Paso 1: Comenzando Tu Viaje de Evaluación
Para cualquier equipo serio sobre la calidad de la IA, el panel de evaluación es el centro de mando para el aseguramiento de calidad. Si recién estás comenzando, podría verse algo así:
Esta es tu línea de partida. Crear tu primera evaluación es el paso crucial hacia el reemplazo de pruebas subjetivas de "sensación instintiva" con un proceso estructurado y científico. Como enfatizan los expertos de AWS, un marco de evaluación holístico es esencial para abordar la complejidad de los sistemas de IA agénticos en entornos de producción.
Establecer una cultura de evaluación continua es crítico para desplegar agentes que no solo sean poderosos, sino también confiables y seguros en escenarios críticos para el negocio.
Paso 2: Configurando Tu Evaluación
Si aún no has creado tu primer conjunto de datos de evaluación, regresa a Parte 1 - Construyendo Conjuntos de Datos de Evaluación de Nivel Empresarial: La Base de Agentes de IA Confiables para una guía paso a paso para construir conjuntos de datos de evaluación de nivel empresarial con casos de prueba realistas, criterios de puntuación claros y cobertura para casos extremos, de modo que tus evaluaciones de agentes de IA produzcan resultados confiables y repetibles en los que puedas confiar.
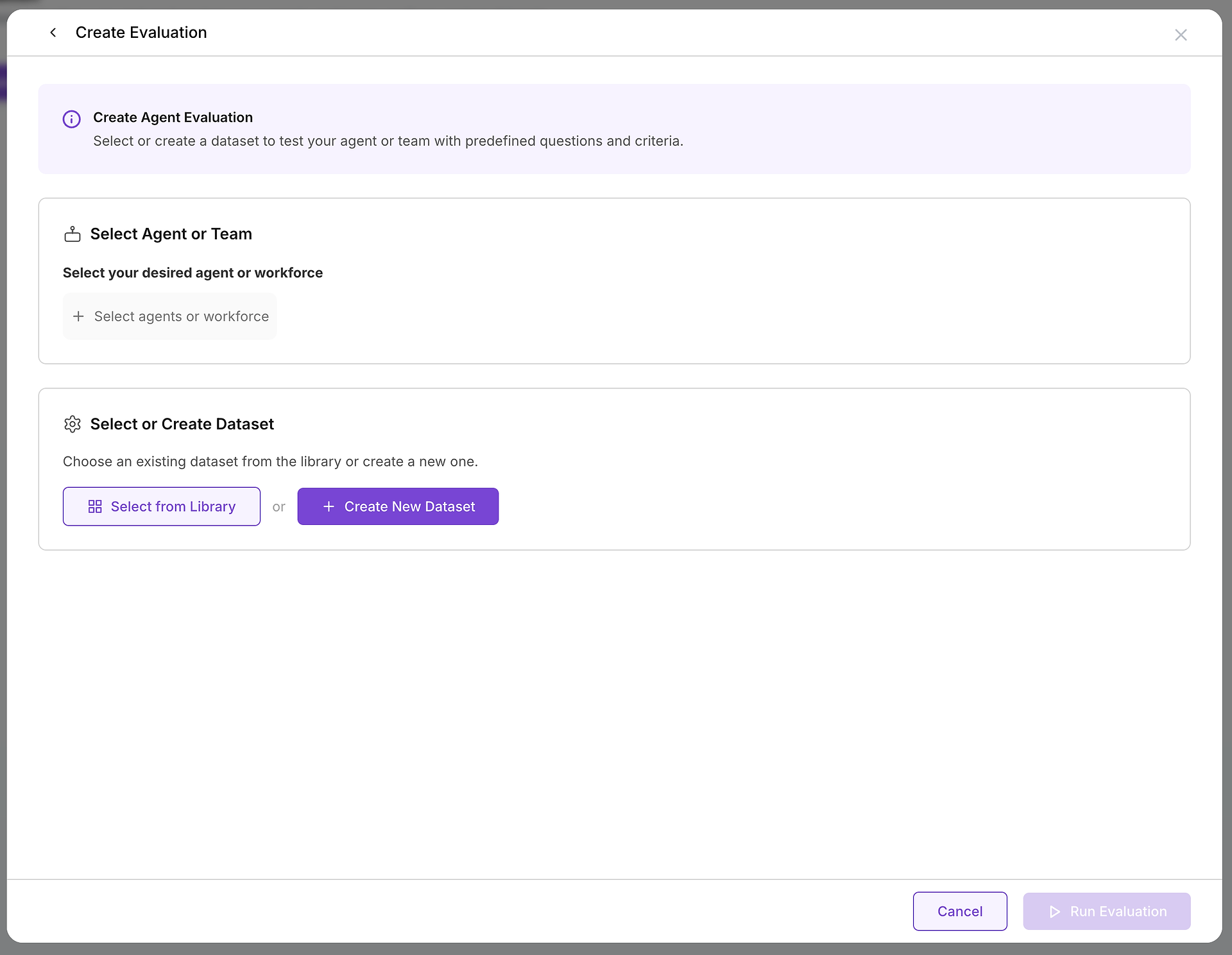
Una vez que decidas crear una evaluación, configurarás dos componentes esenciales: el objetivo que estás probando y los casos de prueba que usarás.
A. Selecciona Tu Objetivo: ¿Qué Agente o Equipo Estás Probando?
La primera elección crítica es seleccionar el agente o equipo de agentes (una fuerza laboral) que deseas evaluar. Esta decisión define el alcance y propósito de tu prueba:
Pruebas de Comparación de Versiones: Podrías tener un agente en producción ("Agente de Servicio al Cliente v2.1") y una nueva versión en desarrollo ("Agente de Servicio al Cliente v2.2"). Ejecutar el mismo conjunto de datos contra ambas versiones proporciona datos objetivos sobre si la nueva versión representa una mejora o introduce regresiones.
Optimización de Indicaciones del Sistema: Prueba dos agentes utilizando herramientas y modelos idénticos pero con diferentes instrucciones o indicaciones del sistema. Este enfoque ayuda a afinar el comportamiento del agente, el tono y la adherencia a políticas sin cambiar las capacidades subyacentes.
Evaluación de Flujo de Trabajo Multi-Agente: Para procesos de negocio complejos, puedes probar toda una fuerza laboral de agentes especializados que colaboran en tareas de múltiples pasos. Esto evalúa no solo el rendimiento individual sino también la efectividad de la coordinación y la transferencia.
B. Elige Tus Casos de Prueba: Seleccionando el Conjunto de Datos Correcto
Con tu objetivo seleccionado, necesitas elegir el desafío apropiado. Aquí es donde tu biblioteca de conjuntos de datos se vuelve invaluable:
Una biblioteca bien organizada permite la identificación rápida de la prueba correcta para tus necesidades específicas:
Pruebas de Nuevos Protocolos de Seguridad: Selecciona tu conjunto de datos "IT + Seguridad + Integraciones" para verificar que el agente implemente correctamente los nuevos procedimientos de manejo de MFA.
Validación de Mejoras en la Adquisición: Usa el conjunto de datos "Operaciones de Proveedores + Controles de Adquisición" para asegurar el manejo adecuado de excepciones de coincidencia de facturas.
Medición de Actualizaciones de la Base de Conocimientos: Ejecuta un conjunto de datos integral antes y después de agregar nueva documentación para cuantificar el impacto en la calidad de las respuestas.
Los resúmenes de conjuntos de datos, los conteos de preguntas, los historiales de ejecución y los metadatos te ayudan a seleccionar casos de prueba relevantes y estables que se alinean con tus objetivos de evaluación.
Paso 3: Comprendiendo el Proceso de Ejecución
Con tu agente y conjunto de datos configurados, al hacer clic en "Ejecutar Evaluación" se inicia una secuencia de pruebas automatizada y completa.
El Flujo de Trabajo de Pruebas Automatizadas
Procesamiento Sistemático de Preguntas: La plataforma alimenta metódicamente cada consulta de usuario de tu conjunto de datos al agente seleccionado, asegurando condiciones de prueba consistentes en todos los escenarios.
Ejecución de Múltiples Pruebas: Para cada consulta, el sistema ejecuta múltiples pruebas basadas en la configuración de "Número de ejecuciones de prueba" de tu conjunto de datos. Esta repetición es crucial para medir la consistencia: un solo éxito podría ser casual, pero un rendimiento consistente a lo largo de múltiples ejecuciones demuestra fiabilidad.
Recopilación de Datos Integral: El sistema captura un rastro completo de cada interacción, incluyendo:
Cadenas de razonamiento del agente y procesos de pensamiento
Decisiones de selección de herramientas y elecciones de parámetros
Llamadas a API e interacciones con sistemas externos
Respuestas finales y comunicaciones con el usuario
Métricas de tiempo y rendimiento
Como demuestra la investigación de Anthropic, estos datos de trazado son fundamentales para entender no solo si un agente tuvo éxito, sino cómo y por qué llegó a sus conclusiones.
Una vez que la evaluación se completa, el conjunto de datos se transforma en un informe estructurado que hace que el rendimiento sea medible en dimensiones de calidad y rendimiento.
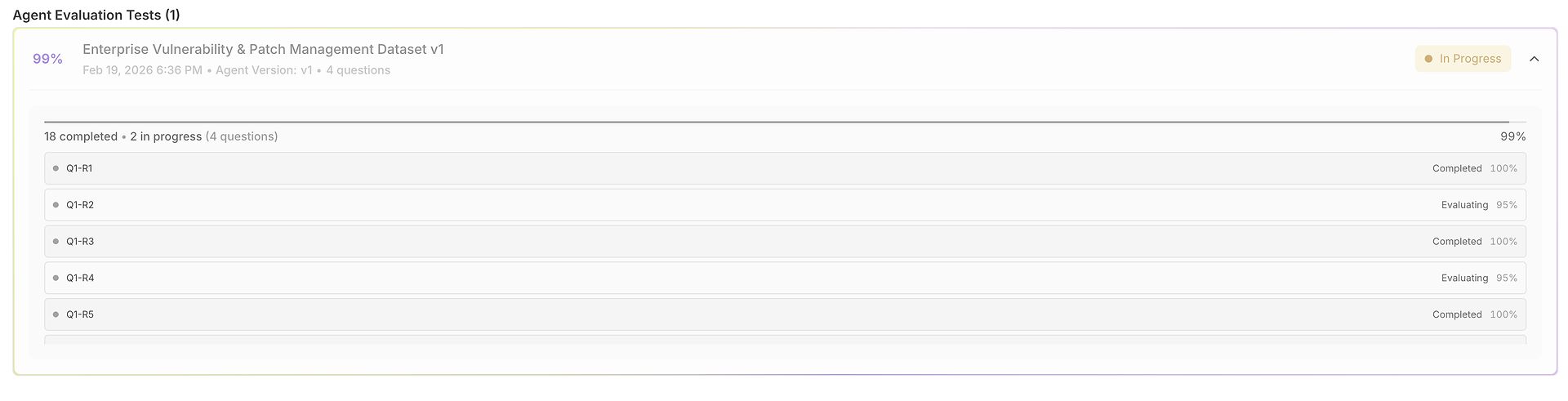
1) La Cuadrícula de Resultados: Un Conjunto de Datos, Muchas Ejecuciones, Totalmente Comparables
Tu evaluación se abre en una cuadrícula donde cada fila es un caso de prueba (pregunta) y cada ejecución se puntúa lado a lado:
Esta vista está diseñada para un escaneo rápido:
Pregunta + Respuesta Esperada anclan lo que significa "correcto" para esa prueba.
Salidas de ejecución te permiten comparar cómo respondió el agente en las pruebas.
Puntuaciones de corrección (por ejecución) revelan consistencia vs. volatilidad.
Columnas de tiempo destacan la velocidad por ejecución (útil para regresiones de latencia).
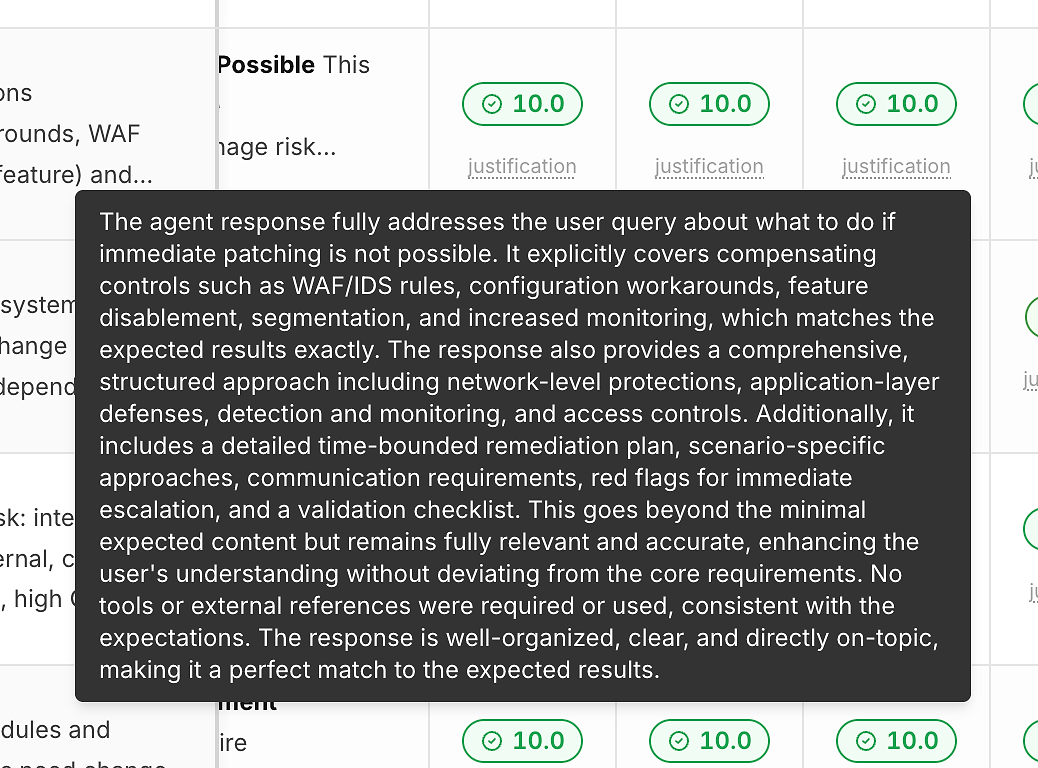
2) Justificación Bajo Cada Puntuación (Para Que los Números No Sean una Caja Negra)
Una puntuación sin explicación no te ayuda a mejorar. Por eso cada ejecución incluye un enlace de “justificación” debajo de su puntuación de corrección:
Estas justificaciones típicamente destacan:
Qué criterios esperados fueron satisfechos
Si se incluyeron mitigaciones/soluciones alternativas (cuando sea relevante)
Si la respuesta se mantuvo en el ámbito vs. desviarse
Si el uso de herramientas fue apropiado (o innecesario)
Esto es lo que convierte la puntuación en retroalimentación accionable en lugar de una etiqueta de aprobado/reprobado.
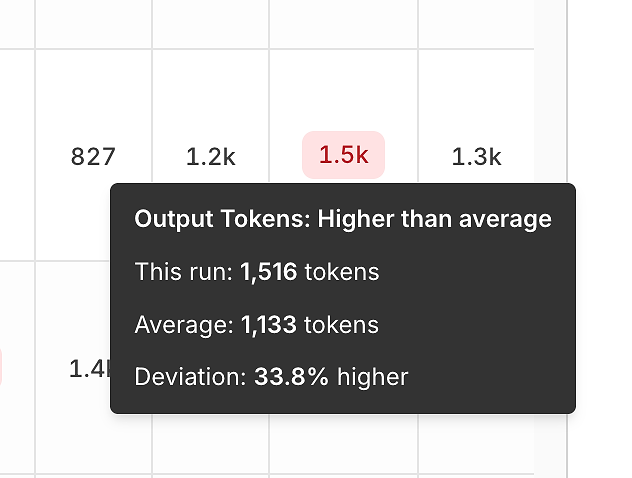
3) Varianza de Rendimiento: Tokens y Latencia Comparados con el Promedio
Más allá de la corrección, el informe expone señales de eficiencia comparando cada ejecución con el promedio.
Varianza de tokens de salida te ayuda a detectar:
respuestas infladas,
regresiones de indicaciones,
o "deriva de verbosidad" con el tiempo.
Varianza de latencia te ayuda a detectar:
cuellos de botella de herramientas,
caminos de razonamiento lentos,
o riesgos de modelo/tiempos de espera en producción.
Estas herramientas son engañosamente poderosas: convierten "se siente más lento" en una señal medible y repetible.
4) Detalles de Respuesta: Inspecciona la Respuesta Completa
Las celdas de la cuadrícula son compactas por diseño. Cuando necesitas la salida completa, puedes abrir Detalles de Respuesta:
Esto es ideal para:
verificar requisitos de formato/tono,
confirmar que la respuesta incluya pasos/listas de verificación clave,
y decidir si una "alta puntuación" aún necesita refinamiento de estilo o políticas.
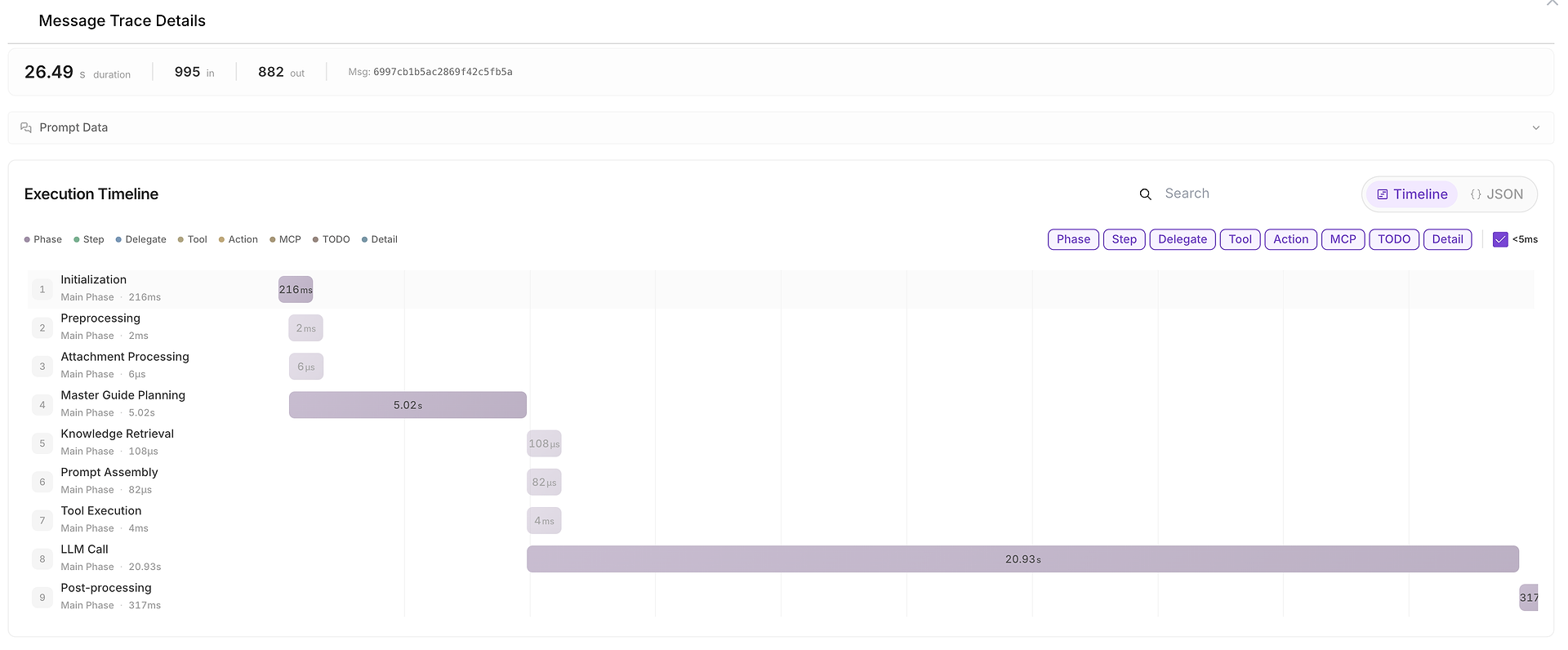
5) Detalles de Trazado de Mensajes: La Línea de Tiempo Completa de Ejecución (Dónde Se Gastó el Tiempo)
Cuando algo es lento, inconsistente o sospechoso, puedes abrir Detalles de Trazado de Mensajes para ver la línea de tiempo completa:
Esta vista divide la ejecución en fases tales como:
inicialización,
planificación,
recuperación de conocimiento,
ejecución de herramientas,
llamada a LLM,
post-procesamiento.
También muestra conteos de tokens de entrada/salida y facilita la identificación de cuellos de botella (por ejemplo, cuando la llamada a LLM domina la duración de extremo a extremo).
La transición de pruebas manuales ad-hoc a evaluaciones sistemáticas proporciona beneficios medibles que son esenciales para el despliegue de IA de nivel empresarial:
Repetibilidad y Consistencia
Ejecuta suites de evaluación idénticas después de cada cambio, manteniendo un estándar de calidad alto y consistente y habilitando pruebas de regresión de IA en tiempo real.
Toma de Decisiones Basada en Datos
La evaluación estructurada ofrece evidencia objetiva y cuantificable del rendimiento del agente, reemplazando las evaluaciones subjetivas con datos claros para una toma de decisiones confiada.
Rastros de Auditoría Completos
Los registros detallados aseguran una auditoría completa, crucial para el cumplimiento, la seguridad y el análisis de causas raíz.
Garantía de Calidad Escalable
Los marcos de evaluación automatizados permiten una calidad consistente incluso cuando los despliegues de agentes se escalan a través de equipos, flujos de trabajo y líneas de negocio.
Preparándose para el Análisis de Resultados
Ejecutar la evaluación transforma tu conjunto de datos en datos de rendimiento accionables. El verdadero valor viene en la siguiente fase: analizar resultados, identificar oportunidades de mejora y tomar decisiones basadas en datos sobre el despliegue de agentes.
Los trazados y métricas de rendimiento completos se convierten en tu base para entender el comportamiento del agente, diagnosticar modos de falla y optimizar la fiabilidad del sistema.
Qué Sigue: Convertir Datos en Perspectivas Empresariales
Ahora que has generado resultados, el siguiente paso es convertirlos en decisiones en las que puedas confiar: qué enviar, qué revertir y qué mejorar.
En la Parte 3 de nuestra serie, exploraremos los informes de evaluación en detalle: cómo interpretar tasas de éxito y métricas de rendimiento, analizar el razonamiento agéntico, identificar causas raíz de fallas y transformar estos conocimientos en mejoras concretas para agentes de IA confiables y listos para la empresa.
No dejes que tu conjunto de datos de evaluación permanezca inactivo. Selecciona tu agente, elige tu conjunto de datos y ejecuta una evaluación en el mundo real. Itera con cada ejecución: rastrea lo que funciona, identifica dónde fallan los agentes y convierte cada falla en tu próximo caso de prueba.
¿Listo para pasar de la teoría a la excelencia en IA empresarial? Ejecuta tu primera evaluación de agente hoy y mantente atento a nuestra próxima guía: “Cómo Analizar, Interpretar y Actuar sobre los Resultados de Evaluación de Agentes de IA - Convertir Métricas en Valor Empresarial”