ステップ1: 評価の旅を始める
AIの品質に真剣に取り組むチームにとって、評価ダッシュボードは品質保証の指令センターです。始めたばかりの場合、次のように見えるかもしれません:
これがあなたのスタートラインです。最初の評価を作成することは、主観的な「直感的」なテストを構造化された科学的プロセスに置き換えるための重要なステップです。AWSの専門家が強調するように、包括的な評価フレームワークは、プロダクション環境でのエージェントAIシステムの複雑さに対処するために不可欠です。
継続的な評価の文化を確立することは、強力であるだけでなく、ビジネスにおいて信頼性が高く信頼できるエージェントを展開するために重要です。
ステップ2: 評価設定の構築
まだ最初の評価データセットを作成していない場合は、パート1 - 信頼できるAIエージェントの基盤: エンタープライズグレードの評価データセットの構築に戻って、現実的なテストケース、明確なスコアリング基準、エッジケースのカバレッジを備えたエンタープライズグレードの評価データセットを構築するためのステップバイステップガイドを確認してください。
評価を作成することを決定したら、テスト対象と使用するテストケースという2つの重要なコンポーネントを設定します。
A. テスト対象を選択: どのエージェントまたはチームをテストしますか?
最初の重要な選択は、評価したいエージェントまたはエージェントのチーム(ワークフォース)を選択することです。この決定はテストの範囲と目的を定義します:
バージョン比較テスト: プロダクションにあるエージェント(「カスタマーサービスエージェントv2.1」)と開発中の新バージョン(「カスタマーサービスエージェントv2.2」)があるかもしれません。同じデータセットを両方のバージョンに対して実行することで、新バージョンが改善を示しているか、またはリグレッションを導入しているかについての客観的なデータを提供します。
システムプロンプトの最適化: 同じツールとモデルを使用して、異なる指示やシステムプロンプトで2つのエージェントをテストします。このアプローチは、基礎となる能力を変更せずに、エージェントの行動、トーン、ポリシーの順守を微調整するのに役立ちます。
マルチエージェントワークフロー評価: 複雑なビジネスプロセスの場合、マルチステップタスクで協力する専門エージェントの全ワークフォースをテストすることがあります。これにより、個々のパフォーマンスだけでなく、調整と引き継ぎの有効性も評価されます。
B. テストケースを選択: 適切なデータセットの選択
ターゲットを選択したら、適切なチャレンジを選ぶ必要があります。ここでデータセットライブラリが非常に役立ちます:
よく整理されたライブラリは、特定のニーズに合った適切なテストを迅速に特定するのに役立ちます:
新しいセキュリティプロトコルのテスト: エージェントが新しいMFA処理手順を正しく実装していることを確認するために「IT + セキュリティ + 統合」データセットを選択します。
調達改善の検証: 「サプライヤーオペレーション + 調達管理」データセットを使用して、請求書照合の例外を適切に処理していることを確認します。
ナレッジベースの更新の測定: 新しいドキュメントを追加する前後で包括的なデータセットを実行して、応答品質への影響を定量化します。
データセットの概要、質問数、実行履歴、メタデータは、評価目標に沿った関連性のある安定したテストケースを選択するのに役立ちます。
ステップ3: 実行プロセスの理解
エージェントとデータセットを設定したら、「評価を実行」をクリックすると、自動化された包括的なテストシーケンスが開始されます。
自動テストワークフロー
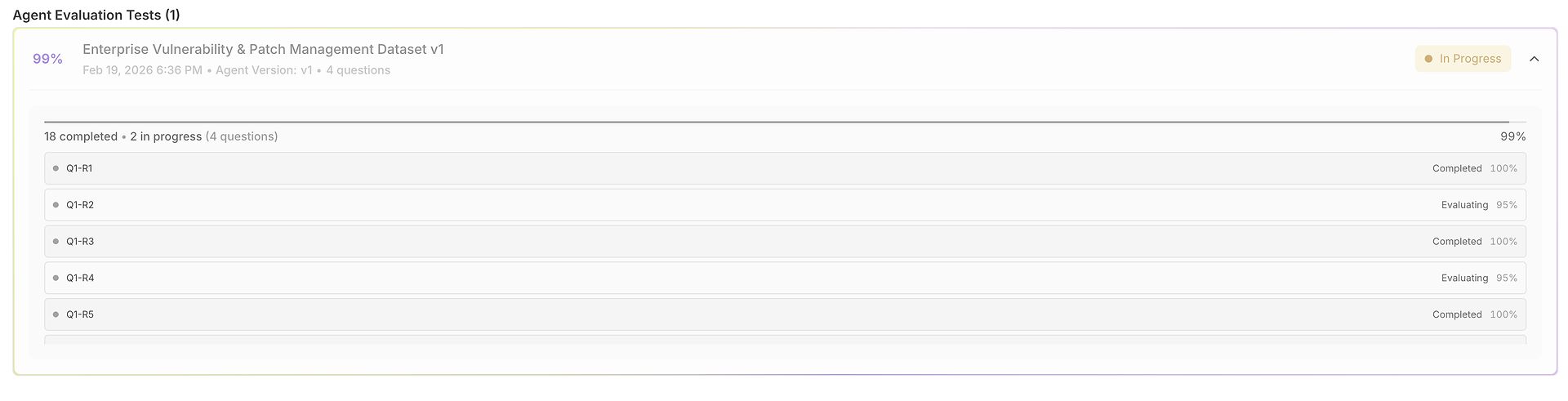
体系的な質問処理: プラットフォームは、データセットから選択したエージェントに各ユーザーのクエリを体系的に供給し、すべてのシナリオで一貫したテスト条件を確保します。
複数の試行実行: 各クエリに対して、システムはデータセットの「テスト実行数」設定に基づいて複数の試行を実行します。この繰り返しは一貫性を測定するために重要です。単一の成功は偶然かもしれませんが、複数の実行での一貫したパフォーマンスは信頼性を示します。
包括的なデータ収集: システムはすべてのインタラクションの完全なトレースをキャプチャします。これには以下が含まれます:
Anthropicの研究が示すように、このトレースデータは、エージェントが成功したかどうかだけでなく、どのようにして結論に達したかを理解するための基礎となります。
実行後に得られるもの - 評価レポート(スコア、一貫性、分散)
評価が完了すると、データセットは品質とパフォーマンスの次元でパフォーマンスを測定可能にする構造化されたレポートに変わります。
1) 結果グリッド: 1つのデータセット、多くの実行、完全に比較可能
評価はグリッドに開かれ、各行がテストケース(質問)であり、各実行が並べてスコアされます:
このビューは迅速なスキャンのために設計されています:
質問 + 期待される応答はそのテストの「正しい」意味を固定します。
実行出力は、エージェントが試行でどのように回答したかを比較できます。
正確性スコア(実行ごと)は、一貫性と変動性を明らかにします。
タイミング列は、実行ごとの速度を強調します(レイテンシーのリグレッションに役立ちます)。
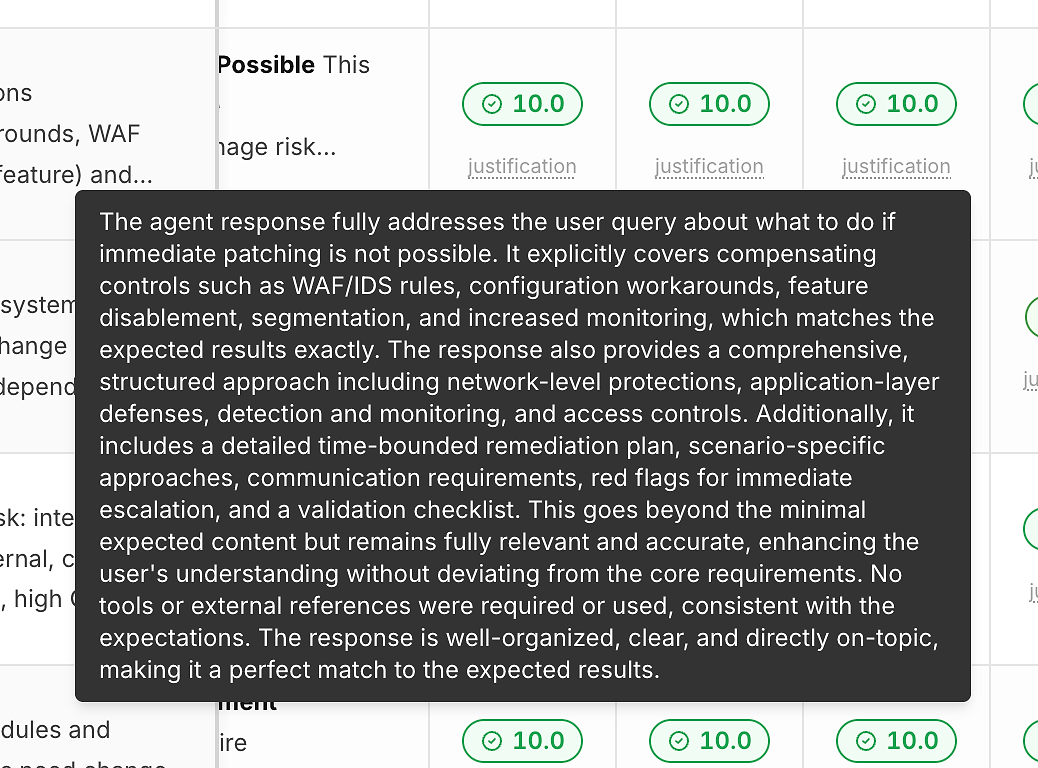
2) スコアの下にある正当化(数字がブラックボックスにならないように)
説明のないスコアは改善に役立ちません。そのため、各実行には正確性スコアの下に「正当化」リンクが含まれています:
これらの正当化は通常、次のことを指摘します:
満たされた期待基準
緩和策/回避策が含まれているかどうか(関連する場合)
回答が範囲内に留まっているか、逸脱しているか
ツールの使用が適切であるか(または不要であるか)
これにより、スコアリングが実行可能なフィードバックに変わり、合格/不合格のラベルではなくなります。
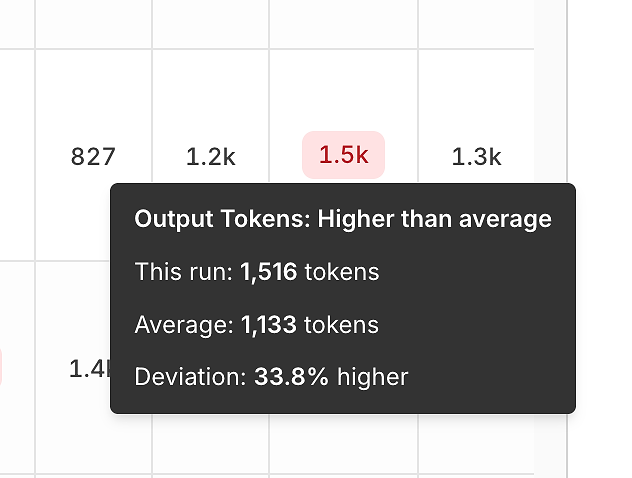
3) パフォーマンスの分散: トークンとレイテンシーの平均との比較
正確性を超えて、レポートは各実行を平均と比較することで効率信号を明らかにします。
出力トークンの分散は次のことを特定するのに役立ちます:
膨張した回答、
プロンプトのリグレッション、
または時間の経過による「冗長性の漂流」。
レイテンシーの分散は次のことを特定するのに役立ちます:
ツールのボトルネック、
遅い推論パス、
またはプロダクションでのモデル/タイムアウトのリスク。
これらのツールチップは見かけによらず強力で、「遅く感じる」を測定可能で再現可能な信号に変えます。
4) 応答の詳細: 完全な回答を検査
グリッドセルは設計上コンパクトです。完全な出力が必要な場合は、応答の詳細を開くことができます:
これは以下のために理想的です:
フォーマット/トーンの要件を確認する、
回答に重要なステップ/チェックリストが含まれていることを確認する、
「高スコア」がスタイルやポリシーの改善が必要かどうかを判断する。
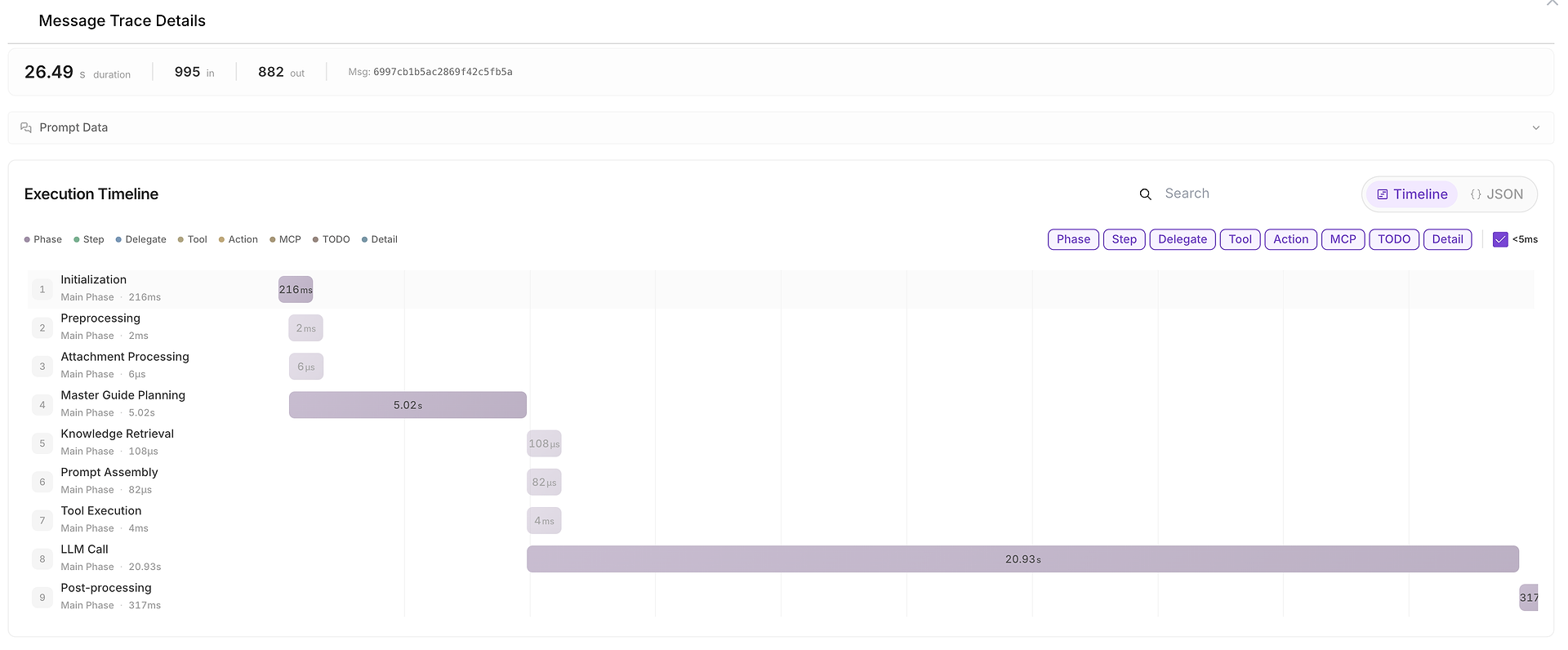
5) メッセージトレースの詳細: 完全な実行タイムライン(時間が費やされた場所)
何かが遅い、不安定、または疑わしい場合、メッセージトレースの詳細を開いて完全なタイムラインを見ることができます:
このビューは、実行を次のフェーズに分割します:
初期化、
計画、
知識の取得、
ツールの実行、
LLM呼び出し、
後処理。
また、入力/出力トークン数を示し、ボトルネックを特定するのが簡単になります(たとえば、LLM呼び出しがエンドツーエンドの期間を支配している場合)。
この構造化されたアプローチがエンタープライズAI品質を変革する理由
アドホックな手動テストから体系的な評価に移行することで、エンタープライズグレードのAI展開に不可欠な測定可能な利点が得られます:
再現性と一貫性
すべての変更後に同一の評価スイートを実行し、高く一貫した品質基準を維持し、リアルタイムのAIリグレッションテストを可能にします。
データ駆動型の意思決定
構造化された評価は、エージェントのパフォーマンスの客観的で定量化可能な証拠を提供し、主観的な評価を明確なデータに置き換えて自信を持って意思決定を行います。
完全な監査トレイル
詳細なログは、コンプライアンス、セキュリティ、根本原因分析に不可欠な包括的な監査可能性を保証します。
スケーラブルな品質保証
自動化された評価フレームワークは、エージェントの展開がチーム、ワークフロー、ビジネスライン全体で拡大しても一貫した品質を保証します。
結果分析の準備
評価を実行すると、データセットが実行可能なパフォーマンスデータに変わります。真の価値は次のフェーズにあります: 結果を分析し、改善の機会を特定し、エージェント展開に関するデータ駆動型の意思決定を行うことです。
包括的なトレースとパフォーマンスメトリクスは、エージェントの行動を理解し、失敗モードを診断し、システムの信頼性を最適化するための基盤となります。
次のステップ: データをエンタープライズインサイトに変える
結果を生成した今、それを信頼できる意思決定に変える次のステップです - 何を出荷し、何をロールバックし、何を改善するか。
シリーズのパート3では、評価レポートを詳しく探り、成功率とパフォーマンスメトリクスを解釈し、エージェントの推論を分析し、失敗の根本原因を特定し、これらのインサイトを信頼できるエンタープライズ対応のAIエージェントの具体的な改善に変える方法を探ります。
評価データセットを放置しないでください。エージェントを選択し、データセットを選び、実際の評価を実行してください。各実行で反復し、何が機能するかを追跡し、エージェントがどこで失敗するかを特定し、すべての失敗を次のテストケースに変えてください。
理論からエンタープライズAIの卓越性に移行する準備はできていますか?今日、最初のエージェント評価を実行し、次のガイドをお楽しみに: 「AIエージェント評価結果を分析し、解釈し、行動に移す方法 - メトリクスをビジネス価値に変える」