AI-forskningsagenter revolutionerar hur vi interagerar med akademisk litteratur, datasyntes och kunskapsupptäckter. På AgentX designar vi autonoma AI-system som inte bara hittar svar—de resonerar genom dem. Vår plattform utnyttjar kedje-tanke-promptning, djupgående tankemodeller och multi-agent-samarbete för att leverera förstklassig forskningsintelligens.
AI-forskningsagenter förändrar hur forskare samlar in, analyserar och syntetiserar information. På AgentX specialiserar vi oss på att bygga intelligenta, autonoma system som effektiviserar akademisk forskning med hjälp av avancerad artificiell intelligens.
I denna omfattande guide kommer du att lära dig hur du skapar en anpassad AI-forskningsagent—en digital assistent kapabel att automatisera tråkiga forskningsarbetsflöden, läsa artiklar, generera sammanfattningar och avslöja insikter på sekunder.
Vad är en AI-forskningsagent?
En AI-forskningsagent är en avancerad mjukvaruapplikation driven av maskininlärning och naturlig språkbehandling (NLP). Till skillnad från regelbaserade system använder dessa agenter kedje-tanke (CoT) promptning och djupinlärningsbaserat resonemang för att simulera människoliknande tänkande.
Nyckelfunktioner hos AI-agenter
En hämtagent samlar in relevant akademisk litteratur
En analysagent tillämpar strukturerat resonemang och mönsterigenkänning
En sammanfattningsagent skapar mänskligt läsbara insikter
En delegeringsagent dirigerar dynamiskt uppgifter baserat på kontext och förtroende
Detta multi-agent delegeringssystem möjliggör skalbart, parallelliserat resonemang och säkerställer att uppgifter hanteras av den mest kvalificerade logikmodulen—vilket dramatiskt förbättrar prestanda, noggrannhet och förklarbarhet.
Steg 1: Definiera målet för din AI-assistent
Innan du bygger ett AI-drivet forskningsverktyg, definiera problemet det löser. Att klargöra din agents uppdrag är viktigt—särskilt om du implementerar multi-agent forskningsarbetsflöden.
Nyckelfrågor för att definiera din AI-agents syfte
Vilka specifika forskningsuppgifter kommer den att automatisera?
Vilka är målgrupperna—forskare, analytiker, studenter?
Vilka domäner (t.ex. hälsa, teknik, utbildning) kommer den att stödja?
Vilka är de förväntade leveranserna—sammanfattningar, citat, insikter?
Vilka prestationsmått kommer du att använda för att utvärdera framgång?
Använd SMART-målramverket—Specifikt, Mätbart, Uppnåeligt, Relevant och Tidsbundet—för att vägleda din utvecklingsprocess.
Steg 2: Samla in och förbered högkvalitativa data
Din agents effektivitet beror på kvaliteten på de träningsdata den får. Att bygga en strukturerad datapipeline är avgörande för framgång.
Bästa praxis för AI-datainsamling
Källa data från ansedda forskningsdatabaser
Tillämpa filter för noggrannhet, auktoritet och relevans
Dokumentera metadata och spåra datalinje
Automatisera datainmatning där det är möjligt
Steg för datapreparering
Datastädning: Ta bort brus, fixa inkonsekvenser och normalisera format
Strukturering: Organisera text, tabeller och metadata i användbara format
Berikning: Lägg till kontextuella etiketter, taggar och referenser
Segmentering: Dela upp data i tränings-, test- och valideringsuppsättningar
En stark pipeline säkerställer att din AI-assistent för forskning kan lära sig från rena, pålitliga och mångsidiga källor.
Steg 3: Välj rätt teknologiska stack
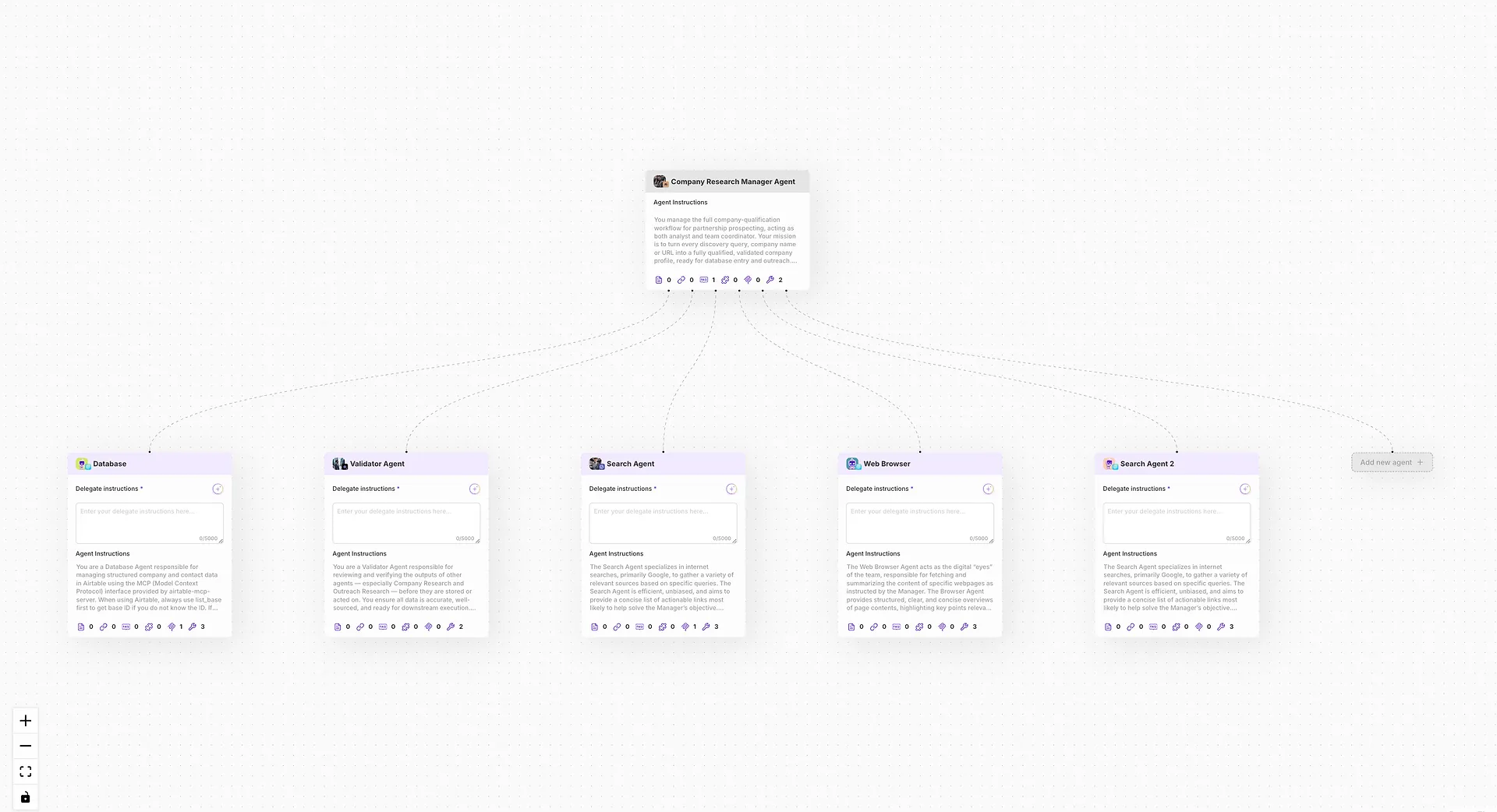
AgentX använder sitt egenutvecklade orkestreringsramverk designat specifikt för multi-agent resonemang och uppgiftsdelegering. Funktioner inkluderar:
Intelligent uppgiftsorkestrering: AgentX:s motor bryter dynamiskt ner forskningsfrågor i deluppgifter och tilldelar dem till specialiserade agenter (t.ex. hämtning, syntes, validering).
Kontextmedveten agentdelegering: Uppgifter dirigeras till den mest kapabla agenten med hjälp av interna prestationspoäng och semantisk matchning—inte bara hårdkodade regler.
Integrerat delat minne: Alla agenter arbetar över ett enhetligt kunskapsutrymme, vilket möjliggör samarbete, korsreferenser och delning av tillstånd i realtid.
Detta system tillåter AgentX-drivna AI-agenter att tänka kooperativt, resonera på djupet och delegera dynamiskt—vilket säkerställer konsekventa, förklarbara och högkvalitativa resultat över komplexa forskningsarbetsflöden.
Steg 4: Designa, träna och bygg din AI-agent med multi-agent resonemang
I hjärtat av varje kraftfullt forskningsautomationssystem finns en design som tänker framåt—bokstavligen. Med AgentX innebär att bygga din AI-agent att skapa ett team av specialister kapabel till djupgående resonemang, samarbetsproblemlösning och intelligent delegering.
Så här gör du det rätt:
Planera din vertikala domän
Börja med att definiera den vertikala domän din agent kommer att verka inom—såsom medicinsk forskning, finansiell analys, juridisk rådgivning eller vetenskaplig publicering.
Vilka specifika problem kommer din AI att lösa inom denna domän?
Vilka typer av källor kommer den att behöva resonera över (t.ex. kliniska prövningar, vitböcker, rättsfall)?
Finns det regulatoriska, etiska eller domänspecifika standarder som AI:n måste följa?
En väl avgränsad vertikal hjälper dig att designa ändamålsenliga agenter med högre relevans och skarpare prestanda.
Välj kunskapsbaser och verktyg för att utöka kapabiliteter
Att välja rätt kunskapsgrund är avgörande för att låsa upp kraftfulla kapabiliteter. AgentX stödjer modulär integration av domänspecifika kunskapsbaser samt interna verktyg som MCP (Model Context Protocol) för att dynamiskt styra agentbeteende.
Strukturerad data: Använd kuraterade dataset eller API:er (t.ex. PubMed, SEC-filings)
Ostrukturerad text: PDF:er, artiklar, forskningsartiklar
MCP: Ett egenutvecklat AgentX-verktyg som tillåter agenter att följa modulära resonemangsmönster, spåra kontext och eskalera när djupare analys behövs. (Till exempel, arXiv MCP)
✅ Tips: Att integrera MCP låter dig definiera återanvändbara “resoneringsstrategier” över olika agenter för att upprätthålla konsistens och logisk stringens.
Skapa och träna varje specialiserad agent
Istället för att bygga en enda monolitisk modell, uppmuntrar AgentX agentspecialisering. Varje underagent är finjusterad för att hantera en del av resonemangspipelinen:
Hämtningsagent: Lokaliserar relevanta dokument och extraherar citat
Analysagent: Utför syntes, jämförelse eller statistiskt resonemang
Kritikagent: Validerar utdata, flaggar motsägelser eller hallucinationer
Syntesagent: Genererar tydliga, evidensbaserade sammanfattningar eller rapporter
Träna varje agent med domänspecifika data och märkta resoneringskedjor. För CoT-prestanda, inkludera exempel som kräver flerstegs deduktion, jämförelser och logikkedjor.
Lägg upp resoneringsregler och CoT-promptstrategier
För varje agent, definiera explicita regler och kedje-tanke-promptar som formar dess tankestil.
Använd strukturerade promptar: "Först, hitta hypotesen. Sedan, lokalisera stödjande studier. Slutligen, utvärdera motsägelser."
Definiera eskaleringsvägar: Om förtroendepoängen är låg, delegera till en annan agent eller begär användarklarering
Tillämpa logikmallar för repetitiva uppgifter som benchmarking eller kontrasterande fynd
Dessa strategier låter din AI-assistent bete sig förutsägbart samtidigt som den förblir flexibel för komplexa indata.
Skapa en multi-agent arbetsstyrka i AgentX
När varje agent är tränad och promptjusterad, använd AgentX:s orkestreringsplattform för att bilda ett kooperativt agentteam—en forsknings "arbetsstyrka" med delat minne, rollbaserade ansvar och uppgiftshantering.
Tilldela tydliga ansvar till varje agent
Definiera delegeringslogik och kommunikationsvägar
Använd AgentX:s interna orkestrering—inte tredjepartsramverk—för dynamisk uppgiftsdirigering och multi-agent utförande
Med en arbetsstyrka av intelligenta agenter får ditt system hastighet, motståndskraft och förklarbarhet—särskilt i storskaliga eller realtidsforskningsmiljöer.
🧠 AgentX bygger inte bara agenter—det bygger AI-arbetsstyrkor som resonerar, delegerar och samarbetar som riktiga forskningslag.
Steg 5: Testa och validera forskningsagenten
Att testa din AI-drivna forskningsassistent är avgörande för att säkerställa att den fungerar i verkliga miljöer.
Viktiga teststrategier
Enhetstestning: Validera individuella funktioner och moduler
Integrationstestning: Säkerställ sömlösa systeminteraktioner
Funktionell testning: Simulera användarinteraktioner i forskningsmiljöer
Stresstestning: Mät prestanda under hög belastning
Grundlig validering säkerställer att ditt verktyg är robust och redo för produktion.
💭AgentX tillhandahåller en fullt transparent tankeprocess (CoT) för varje omgång och steg, så att användaren vet exakt vad agenten tänker och hur orkestreringen pågår. Det gör felsökning och QA mycket enklare.
Steg 6: Distribuera och övervaka i produktion
Efter testning, distribuera ditt AI-forskningsverktyg med prestanda och säkerhet i åtanke.
Distribueringsväsentligheter
Molnhosting: Skalbara, efterfrågestyrda datorkapaciteter
Säkerhetsprotokoll: Data kryptering, rollbaserad åtkomst
Uppoptimering: Lastbalansering, caching, failover-system
Kontinuerlig integration/distribution (CI/CD): Automatiserad testning och uppdateringar
Övervakningsmått
Genomsnittlig svarstid
Noggrannhet i resultat
Server- och resursanvändning
Felloggar och varningsfrekvens
Användarfeedback och engagemang
Med AgentX:s bästa praxis, kommer du att säkerställa en sömlös upplevelse för forskare och analytiker.
Slutsats: Automatisera forskning med en AI-agent från AgentX
Att skapa en fullt fungerande AI-forskningsagent är helt uppnåeligt med dagens verktyg, dataset och ramverk. Från att definiera dina forskningsmål till att distribuera i molnet, är varje steg i denna guide utformad för att hjälpa dig att bygga en skalbar och intelligent forskningsassistent.
💡 Börja med en fokuserad uppgift, som att automatisera klassificering av forskningsartiklar med en finjusterad transformer-modell. Utöka sedan till mer komplexa arbetsflöden—som litteraturöversikter, trendprognoser eller datavisualisering.
Redo att förbättra din forskning med AI? Bygg din egen AgentX-driven forskningsagent och revolutionera hur du arbetar med kunskap.