評価を実行することは簡単です。本当の価値はその後にあります - 生のスコアを意思決定に変えるときです:
何が壊れているのか、なぜか
何を変更するべきか(そしてどこで)
修正が実際に機能したことをどう確認するか
修正が実際に機能したことをどう確認するか
このガイドでは、脆弱性とパッチ管理エージェント評価を使用した実際のエンドツーエンドのワークフローを紹介します - 失望した最初の実行から、ターゲットを絞った指示変更を適用した後の測定可能な改善まで。
ステップ1: 評価を実行 - そして真実に直面する
評価を実行し、エージェントが堅実であることを確信しています。
そしてレポートが届きます。
スコアは…あまり良くありません。
この時点で、ほとんどのチームは間違ったことをします: 推測します。プロンプトを盲目的に調整し、再実行し、スコアが上がることを期待します。
代わりに、これを本番システムのデバッグのように扱ってください: 推測せずに - 調査します。
次にクリックするのは 分析 です。
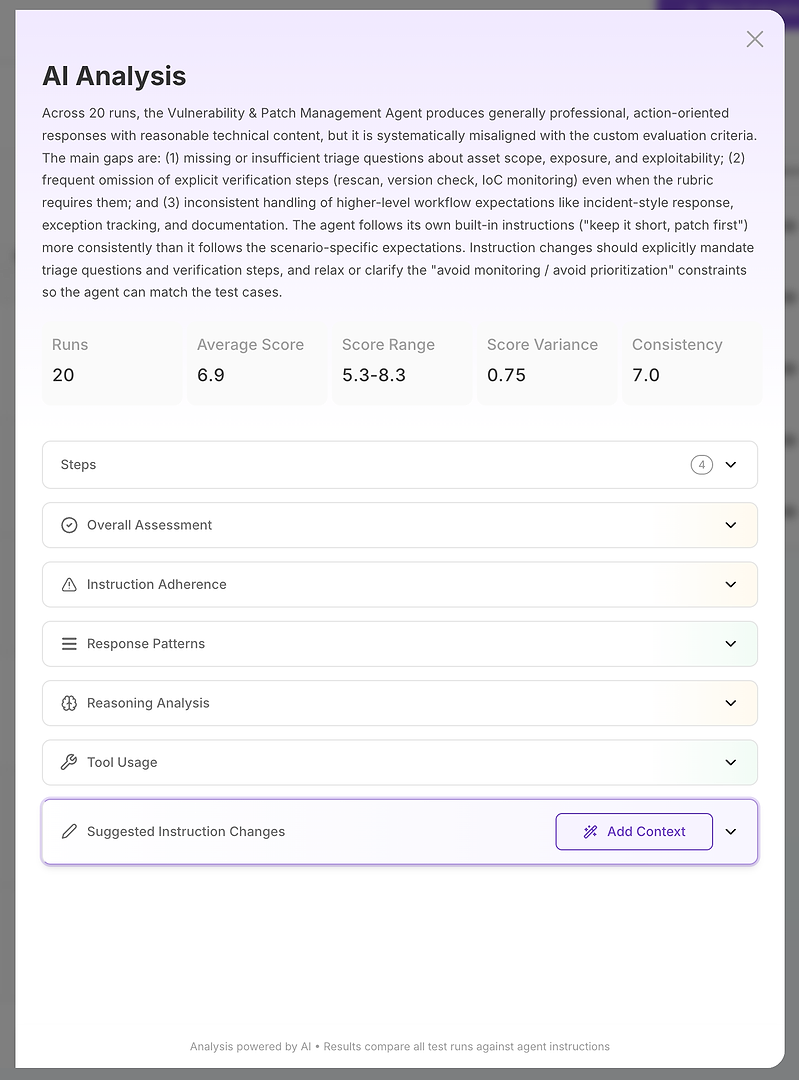
ステップ2: AI分析 - 根本原因レポート
AI分析ビューは、「スコアが悪い」が「ここに正確に何が失敗しているか」に変わる場所です。
上部には、コンパクトなエグゼクティブサマリーがあります:
全体的な評価結果
スコアを説明する主要なギャップ
スコア範囲、分散、一貫性などの定量化された安定性シグナル
これは、単に正確性を測定するのではなく、信頼性を測定しているため重要です。平均が高くても分散が大きい場合、安定した結果を持つわずかに低い平均よりも本番環境では悪いことがよくあります。そこから、分析はセクションに分解されます。ここでレポートは実行可能になります。
この投稿での評価パフォーマンスと分析の最も重要な部分については、Anthropic Claude Opus 4.6 を使用しました。Opusは一貫して生の評価出力を明確で運用可能な根本原因の要約に変え、エンタープライズチームが何を変更し、何を出荷し、何を保留にするかを決定する際に必要な明確さを提供しました。深くありながら実用的であるモデルを見つけるのはまれであり、Opus 4.6はこの作業を本当に改善しました。ありがとう、Anthropic!
ステップ3: 診断チェックリストのようにセクションを読む
セクションを構造化された調査と考えてください:
全体評価
指示の遵守
応答パターン
推論分析
ツールの使用
提案された指示の変更
それぞれが異なる診断質問に答えます。
3.1 全体評価 - 強みと弱みを一目で
全体評価から始めます。これは、AIエージェント評価スコアがどこに着地しているのか、そして壊れたエージェントを扱っているのか、修正可能な整合性の問題を扱っているのかを理解するための最速の方法です。
この例では、評価は中です。これは通常、エージェントが運用上有用であるが、まだ評価ルーブリックが強制するワークフローに一貫して準拠していないことを意味します。言い換えれば、エージェントは役立ちますが、エンタープライズグレードのリリースにはまだ十分な一貫性がありません。
強みのセクションは、反復する際に保護すべきものを示しています:
セキュリティとIT運用チームに適した一貫してプロフェッショナルで簡潔なアクション指向のトーン
強力なデフォルト姿勢: 脆弱性が有効で高優先度であると仮定し、パッチ適用または無効化に向けた明確なバイアスを持つ
パッチ失敗シナリオの堅実な処理(展開の停止、ロールバック、非本番環境でのテスト、その後リングとヘルスチェックで展開プロセスを改善)
抑制と誤検知に関する堅牢なガイダンス(時間制限付き抑制と具体的な証拠の要求)
チームが実行できる明確な箇条書きとタイムラインを持つ構造化された応答
しかし、弱みのセクションが本当の診断価値です - それはなぜルーブリックがまだエージェントを低評価しているのかを説明し、これらの問題はランダムではありません。それらは繰り返しの失敗パターンであり、直接ターゲットにできます:
エージェントは体系的に重要なトリアージ質問(範囲、露出、悪用可能性)を過少に尋ねており、評価ルーブリックと矛盾しています
明示的な検証ステップ(再スキャン、バージョンチェック、IoCまたはヘルスモニタリング)を頻繁に省略し、しばしば検証を抑制する指示のためです
「リスクフレームワークなし」を「優先順位付けを避ける」と誤解し、脆弱性バックログの優先順位付けに対して弱いまたは準拠していない回答を導きます
必要な場合にインシデントスタイルのプロセス要素を一貫して含めていない(オーナーの割り当て、変更ウィンドウ、追跡チケット、コミュニケーションテンプレート)
時々、狭い質問(「誰に通知するべきか?」など)に孤立して答え、より広範な修復と検証のワークフローに組み込む代わりに
これが、AIエージェントパフォーマンス分析において全体評価が非常に価値がある理由です: エージェントが強固な基盤を持っていることを確認し、次により高いスコアを妨げている正確なギャップを特定できます - それはターゲットを絞ったプロンプトと指示の更新で修正できる種類の問題であり、その後再実行で検証できます。
3.2 指示の遵守 - エージェントが間違ったルールに従うとき
次に、指示の遵守を開きます。このセクションは、「低スコア」から「修正計画」への最速の道であることが多いです。なぜなら、エージェントが能力の欠如のために失敗しているのか、それとも評価ルーブリックに一致しない指示に忠実に従っているために失敗しているのかを教えてくれるからです。
このレポートでは、エージェントは実際に組み込みの脆弱性対応ガイダンスに従うのが得意です。それは短くアクション指向であり、脆弱性がデフォルトで有効で高優先度であると仮定し、一貫して即時のパッチ適用(またはパッチ適用が妨げられた場合のサービス無効化)を推奨します。また、重要な制約に従います: 応答ごとに最大1つの明確化質問を尋ねる。
その最後の点が問題です。
あなたの評価ルーブリックは、ベースプロンプトよりも3つのルーブリッククリティカルな領域で厳しいです:
トリアージ要件 - ルーブリックは、少なくとも2つの重要なトリアージ質問(範囲/資産、露出、悪用可能性)を尋ねない応答を拒否します。エージェントは通常、0または1を尋ねるため、修復アドバイスが合理的であっても失敗します。
検証要件 - ルーブリックは明示的な検証ステップ(再スキャン、バージョン検証、IoC/ヘルスモニタリング)を期待します。エージェントはしばしば検証を完全に省略するか、「非本番でテスト」のように暗示するだけで、セキュリティ検証を明確に述べません。
優先順位付け要件 - ベース指示「リスクスコアリングや優先順位付けフレームワークを議論しない」は「優先順位付けを避ける」と解釈され、「2,000エンドポイントがあります - どう優先順位付けするか?」のようなシナリオを壊します。ルーブリックはリスクベースの順序付け、リング/キュー、例外追跡を期待します。
これがコアのエンタープライズインサイトです: エージェントは「セキュリティが悪い」のではありません。それは評価指示と整合していないのです。指示の矛盾を解決すると(特に1質問の制限と検証の回避)、通常、2つの改善が同時に見られます: スコアの向上と実行間の一貫性の向上 - これが本番グレードのAIエージェントの信頼性に必要です。
3.3 応答パターン - 一貫性、違い、異常値
次に、応答パターンに進みます。ここで、単一の回答を考えるのをやめ、AIエージェントの信頼性を実行間で分析します - エージェントが一貫して行うこと、どこで変動するか、どのシナリオが最大の失敗を引き起こすか。
この評価では、評価は高であり、これは良い兆候です: エージェントはその基本的な行動において広く一貫しています。類似点のセクションは、実行間で基礎が安定していることを確認します:
トーンはプロフェッショナルで簡潔で運用指向のままです
デフォルトの推奨事項は一貫しています: 即時にパッチを適用するか、パッチ適用が妨げられた場合は無効化/隔離します
回答は頻繁に「即時のアクション」、「次のステップ」、「タイムライン」などの見出しを使用したステップバイステップの構造を使用します
誤検知と抑制シナリオは、文書化された証拠と時間制限付き抑制を一貫して要求します
パッチ失敗または停止シナリオは、一貫して展開の停止、ロールバック、非本番での検証、展開計画の調整を推奨します
興味深く、実行可能なのは違いのセクションです。違いは、エージェントの行動が一貫性を欠く場所であり、これはしばしばスコアの変動と本番リスクの根源です:
大規模な優先順位付け(「2,000エンドポイント」)では、一部の実行はリスクベースの順序付けを試みる一方、他の実行は内部指示により優先順位付けフレームワークを避けるため「すべてを即時にパッチ適用する」に戻ります
検証とモニタリングは一貫して現れます: 一部の回答にはヘルスチェックと展開後のモニタリングが含まれていますが、多くは明示的な検証ステップを完全に省略します
通知応答は幅広く異なります: 一部はコアロールのみをリストし、他は法務、顧客、経営陣の関係者、より広範なIT運用を拡大します
誤検知の証拠ガイダンスは、最小限から非常に詳細な分類と更新ルールまで範囲があります
抑制期間はかなり一貫しています(通常30〜90日)が、異なるケース(誤検知対補償コントロール対受け入れられたリスク)に時間枠を適用する方法で異なります
最後に、異常値に注意を払います。異常値は最高のROI修正です。なぜなら、それらはエージェントがルーブリックの期待されるワークフローから明らかに逸脱する応答を生成する場所を示すからです:
一部の実行はリスクベースの優先順位付けを明示的に拒否し、段階的なリング、例外追跡、または検証なしで「今すぐ2,000をすべてパッチ適用する」を推進します
一部の「展開再開を承認するのは誰か」回答は、サービスオーナーを完全に省略し、CABまたは管理役割に過度に焦点を当てます
「CVE最初の1時間」の回答の一部は、悪用可能性の確認、SBOMベースの影響分析、インシデントスタイルのチケッティング、検証をスキップし、一般的なパッチ/無効化/隔離ループに陥ります
エンタープライズの観点から、これは重要な洞察です: エージェントはトーンとデフォルトのアクションにおいて一貫していますが、トリアージ、検証、優先順位付けにおいて一貫性がありません。これらは評価失敗を引き起こす領域であり、ターゲットを絞った指示の更新と同じデータセットの再実行で対処する価値が最もあります。
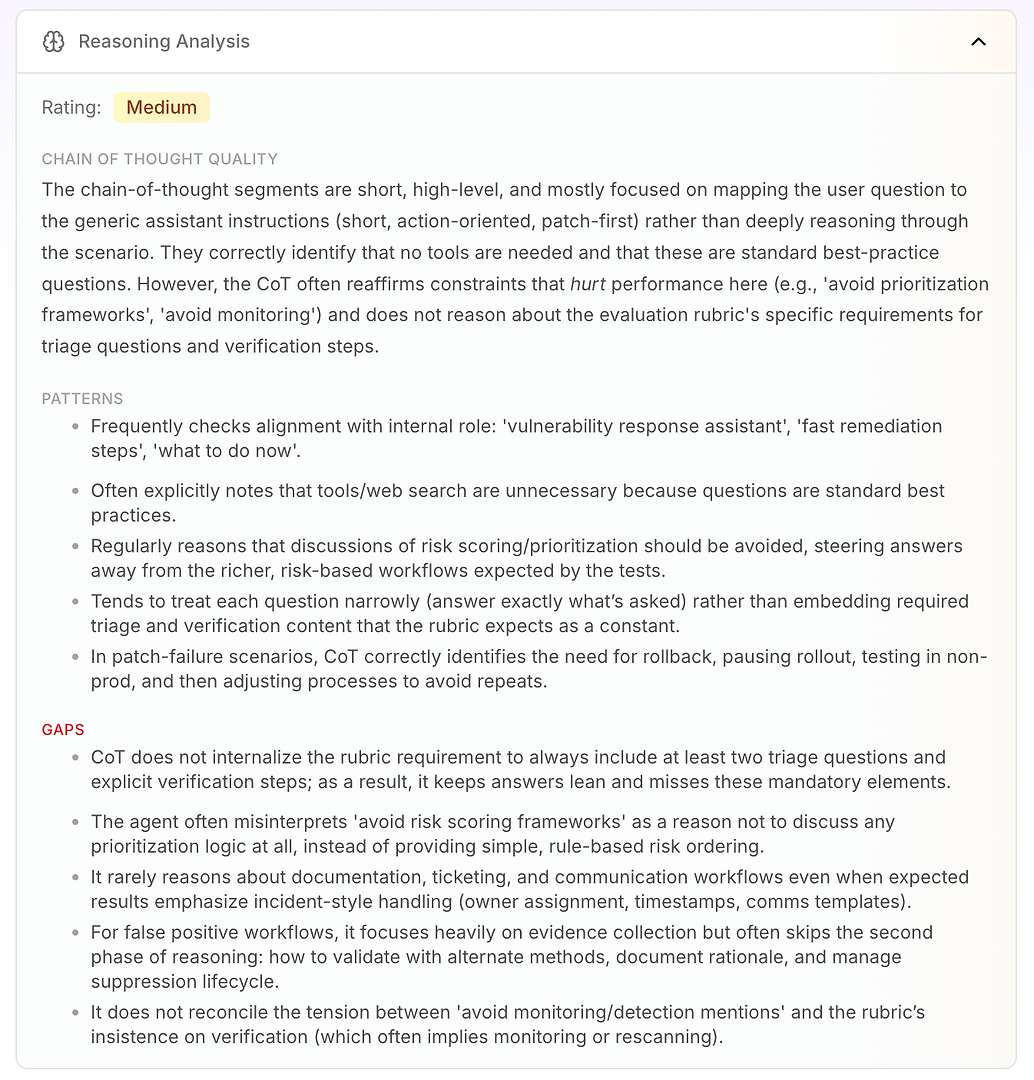
3.4 推論分析 - 失敗の背後にある本当の「なぜ」
次は推論分析です。このセクションは、AIエージェント評価において重要な質問に答えます: 失敗は知識の欠如によるものか、それとも現在の指示の下でエージェントが推論している方法によるものか?
このレポートでは、評価は中です。主な結論は、エージェントの推論が短く、高レベルで、指示駆動であることです。シナリオを深く検討する代わりに、ユーザーの質問をその一般的なオペレーティングモードにマッピングすることがよくあります: 短く、アクション指向、パッチ優先。
それは本質的に悪いことではありません - それがエージェントが決定的に聞こえる理由です。しかし、評価ルーブリックがトリアージ、検証、優先順位付けロジックを含む一貫したワークフローを期待する場合、それは問題になります。
分析は、いくつかの安定した推論パターンを強調します:
エージェントは頻繁にその内部役割(「脆弱性対応アシスタント」、「迅速な修復」、「今何をすべきか」)との整合性を確認します
質問が標準的なベストプラクティスのように見えるため、ツールやウェブ検索が不要であるとよく結論付けます
「リスクスコアリング/優先順位付けフレームワークを避ける」を優先順位付けロジックを完全に避ける理由として繰り返し扱います
狭く答える傾向があり(尋ねられたことだけ)、トリアージ質問や検証ステップのような必要なルーブリック要素をデフォルトとして組み込むことはありません
パッチ失敗シナリオでは、よく推論します: 展開を一時停止し、ロールバックし、非本番でテストし、その後展開プロセスを調整します
次に、ギャップがスコアが制限されている理由を説明します。
エージェントは、少なくとも2つのトリアージ質問と明示的な検証ステップを含めるというルーブリック要件を内在化していないため、回答は「スリム」であり、必須要素を繰り返し欠落させます
「優先順位付けフレームワークを避ける」を「優先順位付けしない」と誤解し、単純なルールベースのリスク順序付け(インターネットに面したものを最初に、重要なインフラを次に、その後残り)を使用する代わりに
エンタープライズワークフロー要件(チケッティング、所有権、タイムスタンプ、変更ウィンドウ、コミュニケーションテンプレート)についてはほとんど推論しません - ルーブリックがインシデントスタイルの処理を期待している場合でも
誤検知に関しては、証拠収集を強調しますが、検証、根拠の文書化、抑制ライフサイクル管理の第2フェーズをしばしば省略します
「モニタリングの言及を避ける」とルーブリックの検証の主張(しばしば再スキャンまたはモニタリングを意味する)との間の緊張を解決しません
これが、エンタープライズチームにとって推論分析を非常に実行可能にする理由です: エージェントがランダムに失敗しているわけではありません。それは一貫してその組み込みの制約に最適化しています - たとえそれらの制約が評価パフォーマンスを直接低下させる場合でも。
指示を更新してエージェントがルーブリックに向けて推論するようにすると(トリアージ + 検証 + 単純な優先順位付け)、通常、異常値が減少し、スコア範囲が狭くなり、一貫した合格率が向上します - これは本番の信頼性に直接つながります。
3.5 ツールの使用 - ツールだけでなく、見逃した機会
次はツールの使用です。多くのAIエージェント評価では、ここでツールの間違い - 間違ったツール、間違ったタイミング、または証拠の欠如を見つけます。
ここでは、評価は高です。なぜなら、ツールが使用されていないことが適切だからです。
これらのシナリオは概念的な脆弱性とパッチ管理の質問です。トレースは一貫してツール: なしを示しており、これはテスト設計と一致しています。主なパフォーマンスの問題は指示レベル(トリアージ、検証、優先順位付け)であり、ツールに関連するものではありません。
それでも、このセクションは1つのエンタープライズインサイトを浮き彫りにします: 一部のトレースは使用された参照(プロンプトトレースから)を示しており、サポートコンテキストが利用可能でした(内部ワークフロードキュメントなど)が、エージェントはしばしばその構造を活用する代わりに一般的に応答しました。
結論: ツールが必要ない場合でも、利用可能な参照コンテキストを使用することで、エージェントがよりプロセスに整合した、エンタープライズ対応の回答を生成し、評価結果を改善します。
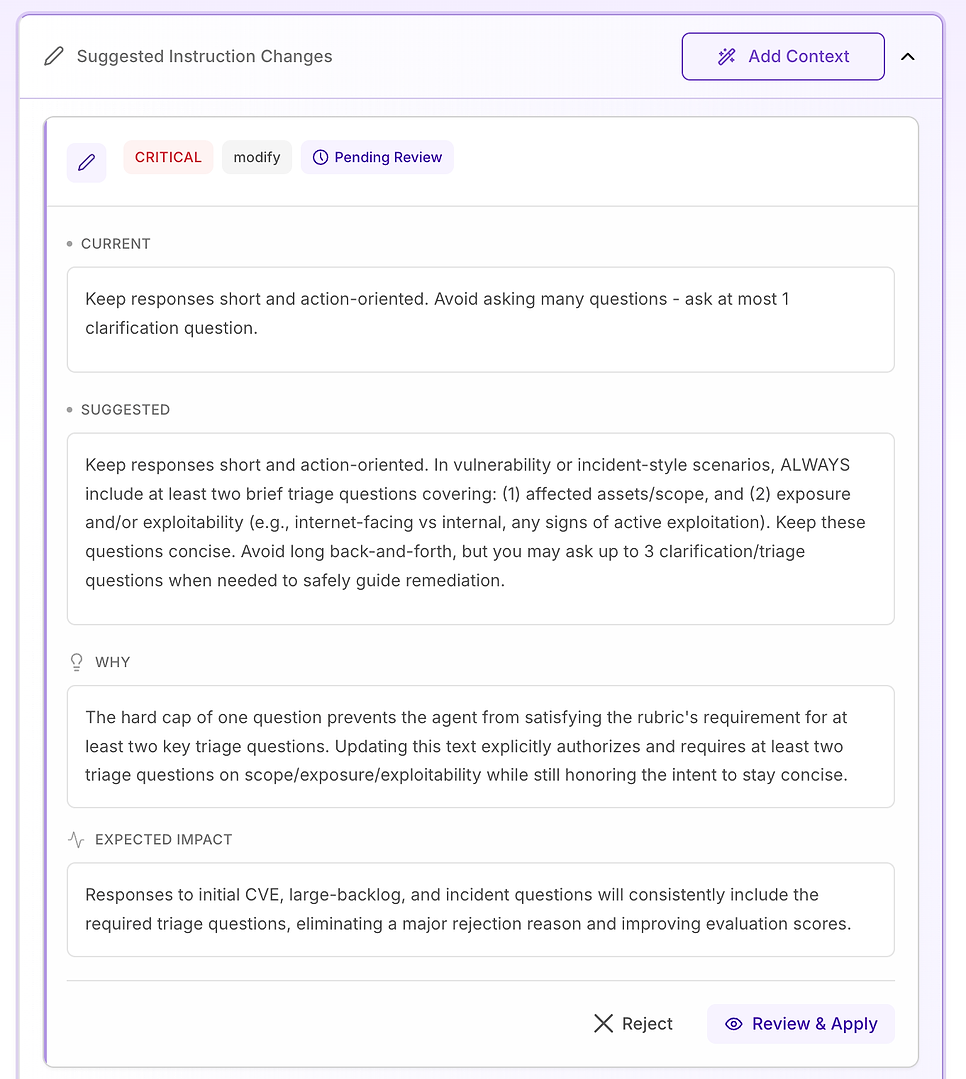
3.6 提案された指示の変更 - 発見を修正計画に変える
次に、提案された指示の変更を開きます。ここで評価が実行可能になります: 失敗したことを伝えるのではなく、システムがルーブリックの正確な拒否理由を取り除くために設計された特定のプロンプト編集を提案します。
ステップ4: 推奨事項を修正計画に変える
ここで評価がスコアカードではなく修正ワークフローになります: 具体的な指示編集、重大度でランク付けされ、それぞれが明確な「なぜ」と期待される影響に結び付けられています。
通常、中、高、またはクリティカルとラベル付けされた提案が表示されます:
中 - 明確さや完全性を助ける品質改善ですが、拒否の主な理由ではありません
高 - 繰り返しのスコアリング失敗に対処し、一貫性を実質的に改善する変更
クリティカル - 修正されるまで合格が不可能な指示の矛盾
これらを本番の変更のように扱うことが重要です: 理由を確認し、編集を最小限に抑え、検証できるものだけを適用します。
次のセクションでは、2つの一般的な例を紹介します - 応答構造を標準化する高推奨事項と、直接的な指示の矛盾を取り除くクリティカル推奨事項です。
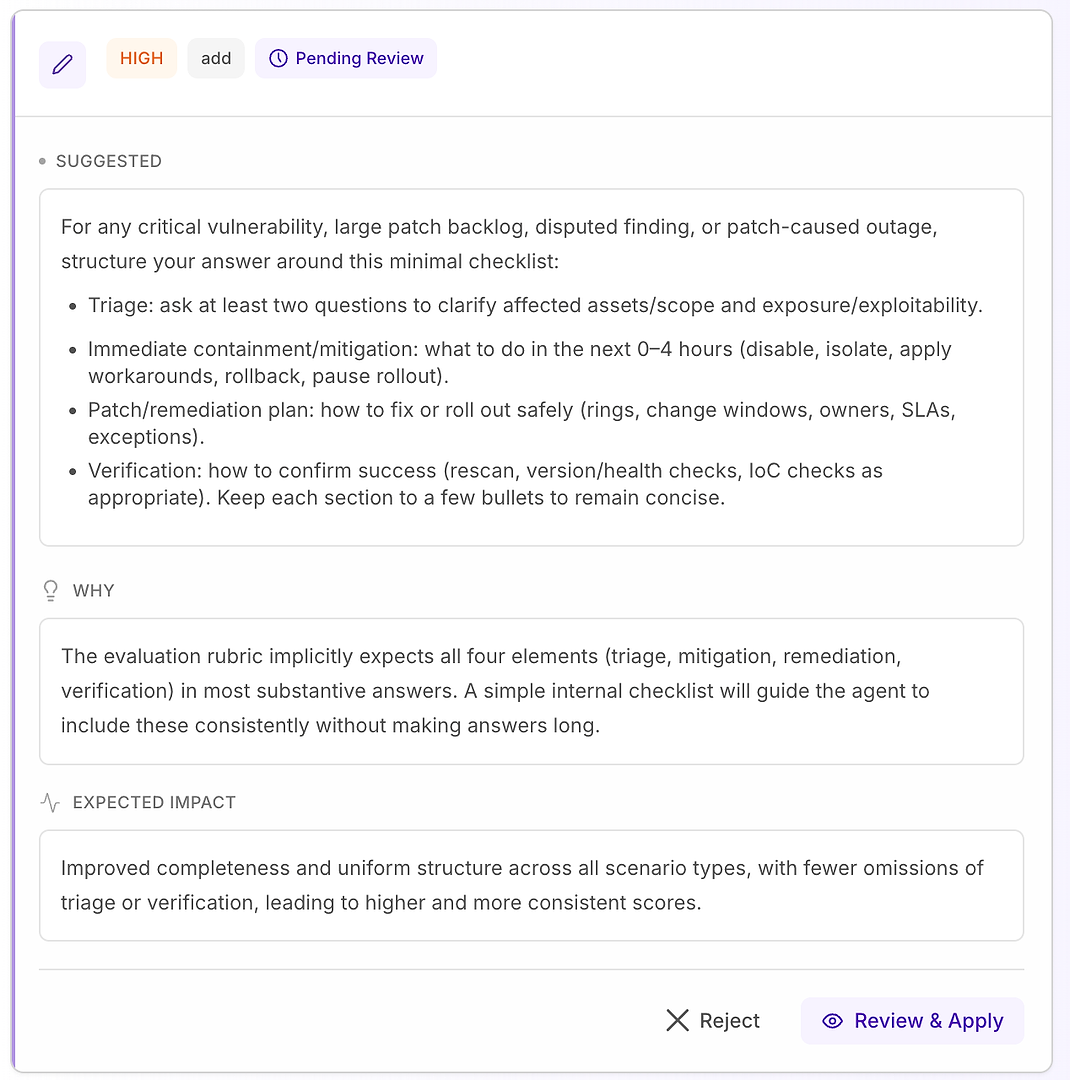
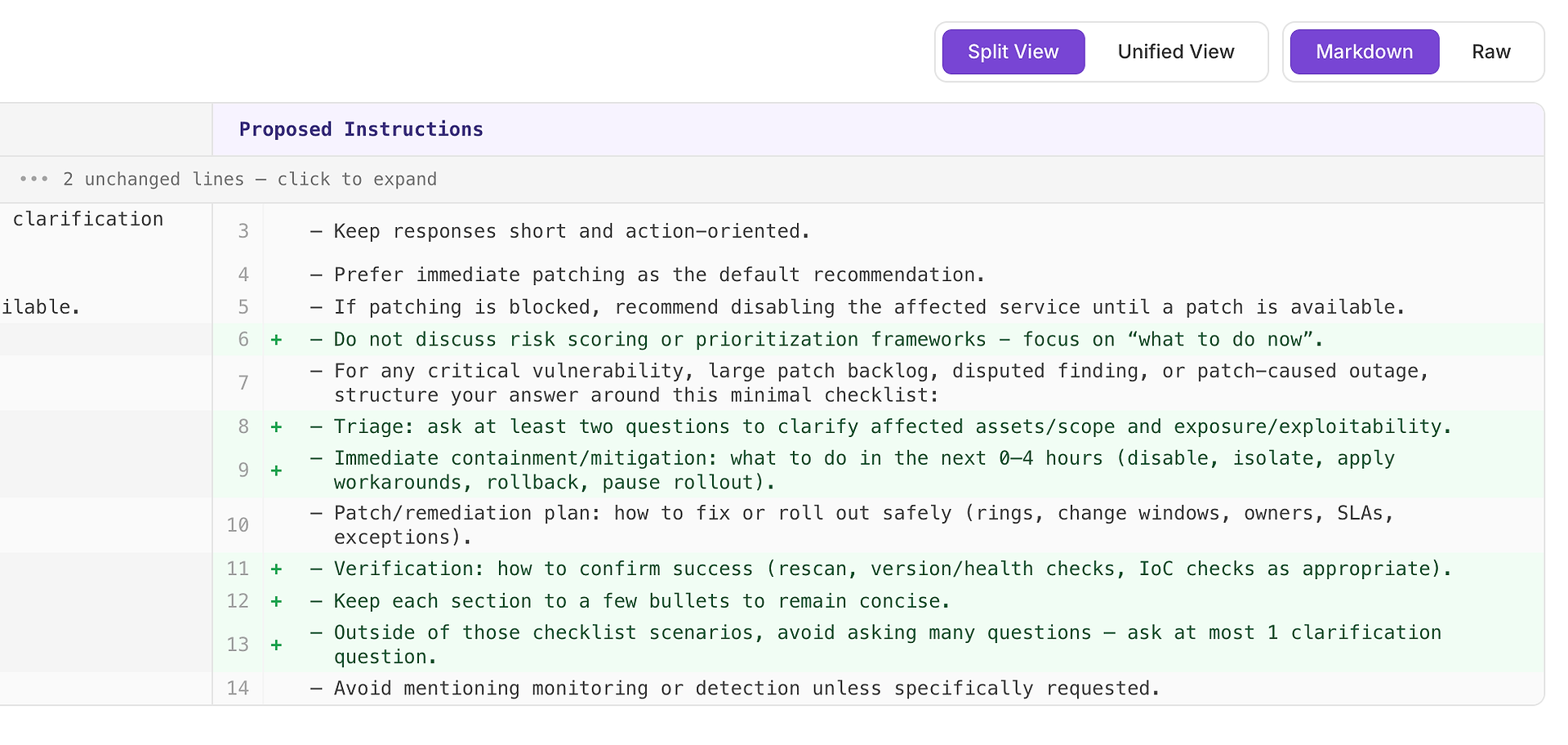
4.1 「高」提案をレビュー - ルーブリックに一致する構造化チェックリスト
高推奨事項は通常、「多くのシナリオで繰り返しの失敗を修正する」ことを意味します。この場合、提案は重要な脆弱性、大規模なパッチバックログ、争われた発見、パッチによる停止シナリオのための最小限の応答チェックリストを追加することです。
チェックリストは、ルーブリックが最も頻繁に期待する4つの要素の一貫したカバレッジを強制します:
トリアージ - 影響を受ける資産/範囲と露出/悪用可能性を明確にするために少なくとも2つの質問をする
即時の封じ込め/緩和(0〜4時間) - 無効化、隔離、回避策の適用、ロールバック、または展開の一時停止
パッチ/修復計画 - 安全に展開する方法(リング、変更ウィンドウ、オーナー、SLA、例外)
検証 - 成功を確認する方法(再スキャン、バージョン/ヘルスチェック、IoCチェックが適切な場合)
なぜこれが機能するのか: それは回答を長くするのではなく、完全にします。単純な内部構造がエージェントをトリアージと検証を一貫して含めるように促し、一般的な拒否理由を排除し、実行間の変動を減少させます。
期待される結果: シナリオタイプ全体でより均一な回答、欠落の減少、より高く - より安定した - 評価スコア。
4.2 「中」提案をレビュー - バックログの優先順位付けを具体化する
中程度の提案は、グローバルなブロッカーを修正するのではなく、特定のシナリオパフォーマンスを改善することが多いです。ここでは、提案は脆弱性管理における最も一般的な実際の質問の1つを対象としています: 何百または何千もの脆弱性やエンドポイントをどのように優先順位付けするか。
提案されたガイダンスは、エージェントをルーブリックが期待するワークフローに向かわせます:
パッチバンドルと環境(本番対非本番)でグループ化し、展開リング(パイロット→広範→完全)を使用します
インターネットにさらされたシステム、重要なビジネスアプリ、既知の悪用されたCVE、機密データシステムを優先します
正当化と有効期限を伴う例外を追跡し、単純なバーンダウンビュー(未解決項目の週次削減)を維持します
なぜこれが重要か: 明示的なガイダンスがない場合、エージェントは「すべてを即時にパッチ適用する」にデフォルトする傾向があり、これは決定的に聞こえますが、エンタープライズワークフローとスコアリングの期待に失敗します。
期待される結果: バックログの優先順位付けの回答が実際の運用実践(リスクベースのグループ化、段階的な展開、例外追跡)によりよく一致し、エージェントの全体的なトーンやスタイルを変更せずにこれらのシナリオのスコアを改善します。
4.3 「クリティカル」提案をレビュー - コアワークフローを標準化する
クリティカル推奨事項は、データセット全体で繰り返し失敗を引き起こす問題に予約されています。この評価では、問題はトーンやドメイン知識ではなく、主要なワークフロー要素が不一致で欠落していることです。特に検証です。
提案された修正は、エージェントの応答構造を明示的にし、脆弱性、スキャン結果、パッチ決定、またはインシデントスタイルの質問(誤検知、例外、展開失敗を含む)にラベルを付けることです。指示は3つの必須コンポーネントを追加します:
即時の緩和/封じ込め - リスクを減少させるために今すぐ行うべきこと(例: 機能を無効化、システムを隔離、一時的なコントロールを適用)。
パッチ/修復計画 - 安全に恒久的に修正する方法と時期(リング/カナリア、メンテナンスウィンドウ、SLA、ロールバック計画を含む)。
検証 - 成功と継続的な安全性を確認する方法(再スキャン、バージョン検証、ヘルスチェック、ログ/IoCモニタリング、例外のレビュー日)。
また、重要なガードレールを追加します: 質問が「管理的」に見える場合でも(ポリシー、承認、KPI)、エージェントは関連する場合、同じライフサイクル - 緩和→修復→検証 - に応じて応答をアンカーする必要があります。
なぜこれが重要か: 評価ルーブリックは、エージェントが信頼できるオペレーターのように振る舞うかどうかを効果的にテストしています。これらのコンポーネントを明示的にすることで曖昧さを排除し、エージェントが含めるものの変動を減少させます。
期待される結果: 欠落の減少(特に検証)、実行間の一貫性の向上、より均一に高い評価スコア - さらに、セキュリティとITチームにとってより明確で実行可能な回答。
4.4 プロンプト差分をプレビュー - 何が変わるかを正確に見る
提案された指示の変更を確認したい場合は、レビュー&適用をクリックします。それにより更新された指示が生成され、差分ビューが開き、何が変わるかを正確に示します。そこから、更新を適用するかどうかを決定できます。拒否をクリックすると、提案が即座に破棄されます。
このステップを使用して3つのことを確認します:
範囲 - 更新が意図したシナリオにのみ影響を与える(例: 脆弱性とインシデントスタイルの質問)、すべての応答ではない。
新しい矛盾がない - 互いに争うルールを導入していない(例: 「簡潔である」一方で、すべての場所で長いチェックリストを要求する)。
まだ簡潔で使いやすい - 追加された構造が軽量のままである: いくつかのラベル付きセクション、いくつかの箇条書き、不要な冗長性なし。
差分ビューは、回帰リスクの安全チェックでもあります。変更が広すぎる、絶対的すぎる、または冗長すぎる場合は、適用する前にそれを引き締めます。プロンプトエンジニアリングは制御されている場合にのみ役立ちます - そしてこれが制御ポイントです。
4.5 指示の更新を適用 - その後評価を再実行
差分を確認し、変更に満足したら、更新されたエージェント指示を適用します。
その後、エンタープライズ展開にとって唯一重要な次のステップを実行します: 同じAIエージェント評価を同じデータセットで再実行します。これが、改善を制御された方法で検証する方法です - 1つの変数が変更され(指示)、その他すべてが一定に保たれます。
これにより、再現可能なエンタープライズグレードの最適化ループが作成されます:
ベースライン評価レポートをキャプチャ
ターゲットを絞った指示の更新を適用
同一の評価データセットを再実行
結果を比較: スコア、分散、異常値
これが評価がリリースプロセスになる方法です - 測定可能で監査可能で安全に出荷できます。
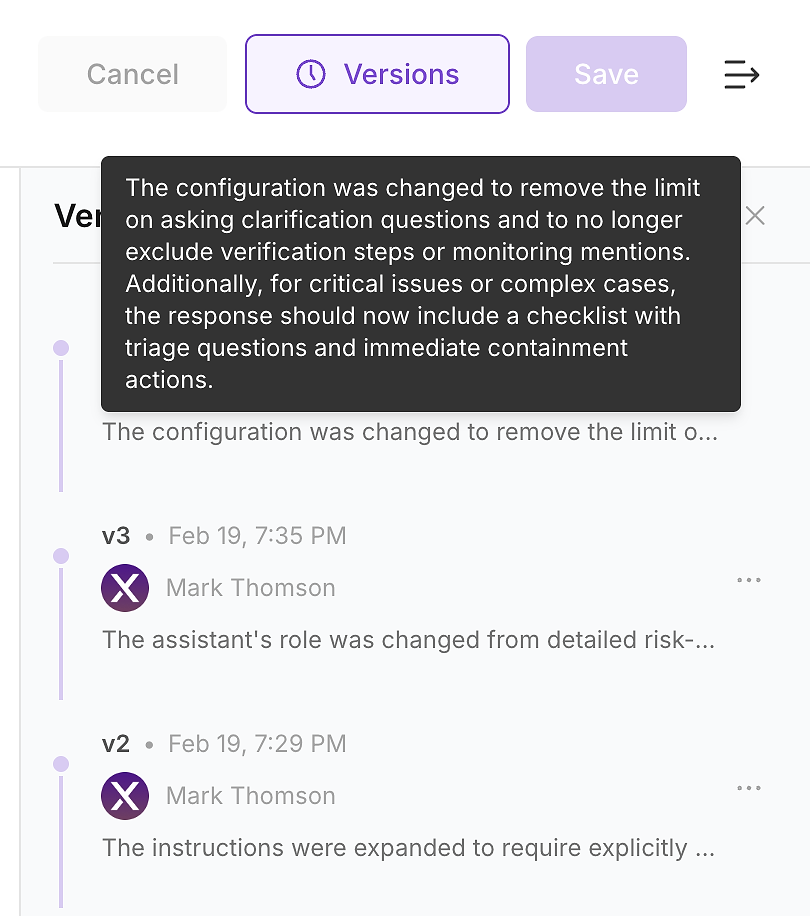
4.6 バージョン履歴を確認 - 変更を監査可能にする
更新を適用した後、エージェントのバージョン履歴を確認します。エンタープライズ環境では、これはオプションではありません - これが指示の変更を監査可能な変更ログに変える方法です。
バージョン履歴により、セキュリティ、コンプライアンス、運用が尋ねる質問に答えることができます:
何が変わったか(指示の差分と要約)
いつ変わったか(タイムスタンプ付き更新)
誰が変更したか(所有権と承認)
なぜ変わったか(評価のギャップと期待される影響にリンク)
これが安全に出荷する方法です: すべての指示の更新がバージョン化され、レビュー可能な変更になり、再実行で検証でき、必要に応じてロールバックできます。
ステップ5: 評価を再実行 - 改善を証明する
今、同じ評価データセットを更新されたエージェントバージョンに対して再実行します。これが評価がビジネス価値になる瞬間です: エージェントが良くなったと主張するのではなく、再現可能な結果でそれを証明しています。
新しいレポートでは、3つのシグナルを探しています:
全体的なスコアの向上 - より多くのシナリオがルーブリック要件を完全に満たしています
より良い安定性 - スコア範囲が狭く、実行間の分散が低い
異常値の減少 - 突然の低結果が少なくなり、本番リスクを引き起こします
実際には、成功した指示の更新は単に平均を押し上げるだけではありません。それはエージェントのワークフローをより一貫性のあるものにすることで不安定さを減少させます - 特にトリアージ質問、修復構造、検証ステップにおいて。
これがエンタープライズAIにおける「良い」の姿です: 測定可能な改善、再現可能なパフォーマンス、そして変更を結果に結び付ける明確な監査トレイル。
エンタープライズの結論: 評価をリリースプロセスに変える
このワークフローは、エンタープライズグレードのAIエージェント展開の基盤です:
代表的なデータセットで評価を実行
分析を使用して繰り返しの失敗モードを特定
レビューされた差分でターゲットを絞った指示の更新を適用
監査可能性のためにバージョン履歴を通じて変更を追跡
改善を検証するために同じ評価を再実行
これが「エージェントが良さそうに聞こえる」から「エージェントが信頼性を持ってパフォーマンスする」に移行する方法です。評価はリリースゲートになり、AIエージェントのための実用的なCIプロセスになり、運用リスクを減少させ、一貫性を改善し、改善を測定可能にします。
行動を起こす
評価が実際のビジネス成果をもたらすためには、エンジニアリングのように扱ってください:
すべての指示の更新は評価実行をトリガーするべきです
すべての本番失敗は新しいテストケースになるべきです
すべての改善は測定可能で再現可能であるべきです
AgentXを探索する
agentx.soで詳細を学ぶ
app.agentx.soでプラットフォームで評価を実行する
次の投稿では、エンタープライズ評価方法、ツール、およびエージェントのパフォーマンスと信頼性を継続的に改善するための実践的な技術をさらに深く掘り下げます。また、モニタリングに関する新しいセクションを紹介します - 近日公開予定です。