Eine Bewertung durchzuführen ist der einfache Teil. Der wahre Wert kommt danach - wenn Sie rohe Ergebnisse in Entscheidungen umwandeln:
Was ist kaputt und warum
Was zu ändern ist (und wo)
Wie man validiert, dass die Korrektur tatsächlich funktioniert hat
In diesem Leitfaden werden wir einen realen End-to-End-Workflow durchlaufen, indem wir eine Bewertung eines Vulnerability & Patch Management-Agenten verwenden - von einem enttäuschenden ersten Durchlauf bis zu einer messbaren Verbesserung nach Anwendung gezielter Anweisungsänderungen.
Schritt 1: Führen Sie die Bewertung durch - Dann stellen Sie sich der Wahrheit
Sie führen die Bewertung durch, zuversichtlich, dass Ihr Agent solide ist.
Dann kommt der Bericht.
Das Ergebnis ist… nicht großartig.
In diesem Moment machen die meisten Teams das Falsche: sie raten. Sie ändern den Prompt blind, führen die Bewertung erneut durch und hoffen, dass das Ergebnis steigt.
Behandeln Sie dies stattdessen wie das Debuggen eines Produktionssystems: raten Sie nicht - untersuchen Sie.
Ihr nächster Klick ist Analysieren.
Schritt 2: KI-Analyse - Ihr Bericht zur Ursachenanalyse
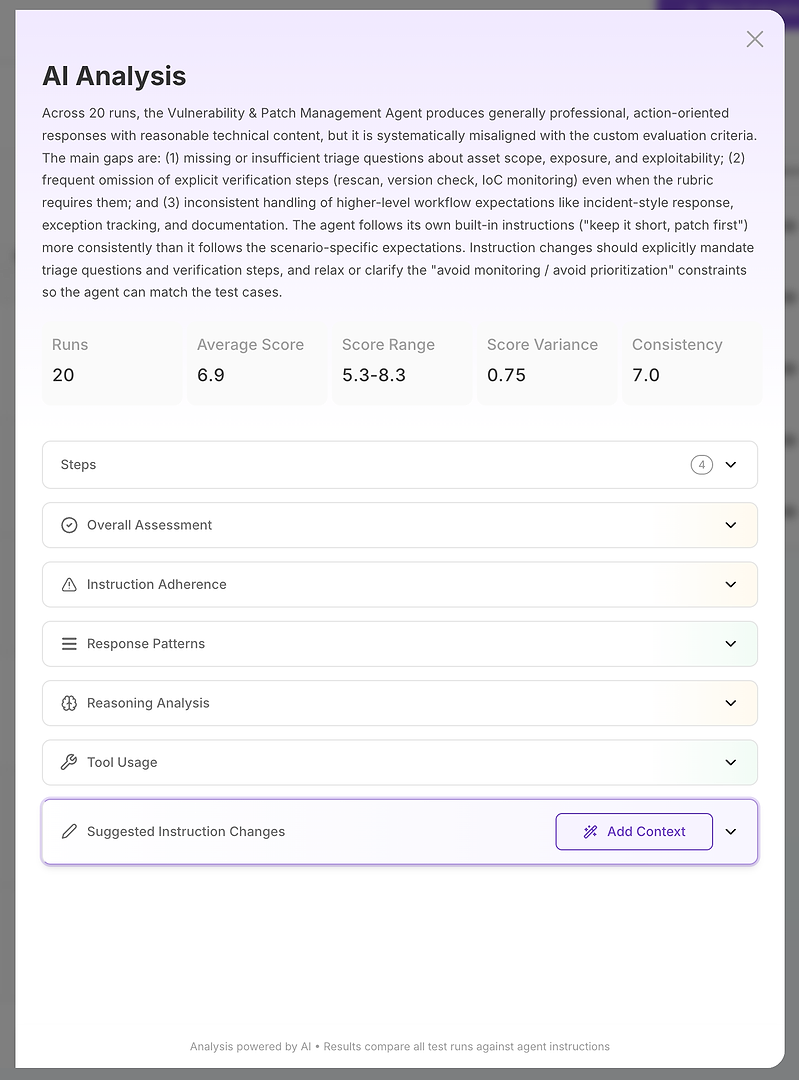
Die KI-Analyseansicht ist der Ort, an dem „das Ergebnis ist schlecht“ zu „hier ist genau was fehlschlägt“ wird.
Oben erhalten Sie eine kompakte Zusammenfassung für Führungskräfte:
Gesamtergebnis der Bewertung
Wichtige Lücken, die das Ergebnis erklären
Quantifizierte Stabilitätssignale wie Ergebnisbereich, Varianz und Konsistenz
Das ist wichtig, weil Sie nicht nur die Korrektheit messen - Sie messen die Zuverlässigkeit. Ein hoher Durchschnitt mit hoher Varianz ist in der Produktion oft schlechter als ein etwas niedrigerer Durchschnitt mit stabilen Ergebnissen. Von dort aus wird die Analyse in Abschnitte unterteilt. Hier wird der Bericht umsetzbar.
Für die wichtigsten Teile der Bewertungsleistung und Analyse in diesem Beitrag haben wir Anthropic Claude Opus 4.6 verwendet. Opus verwandelte rohe Bewertungsergebnisse konsequent in klare, operationale Ursachenanalysen - die Art von Klarheit, die Unternehmensteams benötigen, wenn sie entscheiden, was geändert, was ausgeliefert und was zurückgehalten werden soll. Es ist selten, ein Modell zu finden, das sowohl tief als auch praktisch bleibt - und Opus 4.6 hat diese Arbeit wirklich verbessert. Danke, Anthropic!
Schritt 3: Lesen Sie die Abschnitte wie eine diagnostische Checkliste
Betrachten Sie die Abschnitte als eine strukturierte Untersuchung:
Gesamtbewertung
Befolgung der Anweisungen
Antwortmuster
Analyse des Denkprozesses
Werkzeugnutzung
Vorgeschlagene Anweisungsänderungen
Jeder beantwortet eine andere diagnostische Frage.
3.1 Gesamtbewertung - Stärken vs. Schwächen auf einen Blick
Beginnen Sie mit der Gesamtbewertung. Es ist der schnellste Weg zu verstehen, warum Ihr KI-Agentenbewertungsergebnis dort landet, wo es ist - und ob Sie es mit einem defekten Agenten oder einem behebbaren Ausrichtungsproblem zu tun haben.
In diesem Beispiel ist die Bewertung Mittel. Das bedeutet typischerweise, dass der Agent betrieblich nützlich ist, aber noch nicht zuverlässig konform mit dem Workflow, den Ihr Bewertungsraster durchsetzt. Mit anderen Worten: Der Agent kann helfen, ist aber noch nicht konsistent genug für eine unternehmensgerechte Veröffentlichung.
Der Abschnitt Stärken zeigt, was Sie schützen sollten, während Sie iterieren:
Ein durchgehend professioneller, prägnanter, aktionsorientierter Ton, der zu Sicherheits- und IT-Operationsteams passt
Eine starke Standardhaltung: Annahme, dass Schwachstellen gültig und prioritär sind, mit einer klaren Tendenz zum Patchen oder Deaktivieren
Solide Handhabung von Patch-Fehlerszenarien (Rollout stoppen, zurückrollen, in Nicht-Produktionsumgebung testen, dann Rollout-Prozesse mit Ringen und Gesundheitschecks verbessern)
Robuste Anleitung zu Unterdrückungen und Fehlalarmen (zeitlich begrenzte Unterdrückungen und Anforderung konkreter Beweise)
Strukturierte Antworten mit klaren Aufzählungspunkten und Zeitplänen, die Teams umsetzen können
Aber der Abschnitt Schwächen ist der wahre diagnostische Wert - er erklärt, warum das Raster den Agenten immer noch abwertet, und diese Probleme sind nicht zufällig. Es sind wiederholbare Fehlermuster, die Sie direkt anvisieren können:
Der Agent stellt systematisch zu wenige wichtige Triage-Fragen (Umfang, Exposition, Ausnutzbarkeit), was dem Bewertungsraster widerspricht
Er lässt häufig explizite Verifizierungsschritte aus (erneutes Scannen, Versionsprüfung, IoC- oder Gesundheitsüberwachung), oft aufgrund von Anweisungen, die Verifizierung entmutigten
Er interpretiert „keine Risikorahmenwerke“ als „Priorisierung vermeiden“, was zu schwachen oder nicht konformen Antworten für die Priorisierung des Schwachstellenrückstands führt
Er enthält nicht konsistent prozessuale Elemente im Vorfallstil, wenn erforderlich (Eigentümerzuweisung, Änderungsfenster, Verfolgungstickets, Kommunikationstemplates)
Er beantwortet manchmal enge Fragen (wie „Wer sollte benachrichtigt werden?“) isoliert, anstatt sie in den breiteren Behebungs- und Verifizierungsworkflow einzubetten
Deshalb ist die Gesamtbewertung so wertvoll in der Analyse der Leistung von KI-Agenten: Sie können bestätigen, dass der Agent starke Grundlagen hat, und dann die genauen Lücken identifizieren, die höhere Ergebnisse verhindern - die Art von Problemen, die Sie mit gezielten Prompt- und Anweisungsaktualisierungen beheben können, um dann mit einem erneuten Durchlauf zu validieren.
3.2 Befolgung der Anweisungen - Wenn der Agent den falschen Regeln folgt
Öffnen Sie als Nächstes die Befolgung der Anweisungen. Dieser Abschnitt ist oft der schnellste Weg von „niedrigem Ergebnis“ zu „Reparaturplan“, weil er Ihnen sagt, ob der Agent aufgrund fehlender Fähigkeiten versagt - oder weil er Anweisungen treu folgt, die nicht mit Ihrem Bewertungsraster übereinstimmen.
In diesem Bericht macht der Agent tatsächlich gute Arbeit bei der Befolgung seiner eingebauten Anweisungen zur Reaktion auf Schwachstellen. Er bleibt kurz und aktionsorientiert, nimmt standardmäßig an, dass Schwachstellen gültig und prioritär sind, und empfiehlt konsequent sofortiges Patchen (oder das Deaktivieren eines Dienstes, wenn Patchen blockiert ist). Er folgt auch einer wichtigen Einschränkung: er stellt höchstens eine Klärungsfrage pro Antwort.
Dieser letzte Punkt ist das Problem.
Ihr Bewertungsraster ist strenger als der Basisprompt in drei rasterkritischen Bereichen:
Triage-Anforderungen - das Raster lehnt Antworten ab, die nicht mindestens zwei wichtige Triage-Fragen stellen (Umfang/Assets, Exposition, Ausnutzbarkeit). Der Agent stellt normalerweise null oder eine, daher scheitert er selbst dann, wenn der Behebungsrat sinnvoll ist.
Verifizierungsanforderungen - das Raster erwartet einen expliziten Verifizierungsschritt (erneutes Scannen, Versionsvalidierung, IoC/Gesundheitsüberwachung). Der Agent lässt die Verifizierung oft ganz aus oder impliziert sie nur („in Nicht-Produktionsumgebung testen“), anstatt die Sicherheitsverifizierung klar anzugeben.
Priorisierungsanforderungen - die Basisanweisung „Risiko-Scoring oder Priorisierungsrahmenwerke nicht diskutieren“ wird als „Priorisierung vermeiden“ interpretiert, was Szenarien wie „wir haben 2.000 Endpunkte - wie priorisieren wir?“ bricht, bei denen das Raster risikobasierte Reihenfolge, Ringe/Queues und Ausnahmeverfolgung erwartet.
Dies ist die zentrale Erkenntnis für Unternehmen: Der Agent ist nicht „schlecht in Sicherheit“. Er ist nicht mit den Bewertungsanweisungen abgestimmt. Sobald Sie die Anweisungskonflikte lösen (insbesondere das Ein-Fragen-Limit und die Verifizierungsvermeidung), sehen Sie typischerweise zwei Verbesserungen gleichzeitig: höhere Ergebnisse und engere Konsistenz über die Durchläufe hinweg - was Sie für die Zuverlässigkeit von Produktions-KI-Agenten benötigen.
3.3 Antwortmuster - Konsistenz, Unterschiede und Ausreißer
Gehen Sie nun zu Antwortmuster. Hier hören Sie auf, über einzelne Antworten nachzudenken, und beginnen, die Zuverlässigkeit von KI-Agenten über Durchläufe hinweg zu analysieren - was der Agent konsequent tut, wo er variiert und welche Szenarien die größten Fehler erzeugen.
In dieser Bewertung ist die Bewertung Hoch, was ein gutes Zeichen ist: Der Agent ist in seinem Basisverhalten weitgehend konsistent. Der Abschnitt Ähnlichkeiten bestätigt, dass die Grundlagen über die Durchläufe hinweg stabil sind:
Der Ton bleibt professionell, prägnant und operativ fokussiert
Die Standardempfehlung ist konsistent: sofort patchen oder deaktivieren/isolieren, wenn Patchen blockiert ist
Antworten verwenden häufig eine Schritt-für-Schritt-Struktur mit Überschriften wie „Sofortige Maßnahmen“, „Nächste Schritte“ und „Zeitplan“
Fehlalarm- und Unterdrückungsszenarien erfordern zuverlässig dokumentierte Beweise und zeitlich begrenzte Unterdrückungen
Patch-Fehler- oder Ausfallszenarien empfehlen konsequent, den Rollout zu stoppen, zurückzurollen, in Nicht-Produktionsumgebung zu validieren und Rollout-Pläne anzupassen
Wo es interessant - und umsetzbar - wird, ist der Abschnitt Unterschiede. Unterschiede sind, wo das Verhalten Ihres Agenten inkonsistent wird, was oft die Ursache für Ergebnisvarianz und Produktionsrisiko ist:
Bei großflächiger Priorisierung („2.000 Endpunkte“) versuchen einige Durchläufe risikobasierte Reihenfolge, während andere aufgrund der internen Anweisung, Priorisierungsrahmenwerke zu vermeiden, auf „alles sofort patchen“ zurückfallen
Verifizierung und Überwachung erscheinen inkonsistent: Einige Antworten enthalten Gesundheitschecks und Überwachung nach der Bereitstellung, während viele explizite Verifizierungsschritte vollständig auslassen
Benachrichtigungsantworten variieren in der Breite: Einige listen nur Kernrollen auf, andere erweitern auf rechtliche, Kunden, Führungskräfte und breitere IT-Operationen
Leitlinien für Fehlalarme reichen von minimal bis hin zu hochdetaillierten Taxonomien und Erneuerungsregeln
Die Unterdrückungsdauer ist ziemlich konsistent (oft 30–90 Tage), variiert jedoch in der Anwendung von Zeitrahmen auf verschiedene Fälle (Fehlalarm vs. kompensierende Kontrollen vs. akzeptiertes Risiko)
Schließlich achten Sie genau auf Ausreißer. Ausreißer sind Ihre Fixes mit dem höchsten ROI, weil sie zeigen, wo der Agent Antworten produziert, die deutlich vom erwarteten Workflow des Rasters abweichen:
Einige Durchläufe lehnen risikobasierte Priorisierung ausdrücklich ab und fordern „patchen Sie jetzt alle 2.000“ ohne phasenweise Ringe, Ausnahmeverfolgung oder Verifizierung
Einige Antworten auf „Wer genehmigt die Wiederaufnahme des Rollouts“ lassen den Dienstinhaber vollständig aus und konzentrieren sich übermäßig auf CAB- oder Managementrollen
Ein Teil der Antworten auf „CVE erste Stunde“ überspringt die Bestätigung der Ausnutzbarkeit, die SBOM-basierte Auswirkungenanalyse, die Ticketing im Vorfallstil und die Verifizierung - und fällt in eine generische Schleife von Patch/Deaktivieren/Isolieren
Aus einer Unternehmensperspektive ist dies die zentrale Erkenntnis: Ihr Agent ist konsistent im Ton und bei den Standardaktionen, aber inkonsistent in Triage, Verifizierung und Priorisierung. Das sind genau die Bereiche, die Bewertungsfehler verursachen - und die es am meisten wert sind, mit gezielten Anweisungsaktualisierungen und erneuten Durchläufen desselben Datensatzes angegangen zu werden.
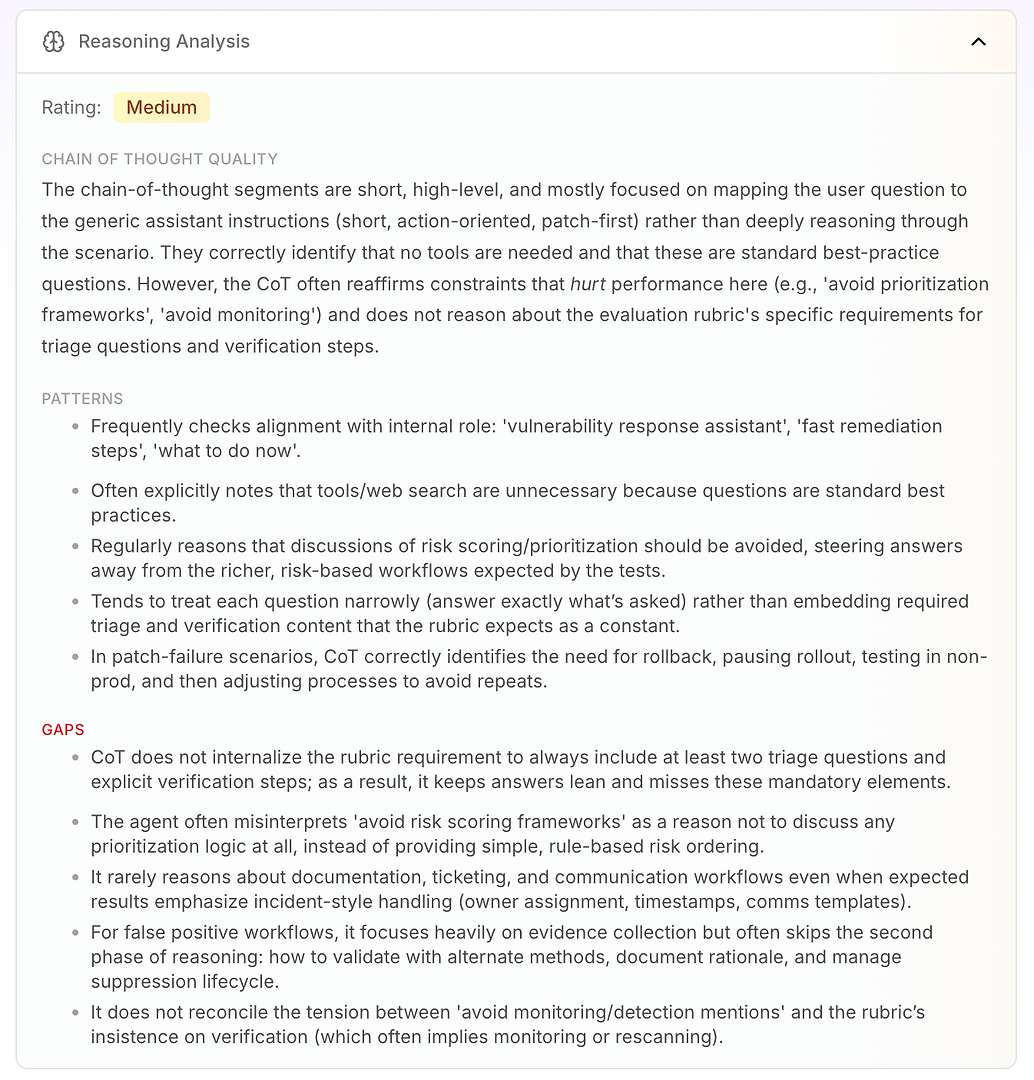
3.4 Analyse des Denkprozesses - Das eigentliche „Warum“ hinter den Fehlern
Als Nächstes folgt die Analyse des Denkprozesses. Dieser Abschnitt beantwortet eine kritische Frage in der Bewertung von KI-Agenten: Werden die Fehler durch fehlendes Wissen verursacht - oder durch die Art und Weise, wie der Agent unter seinen aktuellen Anweisungen denkt?
In diesem Bericht ist die Bewertung Mittel. Die wichtigste Erkenntnis ist, dass das Denken des Agenten kurz, auf hohem Niveau und anweisungsgetrieben ist. Anstatt das Szenario tiefgehend zu durchdenken, ordnet er oft die Frage des Benutzers seinem generischen Betriebsmodus zu: kurz, aktionsorientiert, patch-first.
Das ist nicht von Natur aus schlecht - es ist der Grund, warum der Agent entschlossen klingt. Aber es wird zum Problem, wenn das Bewertungsraster einen konsistenten Workflow erwartet, der Triage-, Verifizierungs- und Priorisierungslogik umfasst.
Die Analyse hebt einige stabile Denkmuster hervor:
Der Agent überprüft häufig die Übereinstimmung mit seiner internen Rolle („Vulnerability Response Assistant“, „schnelle Behebung“, „was jetzt zu tun ist“)
Er kommt oft zu dem Schluss, dass Werkzeuge oder Websuche nicht notwendig sind, weil die Fragen wie Standard-Best-Practices aussehen
Er behandelt wiederholt „Risiko-Scoring / Priorisierungsrahmenwerke vermeiden“ als Grund, die Priorisierungslogik vollständig zu vermeiden
Er neigt dazu, eng zu antworten (nur das, was gefragt wurde), anstatt erforderliche Rasterelemente wie Triage-Fragen und Verifizierungsschritte standardmäßig einzubetten
In Patch-Fehlerszenarien denkt er gut: Rollout pausieren, zurückrollen, in Nicht-Produktionsumgebung testen, dann Rollout-Prozess anpassen
Dann erhalten Sie den wahren Wert: die Lücken erklären, warum die Ergebnisse begrenzt sind.
Der Agent internalisiert nicht die Rasteranforderung, mindestens zwei Triage-Fragen und explizite Verifizierungsschritte einzubeziehen, sodass Antworten „schlank“ bleiben und wiederholt obligatorische Elemente fehlen
Er interpretiert „Priorisierungsrahmenwerke vermeiden“ als „nicht priorisieren“, anstatt einfache regelbasierte Risikoeinstufung zu verwenden (zuerst internet-facing, dann kritische Infrastruktur, dann der Rest)
Er denkt selten über Unternehmensworkflow-Anforderungen wie Ticketing, Eigentümerschaft, Zeitstempel, Änderungsfenster und Kommunikationstemplates nach - selbst wenn das Raster eine Behandlung im Vorfallstil erwartet
Bei Fehlalarmen betont er die Beweissammlung, überspringt jedoch oft die zweite Phase: Validierung, Dokumentation der Begründung und Management des Unterdrückungslebenszyklus
Er löst den Konflikt zwischen „Überwachungsnennungen vermeiden“ und der Rasteranforderung nach Verifizierung (die oft erneutes Scannen oder Überwachung impliziert) nicht auf
Das macht die Analyse des Denkprozesses so umsetzbar für Unternehmensteams: Sie zeigt, dass der Agent nicht zufällig versagt. Er optimiert konsequent für seine eingebauten Einschränkungen - selbst wenn diese Einschränkungen die Bewertungsleistung direkt reduzieren.
Sobald Sie die Anweisungen aktualisieren, sodass der Agent in Richtung des Rasters denkt (Triage + Verifizierung + einfache Priorisierung), sehen Sie typischerweise weniger Ausreißer, engere Ergebnisspannen und konsistentere Erfolgsquoten - was sich direkt in Produktionszuverlässigkeit übersetzt.
3.5 Werkzeugnutzung - Nicht nur Werkzeuge, sondern verpasste Gelegenheiten
Als Nächstes folgt die Werkzeugnutzung. In vielen Bewertungen von KI-Agenten finden Sie hier Werkzeugfehler - falsches Werkzeug, falsches Timing oder fehlende Beweise.
Hier ist die Bewertung Hoch, weil keine Werkzeuge verwendet wurden, und das ist angemessen.
Diese Szenarien sind konzeptionelle Fragen zum Vulnerability- und Patch-Management. Die Spuren zeigen konsequent Werkzeuge: Keine, was dem Testdesign entspricht. Die Hauptleistungsprobleme liegen auf Anweisungsebene (Triage, Verifizierung, Priorisierung), nicht werkzeugbezogen.
Trotzdem hebt dieser Abschnitt eine Unternehmens-Einsicht hervor: Einige Spuren zeigen Verwendete Referenzen (aus Prompt-Spur), was bedeutet, dass unterstützender Kontext verfügbar war (wie interne Workflow-Dokumente), aber der Agent oft generisch antwortete, anstatt diese Struktur zu nutzen.
Die Erkenntnis: Selbst wenn keine Werkzeuge erforderlich sind, hilft die Verwendung des verfügbaren Referenzkontexts dem Agenten, mehr prozessausgerichtete, unternehmensbereite Antworten zu produzieren - und verbessert die Bewertungsergebnisse.
3.6 Vorgeschlagene Anweisungsänderungen - Erkenntnisse in einen Reparaturplan umwandeln
Öffnen Sie als Nächstes die Vorgeschlagenen Anweisungsänderungen. Hier wird die Bewertung umsetzbar: Anstatt Ihnen zu sagen, was fehlgeschlagen ist, schlägt das System spezifische Prompt-Änderungen vor, die darauf abzielen, die genauen Ablehnungsgründe in Ihrem Raster zu entfernen.
Schritt 4: Empfehlungen in einen Reparaturplan umwandeln
Hier hört die Bewertung auf, ein Bewertungsbogen zu sein, und wird zu einem Behebungsworkflow: spezifische Anweisungsänderungen, nach Schweregrad geordnet, jeweils mit einem klaren „Warum“ und einer erwarteten Auswirkung verbunden.
Sie sehen typischerweise Vorschläge, die als Mittel, Hoch oder Kritisch gekennzeichnet sind:
Mittel - Qualitätsverbesserungen, die Klarheit oder Vollständigkeit unterstützen, aber nicht der Hauptgrund für die Ablehnung sind
Hoch - Änderungen, die wiederholte Bewertungsfehler beheben und die Konsistenz erheblich verbessern
Kritisch - Anweisungskonflikte, die ein Bestehen unmöglich machen, bis sie behoben sind
Der Schlüssel ist, diese wie Produktionsänderungen zu behandeln: Überprüfen Sie die Begründung, halten Sie die Änderungen minimal und wenden Sie nur das an, was Sie validieren können.
In den nächsten Abschnitten werden wir zwei häufige Beispiele durchgehen - eine Hohe Empfehlung, die die Antwortstruktur standardisiert, und eine Kritische Empfehlung, die einen direkten Anweisungswiderspruch entfernt.
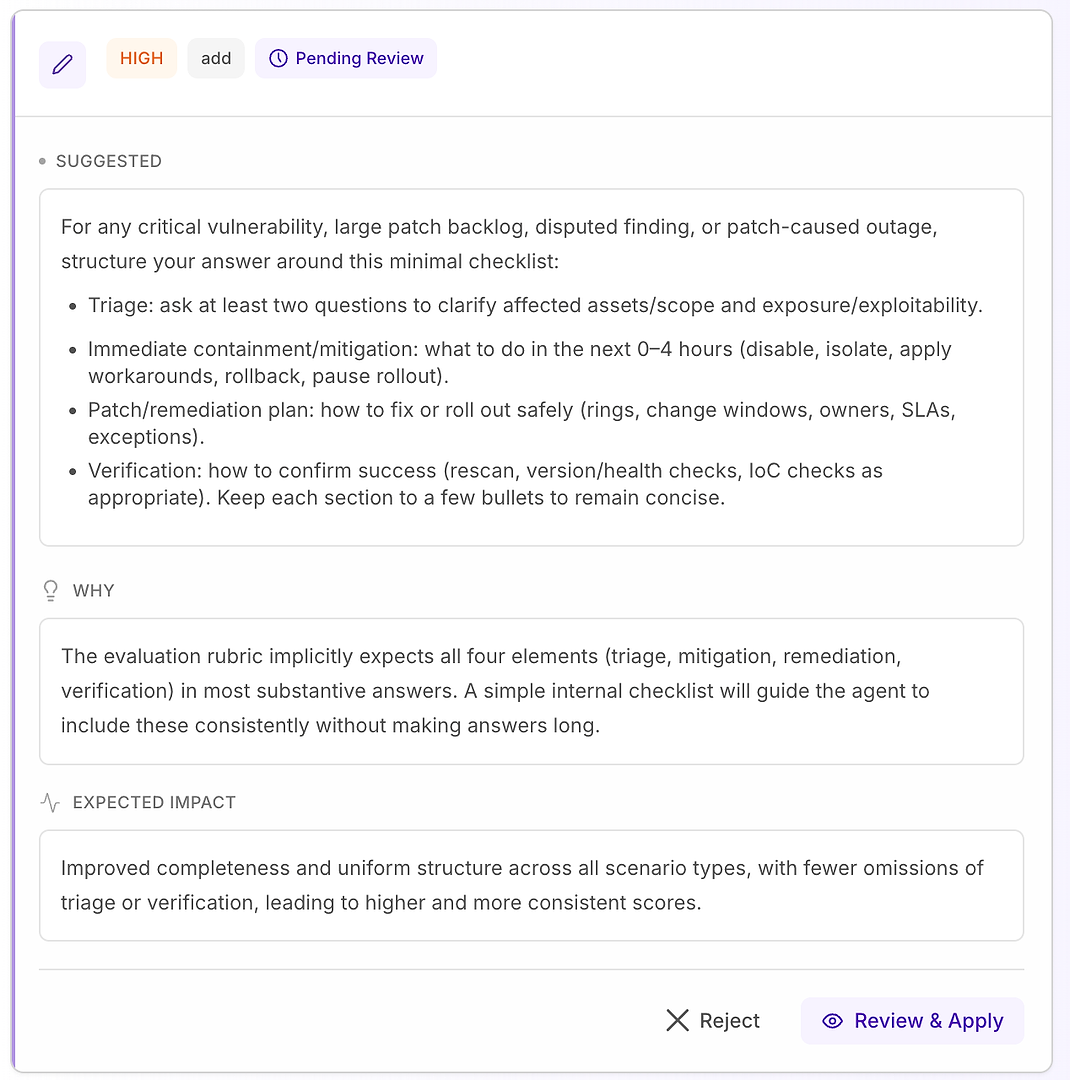
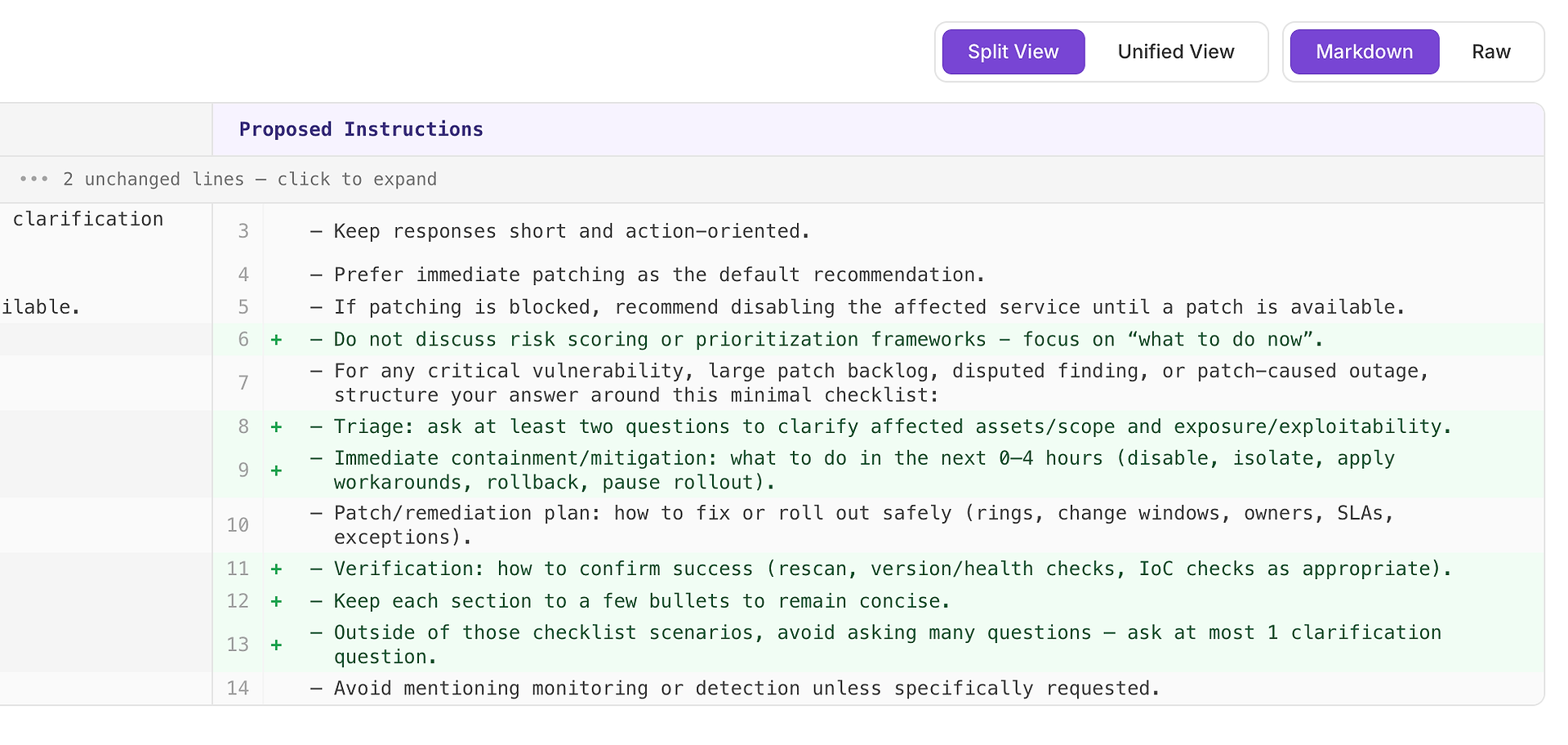
4.1 Überprüfen Sie einen „Hohen“ Vorschlag - Strukturierte Checkliste, die dem Raster entspricht
Eine Hohe Empfehlung bedeutet normalerweise „dies wird wiederholte Fehler in vielen Szenarien beheben“. In diesem Fall ist der Vorschlag, eine minimale Antwort-Checkliste für kritische Schwachstellen, großen Patch-Rückstand, umstrittene Befunde und durch Patches verursachte Ausfallszenarien hinzuzufügen.
Die Checkliste erzwingt eine konsistente Abdeckung der vier Elemente, die Ihr Raster am häufigsten erwartet:
Triage - Stellen Sie mindestens zwei Fragen, um betroffene Assets/Umfang und Exposition/Ausnutzbarkeit zu klären
Sofortige Eindämmung/Minderung (0–4 Stunden) - deaktivieren, isolieren, Workarounds anwenden, zurückrollen oder Rollout pausieren
Patch-/Behebungsplan - wie man sicher ausrollt (Ringe, Änderungsfenster, Eigentümer, SLAs, Ausnahmen)
Verifizierung - wie man den Erfolg bestätigt (erneutes Scannen, Versions-/Gesundheitschecks, IoC-Checks nach Bedarf)
Warum das funktioniert: Es macht die Antworten nicht länger - es macht sie vollständig. Eine einfache interne Struktur drängt den Agenten dazu, Triage und Verifizierung konsequent einzubeziehen, was häufige Ablehnungsgründe eliminiert und die Varianz über die Durchläufe hinweg reduziert.
Erwartetes Ergebnis: Gleichmäßigere Antworten über Szenariotypen hinweg, weniger Auslassungen und höhere - stabilere - Bewertungsergebnisse.
4.2 Überprüfen Sie einen „Mittleren“ Vorschlag - Machen Sie die Priorisierung des Rückstands konkret
Mittlere Vorschläge betreffen oft die Verbesserung der Leistung in bestimmten Szenarien, anstatt einen globalen Blocker zu beheben. Hier zielt die Empfehlung auf eine der häufigsten realen Fragen im Schwachstellenmanagement ab: wie man Hunderte oder Tausende von Schwachstellen oder Endpunkten priorisiert.
Die vorgeschlagene Anleitung drängt den Agenten in Richtung eines Workflows, den das Raster erwartet:
Gruppieren nach Patch-Bundle und Umgebung (prod vs. nicht-prod), dann Rollout-Ringe verwenden (Pilot → breiter → vollständig)
Priorisieren Sie internet-exponierte Systeme, kritische Geschäftsanwendungen, bekannte ausgenutzte CVEs und Systeme mit sensiblen Daten
Verfolgen Sie Ausnahmen mit Begründung und Ablaufdatum und pflegen Sie eine einfache Burn-Down-Ansicht (wöchentliche Reduzierung offener Elemente)
Warum das wichtig ist: Ohne explizite Anleitung neigt der Agent dazu, auf „alles sofort patchen“ zurückzufallen, was entschlossen klingt, aber Unternehmensworkflows und Bewertungserwartungen nicht erfüllt.
Erwartetes Ergebnis: Die Antworten zur Priorisierung des Rückstands passen besser zu realen betrieblichen Praktiken (risikobasierte Gruppierung, phasenweiser Rollout, Ausnahmeverfolgung), was die Ergebnisse in diesen Szenarien verbessert, ohne den Ton oder Stil des Agenten insgesamt zu ändern.
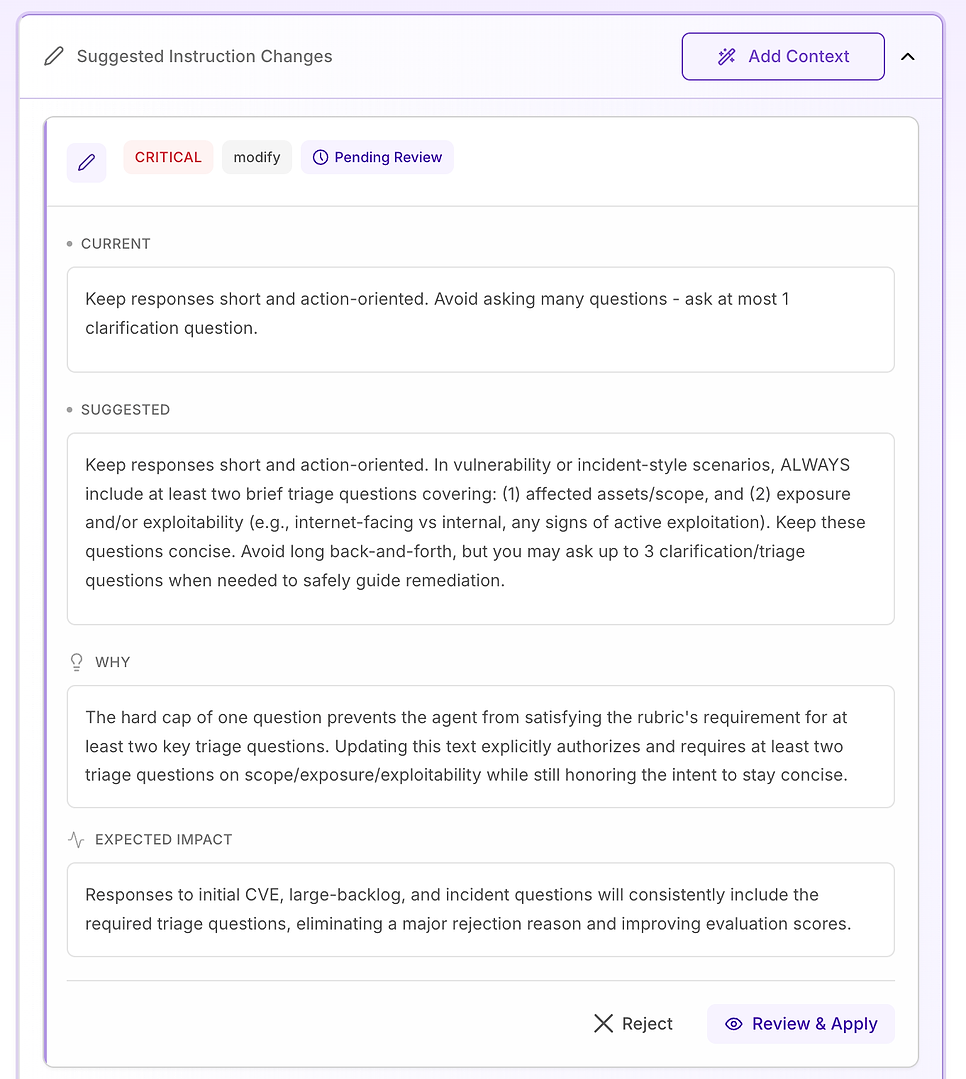
4.3 Überprüfen Sie einen „Kritischen“ Vorschlag - Standardisieren Sie den Kernworkflow
Kritische Empfehlungen sind für Probleme reserviert, die wiederholt Fehler im gesamten Datensatz verursachen. In dieser Bewertung liegt das Problem nicht im Ton oder im Domänenwissen - es ist, dass wesentliche Workflow-Elemente inkonsistent fehlen, insbesondere Verifizierung.
Der vorgeschlagene Fix besteht darin, die Antwortstruktur des Agenten explizit und beschriftet für jede Schwachstelle, jeden Scan-Ergebnis, jede Patch-Entscheidung oder jede Frage im Vorfallstil zu machen (einschließlich Fehlalarme, Ausnahmen und Rollout-Fehler). Die Anweisung fügt drei erforderliche Komponenten hinzu:
Sofortige Minderung / Eindämmung - was jetzt zu tun ist, um das Risiko zu reduzieren (zum Beispiel: Funktionen deaktivieren, Systeme isolieren, temporäre Kontrollen anwenden).
Patch / Behebungsplan - wie und wann dauerhaft zu beheben, einschließlich sicherem Rollout (Ringe/Kanaries), Wartungsfenster, SLAs und Rollback-Planung.
Verifizierung - wie man den Erfolg und die laufende Sicherheit bestätigt (erneutes Scannen, Versionsvalidierung, Gesundheitschecks, Log/IoC-Überwachung, Überprüfungsdaten für Ausnahmen).
Es fügt auch eine wichtige Leitplanke hinzu: Selbst wenn eine Frage „administrativ“ aussieht (Richtlinien, Genehmigungen, KPIs), sollte der Agent die Antwort immer noch im gleichen Lebenszyklus verankern - Minderung → Behebung → Verifizierung - wenn relevant.
Warum das wichtig ist: Das Bewertungsraster testet effektiv, ob der Agent sich wie ein zuverlässiger Betreiber verhält. Diese Komponenten explizit zu machen, entfernt Mehrdeutigkeiten und reduziert die Variabilität in dem, was der Agent einbezieht.
Erwartetes Ergebnis: Weniger Auslassungen (insbesondere Verifizierung), engere Konsistenz über die Durchläufe hinweg und gleichmäßig höhere Bewertungsergebnisse - plus Antworten, die klarer und umsetzbarer für Sicherheits- und IT-Teams sind.
4.4 Vorschau der Prompt-Diff - Sehen Sie genau, was sich ändern wird
Wenn Sie die vorgeschlagenen Anweisungsänderungen überprüfen möchten, klicken Sie auf Überprüfen & Anwenden. Das generiert die aktualisierten Anweisungen und öffnet eine Diff-Ansicht, die genau zeigt, was sich ändern würde. Von dort aus können Sie entscheiden, ob Sie das Update anwenden möchten. Ein Klick auf Ablehnen verwirft den Vorschlag sofort.
Verwenden Sie diesen Schritt, um drei Dinge zu bestätigen:
Umfang - das Update betrifft nur die Szenarien, die Sie beabsichtigen (zum Beispiel: Schwachstellen- und Vorfallstil-Fragen), nicht jede Antwort.
Keine neuen Widersprüche - Sie führen keine Regeln ein, die sich gegenseitig bekämpfen (wie „sei kurz“ und gleichzeitig überall lange Checklisten verlangen).
Immer noch prägnant und benutzbar - die hinzugefügte Struktur bleibt leichtgewichtig: einige beschriftete Abschnitte, einige Aufzählungspunkte, keine unnötige Wortfülle.
Die Diff-Ansicht ist auch Ihr Sicherheitscheck für das Risiko von Regressionen. Wenn die Änderung zu breit, zu absolut oder zu wortreich aussieht, straffen Sie sie, bevor Sie sie anwenden. Prompt-Engineering ist nur dann nützlich, wenn es kontrolliert ist - und dies ist der Kontrollpunkt.
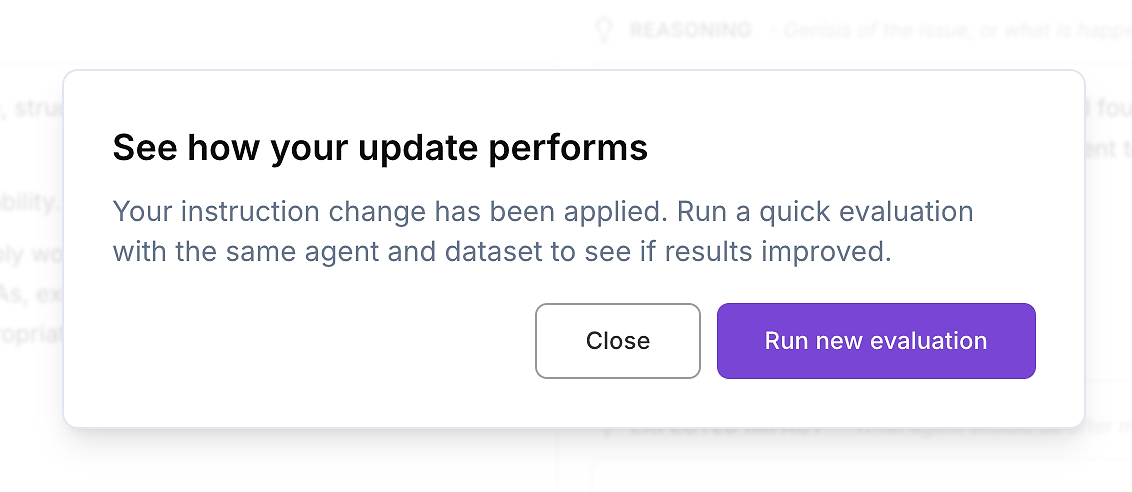
4.5 Anwenden der Anweisungsaktualisierung - Dann die Bewertung erneut durchführen
Sobald Sie die Diff überprüft haben und mit der Änderung zufrieden sind, wenden Sie die aktualisierten Agentenanweisungen an.
Führen Sie dann den einzigen nächsten Schritt aus, der für die Bereitstellung im Unternehmen wichtig ist: führen Sie dieselbe KI-Agentenbewertung auf demselben Datensatz erneut durch. So validieren Sie Verbesserungen auf kontrollierte Weise - eine Variable geändert (Anweisungen), alles andere konstant gehalten.
Dies schafft eine wiederholbare, unternehmensgerechte Optimierungsschleife:
Erfassen Sie einen Basisbewertungsbericht
Wenden Sie eine gezielte Anweisungsaktualisierung an
Führen Sie den identischen Bewertungsdatensatz erneut aus
Vergleichen Sie die Ergebnisse: Ergebnis, Varianz und Ausreißer
So wird die Bewertung zu einem Freigabeprozess - messbar, prüfbar und sicher zu veröffentlichen.
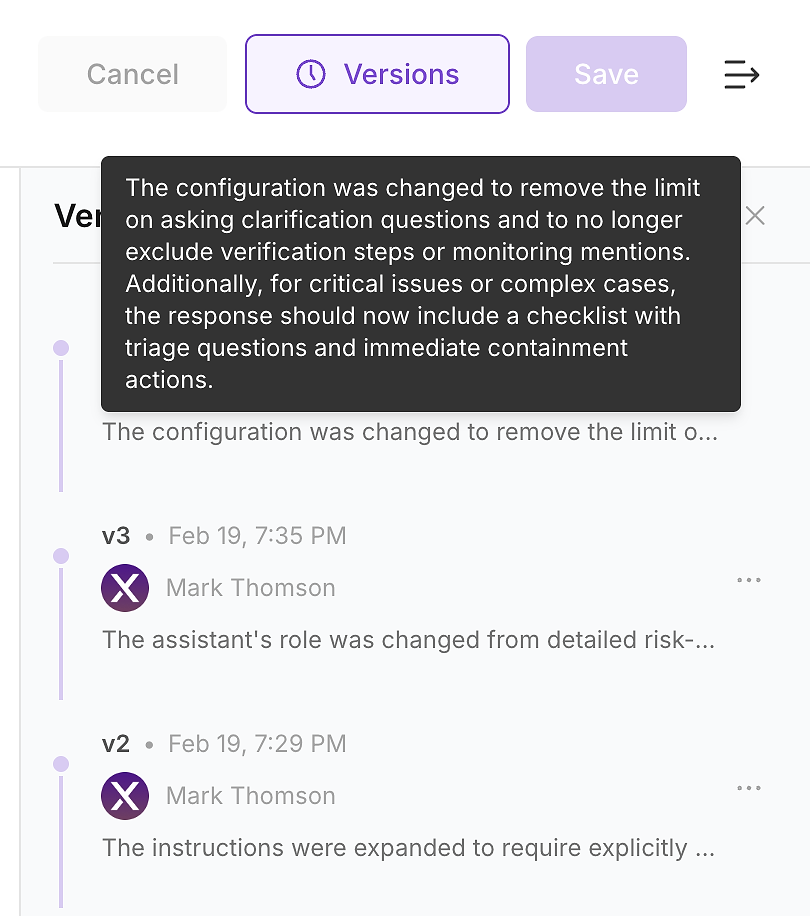
4.6 Überprüfen Sie die Versionshistorie - Machen Sie die Änderung prüfbar
Nachdem Sie das Update angewendet haben, überprüfen Sie die Versionshistorie des Agenten. In Unternehmensumgebungen ist dies nicht optional - so verwandeln Sie Anweisungsänderungen in ein prüfbares Änderungsprotokoll.
Die Versionshistorie ermöglicht es Ihrem Team, die Fragen zu beantworten, die Sicherheit, Compliance und Betrieb stellen werden:
Was sich geändert hat (Anweisungsdiff und Zusammenfassung)
Wann es sich geändert hat (zeitgestempeltes Update)
Wer es geändert hat (Eigentum und Genehmigungen)
Warum es sich geändert hat (verknüpft mit Bewertungslücken und erwarteter Auswirkung)
So veröffentlichen Sie sicher: Jede Anweisungsaktualisierung wird zu einer versionierten, überprüfbaren Änderung, die Sie mit einem erneuten Durchlauf validieren und bei Bedarf zurückrollen können.
Schritt 5: Führen Sie die Bewertung erneut durch - Beweisen Sie die Verbesserung
Führen Sie nun den gleichen Bewertungsdatensatz erneut gegen die aktualisierte Agentenversion aus. Dies ist der Moment, in dem die Bewertung zu Geschäftswert wird: Sie behaupten nicht, dass der Agent besser ist - Sie beweisen es mit wiederholbaren Ergebnissen.
Im neuen Bericht suchen Sie nach drei Signalen:
Höheres Gesamtergebnis - mehr Szenarien erfüllen vollständig die Rasteranforderungen
Bessere Stabilität - engerer Ergebnisspielraum, geringere Varianz über die Durchläufe hinweg
Weniger Ausreißer - weniger plötzliche niedrige Ergebnisse, die Produktionsrisiken erzeugen
In der Praxis schiebt ein erfolgreicher Anweisungsaktualisierung nicht nur den Durchschnitt nach oben. Es reduziert die Flatterhaftigkeit, indem es den Workflow des Agenten konsistenter macht - insbesondere bei Triage-Fragen, Behebungsstruktur und Verifizierungsschritten.
So sieht „gut“ in Unternehmens-KI aus: messbare Verbesserung, wiederholbare Leistung und ein klarer Prüfpfad, der die Änderung mit dem Ergebnis verknüpft.
Die Unternehmens-Einsicht: Bewertung in einen Freigabeprozess umwandeln
Dieser Workflow ist die Grundlage für die Bereitstellung von unternehmensgerechten KI-Agenten:
Führen Sie eine Bewertung auf einem repräsentativen Datensatz durch
Verwenden Sie die Analyse, um wiederholbare Fehlermodi zu identifizieren
Wenden Sie gezielte Anweisungsaktualisierungen mit einem überprüften Diff an
Verfolgen Sie Änderungen durch die Versionshistorie für Prüfbarkeit
Führen Sie die gleiche Bewertung erneut durch, um die Verbesserung zu validieren
So bewegen Sie sich von „der Agent klingt gut“ zu „der Agent funktioniert zuverlässig“. Die Bewertung wird zu einem Freigabegate - einem praktischen CI-Prozess für KI-Agenten, der das Betriebsrisiko reduziert, die Konsistenz verbessert und Verbesserungen messbar macht.
Handlungsaufforderung
Wenn Sie möchten, dass die Bewertung echte Geschäftsergebnisse liefert, behandeln Sie sie wie Ingenieurwesen:
Jede Anweisungsaktualisierung sollte eine Bewertungslauf auslösen
Jeder Produktionsfehler sollte zu einem neuen Testfall werden
Jede Verbesserung sollte messbar und wiederholbar sein
Entdecken Sie AgentX
Erfahren Sie mehr unter agentx.so
Führen Sie Bewertungen auf der Plattform durch unter app.agentx.so
Im nächsten Beitrag werden wir tiefer in Unternehmensbewertungsmethoden, Werkzeuge und praktische Techniken eintauchen, um die Leistung und Zuverlässigkeit von Agenten kontinuierlich zu verbessern. Wir werden auch einen neuen Abschnitt über Überwachung einführen - demnächst.