الخطوة 1: بدء رحلتك التقييمية
بالنسبة لأي فريق جاد بشأن جودة الذكاء الاصطناعي، تعتبر لوحة التقييم مركز القيادة لضمان الجودة. إذا كنت قد بدأت للتو، فقد تبدو شيئًا كهذا:
هذا هو خط البداية الخاص بك. إنشاء تقييمك الأول هو الخطوة الحاسمة نحو استبدال الاختبار الشخصي "الشعور الداخلي" بعملية علمية منظمة. كما يؤكد خبراء AWS، فإن إطار التقييم الشامل ضروري لمعالجة تعقيد أنظمة الذكاء الاصطناعي الوكيل في بيئات الإنتاج.
إنشاء ثقافة التقييم المستمر أمر حاسم لنشر وكلاء ليسوا فقط أقوياء، بل موثوقين وموثوقين في السيناريوهات الحرجة للأعمال.
الخطوة 2: إعداد تكوين التقييم الخاص بك
إذا لم تقم بإنشاء مجموعة البيانات التقييمية الأولى الخاصة بك بعد، فارجع إلى الجزء 1 - بناء مجموعات بيانات تقييم على مستوى المؤسسات: أساس وكلاء الذكاء الاصطناعي الموثوقين للحصول على دليل خطوة بخطوة لبناء مجموعات بيانات تقييم على مستوى المؤسسات مع حالات اختبار واقعية، ومعايير تسجيل واضحة، وتغطية للحالات الحافة - حتى تنتج تقييمات وكلاء الذكاء الاصطناعي نتائج موثوقة وقابلة للتكرار يمكنك الوثوق بها.
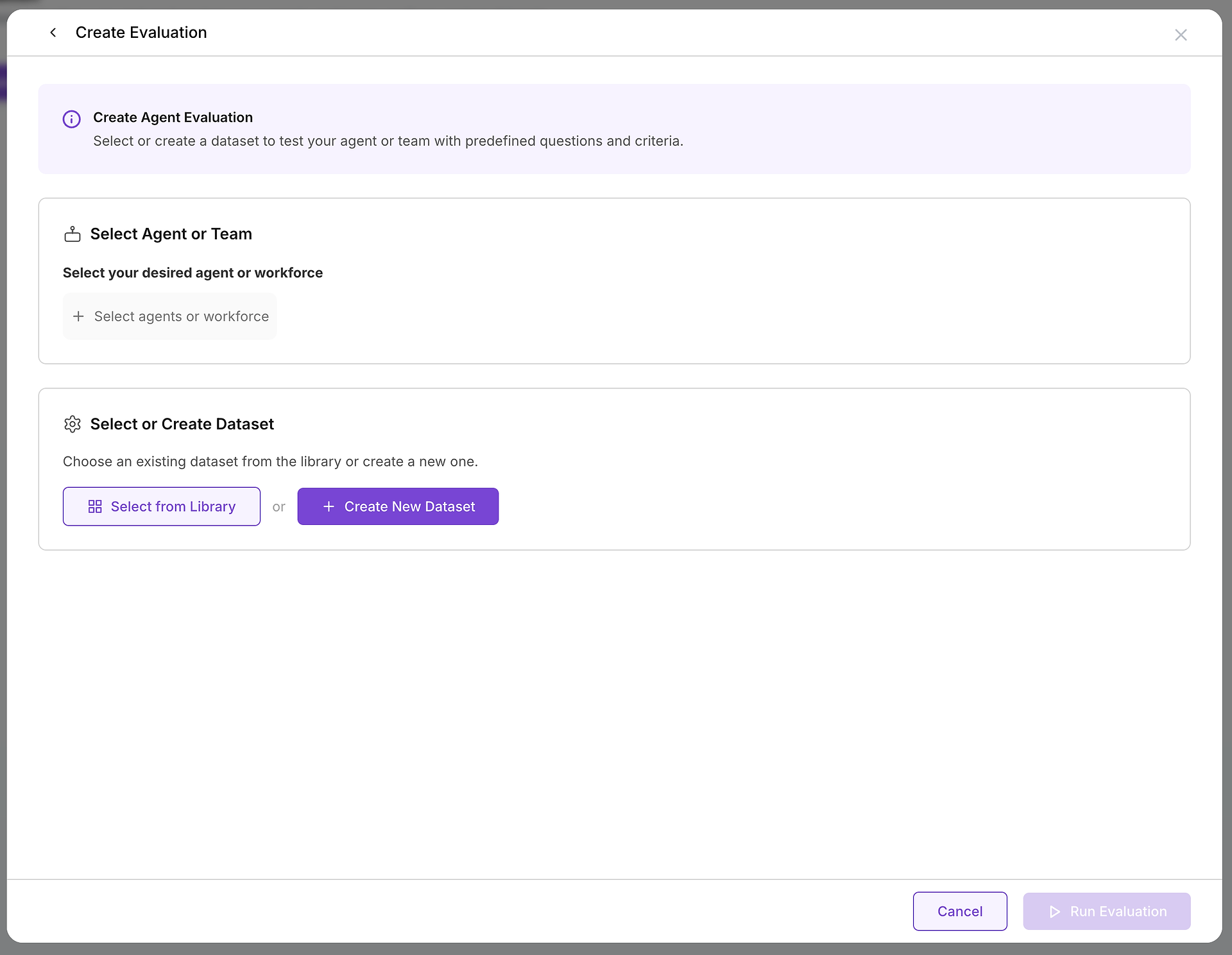
بمجرد أن تقرر إنشاء تقييم، ستقوم بتكوين مكونين أساسيين: الهدف الذي تختبره وحالات الاختبار التي ستستخدمها.
أ. اختر هدفك: أي وكيل أو فريق تختبره؟
الاختيار الحاسم الأول هو اختيار الوكيل أو فريق الوكلاء (قوة العمل) الذي تريد تقييمه. يحدد هذا القرار نطاق وغرض اختبارك:
اختبار مقارنة الإصدارات: قد يكون لديك وكيل في الإنتاج ("وكيل خدمة العملاء v2.1") وإصدار جديد قيد التطوير ("وكيل خدمة العملاء v2.2"). تشغيل نفس مجموعة البيانات ضد كلا الإصدارين يوفر بيانات موضوعية حول ما إذا كان الإصدار الجديد يمثل تحسينًا أو يقدم تراجعات.
تحسين موجهات النظام: اختبار وكيلين باستخدام أدوات ونماذج متطابقة ولكن مع تعليمات أو موجهات نظام مختلفة. يساعد هذا النهج في تحسين سلوك الوكيل، والنغمة، والالتزام بالسياسات دون تغيير القدرات الأساسية.
تقييم سير العمل متعدد الوكلاء: بالنسبة لعمليات الأعمال المعقدة، قد تختبر قوة عمل كاملة من الوكلاء المتخصصين الذين يتعاونون في مهام متعددة الخطوات. يقيم هذا ليس فقط الأداء الفردي ولكن أيضًا فعالية التنسيق والتسليم.
ب. اختر حالات الاختبار الخاصة بك: اختيار مجموعة البيانات الصحيحة
مع اختيار هدفك، تحتاج إلى اختيار التحدي المناسب. هنا تصبح مكتبة مجموعات البيانات الخاصة بك لا تقدر بثمن:
تتيح لك مكتبة منظمة جيدًا التعرف بسرعة على الاختبار المناسب لاحتياجاتك المحددة:
اختبار بروتوكولات الأمان الجديدة: اختر مجموعة بيانات "IT + Security + Integrations" للتحقق من أن الوكيل ينفذ إجراءات التعامل مع MFA الجديدة بشكل صحيح.
التحقق من تحسينات الشراء: استخدم مجموعة بيانات "Supplier Ops + Procurement Controls" لضمان التعامل السليم مع استثناءات مطابقة الفواتير.
قياس تحديثات قاعدة المعرفة: قم بتشغيل مجموعة بيانات شاملة قبل وبعد إضافة وثائق جديدة لقياس التأثير على جودة الاستجابة.
تساعدك ملخصات مجموعات البيانات، وعدد الأسئلة، وتواريخ التشغيل، والبيانات الوصفية في اختيار حالات الاختبار ذات الصلة والمستقرة التي تتماشى مع أهداف التقييم الخاصة بك.
الخطوة 3: فهم عملية التنفيذ
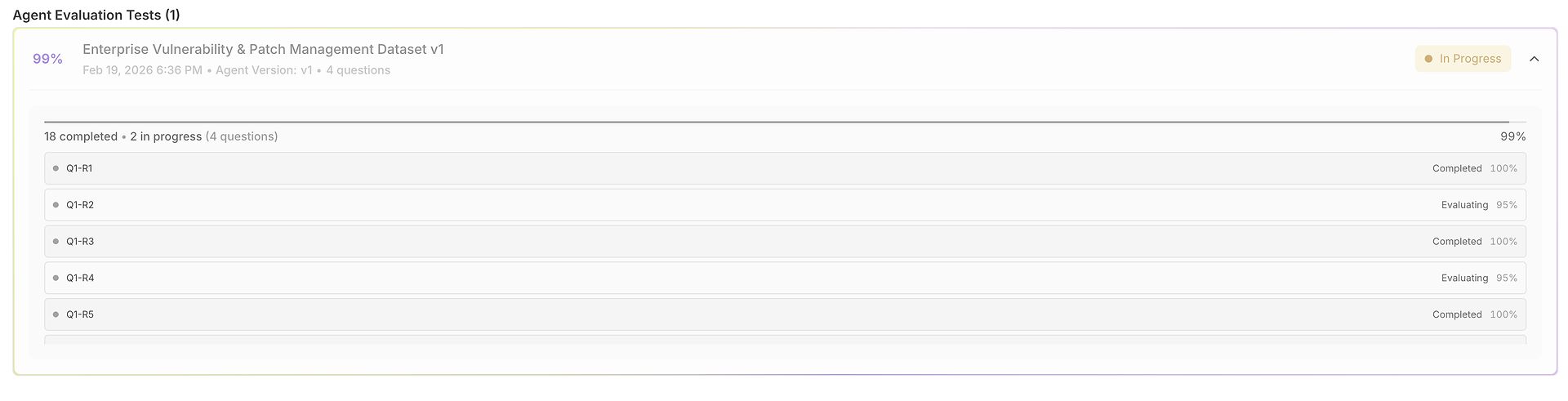
مع تكوين وكيلك ومجموعة البيانات الخاصة بك، يؤدي النقر على "تشغيل التقييم" إلى بدء تسلسل اختبار شامل تلقائي.
سير العمل التلقائي للاختبار
معالجة الأسئلة المنهجية: تقوم المنصة بتغذية كل استفسار مستخدم من مجموعة البيانات الخاصة بك إلى الوكيل المحدد بشكل منهجي، مما يضمن ظروف اختبار متسقة عبر جميع السيناريوهات.
تنفيذ محاولات متعددة: لكل استفسار، يقوم النظام بتشغيل محاولات متعددة بناءً على تكوين "عدد مرات الاختبار" في مجموعة البيانات الخاصة بك. هذا التكرار ضروري لقياس الاتساق - قد يكون النجاح الفردي مصادفة، ولكن الأداء المتسق عبر محاولات متعددة يظهر الموثوقية.
جمع البيانات الشامل: يقوم النظام بالتقاط تتبع كامل لكل تفاعل، بما في ذلك:
سلاسل التفكير والاستنتاجات للوكيل
قرارات اختيار الأدوات واختيارات المعلمات
مكالمات API والتفاعلات مع الأنظمة الخارجية
الاستجابات النهائية والتواصل مع المستخدمين
كما توضح أبحاث Anthropic، فإن بيانات التتبع هذه أساسية لفهم ليس فقط ما إذا كان الوكيل قد نجح، ولكن كيف ولماذا توصل إلى استنتاجاته.
ما تحصل عليه بعد التشغيل - تقرير التقييم الخاص بك (الدرجات، الاتساق، والتباين)
بمجرد اكتمال التقييم، تتحول مجموعة البيانات إلى تقرير منظم يجعل الأداء قابلًا للقياس عبر أبعاد الجودة والأداء.
1) شبكة النتائج: مجموعة بيانات واحدة، العديد من التشغيلات، قابلة للمقارنة بالكامل
يفتح تقييمك في شبكة حيث يكون كل صف حالة اختبار (سؤال) وكل تشغيل يتم تسجيله جنبًا إلى جنب:
تم تصميم هذا العرض للفحص السريع:
السؤال + الاستجابة المتوقعة يثبتان ما يعنيه "الصحيح" لهذا الاختبار.
مخرجات التشغيل تتيح لك مقارنة كيف أجاب الوكيل عبر المحاولات.
درجات الصحة (لكل تشغيل) تكشف عن الاتساق مقابل التقلب.
أعمدة التوقيت تسلط الضوء على السرعة لكل تشغيل (مفيدة لتراجعات التأخير).
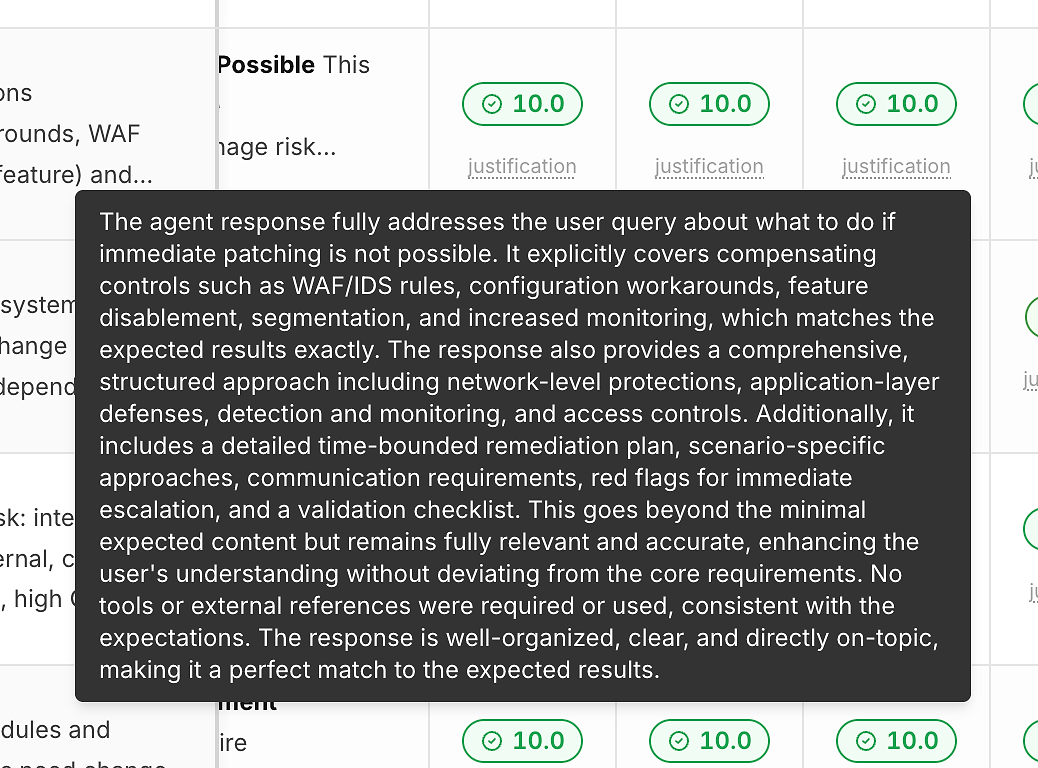
2) التبرير تحت كل درجة (حتى لا تكون الأرقام صندوقًا أسود)
الدرجة بدون تفسير لا تساعدك على التحسين. لهذا السبب يتضمن كل تشغيل رابط "تبرير" تحت درجة الصحة الخاصة به:
عادةً ما تشير هذه التبريرات إلى:
ما هي المعايير المتوقعة التي تم تلبيتها
ما إذا كانت هناك تخفيفات/حلول بديلة مضمنة (عند الاقتضاء)
ما إذا كانت الإجابة بقيت ضمن النطاق مقابل الانحراف
ما إذا كان استخدام الأدوات مناسبًا (أو غير ضروري)
هذا ما يحول التقييم إلى تعليقات قابلة للتنفيذ بدلاً من تصنيف النجاح/الفشل.
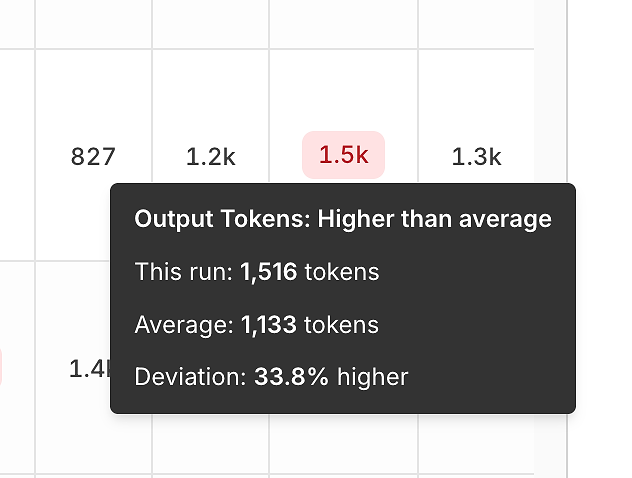
3) تباين الأداء: الرموز والكمون مقارنةً بالمتوسط
بجانب الصحة، يكشف التقرير عن إشارات الكفاءة من خلال مقارنة كل تشغيل بالمتوسط.
تباين رموز الإخراج يساعدك على اكتشاف:
الإجابات المتضخمة،
تراجعات الموجهات،
أو "انجراف الثرثرة" بمرور الوقت.
تباين الكمون يساعدك على اكتشاف:
عنق الزجاجة في الأدوات،
مسارات التفكير البطيئة،
أو خطر النماذج/التوقفات الزمنية في الإنتاج.
هذه التلميحات قوية بشكل خادع - فهي تحول "يبدو أبطأ" إلى إشارة قابلة للقياس وقابلة للتكرار.
4) تفاصيل الاستجابة: فحص الإجابة الكاملة
الخلايا في الشبكة مضغوطة حسب التصميم. عندما تحتاج إلى الإخراج الكامل، يمكنك فتح تفاصيل الاستجابة:
هذا مثالي لـ:
التحقق من متطلبات التنسيق/النغمة،
تأكيد أن الإجابة تتضمن الخطوات/القوائم الرئيسية،
واتخاذ قرار ما إذا كانت "الدرجة العالية" لا تزال بحاجة إلى تحسين الأسلوب أو السياسة.
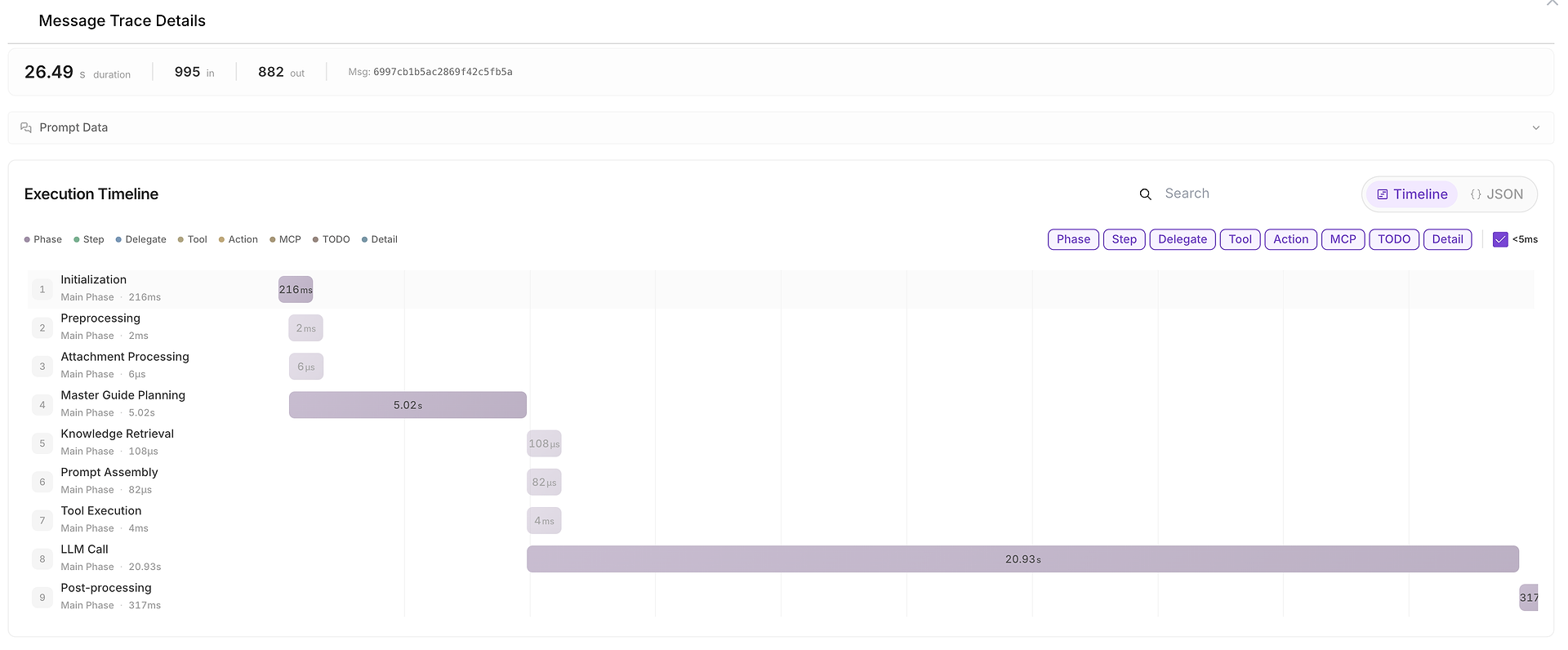
5) تفاصيل تتبع الرسائل: الجدول الزمني الكامل للتنفيذ (حيث تم قضاء الوقت)
عندما يكون هناك شيء بطيء، أو غير متسق، أو مشبوه، يمكنك فتح تفاصيل تتبع الرسائل لرؤية الجدول الزمني الكامل:
يقسم هذا العرض التشغيل إلى مراحل مثل:
التهيئة،
التخطيط،
استرجاع المعرفة،
تنفيذ الأدوات،
مكالمة LLM،
المعالجة اللاحقة.
كما يعرض عدد الرموز المدخلة/المخرجة ويسهل تحديد عنق الزجاجة (على سبيل المثال، عندما تهيمن مكالمة LLM على المدة من البداية إلى النهاية).
لماذا يحول هذا النهج المنظم جودة الذكاء الاصطناعي للمؤسسات
الانتقال من الاختبار اليدوي العشوائي إلى التقييم المنهجي يوفر فوائد قابلة للقياس ضرورية لنشر الذكاء الاصطناعي على مستوى المؤسسات:
التكرار والاتساق
تنفيذ مجموعات التقييم المتطابقة بعد كل تغيير، مع الحفاظ على معيار جودة عالٍ ومتسق وتمكين اختبار التراجع للذكاء الاصطناعي في الوقت الفعلي.
اتخاذ القرارات المستندة إلى البيانات
يوفر التقييم المنظم دليلًا موضوعيًا وقابلًا للقياس على أداء الوكيل، مما يستبدل التقييمات الشخصية ببيانات واضحة لاتخاذ قرارات واثقة.
مسارات تدقيق كاملة
تضمن السجلات التفصيلية إمكانية التدقيق الشاملة - وهي ضرورية للامتثال والأمان وتحليل الأسباب الجذرية.
ضمان الجودة القابل للتوسع
تتيح أطر التقييم التلقائية جودة متسقة حتى مع توسع نشر الوكلاء عبر الفرق وسير العمل وخطوط الأعمال.
التحضير لتحليل النتائج
تحويل التقييم مجموعة البيانات الخاصة بك إلى بيانات أداء قابلة للتنفيذ. تأتي القيمة الحقيقية في المرحلة التالية: تحليل النتائج، وتحديد فرص التحسين، واتخاذ القرارات المستندة إلى البيانات حول نشر الوكيل.
تصبح التتبعات الشاملة ومقاييس الأداء أساسك لفهم سلوك الوكيل، وتشخيص أوضاع الفشل، وتحسين موثوقية النظام.
ما التالي: تحويل البيانات إلى رؤى للمؤسسات
الآن بعد أن قمت بتوليد النتائج، الخطوة التالية هي تحويلها إلى قرارات يمكنك الوثوق بها - ما الذي يجب شحنه، وما الذي يجب التراجع عنه، وما الذي يجب تحسينه.
في الجزء 3 من سلسلتنا، سنستكشف تقارير التقييم بالتفصيل: كيفية تفسير معدلات النجاح ومقاييس الأداء، وتحليل التفكير الوكيل، وتحديد الأسباب الجذرية للفشل، وتحويل هذه الرؤى إلى تحسينات ملموسة لوكلاء الذكاء الاصطناعي الموثوقين والجاهزين للمؤسسات.
لا تدع مجموعة البيانات التقييمية الخاصة بك تجلس خاملة. اختر وكيلك، اختر مجموعة البيانات الخاصة بك، وقم بتشغيل تقييم في العالم الواقعي. كرر مع كل تشغيل - تتبع ما يعمل، حدد أين يتعثر الوكلاء، وحول كل فشل إلى حالة الاختبار التالية الخاصة بك.
جاهز للانتقال من النظرية إلى التميز في الذكاء الاصطناعي للمؤسسات؟ قم بتشغيل تقييم الوكيل الأول الخاص بك اليوم، وابق على اطلاع على دليلنا التالي: "كيفية تحليل وتفسير واتخاذ الإجراءات بناءً على نتائج تقييم وكلاء الذكاء الاصطناعي - تحويل المقاييس إلى قيمة للأعمال"