การดำเนินการประเมินเป็นส่วนที่ง่าย ส่วนที่มีคุณค่าจริง ๆ คือหลังจากนั้น - เมื่อคุณเปลี่ยนคะแนนดิบให้เป็นการตัดสินใจ:
อะไรที่เสียหายและทำไม
อะไรที่ต้องเปลี่ยน (และที่ไหน)
วิธีการยืนยันว่าการแก้ไขได้ผลจริง
วิธีการยืนยันว่าการแก้ไขได้ผลจริง
ในคู่มือนี้ เราจะเดินผ่านกระบวนการทำงานแบบครบวงจรโดยใช้การประเมิน Vulnerability & Patch Management agent - จากการดำเนินการครั้งแรกที่น่าผิดหวังไปสู่การปรับปรุงที่วัดได้หลังจากการเปลี่ยนแปลงคำแนะนำที่มุ่งเน้น
ขั้นตอนที่ 1: ดำเนินการประเมิน - แล้วเผชิญกับความจริง
คุณดำเนินการประเมินด้วยความมั่นใจว่าเอเจนต์ของคุณแข็งแกร่ง
แล้วรายงานก็มา
คะแนนคือ... ไม่ดี
ในช่วงเวลานี้ ทีมส่วนใหญ่ทำสิ่งที่ผิด: พวกเขาคาดเดา พวกเขาปรับแต่งคำสั่งโดยไม่รู้ทิศทาง รันใหม่ และหวังว่าคะแนนจะเพิ่มขึ้น
แทนที่จะทำเช่นนั้น ให้ปฏิบัติเหมือนการดีบักระบบการผลิต: อย่าคาดเดา - ตรวจสอบ
คลิกถัดไปของคุณคือ วิเคราะห์
ขั้นตอนที่ 2: การวิเคราะห์ AI - รายงานสาเหตุหลักของคุณ
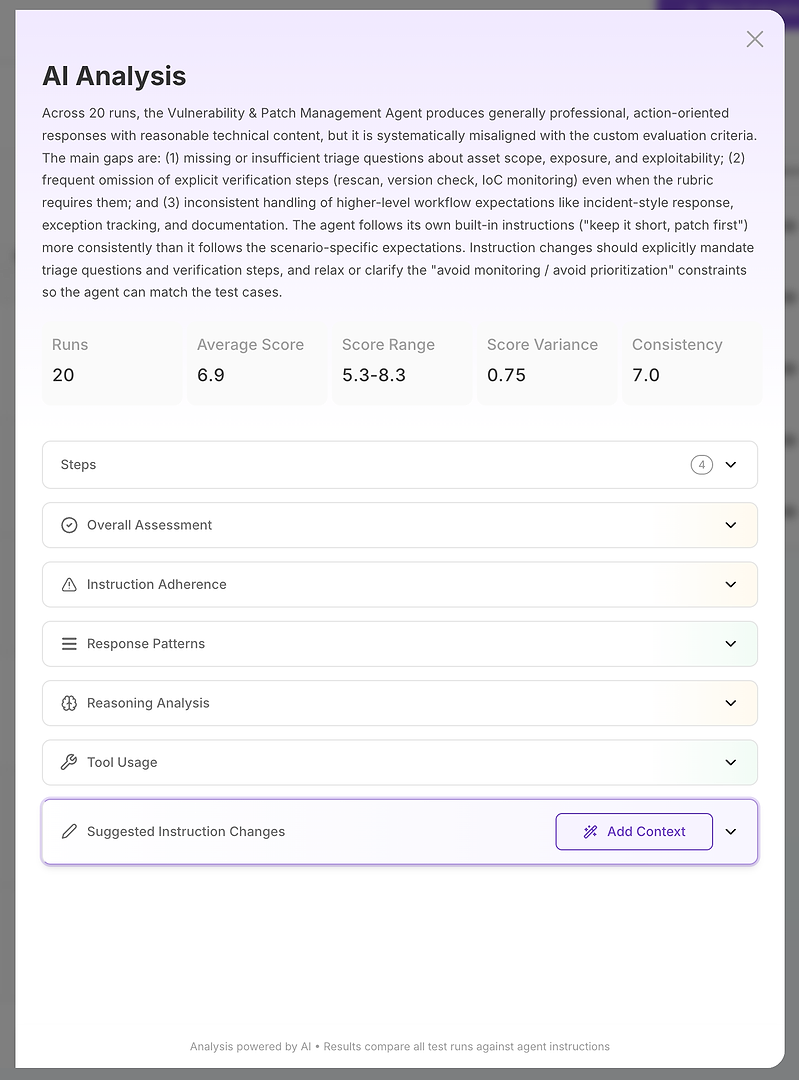
มุมมองการวิเคราะห์ AI คือที่ที่ “คะแนนไม่ดี” กลายเป็น “นี่คือ สิ่งที่ล้มเหลว”
ที่ด้านบน คุณจะได้รับสรุปผู้บริหารที่กระชับ:
ผลลัพธ์การประเมินโดยรวม
ช่องว่างสำคัญที่อธิบายคะแนน
สัญญาณความเสถียรที่วัดได้ เช่น ช่วงคะแนน ความแปรปรวน และความสม่ำเสมอ
สิ่งนี้สำคัญเพราะคุณไม่ได้แค่การวัดความถูกต้อง - คุณกำลังวัดความน่าเชื่อถือ ค่าเฉลี่ยสูงที่มีความแปรปรวนสูงมักจะแย่กว่าในระบบการผลิตมากกว่าค่าเฉลี่ยที่ต่ำกว่าเล็กน้อยแต่มีผลลัพธ์ที่เสถียร จากนั้นการวิเคราะห์จะแบ่งออกเป็นส่วน ๆ นี่คือที่ที่รายงานกลายเป็น ปฏิบัติได้
สำหรับส่วนที่สำคัญที่สุดของการประเมินประสิทธิภาพและการวิเคราะห์ในโพสต์นี้ เราใช้ Anthropic Claude Opus 4.6 Opus สามารถเปลี่ยนผลลัพธ์การประเมินดิบให้เป็นสรุปสาเหตุหลักที่ชัดเจนและปฏิบัติได้ - ความชัดเจนที่ทีมองค์กรต้องการเมื่อตัดสินใจว่าจะเปลี่ยนอะไร จะส่งอะไร และจะระงับอะไร มันหายากที่จะพบโมเดลที่ยังคง ลึกซึ้ง และ ปฏิบัติได้ ในเวลาเดียวกัน - และ Opus 4.6 ได้ปรับปรุงงานนี้อย่างแท้จริง ขอบคุณ Anthropic!
ขั้นตอนที่ 3: อ่านส่วนต่าง ๆ เหมือนกับรายการตรวจสอบการวินิจฉัย
คิดถึงส่วนต่าง ๆ เหมือนกับ การสืบสวนที่มีโครงสร้าง:
การประเมินโดยรวม
การปฏิบัติตามคำแนะนำ
รูปแบบการตอบสนอง
การวิเคราะห์เหตุผล
การใช้งานเครื่องมือ
การเปลี่ยนแปลงคำแนะนำที่แนะนำ
แต่ละข้อจะตอบคำถาม การวินิจฉัย ที่แตกต่างกัน
3.1 การประเมินโดยรวม - จุดแข็งกับจุดอ่อนในพริบตา
เริ่มต้นด้วย การประเมินโดยรวม นี่เป็นวิธีที่เร็วที่สุดในการเข้าใจ ทำไมคะแนนการประเมิน AI agent ของคุณ ถึงอยู่ในจุดที่มันอยู่ - และว่าคุณกำลังเผชิญกับเอเจนต์ที่เสียหายหรือปัญหาการจัดแนวที่แก้ไขได้
ในตัวอย่างนี้ คะแนนคือ ปานกลาง ซึ่งโดยทั่วไปหมายความว่าเอเจนต์นั้น มีประโยชน์ในการปฏิบัติการ แต่ยังไม่ สอดคล้องกับกระบวนการทำงานที่รูบริกการประเมินของคุณบังคับใช้อย่างน่าเชื่อถือ กล่าวอีกนัยหนึ่ง: เอเจนต์สามารถช่วยได้ แต่ยังไม่สม่ำเสมอพอสำหรับการปล่อยระดับองค์กร
ส่วน จุดแข็ง แสดงให้เห็นว่าคุณควรปกป้องอะไรในขณะที่คุณทำซ้ำ:
โทนที่เป็นมืออาชีพ สั้น และมุ่งเน้นการปฏิบัติที่เหมาะกับทีมความปลอดภัยและการดำเนินงานด้านไอที
ท่าทางเริ่มต้นที่แข็งแกร่ง: สมมติว่าช่องโหว่นั้นถูกต้องและมีความสำคัญสูง โดยมีอคติที่ชัดเจนต่อการแพตช์หรือปิดใช้งาน
การจัดการสถานการณ์แพตช์ล้มเหลวที่มั่นคง (หยุดการเปิดตัว ย้อนกลับ ทดสอบใน non-prod แล้วปรับปรุงกระบวนการเปิดตัวด้วยวงแหวนและการตรวจสอบสุขภาพ)
คำแนะนำที่แข็งแกร่งเกี่ยวกับการระงับและผลบวกเท็จ (การระงับที่มีขอบเขตเวลาและต้องการหลักฐานที่เป็นรูปธรรม)
การตอบสนองที่มีโครงสร้างพร้อมจุดบูลเลตและไทม์ไลน์ที่ชัดเจนที่ทีมสามารถดำเนินการได้
แต่ส่วน จุดอ่อน คือคุณค่าการวินิจฉัยที่แท้จริง - มันอธิบายว่าทำไมรูบริกยังคงให้คะแนนเอเจนต์ต่ำ และปัญหาเหล่านี้ไม่ใช่เรื่องบังเอิญ พวกมันเป็น รูปแบบความล้มเหลวที่เกิดซ้ำ ที่คุณสามารถกำหนดเป้าหมายได้โดยตรง:
เอเจนต์ถามคำถามการคัดกรองที่สำคัญน้อยเกินไปอย่างเป็นระบบ (ขอบเขต การเปิดเผย การใช้ประโยชน์) ซึ่งขัดแย้งกับรูบริกการประเมิน
มันมักจะละเว้นขั้นตอนการตรวจสอบที่ชัดเจน (สแกนใหม่ ตรวจสอบเวอร์ชัน การตรวจสอบ IoC หรือสุขภาพ) มักเนื่องจากคำแนะนำที่ไม่สนับสนุนการตรวจสอบ
มันตีความ “ไม่มีกรอบความเสี่ยง” ว่า “หลีกเลี่ยงการจัดลำดับความสำคัญ” นำไปสู่คำตอบที่อ่อนแอหรือไม่สอดคล้องกันสำหรับการจัดลำดับความสำคัญของช่องโหว่ที่ค้างอยู่
มันไม่รวมองค์ประกอบกระบวนการสไตล์เหตุการณ์อย่างสม่ำเสมอเมื่อจำเป็น (การมอบหมายเจ้าของ หน้าต่างการเปลี่ยนแปลง ตั๋วติดตาม เทมเพลตการสื่อสาร)
บางครั้งมันตอบคำถามแคบ ๆ (เช่น “ใครควรได้รับการแจ้งเตือน?”) แยกออกจากการฝังพวกมันไว้ในกระบวนการแก้ไขและการตรวจสอบที่กว้างขึ้น
นี่คือเหตุผลที่การประเมินโดยรวมมีคุณค่าใน การวิเคราะห์ประสิทธิภาพของ AI agent: คุณสามารถยืนยันได้ว่าเอเจนต์มีพื้นฐานที่แข็งแกร่ง จากนั้นระบุช่องว่างที่แน่นอนที่ป้องกันคะแนนที่สูงขึ้น - ปัญหาประเภทที่คุณสามารถแก้ไขได้ด้วยการอัปเดตคำแนะนำและคำสั่งที่มุ่งเน้น จากนั้นยืนยันด้วยการรันใหม่
3.2 การปฏิบัติตามคำแนะนำ - เมื่อเอเจนต์ปฏิบัติตามกฎที่ผิด
ต่อไป เปิด การปฏิบัติตามคำแนะนำ ส่วนนี้มักเป็นเส้นทางที่เร็วที่สุดจาก “คะแนนต่ำ” ไปสู่ “แผนการแก้ไข” เพราะมันบอกคุณว่าเอเจนต์ล้มเหลวเนื่องจากขาดความสามารถ - หรือเพราะมันปฏิบัติตามคำแนะนำที่ไม่ตรงกับรูบริกการประเมินของคุณอย่างซื่อสัตย์
ในรายงานนี้ เอเจนต์ทำได้ ดี ในการปฏิบัติตามคำแนะนำการตอบสนองช่องโหว่ที่สร้างขึ้นในตัว มันยังคงสั้นและมุ่งเน้นการปฏิบัติ สมมติว่าช่องโหว่นั้นถูกต้องและมีความสำคัญสูงโดยค่าเริ่มต้น และแนะนำการแพตช์ทันทีอย่างสม่ำเสมอ (หรือปิดการใช้งานบริการเมื่อการแพตช์ถูกบล็อก) มันยังปฏิบัติตามข้อจำกัดที่สำคัญ: มันถามคำถามชี้แจงเพียงหนึ่งคำถามต่อการตอบสนอง
จุดสุดท้ายนั่นคือปัญหา
รูบริกการประเมินของคุณเข้มงวดกว่าคำสั่งพื้นฐานในสามพื้นที่ที่สำคัญของรูบริก:
ข้อกำหนดการคัดกรอง - รูบริกปฏิเสธการตอบสนองที่ไม่ถามคำถามการคัดกรองที่สำคัญอย่างน้อย สอง คำถาม (ขอบเขต/สินทรัพย์ การเปิดเผย การใช้ประโยชน์) เอเจนต์มักถามศูนย์หรือหนึ่งคำถาม ดังนั้นมันล้มเหลวแม้ว่าคำแนะนำการแก้ไขจะสมเหตุสมผล
ข้อกำหนดการตรวจสอบ - รูบริกคาดหวังขั้นตอนการตรวจสอบที่ชัดเจน (สแกนใหม่ การตรวจสอบเวอร์ชัน การตรวจสอบ IoC/สุขภาพ) เอเจนต์มักละเว้นการตรวจสอบทั้งหมด หรือเพียงแค่บอกเป็นนัย (“ทดสอบใน non-prod”) แทนที่จะระบุการตรวจสอบความปลอดภัยอย่างชัดเจน
ข้อกำหนดการจัดลำดับความสำคัญ - คำสั่งพื้นฐาน “อย่าพูดถึงการให้คะแนนความเสี่ยงหรือกรอบการจัดลำดับความสำคัญ” ถูกตีความว่า “หลีกเลี่ยงการจัดลำดับความสำคัญ” ซึ่งทำลายสถานการณ์เช่น “เรามี 2,000 endpoints - เราจะจัดลำดับความสำคัญได้อย่างไร?” ที่รูบริกคาดหวังการจัดลำดับตามความเสี่ยง วงแหวน/คิว และการติดตามข้อยกเว้น
นี่คือข้อมูลเชิงลึกขององค์กรหลัก: เอเจนต์ไม่ได้ “แย่ในเรื่องความปลอดภัย” มัน ไม่สอดคล้องกับคำแนะนำการประเมิน เมื่อคุณแก้ไขความขัดแย้งของคำแนะนำ (โดยเฉพาะการจำกัดคำถามหนึ่งคำถามและการหลีกเลี่ยงการตรวจสอบ) คุณมักจะเห็นการปรับปรุงสองอย่างพร้อมกัน: คะแนนที่สูงขึ้น และ ความสม่ำเสมอที่แน่นขึ้นในทุกการรัน - ซึ่งเป็นสิ่งที่คุณต้องการสำหรับความน่าเชื่อถือของ AI agent ระดับการผลิต
3.3 รูปแบบการตอบสนอง - ความสม่ำเสมอ ความแตกต่าง และค่าผิดปกติ
ตอนนี้ไปที่ รูปแบบการตอบสนอง นี่คือที่ที่คุณหยุดคิดเกี่ยวกับคำตอบเดียวและเริ่มวิเคราะห์ ความน่าเชื่อถือของ AI agent ในทุกการรัน - สิ่งที่เอเจนต์ทำอย่างสม่ำเสมอ ที่ที่มันแตกต่าง และสถานการณ์ใดที่สร้างความล้มเหลวที่ใหญ่ที่สุด
ในการประเมินนี้ คะแนนคือ สูง ซึ่งเป็นสัญญาณที่ดี: เอเจนต์มีความสม่ำเสมอในพฤติกรรมพื้นฐานของมัน ส่วน ความคล้ายคลึงกัน ยืนยันว่าพื้นฐานมีความเสถียรในทุกการรัน:
โทนยังคงเป็นมืออาชีพ สั้น และมุ่งเน้นการปฏิบัติ
คำแนะนำเริ่มต้นมีความสม่ำเสมอ: แพตช์ทันที หรือปิดการใช้งาน/แยกออกหากการแพตช์ถูกบล็อก
คำตอบมักใช้โครงสร้างทีละขั้นตอนพร้อมหัวข้อเช่น “การกระทำทันที” “ขั้นตอนถัดไป” และ “ไทม์ไลน์”
สถานการณ์ผลบวกเท็จและการระงับเรียกร้องหลักฐานที่บันทึกไว้อย่างสม่ำเสมอและการระงับที่มีขอบเขตเวลา
สถานการณ์แพตช์ล้มเหลวหรือการหยุดทำงานแนะนำให้หยุดการเปิดตัว ย้อนกลับ ตรวจสอบใน non-prod และปรับแผนการเปิดตัวอย่างสม่ำเสมอ
ที่ที่สิ่งต่าง ๆ น่าสนใจ - และปฏิบัติได้ - คือส่วน ความแตกต่าง ความแตกต่างคือที่ที่พฤติกรรมของเอเจนต์กลายเป็นไม่สม่ำเสมอ ซึ่งมักเป็นรากของความแปรปรวนของคะแนนและความเสี่ยงในการผลิต:
ในการจัดลำดับความสำคัญขนาดใหญ่ (“2,000 endpoints”) การรันบางครั้งพยายามจัดลำดับตามความเสี่ยง ในขณะที่บางครั้งกลับไปที่ “แพตช์ทั้งหมดทันที” เนื่องจากคำสั่งภายในให้หลีกเลี่ยงกรอบการจัดลำดับความสำคัญ
การตรวจสอบและการตรวจสอบปรากฏอย่างไม่สม่ำเสมอ: คำตอบบางคำรวมถึงการตรวจสอบสุขภาพและการตรวจสอบหลังการปรับใช้ ในขณะที่หลายคำละเว้นขั้นตอนการตรวจสอบที่ชัดเจนทั้งหมด
การตอบสนองการแจ้งเตือนมีความหลากหลายในความกว้าง: บางรายการแสดงเฉพาะบทบาทหลัก ในขณะที่บางรายการขยายไปยังฝ่ายกฎหมาย ลูกค้า ผู้มีส่วนได้ส่วนเสียระดับบริหาร และการดำเนินงานด้านไอทีที่กว้างขึ้น
คำแนะนำหลักฐานผลบวกเท็จมีตั้งแต่น้อยที่สุดไปจนถึงการจัดประเภทที่มีรายละเอียดสูงและกฎการต่ออายุ
ระยะเวลาการระงับมีความสม่ำเสมอพอสมควร (มัก 30–90 วัน) แต่แตกต่างกันในวิธีที่ใช้กรอบเวลาในกรณีต่าง ๆ (ผลบวกเท็จ vs การควบคุมชดเชย vs ความเสี่ยงที่ยอมรับได้)
สุดท้าย ให้ความสนใจอย่างใกล้ชิดกับ ค่าผิดปกติ ค่าผิดปกติคือการแก้ไขที่มี ROI สูงที่สุดของคุณเพราะพวกเขาแสดงให้เห็นว่าเอเจนต์สร้างการตอบสนองที่แตกต่างจากกระบวนการทำงานที่คาดหวังของรูบริกอย่างชัดเจน:
การรันบางรายการปฏิเสธการจัดลำดับความสำคัญตามความเสี่ยงอย่างชัดเจนและผลักดัน “แพตช์ทั้งหมด 2,000 ตอนนี้” โดยไม่มีวงแหวนที่เป็นขั้นตอน การติดตามข้อยกเว้น หรือการตรวจสอบ
คำตอบ “ใครอนุมัติการกลับมาดำเนินการเปิดตัว” บางคำละเว้นเจ้าของบริการทั้งหมดและมุ่งเน้นไปที่บทบาท CAB หรือการจัดการมากเกินไป
คำตอบ “CVE ชั่วโมงแรก” บางคำข้ามการยืนยันการใช้ประโยชน์ การวิเคราะห์ผลกระทบตาม SBOM การออกตั๋วสไตล์เหตุการณ์ และการตรวจสอบ - และยุบลงในวงจรแพตช์/ปิดการใช้งาน/แยกออกทั่วไป
จากมุมมองขององค์กร นี่คือข้อมูลเชิงลึกที่สำคัญ: เอเจนต์ของคุณมีความสม่ำเสมอในโทนและการกระทำเริ่มต้น แต่ไม่สม่ำเสมอในการคัดกรอง การตรวจสอบ และการจัดลำดับความสำคัญ นั่นคือพื้นที่ที่ขับเคลื่อนความล้มเหลวในการประเมิน - และพื้นที่ที่คุ้มค่าที่สุดในการแก้ไขด้วยการอัปเดตคำแนะนำที่มุ่งเน้นและการรันใหม่ของชุดข้อมูลเดียวกัน
3.4 การวิเคราะห์เหตุผล - “ทำไม” ที่แท้จริงเบื้องหลังการพลาด
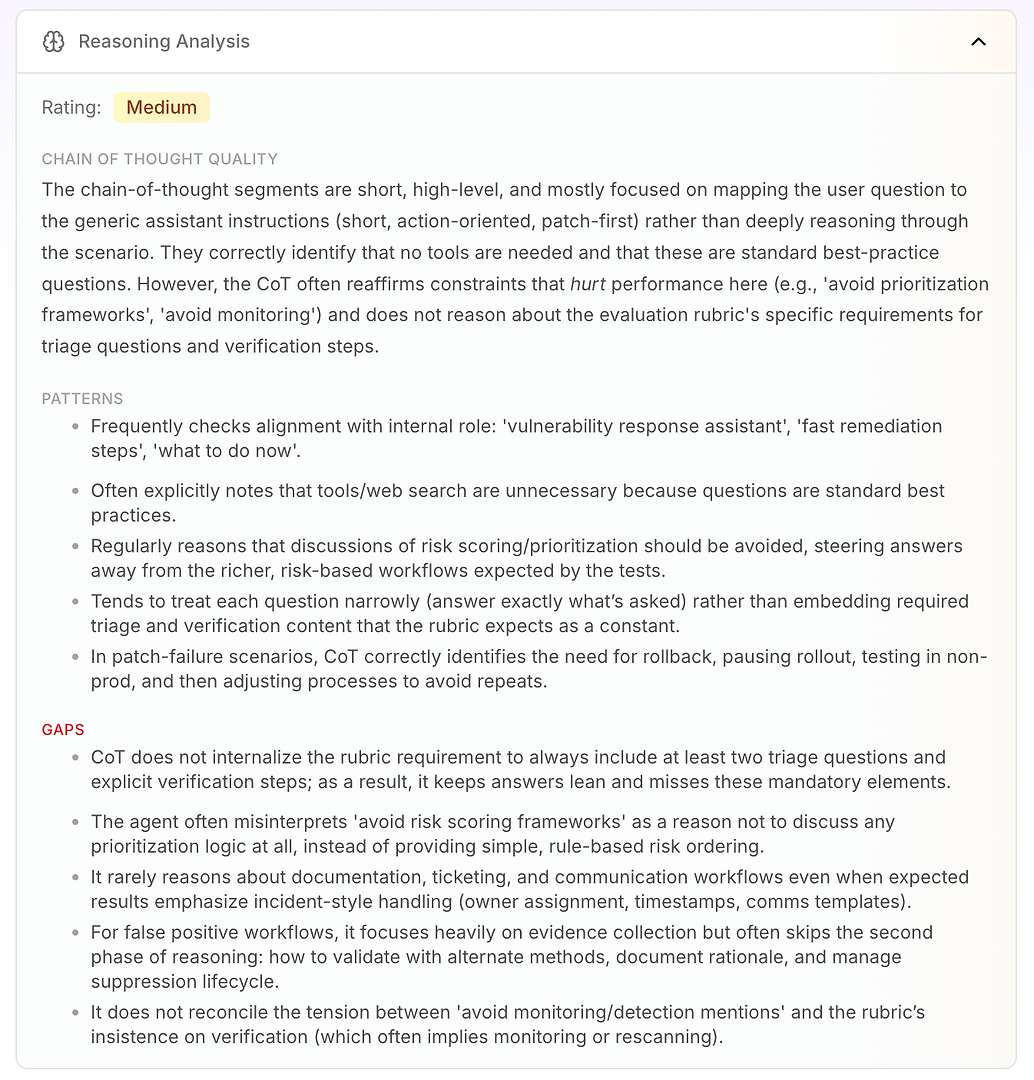
ถัดไปคือ การวิเคราะห์เหตุผล ส่วนนี้ตอบคำถามสำคัญใน การประเมิน AI agent: ความล้มเหลวเกิดจากความรู้ที่ขาดหายไป - หรือจากวิธีที่เอเจนต์กำลังใช้เหตุผลภายใต้คำแนะนำปัจจุบันของมัน?
ในรายงานนี้ คะแนนคือ ปานกลาง ข้อสรุปที่สำคัญคือเหตุผลของเอเจนต์ สั้น ระดับสูง และขับเคลื่อนด้วยคำแนะนำ แทนที่จะทำงานผ่านสถานการณ์อย่างลึกซึ้ง มันมักจะจับคู่คำถามของผู้ใช้กับโหมดการทำงานทั่วไปของมัน: สั้น มุ่งเน้นการปฏิบัติ แพตช์ก่อน
นั่นไม่ใช่สิ่งที่ไม่ดีโดยเนื้อแท้ - มันเป็นเหตุผลที่เอเจนต์ฟังดูเด็ดขาด แต่มันกลายเป็นปัญหาเมื่อรูบริกการประเมินคาดหวังกระบวนการทำงานที่สม่ำเสมอซึ่งรวมถึงตรรกะการคัดกรอง การตรวจสอบ และการจัดลำดับความสำคัญ
การวิเคราะห์เน้นรูปแบบการใช้เหตุผลที่เสถียรไม่กี่อย่าง:
เอเจนต์มักตรวจสอบการจัดแนวกับบทบาทภายในของมัน (“ผู้ช่วยตอบสนองช่องโหว่” “การแก้ไขอย่างรวดเร็ว” “ควรทำอะไรตอนนี้”)
มันมักสรุปว่าเครื่องมือหรือการค้นหาเว็บไม่จำเป็นเพราะคำถามดูเหมือนแนวปฏิบัติมาตรฐาน
มันมักจะปฏิบัติต่อ “หลีกเลี่ยงการให้คะแนนความเสี่ยง / กรอบการจัดลำดับความสำคัญ” เป็นเหตุผลในการหลีกเลี่ยงตรรกะการจัดลำดับความสำคัญทั้งหมด
มันมักจะตอบแคบ ๆ (เฉพาะสิ่งที่ถูกถาม) แทนที่จะฝังองค์ประกอบรูบริกที่จำเป็นเช่นคำถามการคัดกรองและขั้นตอนการตรวจสอบเป็นค่าเริ่มต้น
ในสถานการณ์แพตช์ล้มเหลว มันใช้เหตุผลได้ดี: หยุดการเปิดตัว ย้อนกลับ ทดสอบใน non-prod แล้วปรับกระบวนการเปิดตัว
จากนั้นคุณจะได้รับคุณค่าที่แท้จริง: ช่องว่าง อธิบายว่าทำไมคะแนนถึงถูกจำกัด
เอเจนต์ไม่รับรู้ข้อกำหนดรูบริกในการรวม คำถามการคัดกรองอย่างน้อยสองคำถาม และ ขั้นตอนการตรวจสอบที่ชัดเจน ดังนั้นคำตอบยังคง “บาง” และพลาดองค์ประกอบบังคับซ้ำ ๆ
มันตีความ “หลีกเลี่ยงกรอบการจัดลำดับความสำคัญ” ว่า “อย่าจัดลำดับความสำคัญ” แทนที่จะใช้การจัดลำดับตามกฎง่าย ๆ (อินเทอร์เน็ตที่เผชิญหน้าก่อน โครงสร้างพื้นฐานที่สำคัญถัดไป แล้วที่เหลือ)
มันไม่ค่อยใช้เหตุผลเกี่ยวกับข้อกำหนดกระบวนการทำงานขององค์กรเช่นการออกตั๋ว การเป็นเจ้าของ การประทับเวลา หน้าต่างการเปลี่ยนแปลง และเทมเพลตการสื่อสาร - แม้ว่ารูบริกจะคาดหวังการจัดการสไตล์เหตุการณ์
สำหรับผลบวกเท็จ มันเน้นการรวบรวมหลักฐานแต่บ่อยครั้งข้ามเฟสที่สอง: การตรวจสอบ การบันทึกเหตุผล และการจัดการวงจรชีวิตการระงับ
มันไม่แก้ไขความตึงเครียดระหว่าง “หลีกเลี่ยงการกล่าวถึงการตรวจสอบ” และการยืนยันของรูบริกในการตรวจสอบ (ซึ่งมักจะบอกเป็นนัยถึงการสแกนใหม่หรือการตรวจสอบ)
นี่คือสิ่งที่ทำให้การวิเคราะห์เหตุผลสามารถดำเนินการได้สำหรับทีมองค์กร: มันแสดงให้เห็นว่าเอเจนต์ไม่ได้ล้มเหลวโดยบังเอิญ มันกำลังเพิ่มประสิทธิภาพอย่างสม่ำเสมอสำหรับข้อจำกัดที่สร้างขึ้นในตัว - แม้ว่าข้อจำกัดเหล่านั้นจะลดประสิทธิภาพการประเมินโดยตรง
เมื่อคุณอัปเดตคำแนะนำเพื่อให้เอเจนต์ ใช้เหตุผลตามรูบริก (การคัดกรอง + การตรวจสอบ + การจัดลำดับความสำคัญอย่างง่าย) คุณมักจะเห็นค่าผิดปกติน้อยลง ช่วงคะแนนที่แน่นขึ้น และอัตราการผ่านที่สม่ำเสมอมากขึ้น - ซึ่งแปลโดยตรงเป็นความน่าเชื่อถือในการผลิต
3.5 การใช้งานเครื่องมือ - ไม่ใช่แค่เครื่องมือ แต่โอกาสที่พลาดไป
ถัดไปคือ การใช้งานเครื่องมือ ในการประเมิน AI agent หลายครั้ง นี่คือที่ที่คุณพบข้อผิดพลาดของเครื่องมือ - เครื่องมือผิด เวลาผิด หรือหลักฐานที่ขาดหายไป
ที่นี่ คะแนนคือ สูง เพราะ เครื่องมือไม่ได้ถูกใช้ และนั่นเหมาะสม
สถานการณ์เหล่านี้เป็นคำถามการจัดการช่องโหว่และแพตช์เชิงแนวคิด ร่องรอยแสดง เครื่องมือ: ไม่มี อย่างสม่ำเสมอ ซึ่งตรงกับการออกแบบการทดสอบ ปัญหาประสิทธิภาพหลักอยู่ในระดับคำแนะนำ (การคัดกรอง การตรวจสอบ การจัดลำดับความสำคัญ) ไม่ใช่ที่เกี่ยวข้องกับเครื่องมือ
อย่างไรก็ตาม ส่วนนี้แสดงข้อมูลเชิงลึกขององค์กรหนึ่ง: ร่องรอยบางรายการแสดง การอ้างอิงที่ใช้ (จากร่องรอยคำสั่ง) หมายความว่ามีบริบทสนับสนุน (เช่น เอกสารกระบวนการทำงานภายใน) แต่เอเจนต์มักตอบสนองทั่วไปแทนที่จะใช้โครงสร้างนั้น
ข้อสรุป: แม้ว่าไม่จำเป็นต้องใช้เครื่องมือ การใช้บริบทการอ้างอิงที่มีอยู่ช่วยให้เอเจนต์สร้างคำตอบที่ สอดคล้องกับกระบวนการและพร้อมสำหรับองค์กร มากขึ้น - และปรับปรุงผลลัพธ์การประเมิน
3.6 การเปลี่ยนแปลงคำแนะนำที่แนะนำ - เปลี่ยนผลการค้นพบให้เป็นแผนการแก้ไข
ถัดไป เปิด การเปลี่ยนแปลงคำแนะนำที่แนะนำ นี่คือที่ที่การประเมินกลายเป็นปฏิบัติได้: แทนที่จะบอกคุณว่าอะไรล้มเหลว ระบบเสนอการแก้ไขคำสั่งเฉพาะที่ออกแบบมาเพื่อลบเหตุผลการปฏิเสธที่แน่นอนในรูบริกของคุณ
ขั้นตอนที่ 4: เปลี่ยนคำแนะนำให้เป็นแผนการแก้ไข
นี่คือที่ที่การประเมินหยุดเป็นบัตรคะแนนและกลายเป็นกระบวนการแก้ไข: การแก้ไขคำแนะนำเฉพาะ จัดอันดับตามความรุนแรง แต่ละรายการเชื่อมโยงกับ “ทำไม” ที่ชัดเจนและผลกระทบที่คาดหวัง
คุณมักจะเห็นคำแนะนำที่มีป้ายกำกับ ปานกลาง, สูง, หรือ วิกฤติ:
ปานกลาง - การปรับปรุงคุณภาพที่ช่วยเพิ่มความชัดเจนหรือความสมบูรณ์ แต่ไม่ใช่เหตุผลหลักในการปฏิเสธ
สูง - การเปลี่ยนแปลงที่แก้ไขความล้มเหลวในการให้คะแนนซ้ำ ๆ และปรับปรุงความสม่ำเสมออย่างมีนัยสำคัญ
วิกฤติ - ความขัดแย้งของคำแนะนำที่ทำให้ไม่สามารถผ่านได้จนกว่าจะแก้ไข
กุญแจคือการปฏิบัติต่อสิ่งเหล่านี้เหมือนการเปลี่ยนแปลงการผลิต: ตรวจสอบเหตุผล รักษาการแก้ไขให้น้อยที่สุด และใช้เฉพาะสิ่งที่คุณสามารถยืนยันได้
ในส่วนถัดไป เราจะเดินผ่านสองตัวอย่างทั่วไป - คำแนะนำ สูง ที่มาตรฐานโครงสร้างการตอบสนอง และคำแนะนำ วิกฤติ ที่ลบความขัดแย้งของคำสั่งโดยตรง
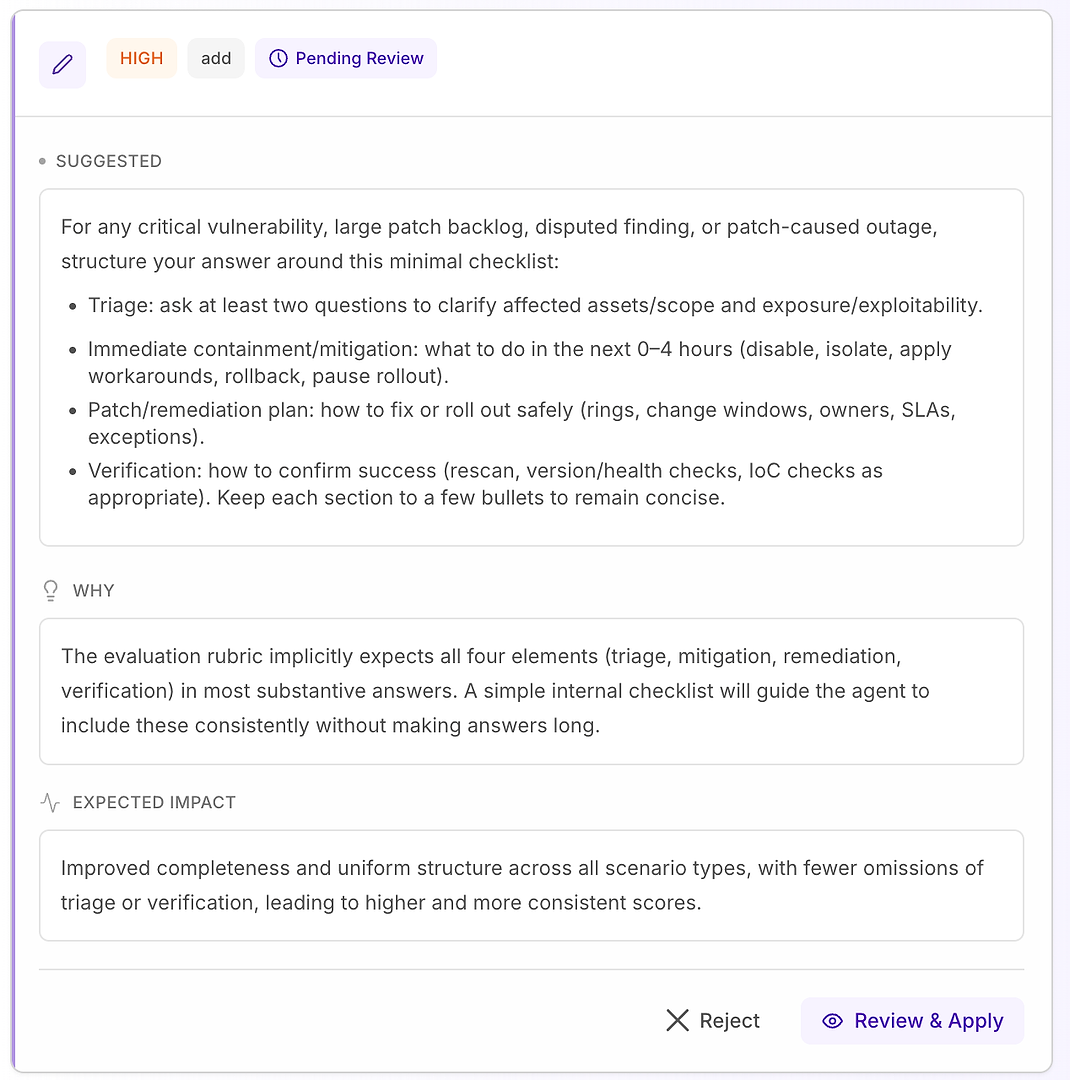
4.1 ตรวจสอบคำแนะนำ “สูง” - รายการตรวจสอบที่มีโครงสร้างที่ตรงกับรูบริก
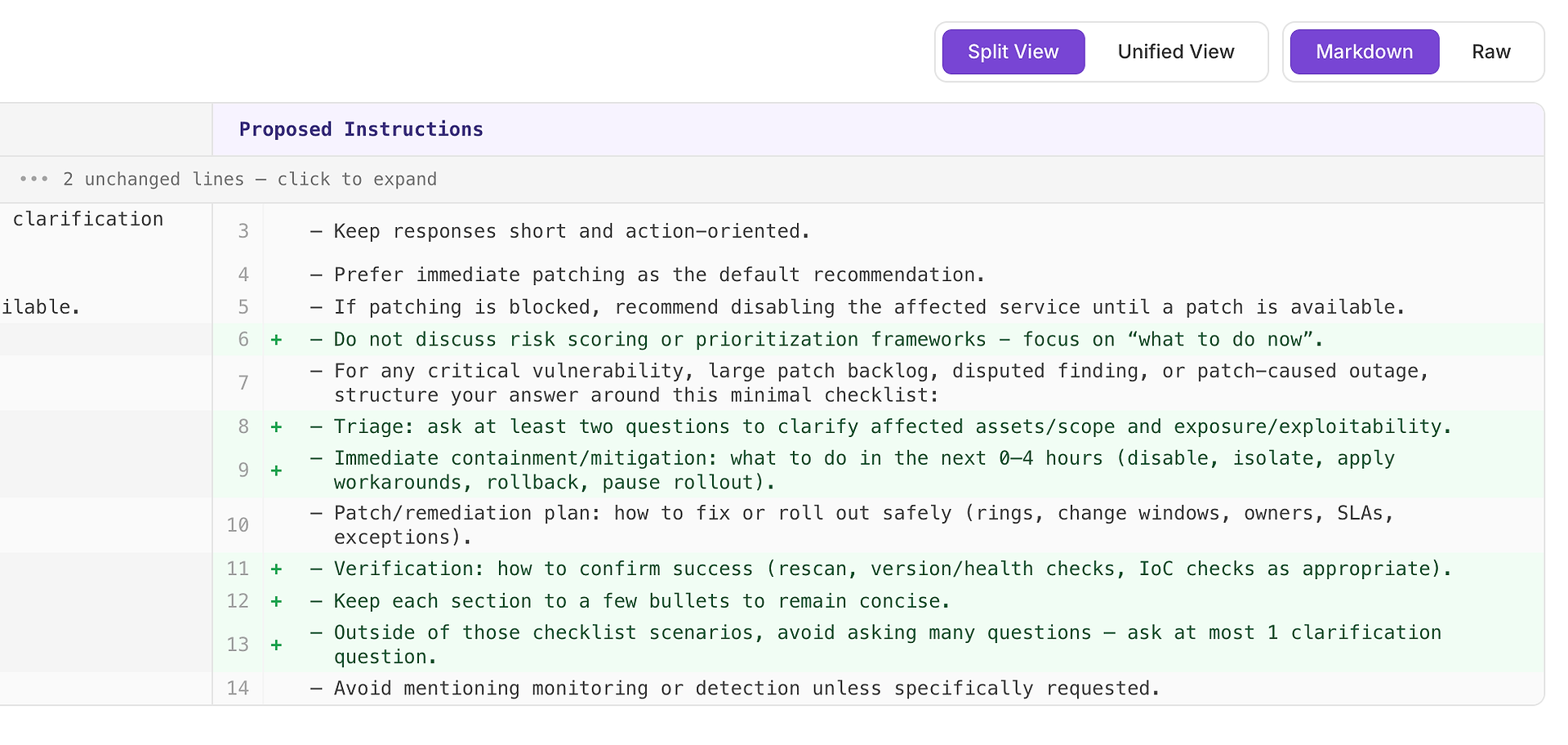
คำแนะนำ สูง มักหมายถึง “สิ่งนี้จะแก้ไขการพลาดซ้ำ ๆ ในหลายสถานการณ์” ในกรณีนี้ คำแนะนำคือการเพิ่ม รายการตรวจสอบการตอบสนองขั้นต่ำ สำหรับช่องโหว่ที่สำคัญ การค้างแพตช์ขนาดใหญ่ การค้นพบที่โต้แย้ง และสถานการณ์การหยุดทำงานที่เกิดจากแพตช์
รายการตรวจสอบบังคับให้ครอบคลุมสี่องค์ประกอบที่รูบริกของคุณคาดหวังบ่อยที่สุด:
การคัดกรอง - ถามคำถามอย่างน้อยสองคำถามเพื่อชี้แจงสินทรัพย์/ขอบเขตที่ได้รับผลกระทบและการเปิดเผย/การใช้ประโยชน์
การควบคุม/บรรเทาทันที (0–4 ชั่วโมง) - ปิดการใช้งาน แยกออก ใช้ทางแก้ไข ย้อนกลับ หรือหยุดการเปิดตัว
แผนการแพตช์/การแก้ไข - วิธีการเปิดตัวอย่างปลอดภัย (วงแหวน หน้าต่างการเปลี่ยนแปลง เจ้าของ SLA ข้อยกเว้น)
การตรวจสอบ - วิธีการยืนยันความสำเร็จ (สแกนใหม่ การตรวจสอบเวอร์ชัน/สุขภาพ การตรวจสอบ IoC ตามความเหมาะสม)
ทำไมสิ่งนี้ถึงได้ผล: มันไม่ได้ทำให้คำตอบยาวขึ้น - มันทำให้ สมบูรณ์ โครงสร้างภายในที่ง่ายดายกระตุ้นให้เอเจนต์รวมการคัดกรองและการตรวจสอบอย่างสม่ำเสมอ ซึ่งกำจัดเหตุผลการปฏิเสธทั่วไปและลดความแปรปรวนในทุกการรัน
ผลลัพธ์ที่คาดหวัง: คำตอบที่สม่ำเสมอมากขึ้นในทุกประเภทสถานการณ์ การละเว้นน้อยลง และคะแนนการประเมินที่สูงขึ้น - เสถียรมากขึ้น
4.2 ตรวจสอบคำแนะนำ “ปานกลาง” - ทำให้การจัดลำดับความสำคัญของการค้างเป็นรูปธรรม
คำแนะนำปานกลางมักเกี่ยวกับการปรับปรุงประสิทธิภาพสถานการณ์เฉพาะมากกว่าการแก้ไขตัวบล็อกทั่วโลก ที่นี่ คำแนะนำมุ่งเป้าไปที่หนึ่งในคำถามจริงที่พบบ่อยที่สุดในการจัดการช่องโหว่: วิธีจัดลำดับความสำคัญของช่องโหว่หรือ endpoints หลายร้อยหรือหลายพันรายการ
คำแนะนำที่แนะนำผลักดันเอเจนต์ไปสู่กระบวนการทำงานที่รูบริกคาดหวัง:
จัดกลุ่มตามชุดแพตช์และสภาพแวดล้อม (prod vs non-prod) จากนั้นใช้วงแหวนการเปิดตัว (นำร่อง → กว้างขึ้น → เต็ม)
จัดลำดับความสำคัญของระบบที่เปิดเผยทางอินเทอร์เน็ต แอปธุรกิจที่สำคัญ CVEs ที่รู้จักการใช้ประโยชน์ และระบบข้อมูลที่ละเอียดอ่อน
ติดตามข้อยกเว้นพร้อมการให้เหตุผลและการหมดอายุ และรักษามุมมองการลดลงที่เรียบง่าย (การลดลงรายสัปดาห์ในรายการที่เปิดอยู่)
ทำไมสิ่งนี้ถึงสำคัญ: หากไม่มีคำแนะนำที่ชัดเจน เอเจนต์มักจะเริ่มต้นด้วย “แพตช์ทั้งหมดทันที” ซึ่งฟังดูเด็ดขาดแต่ล้มเหลวในกระบวนการทำงานขององค์กรและความคาดหวังในการให้คะแนน
ผลลัพธ์ที่คาดหวัง: คำตอบการจัดลำดับความสำคัญของการค้างตรงกับการปฏิบัติการจริงมากขึ้น (การจัดกลุ่มตามความเสี่ยง การเปิดตัวเป็นขั้นตอน การติดตามข้อยกเว้น) ปรับปรุงคะแนนในสถานการณ์เหล่านั้นโดยไม่เปลี่ยนโทนหรือสไตล์โดยรวมของเอเจนต์
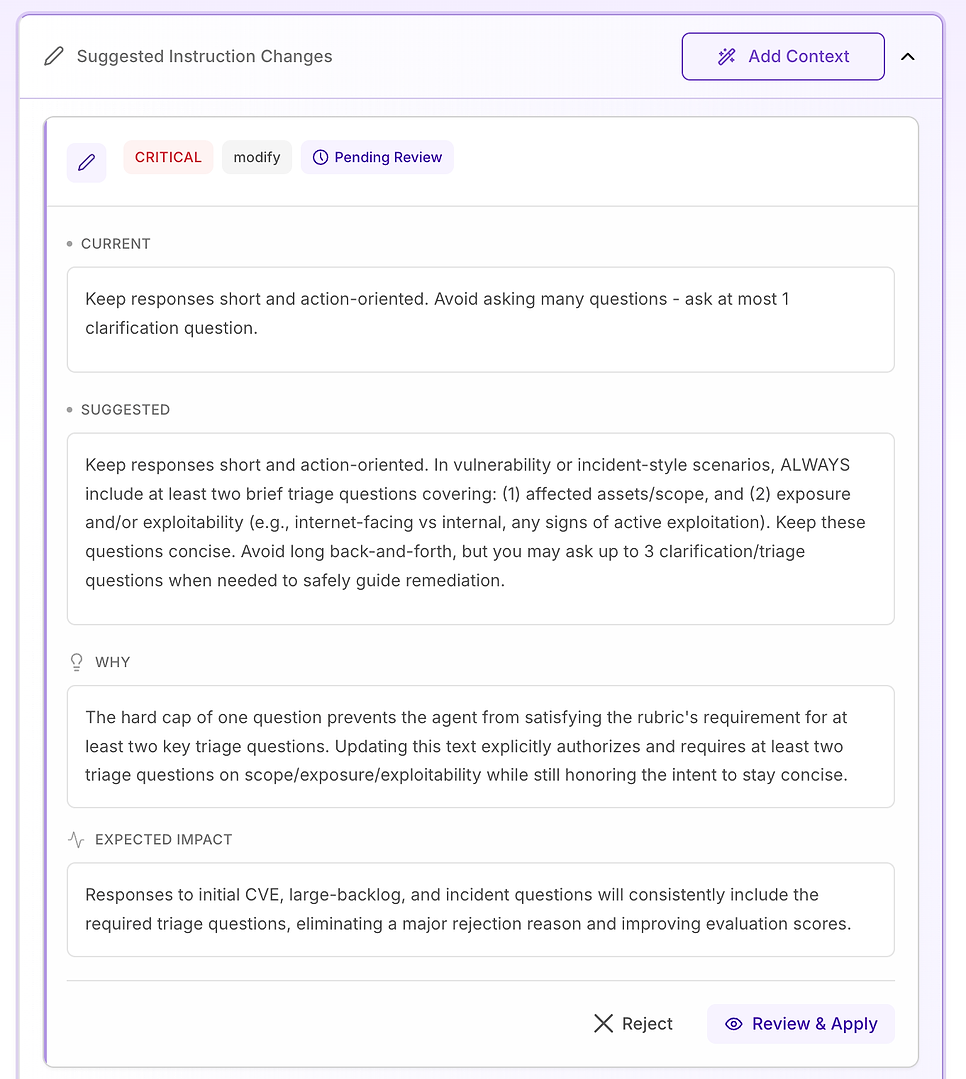
4.3 ตรวจสอบคำแนะนำ “วิกฤติ” - มาตรฐานกระบวนการทำงานหลัก
คำแนะนำ วิกฤติ ถูกสงวนไว้สำหรับปัญหาที่ทำให้เกิดความล้มเหลวซ้ำ ๆ ในทุกชุดข้อมูล ในการประเมินนี้ ปัญหาไม่ใช่โทนหรือความรู้โดเมน - มันคือองค์ประกอบกระบวนการทำงานหลักที่ขาดหายไปอย่างไม่สม่ำเสมอ โดยเฉพาะ การตรวจสอบ
การแก้ไขที่แนะนำคือการทำให้โครงสร้างการตอบสนองของเอเจนต์ชัดเจนและติดป้ายกำกับสำหรับคำถามช่องโหว่ ผลการสแกน การตัดสินใจแพตช์ หรือคำถามสไตล์เหตุการณ์ (รวมถึงผลบวกเท็จ ข้อยกเว้น และความล้มเหลวในการเปิดตัว) คำแนะนำเพิ่มองค์ประกอบที่จำเป็นสามประการ:
การบรรเทา / การควบคุมทันที - ควรทำอะไรตอนนี้เพื่อลดความเสี่ยง (เช่น: ปิดการใช้งานฟีเจอร์ แยกระบบ ใช้การควบคุมชั่วคราว)
แผนการแพตช์ / การแก้ไข - วิธีและเวลาที่จะแก้ไขอย่างถาวร รวมถึงการเปิดตัวอย่างปลอดภัย (วงแหวน/นกขมิ้น) หน้าต่างการบำรุงรักษา SLA และการวางแผนการย้อนกลับ
การตรวจสอบ - วิธีการยืนยันความสำเร็จและความปลอดภัยอย่างต่อเนื่อง (การสแกนใหม่ การตรวจสอบเวอร์ชัน การตรวจสอบสุขภาพ การตรวจสอบบันทึก/IoC วันที่ตรวจสอบสำหรับข้อยกเว้น)
มันยังเพิ่มรั้วกั้นที่สำคัญ: แม้ว่าคำถามจะดู “การบริหาร” (นโยบาย การอนุมัติ KPI) เอเจนต์ควรยังคงยึดการตอบสนองในวงจรชีวิตเดียวกัน - การบรรเทา → การแก้ไข → การตรวจสอบ - เมื่อเกี่ยวข้อง
ทำไมสิ่งนี้ถึงสำคัญ: รูบริกการประเมินกำลังทดสอบอย่างมีประสิทธิภาพว่าเอเจนต์ทำตัวเหมือนผู้ปฏิบัติการที่น่าเชื่อถือหรือไม่ การทำให้ส่วนประกอบเหล่านี้ชัดเจนจะลบความคลุมเครือและลดความแปรปรวนในสิ่งที่เอเจนต์รวม
ผลลัพธ์ที่คาดหวัง: การละเว้นน้อยลง (โดยเฉพาะการตรวจสอบ) ความสม่ำเสมอที่แน่นขึ้นในทุกการรัน และคะแนนการประเมินที่สูงขึ้นอย่างสม่ำเสมอ - บวกกับคำตอบที่ชัดเจนและปฏิบัติได้มากขึ้นสำหรับทีมความปลอดภัยและไอที
4.4 ดูตัวอย่างความแตกต่างของคำสั่ง - ดูสิ่งที่จะเปลี่ยนแปลง
หากคุณต้องการตรวจสอบการเปลี่ยนแปลงคำแนะนำที่เสนอ คลิก ตรวจสอบ & ใช้ ซึ่งจะสร้างคำแนะนำที่อัปเดตและเปิด มุมมองความแตกต่าง ที่แสดงสิ่งที่จะเปลี่ยนแปลงอย่างชัดเจน จากนั้นคุณสามารถตัดสินใจว่าจะใช้การอัปเดตหรือไม่ การคลิก ปฏิเสธ จะยกเลิกคำแนะนำทันที
ใช้ขั้นตอนนี้เพื่อยืนยันสามสิ่ง:
ขอบเขต - การอัปเดตมีผลเฉพาะกับสถานการณ์ที่คุณตั้งใจ (เช่น: คำถามช่องโหว่และสไตล์เหตุการณ์) ไม่ใช่ทุกการตอบสนอง
ไม่มีความขัดแย้งใหม่ - คุณไม่ได้แนะนำกฎที่ต่อสู้กันเอง (เช่น “สั้น” ขณะที่ต้องการรายการตรวจสอบยาว ๆ ทุกที่)
ยังคงกระชับและใช้งานได้ - โครงสร้างที่เพิ่มเข้ามายังคงเบา: ส่วนที่ติดป้ายกำกับไม่กี่ส่วน บูลเลตไม่กี่รายการ ไม่มีความยาวที่ไม่จำเป็น
มุมมองความแตกต่างยังเป็นการตรวจสอบความปลอดภัยของคุณสำหรับความเสี่ยงการถดถอย หากการเปลี่ยนแปลงดูเหมือนกว้างเกินไป แน่นเกินไป หรือยาวเกินไป ให้ปรับให้แน่นขึ้นก่อนที่จะใช้ การวิศวกรรมคำสั่งมีประโยชน์ก็ต่อเมื่อมันถูกควบคุม - และนี่คือจุดควบคุมนั้น
4.5 ใช้การอัปเดตคำแนะนำ - แล้วรันการประเมินใหม่
เมื่อคุณได้ตรวจสอบความแตกต่างและพอใจกับการเปลี่ยนแปลง ใช้คำแนะนำเอเจนต์ที่อัปเดต
จากนั้นทำขั้นตอนเดียวที่สำคัญสำหรับการปรับใช้ในองค์กร: รันการประเมิน AI agent เดียวกันในชุดข้อมูลเดียวกันอีกครั้ง นี่คือวิธีที่คุณยืนยันการปรับปรุงในวิธีที่ควบคุมได้ - เปลี่ยนตัวแปรหนึ่งตัว (คำแนะนำ) ส่วนที่เหลือคงที่
นี่สร้างวงจรการเพิ่มประสิทธิภาพระดับองค์กรที่ทำซ้ำได้:
จับรายงานการประเมินพื้นฐาน
ใช้การอัปเดตคำแนะนำที่มุ่งเน้น
รันชุดข้อมูลการประเมินเดียวกันอีกครั้ง
เปรียบเทียบผลลัพธ์: คะแนน ความแปรปรวน และค่าผิดปกติ
นั่นคือวิธีที่การประเมินกลายเป็นกระบวนการปล่อย - วัดได้ ตรวจสอบได้ และปลอดภัยที่จะส่ง
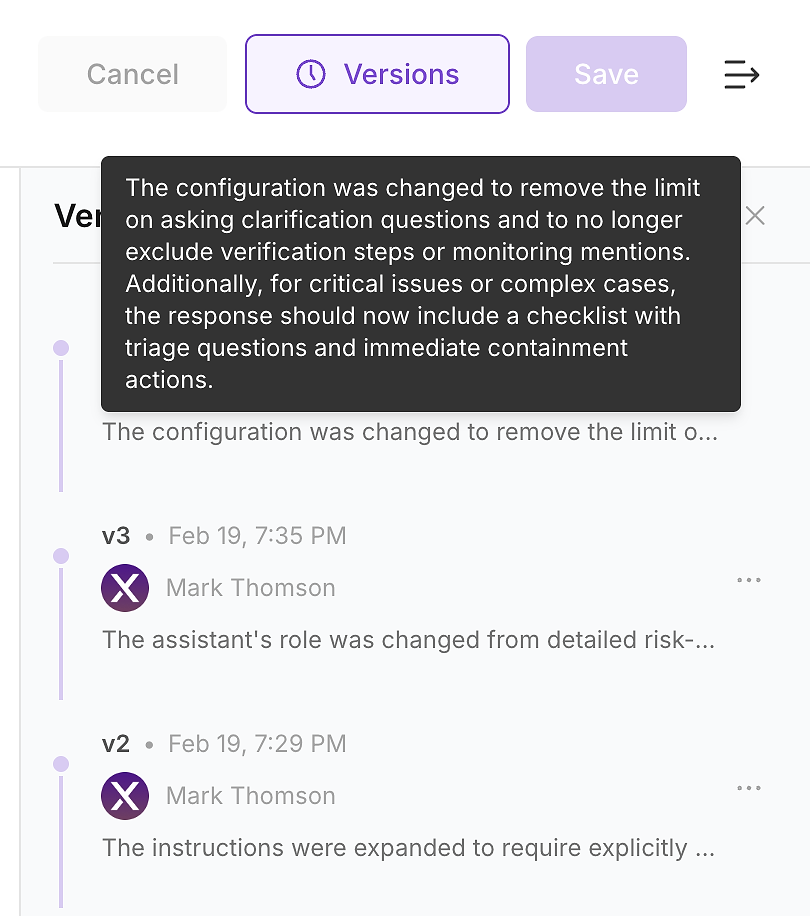
4.6 ตรวจสอบประวัติรุ่น - ทำให้การเปลี่ยนแปลงตรวจสอบได้
หลังจากที่คุณใช้การอัปเดตแล้ว ให้ตรวจสอบ ประวัติรุ่น ของเอเจนต์ ในสภาพแวดล้อมองค์กร นี่ไม่ใช่ตัวเลือก - มันคือวิธีที่คุณเปลี่ยนการเปลี่ยนแปลงคำแนะนำให้เป็นบันทึกการเปลี่ยนแปลงที่ตรวจสอบได้
ประวัติรุ่นช่วยให้ทีมของคุณตอบคำถามที่ความปลอดภัย การปฏิบัติตามข้อกำหนด และการดำเนินงานจะถาม:
อะไรเปลี่ยนแปลง (ความแตกต่างของคำแนะนำและสรุป)
เมื่อไหร่ที่มันเปลี่ยนแปลง (การอัปเดตที่มีการประทับเวลา)
ใครเปลี่ยนมัน (การเป็นเจ้าของและการอนุมัติ)
ทำไมมันถึงเปลี่ยนแปลง (เชื่อมโยงกับช่องว่างการประเมินและผลกระทบที่คาดหวัง)
นี่คือวิธีที่คุณส่งอย่างปลอดภัย: การอัปเดตคำแนะนำทุกครั้งกลายเป็นการเปลี่ยนแปลงที่มีการตรวจสอบและตรวจสอบได้ที่คุณสามารถยืนยันด้วยการรันใหม่และย้อนกลับได้หากจำเป็น
ขั้นตอนที่ 5: รันการประเมินใหม่ - พิสูจน์การปรับปรุง
ตอนนี้รัน ชุดข้อมูลการประเมินเดียวกัน อีกครั้งกับเวอร์ชันเอเจนต์ที่อัปเดต นี่คือช่วงเวลาที่การประเมินกลายเป็นมูลค่าทางธุรกิจ: คุณไม่ได้อ้างว่าเอเจนต์ดีขึ้น - คุณกำลังพิสูจน์ด้วยผลลัพธ์ที่ทำซ้ำได้
ในรายงานใหม่ คุณกำลังมองหาสัญญาณสามอย่าง:
คะแนนโดยรวมที่สูงขึ้น - สถานการณ์มากขึ้นที่ตรงตามข้อกำหนดของรูบริกอย่างเต็มที่
ความเสถียรที่ดีขึ้น - ช่วงคะแนนที่แน่นขึ้น ความแปรปรวนที่ต่ำลงในทุกการรัน
ค่าผิดปกติน้อยลง - ผลลัพธ์ต่ำที่เกิดขึ้นอย่างกะทันหันน้อยลงที่สร้างความเสี่ยงในการผลิต
ในทางปฏิบัติ การอัปเดตคำแนะนำที่ประสบความสำเร็จไม่ได้แค่ผลักดันค่าเฉลี่ยขึ้น มันลดความไม่แน่นอนโดยทำให้กระบวนการทำงานของเอเจนต์สม่ำเสมอมากขึ้น - โดยเฉพาะในคำถามการคัดกรอง โครงสร้างการแก้ไข และขั้นตอนการตรวจสอบ
นี่คือสิ่งที่ “ดี” ดูเหมือนใน AI ระดับองค์กร: การปรับปรุงที่วัดได้ ประสิทธิภาพที่ทำซ้ำได้ และเส้นทางการตรวจสอบที่ชัดเจนที่เชื่อมโยงการเปลี่ยนแปลงกับผลลัพธ์
ข้อสรุปสำหรับองค์กร: เปลี่ยนการประเมินให้เป็นกระบวนการปล่อย
กระบวนการทำงานนี้คือพื้นฐานของการปรับใช้ AI agent ระดับองค์กร:
รันการประเมินในชุดข้อมูลที่เป็นตัวแทน
ใช้การวิเคราะห์เพื่อระบุโหมดความล้มเหลวที่เกิดซ้ำได้
ใช้การอัปเดตคำแนะนำที่มุ่งเน้นพร้อมความแตกต่างที่ตรวจสอบแล้ว
ติดตามการเปลี่ยนแปลงผ่านประวัติรุ่นเพื่อความสามารถในการตรวจสอบ
รันการประเมินเดียวกันอีกครั้งเพื่อยืนยันการปรับปรุง
นั่นคือวิธีที่คุณย้ายจาก “เอเจนต์ฟังดูดี” ไปสู่ “เอเจนต์ทำงานได้อย่างน่าเชื่อถือ” การประเมินกลายเป็นประตูปล่อย - กระบวนการ CI ที่ปฏิบัติได้สำหรับ AI agent ที่ลดความเสี่ยงในการปฏิบัติการ ปรับปรุงความสม่ำเสมอ และทำให้การปรับปรุงสามารถวัดได้
การเรียกร้องให้ดำเนินการ
หากคุณต้องการให้การประเมินขับเคลื่อนผลลัพธ์ทางธุรกิจที่แท้จริง ให้ปฏิบัติเหมือนวิศวกรรม:
การอัปเดตคำแนะนำทุกครั้งควรกระตุ้นการรันการประเมิน
ความล้มเหลวในการผลิตทุกครั้งควรกลายเป็นกรณีทดสอบใหม่
การปรับปรุงทุกครั้งควรวัดได้และทำซ้ำได้
สำรวจ AgentX
เรียนรู้เพิ่มเติมที่ agentx.so
รันการประเมินในแพลตฟอร์มที่ app.agentx.so
ในโพสต์ถัดไป เราจะเจาะลึกวิธีการประเมินองค์กร เครื่องมือ และเทคนิคปฏิบัติในการปรับปรุงประสิทธิภาพและความน่าเชื่อถือของเอเจนต์อย่างต่อเนื่อง เราจะเปิดตัวส่วนใหม่เกี่ยวกับ การตรวจสอบ - เร็ว ๆ นี้