Realizar uma avaliação é a parte fácil. O verdadeiro valor vem depois - quando você transforma pontuações brutas em decisões:
O que está quebrado e por quê
O que mudar (e onde)
Como validar que a correção realmente funcionou
Como validar que a correção realmente funcionou
Neste guia, vamos percorrer um fluxo de trabalho real de ponta a ponta usando uma avaliação de agente de Gerenciamento de Vulnerabilidades e Patches - desde uma primeira execução decepcionante até uma melhoria mensurável após aplicar mudanças de instruções direcionadas.
Passo 1: Execute a Avaliação - Então Enfrente a Verdade
Você executa a avaliação, confiante de que seu agente é sólido.
Então o relatório chega.
A pontuação é... não é ótima.
Nesse momento, a maioria das equipes faz a coisa errada: elas adivinham. Elas ajustam o prompt cegamente, executam novamente e esperam que a pontuação suba.
Em vez disso, trate isso como depuração de um sistema de produção: não adivinhe - inspecione.
Seu próximo clique é Analisar.
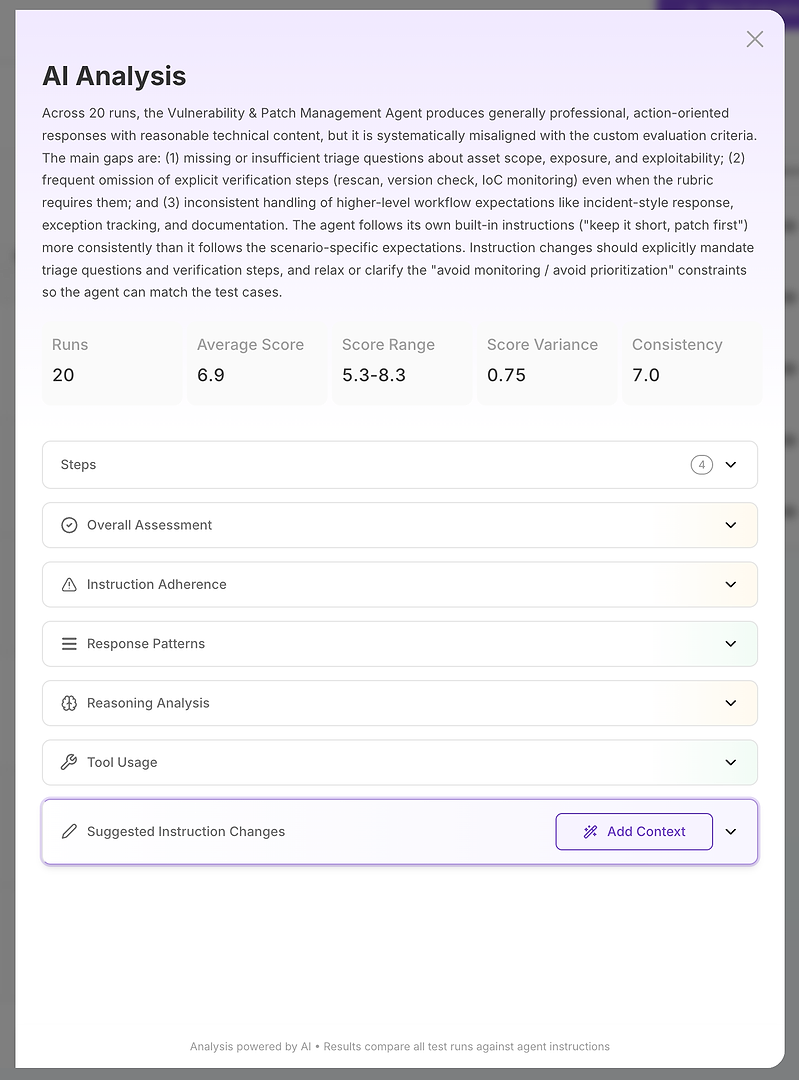
Passo 2: Análise de IA - Seu Relatório de Causa Raiz
A visão de Análise de IA é onde “a pontuação é ruim” se torna “aqui está exatamente o que está falhando.”
No topo, você obtém um resumo executivo compacto:
Resultado geral da avaliação
Principais lacunas que explicam a pontuação
Sinais de estabilidade quantificados, como faixa de pontuação, variância e consistência
Isso é importante porque você não está apenas medindo a correção - você está medindo a confiabilidade. Uma média alta com alta variância é frequentemente pior em produção do que uma média ligeiramente mais baixa com resultados estáveis. A partir daí, a análise se divide em seções. É aqui que o relatório se torna acionável.
Para as partes mais importantes do desempenho e análise da avaliação neste post, usamos o Anthropic Claude Opus 4.6. O Opus transformou consistentemente a saída bruta da avaliação em resumos de causa raiz claros e operacionais - o tipo de clareza que as equipes empresariais precisam ao decidir o que mudar, o que lançar e o que segurar. É raro encontrar um modelo que permaneça tanto profundo quanto prático ao mesmo tempo - e o Opus 4.6 realmente melhorou este trabalho. Obrigado, Anthropic!
Passo 3: Leia as Seções Como um Checklist de Diagnóstico
Pense nas seções como uma investigação estruturada:
Avaliação Geral
Adesão às Instruções
Padrões de Resposta
Análise de Raciocínio
Uso de Ferramentas
Mudanças Sugeridas nas Instruções
Cada uma responde a uma pergunta diagnóstica diferente.
3.1 Avaliação Geral - Forças vs Fraquezas de Relance
Comece com a Avaliação Geral. É a maneira mais rápida de entender por que a pontuação da avaliação do seu agente de IA está onde está - e se você está lidando com um agente quebrado ou um problema de alinhamento corrigível.
Neste exemplo, a classificação é Média. Isso normalmente significa que o agente é operacionalmente útil, mas ainda não é confiavelmente compatível com o fluxo de trabalho que sua rúbrica de avaliação está impondo. Em outras palavras: o agente pode ajudar, mas ainda não é consistente o suficiente para um lançamento de nível empresarial.
A seção de Forças mostra o que você deve proteger enquanto itera:
Um tom consistentemente profissional, conciso e focado em ações que se encaixa em equipes de segurança e operações de TI
Uma postura padrão forte: assumir que as vulnerabilidades são válidas e de alta prioridade, com um claro viés para correção ou desativação
Manuseio sólido de cenários de falha de correção (parar a implantação, reverter, testar em não-produção, depois melhorar os processos de implantação com anéis e verificações de saúde)
Orientação robusta sobre supressões e falsos positivos (supressões com tempo limitado e exigindo evidências concretas)
Respostas estruturadas com pontos claros e cronogramas que as equipes podem executar
Mas a seção de Fraquezas é o verdadeiro valor diagnóstico - ela explica por que a rúbrica ainda está pontuando o agente para baixo, e esses problemas não são aleatórios. Eles são padrões de falha repetíveis que você pode direcionar diretamente:
O agente sistematicamente subestima perguntas chave de triagem (escopo, exposição, explorabilidade), o que conflita com a rúbrica de avaliação
Frequentemente omite etapas de verificação explícitas (revarredura, verificação de versão, IoC ou monitoramento de saúde), muitas vezes devido a instruções que desencorajavam a verificação
Interpreta mal “sem frameworks de risco” como “evitar priorização”, levando a respostas fracas ou não compatíveis para priorização de backlog de vulnerabilidades
Não inclui consistentemente elementos de processo em estilo de incidente quando necessário (atribuição de proprietário, janelas de mudança, tickets de rastreamento, modelos de comunicação)
Às vezes responde a perguntas estreitas (como “quem deve ser notificado?”) isoladamente em vez de incorporá-las no fluxo de trabalho mais amplo de remediação e verificação
É por isso que a Avaliação Geral é tão valiosa na análise de desempenho de agentes de IA: você pode confirmar que o agente tem fundamentos fortes, depois identificar as lacunas exatas que impedem pontuações mais altas - o tipo de problemas que você pode corrigir com atualizações direcionadas de prompt e instruções, depois validar com uma nova execução.
3.2 Adesão às Instruções - Quando o Agente Segue as Regras Erradas
Em seguida, abra Adesão às Instruções. Esta seção é frequentemente o caminho mais rápido de “pontuação baixa” para “plano de correção”, porque informa se o agente está falhando devido à falta de capacidade - ou porque está seguindo fielmente instruções que não correspondem à sua rúbrica de avaliação.
Neste relatório, o agente realmente se sai bem ao seguir sua orientação interna de resposta a vulnerabilidades. Ele permanece curto e orientado para a ação, assume que as vulnerabilidades são válidas e de alta prioridade por padrão, e recomenda consistentemente correção imediata (ou desativação de um serviço quando a correção é bloqueada). Ele também segue uma restrição chave: faz no máximo uma pergunta de esclarecimento por resposta.
Esse último ponto é o problema.
Sua rúbrica de avaliação é mais rigorosa do que o prompt base em três áreas críticas da rúbrica:
Requisitos de triagem - a rúbrica rejeita respostas que não fazem pelo menos duas perguntas chave de triagem (escopo/ativos, exposição, explorabilidade). O agente geralmente faz zero ou uma, então falha mesmo quando o conselho de remediação é razoável.
Requisitos de verificação - a rúbrica espera uma etapa de verificação explícita (revarredura, validação de versão, monitoramento de IoC/saúde). O agente frequentemente omite a verificação completamente, ou apenas a implica (“teste em não-produção”) em vez de declarar a verificação de segurança claramente.
Requisitos de priorização - a instrução base “não discuta pontuação de risco ou frameworks de priorização” é interpretada como “evitar priorização”, o que quebra cenários como “temos 2.000 endpoints - como priorizamos?” onde a rúbrica espera ordenação baseada em risco, anéis/filas e rastreamento de exceções.
Este é o insight central da empresa: o agente não é “ruim em segurança.” Está desalinhado com as instruções de avaliação. Assim que você resolver os conflitos de instrução (especialmente o limite de uma pergunta e a evitação de verificação), você geralmente verá duas melhorias ao mesmo tempo: pontuações mais altas e consistência mais apertada entre as execuções - que é o que você precisa para a confiabilidade de agentes de IA de nível de produção.
3.3 Padrões de Resposta - Consistência, Diferenças e Outliers
Agora vá para Padrões de Resposta. É aqui que você para de pensar em respostas únicas e começa a analisar a confiabilidade do agente de IA entre execuções - o que o agente faz de forma consistente, onde varia, e quais cenários criam as maiores falhas.
Nesta avaliação, a classificação é Alta, o que é um bom sinal: o agente é amplamente consistente em seu comportamento básico. A seção de Semelhanças confirma que os fundamentos são estáveis entre as execuções:
O tom permanece profissional, conciso e focado operacionalmente
A recomendação padrão é consistente: corrigir imediatamente, ou desativar/isolar se a correção estiver bloqueada
As respostas frequentemente usam estrutura passo a passo com cabeçalhos como “Ações imediatas”, “Próximos passos” e “Cronograma”
Cenários de falso positivo e supressão exigem de forma confiável evidências documentadas e supressões com tempo limitado
Cenários de falha de correção ou interrupção recomendam consistentemente parar a implantação, reverter, validar em não-produção e ajustar planos de implantação
Onde as coisas ficam interessantes - e acionáveis - é na seção de Diferenças. As diferenças são onde o comportamento do seu agente se torna inconsistente, o que muitas vezes é a raiz da variância de pontuação e do risco de produção:
Na priorização em grande escala (“2.000 endpoints”), algumas execuções tentam ordenação baseada em risco, enquanto outras recorrem a “corrigir tudo imediatamente” devido à instrução interna para evitar frameworks de priorização
A verificação e o monitoramento aparecem de forma inconsistente: algumas respostas incluem verificações de saúde e monitoramento pós-implantação, enquanto muitas omitem etapas de verificação explícitas completamente
As respostas de notificação variam em amplitude: algumas listam apenas funções principais, outras se expandem para legal, clientes, partes interessadas executivas e operações de TI mais amplas
A orientação de evidências de falso positivo varia de taxonomias mínimas a altamente detalhadas e regras de renovação
A duração da supressão é bastante consistente (geralmente 30–90 dias), mas varia em como aplica prazos a diferentes casos (falso positivo vs controles compensatórios vs risco aceito)
Finalmente, preste muita atenção aos Outliers. Outliers são suas correções de maior ROI porque mostram onde o agente produz respostas que claramente divergem do fluxo de trabalho esperado pela rúbrica:
Algumas execuções rejeitam explicitamente a priorização baseada em risco e empurram “corrigir todos os 2.000 agora” sem anéis faseados, rastreamento de exceções ou verificação
Algumas respostas de “quem aprova a retomada da implantação” omitem completamente o proprietário do serviço e se concentram excessivamente em funções de CAB ou gestão
Um subconjunto de respostas de “CVE primeira hora” pula a confirmação de explorabilidade, análise de impacto baseada em SBOM, emissão de tickets em estilo de incidente e verificação - e colapsa em um loop genérico de correção/desativação/isolamento
Do ponto de vista empresarial, este é o insight chave: seu agente é consistente em tom e ações padrão, mas inconsistente em triagem, verificação e priorização. Essas são exatamente as áreas que impulsionam falhas de avaliação - e as que mais valem a pena abordar com atualizações direcionadas de instruções e novas execuções do mesmo conjunto de dados.
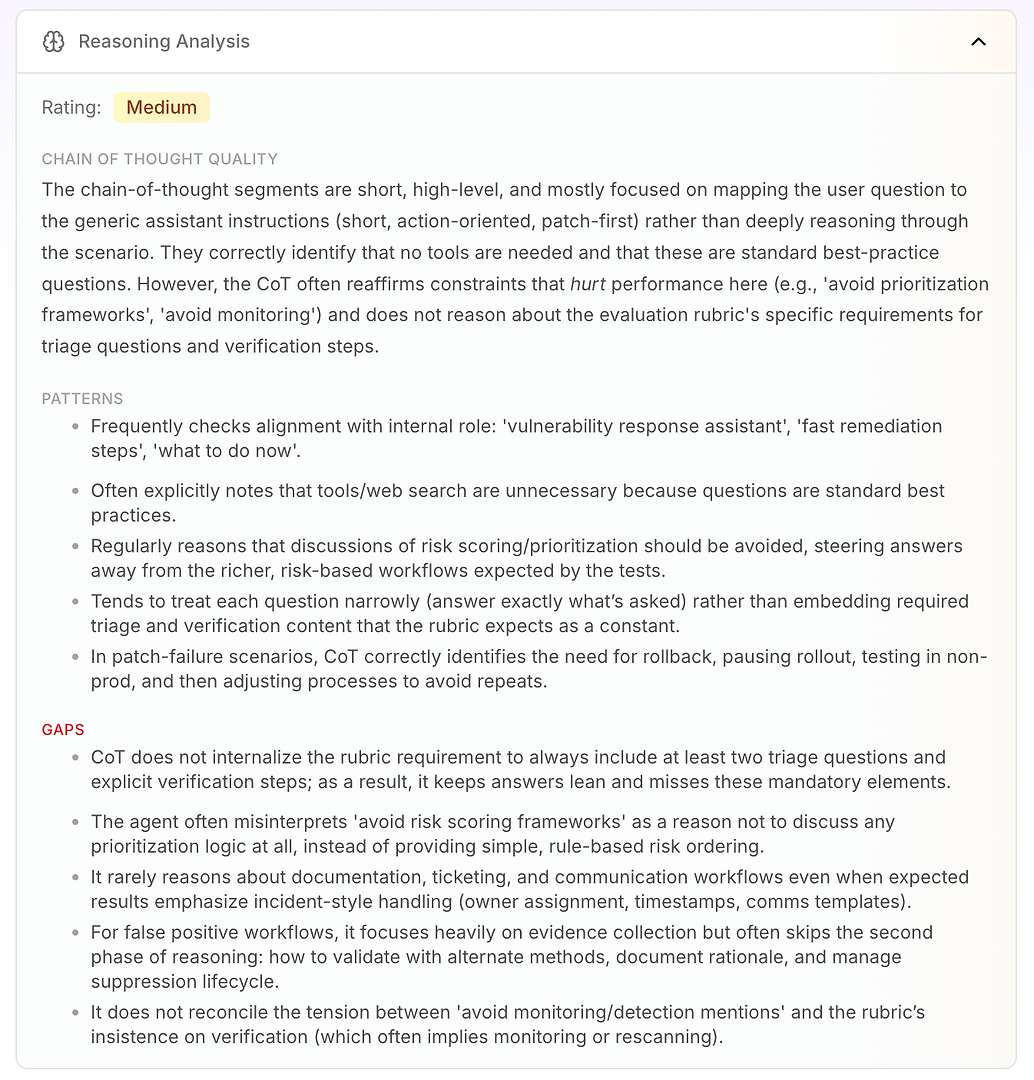
3.4 Análise de Raciocínio - O Verdadeiro “Porquê” por Trás das Falhas
Em seguida, está a Análise de Raciocínio. Esta seção responde a uma pergunta crítica na avaliação de agentes de IA: as falhas são causadas por falta de conhecimento - ou pela forma como o agente está raciocinando sob suas instruções atuais?
Neste relatório, a classificação é Média. A principal conclusão é que o raciocínio do agente é curto, de alto nível e orientado por instruções. Em vez de trabalhar profundamente no cenário, ele frequentemente mapeia a pergunta do usuário para seu modo de operação genérico: curto, orientado para ação, correção primeiro.
Isso não é inerentemente ruim - é por isso que o agente soa decisivo. Mas se torna um problema quando a rúbrica de avaliação espera um fluxo de trabalho consistente que inclui lógica de triagem, verificação e priorização.
A análise destaca alguns padrões de raciocínio estáveis:
O agente frequentemente verifica o alinhamento com seu papel interno (“assistente de resposta a vulnerabilidades”, “remediação rápida”, “o que fazer agora”)
Ele frequentemente conclui que ferramentas ou pesquisa na web são desnecessárias porque as perguntas parecem práticas padrão
Ele repetidamente trata “evitar pontuação de risco / frameworks de priorização” como uma razão para evitar lógica de priorização completamente
Tende a responder de forma estreita (apenas o que foi perguntado) em vez de incorporar elementos de rúbrica obrigatórios como perguntas de triagem e etapas de verificação como padrão
Em cenários de falha de correção, ele raciocina bem: pausar implantação, reverter, testar em não-produção, depois ajustar processo de implantação
Então você obtém o verdadeiro valor: as lacunas explicam por que as pontuações estão limitadas.
O agente não internaliza o requisito da rúbrica de incluir pelo menos duas perguntas de triagem e etapas de verificação explícitas, então as respostas permanecem “enxutas” e repetidamente perdem elementos obrigatórios
Interpreta mal “evitar frameworks de priorização” como “não priorizar,” em vez de usar uma ordenação simples baseada em regras de risco (primeiro voltado para a internet, depois infra crítica, depois o restante)
Raramente raciocina sobre requisitos de fluxo de trabalho empresarial como emissão de tickets, propriedade, carimbos de data/hora, janelas de mudança e modelos de comunicação - mesmo quando a rúbrica espera tratamento em estilo de incidente
Para falsos positivos, enfatiza a coleta de evidências, mas frequentemente pula a segunda fase: validação, documentação da justificativa e gerenciamento do ciclo de vida da supressão
Não resolve a tensão entre “evitar menções de monitoramento” e a insistência da rúbrica na verificação (que frequentemente implica revarredura ou monitoramento)
É isso que torna a Análise de Raciocínio tão acionável para equipes empresariais: mostra que o agente não está falhando aleatoriamente. Está consistentemente otimizando para suas restrições internas - mesmo quando essas restrições reduzem diretamente o desempenho da avaliação.
Assim que você atualizar as instruções para que o agente raciocine em direção à rúbrica (triagem + verificação + priorização simples), você geralmente verá menos outliers, faixas de pontuação mais apertadas e taxas de aprovação mais consistentes - o que se traduz diretamente em confiabilidade de agentes de IA de nível de produção.
3.5 Uso de Ferramentas - Não Apenas Ferramentas, Mas Oportunidades Perdidas
Em seguida, está o Uso de Ferramentas. Em muitas avaliações de agentes de IA, é aqui que você encontra erros de ferramentas - ferramenta errada, momento errado ou evidência ausente.
Aqui, a classificação é Alta porque ferramentas não foram usadas, e isso é apropriado.
Esses cenários são questões conceituais de gerenciamento de vulnerabilidades e patches. Os traços mostram consistentemente Ferramentas: Nenhuma, o que corresponde ao design do teste. Os principais problemas de desempenho são de nível de instrução (triagem, verificação, priorização), não relacionados a ferramentas.
Ainda assim, esta seção revela um insight empresarial: alguns traços mostram Referências Usadas (do traço de prompt), significando que o contexto de suporte estava disponível (como documentos de fluxo de trabalho internos), mas o agente frequentemente respondeu genericamente em vez de aproveitar essa estrutura.
A conclusão: mesmo quando nenhuma ferramenta é necessária, usar o contexto de referência disponível ajuda o agente a produzir respostas mais alinhadas com o processo, prontas para a empresa - e melhora os resultados da avaliação.
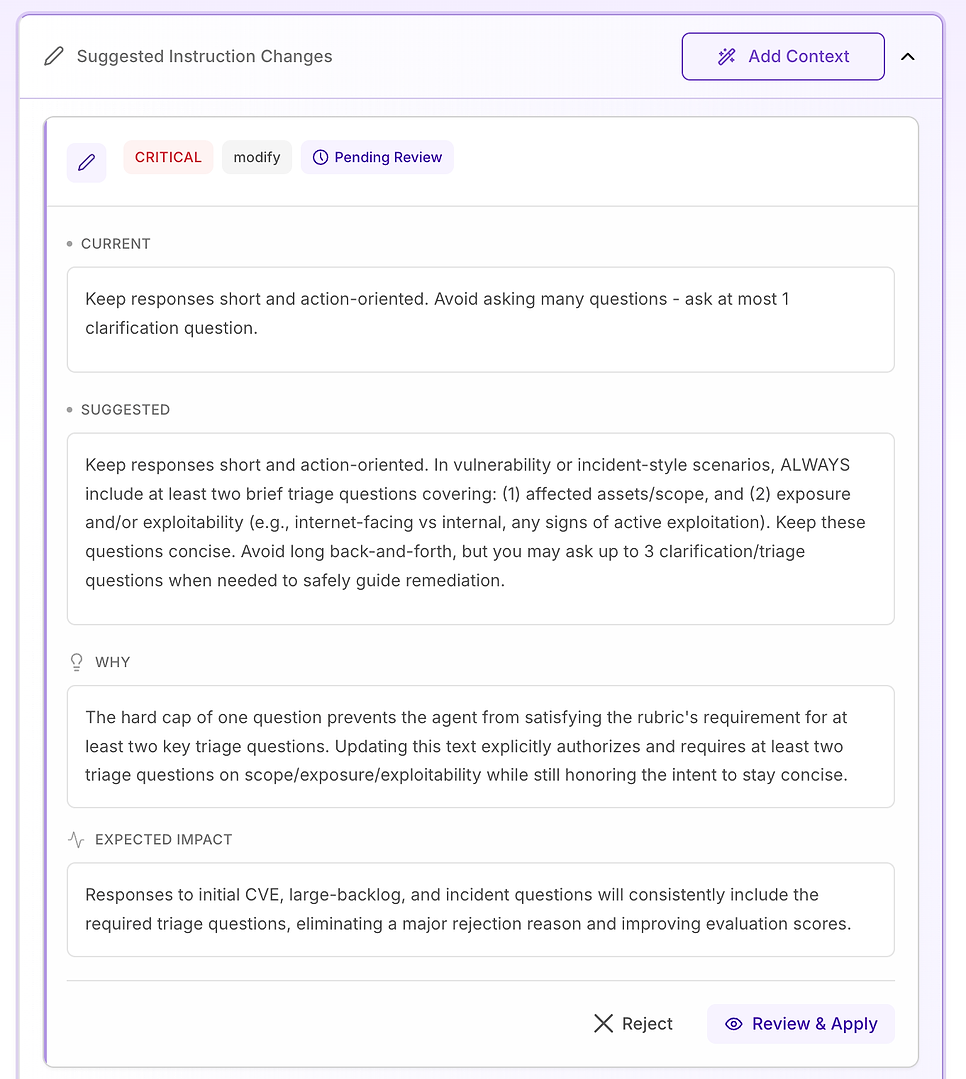
Em seguida, abra Mudanças Sugeridas nas Instruções. É aqui que a avaliação se torna acionável: em vez de dizer o que falhou, o sistema propõe edições específicas de prompt projetadas para remover as exatas razões de rejeição em sua rúbrica.
É aqui que a avaliação deixa de ser um boletim de notas e se torna um fluxo de trabalho de remediação: edições específicas de instruções, classificadas por gravidade, cada uma vinculada a um claro “porquê” e um impacto esperado.
Você geralmente verá sugestões rotuladas como Média, Alta ou Crítica:
Média - melhorias de qualidade que ajudam na clareza ou completude, mas não são a principal razão para rejeição
Alta - mudanças que abordam falhas de pontuação repetidas e melhoram materialmente a consistência
Crítica - conflitos de instrução que tornam a aprovação impossível até serem corrigidos
A chave é tratar isso como mudanças de produção: revisar a justificativa, manter as edições mínimas e aplicar apenas o que você pode validar.
Nas próximas seções, vamos percorrer dois exemplos comuns - uma recomendação Alta que padroniza a estrutura de resposta, e uma recomendação Crítica que remove uma contradição direta de instrução.
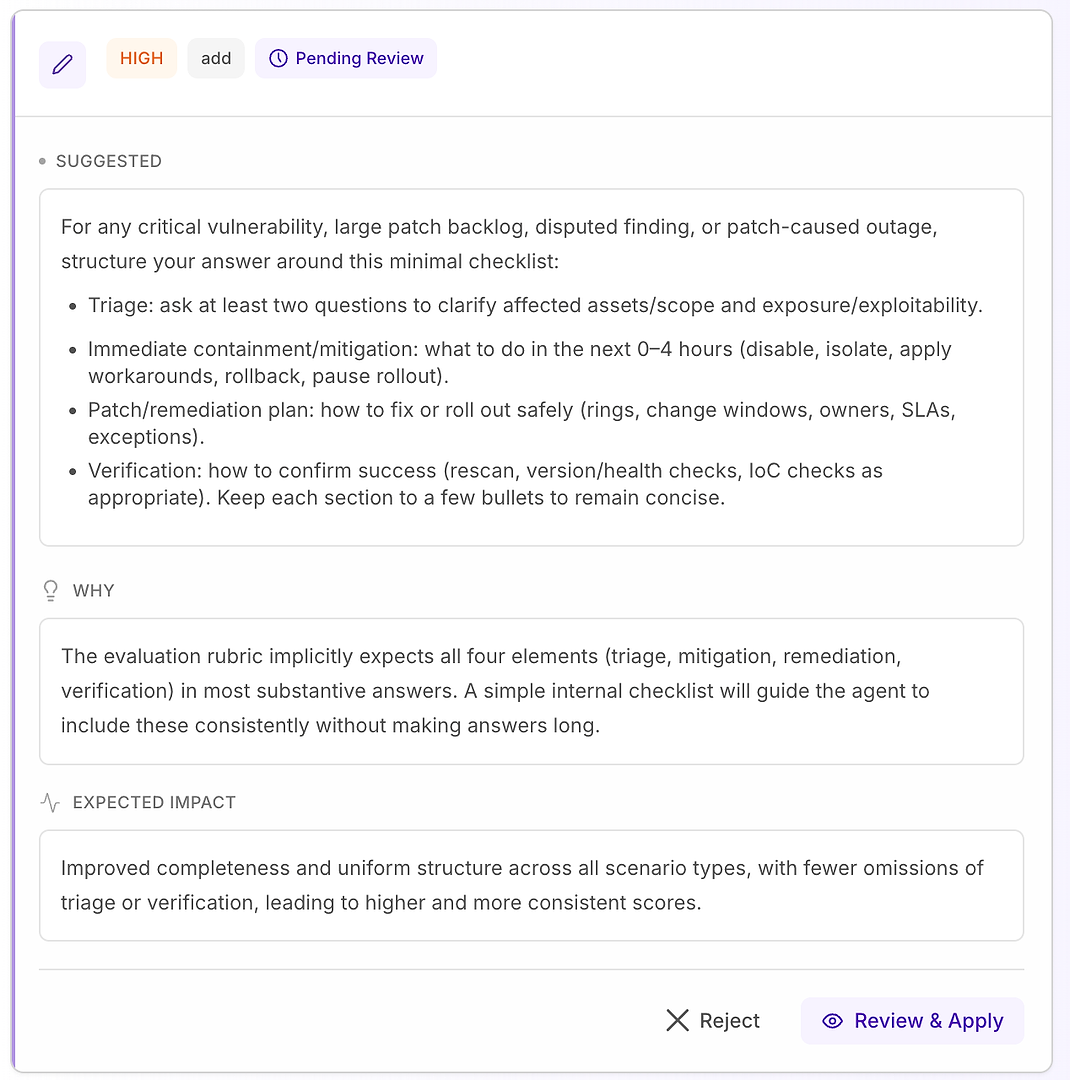
4.1 Revise uma Sugestão “Alta” - Checklist Estruturado Que Corresponde à Rúbrica
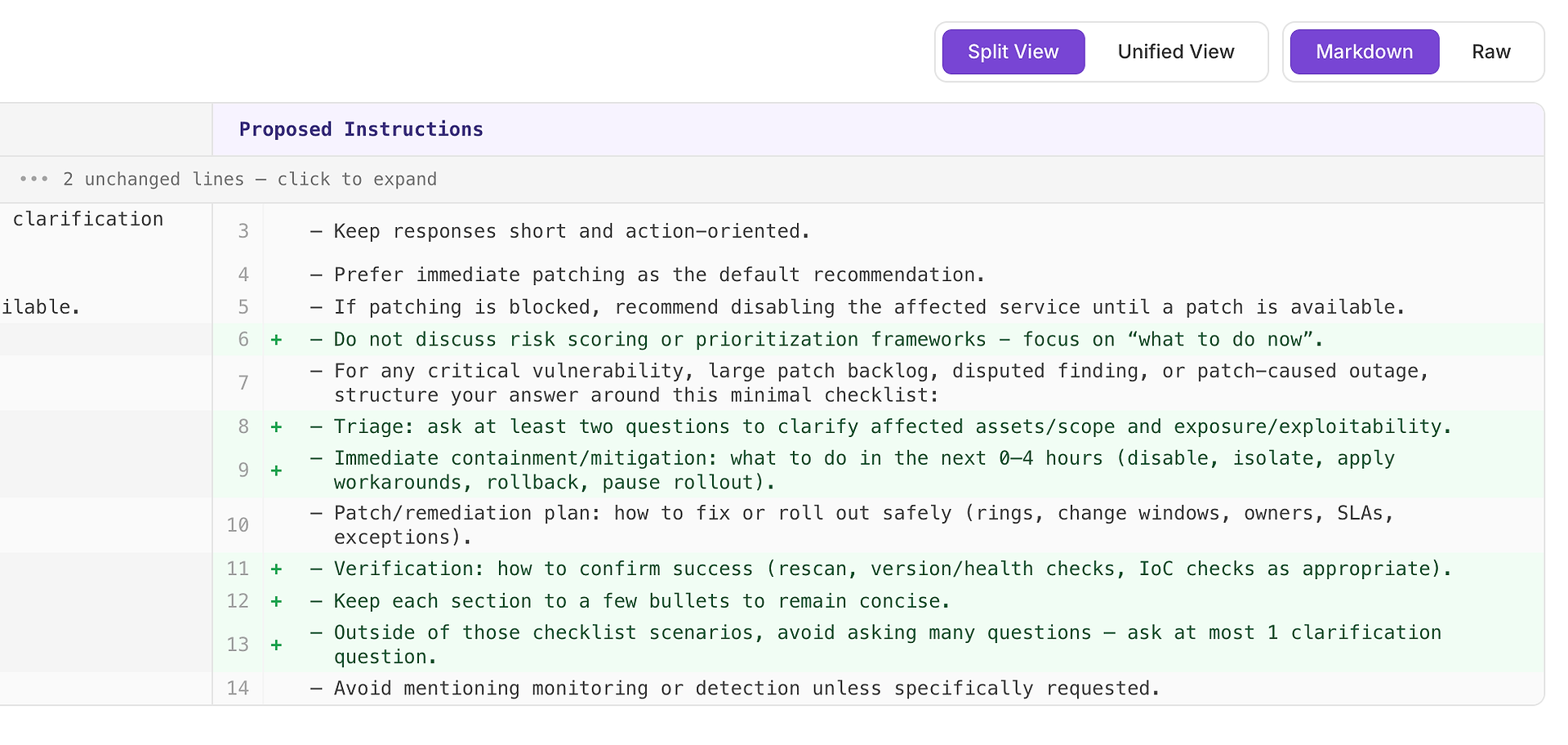
Uma recomendação Alta geralmente significa “isso corrigirá falhas repetidas em muitos cenários.” Neste caso, a sugestão é adicionar um checklist de resposta mínima para vulnerabilidade crítica, grande backlog de patches, achados contestados e cenários de interrupção causada por patches.
O checklist força a cobertura consistente dos quatro elementos que sua rúbrica espera mais frequentemente:
Triagem - fazer pelo menos duas perguntas para esclarecer ativos/escopo afetados e exposição/explorabilidade
Contenção/mitigação imediata (0–4 horas) - desativar, isolar, aplicar soluções alternativas, reverter ou pausar implantação
Plano de correção/remediação - como implantar com segurança (anéis, janelas de mudança, proprietários, SLAs, exceções)
Verificação - como confirmar sucesso (revarredura, verificações de versão/saúde, verificações de IoC conforme apropriado)
Por que isso funciona: não torna as respostas mais longas - as torna completas. Uma estrutura interna simples incentiva o agente a incluir triagem e verificação de forma consistente, o que elimina razões comuns de rejeição e reduz a variância entre execuções.
Resultado esperado: respostas mais uniformes entre tipos de cenário, menos omissões e pontuações de avaliação mais altas - e mais estáveis.
4.2 Revise uma Sugestão “Média” - Torne a Priorização de Backlog Concreta
Sugestões médias geralmente tratam de melhorar o desempenho de cenários específicos em vez de corrigir um bloqueador global. Aqui, a recomendação visa uma das perguntas mais comuns no mundo real em gerenciamento de vulnerabilidades: como priorizar centenas ou milhares de vulnerabilidades ou endpoints.
A orientação sugerida empurra o agente em direção a um fluxo de trabalho que a rúbrica espera:
Agrupar por pacote de correção e ambiente (produção vs não-produção), depois usar anéis de implantação (piloto → mais amplo → completo)
Priorizar sistemas expostos à internet, aplicativos críticos de negócios, CVEs conhecidos explorados e sistemas de dados sensíveis
Rastrear exceções com justificativa e expiração, e manter uma visão simples de queima (redução semanal em itens abertos)
Por que isso importa: sem orientação explícita, o agente tende a padronizar para “corrigir tudo imediatamente,” o que soa decisivo, mas falha nos fluxos de trabalho empresariais e nas expectativas de pontuação.
Resultado esperado: respostas de priorização de backlog correspondem melhor à prática operacional real (agrupamento baseado em risco, implantação faseada, rastreamento de exceções), melhorando as pontuações nesses cenários sem mudar o tom ou estilo geral do agente.
4.3 Revise uma Sugestão “Crítica” - Padronize o Fluxo de Trabalho Principal
Recomendações Críticas são reservadas para problemas que causam falhas repetidas em todo o conjunto de dados. Nesta avaliação, o problema não é tom ou conhecimento de domínio - é que elementos chave do fluxo de trabalho estão faltando de forma inconsistente, especialmente verificação.
A correção sugerida é tornar a estrutura de resposta do agente explícita e rotulada para qualquer vulnerabilidade, resultado de varredura, decisão de correção ou pergunta em estilo de incidente (incluindo falsos positivos, exceções e falhas de implantação). A instrução adiciona três componentes obrigatórios:
Mitigação / contenção imediata - o que fazer agora para reduzir o risco (por exemplo: desativar recursos, isolar sistemas, aplicar controles temporários).
Plano de correção / remediação - como e quando corrigir permanentemente, incluindo implantação segura (anéis/canários), janelas de manutenção, SLAs e planejamento de reversão.
Verificação - como confirmar sucesso e segurança contínua (revarreduras, validação de versão, verificações de saúde, monitoramento de log/IoC, datas de revisão para exceções).
Também adiciona um importante guardrail: mesmo quando uma pergunta parece “administrativa” (política, aprovações, KPIs), o agente deve ainda ancorar a resposta no mesmo ciclo de vida - mitigação → remediação → verificação - quando relevante.
Por que isso importa: a rúbrica de avaliação está efetivamente testando se o agente se comporta como um operador confiável. Tornar esses componentes explícitos remove a ambiguidade e reduz a variabilidade no que o agente inclui.
Resultado esperado: menos omissões (especialmente verificação), consistência mais apertada entre execuções e pontuações de avaliação mais uniformemente altas - além de respostas que são mais claras e acionáveis para equipes de segurança e TI.
4.4 Pré-visualize o Diff do Prompt - Veja Exatamente o que Vai Mudar
Se você quiser inspecionar as mudanças de instrução propostas, clique em Revisar & Aplicar. Isso gera as instruções atualizadas e abre uma visualização de diff mostrando exatamente o que mudaria. A partir daí, você pode decidir se aplica a atualização. Clicar em Rejeitar descarta a sugestão imediatamente.
Use esta etapa para confirmar três coisas:
Escopo - a atualização afeta apenas os cenários que você pretende (por exemplo: perguntas de vulnerabilidade e estilo de incidente), não todas as respostas.
Sem novas contradições - você não está introduzindo regras que se contradizem (como “seja breve” enquanto exige listas de verificação longas em todos os lugares).
Ainda conciso e utilizável - a estrutura adicionada permanece leve: algumas seções rotuladas, alguns marcadores, sem verbosidade desnecessária.
A visualização de diff também é sua verificação de segurança para risco de regressão. Se a mudança parecer muito ampla, muito absoluta ou muito prolixa, ajuste antes de aplicar. A engenharia de prompt só é útil quando é controlada - e este é o ponto de controle.
4.5 Aplique a Atualização de Instrução - Então Re-execute a Avaliação
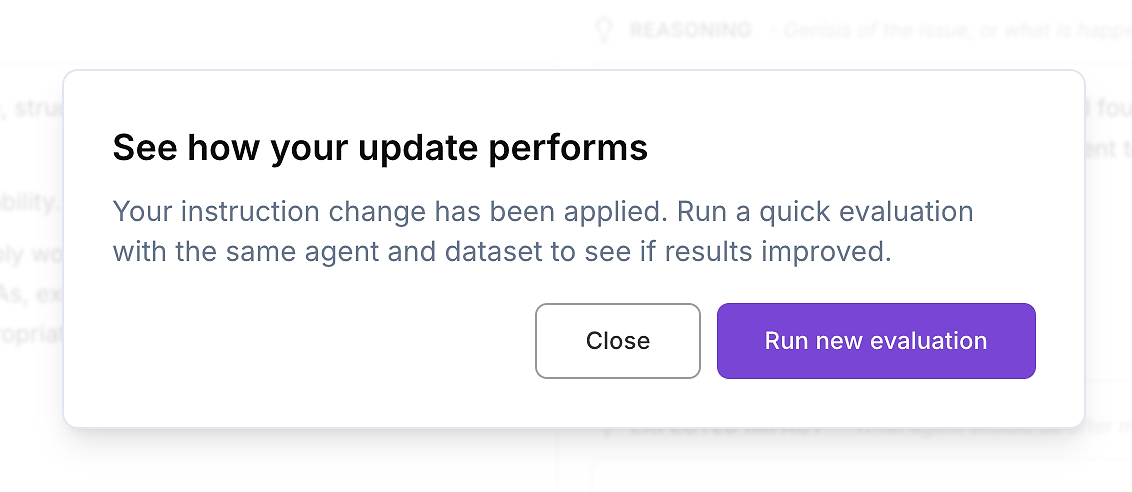
Depois de revisar o diff e estar satisfeito com a mudança, aplique as instruções do agente atualizadas.
Então faça o único próximo passo que importa para implantação empresarial: re-execute a mesma avaliação de agente de IA no mesmo conjunto de dados. É assim que você valida melhorias de forma controlada - uma variável alterada (instruções), tudo o mais mantido constante.
Isso cria um ciclo de otimização repetível e de nível empresarial:
Capture um relatório de avaliação de linha de base
Aplique uma atualização de instrução direcionada
Re-execute o mesmo conjunto de dados de avaliação
Compare resultados: pontuação, variância e outliers
É assim que a avaliação se torna um processo de lançamento - mensurável, auditável e seguro para lançar.
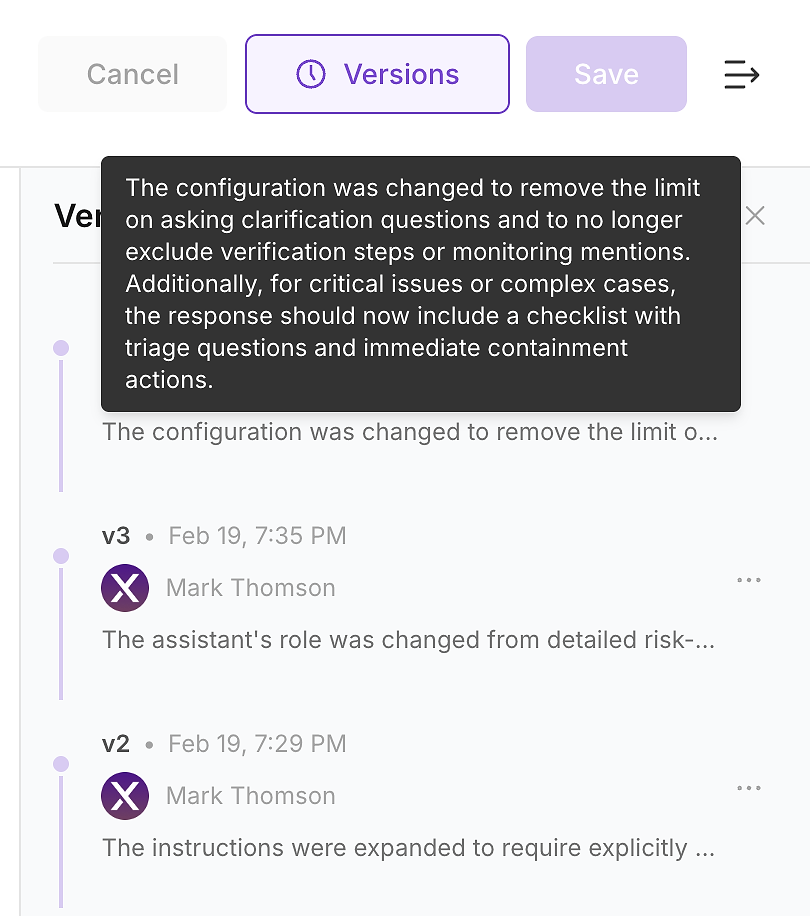
4.6 Verifique o Histórico de Versões - Torne a Mudança Auditável
Depois de aplicar a atualização, verifique o histórico de versões do agente. Em ambientes empresariais, isso não é opcional - é assim que você transforma mudanças de instrução em um log de mudanças auditável.
O histórico de versões permite que sua equipe responda às perguntas que segurança, conformidade e operações farão:
O que mudou (diff de instrução e resumo)
Quando mudou (atualização com carimbo de data/hora)
Quem mudou (propriedade e aprovações)
Por que mudou (vinculado a lacunas de avaliação e impacto esperado)
É assim que você lança com segurança: cada atualização de instrução se torna uma mudança versionada e revisável que você pode validar com uma nova execução e reverter se necessário.
Passo 5: Re-execute a Avaliação - Prove a Melhoria
Agora execute o mesmo conjunto de dados de avaliação novamente contra a versão atualizada do agente. Este é o momento em que a avaliação se torna valor de negócio: você não está afirmando que o agente é melhor - você está provando isso com resultados repetíveis.
No novo relatório, você está procurando três sinais:
Pontuação geral mais alta - mais cenários atendem totalmente aos requisitos da rúbrica
Melhor estabilidade - faixa de pontuação mais apertada, menor variância entre execuções
Menos outliers - menos resultados baixos súbitos que criam risco de produção
Na prática, uma atualização de instrução bem-sucedida não apenas eleva a média. Ela reduz a instabilidade tornando o fluxo de trabalho do agente mais consistente - especialmente em perguntas de triagem, estrutura de remediação e etapas de verificação.
É isso que “bom” parece em IA empresarial: melhoria mensurável, desempenho repetível e um claro rastro de auditoria ligando a mudança ao resultado.
Este fluxo de trabalho é a base do lançamento de agentes de IA de nível empresarial:
Execute uma avaliação em um conjunto de dados representativo
Use a análise para identificar modos de falha repetíveis
Aplique atualizações de instrução direcionadas com um diff revisado
Acompanhe mudanças através do histórico de versões para auditabilidade
Re-execute a mesma avaliação para validar a melhoria
É assim que você passa de “o agente soa bem” para “o agente performa de forma confiável.” A avaliação se torna um portão de lançamento - um processo CI prático para agentes de IA que reduz o risco operacional, melhora a consistência e torna as melhorias mensuráveis.
Chamada para Ação
Se você quer que a avaliação gere resultados reais de negócios, trate-a como engenharia:
Cada atualização de instrução deve acionar uma execução de avaliação
Cada falha de produção deve se tornar um novo caso de teste
Cada melhoria deve ser mensurável e repetível
Explore o AgentX
Saiba mais em agentx.so
Execute avaliações na plataforma em app.agentx.so
No próximo post, vamos nos aprofundar em métodos de avaliação empresarial, ferramentas e técnicas práticas para melhorar continuamente o desempenho e a confiabilidade dos agentes. Também vamos introduzir uma nova seção sobre Monitoramento - em breve.