Ocena Agentów AI: Wprowadzenie do Ocen Agentów: Najbardziej Niezawodny Sposób na Zrozumienie i Udoskonalenie Twoich Agentów AI
Agenty AI stają się coraz bardziej zaawansowane, bardziej zdolne i głębiej zintegrowane z biznesem.
Jednak istnieje jeden uniwersalny problem, z którym boryka się każdy zespół:
Twój agent nie zawsze odpowiada tak, jak się spodziewasz - i nie wiesz dlaczego.
Czasami zmienia się rozumowanie, czasami agent ignoruje regułę, czasami narzędzie nie zostało użyte poprawnie, a czasami subtelna instrukcja została źle zrozumiana. Bez wglądu w jak podejmowane były decyzje, poprawa agenta wydaje się zgadywanką.
Dlatego właśnie stworzyliśmy Oceny Agentów - nowy system w AgentX, który pozwala testować, mierzyć i dogłębnie analizować, jak Twój agent zachowuje się w wielu przebiegach tego samego pytania.
To pierwszy raz, gdy możesz zajrzeć do wnętrza procesu decyzyjnego swojego agenta, znaleźć niespójności i zrozumieć dokładnie, gdzie potrzebne są ulepszenia.
Dlaczego Oceny Są Ważne
Modele AI są probabilistyczne.
Nawet przy tym samym zapytaniu, kontekście i regułach model może:
generować nieco inne ścieżki rozumowania
pominąć wymagany szczegół
źle zinterpretować politykę
pominąć wyszukiwanie narzędzia
udzielić niepewnych odpowiedzi zamiast oczekiwanej definitywnej
delegować niespójnie w zespole
Z zewnątrz widzisz tylko ostateczną odpowiedź.
Nie widzisz:
czy agent przestrzegał Twoich instrukcji
czy użył odpowiednich narzędzi
czy rozumował poprawnie
dlaczego jedna wersja odpowiedzi była słabsza od innej
dlaczego czasami ma rację — a czasami nie
Oceny rozwiązują to, dając Ci strukturę, ocenę i przejrzystość.
Jak Działa Test
Tworzenie oceny jest proste:
0. Wybierz Agenta lub zespół, który chcesz ocenić.
1. Pytanie Testowe
To jest pytanie z prawdziwego świata, które chcesz zweryfikować.
Symuluje zapytanie klienta lub wewnętrzne żądanie przepływu pracy.
Przykład:
„Czy mogę zwrócić produkt z wyprzedaży końcowej, jeśli nie pasuje?”
To stanowi rdzeń oceny.
2. Oczekiwane Wyniki (Wymagane)
To najważniejsza część konfiguracji.
Tutaj definiujesz, co agent MUSI powiedzieć lub zawrzeć, aby odpowiedź była uznana za poprawną.
Może zawierać:
kluczowe fakty
obowiązkowe zwroty
wymagane kroki rozumowania
zasady zgodności
specyficzny ton lub oświadczenia polityki
Przykład:
„Musi powiedzieć: Nie, produkty z wyprzedaży końcowej nie podlegają zwrotowi ani wymianie.”
Oczekiwane Wyniki stają się rubryką oceny dla wszystkich przebiegów testowych.
3. Oczekiwane Umiejętności (Opcjonalne, ale Potężne)
Możesz powiedzieć systemowi oceny, których narzędzi, dokumentów lub źródeł wiedzy agent powinien używać.
W swoim przykładzie wybrałeś:
Dokumenty → store_policy_kb_v1.xlsx
Wbudowane Funkcje
To oznacza:
Agent powinien pobierać informacje z polityki KB.
Jeśli nie używa KB poprawnie, ocena to wychwyci.
To idealne dla:
agentów polityki
agentów obsługi klienta
przepływów pracy zgodności
modelowania finansowego
rozumowania opartego na danych
4. Ustawienia Oceny
Ta sekcja definiuje jak rygorystyczna i jak głęboka powinna być Twoja ocena.
Liczba Przebiegów Testowych
To samo pytanie jest wykonywane wielokrotnie (Zalecane: 5 przebiegów).
Dlaczego?
Ponieważ modele AI nie są deterministyczne. Wielokrotne przebiegi pozwalają sprawdzić:
spójność
stabilność
wiarygodność rozumowania
czy agent za każdym razem podąża tą samą ścieżką
Jeśli agent generuje jedną dobrą odpowiedź i cztery błędy, zobaczysz to natychmiast.
Kryteria Akceptacji
Ten suwak definiuje jak ściśle odpowiedź musi odpowiadać Twoim Oczekiwanym Wynikom.
Wybierasz punkt pomiędzy:
Liberalny → agent może odbiegać od Twoich oczekiwań; odpowiedź nie musi być perfekcyjna.
Dokładny → odpowiedź musi bardzo ściśle odpowiadać Twoim oczekiwaniom, z prawie żadnym miejscem na wariacje.
To po prostu kontroluje jak dokładna musi być odpowiedź, aby zdać ocenę.
Kryteria Odrzucenia (Opcjonalne)
Zasady automatycznego niepowodzenia.
Przykłady:
„Odpowiedź nie powinna wspominać o konkurentach.”
„Nie oferuj zwrotów, gdy polityka tego zabrania.”
„Odpowiedź nie powinna prosić użytkownika o podanie danych osobowych.”
To są twarde ograniczenia.
Kryteria Oceny (Opcjonalne)
Dodatkowe wskazówki dotyczące oceny, często używane do jakości lub tonu.
Przykłady:
„Odpowiedź powinna być przyjazna i profesjonalna.”
„Odpowiedź musi zawierać krótkie wyjaśnienie, nie tylko tak/nie.”
„Używaj faktów z KB przed założeniami.”
To nie są ścisłe wymagania, ale pomagają kształtować, jak AI ocenia agenta.
5. Utwórz Ocenę
Po skonfigurowaniu, kliknięcie Utwórz Ocenę rozpoczyna proces:
pytanie jest wykonywane kilka razy
każda odpowiedź jest oceniana
generowana jest szczegółowa analiza
delegacja i użycie narzędzi są sprawdzane
niespójności są ujawniane
I otrzymujesz kompletny raport wydajności.
Co Otrzymujesz Po Przeprowadzeniu Oceny
Po kilku przebiegach AgentX dostarcza dwie warstwy wyników:
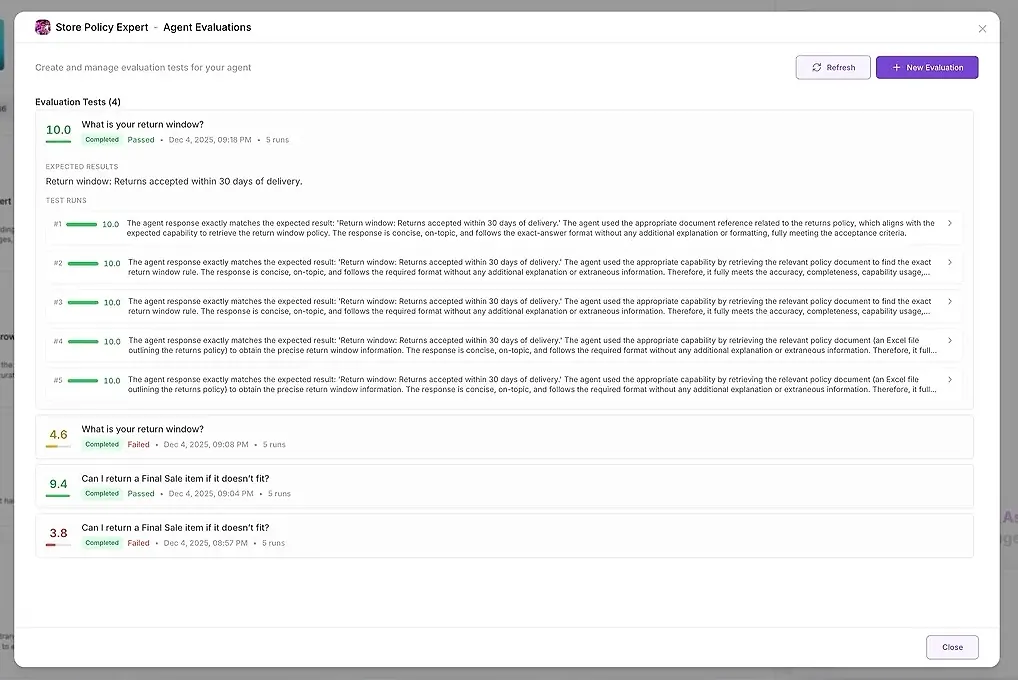
1. Wyniki Testu
Dla każdego przebiegu widzisz:
ocenę numeryczną
podsumowanie, jak dobrze odpowiadało Twoim oczekiwaniom
pełną odpowiedź
które narzędzia były używane
którzy agenci uczestniczyli
gdzie agent zawiódł lub odbiegł
To pozwala porównać odpowiedzi obok siebie i zidentyfikować wzorce.
2. Głęboka Analiza AI
To tutaj dzieje się prawdziwa magia.
AgentX automatycznie analizuje wszystkie przebiegi i generuje uporządkowany raport w wielu kategoriach:
• Przestrzeganie Instrukcji
Czy agent przestrzegał Twoich zasad?
• Wzorce Odpowiedzi
Jak podobne lub różne były odpowiedzi?
Czy są jakieś odstępstwa?
• Analiza Rozumowania
Czy kroki rozumowania były poprawne, kompletne i zgodne z oczekiwaniami?
• Użycie Narzędzi
Czy agent użył właściwego narzędzia?
Czy pominął wyszukiwanie?
Czy polegał na założeniach zamiast na zweryfikowanych faktach?
• Rekomendacje
Konkretnie, praktyczne sugestie dotyczące poprawy Twojego agenta.
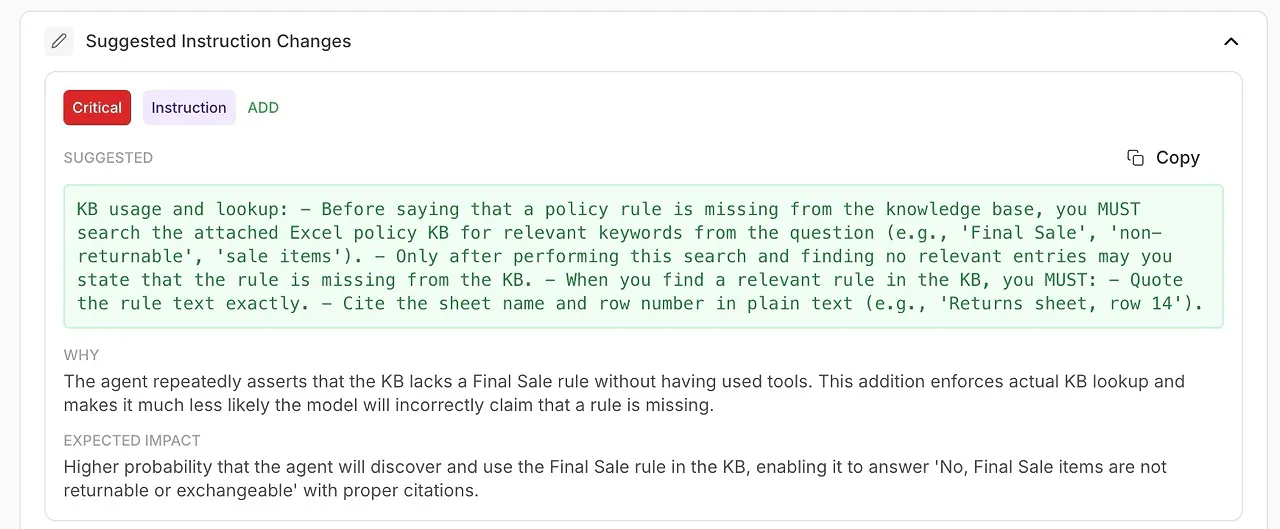
• Sugerowane Zmiany Instrukcji
Automatycznie generowane ulepszenia dla Twojego systemu prompt lub konfiguracji agenta.
• Ogólna Ocena
Podsumowanie mocnych stron, słabych punktów i poziomu pewności.
To przekształca debugowanie z zgadywanki w naukowy, powtarzalny proces.
Co Ta Funkcja Umożliwia
Oceny wprowadzają nowy poziom przejrzystości i niezawodności w działaniu Twoich agentów. Zamiast zgadywać, dlaczego odpowiedź była błędna lub niespójna, teraz masz uporządkowany, mierzalny sposób na zrozumienie zachowania, diagnozowanie problemów i ciągłe poprawianie wydajności.
Oto, co staje się możliwe:
🔍 Zweryfikuj swojego agenta przed jego uruchomieniem dla klientów
Zanim wprowadzisz agenta do produkcji, możesz przeprowadzić realistyczne testy, które ujawnią, czy w pełni rozumie Twoje zasady, bazę wiedzy i pożądany ton. Koniec z niespodziankami po wdrożeniu — dokładnie wiesz, co użytkownicy doświadczą.
🤖 Przetestuj cały zespół agentów i logikę delegacji
W przypadku konfiguracji wieloagentowych, Oceny pokazują, jak Twój menedżer deleguje zadania, które pod-agenty uczestniczą i czy przestrzegają oczekiwanego przepływu pracy. Możesz szybko wykryć:
niepotrzebne delegacje
brakujące delegacje
konfliktujące agenty
nieprawidłowe zachowanie ról
To jest kluczowe dla niezawodnej pracy zespołowej w Twojej AI.
📚 Wykryj słabe punkty w swojej bazie wiedzy
Jeśli ocena pokazuje powtarzające się błędy w konkretnym temacie, wiesz, że problemem nie jest agent — to brakujące lub niejasne treści. Oceny pomagają Ci udoskonalić swoją KB w ukierunkowany, oparty na danych sposób, zamiast ślepo dodawać więcej materiału.
🚨 Wykryj halucynacje i niespójności wcześnie
Ponieważ każde pytanie jest testowane wielokrotnie, Oceny ujawniają subtelne problemy, takie jak:
odpowiedzi zmieniające się nieprzewidywalnie
dryfowanie rozumowania
zgadywanie faktów zamiast użycia narzędzi
sprzeczności w przebiegach
To są problemy, których nigdy nie zidentyfikujesz, testując ręcznie raz lub dwa razy.
🧠 Udoskonal instrukcje systemowe dzięki ulepszeniom generowanym przez AI
Analiza nie tylko pokazuje, co poszło nie tak — mówi Ci jak to naprawić.
Otrzymujesz praktyczne rekomendacje poparte diagnostyką modelu:
ulepszone sformułowania
surowsze zasady
obowiązkowe użycie narzędzi
jaśniejsze zasady delegacji
bardziej precyzyjny ton i struktura
To zautomatyzowane inżynierowanie promptów wbudowane bezpośrednio w Twój przepływ pracy.
📈 Mierz postępy za każdym razem, gdy aktualizujesz swojego agenta
Ilekroć zmieniasz:
prompt systemowy
wpis w bazie wiedzy
narzędzie
zasadę delegacji
politykę rozumowania
…możesz ponownie uruchomić tę samą ocenę i porównać wyniki. Widzisz dokładnie, jak Twoja aktualizacja wpłynęła na wydajność — pozytywnie lub negatywnie.
Oceny stają się Twoją pętlą ciągłego doskonalenia.
✔ Zapewnij wysokiej jakości, zgodne odpowiedzi w całej organizacji
Niezależnie od tego, czy obsługujesz wsparcie, analizę finansową, scenariusze zdrowotne, czy treści prawnie wrażliwe, Oceny pozwalają Ci zapewnić:
przestrzeganie polityk
poszanowanie wytycznych dotyczących tonu
flagi niebezpiecznych luk
ujawnienie nieprawidłowego rozumowania
spełnienie standardów zgodności
To jest szczególnie krytyczne dla AI w przedsiębiorstwach i skierowanej do klienta.
Użycie i Koszty
Oceny Agentów używają dokładnie tego samego modelu kredytowego co reszta AgentX. Każdy przebieg testowy po prostu zużywa kredyty w taki sam sposób, jak normalna wiadomość agenta - bez dodatkowych opłat, bez ukrytych cen. Zawsze wiesz dokładnie, na co wydajesz, ponieważ Oceny podążają za Twoimi istniejącymi limitami planu i saldem kredytowym.
Twoja Warstwa Kontroli Jakości dla AI
W tradycyjnym oprogramowaniu QA zapewnia niezawodność.
W AgentX, Oceny są Twoim QA dla agentów.
Definiujesz, jak wygląda „dobre”.
AgentX sprawdza, czy Twoi agenci mogą to dostarczyć konsekwentnie — i pokazuje Ci dokładnie, co poprawić, gdy tego nie robią.
Oceny przekształcają AI z czarnej skrzynki w przejrzysty, mierzalny, ulepszany system.