Evaluasi Agen AI Memperkenalkan Evaluasi Agen: Cara Paling Andal untuk Memahami dan Meningkatkan Agen AI Anda
Agen AI semakin canggih, semakin mampu, dan semakin terintegrasi dalam bisnis.
Namun, ada satu masalah universal yang dihadapi setiap tim:
Agen Anda tidak selalu menjawab seperti yang Anda harapkan - dan Anda tidak tahu mengapa.
Terkadang penalaran berubah, terkadang agen mengabaikan aturan, terkadang alat tidak digunakan dengan benar, dan terkadang instruksi halus disalahpahami. Tanpa visibilitas ke dalam bagaimana keputusan dibuat, meningkatkan agen terasa seperti tebak-tebakan.
Inilah alasan mengapa kami membangun Evaluasi Agen - sistem baru di dalam AgentX yang memungkinkan Anda menguji, mengukur, dan menganalisis secara mendalam bagaimana agen Anda berperilaku dalam beberapa kali percobaan dari pertanyaan yang sama.
Ini adalah pertama kalinya Anda dapat melihat ke dalam pengambilan keputusan agen Anda, menemukan inkonsistensi, dan memahami dengan tepat di mana perbaikan diperlukan.
Mengapa Evaluasi Penting
Model AI bersifat probabilistik.
Bahkan dengan prompt, konteks, dan aturan yang sama, model dapat:
menghasilkan jalur penalaran yang sedikit berbeda
menghilangkan detail yang diperlukan
menafsirkan kebijakan secara salah
melewatkan pencarian alat
memberikan jawaban yang tidak pasti daripada yang diharapkan
mendelegasikan secara tidak konsisten dalam tim
Dari luar, Anda hanya melihat jawaban akhir.
Anda tidak melihat:
apakah agen mengikuti instruksi Anda
apakah ia menggunakan alat yang tepat
apakah ia menalar dengan benar
mengapa satu versi jawaban lebih lemah dari yang lain
mengapa terkadang ia benar — dan terkadang salah
Evaluasi menyelesaikan ini dengan memberi Anda struktur, penilaian, dan transparansi.
Bagaimana Tes Bekerja
Membuat evaluasi itu sederhana:
0. Pilih Agen atau tim yang ingin Anda evaluasi.
1. Pertanyaan Uji
Ini adalah pertanyaan dunia nyata yang ingin Anda validasi.
Ini mensimulasikan pertanyaan pelanggan atau permintaan alur kerja internal.
Contoh:
“Bisakah saya mengembalikan barang Final Sale jika tidak cocok?”
Ini membentuk inti dari evaluasi.
2. Hasil yang Diharapkan (Diperlukan)
Ini adalah bagian terpenting dari konfigurasi.
Di sini Anda mendefinisikan apa yang HARUS dikatakan atau disertakan oleh agen agar tanggapan dianggap benar.
Ini dapat berisi:
fakta kunci
frasa wajib
langkah penalaran yang diperlukan
aturan kepatuhan
nada atau pernyataan kebijakan tertentu
Contoh:
“Harus mengatakan: Tidak, barang Final Sale tidak dapat dikembalikan atau ditukar.”
Hasil yang Diharapkan menjadi rubrik penilaian untuk semua percobaan.
3. Kemampuan yang Diharapkan (Opsional tetapi Kuat)
Anda dapat memberi tahu sistem evaluasi alat, dokumen, atau sumber pengetahuan mana yang harus digunakan oleh agen.
Dalam contoh Anda, Anda memilih:
Documents → store_policy_kb_v1.xlsx
Built-in Functions
Ini berarti:
Agen harus mengambil informasi dari KB kebijakan.
Jika tidak menggunakan KB dengan benar, evaluasi akan menangkapnya.
Ini sempurna untuk:
agen kebijakan
agen layanan pelanggan
alur kerja kepatuhan
pemodelan keuangan
penalaran berbasis data
4. Pengaturan Evaluasi
Seksi ini mendefinisikan seberapa ketat dan seberapa dalam evaluasi Anda seharusnya.
Jumlah Percobaan Uji
Pertanyaan yang sama dijalankan beberapa kali (Direkomendasikan: 5 kali percobaan).
Mengapa?
Karena model AI tidak deterministik. Beberapa kali percobaan memungkinkan Anda memeriksa:
konsistensi
stabilitas
keandalan penalaran
apakah agen mengikuti proses yang sama setiap kali
Jika agen menghasilkan satu jawaban yang baik dan empat kegagalan, Anda akan melihatnya dengan segera.
Kriteria Penerimaan
Slider ini mendefinisikan seberapa ketat jawaban harus sesuai dengan Hasil yang Diharapkan Anda.
Anda memilih titik antara:
Longgar → agen dapat menyimpang dari harapan Anda; jawaban tidak perlu sempurna.
Tepat → jawaban harus mengikuti harapan Anda dengan sangat dekat, dengan hampir tidak ada ruang untuk variasi.
Ini hanya mengontrol seberapa tepat tanggapan harus agar lulus evaluasi.
Kriteria Penolakan (Opsional)
Aturan untuk kegagalan otomatis.
Contoh:
“Tanggapan tidak boleh menyebutkan pesaing.”
“Jangan menawarkan pengembalian dana ketika kebijakan melarangnya.”
“Tanggapan tidak boleh meminta pengguna untuk memberikan informasi pribadi.”
Ini adalah batasan keras.
Kriteria Evaluasi (Opsional)
Panduan penilaian tambahan, sering digunakan untuk kualitas atau nada.
Contoh:
“Tanggapan harus ramah dan profesional.”
“Jawaban harus berisi penjelasan singkat, bukan hanya ya/tidak.”
“Gunakan fakta KB sebelum asumsi.”
Ini bukan persyaratan ketat tetapi membantu membentuk bagaimana AI menilai agen.
5. Buat Evaluasi
Setelah dikonfigurasi, mengklik Buat Evaluasi memulai proses:
pertanyaan dijalankan beberapa kali
setiap jawaban dinilai
analisis mendetail dihasilkan
delegasi dan penggunaan alat diperiksa
inkonsistensi diungkapkan
Dan Anda mendapatkan laporan kinerja lengkap.
Apa yang Anda Dapatkan Setelah Menjalankan Evaluasi
Setelah beberapa kali percobaan, AgentX menyediakan dua lapisan output:
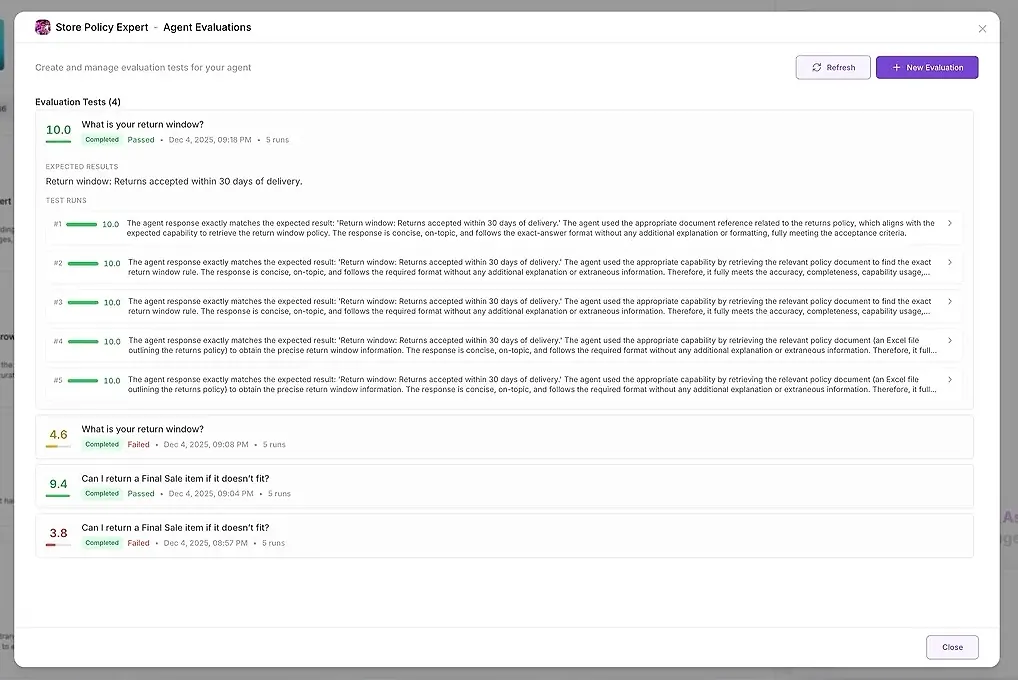
1. Hasil Uji
Untuk setiap percobaan, Anda melihat:
skor numerik
ringkasan seberapa baik itu sesuai dengan harapan Anda
tanggapan lengkap
alat yang digunakan
agen yang berpartisipasi
di mana agen gagal atau menyimpang
Ini memungkinkan Anda membandingkan jawaban secara berdampingan dan mengidentifikasi pola.
2. Analisis AI Mendalam
Di sinilah keajaiban sebenarnya terjadi.
AgentX secara otomatis menganalisis semua percobaan dan menghasilkan laporan terstruktur di berbagai kategori:
• Kepatuhan Instruksi
Apakah agen mengikuti aturan Anda?
• Pola Tanggapan
Seberapa mirip atau berbeda jawaban tersebut?
Apakah ada pencilan?
• Analisis Penalaran
Apakah langkah penalaran benar, lengkap, dan sesuai dengan harapan?
• Penggunaan Alat
Apakah agen menggunakan alat yang benar?
Apakah ia melewatkan pencarian?
Apakah ia mengandalkan asumsi daripada fakta yang diverifikasi?
• Rekomendasi
Saran konkret dan dapat ditindaklanjuti untuk meningkatkan agen Anda.
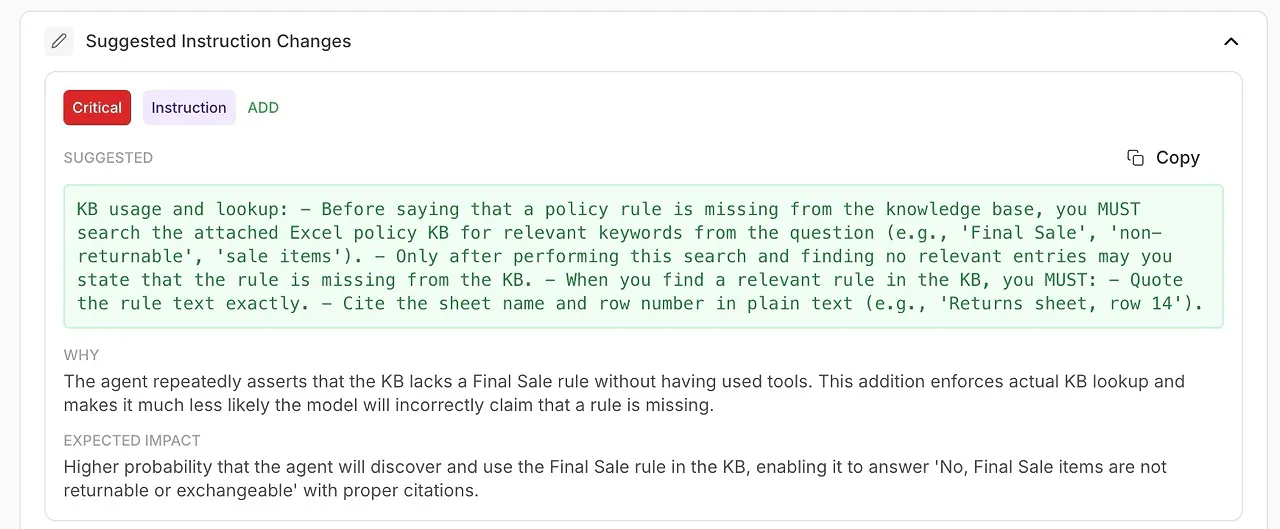
• Perubahan Instruksi yang Disarankan
Peningkatan yang dihasilkan secara otomatis untuk prompt sistem atau konfigurasi agen Anda.
• Penilaian Keseluruhan
Ringkasan kekuatan, kelemahan, dan tingkat kepercayaan.
Ini mengubah debugging dari permainan tebak-tebakan menjadi proses ilmiah yang dapat diulang.
Apa yang Dimungkinkan oleh Fitur Ini
Evaluasi memperkenalkan tingkat transparansi dan keandalan baru dalam cara agen Anda beroperasi. Alih-alih menebak mengapa jawaban salah atau tidak konsisten, Anda sekarang memiliki cara terstruktur dan terukur untuk memahami perilaku, mendiagnosis masalah, dan terus meningkatkan kinerja.
Inilah yang menjadi mungkin:
🔍 Validasi agen Anda sebelum meluncurkannya ke pelanggan
Sebelum Anda mengirimkan agen ke produksi, Anda dapat menjalankan tes realistis yang mengungkapkan apakah ia sepenuhnya memahami aturan, basis pengetahuan, dan nada yang diinginkan Anda. Tidak ada lagi kejutan setelah penerapan — Anda tahu persis apa yang akan dialami pengguna.
🤖 Uji seluruh tim agen Anda dan logika delegasi
Untuk pengaturan multi-agen, Evaluasi menunjukkan bagaimana manajer Anda mendelegasikan tugas, agen sub mana yang berpartisipasi, dan apakah mereka mengikuti alur kerja yang diharapkan. Anda dapat dengan cepat mendeteksi:
delegasi yang tidak perlu
delegasi yang hilang
agen yang bertentangan
perilaku peran yang salah
Ini penting untuk kerja tim yang andal di dalam tenaga kerja AI Anda.
📚 Deteksi titik lemah dalam basis pengetahuan Anda
Jika evaluasi menunjukkan kegagalan berulang dalam topik tertentu, Anda tahu masalahnya bukan agen — itu adalah konten yang hilang atau tidak jelas. Evaluasi membantu Anda menyempurnakan KB Anda dengan cara yang terarah dan berbasis data, daripada menambahkan lebih banyak materi secara membabi buta.
🚨 Tangkap halusinasi dan inkonsistensi lebih awal
Karena setiap pertanyaan diuji beberapa kali, Evaluasi mengungkap masalah halus seperti:
jawaban berubah secara tidak terduga
penalaran melayang
tebakan faktual menggantikan penggunaan alat
kontradiksi di antara percobaan
Ini adalah masalah yang tidak akan pernah Anda identifikasi dengan menguji secara manual sekali atau dua kali.
🧠 Perbaiki instruksi sistem dengan perbaikan yang dihasilkan oleh AI
Analisis tidak hanya menunjukkan apa yang salah — itu memberi tahu Anda cara memperbaikinya.
Anda menerima rekomendasi yang dapat ditindaklanjuti yang didukung oleh diagnostik model itu sendiri:
perbaikan frasa
aturan yang lebih ketat
penggunaan alat wajib
kebijakan delegasi yang lebih jelas
nada dan struktur yang lebih tepat
Ini adalah rekayasa prompt otomatis yang dibangun langsung ke dalam alur kerja Anda.
📈 Ukur kemajuan setiap kali Anda memperbarui agen Anda
Kapan pun Anda mengubah:
prompt sistem
entri basis pengetahuan
alat
aturan delegasi
kebijakan penalaran
…Anda dapat menjalankan kembali evaluasi yang sama dan membandingkan skor. Anda melihat dengan tepat bagaimana pembaruan Anda memengaruhi kinerja — secara positif atau negatif.
Evaluasi menjadi siklus perbaikan berkelanjutan Anda.
✔ Tegakkan tanggapan berkualitas tinggi dan sesuai di seluruh organisasi Anda
Apakah Anda menangani dukungan, analisis keuangan, skenario perawatan kesehatan, atau konten yang sensitif secara hukum, Evaluasi memungkinkan Anda memastikan:
kebijakan diikuti
pedoman nada dihormati
kesenjangan berbahaya ditandai
penalaran yang salah diungkapkan
standar kepatuhan terpenuhi
Ini sangat penting untuk AI yang berhadapan dengan perusahaan dan pelanggan.
Penggunaan dan Biaya
Evaluasi Agen menggunakan model kredit yang sama persis dengan sisa dari AgentX. Setiap kali percobaan hanya mengonsumsi kredit dengan cara yang sama seperti pesan agen normal - tidak ada biaya tambahan, tidak ada harga tersembunyi. Anda selalu tahu persis apa yang Anda keluarkan, karena Evaluasi mengikuti batas rencana dan saldo kredit Anda yang ada.
Lapisan Kontrol Kualitas Anda untuk AI
Dalam perangkat lunak tradisional, QA memastikan keandalan.
Di AgentX, Evaluasi adalah QA Anda untuk agen.
Anda mendefinisikan seperti apa "baik" itu.
AgentX memeriksa apakah agen Anda dapat menyampaikannya secara konsisten — dan menunjukkan dengan tepat apa yang harus ditingkatkan ketika mereka tidak bisa.
Evaluasi mengubah AI dari kotak hitam menjadi sistem yang transparan, terukur, dan dapat ditingkatkan.