
エージェント評価とAI分析ツール
Sebastian Mul
8 min read
EvaluationAI AgentAgentXTesting
AgentXの評価により、AIエージェントを複数回の実行でテストし、不整合を発見し、推論やツールの使用を分析し、実行可能なAI生成の洞察でパフォーマンスを向上させることができます。
AgentXの評価により、AIエージェントを複数回の実行でテストし、不整合を発見し、推論やツールの使用を分析し、実行可能なAI生成の洞察でパフォーマンスを向上させることができます。
AIエージェントはますます高度化し、より多くの能力を持ち、ビジネスに深く統合されています。
しかし、すべてのチームが直面する普遍的な問題があります:
エージェントが期待通りに答えないことがあり、その理由がわからない。
時には推論が変わり、時にはエージェントがルールを無視し、時にはツールが正しく使用されず、時には微妙な指示が誤解されることがあります。どのように意思決定が行われたのかが見えないと、エージェントの改善は推測のように感じられます。
これがまさに私たちがエージェント評価を構築した理由です。AgentX内の新しいシステムで、同じ質問を複数回実行することでエージェントの動作をテスト、測定、深く分析できます。
初めて、エージェントの意思決定の中を見ることができ、不整合を見つけ、どこに改善が必要かを正確に理解できます。
AIモデルは確率的です。
同じプロンプト、コンテキスト、ルールでも、モデルは:
わずかに異なる推論経路を生成する
必要な詳細を省略する
ポリシーを誤解する
ツールの検索をスキップする
期待される決定的な答えではなく不確かな答えを与える
チーム内で一貫性のない委任を行う
外部からは、最終的な答えしか見えません。
あなたは見えません:
エージェントが指示に従ったかどうか
正しいツールを使用したかどうか
正しく推論したかどうか
なぜあるバージョンの答えが他よりも弱かったのか
なぜ時には正しく、時には間違うのか
評価はこれを解決し、構造、スコアリング、透明性を提供します。
評価の作成は簡単です:

これは、検証したい実際の質問です。
顧客の問い合わせや内部のワークフロー要求をシミュレートします。
例:
「最終セール品が合わない場合、返品できますか?」
これが評価の核心を形成します。
これは設定の最も重要な部分です。
ここで、エージェントが正しいと見なされるために言わなければならないことや含めるべきことを定義します。
それには以下が含まれることがあります:
重要な事実
必須のフレーズ
必要な推論ステップ
コンプライアンスルール
特定のトーンやポリシーの声明
例:
「言わなければならない: いいえ、最終セール品は返品または交換できません。」
期待される結果はすべてのテスト実行のための採点ルーブリックになります。

評価システムにエージェントが使用すべきツール、ドキュメント、知識源を指定できます。
例では、以下を選択しました:
Documents → store_policy_kb_v1.xlsx
Built-in Functions
これは次のことを意味します:
エージェントはポリシーKBから情報を取得するべきです。
KBを正しく使用しない場合、評価がそれを検出します。
これは以下に最適です:
ポリシーエージェント
カスタマーサービスエージェント
コンプライアンスワークフロー
財務モデリング
データに基づく推論
このセクションでは、評価の厳密さと深さを定義します。
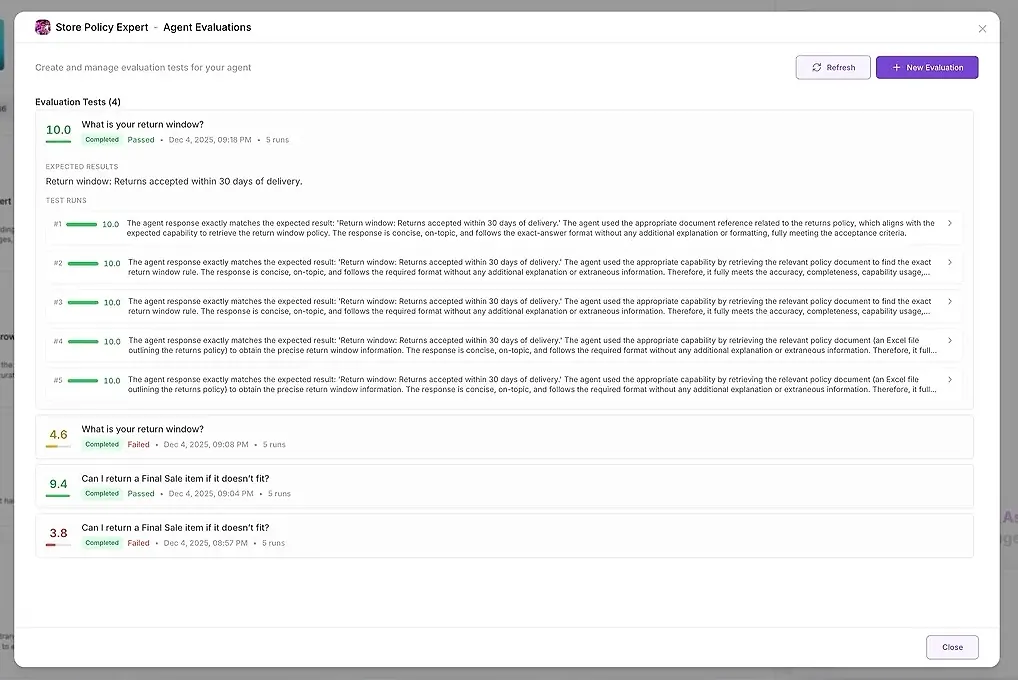
同じ質問が複数回実行されます(推奨: 5回の実行)。
なぜか?
AIモデルは決定論的ではないためです。複数回の実行により、次のことを確認できます:
一貫性
安定性
推論の信頼性
エージェントが毎回同じプロセスに従うかどうか
エージェントが1つの良い答えと4つの失敗を生成した場合、それをすぐに確認できます。
このスライダーは、答えが期待される結果にどれだけ厳密に一致する必要があるかを定義します。
次の間でポイントを選択しています:
寛容 → エージェントは期待から逸脱することができ、答えは完璧である必要はありません。
正確 → 答えは期待に非常に近く、ほとんど変動の余地がない必要があります。
これは、評価に合格するためにどれだけ正確である必要があるかを制御します。

自動失敗のルール。
例:
「回答に競合他社を言及してはならない。」
「ポリシーが禁止している場合、返金を提供してはならない。」
「回答でユーザーに個人情報を提供するよう求めてはならない。」
これらは厳しい制約です。
品質やトーンのために使用される追加のスコアリングガイダンス。
例:
「回答は親しみやすく、プロフェッショナルであるべきです。」
「答えは単なるはい/いいえではなく、短い説明を含む必要があります。」
「仮定の前にKBの事実を使用する。」
これらは厳しい要件ではありませんが、AIがエージェントを評価する方法を形作るのに役立ちます。
設定が完了したら、評価を作成をクリックしてプロセスを開始します:
質問が複数回実行されます
各回答がスコアリングされます
詳細な分析が生成されます
委任とツールの使用が検査されます
不整合が表面化します
そして、完全なパフォーマンスレポートが返されます。
複数回の実行後、AgentXは2つの出力レイヤーを提供します:
各実行について、次のことがわかります:
数値スコア
期待にどれだけ一致したかの要約
完全な回答
使用されたツール
参加したエージェント
エージェントが失敗または逸脱した場所
これにより、回答を並べて比較し、パターンを特定できます。

ここで本当の魔法が起こります。
AgentXはすべての実行を自動的に分析し、複数のカテゴリにわたる構造化レポートを生成します:
エージェントはあなたのルールに従いましたか?
回答はどれだけ似ているか、または異なるか?
外れ値はありますか?

推論ステップは正しく、完全で、期待に沿っていましたか?
エージェントは正しいツールを使用しましたか?
検索をスキップしましたか?
検証された事実ではなく仮定に頼りましたか?
エージェントを改善するための具体的で実行可能な提案。
システムプロンプトやエージェント設定の自動生成された改善。
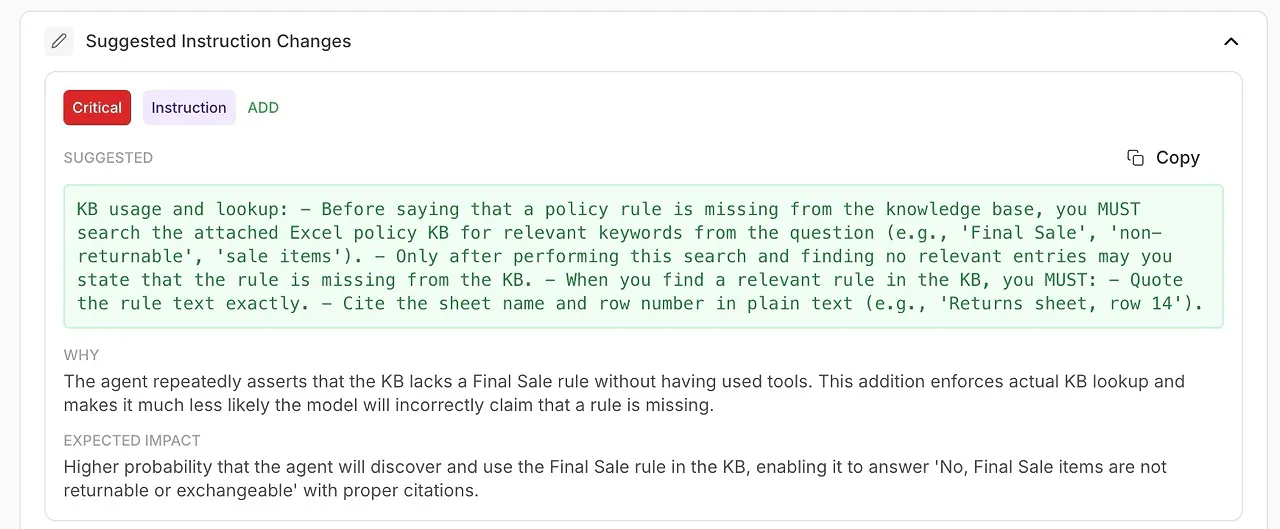
強み、弱み、信頼レベルの要約。
これにより、デバッグが推測ゲームから科学的で再現可能なプロセスに変わります。

評価は、エージェントの運用に新しいレベルの透明性と信頼性をもたらします。なぜ答えが間違っていたのか、または一貫性がなかったのかを推測する代わりに、行動を理解し、問題を診断し、パフォーマンスを継続的に改善するための構造化された測定可能な方法を持つことができます。
これにより可能になること:
エージェントを本番環境に出荷する前に、ルール、知識ベース、望ましいトーンを完全に理解しているかどうかを明らかにする現実的なテストを実行できます。展開後の驚きはありません — ユーザーがどのような体験をするかを正確に把握できます。
マルチエージェントのセットアップでは、評価はマネージャーがタスクをどのように委任するか、どのサブエージェントが参加するか、期待されるワークフローに従うかを示します。次のことを迅速に検出できます:
不要な委任
欠落した委任
競合するエージェント
不正確な役割の行動
これはAI労働力内での信頼できるチームワークに不可欠です。
評価が特定のトピックで繰り返し失敗を示す場合、問題はエージェントではなく、欠落しているか不明瞭なコンテンツです。評価は、無作為に資料を追加するのではなく、ターゲットを絞ったデータ駆動型の方法でKBを洗練するのに役立ちます。
各質問が複数回テストされるため、評価は次のような微妙な問題を表面化します:
答えが予測不可能に変わる
推論が漂う
ツール使用の代わりに事実の推測が行われる
実行間での矛盾
これらは手動で1、2回テストするだけでは決して特定できない問題です。
分析は何が間違っていたかを示すだけでなく、それを修正する方法も教えてくれます。
モデル自身の診断に基づいた実行可能な推奨事項を受け取ります:
改善されたフレージング
より厳格なルール
必須のツール使用
より明確な委任ポリシー
より正確なトーンと構造
これは、ワークフローに直接組み込まれた自動プロンプトエンジニアリングです。
次のいずれかを変更するたびに:
システムプロンプト
知識ベースのエントリ
ツール
委任ルール
推論ポリシー
…同じ評価を再実行してスコアを比較できます。更新がパフォーマンスにどのように影響したかを正確に確認できます — 良い方向にも悪い方向にも。
評価は継続的な改善ループになります。
サポート、財務分析、医療シナリオ、または法的に敏感なコンテンツを扱う場合でも、評価により次のことが保証されます:
ポリシーが遵守される
トーンガイドラインが尊重される
危険なギャップがフラグ付けされる
不正確な推論が表面化する
コンプライアンス基準が満たされる
これは特に企業や顧客向けAIにとって重要です。
エージェント評価は、AgentXの他の部分と同じクレジットモデルを使用します。各テスト実行は通常のエージェントメッセージと同じようにクレジットを消費します - 追加料金や隠れた料金はありません。評価は既存のプラン制限とクレジット残高に従うため、何に費やしているかを常に正確に把握できます。
従来のソフトウェアでは、QAが信頼性を確保します。
AgentXでは、評価がエージェントのQAです。
「良い」とは何かを定義します。
AgentXはエージェントがそれを一貫して提供できるかどうかを確認し、できない場合に改善すべき点を正確に示します。
評価はAIをブラックボックスから透明で測定可能で改善可能なシステムに変えます。
Discover how AgentX can automate, streamline, and elevate your business operations with multi-agent workforces.
AgentX | One-stop AI Agent build platform.
Book a demo© 2026 AgentX Inc

