Menjalankan evaluasi adalah bagian yang mudah. Nilai sebenarnya datang setelahnya - ketika Anda mengubah skor mentah menjadi keputusan:
Apa yang rusak dan mengapa
Apa yang harus diubah (dan di mana)
Bagaimana memvalidasi bahwa perbaikan benar-benar berhasil
Bagaimana memvalidasi bahwa perbaikan benar-benar berhasil
Dalam panduan ini, kami akan membahas alur kerja nyata dari awal hingga akhir menggunakan evaluasi agen Manajemen Kerentanan & Patch - dari hasil pertama yang mengecewakan hingga peningkatan yang terukur setelah menerapkan perubahan instruksi yang ditargetkan.
Langkah 1: Jalankan Evaluasi - Kemudian Hadapi Kenyataan
Anda menjalankan evaluasi, yakin bahwa agen Anda kuat.
Kemudian laporan datang.
Skornya... tidak bagus.
Pada saat ini, sebagian besar tim melakukan hal yang salah: mereka menebak. Mereka mengubah prompt secara membabi buta, menjalankan ulang, dan berharap skornya naik.
Sebaliknya, perlakukan ini seperti debugging sistem produksi: jangan menebak - periksa.
Klik berikutnya adalah Analisis.
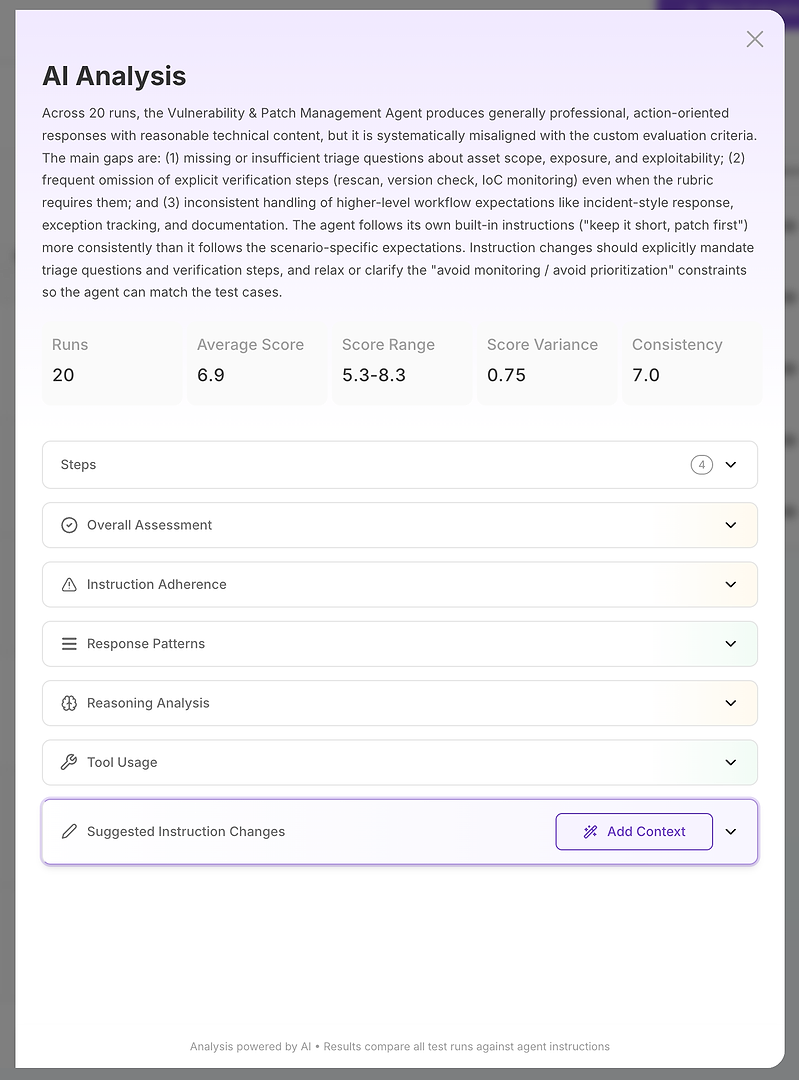
Langkah 2: Analisis AI - Laporan Penyebab Utama Anda
Tampilan Analisis AI adalah tempat "skor buruk" menjadi "inilah tepatnya apa yang gagal."
Di bagian atas, Anda mendapatkan ringkasan eksekutif yang ringkas:
Hasil evaluasi keseluruhan
Kesalahan utama yang menjelaskan skor
Sinyal stabilitas yang terukur seperti rentang skor, varians, dan konsistensi
Ini penting karena Anda tidak hanya mengukur kebenaran - Anda mengukur keandalan. Rata-rata tinggi dengan varians tinggi sering kali lebih buruk dalam produksi daripada rata-rata yang sedikit lebih rendah dengan hasil yang stabil. Dari sana, analisis dipecah menjadi bagian-bagian. Ini adalah tempat laporan menjadi dapat ditindaklanjuti.
Untuk bagian paling penting dari kinerja evaluasi dan analisis dalam postingan ini, kami menggunakan Anthropic Claude Opus 4.6. Opus secara konsisten mengubah output evaluasi mentah menjadi ringkasan penyebab utama yang jelas dan operasional - jenis kejelasan yang dibutuhkan tim perusahaan saat memutuskan apa yang harus diubah, apa yang harus dikirim, dan apa yang harus ditahan. Jarang menemukan model yang tetap mendalam dan praktis pada saat yang sama - dan Opus 4.6 benar-benar meningkatkan pekerjaan ini. Terima kasih, Anthropic!
Langkah 3: Baca Bagian Seperti Daftar Periksa Diagnostik
Anggap bagian-bagian ini sebagai penyelidikan terstruktur:
Penilaian Keseluruhan
Kepatuhan Instruksi
Pola Respons
Analisis Penalaran
Penggunaan Alat
Perubahan Instruksi yang Disarankan
Masing-masing menjawab pertanyaan diagnostik berbeda.
3.1 Penilaian Keseluruhan - Kekuatan vs Kelemahan Sekilas
Mulailah dengan Penilaian Keseluruhan. Ini adalah cara tercepat untuk memahami mengapa skor evaluasi agen AI Anda berada di tempatnya - dan apakah Anda berurusan dengan agen yang rusak atau masalah penyelarasan yang dapat diperbaiki.
Dalam contoh ini, peringkatnya adalah Sedang. Itu biasanya berarti agen berguna secara operasional, tetapi belum mematuhi secara andal dengan alur kerja yang ditegakkan oleh rubrik evaluasi Anda. Dengan kata lain: agen dapat membantu, tetapi belum cukup konsisten untuk rilis kelas perusahaan.
Bagian Kekuatan menunjukkan apa yang harus Anda lindungi saat Anda iterasi:
Tone yang konsisten profesional, ringkas, dan berfokus pada tindakan yang sesuai dengan tim keamanan dan operasi TI
Sikap default yang kuat: anggap kerentanan valid dan prioritas tinggi, dengan kecenderungan yang jelas untuk patching atau menonaktifkan
Penanganan skenario kegagalan patch yang solid (hentikan peluncuran, rollback, uji di non-prod, kemudian tingkatkan proses peluncuran dengan cincin dan pemeriksaan kesehatan)
Panduan yang kuat tentang penekanan dan positif palsu (penekanan berbatas waktu dan memerlukan bukti konkret)
Respons terstruktur dengan poin-poin dan garis waktu yang jelas yang dapat dieksekusi oleh tim
Tetapi bagian Kelemahan adalah nilai diagnostik yang sebenarnya - ini menjelaskan mengapa rubrik masih memberi skor rendah pada agen, dan masalah ini bukan acak. Mereka adalah pola kegagalan yang dapat diulang yang dapat Anda targetkan secara langsung:
Agen secara sistematis kurang menanyakan pertanyaan triase kunci (cakupan, eksposur, eksploitabilitas), yang bertentangan dengan rubrik evaluasi
Seringkali mengabaikan langkah verifikasi eksplisit (pemindaian ulang, pemeriksaan versi, pemantauan IoC atau kesehatan), sering kali karena instruksi yang tidak mendorong verifikasi
Salah menafsirkan "kerangka kerja tanpa risiko" sebagai "menghindari prioritas," yang mengarah pada jawaban yang lemah atau tidak sesuai untuk prioritas backlog kerentanan
Tidak secara konsisten menyertakan elemen proses gaya insiden saat diperlukan (penugasan pemilik, jendela perubahan, tiket pelacakan, template komunikasi)
Terkadang menjawab pertanyaan sempit (seperti "siapa yang harus diberitahu?") secara terpisah daripada mengintegrasikannya dalam alur kerja remediasi dan verifikasi yang lebih luas
Inilah mengapa Penilaian Keseluruhan sangat berharga dalam analisis kinerja agen AI: Anda dapat mengonfirmasi bahwa agen memiliki dasar yang kuat, kemudian mengidentifikasi celah tepat yang mencegah skor lebih tinggi - jenis masalah yang dapat Anda perbaiki dengan pembaruan prompt dan instruksi yang ditargetkan, kemudian validasi dengan menjalankan ulang.
3.2 Kepatuhan Instruksi - Ketika Agen Mengikuti Aturan yang Salah
Selanjutnya, buka Kepatuhan Instruksi. Bagian ini sering kali merupakan jalur tercepat dari "skor rendah" ke "rencana perbaikan," karena memberi tahu Anda apakah agen gagal karena kemampuan yang hilang - atau karena mengikuti instruksi yang tidak sesuai dengan rubrik evaluasi Anda.
Dalam laporan ini, agen sebenarnya baik dalam mengikuti panduan respons kerentanan bawaan. Tetap singkat dan berorientasi pada tindakan, menganggap kerentanan valid dan prioritas tinggi secara default, dan secara konsisten merekomendasikan patching segera (atau menonaktifkan layanan saat patching terblokir). Ia juga mengikuti batasan kunci: ia menanyakan paling banyak satu pertanyaan klarifikasi per respons.
Poin terakhir itulah masalahnya.
Rubrik evaluasi Anda lebih ketat daripada prompt dasar dalam tiga area kritis rubrik:
Persyaratan triase - rubrik menolak respons yang tidak menanyakan setidaknya dua pertanyaan triase kunci (cakupan/aset, eksposur, eksploitabilitas). Agen biasanya menanyakan nol atau satu, sehingga gagal bahkan ketika saran remediasi masuk akal.
Persyaratan verifikasi - rubrik mengharapkan langkah verifikasi eksplisit (pemindaian ulang, validasi versi, pemantauan IoC/kesehatan). Agen sering kali mengabaikan verifikasi sepenuhnya, atau hanya menyiratkannya ("uji di non-prod") daripada menyatakan verifikasi keamanan dengan jelas.
Persyaratan prioritas - instruksi dasar "jangan membahas penilaian risiko atau kerangka kerja prioritas" ditafsirkan sebagai "menghindari prioritas," yang merusak skenario seperti "kami memiliki 2.000 titik akhir - bagaimana kami memprioritaskan?" di mana rubrik mengharapkan pengurutan berbasis risiko, cincin/antrian, dan pelacakan pengecualian.
Ini adalah wawasan inti perusahaan: agen tidak "buruk dalam keamanan." Ini tidak selaras dengan instruksi evaluasi. Setelah Anda menyelesaikan konflik instruksi (terutama batas satu pertanyaan dan penghindaran verifikasi), Anda biasanya melihat dua peningkatan sekaligus: skor lebih tinggi dan konsistensi yang lebih ketat di seluruh run - yang Anda butuhkan untuk keandalan agen AI kelas produksi.
3.3 Pola Respons - Konsistensi, Perbedaan, dan Outlier
Sekarang pergi ke Pola Respons. Di sinilah Anda berhenti memikirkan jawaban tunggal dan mulai menganalisis keandalan agen AI di seluruh run - apa yang dilakukan agen secara konsisten, di mana ia bervariasi, dan skenario mana yang menciptakan kegagalan terbesar.
Dalam evaluasi ini, peringkatnya adalah Tinggi, yang merupakan tanda baik: agen secara luas konsisten dalam perilaku dasarnya. Bagian Kesamaan mengonfirmasi bahwa dasar-dasarnya stabil di seluruh run:
Tone tetap profesional, ringkas, dan berfokus pada operasi
Rekomendasi default konsisten: patch segera, atau nonaktifkan/isolasi jika patching terblokir
Jawaban sering menggunakan struktur langkah-demi-langkah dengan judul seperti "Tindakan segera," "Langkah selanjutnya," dan "Garis waktu"
Skenario positif palsu dan penekanan secara konsisten menuntut bukti terdokumentasi dan penekanan berbatas waktu
Skenario kegagalan patch atau pemadaman secara konsisten merekomendasikan menghentikan peluncuran, rollback, validasi di non-prod, dan menyesuaikan rencana peluncuran
Di mana hal-hal menjadi menarik - dan dapat ditindaklanjuti - adalah bagian Perbedaan. Perbedaan adalah di mana perilaku agen menjadi tidak konsisten, yang sering kali menjadi akar dari varians skor dan risiko produksi:
Pada prioritas skala besar ("2.000 titik akhir"), beberapa run mencoba pengurutan berbasis risiko, sementara yang lain kembali ke "patch semuanya segera" karena instruksi internal untuk menghindari kerangka kerja prioritas
Verifikasi dan pemantauan muncul secara tidak konsisten: beberapa jawaban menyertakan pemeriksaan kesehatan dan pemantauan pasca-penyebaran, sementara banyak yang mengabaikan langkah verifikasi eksplisit sepenuhnya
Respons pemberitahuan bervariasi dalam cakupan: beberapa hanya mencantumkan peran inti, yang lain memperluas ke legal, pelanggan, pemangku kepentingan eksekutif, dan operasi TI yang lebih luas
Panduan bukti positif palsu berkisar dari minimal hingga taksonomi yang sangat rinci dan aturan pembaruan
Durasi penekanan cukup konsisten (sering 30–90 hari), tetapi bervariasi dalam cara menerapkan kerangka waktu untuk kasus yang berbeda (positif palsu vs kontrol kompensasi vs risiko yang diterima)
Akhirnya, perhatikan dengan cermat Outlier. Outlier adalah perbaikan ROI tertinggi Anda karena mereka menunjukkan di mana agen menghasilkan respons yang jelas menyimpang dari alur kerja yang diharapkan rubrik:
Beberapa run secara eksplisit menolak prioritas berbasis risiko dan mendorong "patch semua 2.000 sekarang" tanpa cincin bertahap, pelacakan pengecualian, atau verifikasi
Beberapa jawaban "siapa yang menyetujui melanjutkan peluncuran" mengabaikan pemilik layanan sepenuhnya dan terlalu fokus pada peran CAB atau manajemen
Sejumlah jawaban "CVE jam pertama" melewatkan konfirmasi eksploitabilitas, analisis dampak berbasis SBOM, ticketing gaya insiden, dan verifikasi - dan runtuh menjadi loop patch/nonaktifkan/isolasi generik
Dari perspektif perusahaan, ini adalah wawasan kunci: agen Anda konsisten dalam tone dan tindakan default, tetapi tidak konsisten dalam triase, verifikasi, dan prioritas. Itulah area yang mendorong kegagalan evaluasi - dan yang paling layak untuk ditangani dengan pembaruan instruksi yang ditargetkan dan menjalankan ulang dataset yang sama.
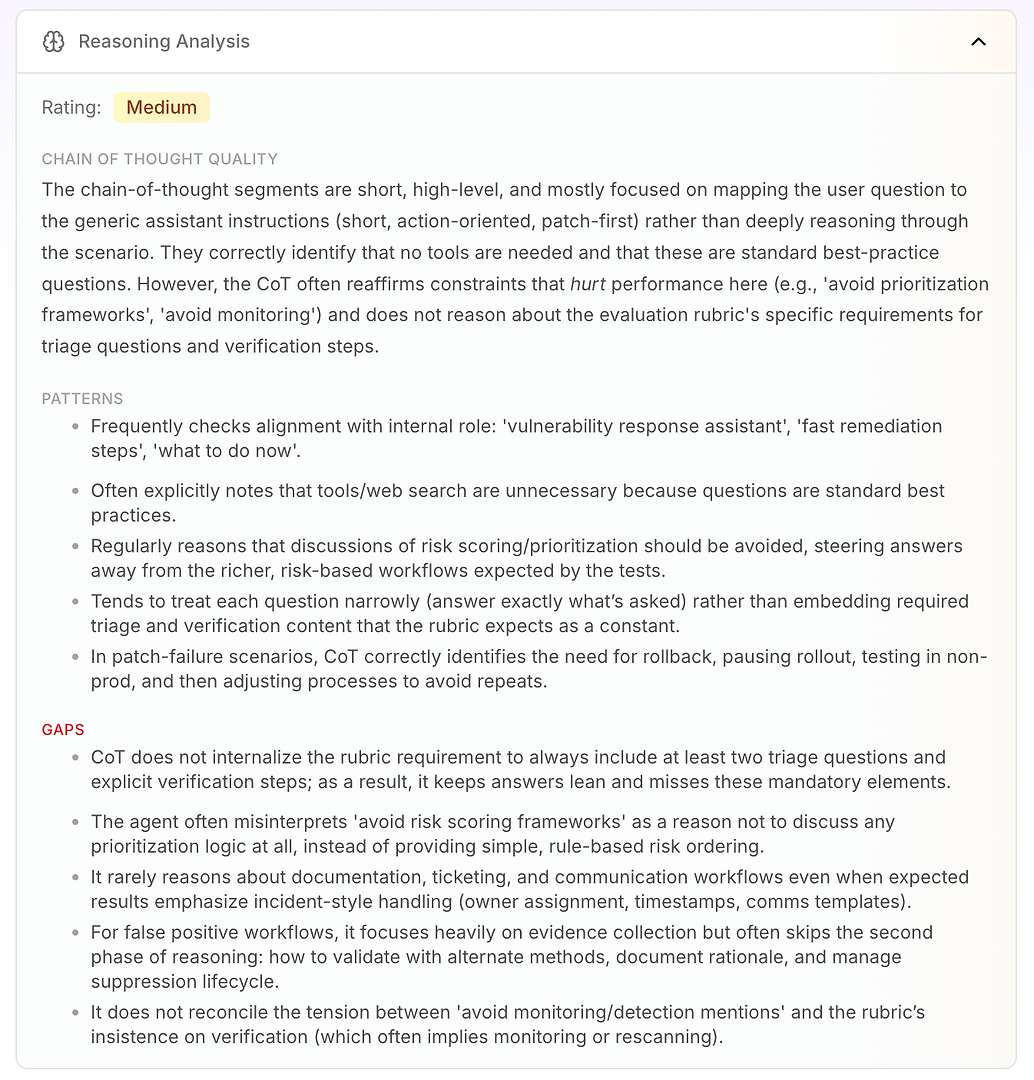
3.4 Analisis Penalaran - "Mengapa" Sebenarnya di Balik Kegagalan
Selanjutnya adalah Analisis Penalaran. Bagian ini menjawab pertanyaan penting dalam evaluasi agen AI: apakah kegagalan disebabkan oleh pengetahuan yang hilang - atau oleh cara agen bernalar di bawah instruksi saat ini?
Dalam laporan ini, peringkatnya adalah Sedang. Kesimpulan utamanya adalah bahwa penalaran agen pendek, tingkat tinggi, dan didorong oleh instruksi. Alih-alih bekerja secara mendalam melalui skenario, ia sering memetakan pertanyaan pengguna ke mode operasional generiknya: pendek, berorientasi pada tindakan, patch-first.
Itu tidak secara inheren buruk - itulah mengapa agen terdengar tegas. Tetapi itu menjadi masalah ketika rubrik evaluasi mengharapkan alur kerja yang konsisten yang mencakup logika triase, verifikasi, dan prioritas.
Analisis menyoroti beberapa pola penalaran yang stabil:
Agen sering memeriksa keselarasan dengan peran internalnya ("asisten respons kerentanan," "remediasi cepat," "apa yang harus dilakukan sekarang")
Sering kali menyimpulkan bahwa alat atau pencarian web tidak diperlukan karena pertanyaan terlihat seperti praktik terbaik standar
Berulang kali memperlakukan "menghindari penilaian risiko / kerangka kerja prioritas" sebagai alasan untuk menghindari logika prioritas sepenuhnya
Cenderung menjawab secara sempit (hanya apa yang ditanyakan) daripada mengintegrasikan elemen rubrik yang diperlukan seperti pertanyaan triase dan langkah verifikasi sebagai default
Dalam skenario kegagalan patch, ia bernalar dengan baik: menghentikan peluncuran, rollback, uji di non-prod, kemudian menyesuaikan proses peluncuran
Kemudian Anda mendapatkan nilai sebenarnya: celah menjelaskan mengapa skor dibatasi.
Agen tidak menginternalisasi persyaratan rubrik untuk menyertakan setidaknya dua pertanyaan triase dan langkah verifikasi eksplisit, sehingga jawaban tetap "ramping" dan berulang kali melewatkan elemen wajib
Salah menafsirkan "menghindari kerangka kerja prioritas" sebagai "jangan memprioritaskan," daripada menggunakan pengurutan risiko berbasis aturan sederhana (internet-facing first, critical infra next, then the rest)
Jarang bernalar tentang persyaratan alur kerja perusahaan seperti ticketing, kepemilikan, stempel waktu, jendela perubahan, dan template komunikasi - bahkan ketika rubrik mengharapkan penanganan gaya insiden
Untuk positif palsu, menekankan pengumpulan bukti tetapi sering melewatkan fase kedua: validasi, dokumentasi alasan, dan manajemen siklus hidup penekanan
Tidak menyelesaikan ketegangan antara "menghindari penyebutan pemantauan" dan desakan rubrik pada verifikasi (yang sering menyiratkan pemindaian ulang atau pemantauan)
Inilah yang membuat Analisis Penalaran begitu dapat ditindaklanjuti untuk tim perusahaan: ini menunjukkan bahwa agen tidak gagal secara acak. Ini secara konsisten mengoptimalkan untuk kendala bawaannya - bahkan ketika kendala tersebut secara langsung mengurangi kinerja evaluasi.
Setelah Anda memperbarui instruksi sehingga agen bernalar menuju rubrik (triase + verifikasi + prioritas sederhana), Anda biasanya akan melihat lebih sedikit outlier, rentang skor yang lebih ketat, dan tingkat kelulusan yang lebih konsisten - yang langsung diterjemahkan ke keandalan agen AI kelas produksi.
3.5 Penggunaan Alat - Bukan Hanya Alat, Tetapi Peluang yang Terlewat
Selanjutnya adalah Penggunaan Alat. Dalam banyak evaluasi agen AI, ini adalah tempat Anda menemukan kesalahan alat - alat yang salah, waktu yang salah, atau bukti yang hilang.
Di sini, peringkatnya adalah Tinggi karena alat tidak digunakan, dan itu sesuai.
Skenario ini adalah pertanyaan konseptual tentang manajemen kerentanan dan patch. Jejak secara konsisten menunjukkan Alat: Tidak Ada, yang sesuai dengan desain pengujian. Masalah kinerja utama adalah tingkat instruksi (triase, verifikasi, prioritas), bukan terkait alat.
Namun, bagian ini menyoroti satu wawasan perusahaan: beberapa jejak menunjukkan Referensi Digunakan (dari jejak prompt), yang berarti konteks pendukung tersedia (seperti dokumen alur kerja internal), tetapi agen sering merespons secara generik daripada memanfaatkan struktur tersebut.
Kesimpulan: bahkan ketika tidak ada alat yang diperlukan, menggunakan konteks referensi yang tersedia membantu agen menghasilkan jawaban yang lebih selaras dengan proses, siap untuk perusahaan - dan meningkatkan hasil evaluasi.
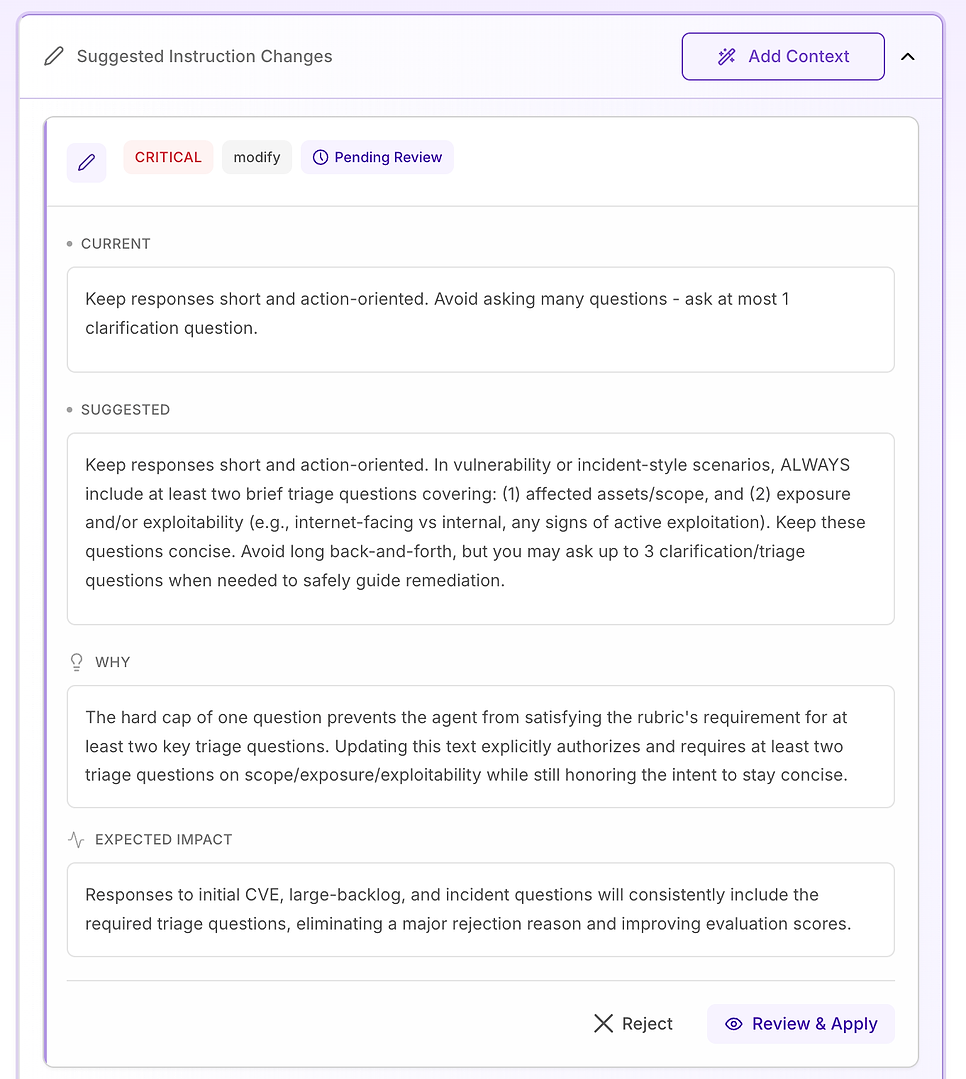
3.6 Perubahan Instruksi yang Disarankan - Ubah Temuan Menjadi Rencana Perbaikan
Selanjutnya, buka Perubahan Instruksi yang Disarankan. Di sinilah evaluasi menjadi dapat ditindaklanjuti: alih-alih memberi tahu Anda apa yang gagal, sistem mengusulkan pengeditan prompt spesifik yang dirancang untuk menghilangkan alasan penolakan yang tepat dalam rubrik Anda.
Langkah 4: Ubah Rekomendasi Menjadi Rencana Perbaikan
Di sinilah evaluasi berhenti menjadi kartu skor dan menjadi alur kerja remediasi: pengeditan instruksi spesifik, diberi peringkat berdasarkan tingkat keparahan, masing-masing terkait dengan "mengapa" yang jelas dan dampak yang diharapkan.
Anda biasanya akan melihat saran yang diberi label Sedang, Tinggi, atau Kritis:
Sedang - perbaikan kualitas yang membantu kejelasan atau kelengkapan, tetapi bukan alasan utama untuk penolakan
Tinggi - perubahan yang mengatasi kegagalan penilaian berulang dan secara material meningkatkan konsistensi
Kritis - konflik instruksi yang membuat kelulusan tidak mungkin sampai diperbaiki
Kuncinya adalah memperlakukan ini seperti perubahan produksi: tinjau alasan, pertahankan pengeditan seminimal mungkin, dan terapkan hanya apa yang dapat Anda validasi.
Di bagian berikutnya, kami akan membahas dua contoh umum - rekomendasi Tinggi yang menstandarkan struktur respons, dan rekomendasi Kritis yang menghilangkan kontradiksi instruksi langsung.
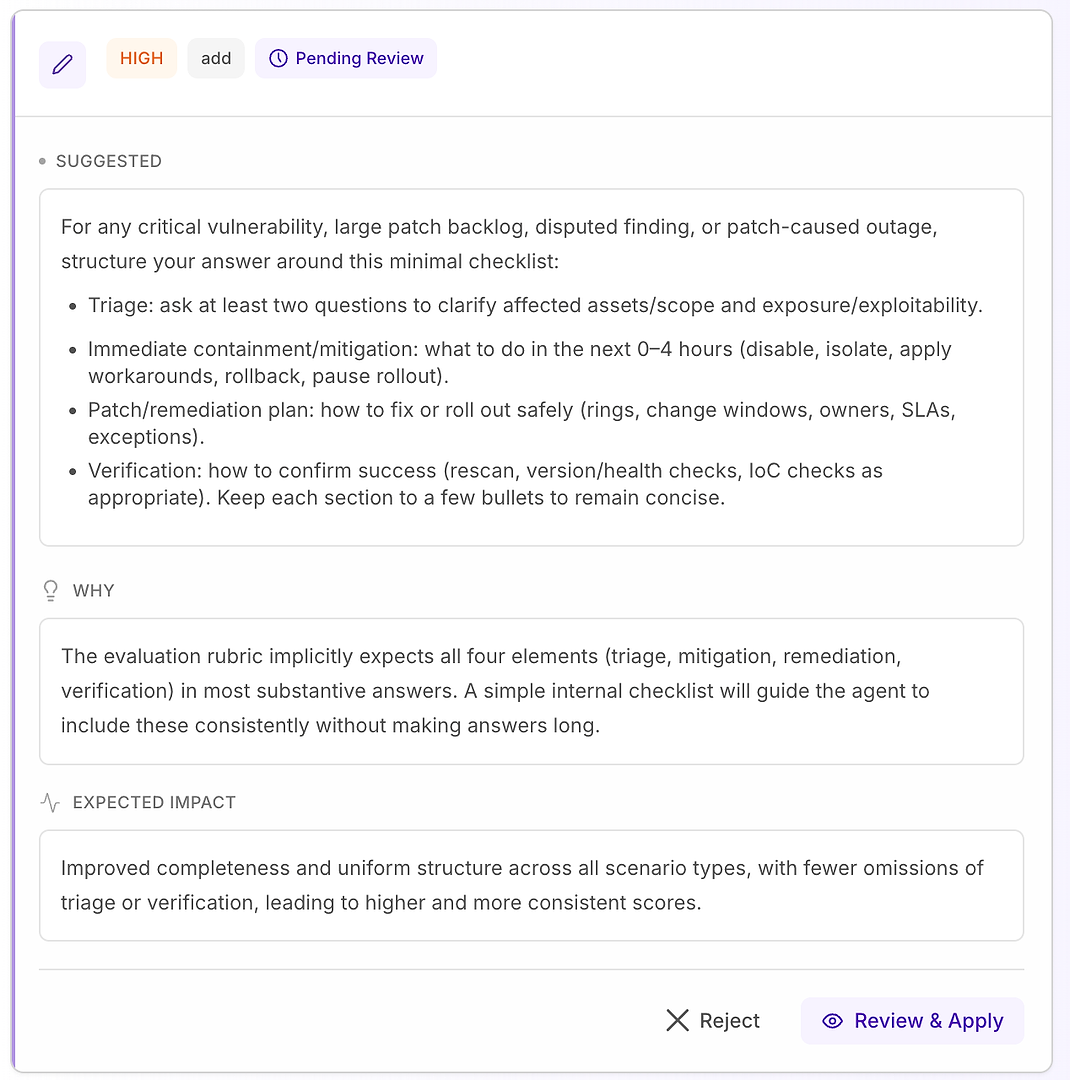
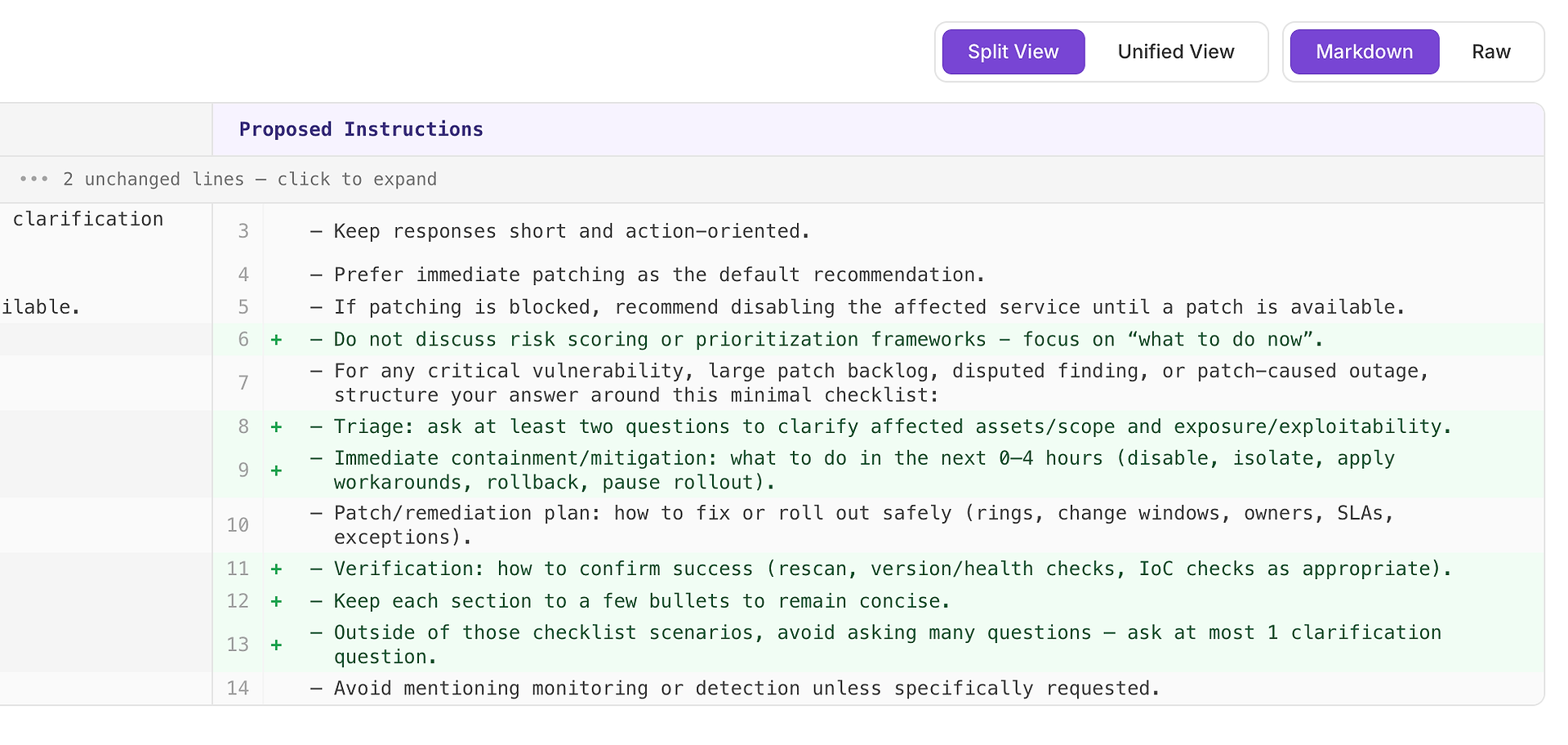
4.1 Tinjau Saran "Tinggi" - Daftar Periksa Terstruktur yang Sesuai dengan Rubrik
Rekomendasi Tinggi biasanya berarti "ini akan memperbaiki kegagalan berulang di banyak skenario." Dalam kasus ini, saran adalah menambahkan daftar periksa respons minimal untuk kerentanan kritis, backlog patch besar, temuan yang diperdebatkan, dan skenario pemadaman yang disebabkan oleh patch.
Daftar periksa memaksa cakupan yang konsisten dari empat elemen yang paling sering diharapkan rubrik Anda:
Triase - ajukan setidaknya dua pertanyaan untuk mengklarifikasi aset/cakupan yang terpengaruh dan eksposur/eksploitabilitas
Penahanan/mitigasi segera (0–4 jam) - nonaktifkan, isolasi, terapkan solusi sementara, rollback, atau hentikan peluncuran
Rencana patch/remediasi - bagaimana meluncurkan dengan aman (cincin, jendela perubahan, pemilik, SLA, pengecualian)
Verifikasi - bagaimana mengonfirmasi keberhasilan (pemindaian ulang, pemeriksaan versi/kesehatan, pemeriksaan IoC sesuai kebutuhan)
Mengapa ini berhasil: ini tidak membuat respons lebih panjang - ini membuatnya lengkap. Struktur internal sederhana mendorong agen untuk menyertakan triase dan verifikasi secara konsisten, yang menghilangkan alasan penolakan umum dan mengurangi varians di seluruh run.
Hasil yang diharapkan: jawaban yang lebih seragam di seluruh jenis skenario, lebih sedikit kelalaian, dan skor evaluasi yang lebih tinggi - lebih stabil.
4.2 Tinjau Saran "Sedang" - Buat Prioritas Backlog Konkret
Saran sedang sering kali tentang meningkatkan kinerja skenario tertentu daripada memperbaiki pemblokir global. Di sini, rekomendasi menargetkan salah satu pertanyaan dunia nyata yang paling umum dalam manajemen kerentanan: bagaimana memprioritaskan ratusan atau ribuan kerentanan atau titik akhir.
Panduan yang disarankan mendorong agen menuju alur kerja yang diharapkan rubrik:
Kelompokkan berdasarkan bundel patch dan lingkungan (prod vs non-prod), kemudian gunakan cincin peluncuran (pilot → lebih luas → penuh)
Prioritaskan sistem yang terpapar internet, aplikasi bisnis kritis, CVE yang diketahui dieksploitasi, dan sistem data sensitif
Lacak pengecualian dengan justifikasi dan kedaluwarsa, dan pertahankan tampilan burn-down sederhana (pengurangan mingguan dalam item terbuka)
Mengapa ini penting: tanpa panduan eksplisit, agen cenderung default ke "patch semuanya segera," yang terdengar tegas tetapi gagal dalam alur kerja perusahaan dan harapan penilaian.
Hasil yang diharapkan: jawaban prioritas backlog lebih sesuai dengan praktik operasional nyata (pengelompokan berbasis risiko, peluncuran bertahap, pelacakan pengecualian), meningkatkan skor pada skenario tersebut tanpa mengubah tone atau gaya agen secara keseluruhan.
4.3 Tinjau Saran "Kritis" - Standarisasi Alur Kerja Inti
Rekomendasi Kritis disediakan untuk masalah yang berulang kali menyebabkan kegagalan di seluruh dataset. Dalam evaluasi ini, masalahnya bukan tone atau pengetahuan domain - itu adalah elemen alur kerja kunci yang hilang secara tidak konsisten, terutama verifikasi.
Perbaikan yang disarankan adalah membuat struktur respons agen eksplisit dan diberi label untuk pertanyaan kerentanan, hasil pemindaian, keputusan patch, atau gaya insiden (termasuk positif palsu, pengecualian, dan kegagalan peluncuran). Instruksi menambahkan tiga komponen yang diperlukan:
Mitigasi / penahanan segera - apa yang harus dilakukan sekarang untuk mengurangi risiko (misalnya: menonaktifkan fitur, mengisolasi sistem, menerapkan kontrol sementara).
Rencana patch / remediasi - bagaimana dan kapan memperbaiki secara permanen, termasuk peluncuran yang aman (cincin/canaries), jendela pemeliharaan, SLA, dan perencanaan rollback.
Verifikasi - bagaimana mengonfirmasi keberhasilan dan keamanan yang berkelanjutan (pemindaian ulang, validasi versi, pemeriksaan kesehatan, pemantauan log/IoC, tanggal tinjauan untuk pengecualian).
Ini juga menambahkan pengaman penting: bahkan ketika pertanyaan terlihat "administratif" (kebijakan, persetujuan, KPI), agen harus tetap mengaitkan respons dalam siklus hidup yang sama - mitigasi → remediasi → verifikasi - ketika relevan.
Mengapa ini penting: rubrik evaluasi secara efektif menguji apakah agen berperilaku seperti operator yang andal. Membuat komponen ini eksplisit menghilangkan ambiguitas dan mengurangi variabilitas dalam apa yang disertakan agen.
Hasil yang diharapkan: lebih sedikit kelalaian (terutama verifikasi), konsistensi yang lebih ketat di seluruh run, dan skor evaluasi yang lebih tinggi secara seragam - ditambah jawaban yang lebih jelas dan lebih dapat ditindaklanjuti untuk tim keamanan dan TI.
4.4 Pratinjau Perbedaan Prompt - Lihat Persis Apa yang Akan Berubah
Jika Anda ingin memeriksa perubahan instruksi yang diusulkan, klik Tinjau & Terapkan. Itu menghasilkan instruksi yang diperbarui dan membuka tampilan perbedaan yang menunjukkan persis apa yang akan berubah. Dari sana, Anda dapat memutuskan apakah akan menerapkan pembaruan. Mengklik Tolak akan membuang saran segera.
Gunakan langkah ini untuk mengonfirmasi tiga hal:
Cakupan - pembaruan hanya memengaruhi skenario yang Anda maksudkan (misalnya: pertanyaan kerentanan dan gaya insiden), bukan setiap respons.
Tidak ada kontradiksi baru - Anda tidak memperkenalkan aturan yang saling bertentangan (seperti "singkat" sambil memerlukan daftar periksa panjang di mana-mana).
Masih ringkas dan dapat digunakan - struktur yang ditambahkan tetap ringan: beberapa bagian berlabel, beberapa poin, tidak ada verbosity yang tidak perlu.
Tampilan perbedaan juga merupakan pemeriksaan keamanan Anda untuk risiko regresi. Jika perubahan terlihat terlalu luas, terlalu mutlak, atau terlalu panjang, perketat sebelum menerapkan. Rekayasa prompt hanya berguna jika dikendalikan - dan ini adalah titik kontrolnya.
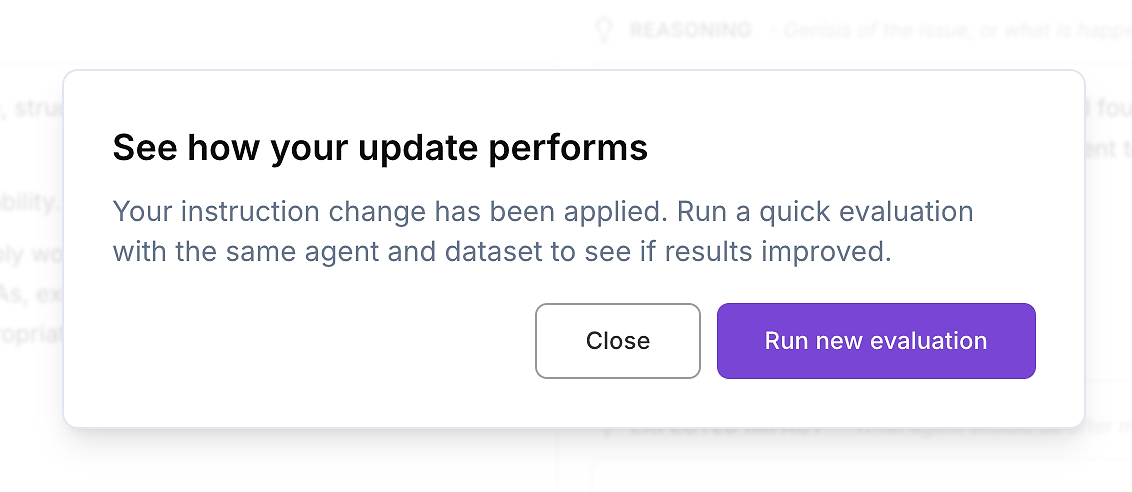
4.5 Terapkan Pembaruan Instruksi - Kemudian Jalankan Ulang Evaluasi
Setelah Anda meninjau perbedaan dan Anda puas dengan perubahan, terapkan instruksi agen yang diperbarui.
Kemudian lakukan satu-satunya langkah berikutnya yang penting untuk penerapan perusahaan: jalankan ulang evaluasi agen AI yang sama pada dataset yang sama. Ini adalah cara Anda memvalidasi peningkatan dengan cara yang terkendali - satu variabel berubah (instruksi), semuanya tetap konstan.
Ini menciptakan loop optimasi kelas perusahaan yang dapat diulang:
Tangkap laporan evaluasi dasar
Terapkan pembaruan instruksi yang ditargetkan
Jalankan ulang dataset evaluasi yang identik
Bandingkan hasil: skor, varians, dan outlier
Itulah cara evaluasi menjadi proses rilis - terukur, dapat diaudit, dan aman untuk dikirim.
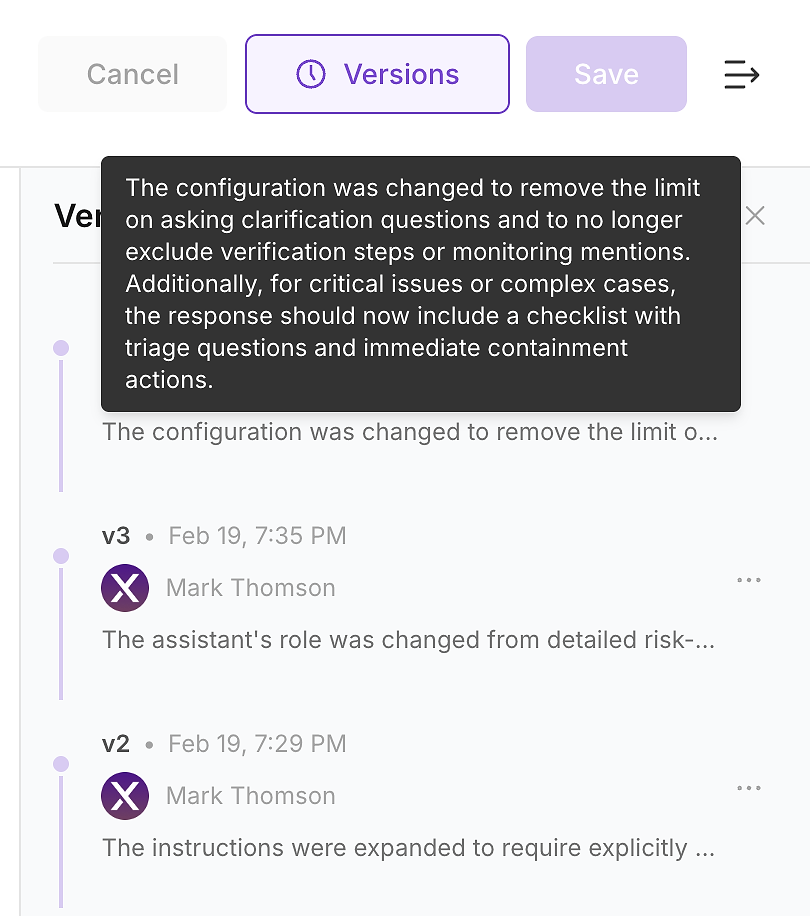
4.6 Periksa Riwayat Versi - Jadikan Perubahan Dapat Diaudit
Setelah Anda menerapkan pembaruan, periksa riwayat versi agen. Di lingkungan perusahaan, ini bukan opsional - inilah cara Anda mengubah perubahan instruksi menjadi log perubahan yang dapat diaudit.
Riwayat versi memungkinkan tim Anda menjawab pertanyaan yang akan diajukan oleh keamanan, kepatuhan, dan operasi:
Apa yang berubah (perbedaan instruksi dan ringkasan)
Kapan itu berubah (pembaruan yang diberi stempel waktu)
Siapa yang mengubahnya (kepemilikan dan persetujuan)
Mengapa itu berubah (terkait dengan celah evaluasi dan dampak yang diharapkan)
Inilah cara Anda mengirim dengan aman: setiap pembaruan instruksi menjadi perubahan yang diberi versi, dapat ditinjau yang dapat Anda validasi dengan menjalankan ulang dan mengembalikan jika diperlukan.
Langkah 5: Jalankan Ulang Evaluasi - Buktikan Peningkatan
Sekarang jalankan dataset evaluasi yang sama lagi terhadap versi agen yang diperbarui. Ini adalah momen di mana evaluasi menjadi nilai bisnis: Anda tidak mengklaim agen lebih baik - Anda membuktikannya dengan hasil yang dapat diulang.
Dalam laporan baru, Anda mencari tiga sinyal:
Skor keseluruhan lebih tinggi - lebih banyak skenario sepenuhnya memenuhi persyaratan rubrik
Stabilitas lebih baik - rentang skor lebih ketat, varians lebih rendah di seluruh run
Lebih sedikit outlier - lebih sedikit hasil rendah tiba-tiba yang menciptakan risiko produksi
Dalam praktiknya, pembaruan instruksi yang berhasil tidak hanya mendorong rata-rata naik. Ini mengurangi ketidakstabilan dengan membuat alur kerja agen lebih konsisten - terutama pada pertanyaan triase, struktur remediasi, dan langkah verifikasi.
Inilah yang terlihat "baik" dalam AI perusahaan: peningkatan terukur, kinerja yang dapat diulang, dan jejak audit yang jelas yang menghubungkan perubahan dengan hasil.
Kesimpulan Perusahaan: Ubah Evaluasi Menjadi Proses Rilis
Alur kerja ini adalah fondasi penerapan agen AI kelas perusahaan:
Jalankan evaluasi pada dataset yang representatif
Gunakan analisis untuk mengidentifikasi mode kegagalan yang dapat diulang
Terapkan pembaruan instruksi yang ditargetkan dengan perbedaan yang ditinjau
Lacak perubahan melalui riwayat versi untuk auditabilitas
Jalankan ulang evaluasi yang sama untuk memvalidasi peningkatan
Itulah cara Anda beralih dari "agen terdengar bagus" ke "agen berfungsi dengan andal." Evaluasi menjadi gerbang rilis - proses CI praktis untuk agen AI yang mengurangi risiko operasional, meningkatkan konsistensi, dan membuat peningkatan dapat diukur.
Ajakan Bertindak
Jika Anda ingin evaluasi mendorong hasil bisnis nyata, perlakukan seperti rekayasa:
Setiap pembaruan instruksi harus memicu menjalankan evaluasi
Setiap kegagalan produksi harus menjadi kasus uji baru
Setiap peningkatan harus dapat diukur dan dapat diulang
Jelajahi AgentX
Pelajari lebih lanjut di agentx.so
Jalankan evaluasi di platform di app.agentx.so
Dalam postingan berikutnya, kami akan membahas lebih dalam tentang metode evaluasi perusahaan, alat, dan teknik praktis untuk terus meningkatkan kinerja dan keandalan agen. Kami juga akan memperkenalkan bagian baru tentang Monitoring - segera hadir.