Évaluation d’agent AIPresentation des évaluations d’agents : la manière la plus fiable de comprendre et d’améliorer vos agents AI
Les agents AI deviennent plus avancés, plus capables et plus profondément intégrés aux entreprises.
Mais il existe un problème universel auquel chaque équipe est confrontée :
Votre agent ne répond pas toujours comme vous l’attendez — et vous ne savez pas pourquoi.
Parfois le raisonnement change, parfois l’agent ignore une règle, parfois l’outil n’a pas été utilisé correctement, et parfois une instruction subtile a été mal comprise. Sans visibilité sur comment les décisions ont été prises, améliorer l’agent ressemble à un jeu de devinettes.
C’est exactement pour cela que nous avons créé Agent Evaluations — un nouveau système dans AgentX qui vous permet de tester, mesurer et analyser en profondeur le comportement de votre agent sur plusieurs exécutions de la même question.
C’est la première fois que vous pouvez voir à l’intérieur de la prise de décision de votre agent, trouver des incohérences et comprendre précisément où des améliorations sont nécessaires.
Pourquoi les évaluations comptent
Les modèles AI sont probabilistes.
Même avec le même prompt, le même contexte et les mêmes règles, le modèle peut :
produire des chemins de raisonnement légèrement différents
omettre un détail requis
mal interpréter une politique
passer une recherche d’outil
donner des réponses incertaines au lieu de la réponse définitive attendue
déléguer de manière incohérente au sein d’une équipe
De l’extérieur, vous ne voyez que la réponse finale.
Vous ne voyez pas :
si l’agent a suivi vos instructions
s’il a utilisé les bons outils
s’il a correctement raisonné
pourquoi une version de la réponse était plus faible qu’une autre
pourquoi il réussit parfois — et parfois se trompe
Les évaluations résolvent cela en vous apportant structure, scoring et transparence.
Créer une évaluation est simple :
0. Sélectionnez l’agent ou l’équipe que vous souhaitez évaluer.
1. Question de test
C’est la question du monde réel que vous souhaitez valider.
Elle simule une question client ou une demande de workflow interne.
Exemple :
« Puis-je retourner un article en Final Sale s’il ne me va pas ? »
Cela constitue le cœur de l’évaluation.
2. Résultats attendus (obligatoire)
C’est la partie la plus importante de la configuration.
Ici, vous définissez ce que l’agent DOIT dire ou inclure pour que la réponse soit considérée comme correcte.
Cela peut contenir :
des faits clés
des formulations obligatoires
des étapes de raisonnement requises
des règles de conformité
un ton spécifique ou des déclarations de politique
Exemple :
« Doit dire : Non, les articles en Final Sale ne sont ni retournables ni échangeables. »
Les résultats attendus deviennent la grille de scoring pour toutes les exécutions de test.
3. Capacités attendues (optionnel mais puissant)
Vous pouvez indiquer au système d’évaluation quels outils, documents ou sources de connaissance l’agent devrait utiliser.
Dans votre exemple, vous avez sélectionné :
Documents → store_policy_kb_v1.xlsx
Built-in Functions
Cela signifie :
L’agent devrait récupérer les informations depuis la KB de politique.
S’il n’utilise pas correctement la KB, l’évaluation le détectera.
C’est parfait pour :
les agents de politique
les agents de service client
les workflows de conformité
la modélisation financière
le raisonnement appuyé par des données
4. Paramètres d’évaluation
Cette section définit à quel point et en profondeur votre évaluation doit être rigoureuse.
Nombre d’exécutions de test
La même question est exécutée plusieurs fois (Recommandé : 5 exécutions).
Pourquoi ?
Parce que les modèles AI ne sont pas déterministes. Plusieurs exécutions vous permettent de vérifier :
la cohérence
la stabilité
la fiabilité du raisonnement
si l’agent suit le même processus à chaque fois
Si l’agent produit une bonne réponse et quatre échecs, vous le verrez instantanément.
Critères d’acceptation
Ce curseur définit à quel point la réponse doit correspondre strictement à vos résultats attendus.
Vous choisissez un point entre :
Lenient → l’agent peut s’écarter de vos attentes ; la réponse n’a pas besoin d’être parfaite.
Exact → la réponse doit suivre vos attentes de très près, avec presque aucune marge de variation.
Cela contrôle simplement à quel point la réponse doit être exacte pour réussir l’évaluation.
Critères de rejet (optionnel)
Règles d’échec automatique.
Exemples :
« La réponse ne doit pas mentionner des concurrents. »
« Ne pas proposer de remboursements lorsque la politique l’interdit. »
« La réponse ne doit pas demander à l’utilisateur de fournir des informations personnelles. »
Ce sont des contraintes strictes.
Critères d’évaluation (optionnel)
Guidage de scoring supplémentaire, souvent utilisé pour la qualité ou le ton.
Exemples :
« La réponse doit être amicale et professionnelle. »
« La réponse doit contenir une courte explication, pas seulement un oui/non. »
« Utiliser les faits de la KB avant les suppositions. »
Ce ne sont pas des exigences strictes, mais elles aident à orienter la manière dont l’AI évalue l’agent.
5. Créer l’évaluation
Une fois configuré, cliquer sur Create Evaluation lance le processus :
la question est exécutée plusieurs fois
chaque réponse est notée
une analyse détaillée est générée
la délégation et l’utilisation des outils sont inspectées
les incohérences sont mises en évidence
Et vous obtenez un rapport complet de performance.
Ce que vous obtenez après l’exécution de l’évaluation
Après plusieurs exécutions, AgentX fournit deux niveaux de sortie :
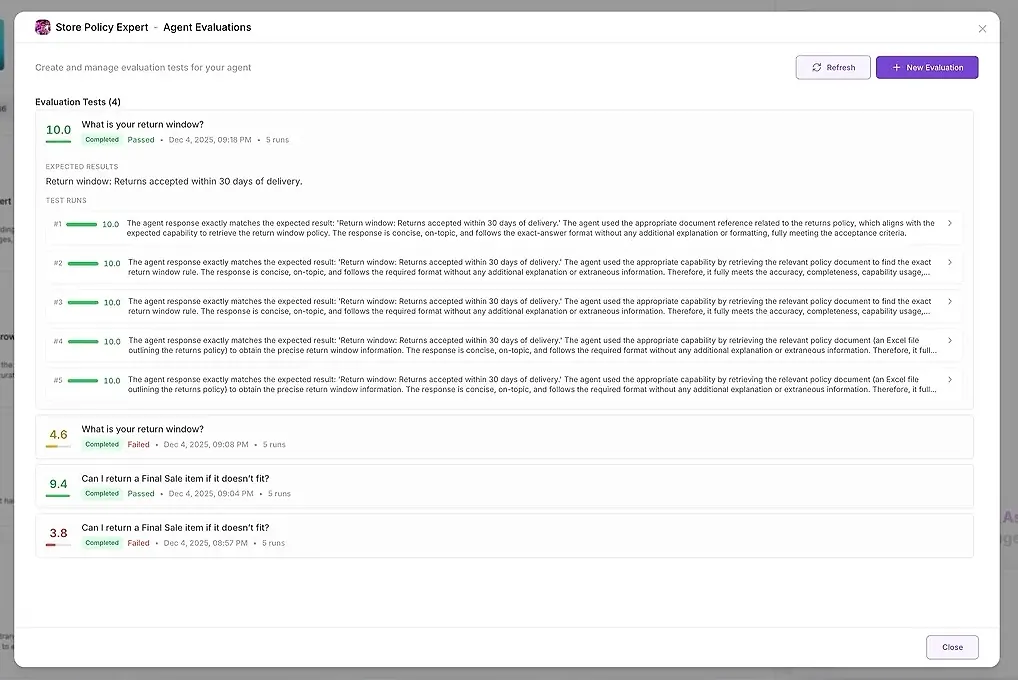
1. Résultats de test
Pour chaque exécution, vous voyez :
un score numérique
un résumé de la correspondance avec vos attentes
la réponse complète
quels outils ont été utilisés
quels agents ont participé
où l’agent a échoué ou s’est écarté
Cela vous permet de comparer les réponses côte à côte et d’identifier des schémas.
2. Analyse AI approfondie
C’est là que la vraie magie opère.
AgentX analyse automatiquement toutes les exécutions et génère un rapport structuré dans plusieurs catégories :
• Respect des instructions
L’agent a-t-il suivi vos règles ?
• Schémas de réponse
À quel point les réponses étaient-elles similaires ou différentes ?
Y a-t-il des valeurs aberrantes ?
• Analyse du raisonnement
Les étapes de raisonnement étaient-elles correctes, complètes et alignées avec les attentes ?
• Utilisation des outils
L’agent a-t-il utilisé le bon outil ?
A-t-il sauté une recherche ?
S’est-il appuyé sur des suppositions plutôt que sur des faits vérifiés ?
• Recommandations
Des suggestions concrètes et actionnables pour améliorer votre agent.
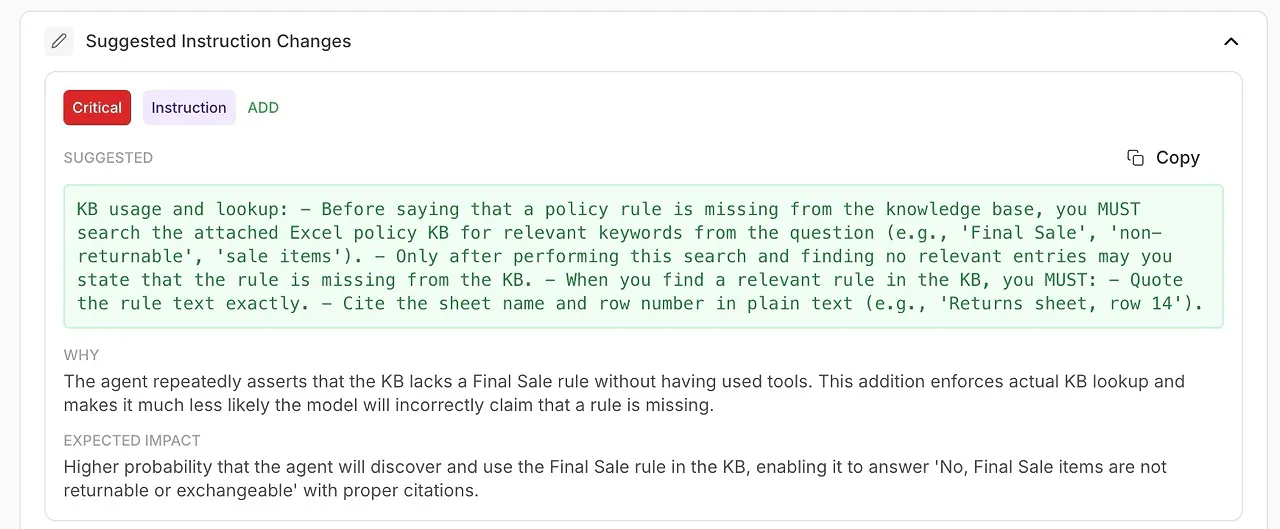
• Changements d’instructions suggérés
Des améliorations générées automatiquement pour votre system prompt ou la configuration de l’agent.
• Évaluation globale
Un résumé des forces, des faiblesses et du niveau de confiance.
Cela transforme le débogage d’un jeu de devinettes en un processus scientifique et reproductible.
Ce que cette fonctionnalité rend possible
Les évaluations introduisent un nouveau niveau de transparence et de fiabilité dans le fonctionnement de vos agents. Au lieu de deviner pourquoi une réponse était incorrecte ou incohérente, vous disposez désormais d’une méthode structurée et mesurable pour comprendre le comportement, diagnostiquer les problèmes et améliorer continuellement les performances.
Voici ce qui devient possible :
🔍 Valider votre agent avant de le lancer auprès des clients
Avant de déployer un agent en production, vous pouvez exécuter des tests réalistes qui révèlent s’il comprend pleinement vos règles, votre base de connaissances et le ton souhaité. Plus de surprises après le déploiement — vous savez exactement ce que les utilisateurs vivront.
🤖 Tester toute votre équipe d’agents et la logique de délégation
Pour les configurations multi-agents, les évaluations montrent comment votre manager délègue les tâches, quels sous-agents participent et s’ils suivent le workflow attendu. Vous pouvez rapidement détecter :
des délégations inutiles
des délégations manquantes
des agents en conflit
un comportement de rôle incorrect
C’est essentiel pour un travail d’équipe fiable au sein de votre workforce AI.
📚 Détecter les points faibles de votre base de connaissances
Si une évaluation montre des échecs répétés sur un sujet spécifique, vous savez que le problème ne vient pas de l’agent — mais d’un contenu manquant ou peu clair. Les évaluations vous aident à affiner votre KB de manière ciblée et guidée par les données, au lieu d’ajouter aveuglément plus de matière.
🚨 Détecter tôt les hallucinations et l’incohérence
Parce que chaque question est testée plusieurs fois, les évaluations font remonter des problèmes subtils comme :
des réponses qui changent de manière imprévisible
un raisonnement qui dérive
des suppositions factuelles qui remplacent l’utilisation d’outils
des contradictions entre les exécutions
Ce sont des problèmes que vous n’identifieriez jamais en testant manuellement une ou deux fois.
🧠 Affiner les instructions système avec des améliorations générées par l’AI
L’analyse ne montre pas seulement ce qui a mal tourné — elle vous dit comment le corriger.
Vous recevez des recommandations actionnables, étayées par les diagnostics du modèle :
une formulation améliorée
des règles plus strictes
une utilisation obligatoire des outils
des politiques de délégation plus claires
un ton et une structure plus précis
C’est du prompt engineering automatisé, intégré directement à votre workflow.
📈 Mesurer les progrès à chaque mise à jour de votre agent
Chaque fois que vous modifiez :
un system prompt
une entrée de base de connaissances
un outil
une règle de délégation
une politique de raisonnement
…vous pouvez relancer la même évaluation et comparer les scores. Vous voyez exactement comment votre mise à jour a affecté les performances — positivement ou négativement.
Les évaluations deviennent votre boucle d’amélioration continue.
Que vous gériez du support, de l’analyse financière, des scénarios de santé ou du contenu juridiquement sensible, les évaluations vous permettent de garantir :
le respect des politiques
le respect des directives de ton
le signalement des lacunes dangereuses
la mise en évidence d’un raisonnement incorrect
le respect des standards de conformité
C’est particulièrement critique pour l’AI en entreprise et orientée client.
Utilisation et coûts
Les évaluations d’agents utilisent exactement le même modèle de crédits que le reste d’AgentX. Chaque exécution de test consomme simplement des crédits de la même manière qu’un message normal d’agent — pas de frais supplémentaires, pas de tarification cachée. Vous savez toujours exactement ce que vous dépensez, car les évaluations respectent les limites de votre plan existant et votre solde de crédits.
Votre couche de contrôle qualité pour l’AI
Dans les logiciels traditionnels, la QA garantit la fiabilité.
Dans AgentX, les évaluations sont votre QA pour les agents.
Vous définissez à quoi ressemble le « bon ».
AgentX vérifie si vos agents peuvent le fournir de manière cohérente — et vous montre exactement quoi améliorer lorsqu’ils n’y parviennent pas.
Les évaluations transforment l’AI d’une boîte noire en un système transparent, mesurable et améliorable.