AI Agent Evaluatie: Introductie van Agent Evaluaties: De Meest Betrouwbare Manier om je AI-Agenten te Begrijpen en Verbeteren
AI-agenten worden steeds geavanceerder, capabeler en dieper geïntegreerd in bedrijven.
Maar er is één universeel probleem waar elk team mee te maken heeft:
Je agent antwoordt niet altijd zoals je verwacht - en je weet niet waarom.
Soms verandert de redenering, soms negeert de agent een regel, soms werd het gereedschap niet correct gebruikt, en soms werd een subtiele instructie verkeerd begrepen. Zonder inzicht in hoe beslissingen werden genomen, voelt het verbeteren van de agent als giswerk.
Precies daarom hebben we Agent Evaluaties gebouwd - een nieuw systeem binnen AgentX waarmee je kunt testen, meten en diepgaand analyseren hoe je agent zich gedraagt over meerdere runs van dezelfde vraag.
Het is de eerste keer dat je in het besluitvormingsproces van je agent kunt kijken, inconsistenties kunt vinden en precies kunt begrijpen waar verbeteringen nodig zijn.
Waarom Evaluaties Belangrijk Zijn
AI-modellen zijn probabilistisch.
Zelfs met dezelfde prompt, context en regels kan het model:
iets andere redeneringspaden produceren
een vereist detail weglaten
een beleid verkeerd interpreteren
een gereedschapsopzoeking overslaan
onzekere antwoorden geven in plaats van het verwachte definitieve antwoord
inconsistente delegatie binnen een team
Van buitenaf zie je alleen het uiteindelijke antwoord.
Je ziet niet:
of de agent je instructies volgde
of het de juiste gereedschappen gebruikte
of het correct redeneerde
waarom de ene versie van het antwoord zwakker was dan de andere
waarom het soms dingen goed doet — en soms fout
Evaluaties lossen dit op door je structuur, scoring en transparantie te geven.
Hoe een Test Werkt
Het maken van een evaluatie is eenvoudig:
0. Selecteer de Agent of het team dat je wilt evalueren.
1. Test Vraag
Dit is de real-world vraag die je wilt valideren.
Het simuleert een klantvraag of een interne workflowverzoek.
Voorbeeld:
“Kan ik een Final Sale item retourneren als het niet past?”
Dit vormt de kern van de evaluatie.
2. Verwachte Resultaten (Vereist)
Dit is het belangrijkste deel van de configuratie.
Hier definieer je wat de agent MOET zeggen of opnemen om de reactie als correct te beschouwen.
Het kan bevatten:
belangrijke feiten
verplichte zinnen
vereiste redeneringsstappen
nalevingsregels
specifieke toon- of beleidsverklaringen
Voorbeeld:
“Moet zeggen: Nee, Final Sale items zijn niet retourneerbaar of inwisselbaar.”
De Verwachte Resultaten worden de beoordelingsrubriek voor alle testuitvoeringen.
3. Verwachte Capaciteiten (Optioneel maar Krachtig)
Je kunt het evaluatiesysteem vertellen welke gereedschappen, documenten of kennisbronnen de agent moet gebruiken.
In je voorbeeld heb je geselecteerd:
Documenten → store_policy_kb_v1.xlsx
Ingebouwde Functies
Dit betekent:
De agent zou informatie moeten ophalen uit de policy KB.
Als het de KB niet correct gebruikt, zal de evaluatie dat opmerken.
Dit is perfect voor:
beleidagenten
klantenserviceagenten
nalevingsworkflows
financiële modellering
gegevensgestuurde redenering
4. Evaluatie Instellingen
Dit gedeelte definieert hoe rigoureus en hoe diepgaand je evaluatie moet zijn.
Aantal Testuitvoeringen
Dezelfde vraag wordt meerdere keren uitgevoerd (Aanbevolen: 5 uitvoeringen).
Waarom?
Omdat AI-modellen niet deterministisch zijn. Meerdere uitvoeringen stellen je in staat om te controleren op:
consistentie
stabiliteit
betrouwbaarheid van redenering
of de agent elke keer hetzelfde proces volgt
Als de agent één goed antwoord en vier fouten produceert, zie je dat onmiddellijk.
Acceptatiecriteria
Deze schuifregelaar definieert hoe strikt het antwoord moet overeenkomen met je Verwachte Resultaten.
Je kiest een punt tussen:
Soepel → de agent kan afwijken van je verwachtingen; het antwoord hoeft niet perfect te zijn.
Exact → het antwoord moet zeer nauwkeurig je verwachtingen volgen, met bijna geen ruimte voor variatie.
Het bepaalt simpelweg hoe exact de reactie moet zijn om de evaluatie te halen.
Afwijzingscriteria (Optioneel)
Regels voor automatische mislukking.
Voorbeelden:
“Reactie mag geen concurrenten vermelden.”
“Bied geen restituties aan wanneer het beleid dit verbiedt.”
“Reactie mag de gebruiker niet vragen om persoonlijke informatie te verstrekken.”
Dit zijn harde beperkingen.
Evaluatiecriteria (Optioneel)
Aanvullende scoringsrichtlijnen, vaak gebruikt voor kwaliteit of toon.
Voorbeelden:
“Reactie moet vriendelijk en professioneel zijn.”
“Antwoord moet een korte uitleg bevatten, niet alleen een ja/nee.”
“Gebruik KB-feiten vóór aannames.”
Dit zijn geen strikte vereisten, maar helpen vorm te geven aan hoe de AI de agent scoort.
5. Maak Evaluatie
Zodra geconfigureerd, start het klikken op Maak Evaluatie het proces:
de vraag wordt meerdere keren uitgevoerd
elk antwoord wordt gescoord
een gedetailleerde analyse wordt gegenereerd
delegatie en gereedschapsgebruik worden geïnspecteerd
inconsistenties worden blootgelegd
En je krijgt een compleet prestatieverslag terug.
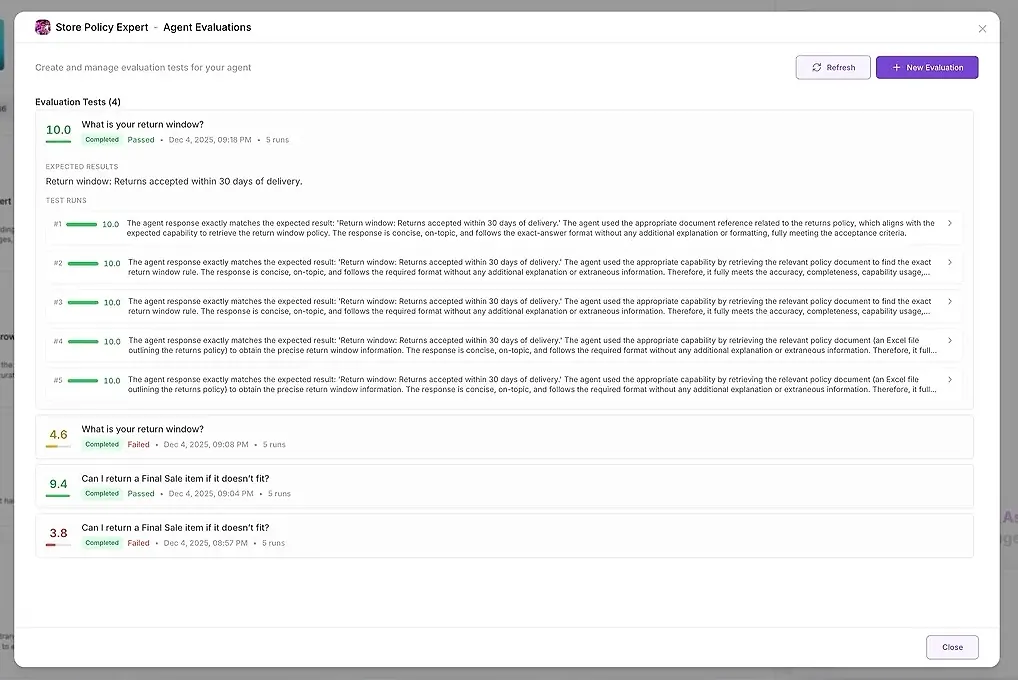
Wat je Krijgt na het Uitvoeren van de Evaluatie
Na meerdere uitvoeringen biedt AgentX twee lagen van output:
1. Testresultaten
Voor elke uitvoering zie je:
een numerieke score
een samenvatting van hoe goed het aan je verwachtingen voldeed
de volledige reactie
welke gereedschappen werden gebruikt
welke agenten deelnamen
waar de agent faalde of afweek
Dit stelt je in staat om antwoorden naast elkaar te vergelijken en patronen te identificeren.
2. Diepe AI Analyse
Dit is waar de echte magie gebeurt.
AgentX analyseert automatisch alle uitvoeringen en genereert een gestructureerd rapport over meerdere categorieën:
• Instructie Naleving
Volgde de agent je regels?
• Reactiepatronen
Hoe vergelijkbaar of verschillend waren de antwoorden?
Zijn er uitschieters?
• Redeneringsanalyse
Waren de redeneringsstappen correct, compleet en in lijn met de verwachtingen?
• Gereedschapsgebruik
Gebruikte de agent het juiste gereedschap?
Sloeg het een opzoeking over?
Vertrouwde het op aannames in plaats van op geverifieerde feiten?
• Aanbevelingen
Concrete, bruikbare suggesties om je agent te verbeteren.
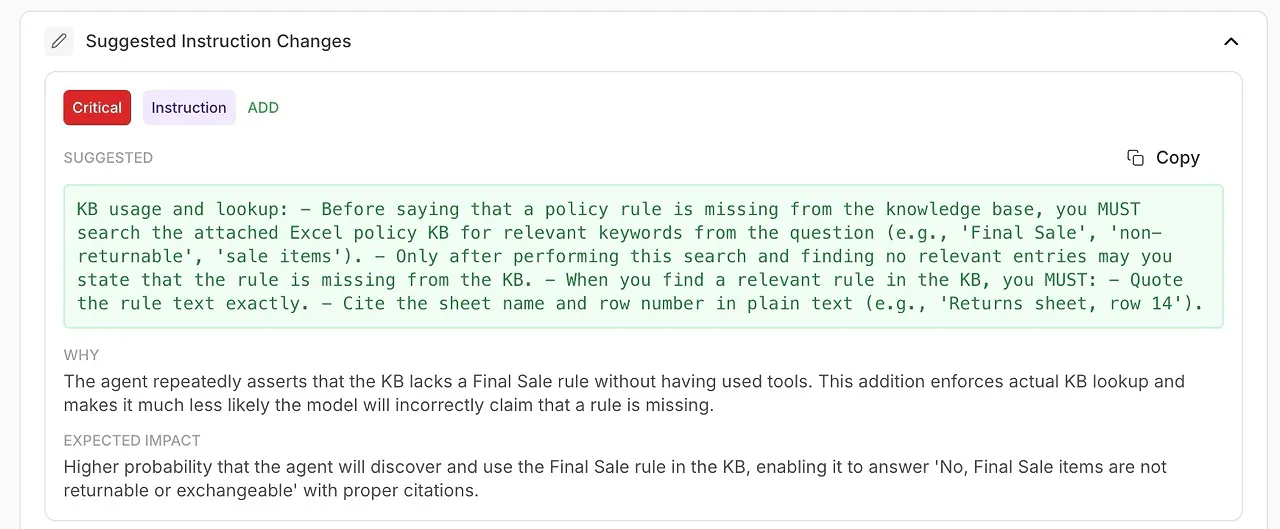
• Voorgestelde Instructiewijzigingen
Automatisch gegenereerde verbeteringen aan je systeemprompt of agentconfiguratie.
• Algemene Beoordeling
Een samenvatting van sterke punten, zwakke punten en betrouwbaarheidsniveau.
Dit transformeert debuggen van een gokspel naar een wetenschappelijk, herhaalbaar proces.
Wat Deze Functie Mogelijk Maakt
Evaluaties introduceren een nieuw niveau van transparantie en betrouwbaarheid in hoe je agenten opereren. In plaats van te raden waarom een antwoord fout of inconsistent was, heb je nu een gestructureerde, meetbare manier om gedrag te begrijpen, problemen te diagnosticeren en prestaties continu te verbeteren.
Hier is wat mogelijk wordt:
🔍 Valideer je agent voordat je deze aan klanten lanceert
Voordat je een agent in productie brengt, kun je realistische tests uitvoeren die onthullen of het je regels, kennisbasis en gewenste toon volledig begrijpt. Geen verrassingen meer na implementatie — je weet precies wat gebruikers zullen ervaren.
🤖 Test je hele agententeam en delegatielogica
Voor multi-agent opstellingen laten Evaluaties zien hoe je manager taken delegeert, welke sub-agenten deelnemen en of ze de verwachte workflow volgen. Je kunt snel detecteren:
onnodige delegaties
ontbrekende delegaties
conflicterende agenten
onjuiste rolgedrag
Dit is essentieel voor betrouwbare samenwerking binnen je AI-werkkracht.
📚 Zwakke punten in je kennisbasis detecteren
Als een evaluatie herhaalde mislukkingen in een specifiek onderwerp laat zien, weet je dat het probleem niet de agent is — het is ontbrekende of onduidelijke inhoud. Evaluaties helpen je om je KB op een gerichte, datagestuurde manier te verfijnen, in plaats van blindelings meer materiaal toe te voegen.
🚨 Vang hallucinaties en inconsistentie vroegtijdig op
Omdat elke vraag meerdere keren wordt getest, brengen Evaluaties subtiele problemen aan het licht zoals:
antwoorden die onvoorspelbaar veranderen
redenering die afdrijft
feitelijke gokwerk vervangt gereedschapsgebruik
tegenstrijdigheden over uitvoeringen heen
Dit zijn problemen die je nooit zou identificeren door handmatig een of twee keer te testen.
🧠 Verfijn systeeminstructies met AI-gegenereerde verbeteringen
De analyse laat niet alleen zien wat er misging — het vertelt je hoe je het kunt oplossen.
Je ontvangt bruikbare aanbevelingen ondersteund door de eigen diagnostiek van het model:
verbeterde formulering
strengere regels
verplicht gereedschapsgebruik
duidelijker delegatiebeleid
meer precieze toon en structuur
Dit is geautomatiseerde prompt engineering direct ingebouwd in je workflow.
📈 Meet vooruitgang elke keer dat je je agent bijwerkt
Telkens wanneer je verandert:
een systeemprompt
een kennisbasisvermelding
een gereedschap
een delegatieregel
een redeneerbeleid
…kun je dezelfde evaluatie opnieuw uitvoeren en scores vergelijken. Je ziet precies hoe je update de prestaties beïnvloedde — positief of negatief.
Evaluaties worden je continue verbeterlus.
Of je nu ondersteuning, financiële analyse, gezondheidszorgscenario's of juridisch gevoelige inhoud behandelt, Evaluaties laten je ervoor zorgen dat:
beleidsregels worden gevolgd
toonrichtlijnen worden gerespecteerd
gevaarlijke hiaten worden gemarkeerd
onjuiste redenering aan het licht komt
nalevingsnormen worden gehaald
Dit is vooral cruciaal voor ondernemingen en klantgerichte AI.
Gebruik en Kosten
Agent Evaluaties gebruiken exact hetzelfde kredietmodel als de rest van AgentX. Elke testuitvoering verbruikt simpelweg credits op dezelfde manier als een normaal agentbericht - geen extra kosten, geen verborgen prijzen. Je weet altijd precies wat je uitgeeft, omdat Evaluaties je bestaande planlimieten en kredietsaldo volgen.
Je Kwaliteitscontrolelaag voor AI
In traditionele software zorgt QA voor betrouwbaarheid.
In AgentX, zijn Evaluaties je QA voor agenten.
Je definieert wat "goed" eruitziet.
AgentX controleert of je agenten het consequent kunnen leveren — en laat je precies zien wat je moet verbeteren als dat niet het geval is.
Evaluaties veranderen AI van een black box in een transparant, meetbaar, verbeterbaar systeem.