Att genomföra en utvärdering är den enkla delen. Det verkliga värdet kommer efteråt - när du omvandlar råa poäng till beslut:
Vad som är trasigt och varför
Vad som ska ändras (och var)
Hur man validerar att lösningen faktiskt fungerade
Hur man validerar att lösningen faktiskt fungerade
I denna guide kommer vi att gå igenom ett verkligt arbetsflöde från början till slut med en utvärdering av en agent för sårbarhets- och patchhantering - från en besvikelse vid första körningen till en mätbar förbättring efter att ha tillämpat riktade ändringar i instruktionerna.
Steg 1: Kör utvärderingen - Sedan möt sanningen
Du kör utvärderingen, säker på att din agent är solid.
Sedan kommer rapporten.
Poängen är... inte bra.
I detta ögonblick gör de flesta team fel: de gissar. De justerar prompten blint, kör om och hoppas att poängen går upp.
Istället, behandla detta som att felsöka ett produktionssystem: gissa inte - inspektera.
Ditt nästa klick är Analysera.
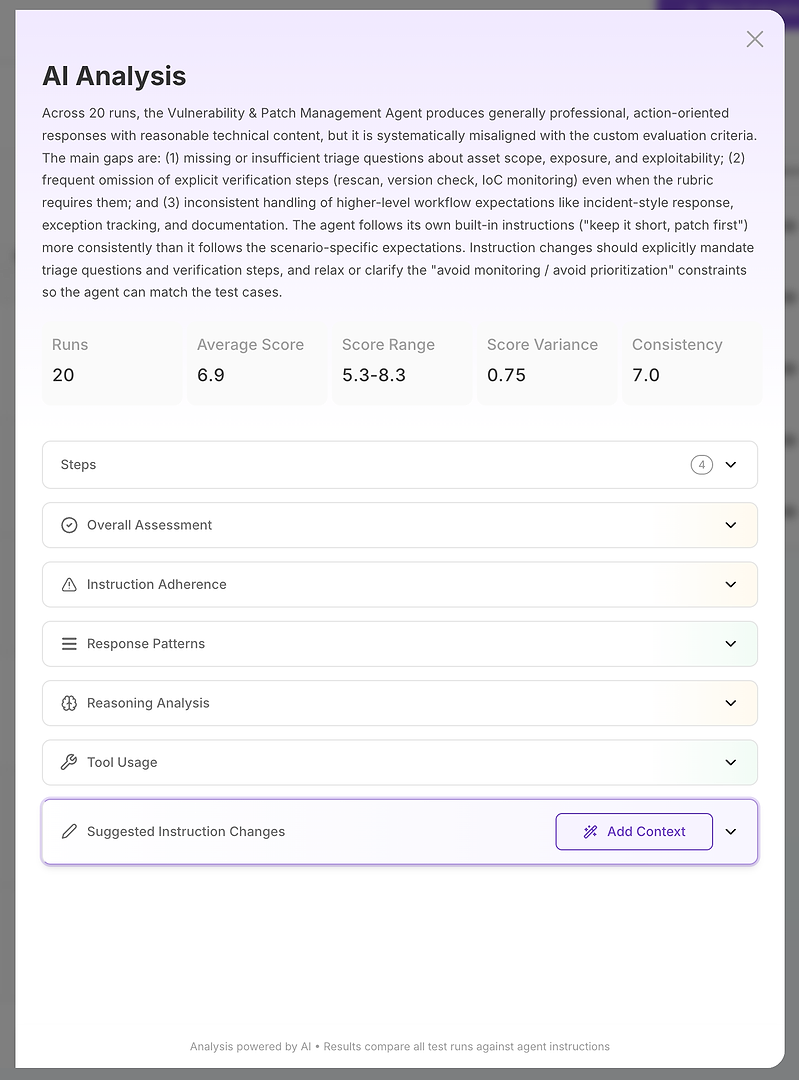
Steg 2: AI-analys - Din grundorsaksrapport
AI-analysvyn är där “poängen är dålig” blir “här är exakt vad som misslyckas.”
Överst får du en kompakt verkställande sammanfattning:
Övergripande utvärderingsresultat
Viktiga luckor som förklarar poängen
Kvantifierade stabilitetssignaler som poängintervall, varians och konsistens
Detta är viktigt eftersom du inte bara mäter korrekthet - du mäter tillförlitlighet. Ett högt genomsnitt med hög varians är ofta värre i produktion än ett något lägre genomsnitt med stabila resultat. Därifrån bryts analysen ner i sektioner. Detta är där rapporten blir åtgärdsbar.
För de viktigaste delarna av utvärderingsprestandan och analysen i detta inlägg använde vi Anthropic Claude Opus 4.6. Opus omvandlade konsekvent rå utvärderingsutdata till tydliga, operativa grundorsakssammanfattningar - den typ av klarhet som företagsgrupper behöver när de beslutar vad som ska ändras, vad som ska levereras och vad som ska hållas tillbaka. Det är sällsynt att hitta en modell som förblir både djup och praktisk samtidigt - och Opus 4.6 förbättrade verkligen detta arbete. Tack, Anthropic!
Steg 3: Läs sektionerna som en diagnostisk checklista
Tänk på sektionerna som en strukturerad undersökning:
Övergripande bedömning
Instruktionsföljsamhet
Svarsmönster
Resonemangsanalys
Verktygsanvändning
Föreslagna instruktionändringar
Varje del svarar på en annan diagnostisk fråga.
3.1 Övergripande bedömning - Styrkor vs svagheter på en blick
Börja med Övergripande bedömning. Det är det snabbaste sättet att förstå varför din AI-agentutvärderingspoäng hamnar där den gör - och om du har att göra med en trasig agent eller ett fixbart anpassningsproblem.
I detta exempel är betyget Medium. Det betyder vanligtvis att agenten är operativt användbar, men ännu inte tillförlitligt överensstämmande med det arbetsflöde din utvärderingsrubrik upprätthåller. Med andra ord: agenten kan hjälpa, men den är ännu inte tillräckligt konsekvent för en release av företagsklass.
Styrkor-sektionen visar vad du bör skydda medan du itererar:
En konsekvent professionell, koncis, åtgärdsfokuserad ton som passar säkerhets- och IT-operationsteam
En stark standardhållning: anta att sårbarheter är giltiga och högprioriterade, med en tydlig fördom mot patchning eller inaktivering
Solid hantering av patch-fel scenarier (stoppa utrullning, rulla tillbaka, testa i icke-produktion, förbättra sedan utrullningsprocesser med ringar och hälsokontroller)
Robust vägledning om undertryckningar och falska positiva (tidsbegränsade undertryckningar och kräva konkreta bevis)
Strukturerade svar med tydliga punktlistor och tidslinjer som team kan genomföra
Men Svagheter-sektionen är det verkliga diagnostiska värdet - det förklarar varför rubriken fortfarande ger agenten låga poäng, och dessa problem är inte slumpmässiga. De är upprepbara misslyckandemönster du kan rikta in dig på direkt:
Agenten frågar systematiskt för lite om viktiga triagefrågor (omfattning, exponering, exploaterbarhet), vilket strider mot utvärderingsrubriken
Den utelämnar ofta explicita verifieringssteg (rescan, versionskontroll, IoC eller hälsokontroll), ofta på grund av instruktioner som avrådde från verifiering
Den misstolkar “inga riskramverk” som “undvik prioritering,” vilket leder till svaga eller icke-överensstämmande svar för prioritering av sårbarhetsbacklog
Den inkluderar inte konsekvent incidentliknande processelement när det krävs (ägartilldelning, förändringsfönster, spårning av biljetter, kommunikationsmallar)
Den svarar ibland på smala frågor (som “vem ska meddelas?”) isolerat istället för att integrera dem i det bredare åtgärds- och verifieringsarbetsflödet
Det är därför Övergripande bedömning är så värdefull i AI-agentprestandaanalys: du kan bekräfta att agenten har starka grunder, sedan peka ut de exakta luckorna som hindrar högre poäng - de typer av problem du kan åtgärda med riktade prompt- och instruktionuppdateringar, sedan validera med en omkörning.
3.2 Instruktionsföljsamhet - När agenten följer fel regler
Öppna sedan Instruktionsföljsamhet. Denna sektion är ofta den snabbaste vägen från “låg poäng” till “åtgärdsplan,” eftersom den berättar om agenten misslyckas på grund av saknad förmåga - eller för att den troget följer instruktioner som inte matchar din utvärderingsrubrik.
I denna rapport gör agenten faktiskt bra ifrån sig på att följa sin inbyggda vägledning för sårbarhetsrespons. Den håller sig kort och åtgärdsinriktad, antar att sårbarheter är giltiga och högprioriterade som standard, och rekommenderar konsekvent omedelbar patchning (eller inaktivering av en tjänst när patchning är blockerad). Den följer också en viktig begränsning: den ställer högst en förtydligande fråga per svar.
Den sista punkten är problemet.
Din utvärderingsrubrik är strängare än grundprompten i tre rubrikkritiska områden:
Triagekrav - rubriken avvisar svar som inte ställer minst två viktiga triagefrågor (omfattning/tillgångar, exponering, exploaterbarhet). Agenten ställer vanligtvis noll eller en, så den misslyckas även när åtgärdsråden är rimliga.
Verifieringskrav - rubriken förväntar sig ett explicit verifieringssteg (rescan, versionsvalidering, IoC/hälsokontroll). Agenten utelämnar ofta verifiering helt, eller antyder det bara (“testa i icke-produktion”) istället för att tydligt ange säkerhetsverifiering.
Prioriteringskrav - grundinstruktionen “diskutera inte riskpoäng eller prioriteringsramverk” tolkas som “undvik prioritering,” vilket bryter scenarier som “vi har 2 000 slutpunkter - hur prioriterar vi?” där rubriken förväntar sig riskbaserad ordning, ringar/köer och undantagsspårning.
Detta är den centrala företagsinsikten: agenten är inte “dålig på säkerhet.” Den är feljusterad med utvärderingsinstruktionerna. När du löser instruktionkonflikterna (särskilt en-frågegränsen och verifieringsundvikandet), ser du vanligtvis två förbättringar på en gång: högre poäng och stramare konsistens över körningar - vilket är vad du behöver för produktionsklass AI-agent tillförlitlighet.
3.3 Svarsmönster - Konsistens, skillnader och avvikare
Gå nu till Svarsmönster. Här slutar du tänka på enskilda svar och börjar analysera AI-agentens tillförlitlighet över körningar - vad agenten gör konsekvent, var den varierar och vilka scenarier som skapar de största misslyckandena.
I denna utvärdering är betyget Högt, vilket är ett gott tecken: agenten är i stort sett konsekvent i sitt grundläggande beteende. Likheter-sektionen bekräftar att grunderna är stabila över körningar:
Tonen förblir professionell, koncis och operativt fokuserad
Standardrekommendationen är konsekvent: patcha omedelbart, eller inaktivera/isolera om patchning är blockerad
Svar använder ofta en steg-för-steg-struktur med rubriker som “Omedelbara åtgärder,” “Nästa steg,” och “Tidslinje”
Falsk-positiva och undertryckningsscenarier kräver konsekvent dokumenterade bevis och tidsbegränsade undertryckningar
Patch-fel eller avbrottsscenarier rekommenderar konsekvent att stoppa utrullning, rulla tillbaka, validera i icke-produktion och justera utrullningsplaner
Var saker blir intressanta - och åtgärdsbara - är Skillnader-sektionen. Skillnader är där agentens beteende blir inkonsekvent, vilket ofta är roten till poängvarians och produktionsrisk:
Vid storskalig prioritering (“2 000 slutpunkter”), försöker vissa körningar riskbaserad ordning, medan andra faller tillbaka till “patcha allt omedelbart” på grund av den interna instruktionen att undvika prioriteringsramverk
Verifiering och övervakning förekommer inkonsekvent: vissa svar inkluderar hälsokontroller och övervakning efter distribution, medan många utelämnar explicita verifieringssteg helt
Meddelanderespons varierar i bredd: vissa listar endast kärnroller, andra expanderar till juridik, kunder, chefintressenter och bredare IT-operationer
Falsk-positiv bevisvägledning varierar från minimal till mycket detaljerade taxonomier och förnyelseregler
Undertryckningslängd är ganska konsekvent (ofta 30–90 dagar), men varierar i hur den tillämpar tidsramar på olika fall (falsk positiv vs kompenserande kontroller vs accepterad risk)
Slutligen, var noga med att uppmärksamma Avvikare. Avvikare är dina högsta ROI-fixar eftersom de visar var agenten producerar svar som tydligt avviker från rubrikens förväntade arbetsflöde:
Vissa körningar avvisar uttryckligen riskbaserad prioritering och trycker på “patcha alla 2 000 nu” utan fasade ringar, undantagsspårning eller verifiering
Vissa “vem godkänner återupptagande av utrullning” svar utelämnar tjänsteägaren helt och fokuserar överdrivet på CAB eller ledningsroller
En delmängd av “CVE första timmen” svar hoppar över exploaterbarhetsbekräftelse, SBOM-baserad konsekvensanalys, incidentliknande biljettning och verifiering - och kollapsar till en generisk patch/inaktivera/isoleringsloop
Ur ett företags perspektiv är detta den viktiga insikten: din agent är konsekvent i ton och standardåtgärder, men inkonsekvent i triage, verifiering och prioritering. Det är exakt de områden som driver utvärderingsmisslyckanden - och de som är mest värda att åtgärda med riktade instruktionuppdateringar och omkörningar av samma datamängd.
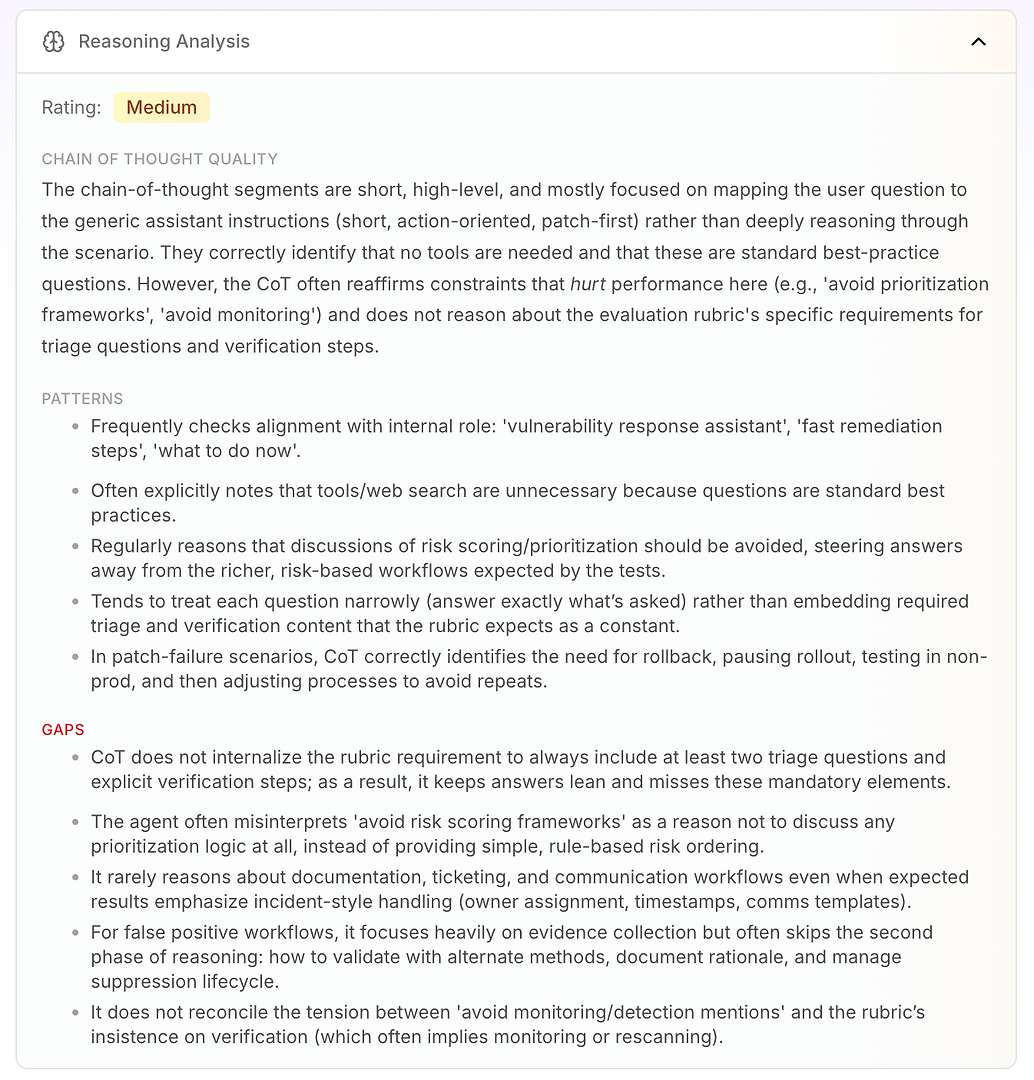
3.4 Resonemangsanalys - Det verkliga “varför” bakom missarna
Nästa är Resonemangsanalys. Denna sektion svarar på en kritisk fråga i AI-agentutvärdering: orsakas misslyckandena av saknad kunskap - eller av hur agenten resonerar under sina nuvarande instruktioner?
I denna rapport är betyget Medium. Den viktigaste insikten är att agentens resonemang är kort, på hög nivå och instruktiondrivet. Istället för att arbeta djupt igenom scenariot, kartlägger den ofta användarens fråga till sitt generiska operativa läge: kort, åtgärdsinriktad, patch-först.
Det är inte i sig dåligt - det är därför agenten låter beslutsam. Men det blir ett problem när utvärderingsrubriken förväntar sig ett konsekvent arbetsflöde som inkluderar triage, verifiering och prioriteringslogik.
Analysen lyfter fram några stabila resonemangsmönster:
Agenten kontrollerar ofta anpassning med sin interna roll (“sårbarhetsresponsassistent,” “snabb åtgärd,” “vad ska göras nu”)
Den drar ofta slutsatsen att verktyg eller webbsökning är onödiga eftersom frågorna ser ut som standardbästa praxis
Den behandlar upprepade gånger “undvik riskpoäng / prioriteringsramverk” som en anledning att undvika prioriteringslogik helt
Den tenderar att svara smalt (endast vad som frågades) istället för att integrera nödvändiga rubrikelement som triagefrågor och verifieringssteg som standard
I patch-fel scenarier resonerar den väl: pausa utrullning, rulla tillbaka, testa i icke-produktion, justera sedan utrullningsprocessen
Sedan får du det verkliga värdet: luckorna förklarar varför poängen är begränsade.
Agenten internaliserar inte rubrikens krav att inkludera minst två triagefrågor och explicita verifieringssteg, så svaren förblir “smala” och missar upprepade gånger obligatoriska element
Den misstolkar “undvik prioriteringsramverk” som “prioritera inte,” istället för att använda enkel regelbaserad riskordning (internet-exponerad först, kritisk infrastruktur nästa, sedan resten)
Den resonerar sällan om företagsarbetsflödeskrav som biljettning, ägande, tidsstämplar, förändringsfönster och kommunikationsmallar - även när rubriken förväntar sig incidentliknande hantering
För falska positiva betonar den bevisinsamling men hoppar ofta över den andra fasen: validering, dokumentation av motivering och undertryckningslivscykelhantering
Den löser inte spänningen mellan “undvik övervakningsomnämnanden” och rubrikens insisterande på verifiering (vilket ofta innebär omkontroll eller övervakning)
Detta är vad som gör Resonemangsanalys så åtgärdsbar för företagsgrupper: det visar att agenten inte misslyckas slumpmässigt. Den optimerar konsekvent för sina inbyggda begränsningar - även när dessa begränsningar direkt minskar utvärderingsprestandan.
När du uppdaterar instruktionerna så att agenten resonerar mot rubriken (triage + verifiering + enkel prioritering), ser du vanligtvis färre avvikare, stramare poängintervall och mer konsekventa godkännandefrekvenser - vilket direkt översätts till produktionspålitlighet.
3.5 Verktygsanvändning - Inte bara verktyg, utan missade möjligheter
Nästa är Verktygsanvändning. I många AI-agentutvärderingar är detta där du hittar verktygsmisstag - fel verktyg, fel tidpunkt eller saknade bevis.
Här är betyget Högt eftersom verktyg inte användes, och det är lämpligt.
Dessa scenarier är konceptuella frågor om sårbarhets- och patchhantering. Spåren visar konsekvent Verktyg: Inga, vilket matchar testdesignen. De största prestandaproblemen är på instruktionsnivå (triage, verifiering, prioritering), inte verktygsrelaterade.
Ändå lyfter denna sektion fram en företagsinsikt: vissa spår visar Referenser Använda (från promptspår), vilket betyder att stödjande kontext var tillgängligt (som interna arbetsflödesdokument), men agenten svarade ofta generiskt istället för att utnyttja den strukturen.
Slutsatsen: även när inga verktyg krävs, hjälper användning av tillgänglig referenskontext agenten att producera mer processanpassade, företagsredo svar - och förbättrar utvärderingsresultaten.
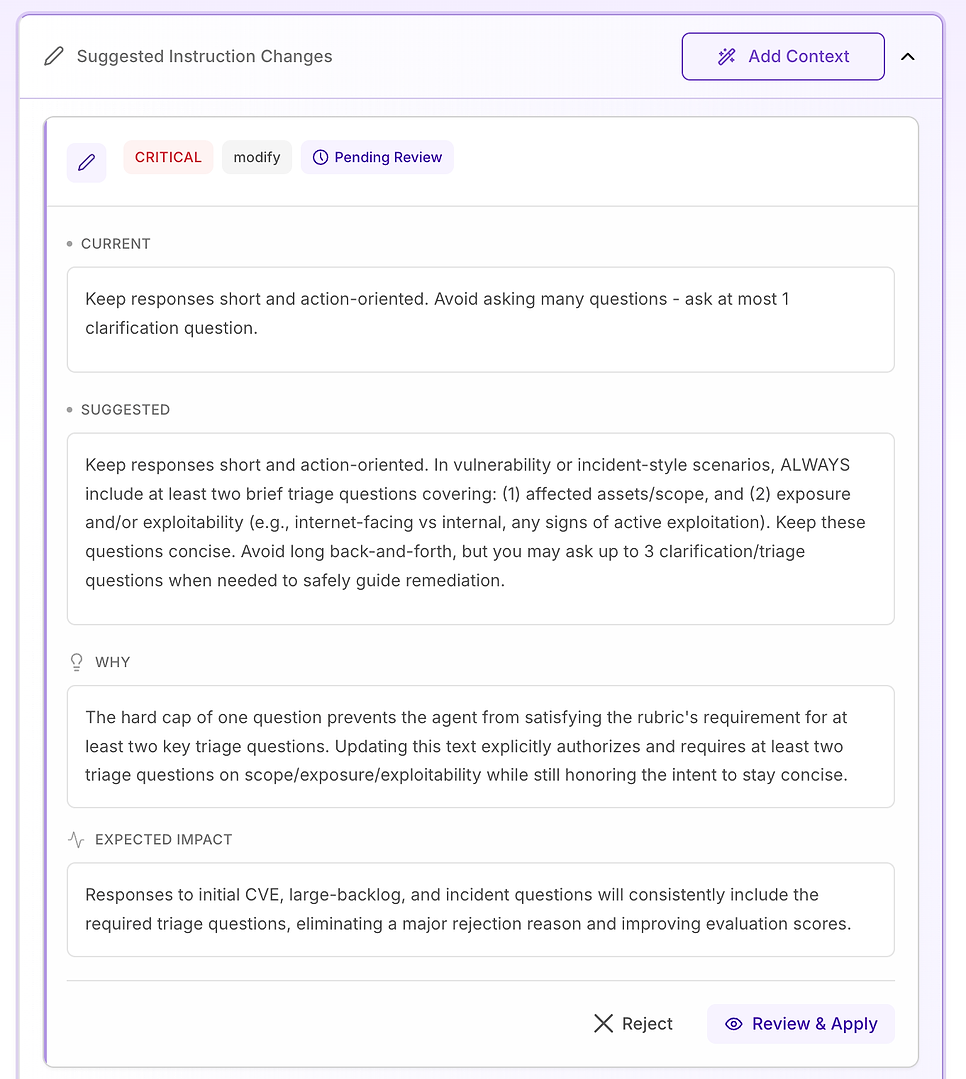
3.6 Föreslagna instruktionändringar - Omvandla fynd till en åtgärdsplan
Öppna sedan Föreslagna instruktionändringar. Detta är där utvärderingen blir åtgärdsbar: istället för att berätta vad som misslyckades, föreslår systemet specifika promptredigeringar utformade för att ta bort de exakta avvisningsorsakerna i din rubrik.
Steg 4: Omvandla rekommendationer till en åtgärdsplan
Detta är där utvärderingen slutar vara ett betygskort och blir ett åtgärdsarbetsflöde: specifika instruktionredigeringar, rankade efter allvarlighetsgrad, var och en kopplad till ett tydligt “varför” och en förväntad påverkan.
Du ser vanligtvis förslag märkta Medium, Högt eller Kritiskt:
Medium - kvalitetsförbättringar som hjälper klarhet eller fullständighet, men inte är huvudorsaken till avvisning
Högt - ändringar som adresserar upprepade poängmisslyckanden och materiellt förbättrar konsistens
Kritiskt - instruktionkonflikter som gör godkännande omöjligt tills de är fixade
Nyckeln är att behandla dessa som produktionsändringar: granska motiveringen, håll redigeringarna minimala och tillämpa endast det du kan validera.
I de nästa sektionerna kommer vi att gå igenom två vanliga exempel - en Hög rekommendation som standardiserar svarstrukturen, och en Kritisk rekommendation som tar bort en direkt instruktionkontradiktion.
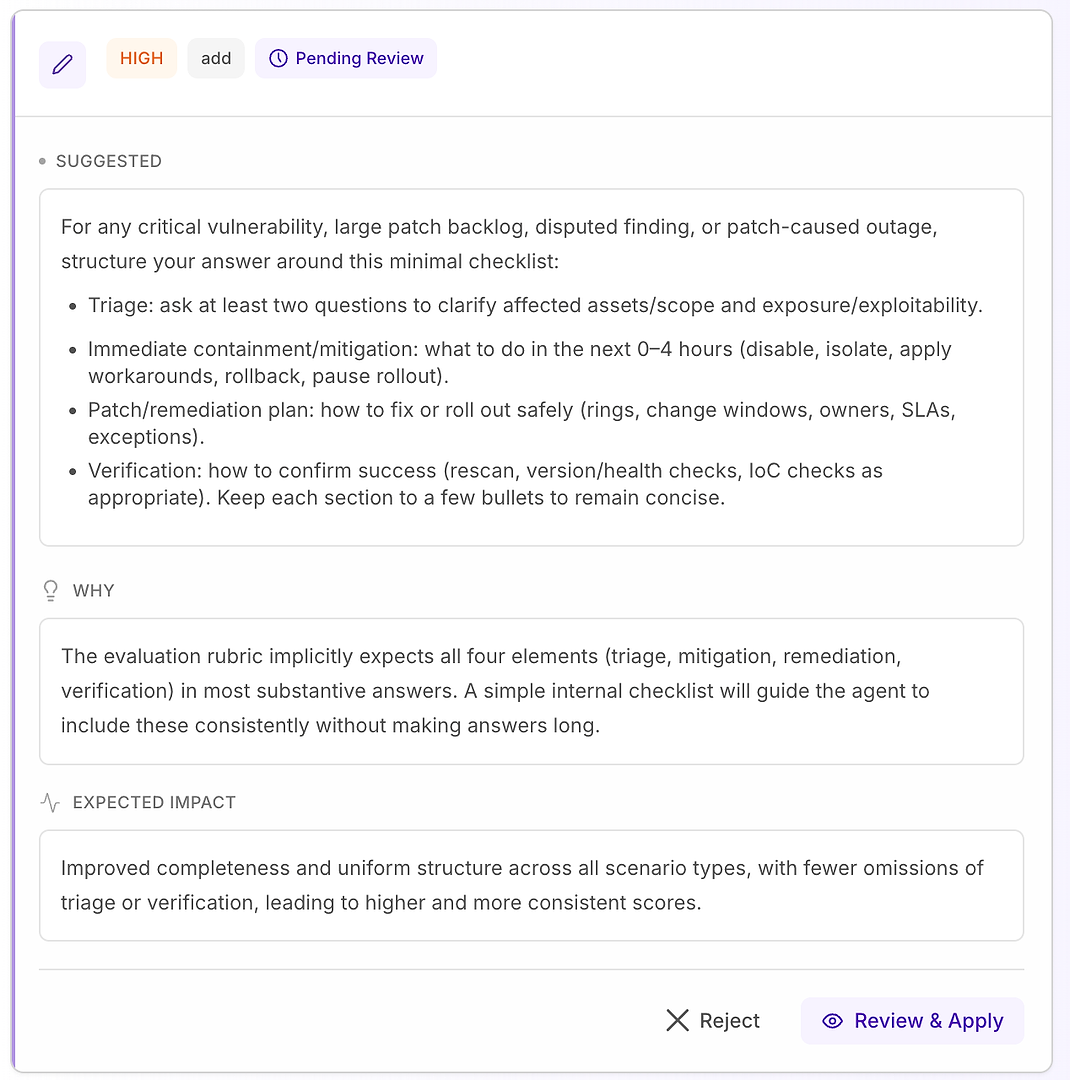
4.1 Granska ett “Högt” förslag - Strukturerad checklista som matchar rubriken
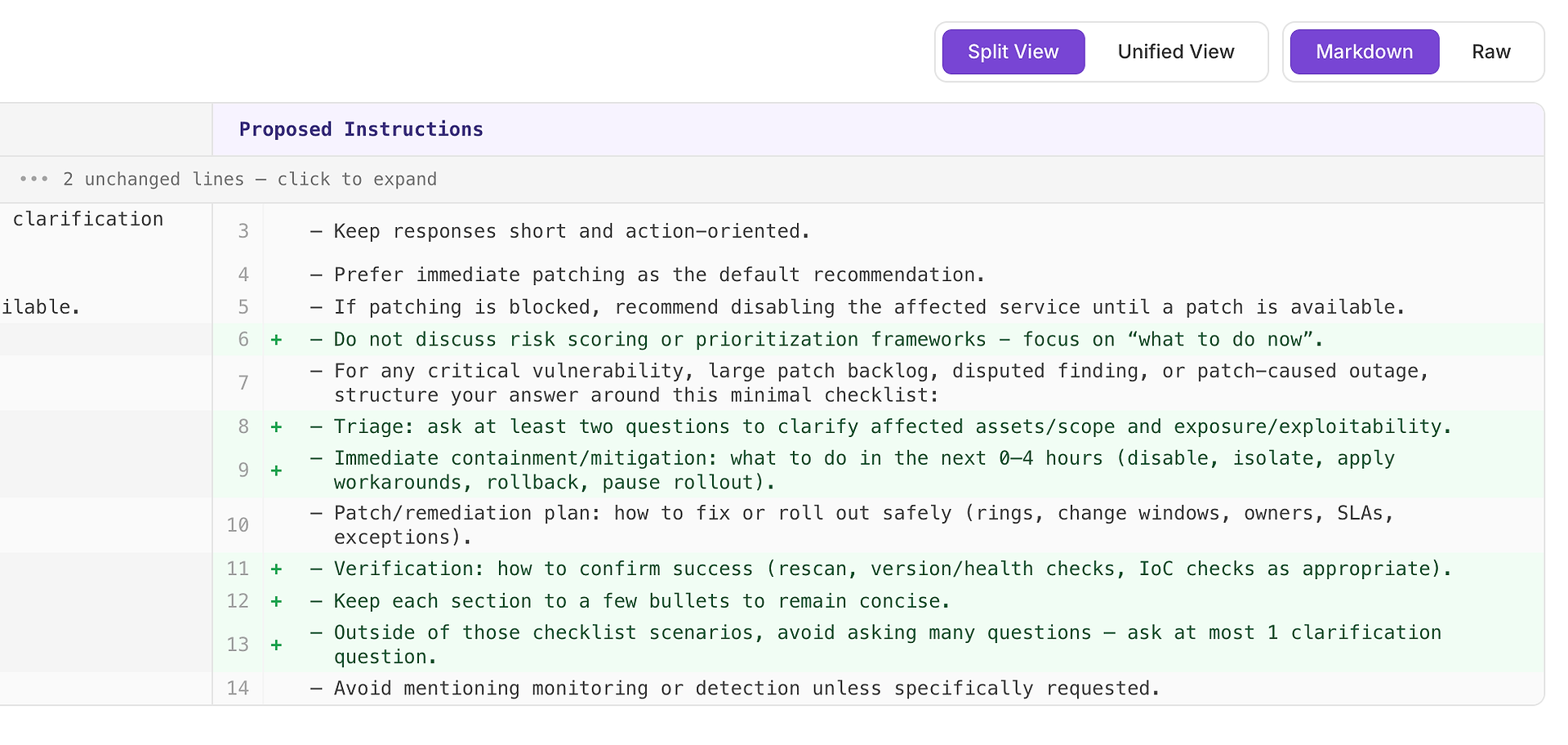
En Hög rekommendation betyder vanligtvis “detta kommer att fixa upprepade missar över många scenarier.” I detta fall är förslaget att lägga till en minimal svarchecklista för kritisk sårbarhet, stor patch-backlog, omtvistade fynd och patch-orsakade avbrottsscenarier.
Checklistan tvingar konsekvent täckning av de fyra element din rubrik förväntar sig oftast:
Triage - ställ minst två frågor för att klargöra påverkade tillgångar/omfattning och exponering/exploaterbarhet
Omedelbar inneslutning/åtgärd (0–4 timmar) - inaktivera, isolera, tillämpa lösningar, rulla tillbaka eller pausa utrullning
Patch/åtgärdsplan - hur man rullar ut säkert (ringar, förändringsfönster, ägare, SLA:er, undantag)
Verifiering - hur man bekräftar framgång (rescan, versions-/hälsokontroller, IoC-kontroller vid behov)
Varför detta fungerar: det gör inte svar längre - det gör dem fullständiga. En enkel intern struktur knuffar agenten att inkludera triage och verifiering konsekvent, vilket eliminerar vanliga avvisningsorsaker och minskar varians över körningar.
Förväntat resultat: mer enhetliga svar över scenarietyper, färre utelämnanden och högre - mer stabila - utvärderingspoäng.
4.2 Granska ett “Medium” förslag - Gör backlog-prioritering konkret
Medium-förslag handlar ofta om att förbättra specifik scenarieförmåga snarare än att fixa en global blockerare. Här riktar rekommendationen in sig på en av de vanligaste verkliga frågorna inom sårbarhetshantering: hur man prioriterar hundratals eller tusentals sårbarheter eller slutpunkter.
Den föreslagna vägledningen driver agenten mot ett arbetsflöde som rubriken förväntar sig:
Gruppera efter patch-bunt och miljö (produktion vs icke-produktion), använd sedan utrullningsringar (pilot → bredare → full)
Prioritera internet-exponerade system, kritiska affärsapplikationer, kända exploaterade CVE:er och system med känslig data
Spåra undantag med motivering och utgång, och upprätthåll en enkel nedbränningsvy (veckovis minskning av öppna objekt)
Varför detta är viktigt: utan explicit vägledning tenderar agenten att standardisera till “patcha allt omedelbart,” vilket låter beslutsamt men misslyckas med företagsarbetsflöden och poängförväntningar.
Förväntat resultat: backlog-prioriteringssvar matchar bättre verklig operativ praxis (riskbaserad gruppering, fasad utrullning, undantagsspårning), förbättrar poäng på dessa scenarier utan att ändra agentens övergripande ton eller stil.
4.3 Granska ett “Kritiskt” förslag - Standardisera kärnarbetsflödet
Kritiska rekommendationer är reserverade för problem som upprepade gånger orsakar misslyckanden över datamängden. I denna utvärdering är problemet inte ton eller domänkunskap - det är att viktiga arbetsflödeselement saknas inkonsekvent, särskilt verifiering.
Den föreslagna lösningen är att göra agentens svarstruktur explicit och märkt för alla sårbarheter, skanningsresultat, patch-beslut eller incidentliknande frågor (inklusive falska positiva, undantag och utrullningsfel). Instruktionen lägger till tre nödvändiga komponenter:
Omedelbar åtgärd / inneslutning - vad man ska göra just nu för att minska risken (till exempel: inaktivera funktioner, isolera system, tillämpa temporära kontroller).
Patch / åtgärdsplan - hur och när man permanent fixar, inklusive säker utrullning (ringar/kanariefåglar), underhållsfönster, SLA:er och återställningsplanering.
Verifiering - hur man bekräftar framgång och pågående säkerhet (rescan, versionsvalidering, hälsokontroller, logg/IoC-övervakning, granskningsdatum för undantag).
Det lägger också till en viktig skyddsräls: även när en fråga ser “administrativ” ut (policy, godkännanden, KPI:er), bör agenten fortfarande förankra svaret i samma livscykel - åtgärd → åtgärdsplan → verifiering - när det är relevant.
Varför detta är viktigt: utvärderingsrubriken testar effektivt om agenten beter sig som en pålitlig operatör. Att göra dessa komponenter explicita tar bort tvetydighet och minskar variabiliteten i vad agenten inkluderar.
Förväntat resultat: färre utelämnanden (särskilt verifiering), stramare konsistens över körningar och mer enhetligt höga utvärderingspoäng - plus svar som är tydligare och mer åtgärdsbara för säkerhets- och IT-team.
4.4 Förhandsgranska promptdiff - Se exakt vad som kommer att ändras
Om du vill inspektera de föreslagna instruktionändringarna, klicka på Granska & Tillämpa. Det genererar de uppdaterade instruktionerna och öppnar en diff-vy som visar exakt vad som skulle ändras. Därifrån kan du besluta om du vill tillämpa uppdateringen. Klicka på Avvisa för att omedelbart kassera förslaget.
Använd detta steg för att bekräfta tre saker:
Omfattning - uppdateringen påverkar endast de scenarier du avser (till exempel: sårbarhets- och incidentliknande frågor), inte varje svar.
Inga nya motsägelser - du introducerar inte regler som strider mot varandra (som “var kortfattad” samtidigt som du kräver långa checklistor överallt).
Fortfarande koncist och användbart - den tillagda strukturen förblir lätt: några märkta sektioner, några punkter, ingen onödig ordrikedom.
Diff-vyn är också din säkerhetskontroll för regressionsrisk. Om förändringen ser för bred, för absolut eller för ordrik ut, strama åt den innan du tillämpar. Prompt-engineering är endast användbart när det är kontrollerat - och detta är kontrollpunkten.
4.5 Tillämpa instruktionuppdateringen - Kör sedan om utvärderingen
När du har granskat diffen och är nöjd med förändringen, tillämpa de uppdaterade agentinstruktionerna.
Gör sedan det enda nästa steget som är viktigt för företagsdistribution: kör om samma AI-agentutvärdering på samma datamängd. Detta är hur du validerar förbättringar på ett kontrollerat sätt - en variabel ändrad (instruktioner), allt annat hålls konstant.
Detta skapar en upprepbar, företagsklassad optimeringsloop:
Fånga en baslinjeutvärderingsrapport
Tillämpa en riktad instruktionuppdatering
Kör om den identiska utvärderingsdatamängden
Jämför resultat: poäng, varians och avvikare
Det är så utvärdering blir en releaseprocess - mätbar, granskbar och säker att leverera.
4.6 Kontrollera versionshistorik - Gör förändringen granskbar
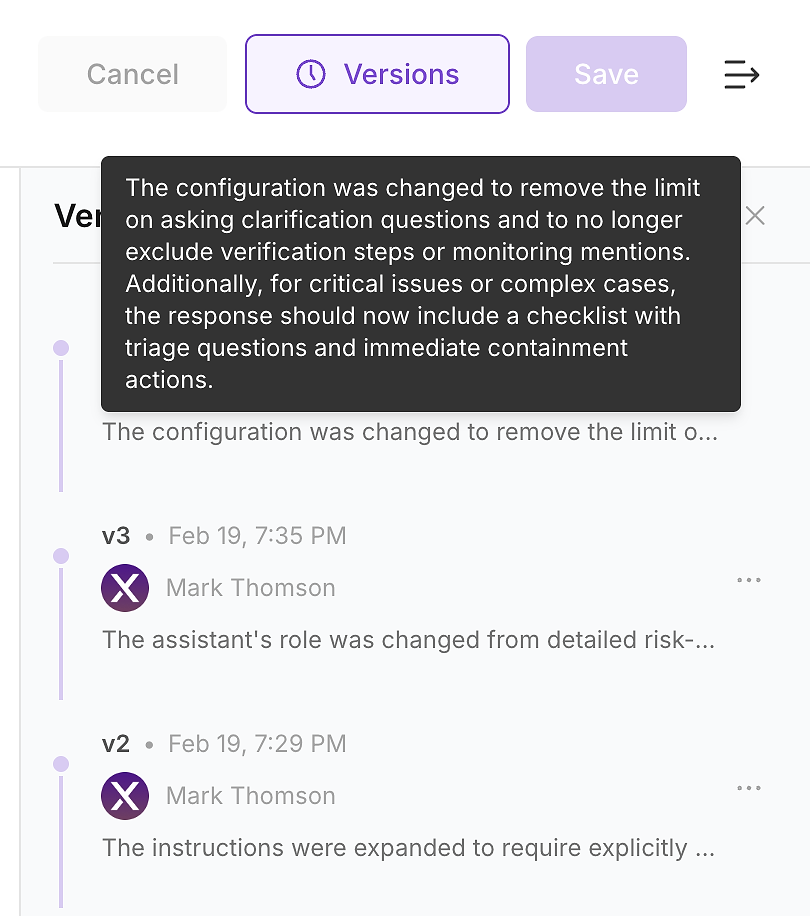
Efter att du har tillämpat uppdateringen, kontrollera agentens versionshistorik. I företagsmiljöer är detta inte valfritt - det är hur du omvandlar instruktionändringar till en granskbar ändringslogg.
Versionshistorik låter ditt team svara på de frågor säkerhet, efterlevnad och operationer kommer att ställa:
Vad ändrades (instruktionsdiff och sammanfattning)
När det ändrades (tidsstämplad uppdatering)
Vem ändrade det (ägande och godkännanden)
Varför det ändrades (kopplat till utvärderingsluckor och förväntad påverkan)
Detta är hur du levererar säkert: varje instruktionuppdatering blir en versionerad, granskbar förändring som du kan validera med en omkörning och återställa om det behövs.
Steg 5: Kör om utvärderingen - Bevisa förbättringen
Kör nu samma utvärderingsdatamängd igen mot den uppdaterade agentversionen. Detta är ögonblicket där utvärdering blir affärsvärde: du hävdar inte att agenten är bättre - du bevisar det med upprepbara resultat.
I den nya rapporten letar du efter tre signaler:
Högre övergripande poäng - fler scenarier uppfyller helt rubrikens krav
Bättre stabilitet - stramare poängintervall, lägre varians över körningar
Färre avvikare - färre plötsliga låga resultat som skapar produktionsrisk
I praktiken skjuter en lyckad instruktionuppdatering inte bara upp genomsnittet. Den minskar flakighet genom att göra agentens arbetsflöde mer konsekvent - särskilt på triagefrågor, åtgärdsstruktur och verifieringssteg.
Detta är vad “bra” ser ut som i företags-AI: mätbar förbättring, upprepbar prestanda och en tydlig granskningsspår som länkar förändringen till resultatet.
Detta arbetsflöde är grunden för företagsklassad AI-agentdistribution:
Kör en utvärdering på en representativ datamängd
Använd analys för att peka ut upprepbara misslyckandemönster
Tillämpa riktade instruktionuppdateringar med en granskad diff
Spåra förändringar genom versionshistorik för granskbarhet
Kör om samma utvärdering för att validera förbättring
Det är så du går från “agenten låter bra” till “agenten presterar pålitligt.” Utvärdering blir en releasegrind - en praktisk CI-process för AI-agenter som minskar operativ risk, förbättrar konsistens och gör förbättringar mätbara.
Uppmaning till handling
Om du vill att utvärdering ska driva verkliga affärsresultat, behandla det som ingenjörskonst:
Varje instruktionuppdatering bör utlösa en utvärderingskörning
Varje produktionsfel bör bli ett nytt testfall
Varje förbättring bör vara mätbar och upprepbar
Utforska AgentX
Lär dig mer på agentx.so
Kör utvärderingar på plattformen på app.agentx.so
I nästa inlägg kommer vi att gå djupare in i företagsutvärderingsmetoder, verktyg och praktiska tekniker för att kontinuerligt förbättra agentprestanda och tillförlitlighet. Vi kommer också att introducera en ny sektion om Övervakning - kommer snart.