Realizar una evaluación es la parte fácil. El verdadero valor viene después, cuando conviertes las puntuaciones en decisiones:
Qué está roto y por qué
Qué cambiar (y dónde)
Cómo validar que la solución realmente funcionó
Cómo validar que la solución realmente funcionó
En esta guía, recorreremos un flujo de trabajo real de principio a fin utilizando una evaluación de agente de Gestión de Vulnerabilidades y Parches, desde una primera ejecución decepcionante hasta una mejora medible después de aplicar cambios específicos en las instrucciones.
Paso 1: Realiza la Evaluación - Luego Enfrenta la Verdad
Realizas la evaluación, confiado en que tu agente es sólido.
Luego llega el informe.
La puntuación es... no es buena.
En este momento, la mayoría de los equipos hacen lo incorrecto: adivinan. Ajustan el prompt a ciegas, vuelven a ejecutar y esperan que la puntuación suba.
En su lugar, trata esto como depurar un sistema de producción: no adivines - inspecciona.
Tu próximo clic es Analizar.
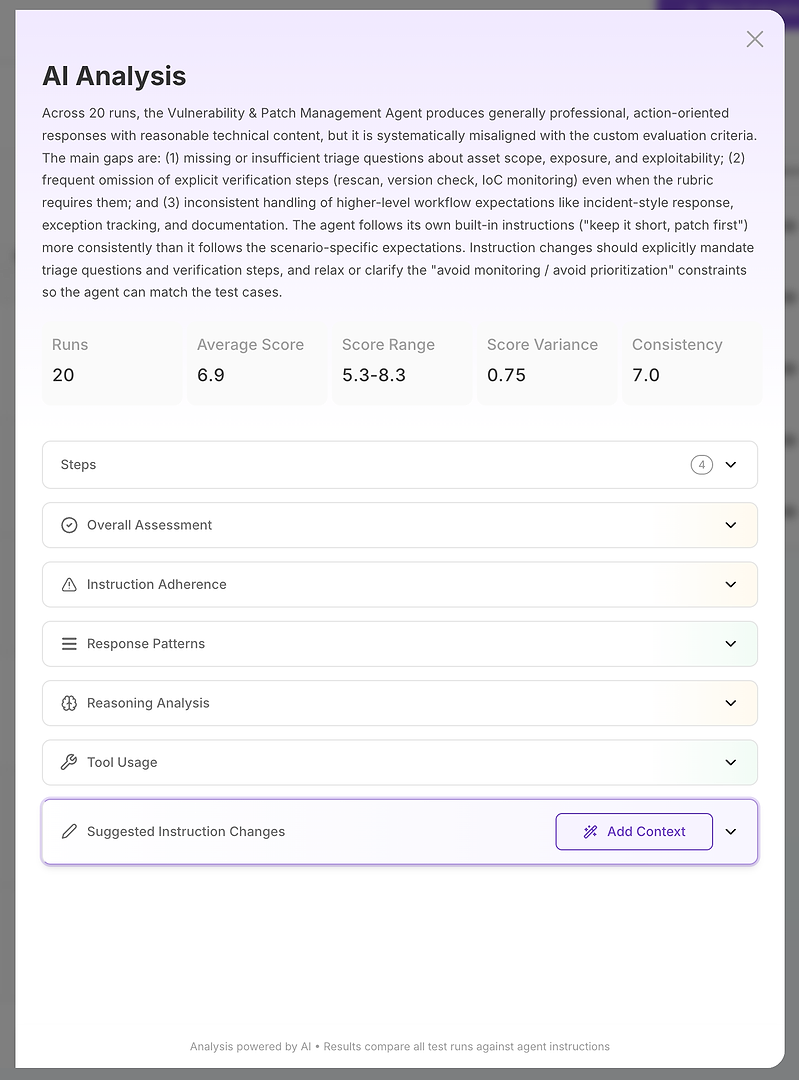
La vista de Análisis de IA es donde “la puntuación es mala” se convierte en “aquí está exactamente lo que está fallando.”
En la parte superior, obtienes un resumen ejecutivo compacto:
Resultado general de la evaluación
Principales brechas que explican la puntuación
Señales de estabilidad cuantificadas como rango de puntuación, varianza y consistencia
Esto es importante porque no solo estás midiendo la corrección, sino la fiabilidad. Un promedio alto con alta varianza es a menudo peor en producción que un promedio ligeramente más bajo con resultados estables. A partir de ahí, el análisis se desglosa en secciones. Aquí es donde el informe se vuelve accionable.
Para las partes más importantes del rendimiento y análisis de la evaluación en esta publicación, utilizamos Anthropic Claude Opus 4.6. Opus convirtió consistentemente la salida de evaluación en resúmenes operativos claros de causa raíz, el tipo de claridad que los equipos empresariales necesitan al decidir qué cambiar, qué enviar y qué retener. Es raro encontrar un modelo que se mantenga tanto profundo como práctico al mismo tiempo, y Opus 4.6 realmente mejoró este trabajo. ¡Gracias, Anthropic!
Paso 3: Lee las Secciones Como una Lista de Verificación Diagnóstica
Piensa en las secciones como una investigación estructurada:
Evaluación General
Cumplimiento de Instrucciones
Patrones de Respuesta
Análisis de Razonamiento
Uso de Herramientas
Cambios Sugeridos en las Instrucciones
Cada una responde a una pregunta diagnóstica diferente.
3.1 Evaluación General - Fortalezas vs Debilidades de un Vistazo
Comienza con la Evaluación General. Es la forma más rápida de entender por qué la puntuación de evaluación de tu agente de IA está donde está, y si estás lidiando con un agente roto o un problema de alineación solucionable.
En este ejemplo, la calificación es Media. Eso generalmente significa que el agente es útil operativamente, pero aún no cumple de manera confiable con el flujo de trabajo que tu rúbrica de evaluación está imponiendo. En otras palabras: el agente puede ayudar, pero aún no es lo suficientemente consistente para un lanzamiento de nivel empresarial.
La sección de Fortalezas muestra lo que debes proteger mientras iteras:
Un tono consistentemente profesional, conciso y enfocado en la acción que se adapta a los equipos de seguridad y operaciones de TI
Una postura predeterminada fuerte: asumir que las vulnerabilidades son válidas y de alta prioridad, con un claro sesgo hacia el parcheo o la desactivación
Manejo sólido de escenarios de fallo de parche (detener el despliegue, revertir, probar en no producción, luego mejorar los procesos de despliegue con anillos y verificaciones de salud)
Orientación robusta sobre supresiones y falsos positivos (supresiones con límite de tiempo y requerimiento de evidencia concreta)
Respuestas estructuradas con puntos claros y cronogramas que los equipos pueden ejecutar
Pero la sección de Debilidades es el verdadero valor diagnóstico: explica por qué la rúbrica aún está puntuando al agente a la baja, y estos problemas no son aleatorios. Son patrones de fallo repetibles que puedes abordar directamente:
El agente sistemáticamente no hace preguntas clave de triaje (alcance, exposición, explotabilidad), lo que entra en conflicto con la rúbrica de evaluación
Frecuentemente omite pasos de verificación explícitos (reescaneo, verificación de versión, monitoreo de IoC o salud), a menudo debido a instrucciones que desalentaron la verificación
Interpreta erróneamente “marcos sin riesgo” como “evitar la priorización,” lo que lleva a respuestas débiles o no conformes para la priorización del backlog de vulnerabilidades
No incluye consistentemente elementos de proceso estilo incidente cuando se requiere (asignación de propietario, ventanas de cambio, tickets de seguimiento, plantillas de comunicación)
A veces responde preguntas estrechas (como “¿quién debe ser notificado?”) de forma aislada en lugar de integrarlas en el flujo de trabajo más amplio de remediación y verificación
Esta es la razón por la que la Evaluación General es tan valiosa en el análisis de rendimiento de agentes de IA: puedes confirmar que el agente tiene fundamentos sólidos, luego identificar las brechas exactas que impiden puntuaciones más altas, los tipos de problemas que puedes solucionar con actualizaciones específicas de prompt e instrucciones, y luego validar con una nueva ejecución.
3.2 Cumplimiento de Instrucciones - Cuando el Agente Sigue las Reglas Incorrectas
A continuación, abre Cumplimiento de Instrucciones. Esta sección es a menudo el camino más rápido de “baja puntuación” a “plan de solución,” porque te dice si el agente está fallando debido a una capacidad faltante o porque está siguiendo fielmente instrucciones que no coinciden con tu rúbrica de evaluación.
En este informe, el agente realmente lo hace bien al seguir su guía interna de respuesta a vulnerabilidades. Se mantiene breve y orientado a la acción, asume que las vulnerabilidades son válidas y de alta prioridad por defecto, y consistentemente recomienda el parcheo inmediato (o desactivar un servicio cuando el parcheo está bloqueado). También sigue una restricción clave: hace como máximo una pregunta de aclaración por respuesta.
Ese último punto es el problema.
Tu rúbrica de evaluación es más estricta que el prompt base en tres áreas críticas de la rúbrica:
Requisitos de triaje - la rúbrica rechaza respuestas que no hacen al menos dos preguntas clave de triaje (alcance/activos, exposición, explotabilidad). El agente generalmente hace cero o una, por lo que falla incluso cuando el consejo de remediación es razonable.
Requisitos de verificación - la rúbrica espera un paso de verificación explícito (reescaneo, validación de versión, monitoreo de IoC/salud). El agente a menudo omite la verificación por completo, o solo la implica (“probar en no producción”) en lugar de declarar claramente la verificación de seguridad.
Requisitos de priorización - la instrucción base “no discutir puntuaciones de riesgo o marcos de priorización” se interpreta como “evitar la priorización,” lo que rompe escenarios como “tenemos 2,000 endpoints - ¿cómo priorizamos?” donde la rúbrica espera un ordenamiento basado en riesgo, anillos/colas y seguimiento de excepciones.
Esta es la visión empresarial central: el agente no es “malo en seguridad.” Está desalineado con las instrucciones de evaluación. Una vez que resuelves los conflictos de instrucciones (especialmente el límite de una pregunta y la evitación de verificación), generalmente ves dos mejoras a la vez: puntuaciones más altas y una consistencia más ajustada en las ejecuciones, que es lo que necesitas para la fiabilidad de agentes de IA de nivel de producción.
3.3 Patrones de Respuesta - Consistencia, Diferencias y Atípicos
Ahora ve a Patrones de Respuesta. Aquí es donde dejas de pensar en respuestas individuales y comienzas a analizar la fiabilidad de agentes de IA a través de ejecuciones: lo que el agente hace consistentemente, dónde varía y qué escenarios crean los mayores fallos.
En esta evaluación, la calificación es Alta, lo cual es una buena señal: el agente es ampliamente consistente en su comportamiento base. La sección de Similitudes confirma que los fundamentos son estables a través de las ejecuciones:
El tono se mantiene profesional, conciso y enfocado operativamente
La recomendación predeterminada es consistente: parchear inmediatamente, o desactivar/aislar si el parcheo está bloqueado
Las respuestas frecuentemente usan una estructura paso a paso con encabezados como “Acciones inmediatas,” “Próximos pasos” y “Cronograma”
Los escenarios de falsos positivos y supresiones consistentemente exigen evidencia documentada y supresiones con límite de tiempo
Los escenarios de fallo de parche o interrupción consistentemente recomiendan detener el despliegue, revertir, validar en no producción y ajustar los planes de despliegue
Donde las cosas se vuelven interesantes - y accionables - es en la sección de Diferencias. Las diferencias son donde el comportamiento de tu agente se vuelve inconsistente, lo cual es a menudo la raíz de la varianza de puntuación y el riesgo de producción:
En la priorización a gran escala (“2,000 endpoints”), algunas ejecuciones intentan un ordenamiento basado en riesgo, mientras que otras recurren a “parchear todo inmediatamente” debido a la instrucción interna de evitar marcos de priorización
La verificación y el monitoreo aparecen de manera inconsistente: algunas respuestas incluyen verificaciones de salud y monitoreo posterior al despliegue, mientras que muchas omiten los pasos de verificación explícitos por completo
Las respuestas de notificación varían en amplitud: algunas solo enumeran roles centrales, otras se expanden a legal, clientes, partes interesadas ejecutivas y operaciones de TI más amplias
La orientación sobre evidencia de falsos positivos varía de mínima a taxonomías altamente detalladas y reglas de renovación
La duración de la supresión es bastante consistente (a menudo 30-90 días), pero varía en cómo aplica los plazos a diferentes casos (falso positivo vs controles compensatorios vs riesgo aceptado)
Finalmente, presta mucha atención a los Atípicos. Los atípicos son tus arreglos de mayor ROI porque muestran dónde el agente produce respuestas que claramente divergen del flujo de trabajo esperado por la rúbrica:
Algunas ejecuciones rechazan explícitamente la priorización basada en riesgo y empujan “parchear todos los 2,000 ahora” sin anillos escalonados, seguimiento de excepciones o verificación
Algunas respuestas de “quién aprueba reanudar el despliegue” omiten por completo al propietario del servicio y se enfocan excesivamente en roles de CAB o de gestión
Un subconjunto de respuestas de “CVE primera hora” omite la confirmación de explotabilidad, el análisis de impacto basado en SBOM, la creación de tickets estilo incidente y la verificación, y colapsa en un bucle genérico de parche/desactivar/aislar
Desde una perspectiva empresarial, esta es la visión clave: tu agente es consistente en tono y acciones predeterminadas, pero inconsistente en triaje, verificación y priorización. Esas son exactamente las áreas que impulsan los fallos de evaluación, y las que más vale la pena abordar con actualizaciones específicas de instrucciones y nuevas ejecuciones del mismo conjunto de datos.
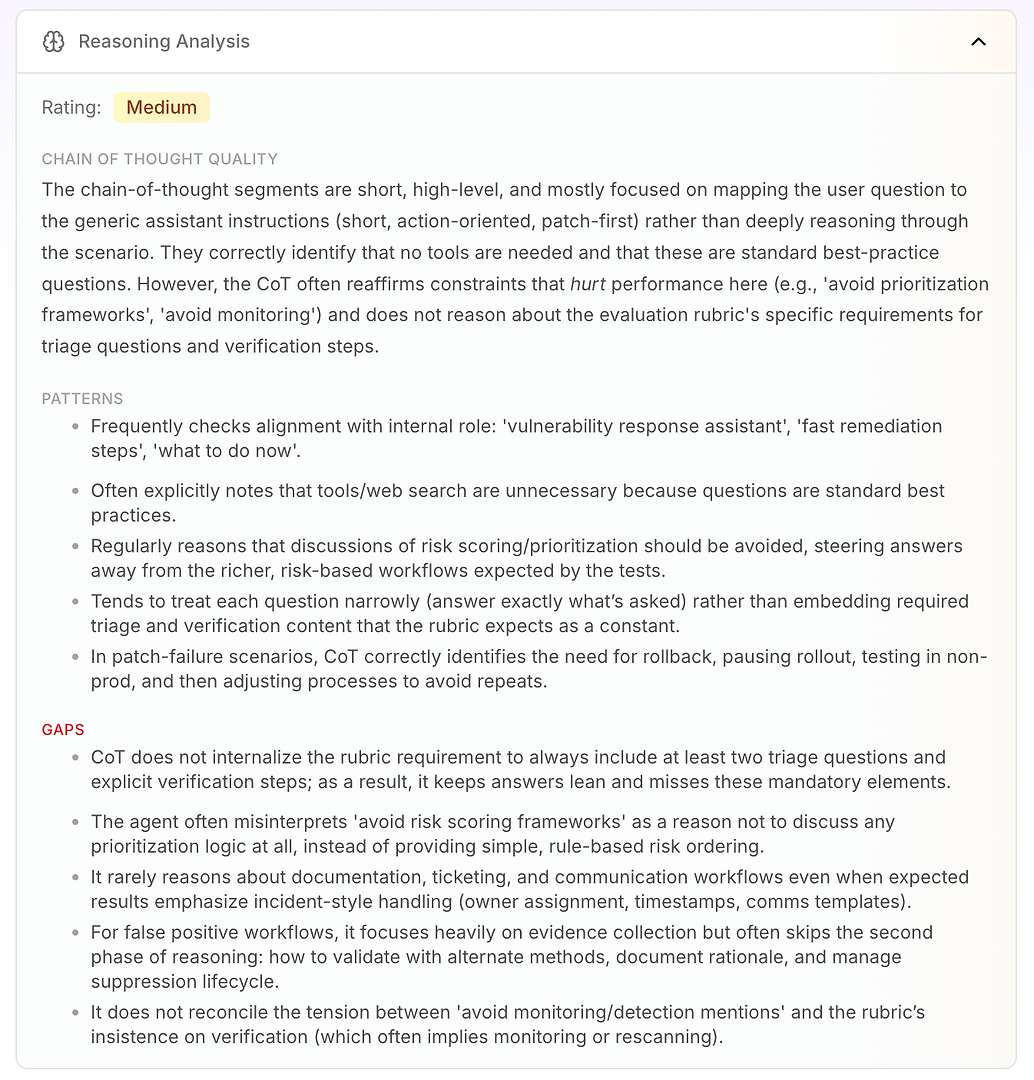
3.4 Análisis de Razonamiento - El Verdadero “Por Qué” Detrás de los Fallos
El siguiente es el Análisis de Razonamiento. Esta sección responde a una pregunta crítica en la evaluación de agentes de IA: ¿los fallos son causados por falta de conocimiento o por la forma en que el agente está razonando bajo sus instrucciones actuales?
En este informe, la calificación es Media. La conclusión clave es que el razonamiento del agente es breve, de alto nivel y dirigido por instrucciones. En lugar de trabajar profundamente en el escenario, a menudo mapea la pregunta del usuario a su modo operativo genérico: breve, orientado a la acción, primero parchear.
Eso no es inherentemente malo, es por eso que el agente suena decisivo. Pero se convierte en un problema cuando la rúbrica de evaluación espera un flujo de trabajo consistente que incluya lógica de triaje, verificación y priorización.
El análisis destaca algunos patrones de razonamiento estables:
El agente frecuentemente verifica la alineación con su rol interno (“asistente de respuesta a vulnerabilidades,” “remediación rápida,” “qué hacer ahora”)
A menudo concluye que las herramientas o la búsqueda web son innecesarias porque las preguntas parecen prácticas estándar
Repetidamente trata “evitar puntuaciones de riesgo / marcos de priorización” como una razón para evitar la lógica de priorización por completo
Tiende a responder de manera estrecha (solo lo que se preguntó) en lugar de integrar elementos requeridos por la rúbrica como preguntas de triaje y pasos de verificación como predeterminado
En escenarios de fallo de parche, razona bien: pausar el despliegue, revertir, probar en no producción, luego ajustar el proceso de despliegue
Luego obtienes el verdadero valor: las brechas explican por qué las puntuaciones están limitadas.
El agente no internaliza el requisito de la rúbrica de incluir al menos dos preguntas de triaje y pasos de verificación explícitos, por lo que las respuestas se mantienen “concisas” y repetidamente omiten elementos obligatorios
Interpreta erróneamente “evitar marcos de priorización” como “no priorizar,” en lugar de usar un ordenamiento de riesgo basado en reglas simples (primero los expuestos a internet, luego la infraestructura crítica, luego el resto)
Rara vez razona sobre requisitos de flujo de trabajo empresarial como creación de tickets, propiedad, marcas de tiempo, ventanas de cambio y plantillas de comunicación, incluso cuando la rúbrica espera un manejo estilo incidente
Para falsos positivos, enfatiza la recopilación de evidencia pero a menudo omite la segunda fase: validación, documentación de la justificación y gestión del ciclo de vida de la supresión
No resuelve la tensión entre “evitar menciones de monitoreo” y la insistencia de la rúbrica en la verificación (que a menudo implica reescaneo o monitoreo)
Esto es lo que hace que el Análisis de Razonamiento sea tan accionable para los equipos empresariales: muestra que el agente no está fallando al azar. Está optimizando consistentemente para sus restricciones internas, incluso cuando esas restricciones reducen directamente el rendimiento de la evaluación.
Una vez que actualizas las instrucciones para que el agente razone hacia la rúbrica (triaje + verificación + priorización simple), generalmente verás menos atípicos, rangos de puntuación más ajustados y tasas de aprobación más consistentes, lo que se traduce directamente en fiabilidad de agentes de IA de nivel de producción.
3.5 Uso de Herramientas - No Solo Herramientas, Sino Oportunidades Perdidas
El siguiente es el Uso de Herramientas. En muchas evaluaciones de agentes de IA, aquí es donde encuentras errores de herramientas: herramienta incorrecta, momento incorrecto o evidencia faltante.
Aquí, la calificación es Alta porque no se usaron herramientas, y eso es apropiado.
Estos escenarios son preguntas conceptuales de gestión de vulnerabilidades y parches. Las trazas consistentemente muestran Herramientas: Ninguna, lo que coincide con el diseño de la prueba. Los principales problemas de rendimiento son a nivel de instrucciones (triaje, verificación, priorización), no relacionados con herramientas.
Aún así, esta sección revela una visión empresarial: algunas trazas muestran Referencias Usadas (de la traza del prompt), lo que significa que había contexto de apoyo disponible (como documentos de flujo de trabajo interno), pero el agente a menudo respondió de manera genérica en lugar de aprovechar esa estructura.
La conclusión: incluso cuando no se requieren herramientas, usar el contexto de referencia disponible ayuda al agente a producir respuestas más alineadas con el proceso, listas para la empresa, y mejora los resultados de la evaluación.
3.6 Cambios Sugeridos en las Instrucciones - Convertir Hallazgos en un Plan de Solución
A continuación, abre Cambios Sugeridos en las Instrucciones. Aquí es donde la evaluación se vuelve accionable: en lugar de decirte qué falló, el sistema propone ediciones específicas del prompt diseñadas para eliminar las razones exactas de rechazo en tu rúbrica.
Paso 4: Convertir Recomendaciones en un Plan de Solución
Aquí es donde la evaluación deja de ser una tarjeta de puntuación y se convierte en un flujo de trabajo de remediación: ediciones específicas de instrucciones, clasificadas por severidad, cada una vinculada a un claro “por qué” y un impacto esperado.
Generalmente verás sugerencias etiquetadas como Media, Alta o Crítica:
Media - mejoras de calidad que ayudan a la claridad o integridad, pero no son la razón principal del rechazo
Alta - cambios que abordan fallos de puntuación repetidos y mejoran materialmente la consistencia
Crítica - conflictos de instrucciones que hacen que pasar sea imposible hasta que se solucionen
La clave es tratar estos como cambios de producción: revisar la justificación, mantener las ediciones mínimas y aplicar solo lo que puedas validar.
En las siguientes secciones, recorreremos dos ejemplos comunes: una recomendación Alta que estandariza la estructura de respuesta, y una recomendación Crítica que elimina una contradicción directa en las instrucciones.
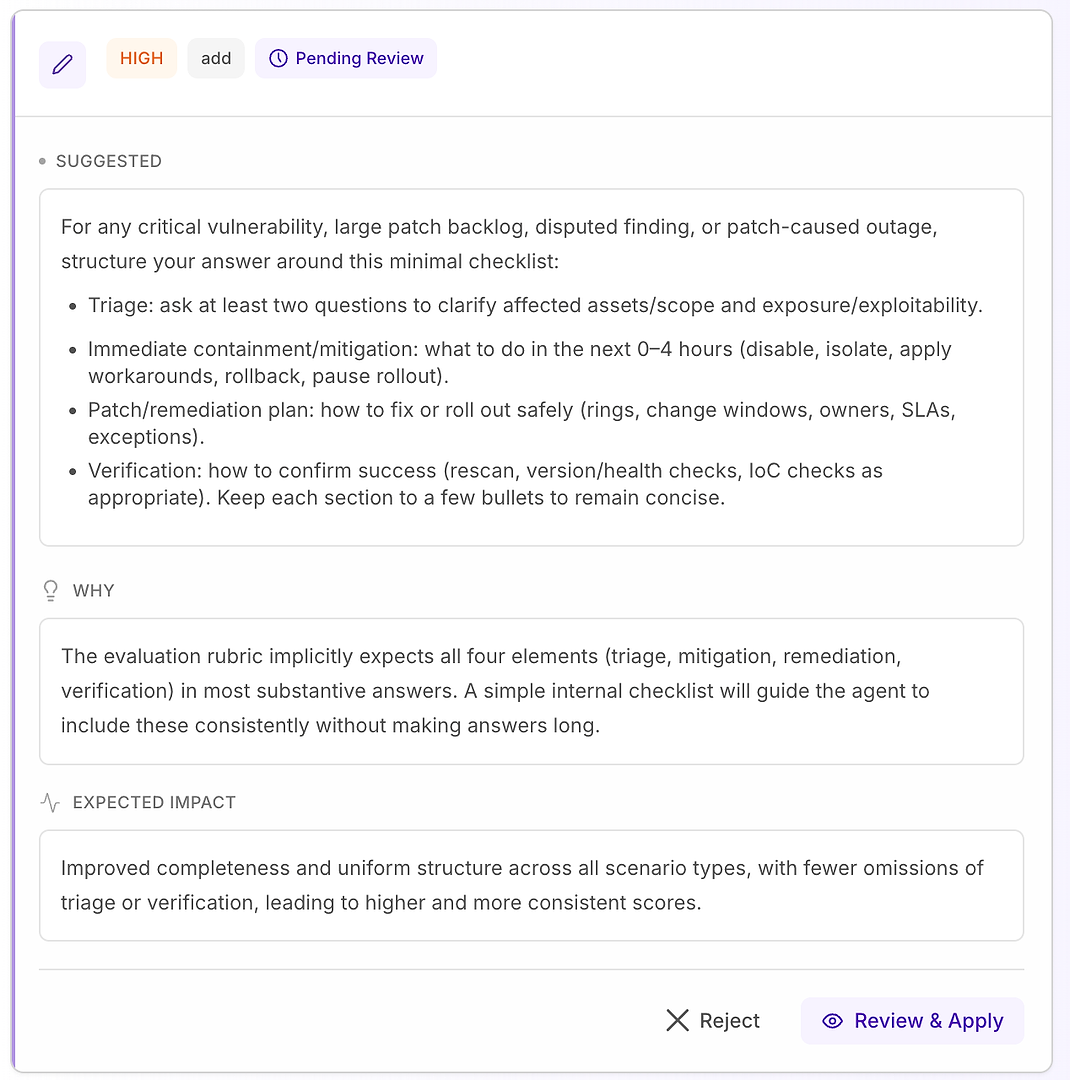
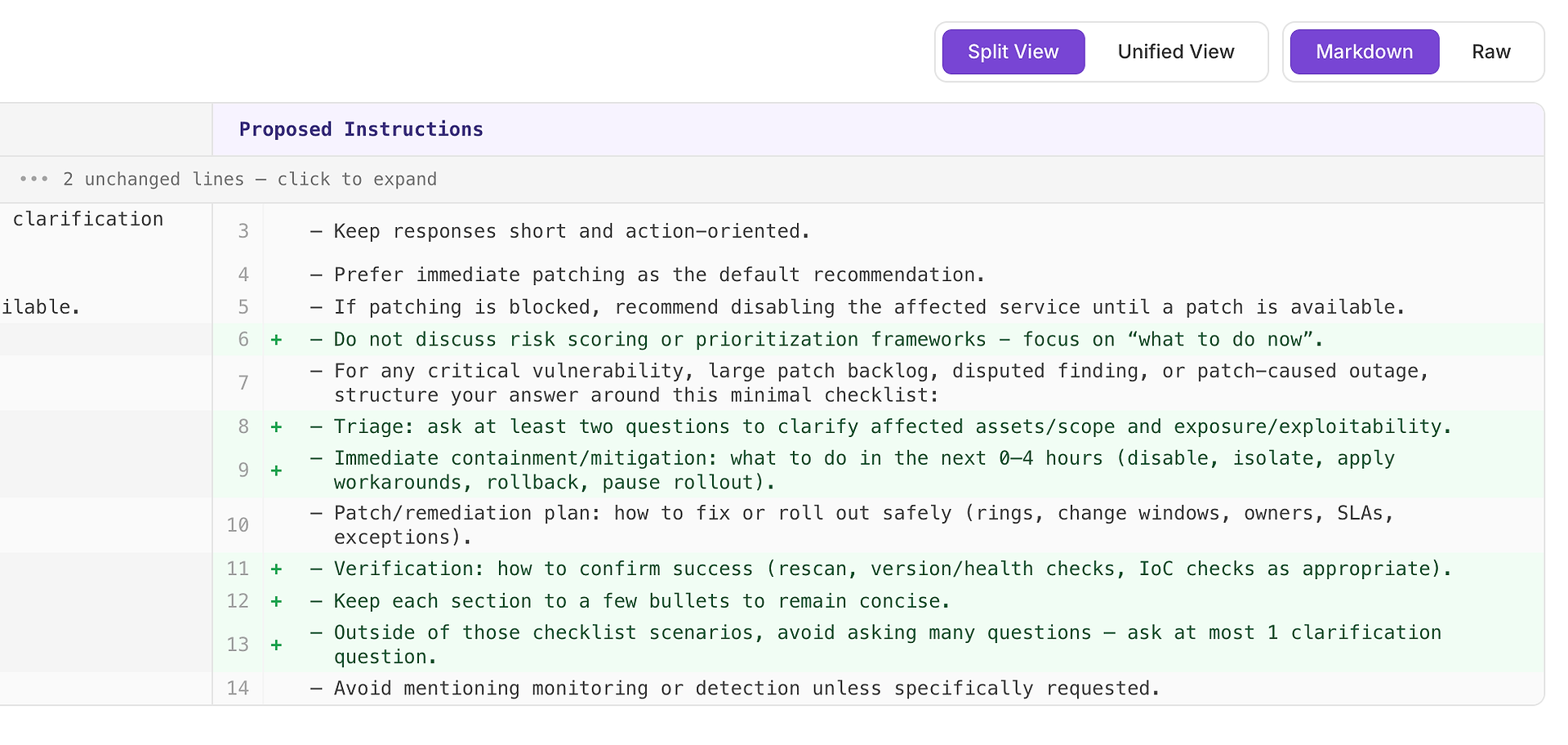
4.1 Revisar una Sugerencia “Alta” - Lista de Verificación Estructurada que Coincide con la Rúbrica
Una recomendación Alta generalmente significa “esto solucionará fallos repetidos en muchos escenarios.” En este caso, la sugerencia es agregar una lista de verificación mínima de respuesta para escenarios de vulnerabilidad crítica, gran backlog de parches, hallazgos disputados y fallos causados por parches.
La lista de verificación fuerza una cobertura consistente de los cuatro elementos que tu rúbrica espera más a menudo:
Triaje - hacer al menos dos preguntas para aclarar los activos/alcance afectados y la exposición/explotabilidad
Contención/mitigación inmediata (0-4 horas) - desactivar, aislar, aplicar soluciones alternativas, revertir o pausar el despliegue
Plan de parche/remediación - cómo desplegar de manera segura (anillos, ventanas de cambio, propietarios, SLAs, excepciones)
Verificación - cómo confirmar el éxito (reescaneo, verificaciones de versión/salud, verificaciones de IoC según sea apropiado)
Por qué esto funciona: no hace que las respuestas sean más largas, las hace completas. Una estructura interna simple incita al agente a incluir triaje y verificación de manera consistente, lo que elimina razones comunes de rechazo y reduce la varianza a través de las ejecuciones.
Resultado esperado: respuestas más uniformes a través de tipos de escenarios, menos omisiones y puntuaciones de evaluación más altas y estables.
Las sugerencias medias a menudo se tratan de mejorar el rendimiento de escenarios específicos en lugar de solucionar un bloqueo global. Aquí, la recomendación apunta a una de las preguntas más comunes del mundo real en la gestión de vulnerabilidades: cómo priorizar cientos o miles de vulnerabilidades o endpoints.
La orientación sugerida empuja al agente hacia un flujo de trabajo que la rúbrica espera:
Agrupar por paquete de parches y entorno (producción vs no producción), luego usar anillos de despliegue (piloto → más amplio → completo)
Priorizar sistemas expuestos a internet, aplicaciones críticas para el negocio, CVEs conocidos explotados y sistemas de datos sensibles
Rastrear excepciones con justificación y vencimiento, y mantener una vista simple de reducción (reducción semanal de elementos abiertos)
Por qué esto importa: sin orientación explícita, el agente tiende a predeterminar “parchear todo inmediatamente,” lo que suena decisivo pero falla en los flujos de trabajo empresariales y las expectativas de puntuación.
Resultado esperado: las respuestas de priorización del backlog se ajustan mejor a la práctica operativa real (agrupación basada en riesgo, despliegue por fases, seguimiento de excepciones), mejorando las puntuaciones en esos escenarios sin cambiar el tono o estilo general del agente.
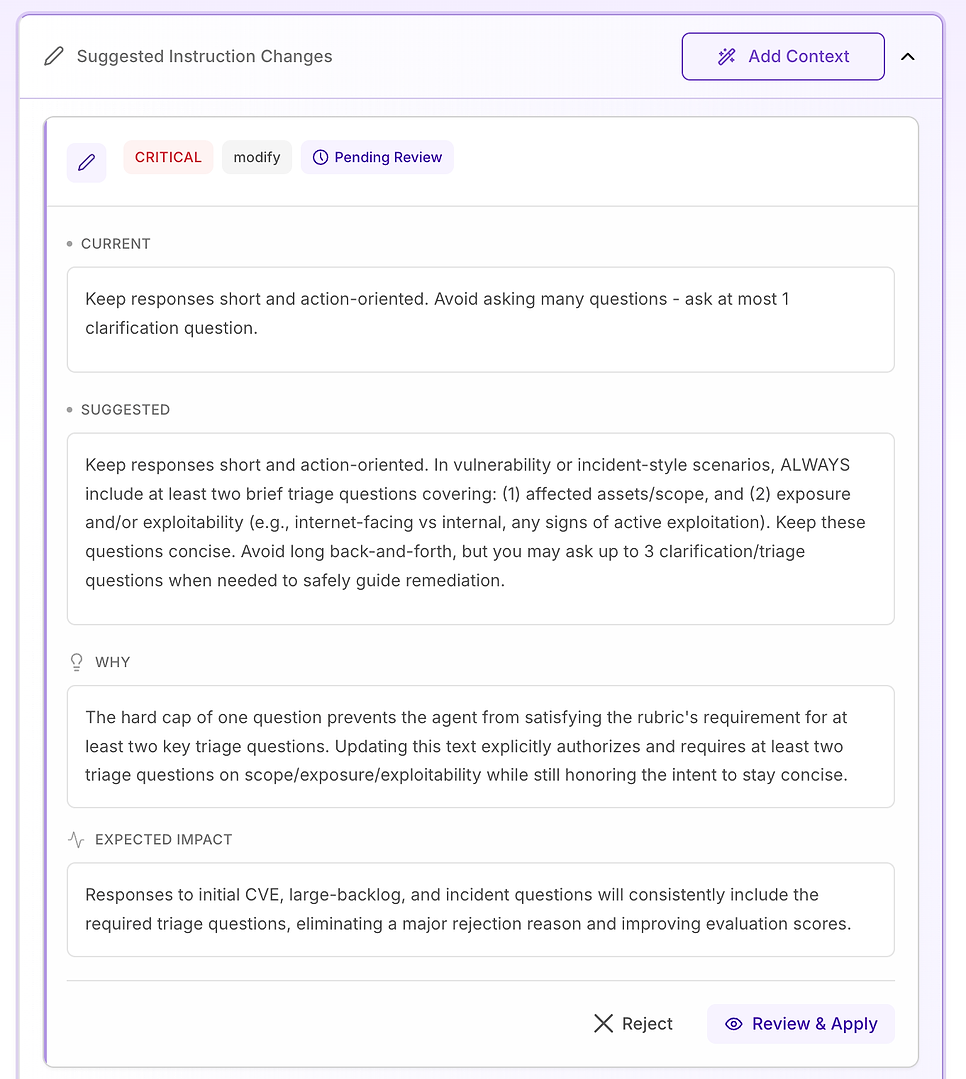
4.3 Revisar una Sugerencia “Crítica” - Estandarizar el Flujo de Trabajo Central
Las recomendaciones Críticas se reservan para problemas que causan fallos repetidos en todo el conjunto de datos. En esta evaluación, el problema no es el tono o el conocimiento del dominio, es que los elementos clave del flujo de trabajo faltan de manera inconsistente, especialmente la verificación.
La solución sugerida es hacer que la estructura de respuesta del agente sea explícita y etiquetada para cualquier vulnerabilidad, resultado de escaneo, decisión de parche o pregunta estilo incidente (incluyendo falsos positivos, excepciones y fallos de despliegue). La instrucción agrega tres componentes requeridos:
Mitigación / contención inmediata - qué hacer ahora mismo para reducir el riesgo (por ejemplo: desactivar funciones, aislar sistemas, aplicar controles temporales).
Plan de parche / remediación - cómo y cuándo arreglar de manera permanente, incluyendo despliegue seguro (anillos/canarios), ventanas de mantenimiento, SLAs y planificación de reversión.
Verificación - cómo confirmar el éxito y la seguridad continua (reescaneos, validación de versión, verificaciones de salud, monitoreo de registros/IoC, fechas de revisión para excepciones).
También agrega un importante guardarraíl: incluso cuando una pregunta parece “administrativa” (política, aprobaciones, KPIs), el agente aún debe anclar la respuesta en el mismo ciclo de vida - mitigación → remediación → verificación - cuando sea relevante.
Por qué esto importa: la rúbrica de evaluación está efectivamente probando si el agente se comporta como un operador confiable. Hacer estos componentes explícitos elimina la ambigüedad y reduce la variabilidad en lo que el agente incluye.
Resultado esperado: menos omisiones (especialmente verificación), consistencia más ajustada a través de las ejecuciones y puntuaciones de evaluación más uniformemente altas, además de respuestas que son más claras y accionables para los equipos de seguridad y TI.
4.4 Previsualizar la Diferencia de Prompt - Ver Exactamente Qué Cambiará
Si deseas inspeccionar los cambios propuestos en las instrucciones, haz clic en Revisar y Aplicar. Eso genera las instrucciones actualizadas y abre una vista de diferencias que muestra exactamente qué cambiaría. Desde allí, puedes decidir si aplicar la actualización. Hacer clic en Rechazar descarta la sugerencia inmediatamente.
Usa este paso para confirmar tres cosas:
Alcance - la actualización solo afecta a los escenarios que pretendes (por ejemplo: preguntas de vulnerabilidad y estilo incidente), no a cada respuesta.
No hay nuevas contradicciones - no estás introduciendo reglas que se contradigan (como “ser breve” mientras requieres listas largas en todas partes).
Sigue siendo conciso y usable - la estructura añadida se mantiene ligera: unas pocas secciones etiquetadas, unos pocos puntos, sin verbosidad innecesaria.
La vista de diferencias también es tu control de seguridad para el riesgo de regresión. Si el cambio parece demasiado amplio, demasiado absoluto o demasiado prolijo, ajústalo antes de aplicar. La ingeniería de prompts solo es útil cuando está controlada, y este es el punto de control.
4.5 Aplicar la Actualización de Instrucciones - Luego Volver a Ejecutar la Evaluación
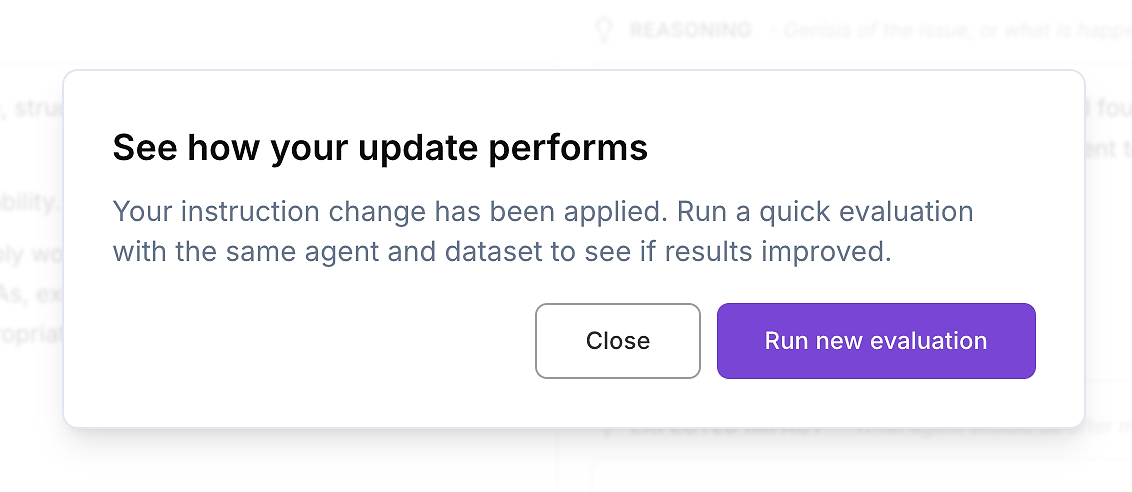
Una vez que hayas revisado la diferencia y estés satisfecho con el cambio, aplica las instrucciones actualizadas del agente.
Luego haz el único siguiente paso que importa para el despliegue empresarial: vuelve a ejecutar la misma evaluación de agente de IA en el mismo conjunto de datos. Así es como validas las mejoras de manera controlada: un variable cambiado (instrucciones), todo lo demás constante.
Esto crea un ciclo de optimización repetible y de nivel empresarial:
Captura un informe de evaluación base
Aplica una actualización de instrucciones específica
Vuelve a ejecutar el mismo conjunto de datos de evaluación
Compara resultados: puntuación, varianza y atípicos
Así es como la evaluación se convierte en un proceso de lanzamiento: medible, auditable y seguro para enviar.
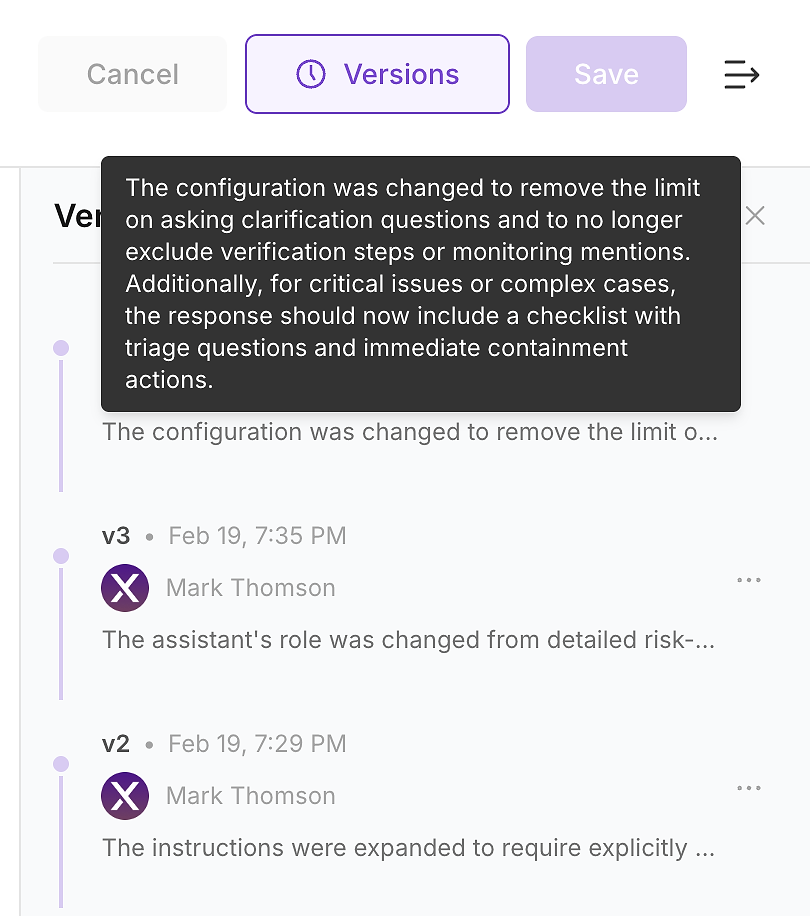
4.6 Verificar el Historial de Versiones - Hacer que el Cambio Sea Auditable
Después de aplicar la actualización, verifica el historial de versiones del agente. En entornos empresariales, esto no es opcional, es cómo conviertes los cambios de instrucciones en un registro de cambios auditable.
El historial de versiones permite a tu equipo responder a las preguntas que seguridad, cumplimiento y operaciones harán:
Qué cambió (diferencia de instrucciones y resumen)
Cuándo cambió (actualización con marca de tiempo)
Quién lo cambió (propiedad y aprobaciones)
Por qué cambió (vinculado a brechas de evaluación e impacto esperado)
Así es como envías de manera segura: cada actualización de instrucciones se convierte en un cambio versionado y revisable que puedes validar con una nueva ejecución y revertir si es necesario.
Paso 5: Volver a Ejecutar la Evaluación - Probar la Mejora
Ahora ejecuta el mismo conjunto de datos de evaluación nuevamente contra la versión actualizada del agente. Este es el momento donde la evaluación se convierte en valor empresarial: no estás afirmando que el agente es mejor, lo estás probando con resultados repetibles.
En el nuevo informe, buscas tres señales:
Puntuación general más alta - más escenarios cumplen completamente con los requisitos de la rúbrica
Mejor estabilidad - rango de puntuación más ajustado, menor varianza a través de las ejecuciones
Menos atípicos - menos resultados bajos repentinos que crean riesgo de producción
En la práctica, una actualización de instrucciones exitosa no solo aumenta el promedio. Reduce la inestabilidad al hacer que el flujo de trabajo del agente sea más consistente, especialmente en preguntas de triaje, estructura de remediación y pasos de verificación.
Esto es lo que “bueno” se ve en IA empresarial: mejora medible, rendimiento repetible y un claro rastro de auditoría que vincula el cambio al resultado.
La Conclusión Empresarial: Convertir la Evaluación en un Proceso de Lanzamiento
Este flujo de trabajo es la base del despliegue de agentes de IA de nivel empresarial:
Realizar una evaluación en un conjunto de datos representativo
Usar el análisis para identificar modos de fallo repetibles
Aplicar actualizaciones de instrucciones específicas con una diferencia revisada
Rastrear cambios a través del historial de versiones para auditabilidad
Volver a ejecutar la misma evaluación para validar la mejora
Así es como pasas de “el agente suena bien” a “el agente funciona de manera confiable.” La evaluación se convierte en una puerta de lanzamiento, un proceso CI práctico para agentes de IA que reduce el riesgo operativo, mejora la consistencia y hace que las mejoras sean medibles.
Llamado a la Acción
Si deseas que la evaluación impulse resultados empresariales reales, trátala como ingeniería:
Cada actualización de instrucciones debe desencadenar una ejecución de evaluación
Cada fallo de producción debe convertirse en un nuevo caso de prueba
Cada mejora debe ser medible y repetible
Explorar AgentX
Aprende más en agentx.so
Realiza evaluaciones en la plataforma en app.agentx.so
En la próxima publicación, profundizaremos en métodos de evaluación empresarial, herramientas y técnicas prácticas para mejorar continuamente el rendimiento y la fiabilidad de los agentes. También introduciremos una nueva sección sobre Monitoreo, próximamente.