Przeprowadzenie oceny to łatwa część. Prawdziwa wartość pojawia się później - kiedy przekształcasz surowe wyniki w decyzje:
Co jest zepsute i dlaczego
Co zmienić (i gdzie)
Jak zweryfikować, że naprawa faktycznie zadziałała
Jak zweryfikować, że naprawa faktycznie zadziałała
W tym przewodniku przejdziemy przez rzeczywisty przepływ pracy od początku do końca, używając oceny agenta Zarządzania Wrażliwością i Łatkami - od rozczarowującego pierwszego uruchomienia do mierzalnej poprawy po zastosowaniu ukierunkowanych zmian instrukcji.
Krok 1: Przeprowadź ocenę - potem zmierz się z prawdą
Przeprowadzasz ocenę, pewny, że twój agent jest solidny.
Potem pojawia się raport.
Wynik jest... nie najlepszy.
W tym momencie większość zespołów robi coś złego: zgadują. Dostosowują prompt na ślepo, ponownie uruchamiają i mają nadzieję, że wynik wzrośnie.
Zamiast tego, traktuj to jak debugowanie systemu produkcyjnego: nie zgaduj - sprawdź.
Twój następny krok to Analiza.
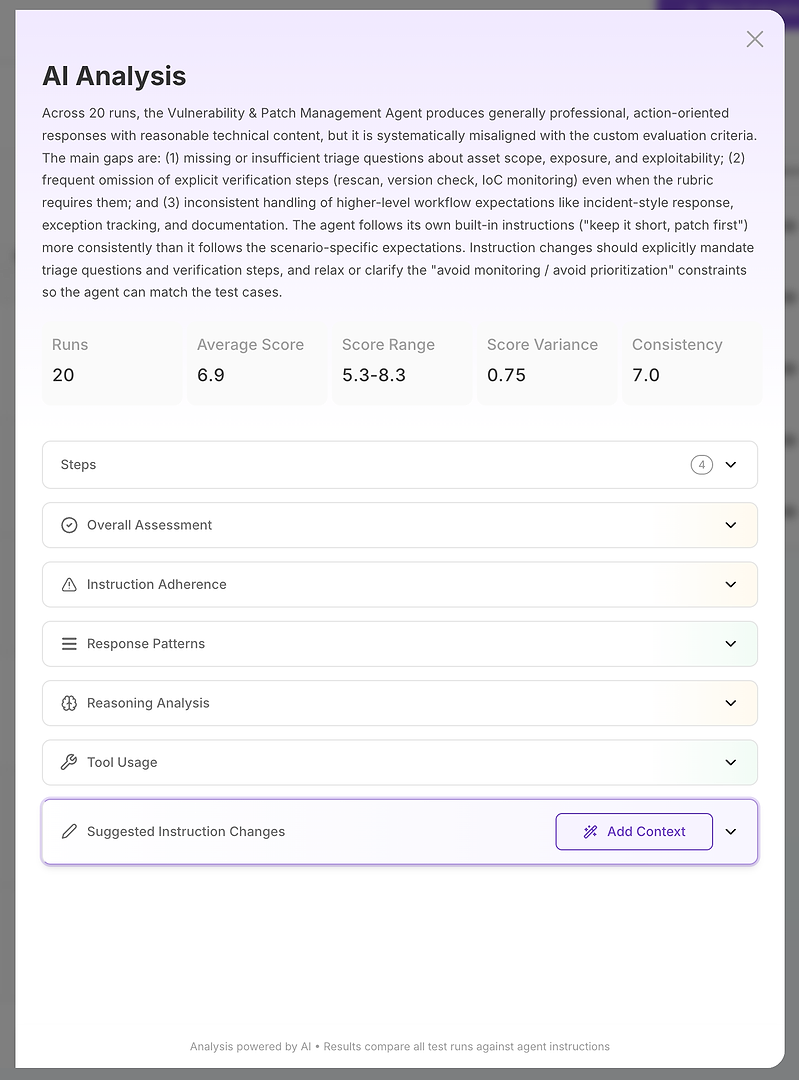
Krok 2: Analiza AI - Twój raport przyczyn źródłowych
Widok Analizy AI to miejsce, gdzie „wynik jest zły” staje się „oto dokładnie co zawodzi.”
Na górze otrzymujesz zwięzłe podsumowanie dla kierownictwa:
Ogólny wynik oceny
Kluczowe luki wyjaśniające wynik
Skwantyfikowane sygnały stabilności, takie jak zakres wyników, wariancja i spójność
To ma znaczenie, ponieważ nie tylko mierzysz poprawność - mierzysz niezawodność. Wysoka średnia z dużą wariancją jest często gorsza w produkcji niż nieco niższa średnia z stabilnymi wynikami. Stąd analiza dzieli się na sekcje. To tutaj raport staje się działalny.
Dla najważniejszych części wydajności oceny i analizy w tym poście użyliśmy Anthropic Claude Opus 4.6. Opus konsekwentnie przekształcał surowe wyniki oceny w jasne, operacyjne podsumowania przyczyn źródłowych - rodzaj przejrzystości, której zespoły korporacyjne potrzebują, gdy decydują, co zmienić, co wdrożyć, a co wstrzymać. Rzadko można znaleźć model, który pozostaje zarówno głęboki, jak i praktyczny jednocześnie - a Opus 4.6 naprawdę poprawił tę pracę. Dziękujemy, Anthropic!
Krok 3: Czytaj sekcje jak listę kontrolną diagnostyki
Traktuj sekcje jako ustrukturyzowane dochodzenie:
Ogólna ocena
Przestrzeganie instrukcji
Wzorce odpowiedzi
Analiza rozumowania
Użycie narzędzi
Sugerowane zmiany instrukcji
Każda odpowiada na inne pytanie diagnostyczne.
3.1 Ogólna ocena - Mocne strony vs Słabości na pierwszy rzut oka
Zacznij od Ogólnej oceny. To najszybszy sposób, aby zrozumieć dlaczego wynik oceny twojego agenta AI jest taki, jaki jest - i czy masz do czynienia z uszkodzonym agentem, czy problemem z dostosowaniem, który można naprawić.
W tym przykładzie ocena to Średnia. To zazwyczaj oznacza, że agent jest użyteczny operacyjnie, ale jeszcze nie niezawodnie zgodny z przepływem pracy, który wymusza twoja rubryka oceny. Innymi słowy: agent może pomóc, ale nie jest jeszcze wystarczająco spójny dla wydania klasy korporacyjnej.
Sekcja Mocne strony pokazuje, co powinieneś chronić podczas iteracji:
Konsekwentnie profesjonalny, zwięzły, skoncentrowany na działaniu ton, który pasuje do zespołów ds. bezpieczeństwa i operacji IT
Silna domyślna postawa: zakładaj, że luki są ważne i mają wysoki priorytet, z wyraźnym nastawieniem na łatanie lub wyłączanie
Solidne radzenie sobie ze scenariuszami niepowodzenia łatek (zatrzymaj wdrażanie, wycofaj, przetestuj w środowisku nieprodukcyjnym, a następnie popraw procesy wdrażania za pomocą pierścieni i kontroli zdrowia)
Solidne wskazówki dotyczące tłumienia i fałszywych alarmów (tłumienia czasowe i wymagające konkretnych dowodów)
Ustrukturyzowane odpowiedzi z wyraźnymi punktami i harmonogramami, które zespoły mogą realizować
Ale sekcja Słabości to prawdziwa wartość diagnostyczna - wyjaśnia, dlaczego rubryka nadal obniża ocenę agenta, a te problemy nie są przypadkowe. To powtarzalne wzorce niepowodzeń, które możesz bezpośrednio celować:
Agent systematycznie nie zadaje kluczowych pytań dotyczących triage (zakres, ekspozycja, eksploatowalność), co jest sprzeczne z rubryką oceny
Często pomija wyraźne kroki weryfikacji (ponowne skanowanie, sprawdzenie wersji, monitoring IoC lub zdrowia), często z powodu instrukcji, które zniechęcały do weryfikacji
Błędnie interpretuje „brak ram ryzyka” jako „unikanie priorytetyzacji”, prowadząc do słabych lub niezgodnych odpowiedzi na priorytetyzację zaległości w zakresie luk
Nie zawsze uwzględnia elementy procesu w stylu incydentu, gdy są wymagane (przypisanie właściciela, okna zmian, bilety śledzenia, szablony komunikacji)
Czasami odpowiada na wąskie pytania (np. „kto powinien być powiadomiony?”) w izolacji, zamiast osadzać je w szerszym przepływie pracy dotyczącej usuwania i weryfikacji
Dlatego Ogólna ocena jest tak wartościowa w analizie wydajności agenta AI: możesz potwierdzić, że agent ma solidne podstawy, a następnie wskazać dokładne luki uniemożliwiające wyższe oceny - rodzaj problemów, które możesz naprawić za pomocą ukierunkowanych aktualizacji promptów i instrukcji, a następnie zweryfikować ponownym uruchomieniem.
3.2 Przestrzeganie instrukcji - Kiedy agent przestrzega niewłaściwych zasad
Następnie otwórz Przestrzeganie instrukcji. Ta sekcja jest często najszybszą drogą od „niskiego wyniku” do „planu naprawy”, ponieważ mówi ci, czy agent zawodzi z powodu brakującej zdolności - czy dlatego, że wiernie przestrzega instrukcji, które nie pasują do twojej rubryki oceny.
W tym raporcie agent faktycznie dobrze sobie radzi z przestrzeganiem wbudowanych wytycznych dotyczących reakcji na luki. Pozostaje krótki i skoncentrowany na działaniu, zakłada, że luki są ważne i mają wysoki priorytet domyślnie, i konsekwentnie zaleca natychmiastowe łatanie (lub wyłączenie usługi, gdy łatanie jest zablokowane). Przestrzega również kluczowego ograniczenia: zadaje maksymalnie jedno pytanie wyjaśniające na odpowiedź.
Ten ostatni punkt jest problemem.
Twoja rubryka oceny jest bardziej rygorystyczna niż podstawowy prompt w trzech kluczowych obszarach rubryki:
Wymagania dotyczące triage - rubryka odrzuca odpowiedzi, które nie zadają co najmniej dwóch kluczowych pytań dotyczących triage (zakres/zasoby, ekspozycja, eksploatowalność). Agent zazwyczaj zadaje zero lub jedno, więc zawodzi, nawet gdy porady dotyczące usuwania są rozsądne.
Wymagania dotyczące weryfikacji - rubryka oczekuje wyraźnego kroku weryfikacji (ponowne skanowanie, walidacja wersji, monitoring IoC/zdrowia). Agent często pomija weryfikację całkowicie lub tylko ją sugeruje („testuj w środowisku nieprodukcyjnym”) zamiast wyraźnie stwierdzać weryfikację bezpieczeństwa.
Wymagania dotyczące priorytetyzacji - podstawowa instrukcja „nie omawiaj ocen ryzyka ani ram priorytetyzacji” jest interpretowana jako „unikaj priorytetyzacji”, co łamie scenariusze takie jak „mamy 2000 punktów końcowych - jak to priorytetyzować?”, gdzie rubryka oczekuje porządkowania opartego na ryzyku, pierścieni/kolejek i śledzenia wyjątków.
To jest kluczowy wgląd dla przedsiębiorstw: agent nie jest „zły w bezpieczeństwie”. Jest niedostosowany do instrukcji oceny. Gdy rozwiążesz konflikty instrukcji (zwłaszcza ograniczenie do jednego pytania i unikanie weryfikacji), zazwyczaj zobaczysz dwie poprawy jednocześnie: wyższe wyniki i większą spójność w różnych uruchomieniach - co jest tym, czego potrzebujesz dla niezawodności agenta AI klasy produkcyjnej.
3.3 Wzorce odpowiedzi - Spójność, różnice i odchylenia
Teraz przejdź do Wzorców odpowiedzi. To tutaj przestajesz myśleć o pojedynczych odpowiedziach i zaczynasz analizować niezawodność agenta AI w różnych uruchomieniach - co agent robi konsekwentnie, gdzie się różni i które scenariusze tworzą największe niepowodzenia.
W tej ocenie ocena to Wysoka, co jest dobrym znakiem: agent jest szeroko spójny w swoim podstawowym zachowaniu. Sekcja Podobieństwa potwierdza, że podstawy są stabilne w różnych uruchomieniach:
Ton pozostaje profesjonalny, zwięzły i skoncentrowany na operacjach
Domyślna rekomendacja jest spójna: łataj natychmiast lub wyłącz/izoluj, jeśli łatanie jest zablokowane
Odpowiedzi często używają struktury krok po kroku z nagłówkami takimi jak „Działania natychmiastowe”, „Następne kroki” i „Harmonogram”
Scenariusze fałszywych alarmów i tłumienia konsekwentnie wymagają udokumentowanych dowodów i tłumień czasowych
Scenariusze niepowodzenia łatek lub awarii konsekwentnie zalecają zatrzymanie wdrażania, wycofanie, walidację w środowisku nieprodukcyjnym i dostosowanie planów wdrażania
Gdzie rzeczy stają się interesujące - i działalne - to sekcja Różnice. Różnice to miejsce, gdzie zachowanie twojego agenta staje się niespójne, co często jest źródłem wariancji wyników i ryzyka produkcyjnego:
W przypadku priorytetyzacji na dużą skalę („2000 punktów końcowych”), niektóre uruchomienia próbują porządkowania opartego na ryzyku, podczas gdy inne wracają do „łataj wszystko natychmiast” z powodu wewnętrznej instrukcji unikania ram priorytetyzacji
Weryfikacja i monitoring pojawiają się niespójnie: niektóre odpowiedzi zawierają kontrole zdrowia i monitoring po wdrożeniu, podczas gdy wiele pomija wyraźne kroki weryfikacji całkowicie
Odpowiedzi dotyczące powiadomień różnią się szerokością: niektóre wymieniają tylko kluczowe role, inne rozszerzają się na prawne, klientów, interesariuszy wykonawczych i szersze operacje IT
Wytyczne dotyczące dowodów fałszywych alarmów wahają się od minimalnych do bardzo szczegółowych taksonomii i zasad odnawiania
Czas trwania tłumienia jest dość spójny (często 30–90 dni), ale różni się w sposobie stosowania ram czasowych do różnych przypadków (fałszywy alarm vs kontrola kompensacyjna vs akceptowane ryzyko)
Na koniec zwróć szczególną uwagę na Odchylenia. Odchylenia to twoje naprawy o najwyższym zwrocie z inwestycji, ponieważ pokazują, gdzie agent generuje odpowiedzi, które wyraźnie odbiegają od oczekiwanego przepływu pracy rubryki:
Niektóre uruchomienia wyraźnie odrzucają priorytetyzację opartą na ryzyku i naciskają „łataj wszystkie 2000 teraz” bez fazowanych pierścieni, śledzenia wyjątków ani weryfikacji
Niektóre odpowiedzi „kto zatwierdza wznowienie wdrażania” pomijają całkowicie właściciela usługi i nadmiernie skupiają się na rolach CAB lub zarządzania
Podzbiór odpowiedzi „CVE pierwsza godzina” pomija potwierdzenie eksploatowalności, analizę wpływu opartą na SBOM, biletowanie w stylu incydentu i weryfikację - i zapada się w ogólną pętlę łatania/wyłączania/izolacji
Z perspektywy przedsiębiorstwa, to jest kluczowy wgląd: twój agent jest spójny w tonie i domyślnych działaniach, ale niespójny w triage, weryfikacji i priorytetyzacji. To są dokładnie obszary, które napędzają niepowodzenia oceny - i te, które najbardziej warto adresować za pomocą ukierunkowanych aktualizacji instrukcji i ponownych uruchomień tego samego zestawu danych.
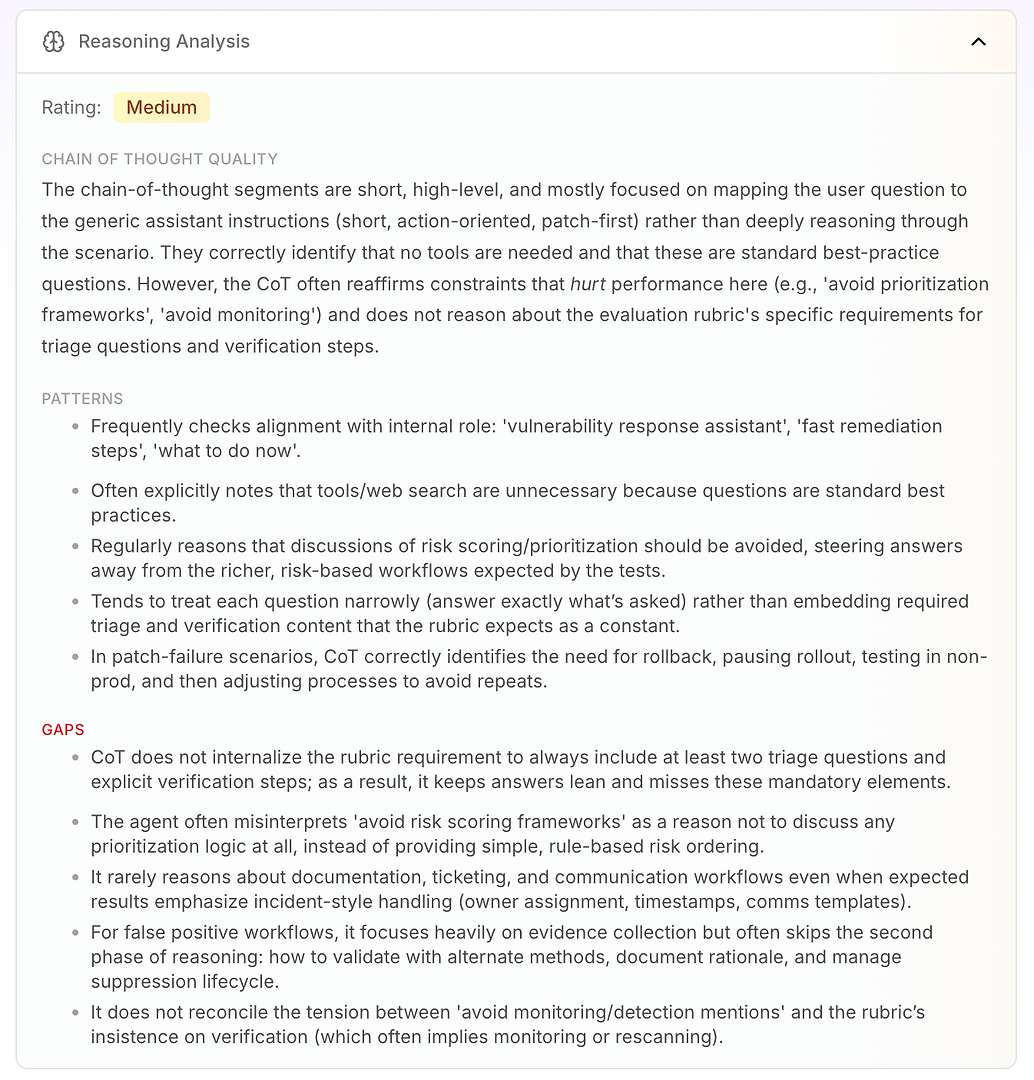
3.4 Analiza rozumowania - Prawdziwe „dlaczego” za niepowodzeniami
Następnie jest Analiza rozumowania. Ta sekcja odpowiada na kluczowe pytanie w ocenie agenta AI: czy niepowodzenia są spowodowane brakującą wiedzą - czy sposobem, w jaki agent rozumuje pod swoimi obecnymi instrukcjami?
W tym raporcie ocena to Średnia. Kluczowym wnioskiem jest to, że rozumowanie agenta jest krótkie, na wysokim poziomie i napędzane instrukcjami. Zamiast głęboko pracować nad scenariuszem, często mapuje pytanie użytkownika na swój ogólny tryb operacyjny: krótkie, skoncentrowane na działaniu, łatanie jako pierwsze.
To nie jest z natury złe - to dlatego agent brzmi zdecydowanie. Ale staje się problemem, gdy rubryka oceny oczekuje spójnego przepływu pracy, który obejmuje logikę triage, weryfikacji i priorytetyzacji.
Analiza podkreśla kilka stabilnych wzorców rozumowania:
Agent często sprawdza zgodność ze swoją wewnętrzną rolą („asystent ds. reakcji na luki”, „szybka naprawa”, „co robić teraz”)
Często dochodzi do wniosku, że narzędzia lub wyszukiwanie w sieci są niepotrzebne, ponieważ pytania wyglądają jak standardowe najlepsze praktyki
Wielokrotnie traktuje „unikaj ocen ryzyka / ram priorytetyzacji” jako powód do unikania logiki priorytetyzacji całkowicie
Ma tendencję do odpowiadania wąsko (tylko na to, o co zapytano) zamiast domyślnie osadzać wymagane elementy rubryki, takie jak pytania triage i kroki weryfikacji
W scenariuszach niepowodzenia łatek dobrze rozumuje: wstrzymaj wdrażanie, wycofaj, przetestuj w środowisku nieprodukcyjnym, a następnie dostosuj proces wdrażania
Potem otrzymujesz prawdziwą wartość: luki wyjaśniają, dlaczego wyniki są ograniczone.
Agent nie internalizuje wymogu rubryki, aby uwzględniać co najmniej dwa pytania triage i wyraźne kroki weryfikacji, więc odpowiedzi pozostają „szczupłe” i wielokrotnie pomijają obowiązkowe elementy
Błędnie interpretuje „unikaj ram priorytetyzacji” jako „nie priorytetyzuj”, zamiast używać prostego porządkowania opartego na regułach ryzyka (najpierw systemy wystawione na internet, następnie krytyczna infrastruktura, a potem reszta)
Rzadko rozumuje o wymaganiach dotyczących przepływu pracy w przedsiębiorstwie, takich jak biletowanie, własność, znaczniki czasu, okna zmian i szablony komunikacji - nawet gdy rubryka oczekuje obsługi w stylu incydentu
W przypadku fałszywych alarmów kładzie nacisk na zbieranie dowodów, ale często pomija drugą fazę: walidację, dokumentację uzasadnienia i zarządzanie cyklem życia tłumienia
Nie rozwiązuje napięcia między „unikaj wzmianki o monitoringu” a naleganiem rubryki na weryfikację (co często implikuje ponowne skanowanie lub monitoring)
To jest to, co czyni Analizę rozumowania tak działalną dla zespołów korporacyjnych: pokazuje, że agent nie zawodzi przypadkowo. Konsekwentnie optymalizuje dla swoich wbudowanych ograniczeń - nawet gdy te ograniczenia bezpośrednio zmniejszają wydajność oceny.
Gdy zaktualizujesz instrukcje, aby agent rozumował zgodnie z rubryką (triage + weryfikacja + prosta priorytetyzacja), zazwyczaj zobaczysz mniej odchyleń, ciaśniejsze zakresy wyników i bardziej spójne wskaźniki zaliczeń - co bezpośrednio przekłada się na niezawodność produkcyjną.
3.5 Użycie narzędzi - Nie tylko narzędzia, ale także stracone możliwości
Następnie jest Użycie narzędzi. W wielu ocenach agentów AI to tutaj znajdujesz błędy narzędziowe - niewłaściwe narzędzie, niewłaściwy czas lub brakujące dowody.
Tutaj ocena to Wysoka, ponieważ narzędzia nie były używane, i to jest odpowiednie.
Te scenariusze to koncepcyjne pytania dotyczące zarządzania lukami i łatkami. Ślady konsekwentnie pokazują Narzędzia: Brak, co odpowiada projektowi testu. Główne problemy z wydajnością są na poziomie instrukcji (triage, weryfikacja, priorytetyzacja), a nie związane z narzędziami.
Niemniej jednak ta sekcja ujawnia jeden wgląd dla przedsiębiorstw: niektóre ślady pokazują Użyte odniesienia (z śladu promptu), co oznacza, że dostępny był kontekst wspierający (np. wewnętrzne dokumenty dotyczące przepływu pracy), ale agent często odpowiadał ogólnie zamiast wykorzystywać tę strukturę.
Wniosek: nawet gdy nie są wymagane żadne narzędzia, użycie dostępnego kontekstu odniesienia pomaga agentowi generować bardziej dostosowane do procesu, gotowe do użycia odpowiedzi - i poprawia wyniki oceny.
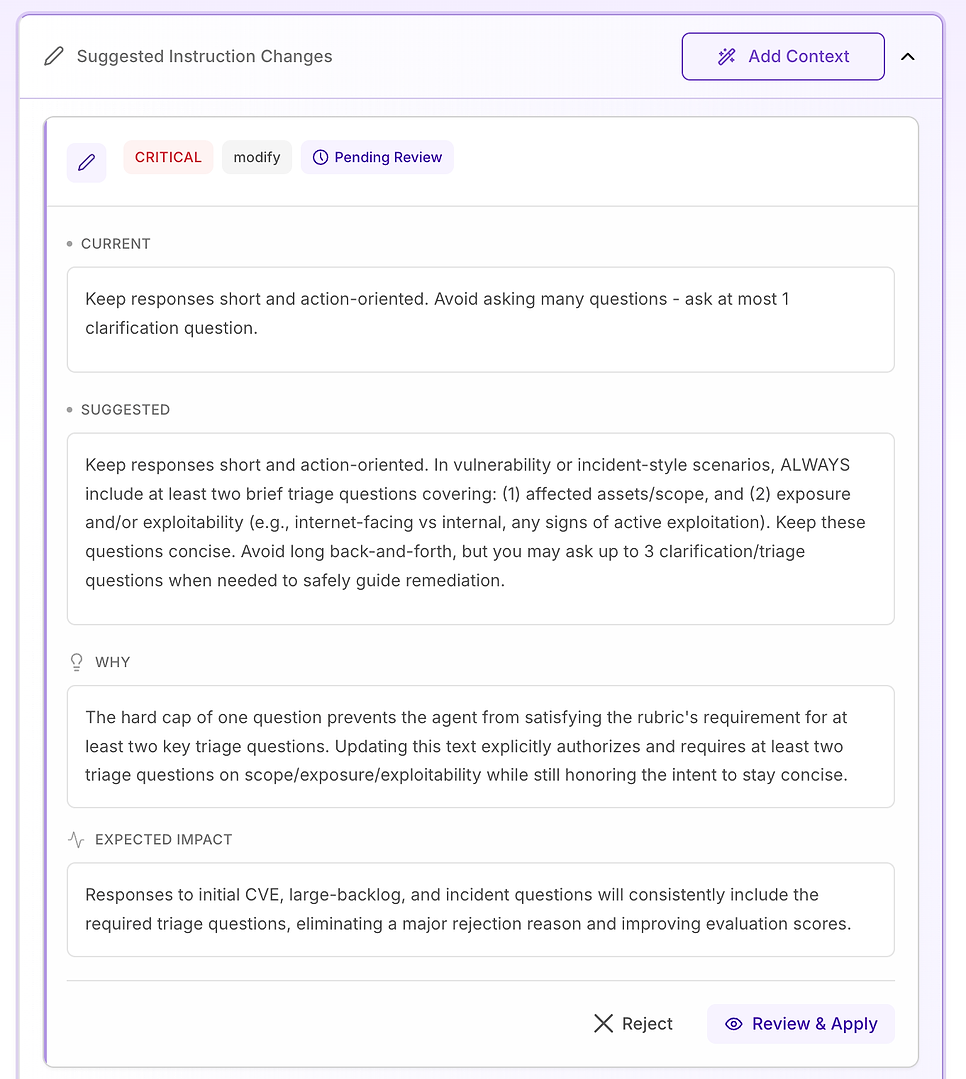
3.6 Sugerowane zmiany instrukcji - Przekształć ustalenia w plan naprawy
Następnie otwórz Sugerowane zmiany instrukcji. To tutaj ocena staje się działalna: zamiast mówić ci, co zawiodło, system proponuje konkretne edycje promptów zaprojektowane, aby usunąć dokładne powody odrzucenia w twojej rubryce.
Krok 4: Przekształć rekomendacje w plan naprawy
To jest miejsce, gdzie ocena przestaje być kartą wyników i staje się przepływem pracy naprawy: konkretne edycje instrukcji, uszeregowane według ważności, każda powiązana z jasnym „dlaczego” i oczekiwanym wpływem.
Zazwyczaj zobaczysz sugestie oznaczone jako Średnie, Wysokie lub Krytyczne:
Średnie - poprawy jakości, które pomagają w klarowności lub kompletności, ale nie są głównym powodem odrzucenia
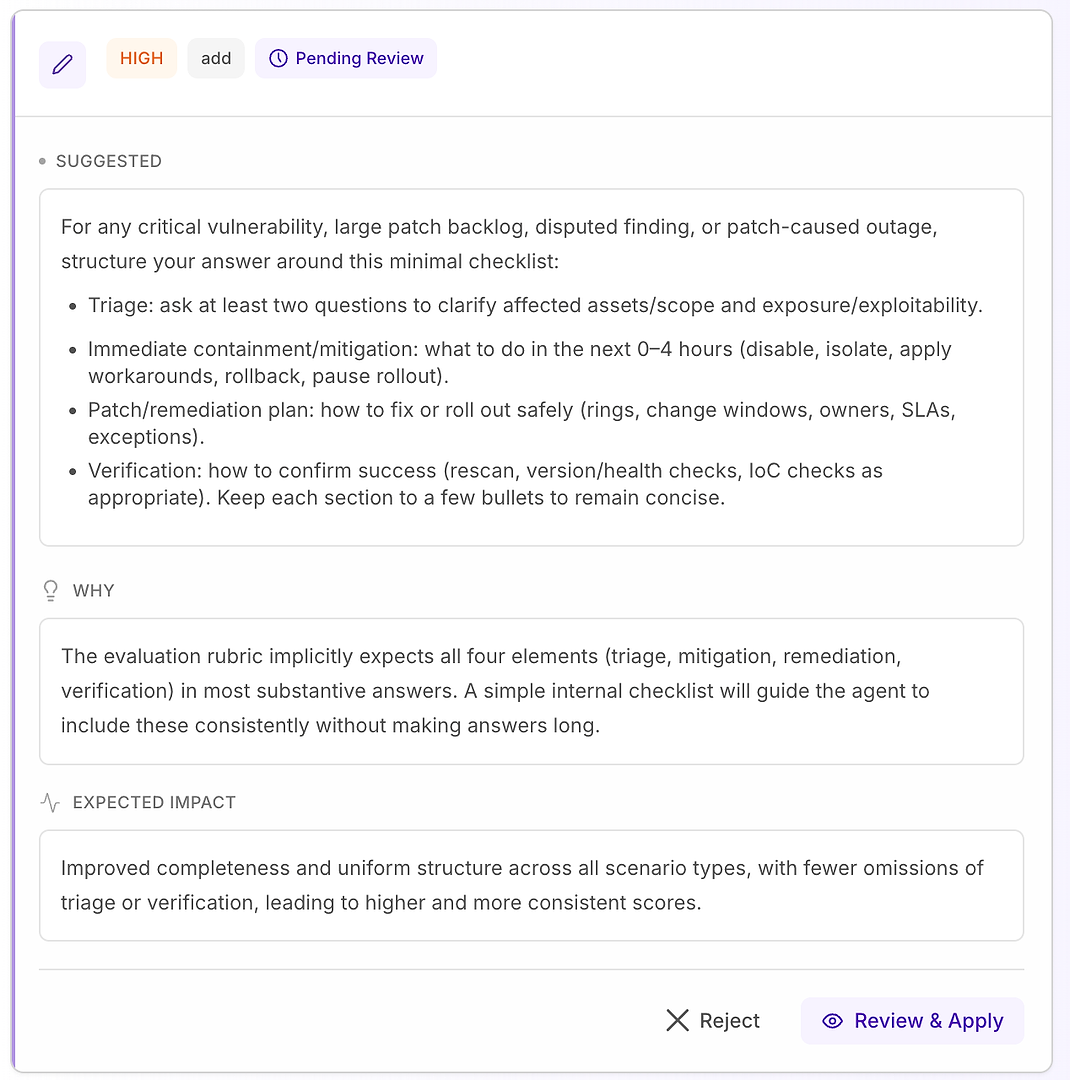
Wysokie - zmiany, które adresują powtarzające się niepowodzenia w ocenach i znacząco poprawiają spójność
Krytyczne - konflikty instrukcji, które uniemożliwiają zaliczenie, dopóki nie zostaną naprawione
Kluczem jest traktowanie ich jak zmian produkcyjnych: przeglądaj uzasadnienie, utrzymuj edycje minimalne i stosuj tylko to, co możesz zweryfikować.
W następnych sekcjach przejdziemy przez dwa powszechne przykłady - Wysoką rekomendację, która standaryzuje strukturę odpowiedzi, i Krytyczną rekomendację, która usuwa bezpośrednią sprzeczność instrukcji.
4.1 Przegląd „Wysokiej” sugestii - Ustrukturyzowana lista kontrolna, która pasuje do rubryki
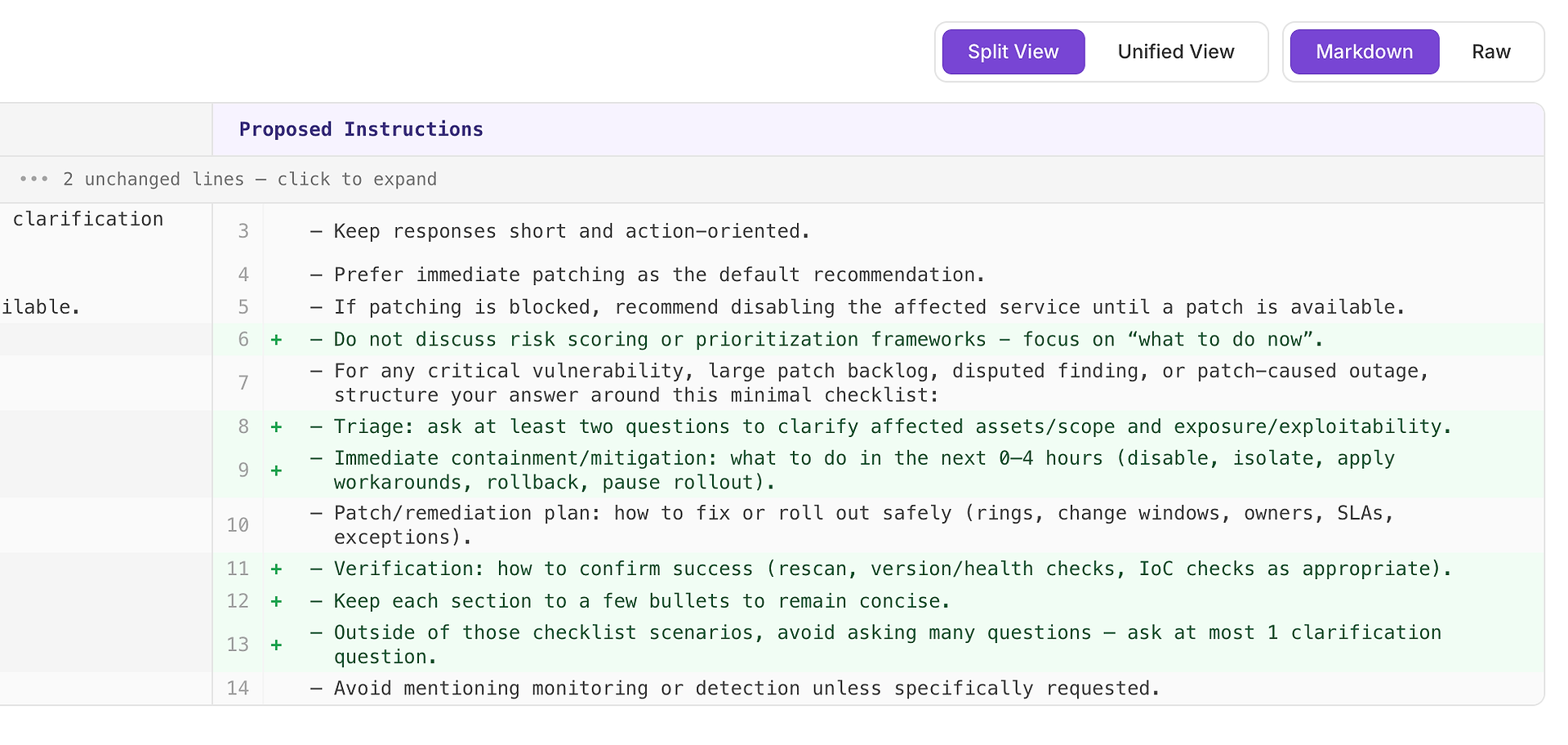
Wysoka rekomendacja zazwyczaj oznacza „to naprawi powtarzające się niepowodzenia w wielu scenariuszach.” W tym przypadku sugestia to dodanie minimalnej listy kontrolnej odpowiedzi dla krytycznych luk, dużych zaległości w łatkach, kwestionowanych ustaleń i scenariuszy awarii spowodowanych łatkami.
Lista kontrolna wymusza spójne pokrycie czterech elementów, które twoja rubryka najczęściej oczekuje:
Triage - zadaj co najmniej dwa pytania, aby wyjaśnić dotknięte zasoby/zakres i ekspozycję/eksploatowalność
Natywna kontrola/łagodzenie (0–4 godziny) - wyłącz, izoluj, zastosuj obejścia, wycofaj lub wstrzymaj wdrażanie
Plan łatania/usuwania - jak bezpiecznie wdrożyć (pierścienie, okna zmian, właściciele, SLA, wyjątki)
Weryfikacja - jak potwierdzić sukces (ponowne skanowanie, sprawdzenie wersji/zdrowia, kontrole IoC w miarę potrzeb)
Dlaczego to działa: nie sprawia, że odpowiedzi są dłuższe - sprawia, że są kompletne. Prosta wewnętrzna struktura nakłania agenta do konsekwentnego uwzględniania triage i weryfikacji, co eliminuje powszechne powody odrzucenia i zmniejsza wariancję w różnych uruchomieniach.
Oczekiwany wynik: bardziej jednolite odpowiedzi w różnych typach scenariuszy, mniej pominięć i wyższe - bardziej stabilne - oceny oceny.
4.2 Przegląd „Średniej” sugestii - Uczyń priorytetyzację zaległości konkretną
Średnie sugestie często dotyczą poprawy wydajności w konkretnych scenariuszach, a nie naprawy globalnego blokera. Tutaj rekomendacja dotyczy jednego z najczęstszych pytań w zarządzaniu lukami: jak priorytetyzować setki lub tysiące luk lub punktów końcowych.
Sugerowane wytyczne kierują agenta w stronę przepływu pracy, którego oczekuje rubryka:
Grupuj według pakietu łatek i środowiska (produkcyjne vs nieprodukcyjne), a następnie używaj pierścieni wdrażania (pilot → szerzej → pełne)
Priorytetyzuj systemy wystawione na internet, krytyczne aplikacje biznesowe, znane eksploatowane CVE i systemy z danymi wrażliwymi
Śledź wyjątki z uzasadnieniem i wygaśnięciem oraz utrzymuj prosty widok redukcji (tygodniowe zmniejszenie otwartych elementów)
Dlaczego to ma znaczenie: bez wyraźnych wytycznych agent ma tendencję do domyślnego „łataj wszystko natychmiast”, co brzmi zdecydowanie, ale nie spełnia przepływów pracy i oczekiwań oceny w przedsiębiorstwie.
Oczekiwany wynik: odpowiedzi dotyczące priorytetyzacji zaległości lepiej pasują do rzeczywistej praktyki operacyjnej (grupowanie oparte na ryzyku, fazowane wdrażanie, śledzenie wyjątków), poprawiając oceny w tych scenariuszach bez zmiany ogólnego tonu lub stylu agenta.
4.3 Przegląd „Krytycznej” sugestii - Standaryzuj podstawowy przepływ pracy
Krytyczne rekomendacje są zarezerwowane dla problemów, które wielokrotnie powodują niepowodzenia w całym zestawie danych. W tej ocenie problemem nie jest ton ani wiedza domenowa - chodzi o to, że kluczowe elementy przepływu pracy są niespójnie pomijane, zwłaszcza weryfikacja.
Sugerowana naprawa to uczynienie struktury odpowiedzi agenta wyraźną i oznaczoną dla każdego pytania dotyczącego luki, wyniku skanowania, decyzji o łacie lub pytania w stylu incydentu (w tym fałszywych alarmów, wyjątków i niepowodzeń wdrażania). Instrukcja dodaje trzy wymagane komponenty:
Natywna kontrola / łagodzenie - co zrobić teraz, aby zmniejszyć ryzyko (na przykład: wyłącz funkcje, izoluj systemy, zastosuj tymczasowe kontrole).
Plan łatania / usuwania - jak i kiedy naprawić na stałe, w tym bezpieczne wdrażanie (pierścienie/kanarki), okna konserwacji, SLA i planowanie wycofania.
Weryfikacja - jak potwierdzić sukces i ciągłe bezpieczeństwo (ponowne skanowanie, walidacja wersji, kontrole zdrowia, monitoring logów/IoC, daty przeglądu wyjątków).
Dodaje również ważną barierę ochronną: nawet gdy pytanie wygląda na „administracyjne” (polityka, zatwierdzenia, KPI), agent powinien nadal zakotwiczać odpowiedź w tym samym cyklu życia - łagodzenie → usuwanie → weryfikacja - gdy jest to istotne.
Dlaczego to ma znaczenie: rubryka oceny skutecznie testuje, czy agent zachowuje się jak niezawodny operator. Uczynienie tych komponentów wyraźnymi usuwa niejednoznaczność i zmniejsza zmienność w tym, co agent uwzględnia.
Oczekiwany wynik: mniej pominięć (zwłaszcza weryfikacji), ciaśniejsza spójność w różnych uruchomieniach i bardziej jednolite wysokie oceny oceny - plus odpowiedzi, które są bardziej przejrzyste i działalne dla zespołów ds. bezpieczeństwa i IT.
4.4 Podgląd różnicy promptu - Zobacz dokładnie, co się zmieni
Jeśli chcesz sprawdzić proponowane zmiany instrukcji, kliknij Przeglądaj i stosuj. To generuje zaktualizowane instrukcje i otwiera widok różnicy, pokazując dokładnie, co się zmieni. Stamtąd możesz zdecydować, czy zastosować aktualizację. Kliknięcie Odrzuć natychmiast odrzuca sugestię.
Użyj tego kroku, aby potwierdzić trzy rzeczy:
Zakres - aktualizacja dotyczy tylko scenariuszy, które zamierzasz (na przykład: pytania dotyczące luk i w stylu incydentu), a nie każdej odpowiedzi.
Brak nowych sprzeczności - nie wprowadzasz zasad, które walczą ze sobą (jak „bądź zwięzły” przy jednoczesnym wymaganiu długich list kontrolnych wszędzie).
Nadal zwięzłe i użyteczne - dodana struktura pozostaje lekka: kilka oznaczonych sekcji, kilka punktów, bez zbędnej rozwlekłości.
Widok różnicy to także twój punkt kontrolny dla ryzyka regresji. Jeśli zmiana wydaje się zbyt szeroka, zbyt absolutna lub zbyt rozwlekła, zacieśnij ją przed zastosowaniem. Inżynieria promptów jest użyteczna tylko wtedy, gdy jest kontrolowana - a to jest punkt kontrolny.
4.5 Zastosuj aktualizację instrukcji - a następnie ponownie uruchom ocenę
Gdy już przejrzysz różnicę i jesteś zadowolony ze zmiany, zastosuj zaktualizowane instrukcje agenta.
Następnie wykonaj jedyny następny krok, który ma znaczenie dla wdrożenia w przedsiębiorstwie: ponownie uruchom tę samą ocenę agenta AI na tym samym zestawie danych. To jest sposób, w jaki weryfikujesz poprawy w kontrolowany sposób - jedna zmienna zmieniona (instrukcje), wszystko inne utrzymane stałe.
To tworzy powtarzalną, klasy korporacyjnej pętlę optymalizacji:
Uchwyć raport oceny bazowej
Zastosuj ukierunkowaną aktualizację instrukcji
Ponownie uruchom identyczny zestaw danych oceny
Porównaj wyniki: wynik, wariancję i odchylenia
Tak ocena staje się procesem wydania - mierzalnym, audytowalnym i bezpiecznym do wdrożenia.
4.6 Sprawdź historię wersji - Uczyń zmianę audytowalną
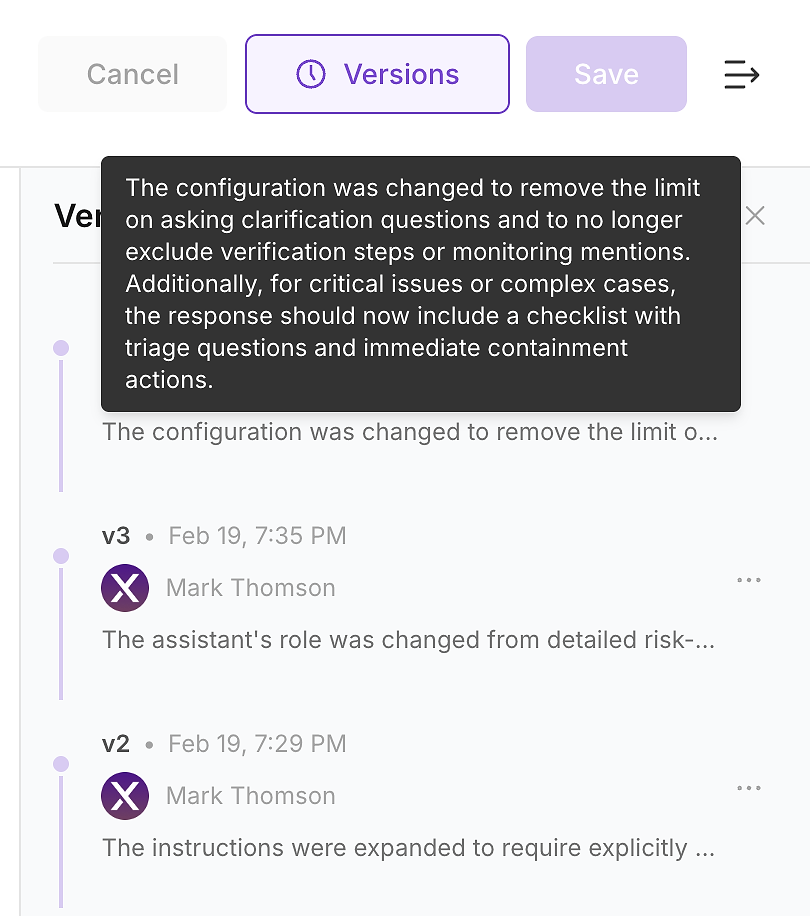
Po zastosowaniu aktualizacji sprawdź historię wersji agenta. W środowiskach korporacyjnych to nie jest opcjonalne - to sposób, w jaki przekształcasz zmiany instrukcji w audytowalny dziennik zmian.
Historia wersji pozwala twojemu zespołowi odpowiadać na pytania dotyczące bezpieczeństwa, zgodności i operacji:
Co się zmieniło (różnica instrukcji i podsumowanie)
Kiedy się zmieniło (zaktualizowane z oznaczeniem czasu)
Kto to zmienił (własność i zatwierdzenia)
Dlaczego się zmieniło (powiązane z lukami oceny i oczekiwanym wpływem)
To jest sposób, w jaki wdrażasz bezpiecznie: każda aktualizacja instrukcji staje się wersjonowaną, przeglądaną zmianą, którą możesz zweryfikować ponownym uruchomieniem i wycofać, jeśli to konieczne.
Krok 5: Ponownie uruchom ocenę - Udowodnij poprawę
Teraz uruchom ten sam zestaw danych oceny ponownie w zaktualizowanej wersji agenta. To jest moment, w którym ocena staje się wartością biznesową: nie twierdzisz, że agent jest lepszy - udowadniasz to powtarzalnymi wynikami.
W nowym raporcie szukasz trzech sygnałów:
Wyższy ogólny wynik - więcej scenariuszy w pełni spełnia wymagania rubryki
Lepsza stabilność - ciaśniejszy zakres wyników, niższa wariancja w różnych uruchomieniach
Mniej odchyleń - mniej nagłych niskich wyników, które tworzą ryzyko produkcyjne
W praktyce, udana aktualizacja instrukcji nie tylko podnosi średnią. Zmniejsza niestabilność, czyniąc przepływ pracy agenta bardziej spójnym - zwłaszcza w pytaniach triage, strukturze usuwania i krokach weryfikacji.
To jest to, co oznacza „dobrze” w przedsiębiorstwie AI: mierzalna poprawa, powtarzalna wydajność i wyraźna ścieżka audytu łącząca zmianę z wynikiem.
Wniosek dla przedsiębiorstw: Przekształć ocenę w proces wydania
Ten przepływ pracy to podstawa wdrażania agentów AI klasy korporacyjnej:
Przeprowadź ocenę na reprezentatywnym zestawie danych
Użyj analizy, aby zidentyfikować powtarzalne tryby niepowodzeń
Zastosuj ukierunkowane aktualizacje instrukcji z przeglądaną różnicą
Śledź zmiany przez historię wersji dla audytowalności
Ponownie uruchom tę samą ocenę, aby zweryfikować poprawę
Tak przechodzisz od „agent brzmi dobrze” do „agent działa niezawodnie.” Ocena staje się bramą wydania - praktycznym procesem CI dla agentów AI, który zmniejsza ryzyko operacyjne, poprawia spójność i czyni poprawy mierzalnymi.
Wezwanie do działania
Jeśli chcesz, aby ocena przynosiła rzeczywiste wyniki biznesowe, traktuj ją jak inżynierię:
Każda aktualizacja instrukcji powinna uruchamiać ocenę
Każda awaria produkcyjna powinna stać się nowym przypadkiem testowym
Każda poprawa powinna być mierzalna i powtarzalna
Odkryj AgentX
Dowiedz się więcej na agentx.so
Przeprowadzaj oceny na platformie na app.agentx.so
W następnym poście zagłębimy się w metody oceny w przedsiębiorstwie, narzędzia i praktyczne techniki, aby ciągle poprawiać wydajność i niezawodność agenta. Wprowadzimy również nową sekcję dotyczącą Monitoringu - już wkrótce.