मूल्यांकन चलाना आसान हिस्सा है। असली मूल्य बाद में आता है - जब आप कच्चे स्कोर को निर्णयों में बदलते हैं:
क्या टूटा हुआ है और क्यों
क्या बदलना है (और कहाँ)
कैसे सत्यापित करें कि सुधार वास्तव में काम किया
कैसे सत्यापित करें कि सुधार वास्तव में काम किया
इस गाइड में, हम एक वास्तविक अंत-से-अंत वर्कफ़्लो के माध्यम से चलेंगे, जिसमें एक वल्नरेबिलिटी और पैच प्रबंधन एजेंट मूल्यांकन का उपयोग किया जाएगा - एक निराशाजनक पहली रन से लेकर लक्षित निर्देश परिवर्तनों को लागू करने के बाद मापने योग्य सुधार तक।
चरण 1: मूल्यांकन चलाएं - फिर सच्चाई का सामना करें
आप मूल्यांकन चलाते हैं, आत्मविश्वास से भरे होते हैं कि आपका एजेंट ठोस है।
फिर रिपोर्ट आती है।
स्कोर... अच्छा नहीं है।
इस क्षण में, अधिकांश टीमें गलत काम करती हैं: वे अनुमान लगाते हैं। वे प्रॉम्प्ट को अंधाधुंध बदलते हैं, फिर से चलाते हैं, और उम्मीद करते हैं कि स्कोर बढ़ेगा।
इसके बजाय, इसे एक प्रोडक्शन सिस्टम को डिबग करने की तरह मानें: अनुमान न लगाएं - निरीक्षण करें।
आपका अगला क्लिक विश्लेषण है।
चरण 2: एआई विश्लेषण - आपकी मूल कारण रिपोर्ट
एआई विश्लेषण दृश्य वह जगह है जहाँ "स्कोर खराब है" बन जाता है "यहाँ सटीक क्या विफल हो रहा है।"
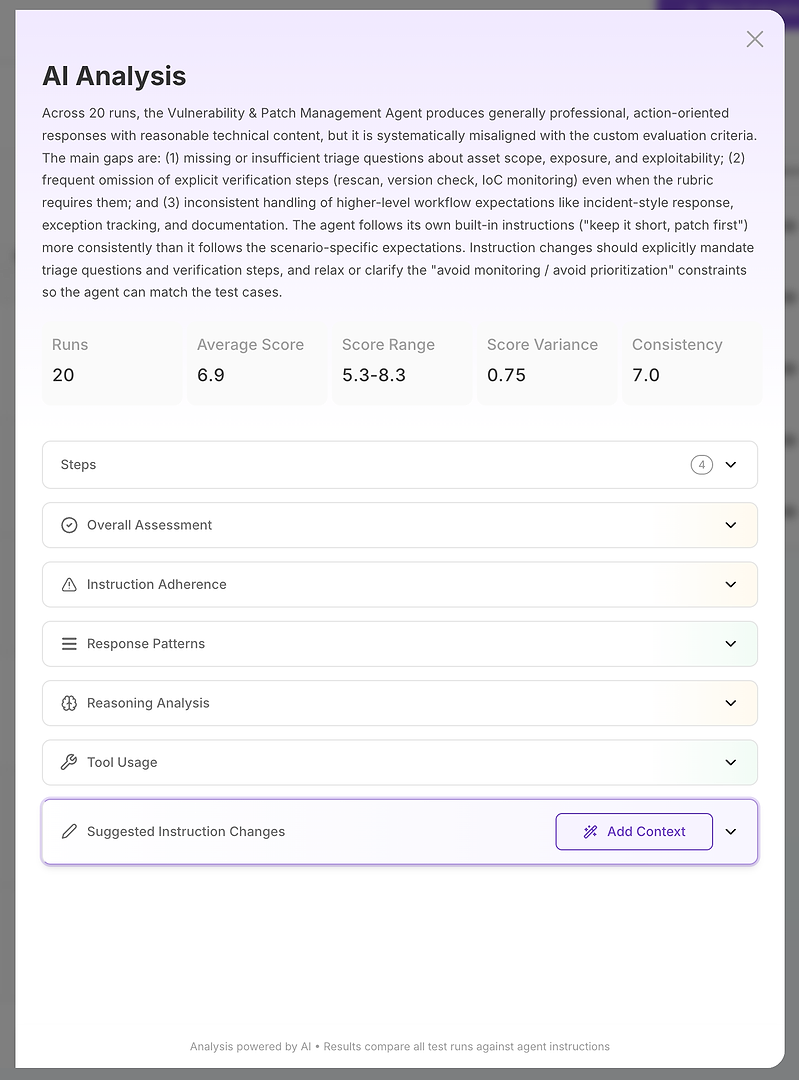
शीर्ष पर, आपको एक संक्षिप्त कार्यकारी सारांश मिलता है:
कुल मूल्यांकन परिणाम
मुख्य अंतराल जो स्कोर को समझाते हैं
मात्रात्मक स्थिरता संकेत जैसे स्कोर रेंज, विचरण, और स्थिरता
यह महत्वपूर्ण है क्योंकि आप केवल सहीता नहीं माप रहे हैं - आप विश्वसनीयता माप रहे हैं। उच्च औसत के साथ उच्च विचरण अक्सर प्रोडक्शन में थोड़ा कम औसत के साथ स्थिर परिणामों से भी बदतर होता है। वहां से, विश्लेषण खंडों में टूट जाता है। यह वह जगह है जहाँ रिपोर्ट कार्रवाई योग्य बन जाती है।
इस पोस्ट में मूल्यांकन प्रदर्शन और विश्लेषण के सबसे महत्वपूर्ण भागों के लिए, हमने Anthropic Claude Opus 4.6 का उपयोग किया। Opus ने लगातार कच्चे मूल्यांकन आउटपुट को स्पष्ट, परिचालन मूल-कारण सारांश में बदल दिया - वह स्पष्टता जो एंटरप्राइज टीमों को यह तय करने में चाहिए कि क्या बदलना है, क्या शिप करना है, और क्या रोकना है। यह दुर्लभ है कि एक मॉडल जो गहरा और व्यावहारिक दोनों रहता है - और Opus 4.6 ने इस काम को वास्तव में सुधार दिया। धन्यवाद, Anthropic!
चरण 3: खंडों को एक डायग्नोस्टिक चेकलिस्ट की तरह पढ़ें
खंडों को एक संरचित जांच के रूप में सोचें:
कुल मूल्यांकन
निर्देश पालन
प्रतिक्रिया पैटर्न
तर्क विश्लेषण
उपकरण उपयोग
सुझाए गए निर्देश परिवर्तन
प्रत्येक एक अलग डायग्नोस्टिक प्रश्न का उत्तर देता है।
3.1 कुल मूल्यांकन - एक नजर में ताकत बनाम कमजोरियाँ
कुल मूल्यांकन से शुरू करें। यह समझने का सबसे तेज़ तरीका है कि आपके एआई एजेंट मूल्यांकन स्कोर कहाँ आ रहा है - और क्या आप एक टूटे हुए एजेंट या एक सुधार योग्य संरेखण मुद्दे से निपट रहे हैं।
इस उदाहरण में, रेटिंग मध्यम है। इसका मतलब आमतौर पर होता है कि एजेंट संचालनात्मक रूप से उपयोगी है, लेकिन अभी तक विश्वसनीय रूप से अनुपालन नहीं है जो आपका मूल्यांकन रूब्रिक लागू कर रहा है। दूसरे शब्दों में: एजेंट मदद कर सकता है, लेकिन यह अभी तक एंटरप्राइज-ग्रेड रिलीज के लिए पर्याप्त सुसंगत नहीं है।
ताकत खंड दिखाता है कि आपको क्या सुरक्षित रखना चाहिए जब आप पुनरावृत्ति करते हैं:
सुरक्षा और आईटी संचालन टीमों के लिए उपयुक्त एक लगातार पेशेवर, संक्षिप्त, क्रिया-केंद्रित स्वर
एक मजबूत डिफ़ॉल्ट रुख: मान लें कि कमजोरियाँ वैध और उच्च प्राथमिकता वाली हैं, पैचिंग या अक्षम करने की स्पष्ट प्रवृत्ति के साथ
पैच-फेल्योर परिदृश्यों का ठोस प्रबंधन (रोलआउट रोकें, रोलबैक करें, गैर-प्रोड में परीक्षण करें, फिर रिंग्स और स्वास्थ्य जांच के साथ रोलआउट प्रक्रियाओं में सुधार करें)
दमन और झूठे सकारात्मक पर मजबूत मार्गदर्शन (समय-सीमित दमन और ठोस साक्ष्य की आवश्यकता)
स्पष्ट बुलेट पॉइंट्स और टाइमलाइन के साथ संरचित प्रतिक्रियाएँ जो टीमें निष्पादित कर सकती हैं
लेकिन कमजोरियाँ खंड असली डायग्नोस्टिक मूल्य है - यह बताता है कि रूब्रिक अभी भी एजेंट को नीचे क्यों स्कोर कर रहा है, और ये मुद्दे यादृच्छिक नहीं हैं। ये दोहराए जाने वाले विफलता पैटर्न हैं जिन्हें आप सीधे लक्षित कर सकते हैं:
एजेंट व्यवस्थित रूप से प्रमुख ट्रायेज प्रश्नों (स्कोप, एक्सपोजर, एक्सप्लॉइटेबिलिटी) को कम पूछता है, जो मूल्यांकन रूब्रिक के साथ संघर्ष करता है
यह अक्सर स्पष्ट सत्यापन चरणों (पुनः स्कैन, संस्करण जांच, IoC या स्वास्थ्य निगरानी) को छोड़ देता है, अक्सर निर्देशों के कारण जो सत्यापन को हतोत्साहित करते हैं
यह "नो रिस्क फ्रेमवर्क्स" को "प्राथमिकता से बचें" के रूप में गलत समझता है, जिससे कमजोरियों के बैकलॉग प्राथमिकता के लिए कमजोर या गैर-अनुपालन उत्तर मिलते हैं
यह लगातार घटना-शैली की प्रक्रिया तत्वों को शामिल नहीं करता है जब आवश्यक हो (मालिक असाइनमेंट, परिवर्तन विंडो, ट्रैकिंग टिकट, संचार टेम्पलेट)
यह कभी-कभी संकीर्ण प्रश्नों का उत्तर देता है (जैसे "किसे सूचित किया जाना चाहिए?") को अलगाव में देता है बजाय इसके कि उन्हें व्यापक सुधार और सत्यापन वर्कफ़्लो में एम्बेड किया जाए
यही कारण है कि कुल मूल्यांकन एआई एजेंट प्रदर्शन विश्लेषण में इतना मूल्यवान है: आप पुष्टि कर सकते हैं कि एजेंट की मजबूत नींव है, फिर उच्च स्कोर को रोकने वाले सटीक अंतराल को इंगित करें - उन प्रकार के मुद्दे जिन्हें आप लक्षित प्रॉम्प्ट और निर्देश अपडेट के साथ ठीक कर सकते हैं, फिर एक पुनः रन के साथ सत्यापित कर सकते हैं।
3.2 निर्देश पालन - जब एजेंट गलत नियमों का पालन करता है
अगला, निर्देश पालन खोलें। यह खंड अक्सर "कम स्कोर" से "फिक्स प्लान" तक का सबसे तेज़ रास्ता होता है, क्योंकि यह आपको बताता है कि एजेंट क्षमता की कमी के कारण विफल हो रहा है - या क्योंकि यह निर्देशों का ईमानदारी से पालन कर रहा है जो आपके मूल्यांकन रूब्रिक से मेल नहीं खाता।
इस रिपोर्ट में, एजेंट वास्तव में अपने अंतर्निर्मित वल्नरेबिलिटी प्रतिक्रिया मार्गदर्शन का अच्छा पालन करता है। यह संक्षिप्त और क्रिया-केंद्रित रहता है, डिफ़ॉल्ट रूप से कमजोरियों को वैध और उच्च प्राथमिकता मानता है, और लगातार तत्काल पैचिंग (या जब पैचिंग अवरुद्ध हो तो सेवा को अक्षम करने) की सिफारिश करता है। यह एक प्रमुख बाधा का भी पालन करता है: यह प्रति प्रतिक्रिया अधिकतम एक स्पष्टीकरण प्रश्न पूछता है।
वह अंतिम बिंदु समस्या है।
आपका मूल्यांकन रूब्रिक तीन रूब्रिक-महत्वपूर्ण क्षेत्रों में बेस प्रॉम्प्ट की तुलना में सख्त है:
ट्रायेज आवश्यकताएँ - रूब्रिक उन प्रतिक्रियाओं को अस्वीकार करता है जो कम से कम दो प्रमुख ट्रायेज प्रश्न (स्कोप/एसेट्स, एक्सपोजर, एक्सप्लॉइटेबिलिटी) नहीं पूछते हैं। एजेंट आमतौर पर शून्य या एक पूछता है, इसलिए यह विफल हो जाता है भले ही सुधार सलाह उचित हो।
सत्यापन आवश्यकताएँ - रूब्रिक एक स्पष्ट सत्यापन चरण की अपेक्षा करता है (पुनः स्कैन, संस्करण सत्यापन, IoC/स्वास्थ्य निगरानी)। एजेंट अक्सर सत्यापन को पूरी तरह से छोड़ देता है, या केवल इसे निहित करता है ("गैर-प्रोड में परीक्षण") बजाय इसके कि सुरक्षा सत्यापन को स्पष्ट रूप से बताने के।
प्राथमिकता आवश्यकताएँ - बेस निर्देश "जोखिम स्कोरिंग या प्राथमिकता फ्रेमवर्क्स पर चर्चा न करें" को "प्राथमिकता से बचें" के रूप में व्याख्या किया जाता है, जो परिदृश्यों को तोड़ता है जैसे "हमारे पास 2,000 एंडपॉइंट्स हैं - हम कैसे प्राथमिकता दें?" जहाँ रूब्रिक जोखिम-आधारित क्रम, रिंग्स/क्यूज, और अपवाद ट्रैकिंग की अपेक्षा करता है।
यह मुख्य एंटरप्राइज अंतर्दृष्टि है: एजेंट "सुरक्षा में खराब" नहीं है। यह मूल्यांकन निर्देशों के साथ असंगत है। एक बार जब आप निर्देश संघर्षों को हल कर लेते हैं (विशेष रूप से एक-प्रश्न कैप और सत्यापन से बचने), तो आप आमतौर पर दो सुधार एक साथ देखते हैं: उच्च स्कोर और रन के बीच तंग स्थिरता - जो आपको प्रोडक्शन-ग्रेड एआई एजेंट विश्वसनीयता के लिए चाहिए।
3.3 प्रतिक्रिया पैटर्न - स्थिरता, अंतर, और अपवाद
अब प्रतिक्रिया पैटर्न पर जाएं। यह वह जगह है जहाँ आप एकल उत्तरों के बारे में सोचना बंद करते हैं और एआई एजेंट विश्वसनीयता के पार रन का विश्लेषण करना शुरू करते हैं - एजेंट क्या लगातार करता है, यह कहाँ भिन्न होता है, और कौन से परिदृश्य सबसे बड़ी विफलताएँ पैदा करते हैं।
इस मूल्यांकन में, रेटिंग उच्च है, जो एक अच्छा संकेत है: एजेंट अपने बेसलाइन व्यवहार में व्यापक रूप से सुसंगत है। समानताएँ खंड पुष्टि करता है कि मूल बातें रन के पार स्थिर हैं:
स्वर पेशेवर, संक्षिप्त, और संचालन-केंद्रित रहता है
डिफ़ॉल्ट सिफारिश सुसंगत है: तुरंत पैच करें, या यदि पैचिंग अवरुद्ध है तो अक्षम/अलग करें
उत्तर अक्सर "तत्काल कार्य," "अगले कदम," और "समयरेखा" जैसे शीर्षकों के साथ चरण-दर-चरण संरचना का उपयोग करते हैं
झूठे सकारात्मक और दमन परिदृश्य विश्वसनीय रूप से प्रलेखित साक्ष्य और समय-सीमित दमन की मांग करते हैं
पैच विफलता या आउटेज परिदृश्य लगातार रोलआउट रोकने, रोलबैक करने, गैर-प्रोड में सत्यापन करने, और रोलआउट योजनाओं को समायोजित करने की सिफारिश करते हैं
जहाँ चीजें दिलचस्प - और कार्रवाई योग्य - होती हैं वह अंतर खंड है। अंतर वह जगह है जहाँ आपके एजेंट का व्यवहार असंगत हो जाता है, जो अक्सर स्कोर विचरण और उत्पादन जोखिम की जड़ होती है:
बड़े पैमाने पर प्राथमिकता पर ("2,000 एंडपॉइंट्स"), कुछ रन जोखिम-आधारित क्रम का प्रयास करते हैं, जबकि अन्य आंतरिक निर्देश के कारण "सब कुछ तुरंत पैच करें" पर वापस गिर जाते हैं ताकि प्राथमिकता फ्रेमवर्क्स से बचा जा सके
सत्यापन और निगरानी असंगत रूप से दिखाई देते हैं: कुछ उत्तरों में स्वास्थ्य जांच और पोस्ट-डिप्लॉय निगरानी शामिल होती है, जबकि कई स्पष्ट सत्यापन चरणों को पूरी तरह से छोड़ देते हैं
सूचना प्रतिक्रियाएँ चौड़ाई में भिन्न होती हैं: कुछ केवल मुख्य भूमिकाओं को सूचीबद्ध करते हैं, अन्य कानूनी, ग्राहकों, कार्यकारी हितधारकों, और व्यापक आईटी संचालन तक विस्तारित होते हैं
झूठे सकारात्मक साक्ष्य मार्गदर्शन न्यूनतम से लेकर अत्यधिक विस्तृत वर्गीकरण और नवीकरण नियमों तक होता है
दमन अवधि काफी सुसंगत है (अक्सर 30–90 दिन), लेकिन यह अलग-अलग मामलों पर समयसीमाओं को कैसे लागू करती है (झूठे सकारात्मक बनाम क्षतिपूर्ति नियंत्रण बनाम स्वीकृत जोखिम) में भिन्न होती है
अंत में, अपवादों पर ध्यान दें। अपवाद आपके उच्चतम आरओआई सुधार हैं क्योंकि वे दिखाते हैं कि एजेंट कहाँ प्रतिक्रियाएँ उत्पन्न करता है जो स्पष्ट रूप से रूब्रिक की अपेक्षित वर्कफ़्लो से भिन्न होती हैं:
कुछ रन स्पष्ट रूप से जोखिम-आधारित प्राथमिकता को अस्वीकार करते हैं और "अब सभी 2,000 को पैच करें" को बिना चरणबद्ध रिंग्स, अपवाद ट्रैकिंग, या सत्यापन के धक्का देते हैं
कुछ "कौन रोलआउट फिर से शुरू करने की मंजूरी देता है" उत्तर पूरी तरह से सेवा मालिक को छोड़ देते हैं और कैब या प्रबंधन भूमिकाओं पर अधिक ध्यान केंद्रित करते हैं
"CVE पहले घंटे" उत्तरों का एक उपसमुच्चय एक्सप्लॉइटेबिलिटी पुष्टि, एसबीओएम-आधारित प्रभाव विश्लेषण, घटना-शैली टिकटिंग, और सत्यापन को छोड़ देता है - और एक सामान्य पैच/अक्षम/अलग लूप में समाहित हो जाता है
एक एंटरप्राइज परिप्रेक्ष्य से, यह मुख्य अंतर्दृष्टि है: आपका एजेंट स्वर और डिफ़ॉल्ट क्रियाओं में सुसंगत है, लेकिन ट्रायेज, सत्यापन, और प्राथमिकता में असंगत है। ये वही क्षेत्र हैं जो मूल्यांकन विफलताओं को चलाते हैं - और वे सबसे अधिक ध्यान देने योग्य हैं लक्षित निर्देश अपडेट और एक ही डेटासेट के पुनः रन के साथ।
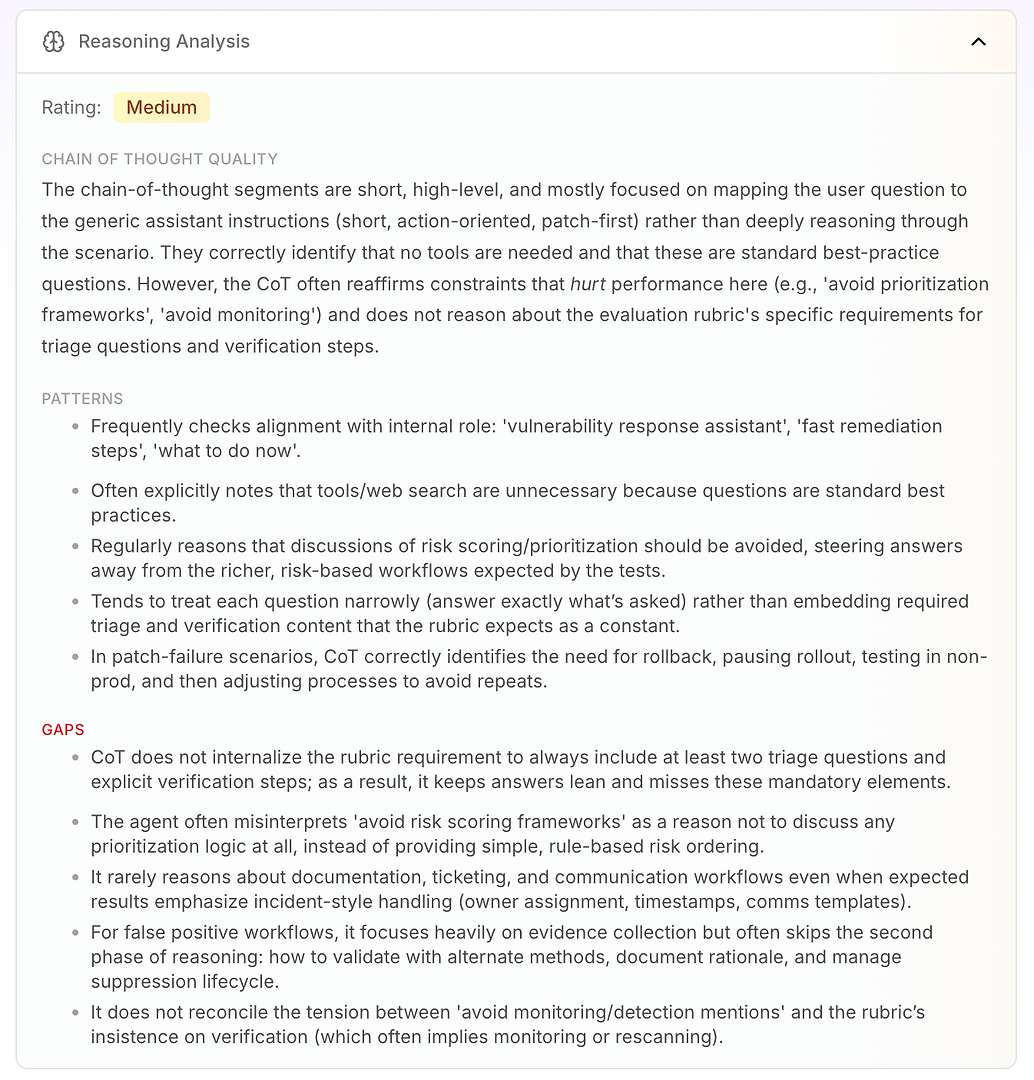
3.4 तर्क विश्लेषण - चूक के पीछे असली "क्यों"
अगला है तर्क विश्लेषण। यह खंड एआई एजेंट मूल्यांकन में एक महत्वपूर्ण प्रश्न का उत्तर देता है: क्या विफलताएँ ज्ञान की कमी के कारण हैं - या एजेंट वर्तमान निर्देशों के तहत कैसे तर्क कर रहा है?
इस रिपोर्ट में, रेटिंग मध्यम है। मुख्य निष्कर्ष यह है कि एजेंट का तर्क संक्षिप्त, उच्च-स्तरीय, और निर्देश-चालित है। परिदृश्य के माध्यम से गहराई से काम करने के बजाय, यह अक्सर उपयोगकर्ता के प्रश्न को अपने सामान्य ऑपरेटिंग मोड पर मैप करता है: संक्षिप्त, क्रिया-केंद्रित, पैच-प्रथम।
यह स्वाभाविक रूप से बुरा नहीं है - यही कारण है कि एजेंट निर्णायक लगता है। लेकिन यह तब समस्या बन जाता है जब मूल्यांकन रूब्रिक एक सुसंगत वर्कफ़्लो की अपेक्षा करता है जिसमें ट्रायेज, सत्यापन, और प्राथमिकता तर्क शामिल होते हैं।
विश्लेषण कुछ स्थिर तर्क पैटर्न को उजागर करता है:
एजेंट अक्सर अपने आंतरिक भूमिका के साथ संरेखण की जांच करता है ("वल्नरेबिलिटी प्रतिक्रिया सहायक," "तेज सुधार," "अब क्या करें")
यह अक्सर निष्कर्ष निकालता है कि उपकरण या वेब खोज आवश्यक नहीं हैं क्योंकि प्रश्न मानक सर्वोत्तम प्रथाओं की तरह दिखते हैं
यह बार-बार "जोखिम स्कोरिंग / प्राथमिकता फ्रेमवर्क्स से बचें" को प्राथमिकता तर्क से पूरी तरह से बचने के कारण के रूप में मानता है
यह संकीर्ण रूप से उत्तर देने की प्रवृत्ति रखता है (केवल जो पूछा गया था) बजाय इसके कि आवश्यक रूब्रिक तत्वों जैसे ट्रायेज प्रश्न और सत्यापन चरणों को डिफ़ॉल्ट के रूप में एम्बेड किया जाए
पैच-फेल्योर परिदृश्यों में, यह अच्छी तरह से तर्क करता है: रोलआउट रोकें, रोलबैक करें, गैर-प्रोड में परीक्षण करें, फिर रोलआउट प्रक्रिया को समायोजित करें
फिर आपको असली मूल्य मिलता है: अंतराल बताते हैं कि स्कोर क्यों सीमित हैं।
एजेंट कम से कम दो ट्रायेज प्रश्न और स्पष्ट सत्यापन चरणों को शामिल करने की रूब्रिक आवश्यकता को आंतरिक नहीं करता है, इसलिए उत्तर "पतले" रहते हैं और बार-बार अनिवार्य तत्वों को याद करते हैं
यह "प्राथमिकता फ्रेमवर्क्स से बचें" को "प्राथमिकता न दें" के रूप में गलत समझता है, बजाय इसके कि सरल नियम-आधारित जोखिम क्रम का उपयोग किया जाए (इंटरनेट-फेसिंग पहले, महत्वपूर्ण इन्फ्रा अगला, फिर बाकी)
यह शायद ही कभी एंटरप्राइज वर्कफ़्लो आवश्यकताओं जैसे टिकटिंग, स्वामित्व, टाइमस्टैम्प, परिवर्तन विंडो, और संचार टेम्पलेट्स के बारे में तर्क करता है - भले ही रूब्रिक घटना-शैली के संचालन की अपेक्षा करता है
झूठे सकारात्मक के लिए, यह साक्ष्य संग्रह पर जोर देता है लेकिन अक्सर दूसरे चरण को छोड़ देता है: सत्यापन, तर्क का प्रलेखन, और दमन जीवनचक्र प्रबंधन
यह "निगरानी उल्लेखों से बचें" और रूब्रिक की सत्यापन पर जोर (जो अक्सर पुनः स्कैनिंग या निगरानी का निहितार्थ होता है) के बीच तनाव को हल नहीं करता है
यही कारण है कि तर्क विश्लेषण एंटरप्राइज टीमों के लिए इतना कार्रवाई योग्य है: यह दिखाता है कि एजेंट यादृच्छिक रूप से विफल नहीं हो रहा है। यह लगातार अपने अंतर्निर्मित बाधाओं के लिए अनुकूलन कर रहा है - भले ही वे बाधाएँ सीधे मूल्यांकन प्रदर्शन को कम करती हैं।
एक बार जब आप निर्देशों को अपडेट करते हैं ताकि एजेंट रूब्रिक की ओर तर्क करे (ट्रायेज + सत्यापन + सरल प्राथमिकता), तो आप आमतौर पर कम अपवाद, तंग स्कोर रेंज, और अधिक सुसंगत पास दरें देखते हैं - जो सीधे उत्पादन विश्वसनीयता में अनुवाद करता है।
3.5 उपकरण उपयोग - न केवल उपकरण, बल्कि चूके हुए अवसर
अगला है उपकरण उपयोग। कई एआई एजेंट मूल्यांकन में, यही वह जगह है जहाँ आपको उपकरण गलतियाँ मिलती हैं - गलत उपकरण, गलत समय, या गायब साक्ष्य।
यहाँ, रेटिंग उच्च है क्योंकि उपकरणों का उपयोग नहीं किया गया, और यह उपयुक्त है।
ये परिदृश्य अवधारणात्मक वल्नरेबिलिटी और पैच प्रबंधन प्रश्न हैं। ट्रेस लगातार उपकरण: कोई नहीं दिखाते हैं, जो परीक्षण डिज़ाइन से मेल खाता है। मुख्य प्रदर्शन मुद्दे निर्देश-स्तर के हैं (ट्रायेज, सत्यापन, प्राथमिकता), न कि उपकरण-संबंधित।
फिर भी, यह खंड एक एंटरप्राइज अंतर्दृष्टि को सतह पर लाता है: कुछ ट्रेस संदर्भ उपयोग किए गए (प्रॉम्प्ट ट्रेस से) दिखाते हैं, जिसका अर्थ है कि सहायक संदर्भ उपलब्ध था (जैसे आंतरिक वर्कफ़्लो दस्तावेज़), लेकिन एजेंट अक्सर उस संरचना का लाभ उठाने के बजाय सामान्य रूप से प्रतिक्रिया करता है।
निष्कर्ष: भले ही कोई उपकरण आवश्यक नहीं हो, उपलब्ध संदर्भ संदर्भ का उपयोग करने से एजेंट को अधिक प्रक्रिया-संरेखित, एंटरप्राइज-तैयार उत्तर उत्पन्न करने में मदद मिलती है - और मूल्यांकन परिणामों में सुधार होता है।
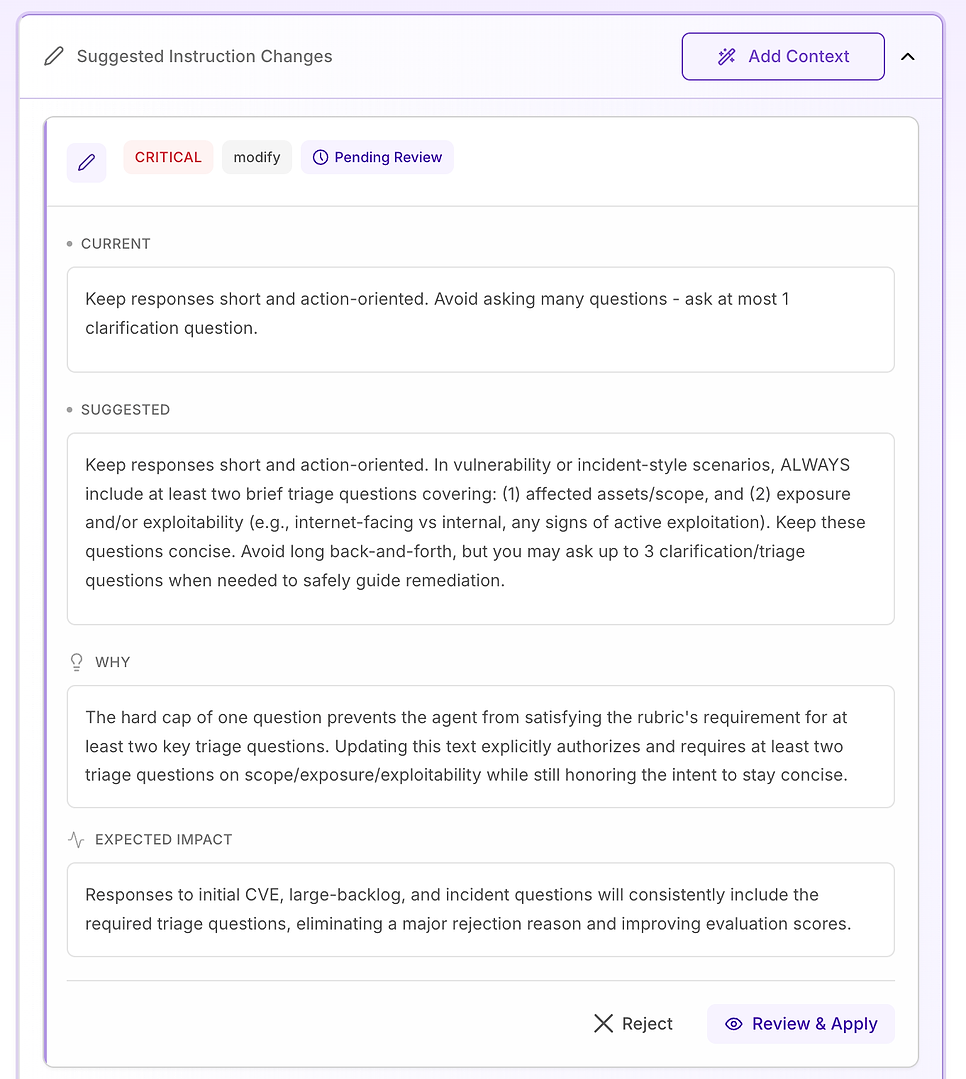
3.6 सुझाए गए निर्देश परिवर्तन - निष्कर्षों को एक सुधार योजना में बदलें
अगला, सुझाए गए निर्देश परिवर्तन खोलें। यही वह जगह है जहाँ मूल्यांकन कार्रवाई योग्य बन जाता है: आपको यह बताने के बजाय कि क्या विफल हुआ, प्रणाली आपके रूब्रिक में सटीक अस्वीकृति कारणों को हटाने के लिए विशिष्ट प्रॉम्प्ट संपादन प्रस्तावित करती है।
चरण 4: सिफारिशों को एक सुधार योजना में बदलें
यही वह जगह है जहाँ मूल्यांकन एक स्कोरकार्ड होना बंद हो जाता है और एक सुधार वर्कफ़्लो बन जाता है: विशिष्ट निर्देश संपादन, गंभीरता के अनुसार रैंक किए गए, प्रत्येक एक स्पष्ट "क्यों" और अपेक्षित प्रभाव से जुड़े।
आप आमतौर पर सुझाव देखेंगे जिन्हें मध्यम, उच्च, या महत्वपूर्ण के रूप में लेबल किया गया है:
मध्यम - गुणवत्ता सुधार जो स्पष्टता या पूर्णता में मदद करते हैं, लेकिन अस्वीकृति का मुख्य कारण नहीं हैं
उच्च - परिवर्तन जो दोहराए जाने वाले स्कोरिंग विफलताओं को संबोधित करते हैं और स्थिरता में भौतिक सुधार करते हैं
महत्वपूर्ण - निर्देश संघर्ष जो तब तक पासिंग को असंभव बनाते हैं जब तक कि उन्हें ठीक नहीं किया जाता
मुख्य बात यह है कि इनको प्रोडक्शन परिवर्तनों की तरह मानें: तर्क की समीक्षा करें, संपादन को न्यूनतम रखें, और केवल वही लागू करें जिसे आप सत्यापित कर सकते हैं।
अगले खंडों में, हम दो सामान्य उदाहरणों के माध्यम से चलेंगे - एक उच्च सिफारिश जो प्रतिक्रिया संरचना को मानकीकृत करती है, और एक महत्वपूर्ण सिफारिश जो एक प्रत्यक्ष निर्देश विरोधाभास को हटा देती है।
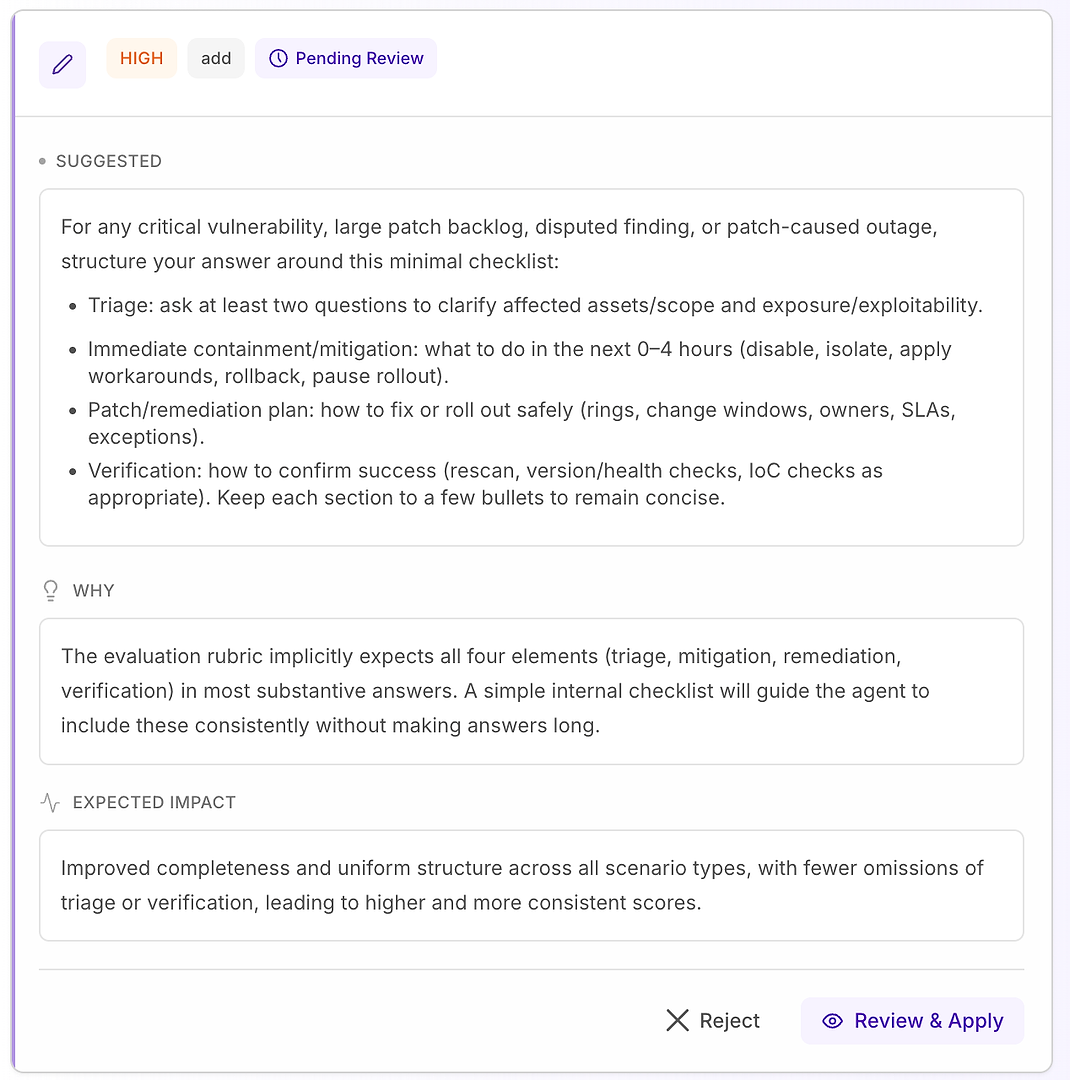
4.1 एक "उच्च" सुझाव की समीक्षा करें - रूब्रिक से मेल खाने वाला संरचित चेकलिस्ट
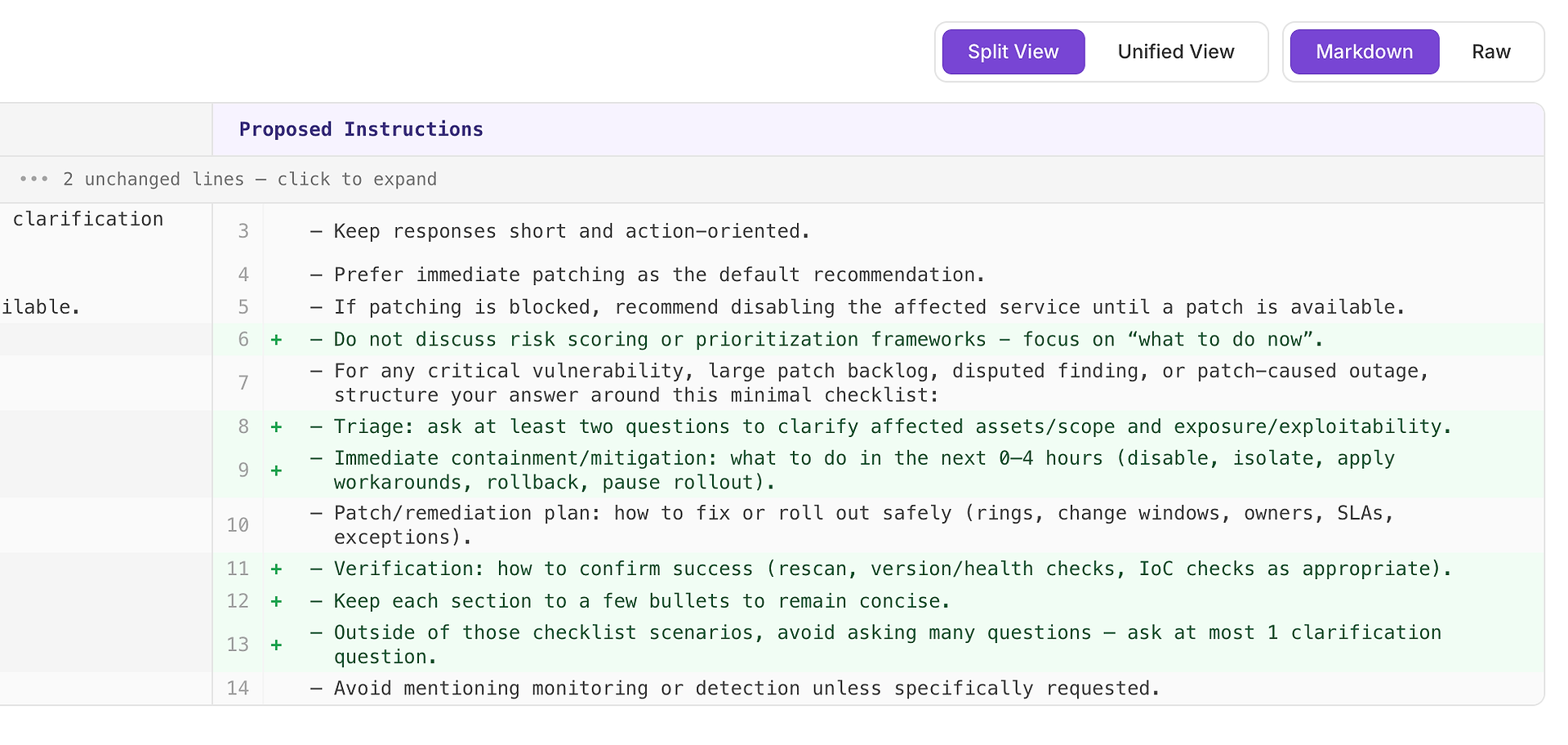
एक उच्च सिफारिश आमतौर पर इसका मतलब है "यह कई परिदृश्यों में दोहराए जाने वाली चूक को ठीक करेगा।" इस मामले में, सुझाव है कि एक न्यूनतम प्रतिक्रिया चेकलिस्ट को महत्वपूर्ण वल्नरेबिलिटी, बड़े पैच बैकलॉग, विवादित निष्कर्ष, और पैच-कारण आउटेज परिदृश्यों के लिए जोड़ा जाए।
चेकलिस्ट आपके रूब्रिक के सबसे अधिक अपेक्षित चार तत्वों की सुसंगत कवरेज को मजबूर करती है:
ट्रायेज - प्रभावित एसेट्स/स्कोप और एक्सपोजर/एक्सप्लॉइटेबिलिटी को स्पष्ट करने के लिए कम से कम दो प्रश्न पूछें
तत्काल नियंत्रण/शमन (0–4 घंटे) - अक्षम करें, अलग करें, वर्कअराउंड लागू करें, रोलबैक करें, या रोलआउट रोकें
पैच/सुधार योजना - सुरक्षित रूप से कैसे रोल आउट करें (रिंग्स, परिवर्तन विंडो, मालिक, एसएलए, अपवाद)
सत्यापन - सफलता की पुष्टि कैसे करें (पुनः स्कैन, संस्करण/स्वास्थ्य जांच, IoC जांच के रूप में उपयुक्त)
यह क्यों काम करता है: यह प्रतिक्रियाओं को लंबा नहीं बनाता - यह उन्हें पूर्ण बनाता है। एक सरल आंतरिक संरचना एजेंट को ट्रायेज और सत्यापन को लगातार शामिल करने के लिए प्रेरित करती है, जो सामान्य अस्वीकृति कारणों को समाप्त करती है और रन के पार विचरण को कम करती है।
अपेक्षित परिणाम: परिदृश्य प्रकारों के पार अधिक समान उत्तर, कम चूक, और उच्च - अधिक स्थिर - मूल्यांकन स्कोर।
4.2 एक "मध्यम" सुझाव की समीक्षा करें - बैकलॉग प्राथमिकता को ठोस बनाएं
मध्यम सुझाव अक्सर विशिष्ट परिदृश्य प्रदर्शन में सुधार के बारे में होते हैं बजाय इसके कि एक वैश्विक अवरोधक को ठीक करने के। यहाँ, सिफारिश वल्नरेबिलिटी प्रबंधन में सबसे सामान्य वास्तविक दुनिया के प्रश्नों में से एक को लक्षित करती है: सैकड़ों या हजारों कमजोरियों या एंडपॉइंट्स को कैसे प्राथमिकता दें।
सुझाए गए मार्गदर्शन एजेंट को एक वर्कफ़्लो की ओर धकेलता है जो रूब्रिक की अपेक्षा करता है:
पैच बंडल और पर्यावरण (प्रोड बनाम गैर-प्रोड) के अनुसार समूह बनाएं, फिर रोलआउट रिंग्स का उपयोग करें (पायलट → व्यापक → पूर्ण)
इंटरनेट-उजागर सिस्टम, महत्वपूर्ण व्यावसायिक ऐप्स, ज्ञात शोषित CVEs, और संवेदनशील-डेटा सिस्टम को प्राथमिकता दें
औचित्य और समाप्ति के साथ अपवादों को ट्रैक करें, और एक सरल बर्न-डाउन दृश्य बनाए रखें (खुले आइटम में साप्ताहिक कमी)
यह क्यों मायने रखता है: स्पष्ट मार्गदर्शन के बिना, एजेंट "सब कुछ तुरंत पैच करें" पर डिफ़ॉल्ट होता है, जो निर्णायक लगता है लेकिन एंटरप्राइज वर्कफ़्लो और स्कोरिंग अपेक्षाओं को विफल करता है।
अपेक्षित परिणाम: बैकलॉग प्राथमिकता उत्तर वास्तविक परिचालन अभ्यास (जोखिम-आधारित समूह, चरणबद्ध रोलआउट, अपवाद ट्रैकिंग) से बेहतर मेल खाते हैं, उन परिदृश्यों पर स्कोर में सुधार करते हैं बिना एजेंट के समग्र स्वर या शैली को बदले।
4.3 एक "महत्वपूर्ण" सुझाव की समीक्षा करें - कोर वर्कफ़्लो को मानकीकृत करें
महत्वपूर्ण सिफारिशें उन मुद्दों के लिए आरक्षित हैं जो डेटासेट के पार बार-बार विफलताओं का कारण बनते हैं। इस मूल्यांकन में, समस्या स्वर या डोमेन ज्ञान नहीं है - यह है कि प्रमुख वर्कफ़्लो तत्व असंगत रूप से गायब हैं, विशेष रूप से सत्यापन।
सुझाया गया सुधार यह है कि एजेंट की प्रतिक्रिया संरचना को स्पष्ट और लेबल किया जाए किसी भी वल्नरेबिलिटी, स्कैन परिणाम, पैच निर्णय, या घटना-शैली प्रश्न के लिए (जिसमें झूठे सकारात्मक, अपवाद, और रोलआउट विफलताएँ शामिल हैं)। निर्देश तीन आवश्यक घटक जोड़ता है:
तत्काल शमन / नियंत्रण - जोखिम को कम करने के लिए अभी क्या करना है (उदाहरण के लिए: सुविधाओं को अक्षम करें, सिस्टम को अलग करें, अस्थायी नियंत्रण लागू करें)।
पैच / सुधार योजना - कैसे और कब स्थायी रूप से ठीक करें, जिसमें सुरक्षित रोलआउट (रिंग्स/कैनरीज़), रखरखाव विंडो, एसएलए, और रोलबैक योजना शामिल है।
सत्यापन - सफलता और चल रही सुरक्षा की पुष्टि कैसे करें (पुनः स्कैन, संस्करण सत्यापन, स्वास्थ्य जांच, लॉग/IoC निगरानी, अपवादों के लिए समीक्षा तिथियाँ)।
यह एक महत्वपूर्ण गार्डरेल भी जोड़ता है: भले ही कोई प्रश्न "प्रशासनिक" दिखता हो (नीतियाँ, अनुमोदन, KPI), एजेंट को अभी भी उसी जीवनचक्र में प्रतिक्रिया को एंकर करना चाहिए - शमन → सुधार → सत्यापन - जब प्रासंगिक हो।
यह क्यों मायने रखता है: मूल्यांकन रूब्रिक प्रभावी रूप से परीक्षण कर रहा है कि क्या एजेंट एक विश्वसनीय ऑपरेटर की तरह व्यवहार करता है। इन घटकों को स्पष्ट बनाना अस्पष्टता को हटा देता है और एजेंट क्या शामिल करता है में परिवर्तनशीलता को कम करता है।
अपेक्षित परिणाम: कम चूक (विशेष रूप से सत्यापन), रन के पार तंग स्थिरता, और अधिक समान रूप से उच्च मूल्यांकन स्कोर - साथ ही उत्तर जो सुरक्षा और आईटी टीमों के लिए स्पष्ट और अधिक कार्रवाई योग्य हैं।
4.4 प्रॉम्प्ट डिफ़ का पूर्वावलोकन करें - देखें कि वास्तव में क्या बदलेगा
यदि आप प्रस्तावित निर्देश परिवर्तनों का निरीक्षण करना चाहते हैं, तो समीक्षा और लागू करें पर क्लिक करें। यह अद्यतन निर्देश उत्पन्न करता है और एक डिफ़ दृश्य खोलता है जो दिखाता है कि वास्तव में क्या बदलेगा। वहां से, आप तय कर सकते हैं कि अपडेट लागू करना है या नहीं। अस्वीकार करें पर क्लिक करने से सुझाव तुरंत खारिज हो जाता है।
इस चरण का उपयोग तीन चीजों की पुष्टि करने के लिए करें:
दायरा - अपडेट केवल उन परिदृश्यों को प्रभावित करता है जिन्हें आप इरादा रखते हैं (उदाहरण के लिए: वल्नरेबिलिटी और घटना-शैली प्रश्न), न कि हर प्रतिक्रिया।
कोई नया विरोधाभास नहीं - आप ऐसे नियम नहीं पेश कर रहे हैं जो एक-दूसरे से लड़ते हैं (जैसे "संक्षिप्त रहें" जबकि हर जगह लंबे चेकलिस्ट की आवश्यकता होती है)।
अभी भी संक्षिप्त और उपयोगी - जोड़ा गया संरचना हल्का रहता है: कुछ लेबल वाले खंड, कुछ बुलेट्स, कोई अनावश्यक शब्दाडंबर नहीं।
डिफ़ दृश्य आपके लिए प्रतिगमन जोखिम के लिए सुरक्षा जांच भी है। यदि परिवर्तन बहुत व्यापक, बहुत पूर्ण, या बहुत शब्दाडंबरपूर्ण लगता है, तो इसे लागू करने से पहले इसे कसें। प्रॉम्प्ट इंजीनियरिंग केवल तभी उपयोगी है जब यह नियंत्रित हो - और यह नियंत्रण बिंदु है।
4.5 निर्देश अपडेट लागू करें - फिर मूल्यांकन को पुनः चलाएं
एक बार जब आप डिफ़ की समीक्षा कर लेते हैं और आप परिवर्तन से संतुष्ट होते हैं, अद्यतन एजेंट निर्देश लागू करें।
फिर एंटरप्राइज परिनियोजन के लिए एकमात्र अगला कदम करें: उसी एआई एजेंट मूल्यांकन को उसी डेटासेट पर पुनः चलाएं। यह वह तरीका है जिससे आप नियंत्रित तरीके से सुधारों को मान्य करते हैं - एक चर बदला (निर्देश), बाकी सब कुछ स्थिर रखा।
यह एक दोहराने योग्य, एंटरप्राइज-ग्रेड अनुकूलन लूप बनाता है:
एक आधारभूत मूल्यांकन रिपोर्ट कैप्चर करें
एक लक्षित निर्देश अपडेट लागू करें
समान मूल्यांकन डेटासेट को पुनः चलाएं
परिणामों की तुलना करें: स्कोर, विचरण, और अपवाद
यही कारण है कि मूल्यांकन एक रिलीज प्रक्रिया बन जाता है - मापने योग्य, ऑडिट करने योग्य, और शिप करने के लिए सुरक्षित।
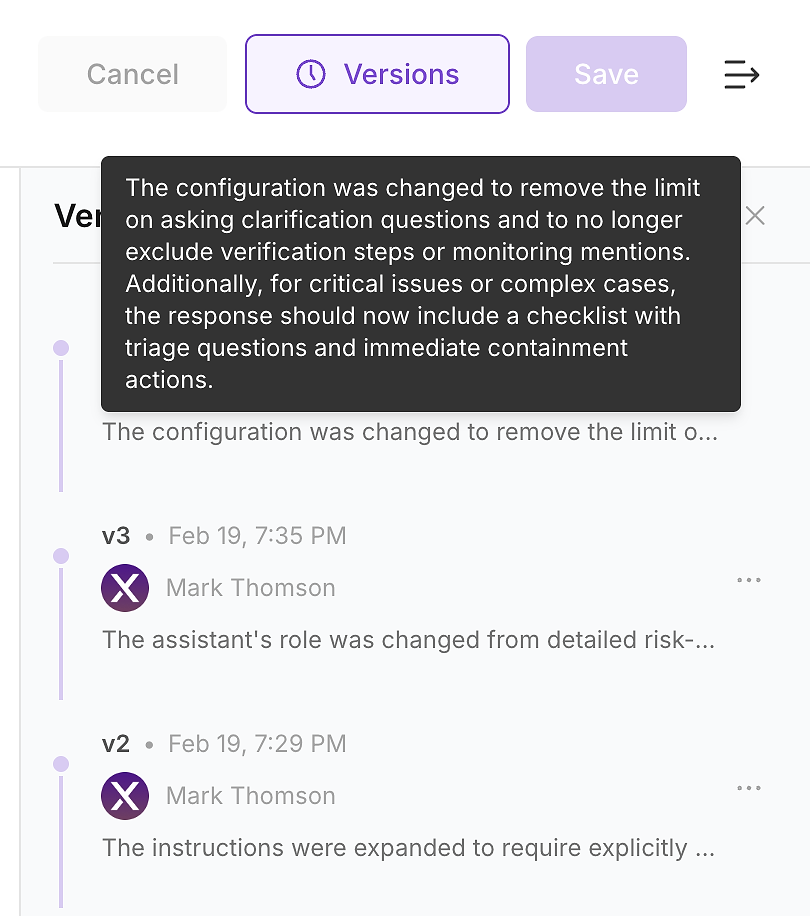
4.6 संस्करण इतिहास की जाँच करें - परिवर्तन को ऑडिट करने योग्य बनाएं
अपडेट लागू करने के बाद, एजेंट के संस्करण इतिहास की जाँच करें। एंटरप्राइज वातावरण में, यह वैकल्पिक नहीं है - यह वह तरीका है जिससे आप निर्देश परिवर्तनों को एक ऑडिट करने योग्य परिवर्तन लॉग में बदलते हैं।
संस्करण इतिहास आपकी टीम को सुरक्षा, अनुपालन, और संचालन द्वारा पूछे जाने वाले प्रश्नों का उत्तर देने देता है:
क्या बदला (निर्देश डिफ़ और सारांश)
कब बदला (टाइमस्टैम्प्ड अपडेट)
किसने बदला (स्वामित्व और अनुमोदन)
क्यों बदला (मूल्यांकन अंतराल और अपेक्षित प्रभाव से जुड़ा)
यही कारण है कि आप सुरक्षित रूप से शिप करते हैं: हर निर्देश अपडेट एक संस्करणित, समीक्षा योग्य परिवर्तन बन जाता है जिसे आप पुनः रन के साथ सत्यापित कर सकते हैं और यदि आवश्यक हो तो रोल बैक कर सकते हैं।
चरण 5: मूल्यांकन को पुनः चलाएं - सुधार को साबित करें
अब समान मूल्यांकन डेटासेट को फिर से अद्यतन एजेंट संस्करण के खिलाफ चलाएं। यह वह क्षण है जहाँ मूल्यांकन व्यावसायिक मूल्य बन जाता है: आप यह दावा नहीं कर रहे हैं कि एजेंट बेहतर है - आप इसे दोहराने योग्य परिणामों के साथ साबित कर रहे हैं।
नई रिपोर्ट में, आप तीन संकेतों की तलाश कर रहे हैं:
उच्च समग्र स्कोर - अधिक परिदृश्य पूरी तरह से रूब्रिक आवश्यकताओं को पूरा करते हैं
बेहतर स्थिरता - तंग स्कोर रेंज, रन के पार कम विचरण
कम अपवाद - कम अचानक कम परिणाम जो उत्पादन जोखिम पैदा करते हैं
व्यवहार में, एक सफल निर्देश अपडेट केवल औसत को ऊपर नहीं धकेलता। यह एजेंट के वर्कफ़्लो को अधिक सुसंगत बनाकर फ्लेकीनेस को कम करता है - विशेष रूप से ट्रायेज प्रश्नों, सुधार संरचना, और सत्यापन चरणों पर।
यही वह है जो एंटरप्राइज एआई में "अच्छा" दिखता है: मापने योग्य सुधार, दोहराने योग्य प्रदर्शन, और एक स्पष्ट ऑडिट ट्रेल जो परिवर्तन को परिणाम से जोड़ता है।
एंटरप्राइज निष्कर्ष: मूल्यांकन को एक रिलीज प्रक्रिया में बदलें
यह वर्कफ़्लो एंटरप्राइज-ग्रेड एआई एजेंट परिनियोजन की नींव है:
एक प्रतिनिधि डेटासेट पर मूल्यांकन चलाएं
दोहराए जाने वाले विफलता मोड को इंगित करने के लिए विश्लेषण का उपयोग करें
समीक्षित डिफ़ के साथ लक्षित निर्देश अपडेट लागू करें
ऑडिटेबिलिटी के लिए संस्करण इतिहास के माध्यम से परिवर्तनों को ट्रैक करें
सुधार को मान्य करने के लिए समान मूल्यांकन को पुनः चलाएं
यही कारण है कि आप "एजेंट अच्छा लगता है" से "एजेंट विश्वसनीय रूप से प्रदर्शन करता है" तक जाते हैं। मूल्यांकन एक रिलीज गेट बन जाता है - एआई एजेंटों के लिए एक व्यावहारिक सीआई प्रक्रिया जो संचालन जोखिम को कम करती है, स्थिरता में सुधार करती है, और सुधारों को मापने योग्य बनाती है।
कार्यवाई के लिए आह्वान
यदि आप चाहते हैं कि मूल्यांकन वास्तविक व्यावसायिक परिणाम उत्पन्न करे, तो इसे इंजीनियरिंग की तरह मानें:
हर निर्देश अपडेट को एक मूल्यांकन रन को ट्रिगर करना चाहिए
हर उत्पादन विफलता को एक नया परीक्षण मामला बनना चाहिए
हर सुधार मापने योग्य और दोहराने योग्य होना चाहिए
AgentX का अन्वेषण करें
अधिक जानें agentx.so पर
प्लेटफ़ॉर्म में मूल्यांकन चलाएं app.agentx.so पर
अगली पोस्ट में, हम एंटरप्राइज मूल्यांकन विधियों, उपकरणों, और व्यावहारिक तकनीकों में गहराई से जाएंगे ताकि एजेंट प्रदर्शन और विश्वसनीयता में लगातार सुधार किया जा सके। हम मॉनिटरिंग पर एक नया खंड भी पेश करेंगे - जल्द ही आ रहा है।