एआई एजेंट मूल्यांकन: अपने एआई एजेंटों को समझने और सुधारने का सबसे विश्वसनीय तरीका
एआई एजेंट अधिक उन्नत, अधिक सक्षम और व्यवसायों में अधिक गहराई से एकीकृत हो रहे हैं।
लेकिन हर टीम को एक सार्वभौमिक समस्या का सामना करना पड़ता है:
आपका एजेंट हमेशा आपकी अपेक्षा के अनुसार जवाब नहीं देता - और आप नहीं जानते क्यों।
कभी-कभी तर्क बदल जाता है, कभी-कभी एजेंट एक नियम को अनदेखा कर देता है, कभी-कभी उपकरण का सही उपयोग नहीं किया गया, और कभी-कभी एक सूक्ष्म निर्देश को गलत समझा गया। कैसे निर्णय लिए गए, इस पर दृश्यता के बिना, एजेंट में सुधार करना अनुमान का खेल लगता है।
यही कारण है कि हमने एजेंट मूल्यांकन बनाया - AgentX के अंदर एक नया सिस्टम जो आपको एक ही प्रश्न के कई बार परीक्षण, माप और गहराई से विश्लेषण करने की अनुमति देता है कि आपका एजेंट कैसे व्यवहार करता है।
यह पहली बार है जब आप अपने एजेंट के निर्णय लेने के अंदर देख सकते हैं, असंगतियों को खोज सकते हैं, और समझ सकते हैं कि सुधार की आवश्यकता कहां है।
मूल्यांकन क्यों महत्वपूर्ण हैं
एआई मॉडल संभाव्यात्मक होते हैं।
यहां तक कि एक ही प्रॉम्प्ट, संदर्भ, और नियमों के साथ, मॉडल निम्नलिखित कर सकता है:
थोड़ा अलग तर्क पथ उत्पन्न कर सकता है
एक आवश्यक विवरण छोड़ सकता है
एक नीति का गलत अर्थ निकाल सकता है
एक उपकरण लुकअप को छोड़ सकता है
अपेक्षित निश्चित उत्तर के बजाय अनिश्चित उत्तर दे सकता है
टीम के अंदर असंगत रूप से कार्य सौंप सकता है
बाहर से, आप केवल अंतिम उत्तर देखते हैं।
आप नहीं देखते:
क्या एजेंट ने आपके निर्देशों का पालन किया
क्या उसने सही उपकरण का उपयोग किया
क्या उसने सही तर्क किया
क्यों एक संस्करण का उत्तर दूसरे से कमजोर था
क्यों कभी-कभी यह सही होता है — और कभी-कभी गलत
मूल्यांकन इसे संरचना, स्कोरिंग, और पारदर्शिता प्रदान करके हल करते हैं।
कैसे एक परीक्षण काम करता है
एक मूल्यांकन बनाना सरल है:
0. उस एजेंट या टीम का चयन करें जिसे आप मूल्यांकन करना चाहते हैं।
1. परीक्षण प्रश्न
यह वास्तविक दुनिया का प्रश्न है जिसे आप सत्यापित करना चाहते हैं।
यह एक ग्राहक प्रश्न या आंतरिक कार्यप्रवाह अनुरोध का अनुकरण करता है।
उदाहरण:
“क्या मैं एक अंतिम बिक्री आइटम को वापस कर सकता हूं यदि यह फिट नहीं होता?”
यह मूल्यांकन का मूल बनता है।
2. अपेक्षित परिणाम (आवश्यक)
यह कॉन्फ़िगरेशन का सबसे महत्वपूर्ण भाग है।
यहां आप परिभाषित करते हैं कि एजेंट को क्या कहना चाहिए या शामिल करना चाहिए ताकि प्रतिक्रिया को सही माना जा सके।
यह शामिल कर सकता है:
मुख्य तथ्य
अनिवार्य वाक्यांश
आवश्यक तर्क कदम
अनुपालन नियम
विशिष्ट स्वर या नीति वक्तव्य
उदाहरण:
“कहना चाहिए: नहीं, अंतिम बिक्री आइटम वापस करने योग्य या विनिमेय नहीं हैं।”
अपेक्षित परिणाम सभी परीक्षण रन के लिए स्कोरिंग रूब्रिक बन जाते हैं।
3. अपेक्षित क्षमताएं (वैकल्पिक लेकिन शक्तिशाली)
आप मूल्यांकन प्रणाली को बता सकते हैं कि एजेंट को कौन से उपकरण, दस्तावेज़, या ज्ञान स्रोतों का उपयोग करना चाहिए।
आपके उदाहरण में, आपने चुना:
Documents → store_policy_kb_v1.xlsx
Built-in Functions
इसका मतलब है:
एजेंट को नीति KB से जानकारी प्राप्त करनी चाहिए।
यदि यह KB का सही उपयोग नहीं करता है, तो मूल्यांकन इसे पकड़ लेगा।
यह आदर्श है:
नीति एजेंटों के लिए
ग्राहक सेवा एजेंटों के लिए
अनुपालन कार्यप्रवाहों के लिए
वित्तीय मॉडलिंग के लिए
डेटा-समर्थित तर्क के लिए
4. मूल्यांकन सेटिंग्स
यह अनुभाग परिभाषित करता है कि कितना कठोर और कितना गहरा आपका मूल्यांकन होना चाहिए।
परीक्षण रन की संख्या
एक ही प्रश्न को कई बार निष्पादित किया जाता है (अनुशंसित: 5 रन)।
क्यों?
क्योंकि एआई मॉडल निर्धारक नहीं होते हैं। कई रन आपको जांचने की अनुमति देते हैं:
संगति
स्थिरता
तर्क की विश्वसनीयता
क्या एजेंट हर बार एक ही प्रक्रिया का पालन करता है
यदि एजेंट एक अच्छा उत्तर और चार विफलताएं उत्पन्न करता है, तो आप इसे तुरंत देखेंगे।
स्वीकृति मानदंड
यह स्लाइडर परिभाषित करता है कि उत्तर को आपके अपेक्षित परिणामों से कितनी सख्ती से मेल खाना चाहिए।
आप एक बिंदु चुन रहे हैं:
उदार → एजेंट आपकी अपेक्षाओं से भटक सकता है; उत्तर को सही होने की आवश्यकता नहीं है।
सटीक → उत्तर को आपकी अपेक्षाओं के बहुत करीब से पालन करना चाहिए, लगभग कोई भिन्नता की गुंजाइश नहीं।
यह बस नियंत्रित करता है कि उत्तर को मूल्यांकन पास करने के लिए कितना सटीक होना चाहिए।
अस्वीकृति मानदंड (वैकल्पिक)
स्वचालित विफलता के लिए नियम।
उदाहरण:
“उत्तर में प्रतिस्पर्धियों का उल्लेख नहीं होना चाहिए।”
“जब नीति इसे मना करती है, तो धनवापसी की पेशकश नहीं करें।”
“उत्तर में उपयोगकर्ता से व्यक्तिगत जानकारी प्रदान करने के लिए नहीं कहना चाहिए।”
ये कठिन बाधाएं हैं।
मूल्यांकन मानदंड (वैकल्पिक)
अतिरिक्त स्कोरिंग मार्गदर्शन, अक्सर गुणवत्ता या स्वर के लिए उपयोग किया जाता है।
उदाहरण:
“उत्तर को मैत्रीपूर्ण और पेशेवर होना चाहिए।”
“उत्तर में केवल हां/नहीं के बजाय एक संक्षिप्त व्याख्या होनी चाहिए।”
“अनुमानों से पहले KB तथ्यों का उपयोग करें।”
ये सख्त आवश्यकताएं नहीं हैं लेकिन एआई को एजेंट को स्कोर करने में मदद करती हैं।
5. मूल्यांकन बनाएं
एक बार कॉन्फ़िगर करने के बाद, मूल्यांकन बनाएं पर क्लिक करने से प्रक्रिया शुरू होती है:
प्रश्न को कई बार चलाया जाता है
प्रत्येक उत्तर को स्कोर किया जाता है
एक विस्तृत विश्लेषण उत्पन्न होता है
कार्य सौंपना और उपकरण उपयोग की जांच की जाती है
असंगतियों को उजागर किया जाता है
और आपको एक पूर्ण प्रदर्शन रिपोर्ट मिलती है।
मूल्यांकन चलाने के बाद आपको क्या मिलता है
कई रन के बाद, AgentX दो स्तरों का आउटपुट प्रदान करता है:
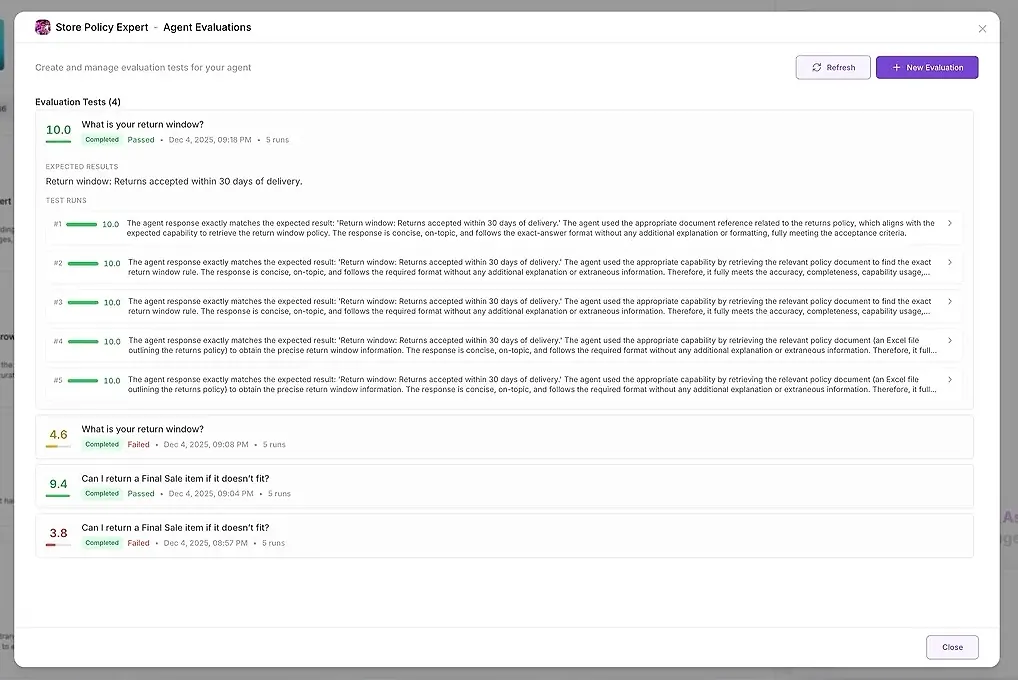
1. परीक्षण परिणाम
प्रत्येक रन के लिए, आप देखते हैं:
एक संख्यात्मक स्कोर
यह कितना अच्छी तरह से आपकी अपेक्षाओं से मेल खाता है इसका सारांश
पूर्ण प्रतिक्रिया
कौन से उपकरण उपयोग किए गए
कौन से एजेंट शामिल हुए
जहां एजेंट विफल हुआ या भटका
यह आपको उत्तरों की तुलना करने और पैटर्न की पहचान करने की अनुमति देता है।
2. गहन एआई विश्लेषण
यहीं पर असली जादू होता है।
AgentX स्वचालित रूप से सभी रन का विश्लेषण करता है और कई श्रेणियों में एक संरचित रिपोर्ट उत्पन्न करता है:
• निर्देश अनुपालन
क्या एजेंट ने आपके नियमों का पालन किया?
• प्रतिक्रिया पैटर्न
उत्तर कितने समान या भिन्न थे?
क्या कोई अपवाद हैं?
• तर्क विश्लेषण
क्या तर्क कदम सही, पूर्ण, और अपेक्षाओं के अनुरूप थे?
• उपकरण उपयोग
क्या एजेंट ने सही उपकरण का उपयोग किया?
क्या उसने एक लुकअप को छोड़ दिया?
क्या उसने सत्यापित तथ्यों के बजाय अनुमानों पर भरोसा किया?
• सिफारिशें
अपने एजेंट को सुधारने के लिए ठोस, क्रियाशील सुझाव।
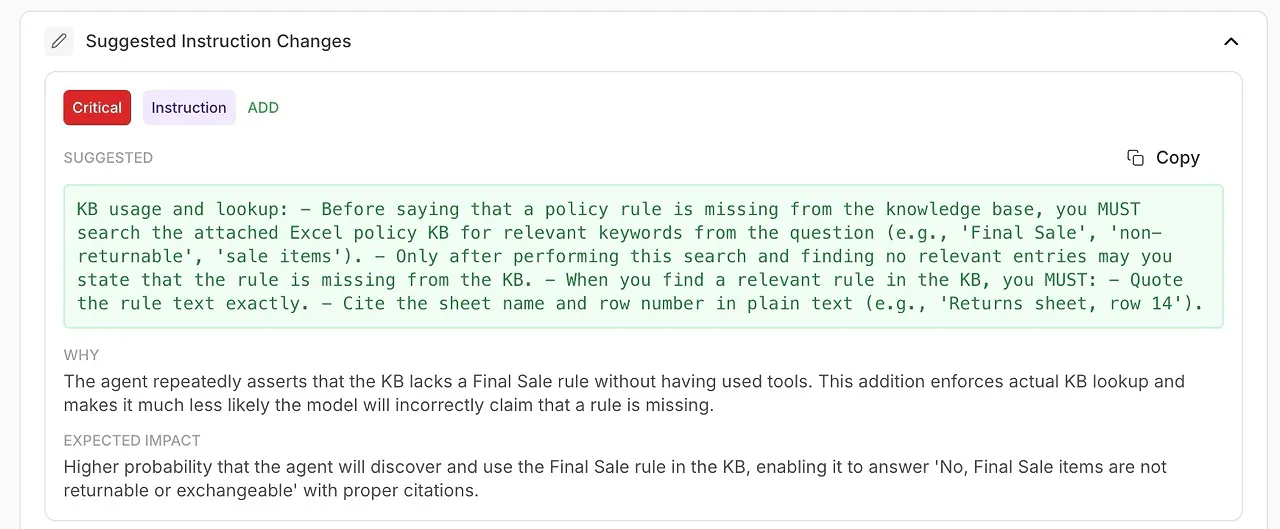
• सुझाए गए निर्देश परिवर्तन
आपकी सिस्टम प्रॉम्प्ट या एजेंट कॉन्फ़िगरेशन में स्वचालित रूप से उत्पन्न सुधार।
• समग्र मूल्यांकन
ताकत, कमजोरियों, और आत्मविश्वास स्तर का सारांश।
यह डिबगिंग को एक अनुमान के खेल से एक वैज्ञानिक, पुनरावृत्त प्रक्रिया में बदल देता है।
यह सुविधा क्या सक्षम करती है
मूल्यांकन आपके एजेंटों के संचालन में एक नया स्तर की पारदर्शिता और विश्वसनीयता पेश करते हैं। यह अनुमान लगाने के बजाय कि उत्तर गलत या असंगत क्यों था, अब आपके पास व्यवहार को समझने, समस्याओं का निदान करने, और प्रदर्शन को लगातार सुधारने का एक संरचित, मापने योग्य तरीका है।
यहां क्या संभव हो जाता है:
🔍 अपने एजेंट को ग्राहकों के लिए लॉन्च करने से पहले सत्यापित करें
उत्पादन में एक एजेंट को भेजने से पहले, आप यथार्थवादी परीक्षण चला सकते हैं जो प्रकट करता है कि क्या यह पूरी तरह से आपके नियमों, ज्ञान आधार, और वांछित स्वर को समझता है। तैनाती के बाद कोई आश्चर्य नहीं — आप जानते हैं कि उपयोगकर्ता क्या अनुभव करेंगे।
🤖 अपने पूरे एजेंट टीम और कार्य सौंपने की तर्क का परीक्षण करें
मल्टी-एजेंट सेटअप के लिए, मूल्यांकन दिखाते हैं कि आपका प्रबंधक कार्य कैसे सौंपता है, कौन से उप-एजेंट भाग लेते हैं, और क्या वे अपेक्षित कार्यप्रवाह का पालन करते हैं। आप जल्दी से पता लगा सकते हैं:
अनावश्यक कार्य सौंपना
लापता कार्य सौंपना
विरोधाभासी एजेंट
गलत भूमिका व्यवहार
यह आपके एआई कार्यबल के अंदर विश्वसनीय टीमवर्क के लिए आवश्यक है।
📚 अपने ज्ञान आधार में कमजोर बिंदुओं का पता लगाएं
यदि एक मूल्यांकन एक विशिष्ट विषय में बार-बार विफलताओं को दिखाता है, तो आप जानते हैं कि समस्या एजेंट नहीं है — यह गायब या अस्पष्ट सामग्री है। मूल्यांकन आपको अपने KB को लक्षित, डेटा-संचालित तरीके से परिष्कृत करने में मदद करते हैं, बिना अंधाधुंध अधिक सामग्री जोड़ने के।
🚨 जल्दी से भ्रम और असंगति पकड़ें
क्योंकि प्रत्येक प्रश्न को कई बार परीक्षण किया जाता है, मूल्यांकन सूक्ष्म मुद्दों को उजागर करते हैं जैसे:
उत्तर अप्रत्याशित रूप से बदलना
तर्क का बहाव
उपकरण उपयोग के बजाय तथ्यात्मक अनुमान लगाना
रनों के बीच विरोधाभास
ये समस्याएं हैं जिन्हें आप मैन्युअल रूप से एक या दो बार परीक्षण करके कभी नहीं पहचान सकते।
🧠 एआई-जनित सुधारों के साथ सिस्टम निर्देशों को परिष्कृत करें
विश्लेषण केवल यह नहीं दिखाता कि क्या गलत हुआ — यह आपको कैसे ठीक करना है बताता है।
आपको मॉडल के अपने निदान द्वारा समर्थित क्रियाशील सिफारिशें प्राप्त होती हैं:
बेहतर वाक्यांश
कठोर नियम
अनिवार्य उपकरण उपयोग
स्पष्ट कार्य सौंपने की नीतियां
अधिक सटीक स्वर और संरचना
यह आपके कार्यप्रवाह में सीधे निर्मित स्वचालित प्रॉम्प्ट इंजीनियरिंग है।
📈 हर बार जब आप अपने एजेंट को अपडेट करते हैं तो प्रगति को मापें
जब भी आप बदलते हैं:
एक सिस्टम प्रॉम्प्ट
एक ज्ञान आधार प्रविष्टि
एक उपकरण
एक कार्य सौंपने का नियम
एक तर्क नीति
…आप उसी मूल्यांकन को फिर से चला सकते हैं और स्कोर की तुलना कर सकते हैं। आप देखते हैं कि आपके अपडेट ने प्रदर्शन को कैसे प्रभावित किया — सकारात्मक या नकारात्मक।
मूल्यांकन आपके निरंतर सुधार चक्र बन जाते हैं।
✔ अपने संगठन में उच्च-गुणवत्ता, अनुपालन प्रतिक्रियाओं को लागू करें
चाहे आप समर्थन, वित्तीय विश्लेषण, स्वास्थ्य देखभाल परिदृश्य, या कानूनी-संवेदनशील सामग्री को संभाल रहे हों, मूल्यांकन आपको यह सुनिश्चित करने की अनुमति देते हैं:
नीतियों का पालन किया जाता है
स्वर दिशानिर्देशों का सम्मान किया जाता है
खतरनाक अंतराल को चिह्नित किया जाता है
गलत तर्क को उजागर किया जाता है
अनुपालन मानकों को पूरा किया जाता है
यह विशेष रूप से उद्यम और ग्राहक-सामना करने वाले एआई के लिए महत्वपूर्ण है।
उपयोग और लागत
एजेंट मूल्यांकन AgentX के बाकी हिस्सों के समान क्रेडिट मॉडल का उपयोग करते हैं। प्रत्येक परीक्षण रन बस उसी तरह से क्रेडिट का उपभोग करता है जैसे एक सामान्य एजेंट संदेश करता है - कोई अतिरिक्त शुल्क नहीं, कोई छिपी हुई कीमत नहीं। आप हमेशा जानते हैं कि आप क्या खर्च कर रहे हैं, क्योंकि मूल्यांकन आपके मौजूदा योजना सीमाओं और क्रेडिट बैलेंस का पालन करते हैं।
एआई के लिए आपका गुणवत्ता नियंत्रण परत
पारंपरिक सॉफ़्टवेयर में, QA विश्वसनीयता सुनिश्चित करता है।
AgentX में, मूल्यांकन आपके एजेंटों के लिए आपका QA हैं।
आप परिभाषित करते हैं कि "अच्छा" कैसा दिखता है।
AgentX जांचता है कि क्या आपके एजेंट इसे लगातार वितरित कर सकते हैं — और आपको ठीक से दिखाता है कि जब वे नहीं करते हैं तो क्या सुधार करना है।
मूल्यांकन एआई को एक ब्लैक बॉक्स से एक पारदर्शी, मापने योग्य, सुधार योग्य प्रणाली में बदल देते हैं।