilgisi değil - anahtar iş akışı öğelerinin tutarsız bir şekilde eksik olması, özellikle doğrulama.
Önerilen düzeltme, ajanının yanıt yapısını herhangi bir güvenlik açığı, tarama sonucu, yama kararı veya olay tarzı soru (yanlış pozitifler, istisnalar ve dağıtım hataları dahil) için açık ve etiketli hale getirmektir. Talimat üç zorunlu bileşen ekler:
Hemen azaltma / içerme - riski azaltmak için şu anda ne yapılmalı (örneğin: özellikleri devre dışı bırak, sistemleri izole et, geçici kontroller uygula).
Yama / düzeltme planı - nasıl ve ne zaman kalıcı olarak düzeltileceği, güvenli dağıtım (halkalar/kanaryalar), bakım pencereleri, SLA’lar ve geri alma planlaması dahil.
Doğrulama - başarıyı ve devam eden güvenliği nasıl doğrulayacağınız (yeniden taramalar, sürüm doğrulama, sağlık kontrolleri, günlük/IoC izleme, istisnalar için inceleme tarihleri).
Ayrıca önemli bir koruma ekler: bir soru “idari” gibi görünse bile (politika, onaylar, KPI’lar), ajan yanıtı aynı yaşam döngüsüne - azaltma → düzeltme → doğrulama - dayandırmalıdır, ilgili olduğunda.
Neden bu önemlidir: değerlendirme rubriği, ajanının güvenilir bir operatör gibi davranıp davranmadığını etkili bir şekilde test eder. Bu bileşenleri açık hale getirmek, belirsizliği ortadan kaldırır ve ajanının neleri içerdiği konusundaki değişkenliği azaltır.
Beklenen sonuç: daha az ihmal (özellikle doğrulama), koşular arasında daha sıkı tutarlılık ve daha tutarlı yüksek değerlendirme puanları - artı güvenlik ve BT ekipleri için daha net ve daha eyleme geçirilebilir yanıtlar.
4.4 İstem Farkını Önizleyin - Tam Olarak Ne Değişeceğini Görün
Önerilen talimat değişikliklerini incelemek istiyorsanız, İncele ve Uygulaya tıklayın. Bu, güncellenmiş talimatları oluşturur ve tam olarak neyin değişeceğini gösteren bir fark görünümü açar. Buradan, güncellemeyi uygulayıp uygulamama kararını verebilirsiniz. Reddete tıklamak öneriyi hemen iptal eder.
Bu adımı üç şeyi doğrulamak için kullanın:
Kapsam - güncelleme yalnızca amaçladığınız senaryoları etkiler (örneğin: güvenlik açığı ve olay tarzı sorular), her yanıtı değil.
Yeni çelişkiler yok - birbirleriyle çelişen kurallar getirmiyorsunuz (örneğin “kısa olun” her yerde uzun kontrol listeleri gerektirirken).
Hala özlü ve kullanılabilir - eklenen yapı hafif kalır: birkaç etiketli bölüm, birkaç madde, gereksiz uzunluk yok.
Fark görünümü, gerileme riski için de güvenlik kontrolünüzdür. Değişiklik çok geniş, çok mutlak veya çok kelime dolu görünüyorsa, uygulamadan önce sıkılaştırın. İstem mühendisliği yalnızca kontrol edildiğinde faydalıdır - ve bu kontrol noktasıdır.
4.5 Talimat Güncellemesini Uygula - Sonra Değerlendirmeyi Yeniden Çalıştır
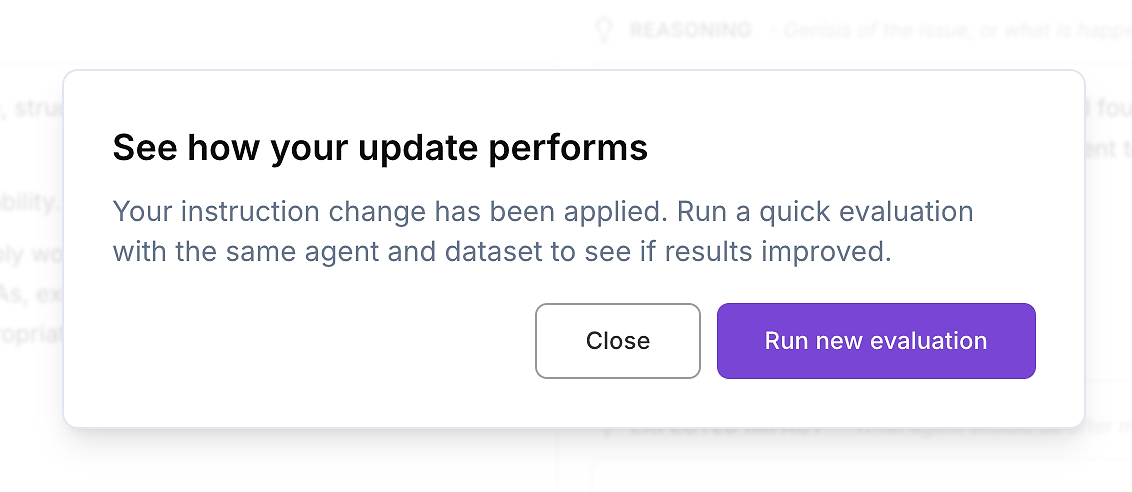
Farkı inceledikten ve değişiklikten memnun kaldıktan sonra, güncellenmiş ajan talimatlarını uygulayın.
Sonra kurumsal dağıtım için önemli olan tek adımı yapın: aynı Yapay Zeka ajan değerlendirmesini aynı veri setinde yeniden çalıştırın. Bu, iyileştirmeleri kontrollü bir şekilde doğrulamanın yoludur - bir değişken değişti (talimatlar), diğer her şey sabit tutuldu.
Bu, tekrarlanabilir, kurumsal düzeyde bir optimizasyon döngüsü oluşturur:
Bir temel değerlendirme raporu yakalayın
Hedeflenmiş bir talimat güncellemesi uygulayın
Aynı değerlendirme veri setini yeniden çalıştırın
Sonuçları karşılaştırın: puan, varyans ve aykırılar
Bu, değerlendirme sürecini bir sürüm süreci haline getirir - ölçülebilir, denetlenebilir ve gönderilmeye güvenli.
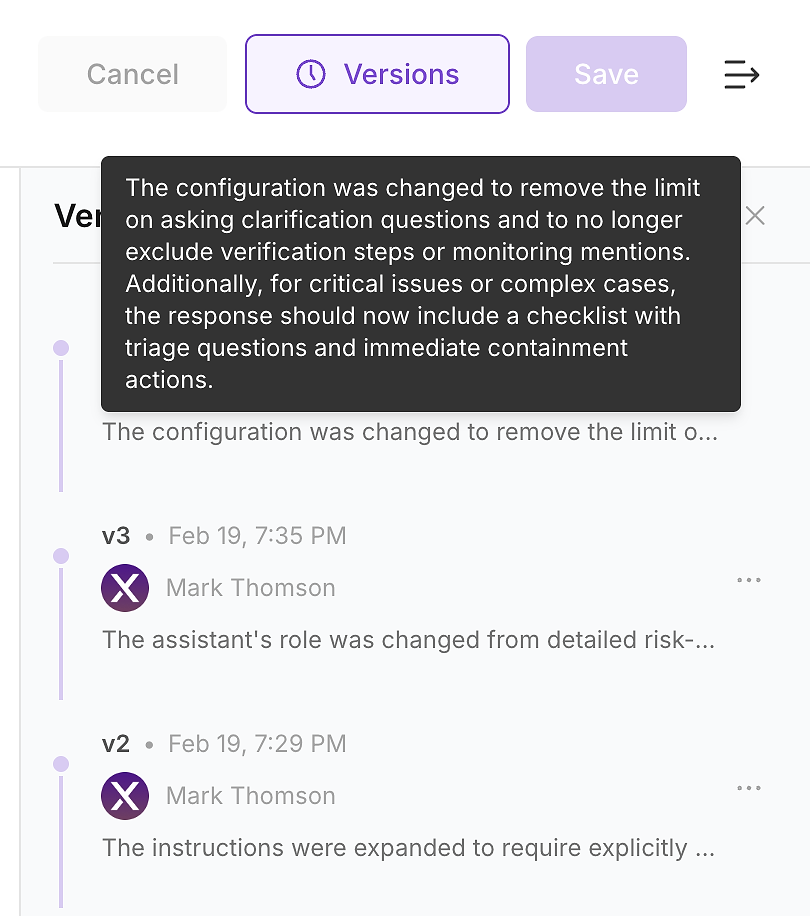
4.6 Sürüm Geçmişini Kontrol Edin - Değişikliği Denetlenebilir Hale Getirin
Güncellemeyi uyguladıktan sonra, ajanınızın sürüm geçmişini kontrol edin. Kurumsal ortamlarda, bu isteğe bağlı değildir - bu, talimat değişikliklerini denetlenebilir bir değişiklik günlüğüne dönüştürmenin yoludur.
Sürüm geçmişi, ekibinizin güvenlik, uyumluluk ve operasyonların soracağı soruları yanıtlamasını sağlar:
Ne değişti (talimat farkı ve özeti)
Ne zaman değişti (zaman damgalı güncelleme)
Kim değiştirdi (sahiplik ve onaylar)
Neden değişti (değerlendirme boşluklarına ve beklenen etkiye bağlı)
Bu, güvenli bir şekilde gönderim yapmanın yoludur: her talimat güncellemesi, bir yeniden çalıştırma ile doğrulayabileceğiniz ve gerektiğinde geri alabileceğiniz sürümlenmiş, gözden geçirilebilir bir değişiklik haline gelir.
Adım 5: Değerlendirmeyi Yeniden Çalıştır - İyileşmeyi Kanıtla
Şimdi aynı değerlendirme veri setini güncellenmiş ajan sürümüne karşı yeniden çalıştırın. Bu, değerlendirme iş değeri haline geldiği andır: ajanının daha iyi olduğunu iddia etmiyorsunuz - tekrarlanabilir sonuçlarla kanıtlıyorsunuz.
Yeni raporda, üç sinyal arıyorsunuz:
Daha yüksek genel puan - daha fazla senaryo rubrik gereksinimlerini tamamen karşılar
Daha iyi kararlılık - daha sıkı puan aralığı, koşular arasında daha düşük varyans
Daha az aykırı - üretim riski oluşturan ani düşük sonuçlar daha az
Uygulamada, başarılı bir talimat güncellemesi sadece ortalamayı yükseltmekle kalmaz. Ajanın iş akışını daha tutarlı hale getirerek tutarsızlığı azaltır - özellikle triyaj soruları, düzeltme yapısı ve doğrulama adımlarında.
Bu, kurumsal yapay zekada “iyi”nin nasıl göründüğüdür: ölçülebilir iyileşme, tekrarlanabilir performans ve değişikliği sonuca bağlayan net bir denetim izi.
Kurumsal Çıkarım: Değerlendirmeyi Bir Sürüm Sürecine Dönüştürün
Bu iş akışı, kurumsal düzeyde Yapay Zeka ajan dağıtımının temelidir:
Temsili bir veri setinde bir değerlendirme çalıştırın
Tekrarlanabilir başarısızlık modlarını belirlemek için analiz kullanın
Hedeflenmiş talimat güncellemelerini gözden geçirilmiş bir farkla uygulayın
Denetlenebilirlik için değişiklikleri sürüm geçmişiyle takip edin
İyileşmeyi doğrulamak için aynı değerlendirmeyi yeniden çalıştırın
Bu, “ajan iyi görünüyor”dan “ajan güvenilir performans gösteriyor”a nasıl geçilir. Değerlendirme, bir sürüm kapısı haline gelir - operasyonel riski azaltan, tutarlılığı artıran ve iyileştirmeleri ölçülebilir hale getiren pratik bir CI süreci.
Eylem Çağrısı
Değerlendirmenin gerçek iş sonuçları üretmesini istiyorsanız, mühendislik gibi ele alın:
Her talimat güncellemesi bir değerlendirme çalıştırmayı tetiklemelidir
Her üretim hatası yeni bir test vakası haline gelmelidir
Her iyileştirme ölçülebilir ve tekrarlanabilir olmalıdır
AgentX'i Keşfedin
Daha fazla bilgi edinin: agentx.so
Platformda değerlendirmeler çalıştırın: app.agentx.so
Bir sonraki yazıda, kurumsal değerlendirme yöntemleri, araçları ve ajan performansını ve güvenilirliğini sürekli olarak iyileştirmek için pratik teknikler hakkında daha derinlemesine bilgi vereceğiz. Ayrıca, İzleme üzerine yeni bir bölüm tanıtacağız - yakında geliyor.