चरण 1: अपने मूल्यांकन यात्रा की शुरुआत
किसी भी टीम के लिए जो AI गुणवत्ता के प्रति गंभीर है, मूल्यांकन डैशबोर्ड गुणवत्ता आश्वासन के लिए कमांड सेंटर है। यदि आप अभी शुरुआत कर रहे हैं, तो यह कुछ इस तरह दिख सकता है:
यह आपकी शुरुआत की रेखा है। अपना पहला मूल्यांकन बनाना एक महत्वपूर्ण कदम है जो व्यक्तिपरक "आंत-भावना" परीक्षण को एक संरचित, वैज्ञानिक प्रक्रिया के साथ बदलने की दिशा में है। जैसा कि AWS के विशेषज्ञ जोर देते हैं, उत्पादन वातावरण में एजेंटिक AI सिस्टम की जटिलता को संबोधित करने के लिए एक समग्र मूल्यांकन ढांचा आवश्यक है।
निरंतर मूल्यांकन की संस्कृति स्थापित करना उन एजेंटों को तैनात करने के लिए महत्वपूर्ण है जो न केवल शक्तिशाली हैं, बल्कि व्यापार-महत्वपूर्ण परिदृश्यों में भी भरोसेमंद और विश्वसनीय हैं।
चरण 2: अपने मूल्यांकन कॉन्फ़िगरेशन की स्थापना
यदि आपने अभी तक अपना पहला मूल्यांकन डेटासेट नहीं बनाया है, तो भाग 1 - एंटरप्राइज़-ग्रेड मूल्यांकन डेटासेट का निर्माण: विश्वसनीय AI एजेंटों की नींव पर वापस जाएं, जो एंटरप्राइज़-ग्रेड मूल्यांकन डेटासेट बनाने के लिए चरण-दर-चरण मार्गदर्शिका है, जिसमें यथार्थवादी परीक्षण मामले, स्पष्ट स्कोरिंग मानदंड, और एज मामलों के लिए कवरेज शामिल है - ताकि आपके AI एजेंट मूल्यांकन विश्वसनीय, दोहराने योग्य परिणाम उत्पन्न कर सकें जिन पर आप भरोसा कर सकते हैं।
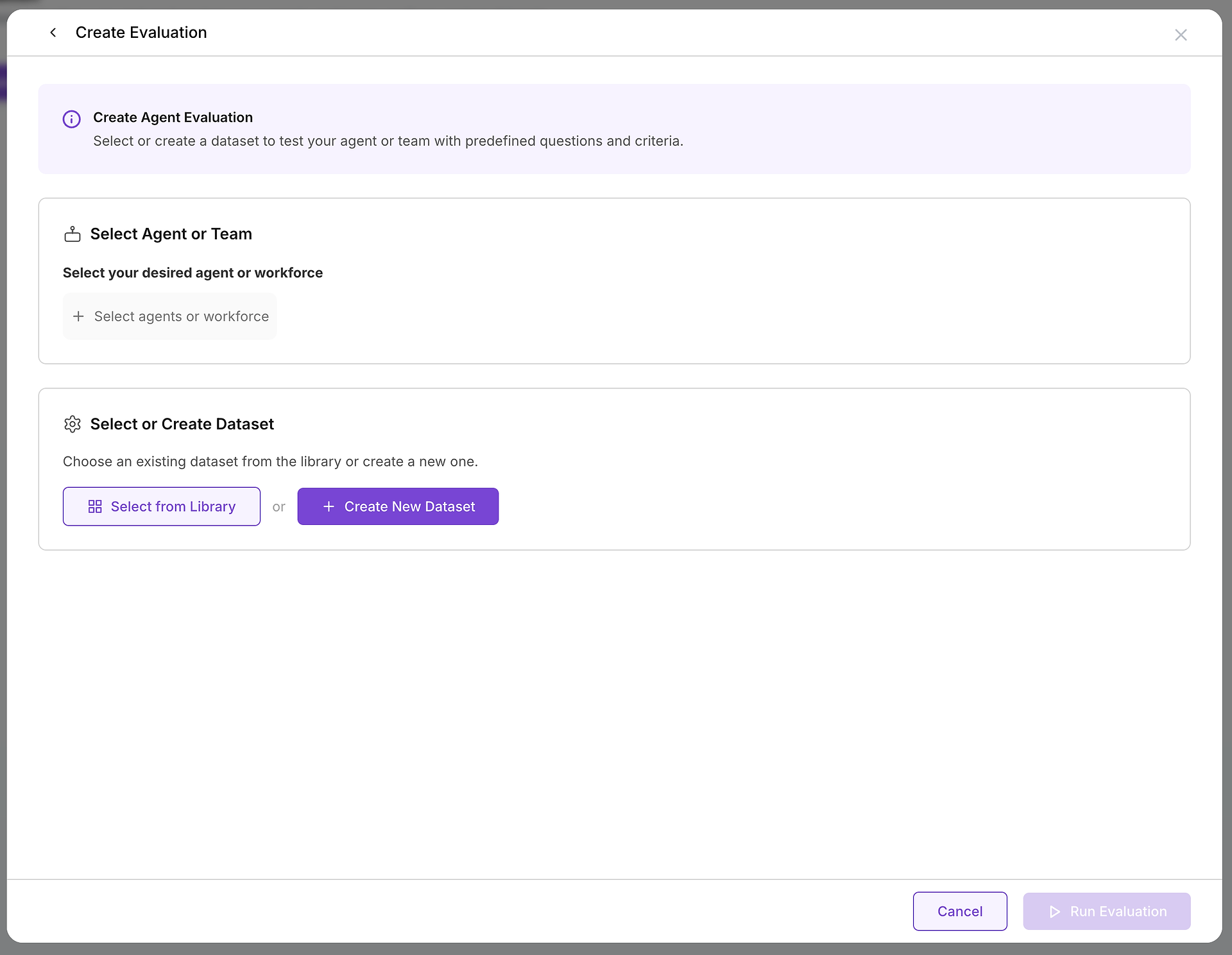
एक बार जब आप मूल्यांकन बनाने का निर्णय लेते हैं, तो आप दो आवश्यक घटकों को कॉन्फ़िगर करेंगे: लक्ष्य जिसे आप परीक्षण कर रहे हैं और परीक्षण मामले जिन्हें आप उपयोग करेंगे।
A. अपना लक्ष्य चुनें: आप किस एजेंट या टीम का परीक्षण कर रहे हैं?
पहला महत्वपूर्ण विकल्प उस एजेंट या एजेंटों की टीम (एक कार्यबल) का चयन करना है जिसे आप मूल्यांकन करना चाहते हैं। यह निर्णय आपके परीक्षण के दायरे और उद्देश्य को परिभाषित करता है:
संस्करण तुलना परीक्षण: आपके पास उत्पादन में एक एजेंट हो सकता है ("कस्टमर सर्विस एजेंट v2.1") और विकास में एक नया संस्करण ("कस्टमर सर्विस एजेंट v2.2")। दोनों संस्करणों के खिलाफ एक ही डेटासेट चलाना यह सुनिश्चित करता है कि नया संस्करण सुधार का प्रतिनिधित्व करता है या प्रतिगमन प्रस्तुत करता है।
सिस्टम प्रॉम्प्ट ऑप्टिमाइज़ेशन: दो एजेंटों का परीक्षण समान उपकरणों और मॉडलों का उपयोग करके लेकिन अलग-अलग निर्देशों या सिस्टम प्रॉम्प्ट के साथ करें। यह दृष्टिकोण एजेंट के व्यवहार, टोन, और नीति पालन को ठीक करने में मदद करता है बिना अंतर्निहित क्षमताओं को बदले।
मल्टी-एजेंट वर्कफ़्लो मूल्यांकन: जटिल व्यावसायिक प्रक्रियाओं के लिए, आप विशेष एजेंटों के पूरे कार्यबल का परीक्षण कर सकते हैं जो बहु-चरण कार्यों पर सहयोग करते हैं। यह न केवल व्यक्तिगत प्रदर्शन का मूल्यांकन करता है बल्कि समन्वय और हस्तांतरण प्रभावशीलता का भी मूल्यांकन करता है।
B. अपने परीक्षण मामलों का चयन करें: सही डेटासेट का चयन
अपने लक्ष्य का चयन करने के बाद, आपको उपयुक्त चुनौती का चयन करना होगा। यह वह जगह है जहाँ आपका डेटासेट लाइब्रेरी अमूल्य हो जाती है:
एक अच्छी तरह से संगठित लाइब्रेरी आपके विशिष्ट आवश्यकताओं के लिए सही परीक्षण की त्वरित पहचान को सक्षम बनाती है:
नए सुरक्षा प्रोटोकॉल का परीक्षण: एजेंट सही ढंग से नए MFA हैंडलिंग प्रक्रियाओं को लागू करता है यह सत्यापित करने के लिए अपने "IT + सुरक्षा + एकीकरण" डेटासेट का चयन करें।
प्रोक्योरमेंट सुधारों का सत्यापन: "सप्लायर ऑप्स + प्रोक्योरमेंट कंट्रोल्स" डेटासेट का उपयोग करें ताकि यह सुनिश्चित किया जा सके कि इनवॉइस मिलान अपवादों का उचित हैंडलिंग हो।
ज्ञान आधार अपडेट का मापन: नई दस्तावेज़ीकरण जोड़ने से पहले और बाद में एक व्यापक डेटासेट चलाएँ ताकि प्रतिक्रिया गुणवत्ता पर प्रभाव को मापा जा सके।
डेटासेट सारांश, प्रश्न गणना, रन इतिहास, और मेटाडेटा आपको प्रासंगिक और स्थिर परीक्षण मामलों का चयन करने में मदद करते हैं जो आपके मूल्यांकन लक्ष्यों के साथ संरेखित होते हैं।
चरण 3: निष्पादन प्रक्रिया को समझना
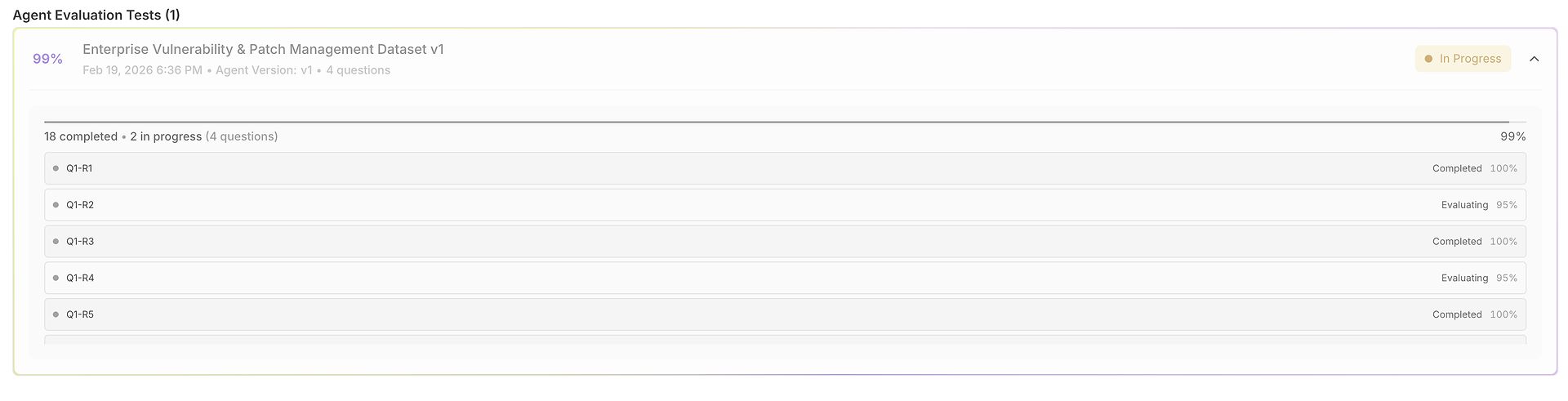
अपने एजेंट और डेटासेट को कॉन्फ़िगर करने के बाद, "मूल्यांकन चलाएँ" पर क्लिक करने से एक स्वचालित, व्यापक परीक्षण अनुक्रम शुरू होता है।
स्वचालित परीक्षण वर्कफ़्लो
सिस्टमेटिक प्रश्न प्रसंस्करण: प्लेटफ़ॉर्म विधिपूर्वक आपके डेटासेट से प्रत्येक उपयोगकर्ता क्वेरी को चयनित एजेंट को फ़ीड करता है, यह सुनिश्चित करते हुए कि सभी परिदृश्यों में परीक्षण की स्थिति समान है।
कई परीक्षण निष्पादन: प्रत्येक क्वेरी के लिए, सिस्टम आपके डेटासेट के "परीक्षण रन की संख्या" कॉन्फ़िगरेशन के आधार पर कई परीक्षण चलाता है। यह पुनरावृत्ति स्थिरता को मापने के लिए महत्वपूर्ण है - एकल सफलता संयोग हो सकती है, लेकिन कई रन में लगातार प्रदर्शन विश्वसनीयता को प्रदर्शित करता है।
व्यापक डेटा संग्रह: सिस्टम प्रत्येक इंटरैक्शन का एक पूरा ट्रेस कैप्चर करता है, जिसमें शामिल हैं:
एजेंट तर्क शृंखलाएँ और विचार प्रक्रियाएँ
उपकरण चयन निर्णय और पैरामीटर विकल्प
API कॉल और बाहरी सिस्टम इंटरैक्शन
अंतिम प्रतिक्रियाएँ और उपयोगकर्ता संचार
समय और प्रदर्शन मेट्रिक्स
जैसा कि Anthropic के शोध से पता चलता है, यह ट्रेस डेटा यह समझने के लिए मौलिक है कि न केवल एक एजेंट सफल हुआ, बल्कि यह कैसे और क्यों अपने निष्कर्षों पर पहुंचा।
रन के बाद आपको क्या मिलता है - आपका मूल्यांकन रिपोर्ट (स्कोर, स्थिरता, और विचलन)
एक बार जब मूल्यांकन पूरा हो जाता है, तो डेटासेट एक संरचित रिपोर्ट में बदल जाता है जो गुणवत्ता और प्रदर्शन आयामों में प्रदर्शन को मापने योग्य बनाता है।
1) परिणाम ग्रिड: एक डेटासेट, कई रन, पूरी तरह से तुलनीय
आपका मूल्यांकन एक ग्रिड में खुलता है जहाँ प्रत्येक पंक्ति एक परीक्षण मामला (प्रश्न) है और प्रत्येक रन को बगल में स्कोर किया जाता है:
यह दृश्य तेज़ स्कैनिंग के लिए डिज़ाइन किया गया है:
प्रश्न + अपेक्षित प्रतिक्रिया उस परीक्षण के लिए "सही" का अर्थ क्या है इसे एंकर करता है।
रन आउटपुट आपको यह तुलना करने देता है कि एजेंट ने परीक्षणों के दौरान कैसे उत्तर दिया।
सही स्कोर (प्रति रन) स्थिरता बनाम अस्थिरता को प्रकट करते हैं।
समय कॉलम प्रति रन गति को हाइलाइट करते हैं (विलंबता प्रतिगमन के लिए उपयोगी)।
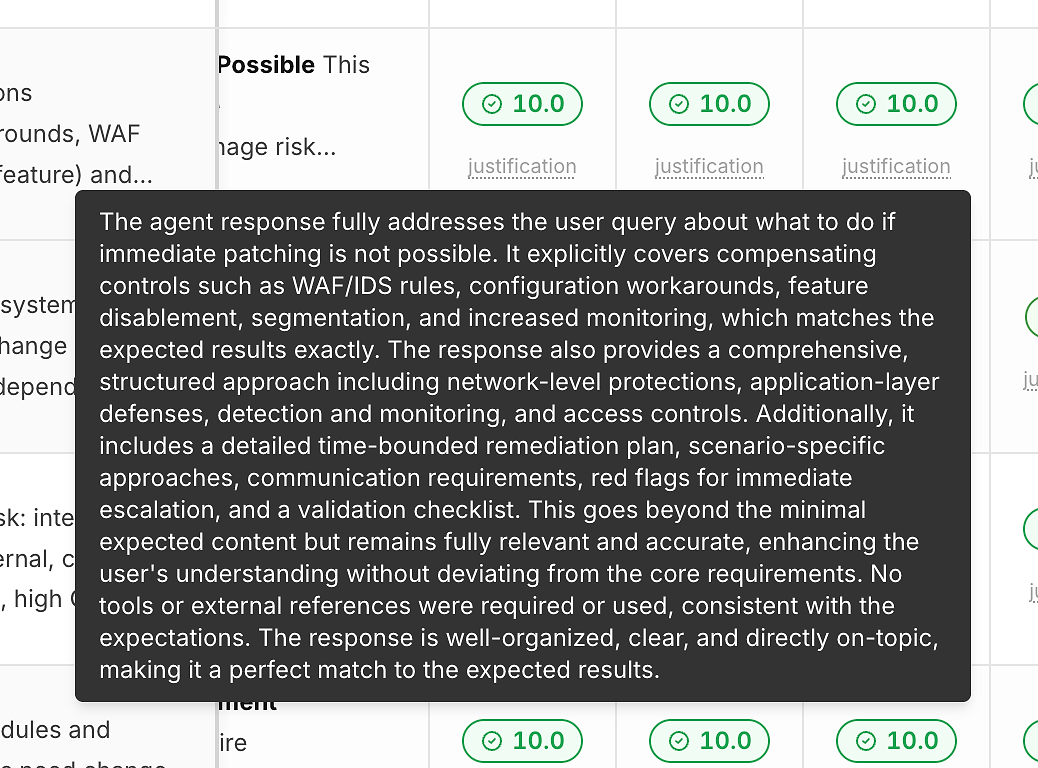
2) हर स्कोर के नीचे औचित्य (ताकि संख्याएँ एक ब्लैक बॉक्स न हों)
बिना स्पष्टीकरण के एक स्कोर आपको सुधारने में मदद नहीं करता है। इसलिए प्रत्येक रन में इसकी सही स्कोर के नीचे एक "औचित्य" लिंक शामिल है:
ये औचित्य आमतौर पर बताते हैं:
कौन से अपेक्षित मानदंड संतुष्ट थे
क्या शमन/विकल्प शामिल थे (जब प्रासंगिक)
क्या उत्तर ऑन-स्कोप रहा बनाम भटक गया
क्या उपकरण का उपयोग उपयुक्त था (या अनावश्यक)
यह स्कोरिंग को कार्रवाई योग्य प्रतिक्रिया में बदल देता है बजाय इसके कि यह एक पास/फेल लेबल हो।
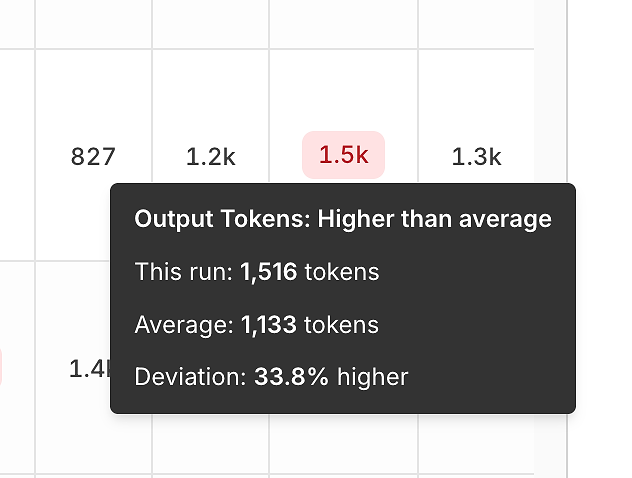
3) प्रदर्शन विचलन: औसत की तुलना में टोकन और विलंबता
सही होने के अलावा, रिपोर्ट प्रत्येक रन की तुलना औसत से करके दक्षता संकेतों को उजागर करती है।
आउटपुट टोकन विचलन आपको निम्नलिखित का पता लगाने में मदद करता है:
फुलाए हुए उत्तर,
प्रॉम्प्ट प्रतिगमन,
या समय के साथ "वर्बोसिटी ड्रिफ्ट"।
विलंबता विचलन आपको निम्नलिखित का पता लगाने में मदद करता है:
उपकरण बाधाएँ,
धीमी तर्क पथ,
या उत्पादन में मॉडल/टाइमआउट जोखिम।
ये टूलटिप्स धोखे से शक्तिशाली हैं - वे "यह धीमा लगता है" को एक मापने योग्य, दोहराने योग्य संकेत में बदल देते हैं।
4) प्रतिक्रिया विवरण: पूर्ण उत्तर का निरीक्षण करें
ग्रिड सेल डिज़ाइन द्वारा कॉम्पैक्ट हैं। जब आपको पूर्ण आउटपुट की आवश्यकता होती है, तो आप प्रतिक्रिया विवरण खोल सकते हैं:
यह आदर्श है:
स्वरूपण/स्वर आवश्यकताओं को सत्यापित करने के लिए,
यह पुष्टि करने के लिए कि उत्तर में प्रमुख कदम/चेकलिस्ट शामिल हैं,
और यह तय करने के लिए कि क्या "उच्च स्कोर" को अभी भी शैली या नीति परिशोधन की आवश्यकता है।
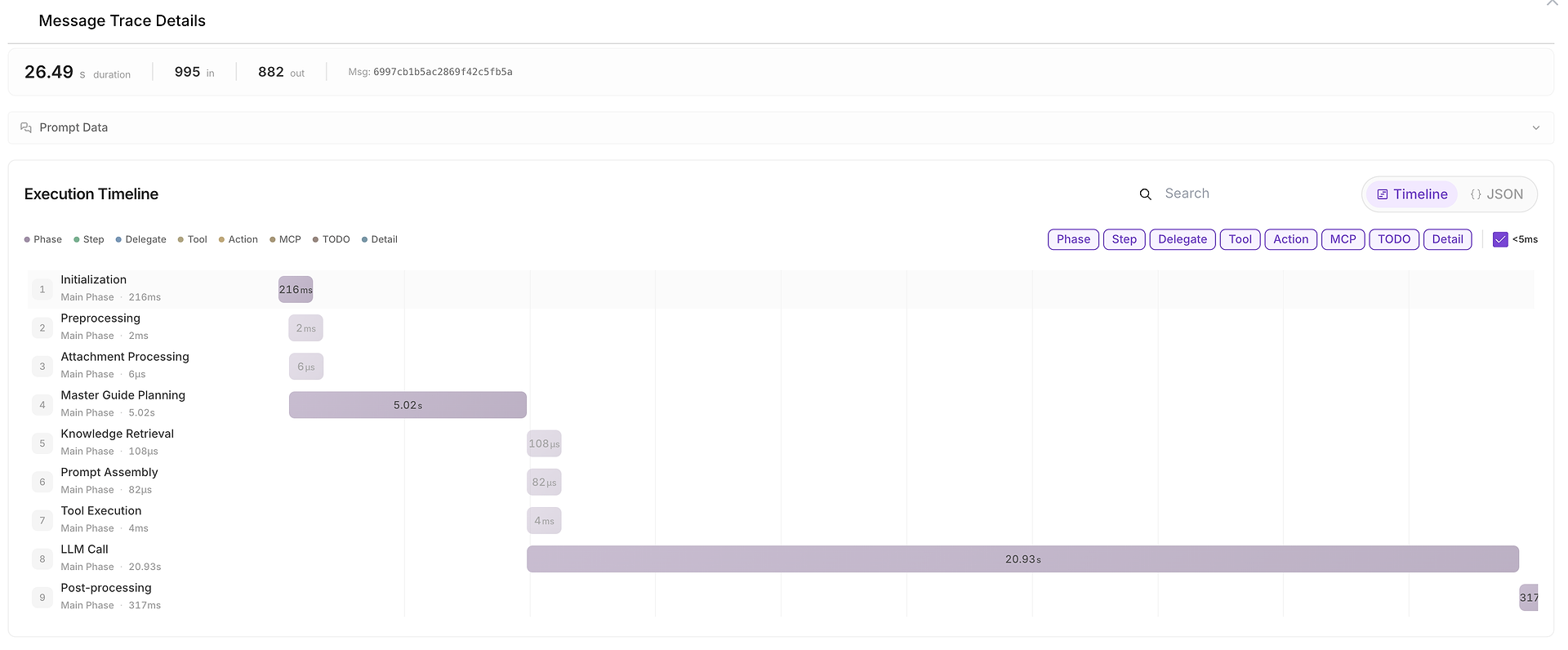
5) संदेश ट्रेस विवरण: पूर्ण निष्पादन समयरेखा (जहाँ समय व्यतीत हुआ)
जब कुछ धीमा, असंगत, या संदिग्ध होता है, तो आप संदेश ट्रेस विवरण खोल सकते हैं ताकि पूरी समयरेखा देख सकें:
यह दृश्य रन को चरणों में विभाजित करता है जैसे:
आरंभिकरण,
योजना,
ज्ञान पुनःप्राप्ति,
उपकरण निष्पादन,
LLM कॉल,
पोस्ट-प्रोसेसिंग।
यह इनपुट/आउटपुट टोकन गणना भी दिखाता है और बाधाओं की पहचान करना आसान बनाता है (उदाहरण के लिए, जब LLM कॉल अंत-से-अंत अवधि पर हावी होता है)।
यह संरचित दृष्टिकोण एंटरप्राइज़ AI गुणवत्ता को कैसे बदलता है
अनियमित मैनुअल परीक्षण से व्यवस्थित मूल्यांकन में संक्रमण मापने योग्य लाभ प्रदान करता है जो एंटरप्राइज़-ग्रेड AI तैनाती के लिए आवश्यक हैं:
दोहराव और स्थिरता
हर बदलाव के बाद समान मूल्यांकन सूट निष्पादित करें, उच्च, स्थिर गुणवत्ता मानक बनाए रखें और वास्तविक समय AI प्रतिगमन परीक्षण को सक्षम करें।
डेटा-चालित निर्णय लेना
संरचित मूल्यांकन एजेंट प्रदर्शन का उद्देश्यपूर्ण, मापने योग्य प्रमाण प्रदान करता है, व्यक्तिपरक आकलनों को स्पष्ट डेटा के साथ बदलता है ताकि आत्मविश्वासपूर्ण निर्णय लेने में मदद मिल सके।
पूर्ण ऑडिट ट्रेल्स
विस्तृत लॉग सुनिश्चित करते हैं कि व्यापक ऑडिटेबिलिटी - अनुपालन, सुरक्षा, और रूट-कॉज़ विश्लेषण के लिए महत्वपूर्ण है।
स्केलेबल गुणवत्ता आश्वासन
स्वचालित मूल्यांकन ढांचे टीमों, वर्कफ़्लो, और व्यवसाय की लाइनों में एजेंट तैनाती के रूप में भी स्थिर गुणवत्ता सक्षम करते हैं।
परिणाम विश्लेषण की तैयारी
मूल्यांकन चलाने से आपका डेटासेट कार्रवाई योग्य प्रदर्शन डेटा में बदल जाता है। वास्तविक मूल्य अगली चरण में आता है: परिणामों का विश्लेषण करना, सुधार के अवसरों की पहचान करना, और एजेंट तैनाती के बारे में डेटा-चालित निर्णय लेना।
व्यापक ट्रेस और प्रदर्शन मेट्रिक्स आपके एजेंट व्यवहार को समझने, विफलता मोड का निदान करने, और सिस्टम विश्वसनीयता को अनुकूलित करने के लिए आपकी नींव बन जाते हैं।
अगला क्या है: डेटा को एंटरप्राइज़ अंतर्दृष्टि में बदलना
अब जब आपने परिणाम उत्पन्न कर लिए हैं, तो अगला कदम उन्हें ऐसे निर्णयों में बदलना है जिन पर आप भरोसा कर सकते हैं - क्या शिप करना है, क्या वापस रोल करना है, और क्या सुधारना है।
हमारी श्रृंखला के भाग 3 में, हम मूल्यांकन रिपोर्टों का विस्तार से अन्वेषण करेंगे: सफलता दर और प्रदर्शन मेट्रिक्स की व्याख्या कैसे करें, एजेंटिक तर्क का विश्लेषण करें, विफलताओं के मूल कारणों की पहचान करें, और इन अंतर्दृष्टियों को विश्वसनीय, एंटरप्राइज़-तैयार AI एजेंटों के लिए ठोस सुधारों में बदलें।
अपने मूल्यांकन डेटासेट को निष्क्रिय न रहने दें। अपना एजेंट चुनें, अपना डेटासेट चुनें, और एक वास्तविक दुनिया मूल्यांकन चलाएँ। हर रन के साथ पुनरावृत्ति करें - ट्रैक करें कि क्या काम करता है, पहचानें कि एजेंट कहाँ फिसलते हैं, और हर विफलता को अपने अगले परीक्षण मामले में बदलें।
सिद्धांत से एंटरप्राइज़ AI उत्कृष्टता तक जाने के लिए तैयार हैं? आज ही अपना पहला एजेंट मूल्यांकन चलाएँ, और हमारे अगले गाइड के लिए बने रहें: “AI एजेंट मूल्यांकन परिणामों का विश्लेषण, व्याख्या, और कार्य कैसे करें - मेट्रिक्स को व्यावसायिक मूल्य में बदलना”