
AIエージェント研究チームの構築方法:コンセプトから自動化まで
Robin
6 min read
AI AgentsResearch AgentCoTResearch AI
明確な垂直ドメインを定義し、適切な知識ベースとツールを選択することで、AI研究エージェントを設計し訓練します。AgentXを使用すれば、研究の自動化を拡大するためのマルチエージェントAI研究チームを構築できます。
明確な垂直ドメインを定義し、適切な知識ベースとツールを選択することで、AI研究エージェントを設計し訓練します。AgentXを使用すれば、研究の自動化を拡大するためのマルチエージェントAI研究チームを構築できます。
AI研究エージェントは、学術文献、データ合成、知識発見との関わり方を革命的に変えています。AgentXでは、単に答えを見つけるだけでなく、それを論理的に考察する自律型AIシステムを設計しています。当社のプラットフォームは、思考の連鎖プロンプト、深層思考モデル、マルチエージェント協力を活用して、世界クラスの研究インテリジェンスを提供します。
AI研究エージェントは、研究者が情報を収集、分析、合成する方法を変革しています。AgentXでは、最先端の人工知能を使用して学術研究を合理化するインテリジェントで自律的なシステムの構築を専門としています。
この包括的なガイドでは、カスタムAI研究エージェントを作成する方法を学びます。これは、面倒な研究ワークフローを自動化し、論文を読み、要約を生成し、数秒で洞察を発見するデジタルアシスタントです。
AI研究エージェントは、機械学習と自然言語処理(NLP)によって駆動される高度なソフトウェアアプリケーションです。ルールベースのシステムとは異なり、これらのエージェントは思考の連鎖(CoT)プロンプトと深層学習ベースの推論を使用して、人間のような思考をシミュレートします。
リトリーバルエージェントは関連する学術文献を収集します
分析エージェントは構造化された推論とパターン認識を適用します
要約エージェントは人間が読める洞察を作成します
デリゲーターエージェントはコンテキストと信頼度に基づいてタスクを動的にルーティングします
このマルチエージェントデリゲーションシステムは、スケーラブルで並列化された推論を可能にし、タスクが最も適した論理モジュールによって処理されることを保証します。これにより、パフォーマンス、精度、説明可能性が劇的に向上します。
AI駆動の研究ツールを構築する前に、それが解決する問題を定義します。特にマルチエージェント研究ワークフローを展開する場合、エージェントの使命を明確にすることが重要です。
どの特定の研究タスクを自動化しますか?
ターゲットユーザーは誰ですか—研究者、アナリスト、学生?
どのドメイン(例:ヘルスケア、エンジニアリング、教育)をサポートしますか?
期待される成果物は何ですか—要約、引用、洞察?
成功を評価するためにどのパフォーマンス指標を使用しますか?
SMARTゴールフレームワーク—具体的、測定可能、達成可能、関連性があり、時間制約のある—を使用して開発プロセスをガイドします。
エージェントの効果は、受け取るトレーニングデータの品質に依存します。構造化されたデータパイプラインを構築することが成功の鍵です。
信頼できる研究データベースからデータを取得する
正確性、権威性、関連性のためにフィルターを適用する
メタデータを文書化し、データの系譜を追跡する
可能な限りデータの取り込みを自動化する
データクリーニング:ノイズを除去し、不整合を修正し、形式を正規化する
構造化:テキスト、テーブル、メタデータを使用可能な形式に整理する
エンリッチメント:コンテキストラベル、タグ、参照を追加する
セグメンテーション:データをトレーニング、テスト、検証セットに分割する
強力なパイプラインは、研究用AIアシスタントがクリーンで信頼性があり多様なソースから学習できるようにします。
AgentXは、特にマルチエージェント推論とタスクデリゲーションのために設計された独自のオーケストレーションフレームワークを使用しています。特徴:
インテリジェントタスクオーケストレーション:AgentXのエンジンは研究クエリを動的にサブタスクに分解し、専門エージェント(例:リトリーバル、合成、検証)に割り当てます。
コンテキスト対応エージェントデリゲーション:タスクは、内部パフォーマンススコアとセマンティックマッチングを使用して最も能力のあるエージェントにルーティングされます—ハードコードされたルールだけではありません。
統合共有メモリ:すべてのエージェントは統一された知識空間で動作し、リアルタイムでの協力、クロスリファレンス、状態共有を可能にします。
このシステムにより、AgentX駆動のAIエージェントは協力的に考え、深く推論し、動的にデリゲートすることができ、複雑な研究ワークフロー全体で一貫した、説明可能で高品質な結果を保証します。
強力な研究自動化システムの中心には、文字通り先を見越して考えるデザインがあります。AgentXを使用すると、AIエージェントを構築することは、深い推論、協力的な問題解決、インテリジェントなデリゲーションが可能な専門家チームを作成することを意味します。
正しく行う方法は次のとおりです:
エージェントが操作する垂直ドメインを定義することから始めます。例えば、医療研究、財務分析、法律相談、科学出版などです。
このドメインでAIが解決する具体的な問題は何ですか?
どのような種類のソースを推論する必要がありますか(例:臨床試験、ホワイトペーパー、判例法)?
AIが遵守すべき規制、倫理、またはドメイン固有の基準はありますか?
よくスコープされた垂直ドメインは、より関連性が高く、パフォーマンスが鋭い目的に特化したエージェントを設計するのに役立ちます。
適切な知識基盤を選択することは、強力な能力を解放するために不可欠です。AgentXは、ドメイン固有の知識ベースのモジュラー統合をサポートしており、MCP(モデルコンテキストプロトコル)などの内部ツールを使用してエージェントの行動を動的にガイドします。
構造化データ:キュレーションされたデータセットやAPI(例:PubMed、SECファイリング)を使用する
非構造化テキスト:PDF、記事、研究論文
MCP:エージェントがモジュラー推論パターンを追跡し、コンテキストを追跡し、より深い分析が必要な場合にエスカレートすることを可能にするAgentXの独自ツール。(例:arXiv MCP)
✅ ヒント:MCPを統合することで、異なるエージェント間で一貫性と論理的厳密性を確保するための再利用可能な「推論戦略」を定義できます。
単一のモノリシックモデルを構築するのではなく、AgentXはエージェントの専門化を奨励します。各サブエージェントは、推論パイプラインの一部を処理するように微調整されています:
リトリーバルエージェント:関連する文書を見つけ、引用を抽出します
分析エージェント:合成、比較、または統計的推論を行います
批評エージェント:出力を検証し、矛盾や幻覚を指摘します
合成エージェント:明確で証拠に基づいた要約やレポートを生成します
各エージェントをドメイン固有のデータとラベル付き推論チェーンで訓練します。CoTパフォーマンスのためには、マルチステップの推論、比較、論理チェーンを必要とする例を含めます。
各エージェントに対して、その思考スタイルを形作る明確なルールとChain-of-Thoughtプロンプトを定義します。
構造化プロンプトを使用する:「まず仮説を見つけます。次に、支持する研究を見つけます。最後に、矛盾を評価します。」
エスカレーションパスを定義する:信頼度スコアが低い場合は、別のエージェントに委任するか、ユーザーに明確化を要求します
ベンチマークや対比結果などの反復タスクに論理テンプレートを適用します
これらの戦略により、AIアシスタントは予測可能に振る舞いながらも、複雑な入力に柔軟に対応できます。
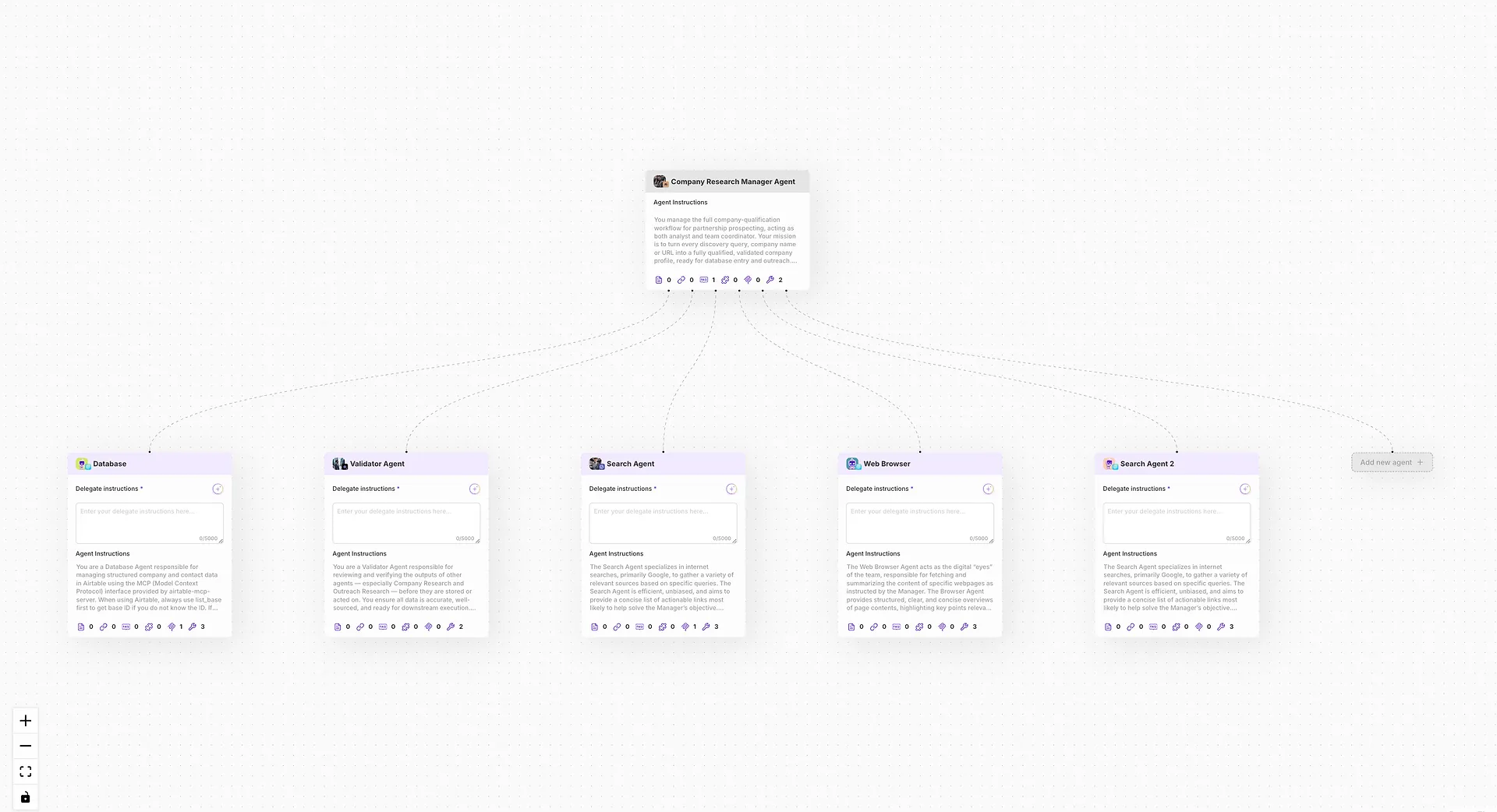
各エージェントが訓練され、プロンプト調整されたら、AgentXのオーケストレーションプラットフォームを使用して、協力的なエージェントチームを形成します。これは、共有メモリ、役割ベースの責任、タスクの引き継ぎを持つ研究「労働力」です。
各エージェントに明確な責任を割り当てます
デリゲーションロジックとコミュニケーション経路を定義します
AgentXの内部オーケストレーションを使用し、サードパーティのフレームワークではなく、動的なタスクルーティングとマルチエージェント実行を行います
インテリジェントエージェントの労働力を持つことで、システムは大規模またはリアルタイムの研究環境で特にスピード、回復力、説明可能性を獲得します。
🧠 AgentXは単にエージェントを構築するだけでなく、実際の研究チームのように推論し、委任し、協力するAI労働力を構築します。

AI駆動の研究アシスタントをテストすることは、実際の環境で機能することを確認するために重要です。
ユニットテスト:個々の機能とモジュールを検証します
統合テスト:システム間のシームレスな相互作用を確保します
機能テスト:研究環境でのユーザーインタラクションをシミュレートします
ストレステスト:重負荷下でのパフォーマンスを測定します
徹底的な検証により、ツールが堅牢で本番環境に準備が整っていることを確認します。
💭AgentXは、各ラウンドとステップに対して完全に透明な思考プロセス(CoT)を提供するため、ユーザーはエージェントが何を考えているのか、オーケストレーションがどのように進行しているのかを正確に知ることができます。これにより、デバッグとQAが非常に簡単になります。
テスト後、AI研究ツールをパフォーマンスとセキュリティを考慮してデプロイします。
クラウドホスティング:スケーラブルでオンデマンドのコンピュートリソース
セキュリティプロトコル:データの暗号化、役割ベースのアクセス
稼働時間の最適化:負荷分散、キャッシング、フェイルオーバーシステム
継続的インテグレーション/デプロイメント(CI/CD):自動テストと更新
平均応答時間
結果の精度
サーバーとリソースの利用率
エラーログとアラートの頻度
ユーザーフィードバックとエンゲージメント
AgentXのベストプラクティスを使用すれば、研究者やアナリストにとってシームレスな体験を保証します。
完全に機能するAI研究エージェントを作成することは、今日のツール、データセット、およびフレームワークを使用すれば完全に達成可能です。研究目標を定義することからクラウドにデプロイすることまで、このガイドの各ステップは、スケーラブルでインテリジェントな研究アシスタントを構築するのに役立つように設計されています。
💡 フォーカスされたタスクから始める:例えば、微調整されたトランスフォーマーモデルを使用して研究論文の分類を自動化します。その後、文献レビュー、トレンド予測、データビジュアライゼーションなど、より複雑なワークフローに拡張します。
AIで研究を強化する準備はできましたか?自身のAgentX駆動の研究エージェントを構築し、知識との関わり方を革命的に変えましょう。
Discover how AgentX can automate, streamline, and elevate your business operations with multi-agent workforces.
AgentX | One-stop AI Agent build platform.
Book a demo© 2026 AgentX Inc

