تقييم وكيل الذكاء الاصطناعي: تقديم تقييمات الوكلاء: الطريقة الأكثر موثوقية لفهم وتحسين وكلاء الذكاء الاصطناعي لديك
أصبح وكلاء الذكاء الاصطناعي أكثر تقدمًا وقدرة واندماجًا في الأعمال التجارية.
ولكن هناك مشكلة عالمية تواجه كل فريق:
وكيلك لا يجيب دائمًا بالطريقة التي تتوقعها - ولا تعرف السبب.
أحيانًا يتغير التفكير، وأحيانًا يتجاهل الوكيل قاعدة، وأحيانًا لم تُستخدم الأداة بشكل صحيح، وأحيانًا يُساء فهم تعليمات دقيقة. بدون رؤية لكيفية اتخاذ القرارات، يبدو تحسين الوكيل كأنه تخمين.
لهذا السبب بالضبط قمنا ببناء تقييمات الوكلاء - نظام جديد داخل AgentX يتيح لك اختبار وقياس وتحليل كيفية تصرف وكيلك عبر عمليات متعددة لنفس السؤال.
إنها المرة الأولى التي يمكنك فيها رؤية داخل عملية اتخاذ القرار لوكيلك، العثور على التناقضات، وفهم بالضبط أين تحتاج إلى تحسينات.
لماذا التقييمات مهمة
نماذج الذكاء الاصطناعي احتمالية.
حتى مع نفس الطلب والسياق والقواعد، قد يقوم النموذج بـ:
إنتاج مسارات تفكير مختلفة قليلاً
إغفال تفاصيل مطلوبة
سوء تفسير سياسة
تخطي البحث عن أداة
إعطاء إجابات غير مؤكدة بدلاً من الإجابة النهائية المتوقعة
تفويض غير متسق داخل الفريق
من الخارج، ترى فقط الإجابة النهائية.
أنت لا ترى:
ما إذا كان الوكيل قد اتبع تعليماتك
ما إذا كان استخدم الأدوات الصحيحة
ما إذا كان فكر بشكل صحيح
لماذا كانت نسخة من الإجابة أضعف من أخرى
لماذا يصيب الأمور أحيانًا - ويخطئ أحيانًا أخرى
تحل التقييمات هذا من خلال منحك الهيكل، والتسجيل، والشفافية.
كيف يعمل الاختبار
إنشاء تقييم بسيط:
0. اختر الوكيل أو الفريق الذي تريد تقييمه.
1. سؤال الاختبار
هذا هو السؤال الواقعي الذي تريد التحقق منه.
يحاكي استفسار عميل أو طلب سير عمل داخلي.
مثال:
“هل يمكنني إرجاع عنصر بيع نهائي إذا لم يكن مناسبًا؟”
يشكل هذا جوهر التقييم.
2. النتائج المتوقعة (مطلوبة)
هذا هو الجزء الأكثر أهمية في التكوين.
هنا تحدد ما يجب أن يقوله الوكيل أو يتضمنه ليُعتبر الرد صحيحًا.
يمكن أن يحتوي على:
حقائق أساسية
عبارات إلزامية
خطوات التفكير المطلوبة
قواعد الامتثال
نغمة أو بيانات سياسة محددة
مثال:
“يجب أن يقول: لا، عناصر البيع النهائي غير قابلة للإرجاع أو الاستبدال.”
تصبح النتائج المتوقعة معيار التقييم لجميع عمليات الاختبار.
3. القدرات المتوقعة (اختيارية ولكن قوية)
يمكنك إخبار نظام التقييم بالأدوات أو المستندات أو مصادر المعرفة التي يجب أن يستخدمها الوكيل.
في مثالك، اخترت:
Documents → store_policy_kb_v1.xlsx
وظائف مدمجة
هذا يعني:
يجب أن يسترد الوكيل المعلومات من قاعدة بيانات السياسة.
إذا لم يستخدم قاعدة البيانات بشكل صحيح، سيلتقط التقييم ذلك.
هذا مثالي لـ:
وكلاء السياسة
وكلاء خدمة العملاء
سير العمل الامتثالي
نمذجة المالية
التفكير المدعوم بالبيانات
4. إعدادات التقييم
يحدد هذا القسم مدى صرامة وعمق التقييم الخاص بك.
عدد عمليات الاختبار
يتم تنفيذ نفس السؤال عدة مرات (موصى به: 5 مرات).
لماذا؟
لأن نماذج الذكاء الاصطناعي ليست حتمية. تتيح لك العمليات المتعددة التحقق من:
الاتساق
الاستقرار
موثوقية التفكير
ما إذا كان الوكيل يتبع نفس العملية في كل مرة
إذا أنتج الوكيل إجابة جيدة واحدة وأربع فشل، سترى ذلك على الفور.
معايير القبول
يحدد هذا المنزلق مدى تطابق الإجابة مع نتائجك المتوقعة.
أنت تختار نقطة بين:
متساهل → يمكن للوكيل الانحراف عن توقعاتك؛ لا تحتاج الإجابة إلى أن تكون مثالية.
دقيق → يجب أن تتبع الإجابة توقعاتك عن كثب، مع عدم وجود مجال تقريبًا للتغيير.
إنه ببساطة يتحكم في مدى دقة الاستجابة المطلوبة لاجتياز التقييم.
معايير الرفض (اختياري)
قواعد للفشل التلقائي.
أمثلة:
“يجب ألا تذكر الاستجابة المنافسين.”
“لا تقدم استردادًا عندما تمنع السياسة ذلك.”
“يجب ألا تطلب الاستجابة من المستخدم تقديم معلومات شخصية.”
هذه قيود صارمة.
معايير التقييم (اختياري)
إرشادات تسجيل إضافية، تُستخدم غالبًا للجودة أو النغمة.
أمثلة:
“يجب أن تكون الاستجابة ودية ومهنية.”
“يجب أن تحتوي الإجابة على تفسير قصير، وليس مجرد نعم/لا.”
“استخدم حقائق قاعدة البيانات قبل الافتراضات.”
هذه ليست متطلبات صارمة ولكنها تساعد في تشكيل كيفية تسجيل الذكاء الاصطناعي للوكيل.
5. إنشاء التقييم
بمجرد التكوين، يبدأ النقر على إنشاء التقييم العملية:
يتم تشغيل السؤال عدة مرات
يتم تسجيل كل إجابة
يتم إنشاء تحليل مفصل
يتم فحص التفويض واستخدام الأدوات
يتم إبراز التناقضات
وتحصل على تقرير أداء كامل.
ما تحصل عليه بعد تشغيل التقييم
بعد عدة عمليات، يوفر AgentX طبقتين من المخرجات:
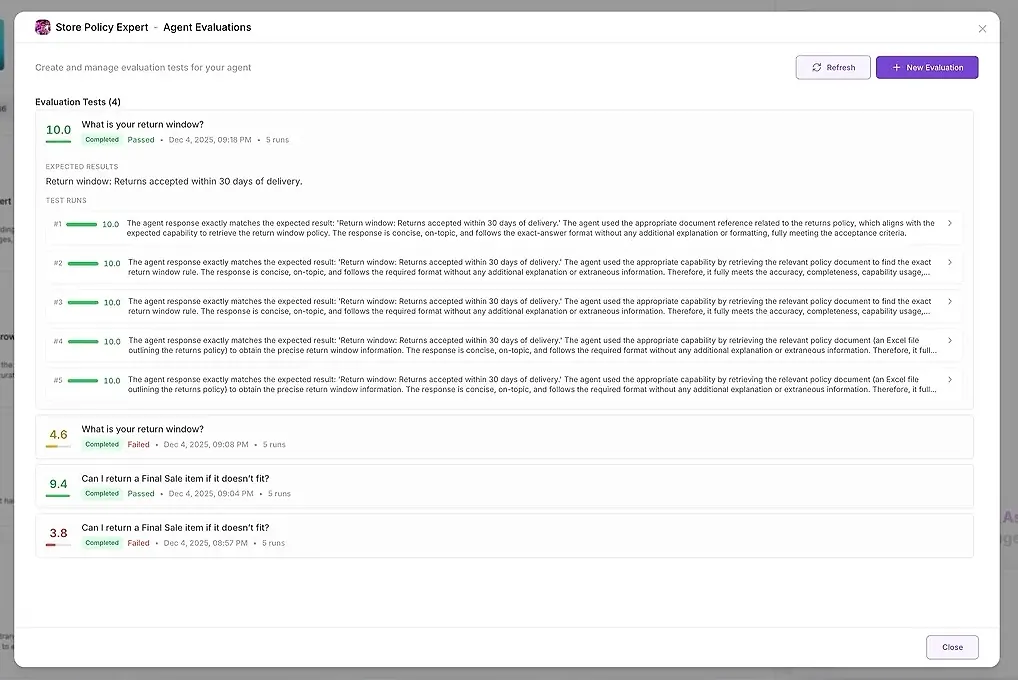
1. نتائج الاختبار
لكل عملية، ترى:
درجة رقمية
ملخص لمدى تطابقها مع توقعاتك
الاستجابة الكاملة
الأدوات المستخدمة
الوكلاء المشاركين
أين فشل الوكيل أو انحرف
يتيح لك ذلك مقارنة الإجابات جنبًا إلى جنب وتحديد الأنماط.
2. تحليل الذكاء الاصطناعي العميق
هنا يحدث السحر الحقيقي.
يقوم AgentX بتحليل جميع العمليات تلقائيًا ويولد تقريرًا منظمًا عبر فئات متعددة:
• الالتزام بالتعليمات
هل اتبع الوكيل قواعدك؟
• أنماط الاستجابة
ما مدى تشابه أو اختلاف الإجابات؟
هل هناك نقاط شاذة؟
• تحليل التفكير
هل كانت خطوات التفكير صحيحة وكاملة ومتوافقة مع التوقعات؟
• استخدام الأدوات
هل استخدم الوكيل الأداة الصحيحة؟
هل تخطى البحث؟
هل اعتمد على الافتراضات بدلاً من الحقائق المؤكدة؟
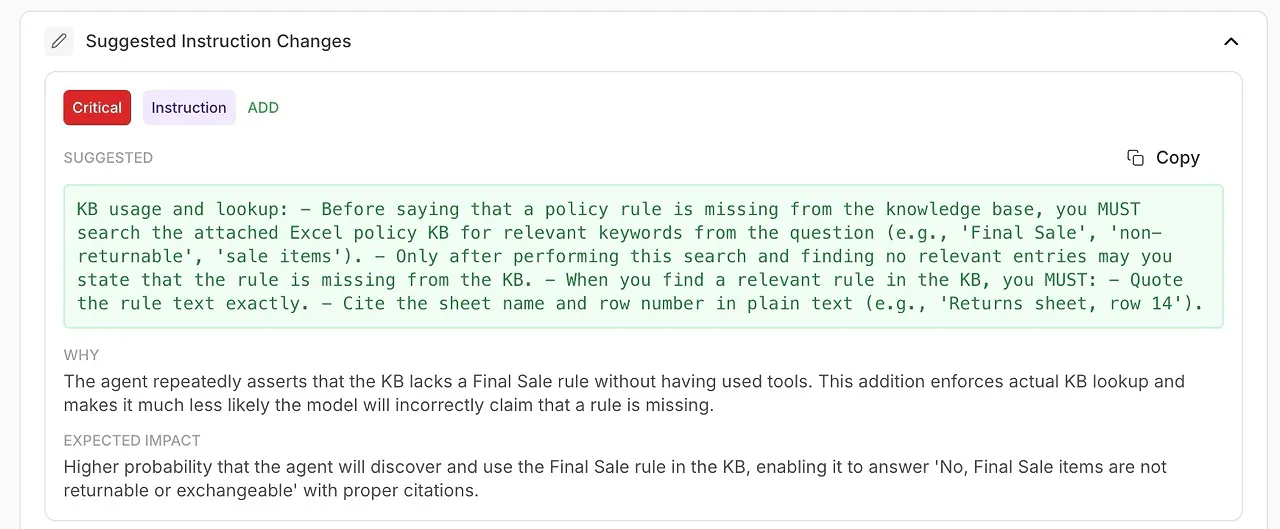
• التوصيات
اقتراحات ملموسة وقابلة للتنفيذ لتحسين وكيلك.
• التغييرات المقترحة على التعليمات
تحسينات تم إنشاؤها تلقائيًا لموجه النظام أو تكوين الوكيل الخاص بك.
• التقييم العام
ملخص لنقاط القوة والضعف ومستوى الثقة.
يحول هذا عملية التصحيح من لعبة تخمين إلى عملية علمية قابلة للتكرار.
ما الذي يمكن أن يحققه هذا الميزة
تقدم التقييمات مستوى جديدًا من الشفافية والموثوقية في كيفية عمل وكلائك. بدلاً من التخمين لماذا كانت الإجابة خاطئة أو غير متسقة، لديك الآن طريقة منظمة وقابلة للقياس لفهم السلوك وتشخيص المشكلات وتحسين الأداء باستمرار.
إليك ما يصبح ممكنًا:
🔍 تحقق من وكيلك قبل إطلاقه للعملاء
قبل أن تقوم بإطلاق وكيل في الإنتاج، يمكنك إجراء اختبارات واقعية تكشف ما إذا كان يفهم تمامًا قواعدك وقاعدة معرفتك والنغمة المطلوبة. لا مزيد من المفاجآت بعد النشر — تعرف بالضبط ما سيختبره المستخدمون.
🤖 اختبر فريق الوكلاء بالكامل ومنطق التفويض
بالنسبة لإعدادات الوكلاء المتعددة، تُظهر التقييمات كيف يقوم المدير بتفويض المهام، وأي وكلاء فرعيين يشاركون، وما إذا كانوا يتبعون سير العمل المتوقع. يمكنك بسرعة اكتشاف:
التفويضات غير الضرورية
التفويضات المفقودة
الوكلاء المتضاربين
سلوك الدور غير الصحيح
هذا ضروري للعمل الجماعي الموثوق داخل قوة العمل الذكاء الاصطناعي الخاصة بك.
📚 اكتشف النقاط الضعيفة في قاعدة معرفتك
إذا أظهر التقييم فشلًا متكررًا في موضوع معين، فأنت تعرف أن المشكلة ليست في الوكيل — إنها محتوى مفقود أو غير واضح. تساعدك التقييمات في تحسين قاعدة معرفتك بطريقة مستهدفة ومدفوعة بالبيانات، بدلاً من إضافة المزيد من المواد بشكل أعمى.
🚨 اكتشف الهلوسات وعدم الاتساق مبكرًا
لأن كل سؤال يتم اختباره عدة مرات، تُظهر التقييمات مشكلات دقيقة مثل:
تغيير الإجابات بشكل غير متوقع
انجراف التفكير
استبدال التخمينات الواقعية باستخدام الأدوات
التناقضات عبر العمليات
هذه مشكلات لن تتمكن من تحديدها أبدًا عن طريق الاختبار اليدوي مرة أو مرتين.
🧠 صقل تعليمات النظام باستخدام تحسينات تم إنشاؤها بواسطة الذكاء الاصطناعي
لا يُظهر التحليل فقط ما حدث خطأ — بل يخبرك كيف تصلحه.
تحصل على توصيات قابلة للتنفيذ مدعومة بتشخيصات النموذج الخاصة:
تحسين الصياغة
قواعد أكثر صرامة
استخدام الأدوات الإلزامي
سياسات تفويض أوضح
نغمة وهيكل أكثر دقة
هذا هو هندسة الموجهات الآلية المدمجة مباشرة في سير عملك.
📈 قياس التقدم في كل مرة تقوم فيها بتحديث وكيلك
كلما قمت بتغيير:
موجه النظام
إدخال قاعدة المعرفة
أداة
قاعدة التفويض
سياسة التفكير
…يمكنك إعادة تشغيل نفس التقييم ومقارنة الدرجات. ترى بالضبط كيف أثرت تحديثاتك على الأداء — بشكل إيجابي أو سلبي.
تصبح التقييمات حلقة التحسين المستمرة الخاصة بك.
✔ فرض استجابات عالية الجودة ومتوافقة عبر مؤسستك
سواء كنت تتعامل مع الدعم أو التحليل المالي أو سيناريوهات الرعاية الصحية أو المحتوى الحساس قانونيًا، تتيح لك التقييمات ضمان:
اتباع السياسات
احترام إرشادات النغمة
الإشارة إلى الفجوات الخطيرة
إبراز التفكير غير الصحيح
الامتثال للمعايير
هذا مهم بشكل خاص للذكاء الاصطناعي المؤسسي والموجه للعملاء.
الاستخدام والتكاليف
تستخدم تقييمات الوكلاء نفس نموذج الائتمان مثل بقية AgentX. كل عملية اختبار تستهلك ببساطة الائتمانات بنفس الطريقة التي يفعلها رسالة الوكيل العادية - لا توجد رسوم إضافية، ولا تسعير مخفي. تعرف دائمًا بالضبط ما تنفقه، لأن التقييمات تتبع حدود خطتك الحالية ورصيد الائتمان.
طبقة التحكم في الجودة الخاصة بك للذكاء الاصطناعي
في البرمجيات التقليدية، يضمن ضمان الجودة الموثوقية.
في AgentX، التقييمات هي ضمان الجودة للوكلاء.
أنت تحدد ما يبدو عليه "الجيد".
يتحقق AgentX مما إذا كان وكلاؤك يمكنهم تقديمه باستمرار — ويظهر لك بالضبط ما يجب تحسينه عندما لا يفعلون.
تحول التقييمات الذكاء الاصطناعي من صندوق أسود إلى نظام شفاف وقابل للقياس والتحسين.