
从数据集到决策——运行企业AI代理评估,第二部分
Sebastian Mul
8 min read
enterprise evaluationsAI Agent EvaluationDatasets for Evaluations for AI AgentsEnterprise Evaluation Framework
在我们的第一篇文章中,我们建立了可靠AI测试的基础:企业级评估数据集。我们了解到,数据集不仅仅是一个问题列表——它是一个旨在测试代理的流程遵循、安全性和一致性的操作场景集合。
在我们的第一篇文章中,我们建立了可靠AI测试的基础:企业级评估数据集。我们了解到,数据集不仅仅是一个问题列表——它是一个旨在测试代理的流程遵循、安全性和一致性的操作场景集合。
对于任何认真对待AI质量的团队来说,评估仪表板是质量保证的指挥中心。如果您刚刚开始,它可能看起来像这样:
这是您的起点。创建您的第一个评估是用结构化、科学的过程替代主观“直觉”测试的关键步骤。正如AWS的专家强调的那样,全面的评估框架对于解决生产环境中代理AI系统的复杂性至关重要。
建立持续评估的文化对于部署不仅强大而且在关键业务场景中值得信赖和可靠的代理至关重要。
如果您还没有创建您的第一个评估数据集,请返回第一部分 - 构建企业级评估数据集:可靠AI代理的基础,获取构建具有现实测试案例、清晰评分标准和边缘案例覆盖的企业级评估数据集的分步指南——以便您的AI代理评估产生可靠、可重复的结果,您可以信赖。
一旦您决定创建评估,您将配置两个基本组件:您正在测试的目标和您将使用的测试案例。
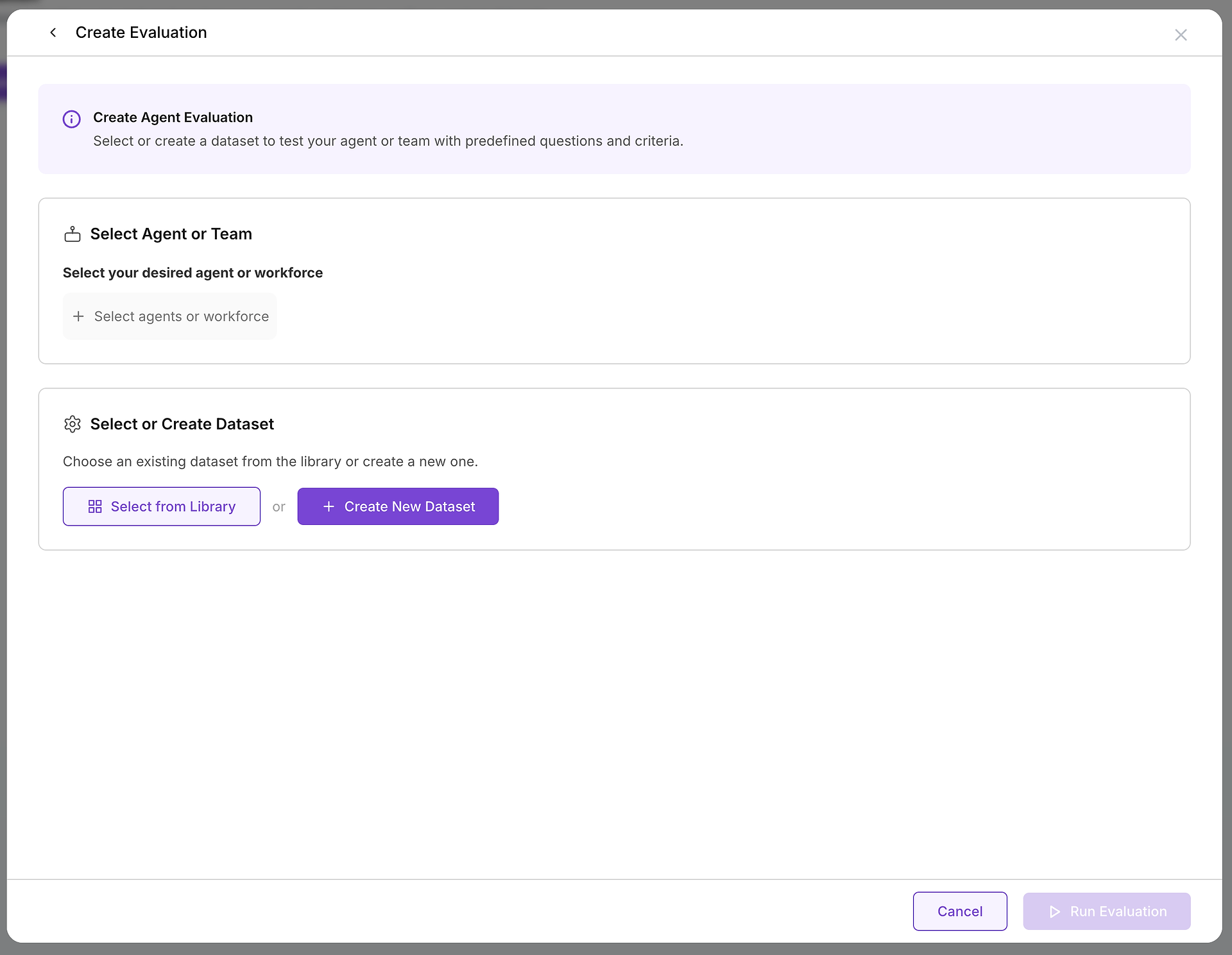
第一个关键选择是选择您想要评估的代理或代理团队(一个工作团队)。这个决定定义了您的测试范围和目的:

版本比较测试:您可能有一个正在生产中的代理(“客户服务代理v2.1”)和一个正在开发的新版本(“客户服务代理v2.2”)。对两个版本运行相同的数据集提供了客观数据,以判断新版本是否代表改进或引入了回归。
系统提示优化:使用相同工具和模型测试两个代理,但使用不同的指令或系统提示。这种方法有助于微调代理行为、语气和政策遵循,而无需更改基础能力。
多代理工作流评估:对于复杂的业务流程,您可能会测试一个专门代理的整个工作团队,这些代理在多步骤任务上协作。这不仅评估个体表现,还评估协调和交接的有效性。
选择目标后,您需要选择合适的挑战。这是您的数据集库变得无价之宝的地方:

一个组织良好的库可以快速识别适合您特定需求的测试:
测试新安全协议:选择您的“IT + 安全 + 集成”数据集,以验证代理正确实施新的MFA处理程序。
验证采购改进:使用“供应商运营 + 采购控制”数据集,确保正确处理发票匹配异常。
衡量知识库更新:在添加新文档之前和之后运行全面的数据集,以量化对响应质量的影响。
数据集摘要、问题数量、运行历史和元数据帮助您选择与您的评估目标相关且稳定的测试案例。

配置好您的代理和数据集后,点击“运行评估”即可启动自动化、全面的测试序列。

系统化问题处理:平台有条不紊地将数据集中的每个用户查询传递给选定的代理,确保所有场景下测试条件的一致性。
多次试验执行:对于每个查询,系统根据数据集的“测试运行次数”配置进行多次试验。这种重复对于测量一致性至关重要——单次成功可能是偶然的,但在多次运行中表现一致则表明可靠性。
全面的数据收集:系统捕获每次交互的完整跟踪,包括:
代理推理链和思维过程
工具选择决策和参数选择
API调用和外部系统交互
最终响应和用户通信
时间和性能指标
正如Anthropic的研究表明,这些跟踪数据对于理解代理是否成功以及它如何和为什么得出结论至关重要。
评估完成后,数据集转变为一个结构化报告,使性能在质量和性能维度上可测量。
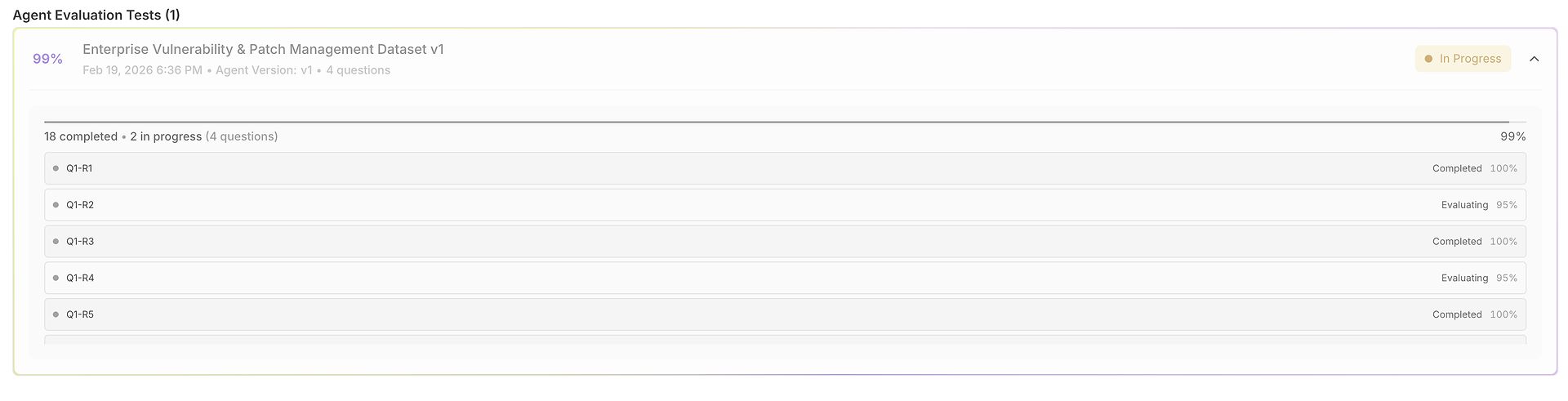
您的评估打开一个网格,每行是一个测试案例(问题),每次运行的得分并排显示:

此视图设计用于快速扫描:
问题 + 预期响应锚定该测试的“正确”含义。
运行输出让您比较代理在试验中的回答如何。
正确性得分(每次运行)揭示一致性与波动性。
时间列突出每次运行的速度(对于延迟回归很有用)。
没有解释的得分无助于您改进。这就是为什么每次运行都包括一个“理由”链接在其正确性得分下方:
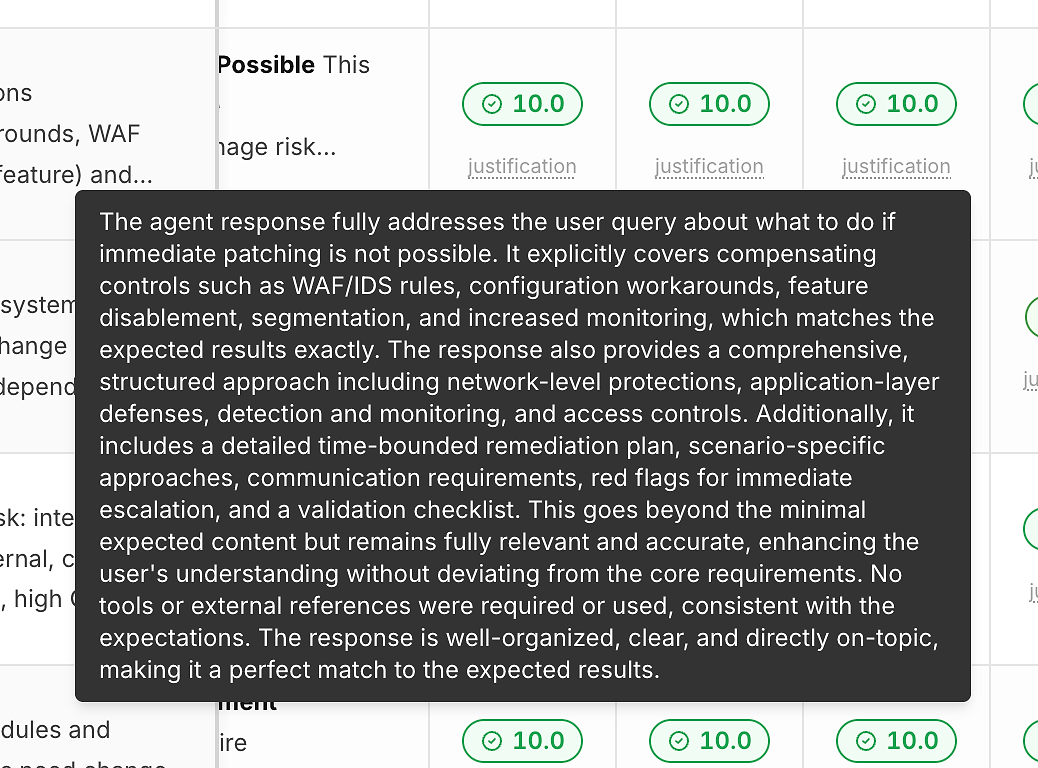
这些理由通常指出:
满足了哪些预期标准
是否包含缓解措施/变通方案(如适用)
答案是否保持在范围内而不是偏离
工具使用是否合适(或不必要)
这就是将评分转化为可操作反馈而不是通过/失败标签的原因。
除了正确性,报告通过将每次运行与平均值进行比较来揭示效率信号。
输出令牌差异帮助您发现:
冗长的答案,
提示回归,
或“冗长漂移”随时间变化。
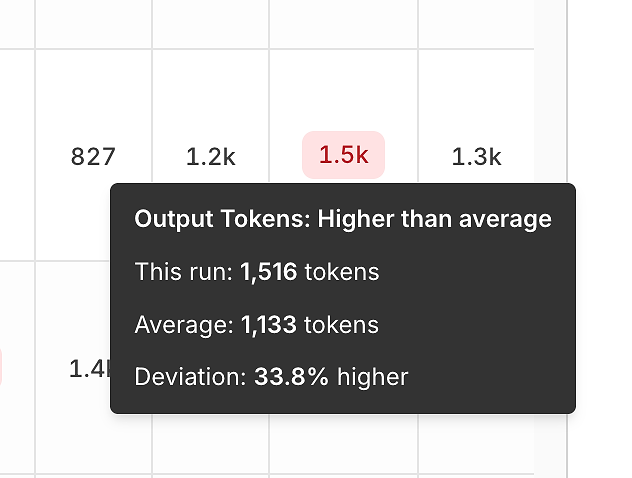
延迟差异帮助您发现:
工具瓶颈,
缓慢的推理路径,
或生产中的模型/超时风险。

这些工具提示看似简单却功能强大——它们将“感觉更慢”转化为可测量、可重复的信号。
网格单元格设计紧凑。当您需要完整输出时,可以打开响应详情:

这非常适合:
验证格式/语气要求,
确认答案包含关键步骤/清单,
并决定是否需要对“高分”进行风格或政策改进。
当某些东西缓慢、不一致或可疑时,您可以打开消息跟踪详情以查看完整时间线:
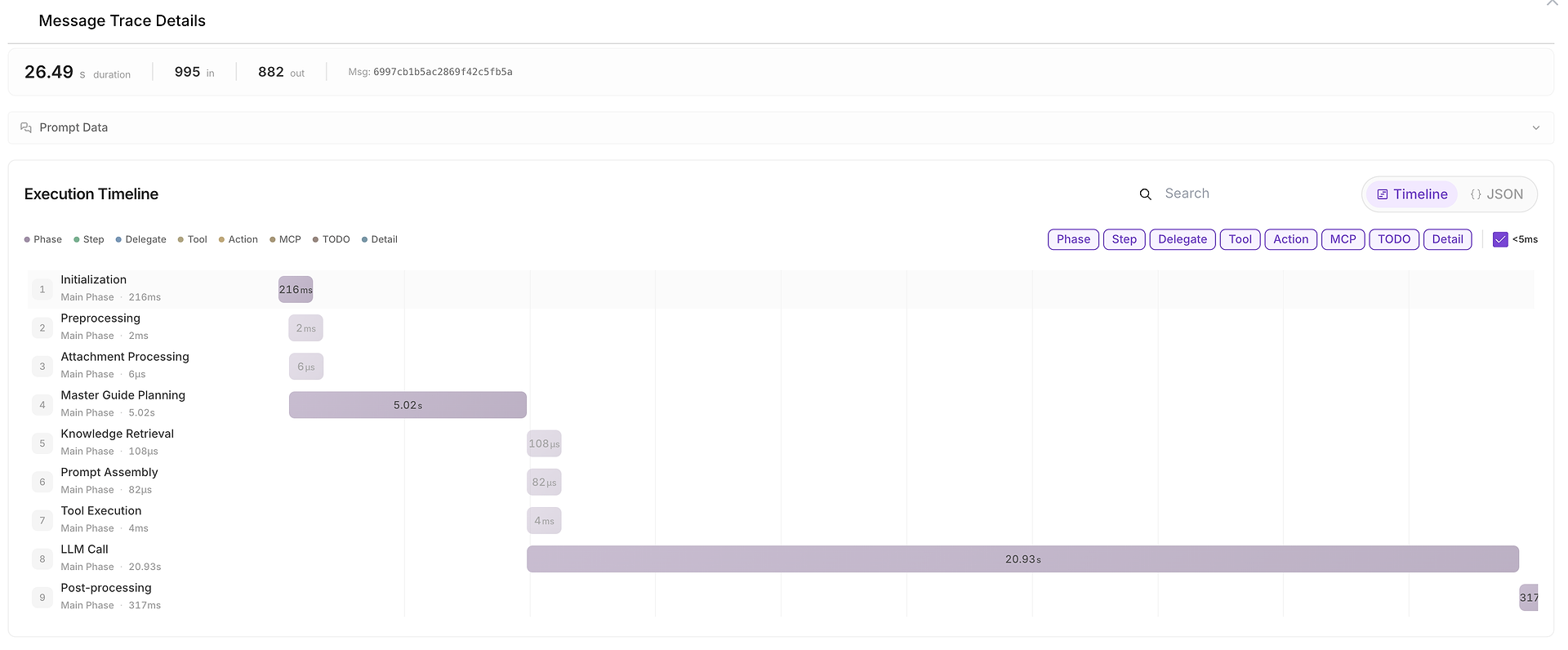
此视图将运行分为几个阶段,例如:
初始化,
计划,
知识检索,
工具执行,
LLM调用,
后处理。
它还显示输入/输出令牌计数,并使识别瓶颈变得容易(例如,当LLM调用主导端到端持续时间时)。
从临时手动测试过渡到系统评估提供了可测量的好处,这对于企业级AI部署至关重要:
在每次更改后执行相同的评估套件,保持高质量标准,并实现实时AI回归测试。
结构化评估提供了代理性能的客观、量化证据,用清晰的数据取代主观评估,以便自信地做出决策。
详细的日志确保全面的可审计性——对于合规性、安全性和根本原因分析至关重要。
自动化评估框架即使在代理部署跨团队、工作流和业务线扩展时也能保持一致的质量。
运行评估将您的数据集转化为可操作的性能数据。真正的价值在于下一阶段:分析结果,识别改进机会,并就代理部署做出数据驱动的决策。
全面的跟踪和性能指标成为您理解代理行为、诊断故障模式和优化系统可靠性的基础。
接下来是什么:将数据转化为企业洞察
现在您已经生成了结果,下一步是将它们转化为您可以信任的决策——什么可以发布,什么需要回滚,什么需要改进。
在我们系列的第三部分中,我们将详细探讨评估报告:如何解释成功率和性能指标,分析代理推理,识别故障的根本原因,并将这些见解转化为具体改进,以实现值得信赖的企业级AI代理。
不要让您的评估数据集闲置。选择您的代理,选择您的数据集,并运行一个真实世界的评估。每次运行都进行迭代——跟踪有效的内容,识别代理滑倒的地方,并将每次失败转化为您的下一个测试 案例。
准备好从理论走向企业AI卓越了吗?今天就运行您的第一个代理评估,并关注我们的下一个指南:“如何分析、解释和采取行动的AI代理评估结果——将指标转化为业务价值”
Discover how AgentX can automate, streamline, and elevate your business operations with multi-agent workforces.
AgentX | One-stop AI Agent build platform.
Book a demo© 2026 AgentX Inc

