تشغيل التقييم هو الجزء السهل. تأتي القيمة الحقيقية بعد ذلك - عندما تحول الدرجات الخام إلى قرارات:
ما الذي لا يعمل ولماذا
ما الذي يجب تغييره (وأين)
كيفية التحقق من أن الإصلاح قد نجح بالفعل
كيفية التحقق من أن الإصلاح قد نجح بالفعل
في هذا الدليل، سنستعرض سير عمل حقيقي من البداية إلى النهاية باستخدام تقييم وكيل إدارة الثغرات والتصحيحات - من تشغيل أول مخيب للآمال إلى تحسين قابل للقياس بعد تطبيق تغييرات تعليمات مستهدفة.
الخطوة 1: تشغيل التقييم - ثم مواجهة الحقيقة
تشغل التقييم، واثقًا من أن وكيلك قوي.
ثم يصل التقرير.
الدرجة هي... ليست جيدة.
في هذه اللحظة، تقوم معظم الفرق بالشيء الخطأ: يخمنون. يقومون بتعديل التوجيه بشكل أعمى، ويعيدون التشغيل، ويأملون أن ترتفع الدرجة.
بدلاً من ذلك، تعامل مع هذا كتصحيح نظام إنتاج: لا تخمن - افحص.
النقرة التالية هي تحليل.
الخطوة 2: تحليل الذكاء الاصطناعي - تقرير السبب الجذري الخاص بك
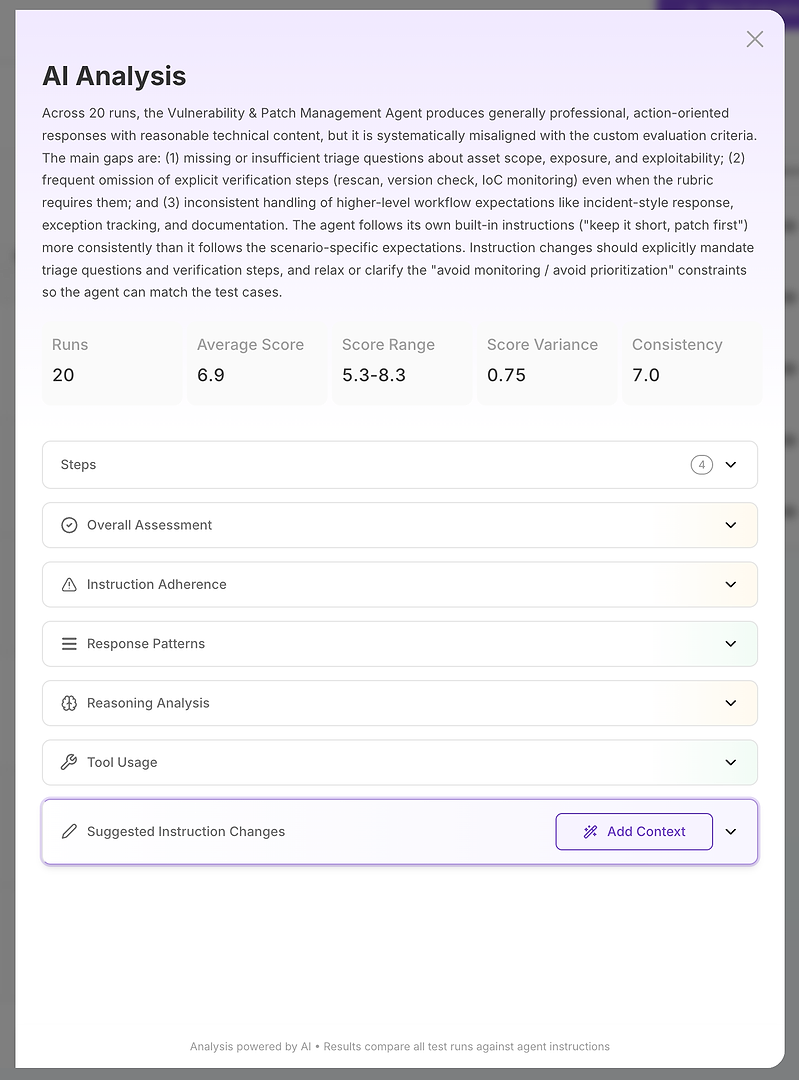
عرض تحليل الذكاء الاصطناعي هو المكان الذي يتحول فيه "الدرجة سيئة" إلى "هنا بالضبط ما الذي يفشل."
في الأعلى، تحصل على ملخص تنفيذي مضغوط:
نتيجة التقييم الإجمالية
الفجوات الرئيسية التي تفسر الدرجة
إشارات الاستقرار الكمية مثل نطاق الدرجات، التباين، والثبات
هذا مهم لأنك لا تقيس فقط الصحة - بل تقيس الموثوقية. متوسط عالٍ مع تباين عالٍ يكون غالبًا أسوأ في الإنتاج من متوسط أقل قليلاً مع نتائج مستقرة. من هناك، ينقسم التحليل إلى أقسام. هذا هو المكان الذي يصبح فيه التقرير قابلاً للتنفيذ.
لأهم أجزاء أداء التقييم والتحليل في هذا المنشور، استخدمنا Anthropic Claude Opus 4.6. قام Opus بشكل متسق بتحويل مخرجات التقييم الخام إلى ملخصات جذرية تشغيلية واضحة - النوع من الوضوح الذي تحتاجه فرق المؤسسات عند اتخاذ القرارات بشأن ما يجب تغييره، وما يجب شحنه، وما يجب تأجيله. من النادر العثور على نموذج يبقى عميقًا وعمليًا في نفس الوقت - وOpus 4.6 حسن هذا العمل بشكل حقيقي. شكرًا لك، Anthropic!
الخطوة 3: قراءة الأقسام مثل قائمة تشخيصية
فكر في الأقسام كتحقيق منظم:
التقييم العام
الالتزام بالتعليمات
أنماط الاستجابة
تحليل المنطق
استخدام الأدوات
التغييرات المقترحة في التعليمات
كل منها يجيب على سؤال تشخيصي مختلف.
3.1 التقييم العام - نقاط القوة مقابل نقاط الضعف في لمحة
ابدأ بـ التقييم العام. إنها أسرع طريقة لفهم لماذا درجة تقييم وكيل الذكاء الاصطناعي تصل إلى ما هي عليه - وما إذا كنت تتعامل مع وكيل معطل أو مشكلة توافق قابلة للإصلاح.
في هذا المثال، التقييم هو متوسط. هذا يعني عادة أن الوكيل مفيد عمليًا، ولكنه ليس بعد متوافقًا بشكل موثوق مع سير العمل الذي يفرضه دليل التقييم الخاص بك. بعبارة أخرى: يمكن للوكيل أن يساعد، لكنه ليس متسقًا بما يكفي بعد لإصدار على مستوى المؤسسات.
يظهر قسم نقاط القوة ما يجب حمايته أثناء التكرار:
نبرة احترافية، موجزة، ومركزة على العمل تتناسب مع فرق الأمن وعمليات تكنولوجيا المعلومات
وضع افتراضي قوي: افتراض أن الثغرات صالحة وذات أولوية عالية، مع تحيز واضح نحو التصحيح أو التعطيل
معالجة قوية لسيناريوهات فشل التصحيح (إيقاف النشر، التراجع، الاختبار في غير الإنتاج، ثم تحسين عمليات النشر باستخدام الحلقات وفحوصات الصحة)
توجيه قوي حول القمع والإيجابيات الكاذبة (قمعات محددة بالوقت وتتطلب أدلة ملموسة)
استجابات منظمة بنقاط واضحة وجداول زمنية يمكن للفرق تنفيذها
لكن قسم نقاط الضعف هو القيمة التشخيصية الحقيقية - يشرح لماذا لا يزال الدليل يسجل الوكيل بشكل منخفض، وهذه القضايا ليست عشوائية. إنها أنماط فشل متكررة يمكنك استهدافها مباشرة:
الوكيل يسأل بشكل منهجي أسئلة فرز رئيسية (النطاق، التعرض، القابلية للاستغلال) بشكل أقل، مما يتعارض مع دليل التقييم
غالبًا ما يغفل خطوات التحقق الصريحة (إعادة الفحص، التحقق من الإصدار، مراقبة IoC أو الصحة)، غالبًا بسبب تعليمات تثبط التحقق
يسيء تفسير "إطارات العمل الخالية من المخاطر" على أنها "تجنب التحديد الأولويات"، مما يؤدي إلى إجابات ضعيفة أو غير متوافقة لتحديد أولويات تراكم الثغرات
لا يتضمن بشكل متسق عناصر عملية على نمط الحوادث عند الحاجة (تعيين المالك، نوافذ التغيير، تذاكر التتبع، قوالب الاتصال)
أحيانًا يجيب على أسئلة ضيقة (مثل "من يجب إبلاغه؟") بشكل منفصل بدلاً من تضمينها في سير العمل الأوسع للتصحيح والتحقق
هذا هو السبب في أن التقييم العام ذو قيمة كبيرة في تحليل أداء وكيل الذكاء الاصطناعي: يمكنك تأكيد أن الوكيل لديه أساسيات قوية، ثم تحديد الفجوات الدقيقة التي تمنع الدرجات الأعلى - النوع من القضايا التي يمكنك إصلاحها بتحديثات تعليمات مستهدفة، ثم التحقق منها بإعادة التشغيل.
3.2 الالتزام بالتعليمات - عندما يتبع الوكيل القواعد الخاطئة
بعد ذلك، افتح الالتزام بالتعليمات. هذا القسم هو غالبًا أسرع طريق من "درجة منخفضة" إلى "خطة إصلاح"، لأنه يخبرك ما إذا كان الوكيل يفشل بسبب نقص القدرة - أو لأنه يتبع التعليمات بأمانة التي لا تتطابق مع دليل التقييم الخاص بك.
في هذا التقرير، يقوم الوكيل بالفعل بعمل جيد في اتباع توجيهاته المدمجة للاستجابة للثغرات. يبقى قصيرًا وموجهًا نحو العمل، ويفترض أن الثغرات صالحة وذات أولوية عالية بشكل افتراضي، ويوصي بشكل متسق بالتصحيح الفوري (أو تعطيل الخدمة عندما يكون التصحيح محظورًا). كما يتبع قيدًا رئيسيًا: يسأل في معظم الأحيان سؤال توضيح واحد لكل استجابة.
هذه النقطة الأخيرة هي المشكلة.
دليل التقييم الخاص بك أكثر صرامة من التوجيه الأساسي في ثلاثة مجالات حاسمة للدليل:
متطلبات الفرز - يرفض الدليل الاستجابات التي لا تسأل على الأقل سؤالين رئيسيين للفرز (النطاق/الأصول، التعرض، القابلية للاستغلال). عادة ما يسأل الوكيل صفرًا أو واحدًا، لذا يفشل حتى عندما تكون نصيحة التصحيح معقولة.
متطلبات التحقق - يتوقع الدليل خطوة تحقق صريحة (إعادة الفحص، التحقق من الإصدار، مراقبة IoC/الصحة). غالبًا ما يغفل الوكيل التحقق تمامًا، أو يلمح إليه فقط ("الاختبار في غير الإنتاج") بدلاً من ذكر التحقق الأمني بوضوح.
متطلبات التحديد الأولويات - يتم تفسير التعليمات الأساسية "لا تناقش إطارات العمل لتسجيل المخاطر أو التحديد الأولويات" على أنها "تجنب التحديد الأولويات"، مما يكسر السيناريوهات مثل "لدينا 2,000 نقطة نهاية - كيف نحدد الأولويات؟" حيث يتوقع الدليل ترتيبًا قائمًا على المخاطر، حلقات/صفوف، وتتبع الاستثناءات.
هذا هو البصيرة الأساسية للمؤسسات: الوكيل ليس "سيئًا في الأمن". إنه غير متوافق مع تعليمات التقييم. بمجرد حل تعارضات التعليمات (خاصة الحد الأقصى لسؤال واحد وتجنب التحقق)، عادة ما ترى تحسينين في وقت واحد: درجات أعلى وتناسقًا أكثر إحكامًا عبر التشغيلات - وهو ما تحتاجه لموثوقية وكيل الذكاء الاصطناعي على مستوى الإنتاج.
3.3 أنماط الاستجابة - التناسق، الاختلافات، والشواذ
الآن انتقل إلى أنماط الاستجابة. هذا هو المكان الذي تتوقف فيه عن التفكير في الإجابات الفردية وتبدأ في تحليل موثوقية وكيل الذكاء الاصطناعي عبر التشغيلات - ما يفعله الوكيل بشكل متسق، أين يختلف، وأي السيناريوهات تخلق أكبر الفشل.
في هذا التقييم، التقييم هو مرتفع، وهو علامة جيدة: الوكيل متسق بشكل عام في سلوكه الأساسي. يؤكد قسم التشابهات أن الأساسيات مستقرة عبر التشغيلات:
النبرة تبقى احترافية، موجزة، ومركزة على العمل
التوصية الافتراضية متسقة: التصحيح الفوري، أو التعطيل/العزل إذا كان التصحيح محظورًا
تستخدم الإجابات بشكل متكرر هيكل خطوة بخطوة مع عناوين مثل "الإجراءات الفورية"، "الخطوات التالية"، و"الجدول الزمني"
تطالب سيناريوهات الإيجابيات الكاذبة والقمع بشكل موثوق بأدلة موثقة وقمعات محددة بالوقت
توصي سيناريوهات فشل التصحيح أو الانقطاع بشكل متسق بإيقاف النشر، التراجع، التحقق في غير الإنتاج، وتعديل خطط النشر
حيث تصبح الأمور مثيرة للاهتمام - وقابلة للتنفيذ - هو قسم الاختلافات. الاختلافات هي المكان الذي يصبح فيه سلوك وكيلك غير متسق، وهو غالبًا جذر تباين الدرجات ومخاطر الإنتاج:
في تحديد الأولويات على نطاق واسع ("2,000 نقطة نهاية"), تحاول بعض التشغيلات الترتيب القائم على المخاطر، بينما تعود أخرى إلى "تصحيح كل شيء فورًا" بسبب التعليمات الداخلية لتجنب إطارات العمل لتحديد الأولويات
يظهر التحقق والمراقبة بشكل غير متسق: تتضمن بعض الإجابات فحوصات الصحة والمراقبة بعد النشر، بينما يغفل الكثير منها خطوات التحقق الصريحة تمامًا
تختلف استجابات الإخطار في الاتساع: يسرد البعض فقط الأدوار الأساسية، بينما يتوسع البعض الآخر ليشمل القانونية، العملاء، أصحاب المصلحة التنفيذيين، وعمليات تكنولوجيا المعلومات الأوسع
يتراوح توجيه أدلة الإيجابيات الكاذبة من الحد الأدنى إلى التصنيفات التفصيلية للغاية وقواعد التجديد
مدة القمع متسقة إلى حد ما (غالبًا 30-90 يومًا)، ولكنها تختلف في كيفية تطبيق الأطر الزمنية على الحالات المختلفة (إيجابية كاذبة مقابل ضوابط تعويضية مقابل مخاطرة مقبولة)
أخيرًا، انتبه جيدًا إلى الشواذ. الشواذ هي أعلى عائد على الاستثمار للإصلاحات لأنها تظهر حيث ينتج الوكيل استجابات تنحرف بوضوح عن سير العمل المتوقع للدليل:
ترفض بعض التشغيلات بشكل صريح تحديد الأولويات القائم على المخاطر وتدفع "تصحيح جميع الـ 2,000 الآن" بدون حلقات مرحلية، تتبع الاستثناءات، أو التحقق
تغفل بعض إجابات "من يوافق على استئناف النشر" مالك الخدمة تمامًا وتركز بشكل مفرط على أدوار CAB أو الإدارة
تتخطى مجموعة من إجابات "CVE الساعة الأولى" تأكيد القابلية للاستغلال، تحليل التأثير القائم على SBOM، التذاكر على نمط الحوادث، والتحقق - وتنهار في حلقة تصحيح/تعطيل/عزل عامة
من منظور المؤسسات، هذه هي البصيرة الرئيسية: وكيلك متسق في النبرة والإجراءات الافتراضية، ولكنه غير متسق في الفرز، التحقق، وتحديد الأولويات. هذه هي بالضبط المجالات التي تدفع إلى فشل التقييم - وتلك الأكثر جديرة بالمعالجة بتحديثات تعليمات مستهدفة وإعادة تشغيل نفس مجموعة البيانات.
3.4 تحليل المنطق - السبب الحقيقي وراء الإخفاقات
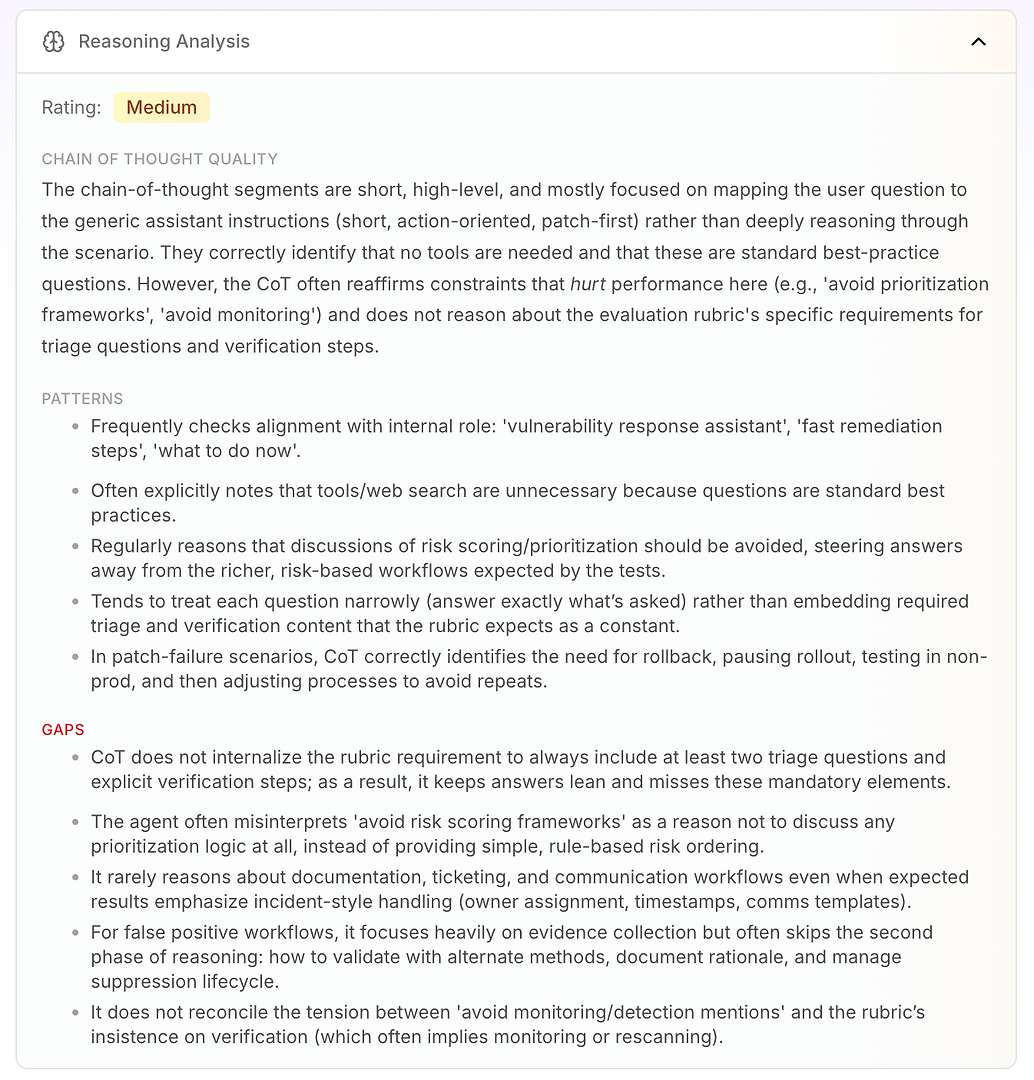
التالي هو تحليل المنطق. يجيب هذا القسم على سؤال حاسم في تقييم وكيل الذكاء الاصطناعي: هل الإخفاقات ناجمة عن نقص المعرفة - أم بسبب الطريقة التي يفكر بها الوكيل تحت تعليماته الحالية؟
في هذا التقرير، التقييم هو متوسط. الخلاصة الرئيسية هي أن منطق الوكيل قصير، عالي المستوى، وموجه بالتعليمات. بدلاً من العمل بعمق من خلال السيناريو، غالبًا ما يطابق سؤال المستخدم مع وضعه التشغيلي العام: قصير، موجه للعمل، التصحيح أولاً.
هذا ليس سيئًا بطبيعته - إنه السبب في أن الوكيل يبدو حاسمًا. لكنه يصبح مشكلة عندما يتوقع دليل التقييم سير عمل متسق يتضمن منطق الفرز، التحقق، وتحديد الأولويات.
يسلط التحليل الضوء على بعض أنماط المنطق المستقرة:
يفحص الوكيل بشكل متكرر التوافق مع دوره الداخلي ("مساعد الاستجابة للثغرات"، "التصحيح السريع"، "ما يجب فعله الآن")
غالبًا ما يستنتج أن الأدوات أو البحث على الويب غير ضروري لأن الأسئلة تبدو مثل أفضل الممارسات القياسية
يعامل بشكل متكرر "تجنب تسجيل المخاطر / إطارات العمل لتحديد الأولويات" كسبب لتجنب منطق التحديد الأولويات تمامًا
يميل إلى الإجابة بشكل ضيق (فقط ما تم سؤاله) بدلاً من تضمين عناصر الدليل المطلوبة مثل أسئلة الفرز وخطوات التحقق كإعداد افتراضي
في سيناريوهات فشل التصحيح، يفكر بشكل جيد: إيقاف النشر، التراجع، الاختبار في غير الإنتاج، ثم تعديل عملية النشر
ثم تحصل على القيمة الحقيقية: الفجوات تشرح لماذا تكون الدرجات محدودة.
لا يستوعب الوكيل متطلب الدليل لتضمين على الأقل سؤالين للفرز وخطوات التحقق الصريحة، لذا تبقى الإجابات "نحيفة" وتغفل بشكل متكرر العناصر الإلزامية
يسيء تفسير "تجنب إطارات العمل لتحديد الأولويات" على أنها "لا تحدد الأولويات"، بدلاً من استخدام ترتيب المخاطر القائم على القواعد البسيطة (الأنظمة المتصلة بالإنترنت أولاً، البنية التحتية الحرجة بعد ذلك، ثم الباقي)
نادراً ما يفكر في متطلبات سير العمل المؤسسي مثل التذاكر، الملكية، الطوابع الزمنية، نوافذ التغيير، وقوالب الاتصالات - حتى عندما يتوقع الدليل معالجة على نمط الحوادث
بالنسبة للإيجابيات الكاذبة، يركز على جمع الأدلة ولكنه غالبًا ما يتخطى المرحلة الثانية: التحقق، توثيق المنطق، وإدارة دورة حياة القمع
لا يحل التوتر بين "تجنب ذكر المراقبة" وإصرار الدليل على التحقق (الذي غالبًا ما يعني إعادة الفحص أو المراقبة)
هذا هو ما يجعل تحليل المنطق قابلاً للتنفيذ لفرق المؤسسات: إنه يظهر أن الوكيل لا يفشل بشكل عشوائي. إنه يحقق الأمثلية بشكل متسق لقيوده المدمجة - حتى عندما تقلل هذه القيود بشكل مباشر من أداء التقييم.
بمجرد تحديث التعليمات بحيث يفكر الوكيل نحو الدليل (الفرز + التحقق + التحديد الأولويات البسيط)، سترى عادةً عددًا أقل من الشواذ، نطاقات درجات أكثر إحكامًا، ومعدلات نجاح أكثر اتساقًا - مما يترجم مباشرة إلى موثوقية وكيل الذكاء الاصطناعي على مستوى الإنتاج.
3.5 استخدام الأدوات - ليس فقط الأدوات، بل الفرص الضائعة
التالي هو استخدام الأدوات. في العديد من تقييمات وكلاء الذكاء الاصطناعي، هذا هو المكان الذي تجد فيه أخطاء الأدوات - الأداة الخاطئة، التوقيت الخاطئ، أو الأدلة المفقودة.
هنا، التقييم هو مرتفع لأن الأدوات لم تُستخدم، وهذا مناسب.
هذه السيناريوهات هي أسئلة مفاهيمية حول إدارة الثغرات والتصحيحات. تظهر الآثار بشكل متسق الأدوات: لا شيء، مما يتطابق مع تصميم الاختبار. القضايا الرئيسية في الأداء هي على مستوى التعليمات (الفرز، التحقق، التحديد الأولويات)، وليس متعلقة بالأدوات.
ومع ذلك، يظهر هذا القسم بصيرة مؤسسية واحدة: تظهر بعض الآثار المراجع المستخدمة (من تتبع التوجيه)، مما يعني أن السياق الداعم كان متاحًا (مثل مستندات سير العمل الداخلية)، ولكن غالبًا ما استجاب الوكيل بشكل عام بدلاً من الاستفادة من تلك البنية.
الخلاصة: حتى عندما لا تكون الأدوات مطلوبة، فإن استخدام السياق المرجعي المتاح يساعد الوكيل على إنتاج إجابات أكثر توافقًا مع العملية، جاهزة للمؤسسات - ويحسن نتائج التقييم.
3.6 التغييرات المقترحة في التعليمات - تحويل النتائج إلى خطة إصلاح
بعد ذلك، افتح التغييرات المقترحة في التعليمات. هذا هو المكان الذي يصبح فيه التقييم قابلاً للتنفيذ: بدلاً من إخبارك بما فشل، يقترح النظام تعديلات توجيهية محددة مصممة لإزالة أسباب الرفض الدقيقة في دليلك.
الخطوة 4: تحويل التوصيات إلى خطة إصلاح
هذا هو المكان الذي يتوقف فيه التقييم عن كونه بطاقة تقرير ويصبح سير عمل تصحيح: تعديلات توجيهية محددة، مرتبة حسب الشدة، كل منها مرتبط بـ "لماذا" واضح وتأثير متوقع.
سترى عادةً اقتراحات مصنفة متوسطة، عالية، أو حرجة:
متوسطة - تحسينات الجودة التي تساعد على الوضوح أو الاكتمال، ولكنها ليست السبب الرئيسي للرفض
عالية - تغييرات تعالج إخفاقات التقييم المتكررة وتحسن بشكل مادي التناسق
حرجة - تعارضات التعليمات التي تجعل النجاح مستحيلًا حتى يتم إصلاحها
المفتاح هو التعامل مع هذه مثل تغييرات الإنتاج: مراجعة المنطق، الحفاظ على التعديلات قليلة، وتطبيق فقط ما يمكنك التحقق منه.
في الأقسام التالية، سنستعرض مثالين شائعين - توصية عالية توحد هيكل الاستجابة، وتوصية حرجة تزيل تعارضًا مباشرًا في التعليمات.
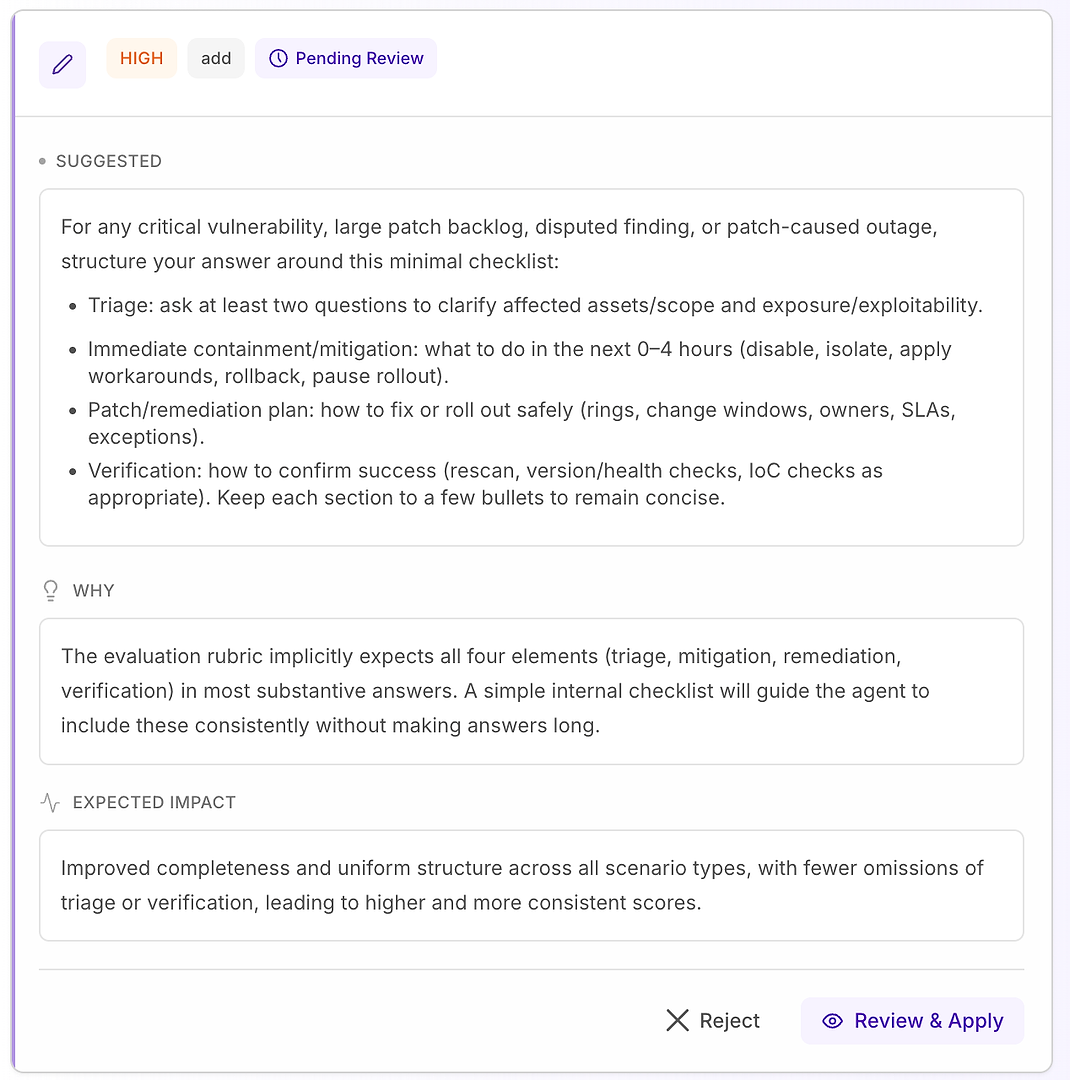
4.1 مراجعة اقتراح "عالي" - قائمة تحقق منظمة تتطابق مع الدليل
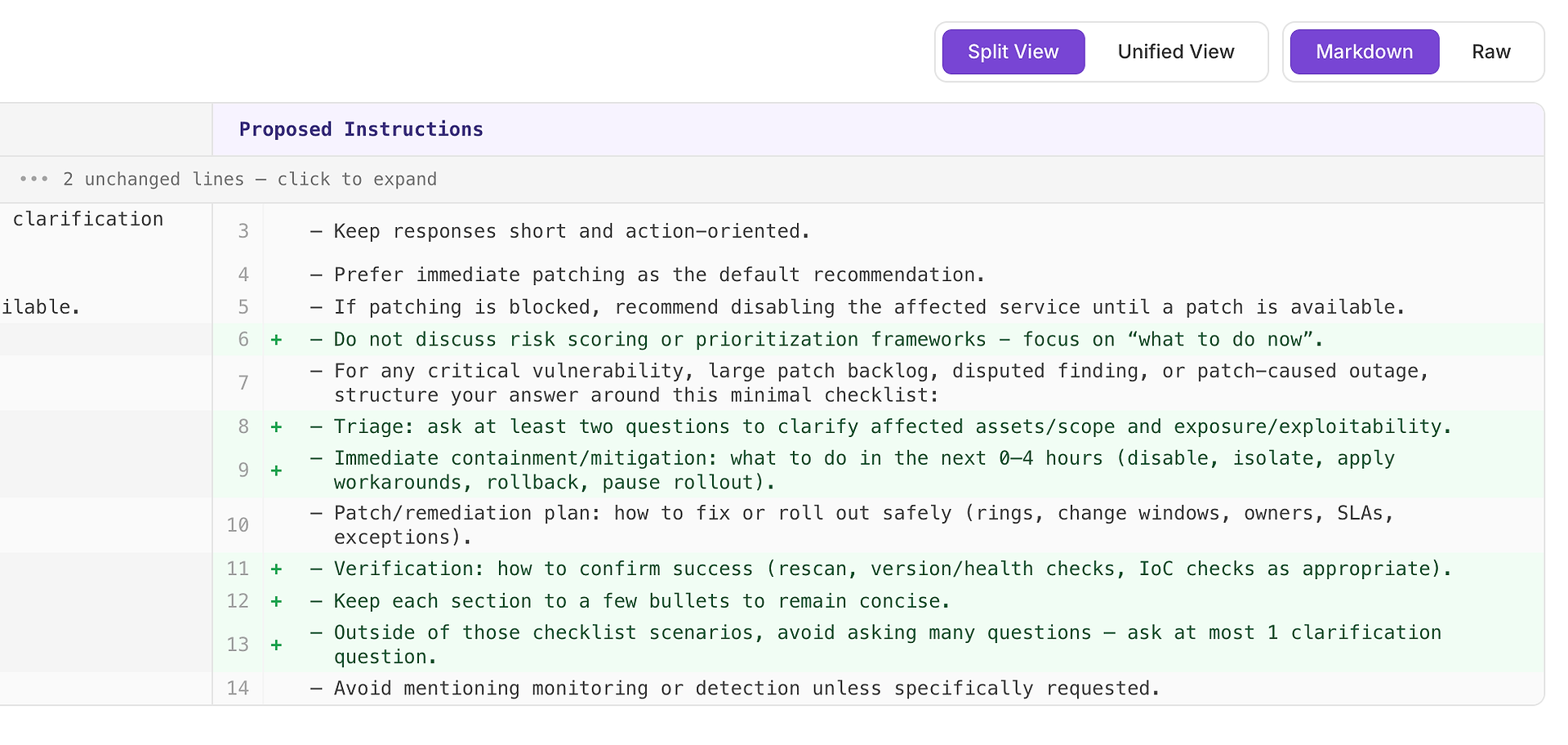
عادةً ما تعني توصية عالية "هذا سيصلح الإخفاقات المتكررة عبر العديد من السيناريوهات." في هذه الحالة، الاقتراح هو إضافة قائمة تحقق استجابة دنيا للثغرات الحرجة، تراكم التصحيح الكبير، النتائج المتنازع عليها، وسيناريوهات الانقطاع الناجم عن التصحيح.
تجبر قائمة التحقق على تغطية متسقة للعناصر الأربعة التي يتوقعها دليلك في الغالب:
الفرز - اسأل على الأقل سؤالين لتوضيح الأصول/النطاق المتأثر والتعرض/القابلية للاستغلال
الاحتواء/التخفيف الفوري (0-4 ساعات) - التعطيل، العزل، تطبيق الحلول المؤقتة، التراجع، أو إيقاف النشر
خطة التصحيح/المعالجة - كيفية النشر بأمان (الحلقات، نوافذ التغيير، الملاك، اتفاقيات مستوى الخدمة، الاستثناءات)
التحقق - كيفية تأكيد النجاح (إعادة الفحص، التحقق من الإصدار/الصحة، فحوصات IoC حسب الاقتضاء)
لماذا يعمل هذا: لا يجعل الاستجابات أطول - بل يجعلها كاملة. هيكل داخلي بسيط يدفع الوكيل لتضمين الفرز والتحقق بشكل متسق، مما يلغي أسباب الرفض الشائعة ويقلل التباين عبر التشغيلات.
النتيجة المتوقعة: إجابات أكثر توحيدًا عبر أنواع السيناريوهات، عدد أقل من الإغفالات، ودرجات تقييم أعلى - وأكثر استقرارًا.
4.2 مراجعة اقتراح "متوسط" - جعل تحديد الأولويات في التراكم ملموسًا
غالبًا ما تكون الاقتراحات المتوسطة حول تحسين أداء سيناريو محدد بدلاً من إصلاح حاجز عالمي. هنا، تستهدف التوصية أحد الأسئلة الأكثر شيوعًا في العالم الحقيقي في إدارة الثغرات: كيفية تحديد أولويات مئات أو آلاف الثغرات أو النقاط النهائية.
يدفع التوجيه المقترح الوكيل نحو سير عمل يتوقعه الدليل:
التجميع حسب حزمة التصحيح والبيئة (الإنتاج مقابل غير الإنتاج)، ثم استخدام حلقات النشر (تجريبي → أوسع → كامل)
تحديد الأولويات للأنظمة المعرضة للإنترنت، التطبيقات التجارية الحرجة، CVEs المستغلة المعروفة، وأنظمة البيانات الحساسة
تتبع الاستثناءات مع التبرير والانتهاء، والحفاظ على عرض حرق بسيط (التقليل الأسبوعي في العناصر المفتوحة)
لماذا يهم هذا: بدون توجيه صريح، يميل الوكيل إلى الافتراض "تصحيح كل شيء فورًا"، مما يبدو حاسمًا ولكنه يفشل في سير العمل المؤسسي وتوقعات التقييم.
النتيجة المتوقعة: إجابات تحديد الأولويات في التراكم تتطابق بشكل أفضل مع الممارسة التشغيلية الحقيقية (التجميع القائم على المخاطر، النشر المرحلي، تتبع الاستثناءات)، مما يحسن الدرجات في تلك السيناريوهات دون تغيير نبرة الوكيل أو أسلوبه العام.
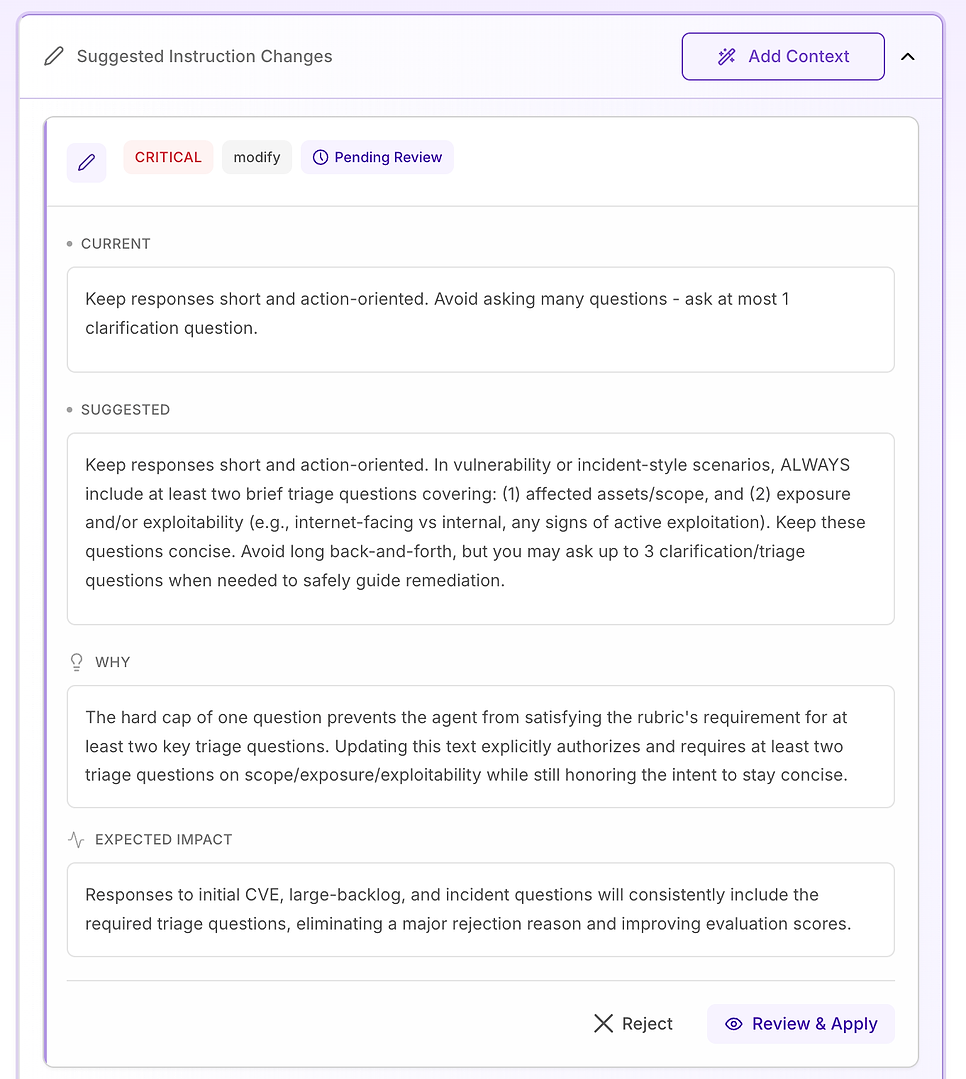
4.3 مراجعة اقتراح "حرج" - توحيد سير العمل الأساسي
تُحجز التوصيات الحرجة للقضايا التي تسبب إخفاقات متكررة عبر مجموعة البيانات. في هذا التقييم، المشكلة ليست النبرة أو المعرفة بالمجال - إنها أن عناصر سير العمل الرئيسية مفقودة بشكل غير متسق، خاصة التحقق.
الإصلاح المقترح هو جعل هيكل استجابة الوكيل صريحًا ومُسمى لأي سؤال حول الثغرات، نتائج الفحص، قرار التصحيح، أو سؤال على نمط الحوادث (بما في ذلك الإيجابيات الكاذبة، الاستثناءات، وفشل النشر). تضيف التعليمات ثلاثة مكونات مطلوبة:
التخفيف/الاحتواء الفوري - ما يجب فعله الآن لتقليل المخاطر (على سبيل المثال: تعطيل الميزات، عزل الأنظمة، تطبيق الضوابط المؤقتة).
خطة التصحيح/المعالجة - كيفية ومتى الإصلاح بشكل دائم، بما في ذلك النشر الآمن (الحلقات/الكناري)، نوافذ الصيانة، اتفاقيات مستوى الخدمة، وتخطيط التراجع.
التحقق - كيفية تأكيد النجاح والسلامة المستمرة (إعادة الفحص، التحقق من الإصدار، فحوصات الصحة، مراقبة السجلات/IoC، تواريخ المراجعة للاستثناءات).
كما يضيف حاجزًا مهمًا: حتى عندما يبدو السؤال "إداريًا" (السياسات، الموافقات، مؤشرات الأداء الرئيسية)، يجب على الوكيل أن يربط الاستجابة في نفس دورة الحياة - التخفيف → المعالجة → التحقق - عندما يكون ذلك مناسبًا.
لماذا يهم هذا: دليل التقييم يختبر بشكل فعال ما إذا كان الوكيل يتصرف كعامل موثوق. جعل هذه المكونات صريحة يزيل الغموض ويقلل التباين في ما يتضمنه الوكيل.
النتيجة المتوقعة: عدد أقل من الإغفالات (خاصة التحقق)، تناسق أكثر إحكامًا عبر التشغيلات، ودرجات تقييم عالية بشكل موحد - بالإضافة إلى إجابات أوضح وأكثر قابلية للتنفيذ لفرق الأمن وتكنولوجيا المعلومات.
4.4 معاينة الفرق في التوجيه - رؤية ما سيتغير بالضبط
إذا كنت تريد فحص التغييرات المقترحة في التعليمات، انقر على مراجعة وتطبيق. هذا يولد التعليمات المحدثة ويفتح عرض الفرق الذي يظهر بالضبط ما سيتغير. من هناك، يمكنك أن تقرر ما إذا كنت ستطبق التحديث. النقر على رفض يلغي الاقتراح فورًا.
استخدم هذه الخطوة لتأكيد ثلاثة أشياء:
النطاق - التحديث يؤثر فقط على السيناريوهات التي تنويها (على سبيل المثال: الأسئلة حول الثغرات ونمط الحوادث)، وليس كل استجابة.
لا توجد تناقضات جديدة - أنت لا تقدم قواعد تتعارض مع بعضها البعض (مثل "كن موجزًا" أثناء طلب قوائم تحقق طويلة في كل مكان).
لا يزال موجزًا وقابلًا للاستخدام - يبقى الهيكل المضاف خفيف الوزن: بضع أقسام مسماة، بضع نقاط، لا توجد إسهاب غير ضروري.
عرض الفرق هو أيضًا فحص الأمان الخاص بك لمخاطر التراجع. إذا بدا التغيير واسعًا جدًا، مطلقًا جدًا، أو طويلًا جدًا، فقم بتضييقه قبل التطبيق. هندسة التوجيه مفيدة فقط عندما تكون محكومة - وهذا هو نقطة التحكم.
4.5 تطبيق تحديث التعليمات - ثم إعادة تشغيل التقييم
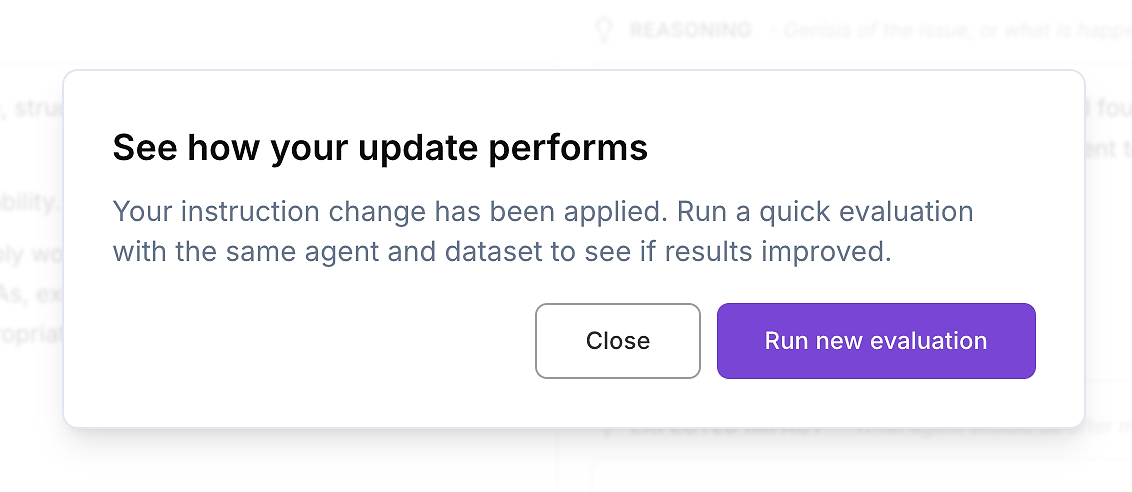
بمجرد مراجعة الفرق ورضاك عن التغيير، قم بتطبيق تعليمات الوكيل المحدثة.
ثم قم بالخطوة الوحيدة التالية التي تهم لنشر المؤسسات: إعادة تشغيل نفس تقييم وكيل الذكاء الاصطناعي على نفس مجموعة البيانات. هذه هي الطريقة التي تتحقق بها من التحسينات بطريقة محكومة - متغير واحد تغير (التعليمات)، وكل شيء آخر ثابت.
هذا يخلق حلقة تحسين قابلة للتكرار على مستوى المؤسسات:
التقاط تقرير تقييم أساسي
تطبيق تحديث تعليمات مستهدف
إعادة تشغيل مجموعة البيانات التقييمية المتطابقة
مقارنة النتائج: الدرجة، التباين، والشواذ
هذه هي الطريقة التي يصبح بها التقييم عملية إصدار - قابلة للقياس، قابلة للمراجعة، وآمنة للشحن.
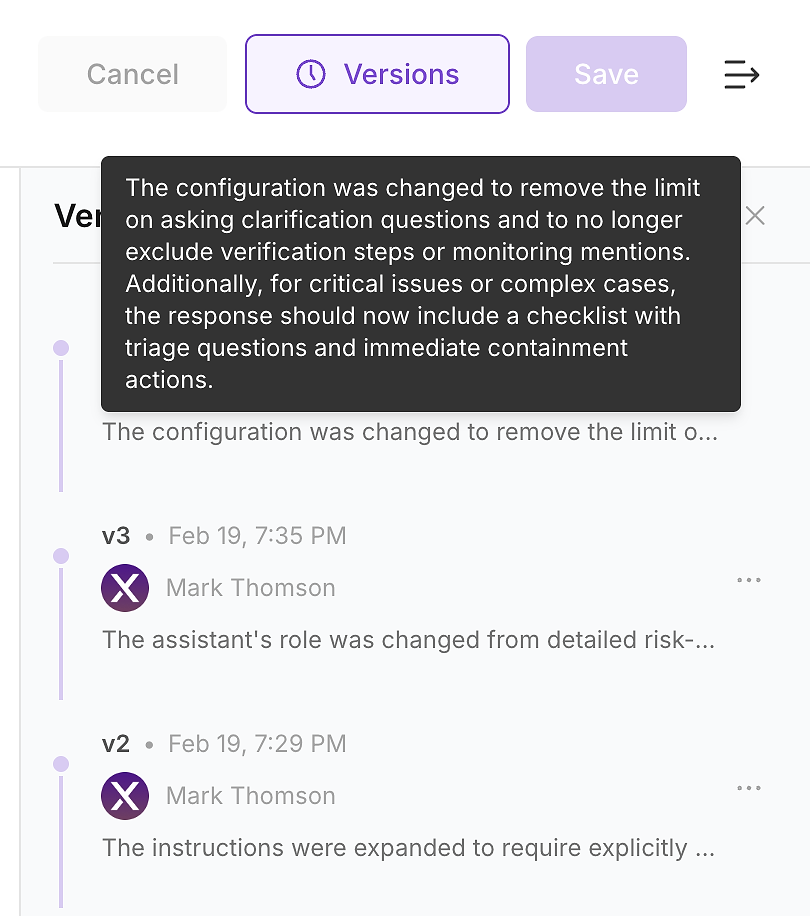
4.6 التحقق من سجل الإصدار - جعل التغيير قابلاً للمراجعة
بعد تطبيق التحديث، تحقق من سجل إصدار الوكيل. في بيئات المؤسسات، هذا ليس اختياريًا - إنه الطريقة التي تحول بها تغييرات التعليمات إلى سجل تغييرات قابل للمراجعة.
يتيح سجل الإصدار لفريقك الإجابة على الأسئلة التي ستطرحها الأمن، الامتثال، والعمليات:
ما الذي تغير (الفرق في التعليمات والملخص)
متى تغير (التحديث الموقوت)
من الذي غيره (الملكية والموافقات)
لماذا تغير (مرتبط بفجوات التقييم والتأثير المتوقع)
هذه هي الطريقة التي تشحن بها بأمان: كل تحديث تعليمات يصبح تغييرًا مراجعًا بالإصدار يمكنك التحقق منه بإعادة التشغيل والتراجع إذا لزم الأمر.
الخطوة 5: إعادة تشغيل التقييم - إثبات التحسين
الآن قم بتشغيل نفس مجموعة البيانات التقييمية مرة أخرى ضد إصدار الوكيل المحدث. هذه هي اللحظة التي يصبح فيها التقييم قيمة تجارية: أنت لا تدعي أن الوكيل أفضل - أنت تثبت ذلك بنتائج قابلة للتكرار.
في التقرير الجديد، تبحث عن ثلاثة إشارات:
درجة أعلى بشكل عام - تفي المزيد من السيناريوهات بمتطلبات الدليل بالكامل
استقرار أفضل - نطاق درجات أكثر إحكامًا، تباين أقل عبر التشغيلات
عدد أقل من الشواذ - عدد أقل من النتائج المنخفضة المفاجئة التي تخلق مخاطر الإنتاج
في الممارسة العملية، لا يدفع تحديث التعليمات الناجح المتوسط فقط إلى الأعلى. إنه يقلل من التقلبات بجعل سير عمل الوكيل أكثر اتساقًا - خاصة في أسئلة الفرز، هيكل المعالجة، وخطوات التحقق.
هذا هو ما يبدو عليه "الجيد" في الذكاء الاصطناعي للمؤسسات: تحسين قابل للقياس، أداء قابل للتكرار، ومسار تدقيق واضح يربط التغيير بالنتيجة.
الخلاصة المؤسسية: تحويل التقييم إلى عملية إصدار
هذا سير العمل هو أساس نشر وكلاء الذكاء الاصطناعي على مستوى المؤسسات:
تشغيل تقييم على مجموعة بيانات تمثيلية
استخدام التحليل لتحديد أوضاع الفشل المتكررة
تطبيق تحديثات تعليمات مستهدفة مع فرق مراجعة
تتبع التغييرات عبر سجل الإصدار للمراجعة
إعادة تشغيل نفس التقييم للتحقق من التحسين
هذه هي الطريقة التي تنتقل بها من "يبدو الوكيل جيدًا" إلى "يؤدي الوكيل بشكل موثوق." يصبح التقييم بوابة إصدار - عملية CI عملية لوكلاء الذكاء الاصطناعي تقلل من مخاطر التشغيل، تحسن التناسق، وتجعل التحسينات قابلة للقياس.
دعوة للعمل
إذا كنت تريد أن يقود التقييم نتائج تجارية حقيقية، فتعامل معه مثل الهندسة:
يجب أن يؤدي كل تحديث تعليمات إلى تشغيل تقييم
يجب أن يصبح كل فشل إنتاج حالة اختبار جديدة
يجب أن يكون كل تحسين قابلاً للقياس وقابلاً للتكرار
استكشاف AgentX
تعرف على المزيد في agentx.so
تشغيل التقييمات في المنصة على app.agentx.so
في المنشور التالي، سنتعمق في طرق التقييم المؤسسية، الأدوات، والتقنيات العملية لتحسين أداء الوكيل وموثوقيته بشكل مستمر. سنقدم أيضًا قسمًا جديدًا عن المراقبة - قريبًا.