การประเมินตัวแทน AI: แนะนำการประเมินตัวแทน: วิธีที่น่าเชื่อถือที่สุดในการเข้าใจและปรับปรุงตัวแทน AI ของคุณ
ตัวแทน AI กำลังพัฒนาไปอย่างรวดเร็ว มีความสามารถมากขึ้น และถูกรวมเข้ากับธุรกิจอย่างลึกซึ้งมากขึ้น
แต่มีปัญหาสากลที่ทุกทีมต้องเผชิญ:
ตัวแทนของคุณไม่ได้ตอบตามที่คุณคาดหวังเสมอไป - และคุณไม่รู้ว่าทำไม
บางครั้งการใช้เหตุผลเปลี่ยนไป บางครั้งตัวแทนละเลยกฎ บางครั้งเครื่องมือไม่ได้ถูกใช้อย่างถูกต้อง และบางครั้งคำสั่งที่ละเอียดอ่อนถูกเข้าใจผิด โดยไม่มีการมองเห็นว่า อย่างไร การตัดสินใจถูกทำขึ้น การปรับปรุงตัวแทนจึงรู้สึกเหมือนการเดา
นี่คือเหตุผลที่เราสร้าง การประเมินตัวแทน - ระบบใหม่ภายใน AgentX ที่ช่วยให้คุณทดสอบ วัดผล และวิเคราะห์อย่างลึกซึ้งว่าตัวแทนของคุณทำงานอย่างไรในหลายๆ การทำงานของคำถามเดียวกัน
เป็นครั้งแรกที่คุณสามารถ มองเห็นภายในการตัดสินใจของตัวแทนของคุณ ค้นหาความไม่สอดคล้อง และเข้าใจอย่างชัดเจนว่าต้องปรับปรุงที่ไหน
ทำไมการประเมินจึงสำคัญ
โมเดล AI เป็นแบบความน่าจะเป็น
แม้จะมีคำสั่งเดียวกัน บริบทเดียวกัน และกฎเดียวกัน โมเดลอาจ:
สร้างเส้นทางการใช้เหตุผลที่แตกต่างกันเล็กน้อย
ละเว้นรายละเอียดที่จำเป็น
ตีความนโยบายผิด
ข้ามการค้นหาเครื่องมือ
ให้คำตอบที่ไม่แน่นอนแทนที่จะเป็นคำตอบที่ชัดเจน
มอบหมายงานภายในทีมอย่างไม่สม่ำเสมอ
จากภายนอก คุณจะเห็นเพียงคำตอบสุดท้าย
คุณ ไม่ เห็น:
ว่าตัวแทนปฏิบัติตามคำสั่งของคุณหรือไม่
ว่ามันใช้เครื่องมือที่ถูกต้องหรือไม่
ว่ามันใช้เหตุผลถูกต้องหรือไม่
ทำไมคำตอบหนึ่งถึงอ่อนแอกว่าอีกคำตอบหนึ่ง
ทำไมบางครั้งมันทำถูกต้อง — และบางครั้งทำผิด
การประเมินแก้ไขปัญหานี้โดยให้โครงสร้าง การให้คะแนน และความโปร่งใสแก่คุณ
การทดสอบทำงานอย่างไร
การสร้างการประเมินนั้นง่าย:
0. เลือกตัวแทนหรือทีมที่คุณต้องการประเมิน
1. คำถามทดสอบ
นี่คือคำถามในโลกจริงที่คุณต้องการตรวจสอบ
มันจำลองคำถามจากลูกค้าหรือคำขอการทำงานภายใน
ตัวอย่าง:
“ฉันสามารถคืนสินค้าขายสุดท้ายได้หรือไม่ถ้ามันไม่พอดี?”
นี่คือแกนหลักของการประเมิน
2. ผลลัพธ์ที่คาดหวัง (จำเป็น)
นี่คือส่วนที่สำคัญที่สุดของการกำหนดค่า
ที่นี่คุณกำหนดว่าตัวแทนต้องพูดหรือรวมอะไรบ้างเพื่อให้การตอบสนองถือว่าถูกต้อง
มันสามารถประกอบด้วย:
ข้อเท็จจริงสำคัญ
วลีบังคับ
ขั้นตอนการใช้เหตุผลที่จำเป็น
กฎการปฏิบัติตาม
โทนหรือคำแถลงนโยบายเฉพาะ
ตัวอย่าง:
“ต้องพูด: ไม่ สินค้าขายสุดท้ายไม่สามารถคืนหรือเปลี่ยนได้”
ผลลัพธ์ที่คาดหวังกลายเป็น เกณฑ์การให้คะแนน สำหรับการทดสอบทั้งหมด
3. ความสามารถที่คาดหวัง (ไม่บังคับแต่ทรงพลัง)
คุณสามารถบอกระบบการประเมินว่าตัวแทนควรใช้เครื่องมือ เอกสาร หรือแหล่งข้อมูลใด
ในตัวอย่างของคุณ คุณเลือก:
Documents → store_policy_kb_v1.xlsx
Built-in Functions
หมายความว่า:
ตัวแทน ควร ดึงข้อมูลจาก policy KB
ถ้ามันไม่ใช้ KB อย่างถูกต้อง การประเมินจะจับได้
นี่เหมาะสำหรับ:
ตัวแทนนโยบาย
ตัวแทนบริการลูกค้า
เวิร์กโฟลว์การปฏิบัติตาม
การสร้างแบบจำลองทางการเงิน
การใช้เหตุผลที่สนับสนุนด้วยข้อมูล
4. การตั้งค่าการประเมิน
ส่วนนี้กำหนดว่า เข้มงวด และ ลึกซึ้ง การประเมินของคุณควรเป็นอย่างไร
จำนวนการทดสอบ
คำถามเดียวกันถูกดำเนินการหลายครั้ง (แนะนำ: 5 ครั้ง)
ทำไม?
เพราะโมเดล AI ไม่ได้เป็นแบบกำหนดแน่นอน การทำงานหลายครั้งช่วยให้คุณตรวจสอบ:
ความสม่ำเสมอ
ความเสถียร
ความน่าเชื่อถือของการใช้เหตุผล
ว่าตัวแทนปฏิบัติตามกระบวนการเดียวกันทุกครั้งหรือไม่
ถ้าตัวแทนสร้างคำตอบที่ดีหนึ่งครั้งและล้มเหลวสี่ครั้ง คุณจะเห็นได้ทันที
เกณฑ์การยอมรับ
แถบเลื่อนนี้กำหนดว่า คำตอบต้องตรงกับผลลัพธ์ที่คาดหวังของคุณอย่างไร
คุณกำลังเลือกจุดระหว่าง:
ผ่อนปรน → ตัวแทนสามารถเบี่ยงเบนจากความคาดหวังของคุณได้ คำตอบไม่จำเป็นต้องสมบูรณ์แบบ
ตรงเป๊ะ → คำตอบต้องตามความคาดหวังของคุณอย่างใกล้ชิด โดยแทบไม่มีที่ว่างสำหรับการเบี่ยงเบน
มันควบคุมเพียงว่า คำตอบต้องแม่นยำเพียงใด เพื่อผ่านการประเมิน
เกณฑ์การปฏิเสธ (ไม่บังคับ)
กฎสำหรับการล้มเหลวอัตโนมัติ
ตัวอย่าง:
“คำตอบไม่ควรกล่าวถึงคู่แข่ง”
“อย่าเสนอการคืนเงินเมื่อกฎห้าม”
“คำตอบไม่ควรถามให้ผู้ใช้ให้ข้อมูลส่วนตัว”
เหล่านี้เป็นข้อจำกัดที่เข้มงวด
เกณฑ์การประเมิน (ไม่บังคับ)
คำแนะนำการให้คะแนนเพิ่มเติม มักใช้สำหรับคุณภาพหรือโทน
ตัวอย่าง:
“คำตอบควรเป็นมิตรและเป็นมืออาชีพ”
“คำตอบต้องมีคำอธิบายสั้นๆ ไม่ใช่แค่ใช่/ไม่ใช่”
“ใช้ข้อเท็จจริงจาก KB ก่อนการสมมติ”
เหล่านี้ไม่ใช่ข้อกำหนดที่เข้มงวด แต่ช่วยกำหนดว่าคะแนน AI จะให้คะแนนตัวแทนอย่างไร
5. สร้างการประเมิน
เมื่อกำหนดค่าแล้ว การคลิก สร้างการประเมิน จะเริ่มกระบวนการ:
คำถามถูกดำเนินการหลายครั้ง
แต่ละคำตอบจะได้รับคะแนน
การวิเคราะห์รายละเอียดถูกสร้างขึ้น
การมอบหมายงานและการใช้เครื่องมือถูกตรวจสอบ
ความไม่สอดคล้องถูกเปิดเผย
และคุณจะได้รับรายงานประสิทธิภาพที่สมบูรณ์
สิ่งที่คุณได้รับหลังจากรันการประเมิน
หลังจากการทำงานหลายครั้ง AgentX ให้ผลลัพธ์สองชั้น:
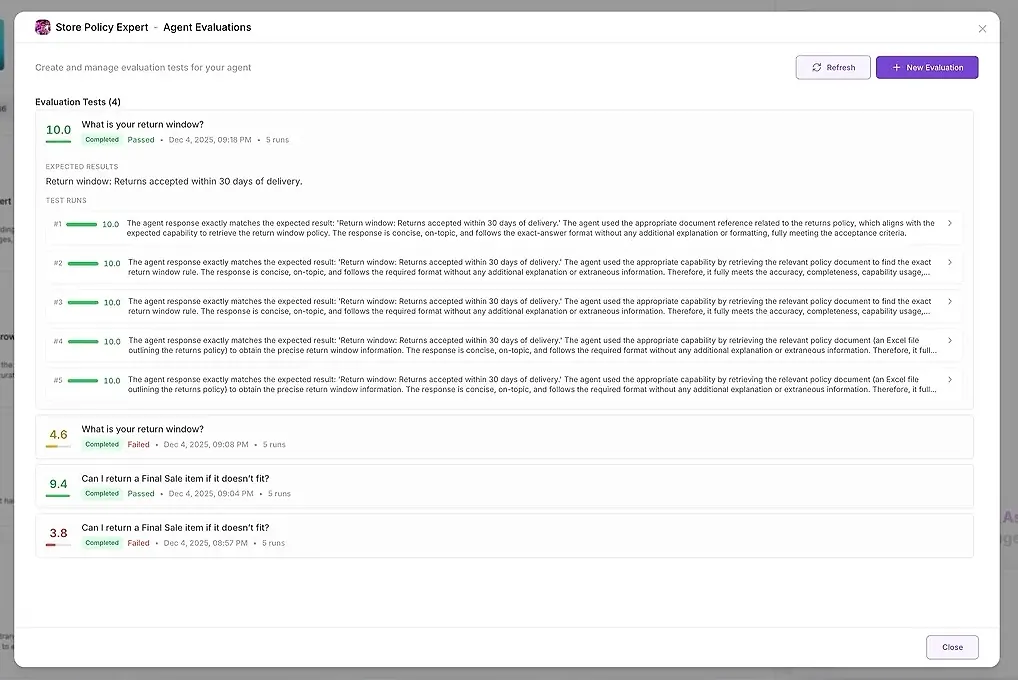
1. ผลการทดสอบ
สำหรับแต่ละการทำงาน คุณจะเห็น:
คะแนนตัวเลข
สรุปว่ามันตรงกับความคาดหวังของคุณดีเพียงใด
คำตอบเต็มรูปแบบ
เครื่องมือที่ใช้
ตัวแทนที่เข้าร่วม
ที่ที่ตัวแทนล้มเหลวหรือเบี่ยงเบน
สิ่งนี้ช่วยให้คุณเปรียบเทียบคำตอบข้างเคียงและระบุรูปแบบได้
2. การวิเคราะห์ AI เชิงลึก
นี่คือที่ที่เวทมนตร์จริงเกิดขึ้น
AgentX วิเคราะห์การทำงานทั้งหมดโดยอัตโนมัติและสร้างรายงานที่มีโครงสร้างในหลายหมวดหมู่:
• การปฏิบัติตามคำสั่ง
ตัวแทนปฏิบัติตามกฎของคุณหรือไม่?
• รูปแบบการตอบสนอง
คำตอบมีความคล้ายคลึงหรือแตกต่างกันเพียงใด?
มีค่าผิดปกติหรือไม่?
• การวิเคราะห์การใช้เหตุผล
ขั้นตอนการใช้เหตุผลถูกต้อง ครบถ้วน และสอดคล้องกับความคาดหวังหรือไม่?
• การใช้เครื่องมือ
ตัวแทนใช้เครื่องมือที่ถูกต้องหรือไม่?
มันข้ามการค้นหาหรือไม่?
มันพึ่งพาสมมติฐานแทนข้อเท็จจริงที่ตรวจสอบแล้วหรือไม่?
• คำแนะนำ
คำแนะนำที่เป็นรูปธรรมและสามารถดำเนินการได้เพื่อปรับปรุงตัวแทนของคุณ
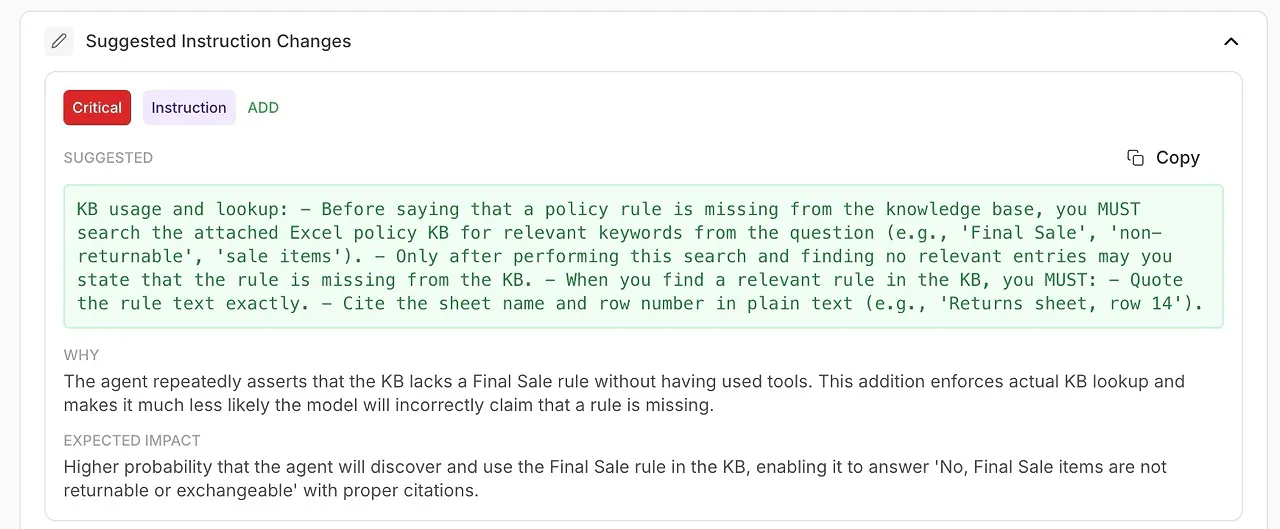
• การเปลี่ยนแปลงคำสั่งที่แนะนำ
การปรับปรุงที่สร้างโดยอัตโนมัติสำหรับคำสั่งระบบหรือการกำหนดค่าตัวแทนของคุณ
• การประเมินโดยรวม
สรุปจุดแข็ง จุดอ่อน และระดับความมั่นใจ
สิ่งนี้เปลี่ยนการดีบักจากการเดาเป็นกระบวนการทางวิทยาศาสตร์ที่สามารถทำซ้ำได้
สิ่งที่ฟีเจอร์นี้ทำให้สามารถทำได้
การประเมินนำเสนอระดับใหม่ของความโปร่งใสและความน่าเชื่อถือในการทำงานของตัวแทนของคุณ แทนที่จะเดาว่าทำไมคำตอบถึงผิดหรือไม่สอดคล้องกัน คุณมีวิธีการที่มีโครงสร้างและสามารถวัดได้ในการเข้าใจพฤติกรรม วินิจฉัยปัญหา และปรับปรุงประสิทธิภาพอย่างต่อเนื่อง
นี่คือสิ่งที่สามารถทำได้:
🔍 ตรวจสอบตัวแทนของคุณก่อนเปิดตัวให้ลูกค้า
ก่อนที่คุณจะส่งตัวแทนเข้าสู่การผลิต คุณสามารถทำการทดสอบที่สมจริงที่เปิดเผยว่ามันเข้าใจกฎ ฐานความรู้ และโทนที่ต้องการของคุณเต็มที่หรือไม่ ไม่มีเซอร์ไพรส์หลังการเปิดตัว — คุณรู้ว่าผู้ใช้จะได้รับประสบการณ์อย่างไร
🤖 ทดสอบทีมตัวแทนทั้งหมดและตรรกะการมอบหมายงาน
สำหรับการตั้งค่าหลายตัวแทน การประเมินแสดงให้เห็นว่าผู้จัดการของคุณมอบหมายงานอย่างไร ตัวแทนย่อยใดเข้าร่วม และพวกเขาปฏิบัติตามเวิร์กโฟลว์ที่คาดหวังหรือไม่ คุณสามารถตรวจจับได้อย่างรวดเร็ว:
การมอบหมายงานที่ไม่จำเป็น
การมอบหมายงานที่ขาดหายไป
ตัวแทนที่ขัดแย้งกัน
พฤติกรรมบทบาทที่ไม่ถูกต้อง
นี่เป็นสิ่งสำคัญสำหรับการทำงานเป็นทีมที่เชื่อถือได้ภายในแรงงาน AI ของคุณ
📚 ตรวจจับจุดอ่อนในฐานความรู้ของคุณ
หากการประเมินแสดงความล้มเหลวซ้ำๆ ในหัวข้อเฉพาะ คุณรู้ว่าปัญหาไม่ใช่ตัวแทน — มันคือเนื้อหาที่ขาดหายไปหรือไม่ชัดเจน การประเมินช่วยให้คุณปรับปรุง KB ของคุณในทางที่มีเป้าหมายและขับเคลื่อนด้วยข้อมูล แทนที่จะเพิ่มเนื้อหาอย่างสุ่มสี่สุ่มห้า
🚨 จับภาพหลอนและความไม่สอดคล้องกันแต่เนิ่นๆ
เพราะแต่ละคำถามถูกทดสอบหลายครั้ง การประเมินเปิดเผยปัญหาละเอียดอ่อนเช่น:
คำตอบเปลี่ยนไปอย่างไม่คาดคิด
การใช้เหตุผลเบี่ยงเบน
การคาดเดาข้อเท็จจริงแทนการใช้เครื่องมือ
ความขัดแย้งระหว่างการทำงาน
เหล่านี้เป็นปัญหาที่คุณจะไม่สามารถระบุได้ด้วยการทดสอบด้วยตนเองเพียงครั้งหรือสองครั้ง
🧠 ปรับปรุงคำสั่งระบบด้วยการปรับปรุงที่สร้างโดย AI
การวิเคราะห์ไม่ได้แสดงเพียงสิ่งที่ผิดพลาด — มันบอกคุณ วิธีแก้ไข
คุณได้รับคำแนะนำที่สามารถดำเนินการได้ซึ่งได้รับการสนับสนุนจากการวินิจฉัยของโมเดลเอง:
การปรับปรุงการใช้ถ้อยคำ
กฎที่เข้มงวดขึ้น
การใช้เครื่องมือที่บังคับ
นโยบายการมอบหมายงานที่ชัดเจนขึ้น
โทนและโครงสร้างที่แม่นยำยิ่งขึ้น
นี่คือการออกแบบคำสั่งอัตโนมัติที่ถูกรวมเข้ากับเวิร์กโฟลว์ของคุณโดยตรง
📈 วัดความก้าวหน้าทุกครั้งที่คุณอัปเดตตัวแทนของคุณ
เมื่อใดก็ตามที่คุณเปลี่ยนแปลง:
คำสั่งระบบ
รายการในฐานความรู้
เครื่องมือ
กฎการมอบหมายงาน
นโยบายการใช้เหตุผล
…คุณสามารถรันการประเมินเดียวกันอีกครั้งและเปรียบเทียบคะแนน คุณจะเห็นได้ชัดเจนว่าการอัปเดตของคุณส่งผลต่อประสิทธิภาพอย่างไร — ในทางบวกหรือทางลบ
การประเมินกลายเป็นวงจรการปรับปรุงอย่างต่อเนื่องของคุณ
✔ บังคับใช้การตอบสนองที่มีคุณภาพสูงและเป็นไปตามมาตรฐานทั่วทั้งองค์กรของคุณ
ไม่ว่าคุณจะจัดการการสนับสนุน การวิเคราะห์ทางการเงิน สถานการณ์ด้านสุขภาพ หรือเนื้อหาที่มีความอ่อนไหวทางกฎหมาย การประเมินช่วยให้คุณมั่นใจว่า:
นโยบายถูกปฏิบัติตาม
แนวทางโทนได้รับการเคารพ
ช่องว่างที่อันตรายถูกตั้งค่าสถานะ
การใช้เหตุผลที่ไม่ถูกต้องถูกเปิดเผย
มาตรฐานการปฏิบัติตามถูกปฏิบัติ
นี่เป็นสิ่งสำคัญอย่างยิ่งสำหรับ AI ที่เผชิญหน้ากับองค์กรและลูกค้า
การใช้งานและค่าใช้จ่าย
การประเมินตัวแทนใช้โมเดลเครดิตเดียวกันกับ ส่วนที่เหลือของ AgentX การทดสอบแต่ละครั้งจะใช้เครดิตในลักษณะเดียวกับข้อความตัวแทนปกติ - ไม่มีค่าธรรมเนียมเพิ่มเติม ไม่มีการกำหนดราคาที่ซ่อนอยู่ คุณรู้เสมอว่าคุณกำลังใช้จ่ายอะไร เพราะการประเมินเป็นไปตามขีดจำกัดแผนและยอดเครดิตที่มีอยู่ของคุณ
ชั้นควบคุมคุณภาพของคุณสำหรับ AI
ในซอฟต์แวร์แบบดั้งเดิม QA รับรองความน่าเชื่อถือ
ใน AgentX, การประเมินคือ QA ของคุณสำหรับตัวแทน
คุณกำหนดว่า “ดี” มีลักษณะอย่างไร
AgentX ตรวจสอบว่าตัวแทนของคุณสามารถส่งมอบได้อย่างสม่ำเสมอหรือไม่ — และแสดงให้คุณเห็นอย่างชัดเจนว่าต้องปรับปรุงอะไรเมื่อพวกเขาไม่สามารถทำได้
การประเมินเปลี่ยน AI จากกล่องดำเป็นระบบที่โปร่งใส สามารถวัดได้ และสามารถปรับปรุงได้