AI-agentutvärdering: Introducerar Agentutvärderingar: Det mest tillförlitliga sättet att förstå och förbättra dina AI-agenter
AI-agenter blir mer avancerade, mer kapabla och mer djupt integrerade i företag.
Men det finns ett universellt problem som varje team står inför:
Din agent svarar inte alltid som du förväntar dig - och du vet inte varför.
Ibland ändras resonemanget, ibland ignorerar agenten en regel, ibland användes verktyget inte korrekt, och ibland missförstods en subtil instruktion. Utan insyn i hur beslut fattades, känns det som gissningsarbete att förbättra agenten.
Det är precis därför vi byggde Agentutvärderingar - ett nytt system inom AgentX som låter dig testa, mäta och djupt analysera hur din agent beter sig över flera körningar av samma fråga.
Det är första gången du kan se inuti din agents beslutsfattande, hitta inkonsekvenser och förstå exakt var förbättringar behövs.
Varför utvärderingar är viktiga
AI-modeller är probabilistiska.
Även med samma prompt, kontext och regler kan modellen:
producera något olika resonemangsvägar
utelämna en nödvändig detalj
missförstå en policy
hoppa över en verktygsuppslagning
ge osäkra svar istället för det förväntade definitiva
delegera inkonsekvent inom ett team
Utifrån ser du bara det slutliga svaret.
Du ser inte:
om agenten följde dina instruktioner
om den använde rätt verktyg
om den resonerade korrekt
varför en version av svaret var svagare än en annan
varför den ibland får saker rätt — och ibland fel
Utvärderingar löser detta genom att ge dig struktur, poängsättning och transparens.
Hur ett test fungerar
Att skapa en utvärdering är enkelt:
0. Välj agent eller team som du vill utvärdera.
1. Testfråga
Detta är den verkliga frågan du vill validera.
Den simulerar en kundförfrågan eller en intern arbetsflödesbegäran.
Exempel:
“Kan jag returnera en slutrea-artikel om den inte passar?”
Detta utgör kärnan i utvärderingen.
2. Förväntade resultat (Obligatoriskt)
Detta är den viktigaste delen av konfigurationen.
Här definierar du vad agenten MÅSTE säga eller inkludera för att svaret ska anses korrekt.
Det kan innehålla:
nyckelfakta
obligatoriska fraser
nödvändiga resonemangssteg
efterlevnadsregler
specifik ton eller policyuttalanden
Exempel:
“Måste säga: Nej, slutrea-artiklar är inte returnerbara eller utbytbara.”
De förväntade resultaten blir bedömningsmallen för alla testrundor.
3. Förväntade kapaciteter (Valfritt men kraftfullt)
Du kan tala om för utvärderingssystemet vilka verktyg, dokument eller kunskapskällor agenten bör använda.
I ditt exempel valde du:
Documents → store_policy_kb_v1.xlsx
Inbyggda funktioner
Detta betyder:
Agenten borde hämta information från policy-KB.
Om den inte använder KB korrekt, kommer utvärderingen att fånga det.
Detta är perfekt för:
policyagenter
kundtjänstagenter
efterlevnadsarbetsflöden
finansmodellering
databaserat resonemang
4. Utvärderingsinställningar
Detta avsnitt definierar hur rigorös och hur djup din utvärdering ska vara.
Antal testrundor
Samma fråga körs flera gånger (Rekommenderat: 5 rundor).
Varför?
För att AI-modeller inte är deterministiska. Flera körningar låter dig kontrollera:
konsekvens
stabilitet
resonemangets tillförlitlighet
om agenten följer samma process varje gång
Om agenten producerar ett bra svar och fyra misslyckanden, kommer du att se det direkt.
Acceptanskriterier
Denna reglage definierar hur strikt svaret måste matcha dina förväntade resultat.
Du väljer en punkt mellan:
Generös → agenten kan avvika från dina förväntningar; svaret behöver inte vara perfekt.
Exakt → svaret måste följa dina förväntningar mycket noggrant, med nästan inget utrymme för variation.
Det kontrollerar helt enkelt hur exakt svaret behöver vara för att klara utvärderingen.
Avvisningskriterier (Valfritt)
Regler för automatisk misslyckande.
Exempel:
“Svaret bör inte nämna konkurrenter.”
“Erbjud inte återbetalningar när policyn förbjuder det.”
“Svaret bör inte be användaren att lämna personlig information.”
Dessa är hårda begränsningar.
Utvärderingskriterier (Valfritt)
Ytterligare poängvägledning, ofta använd för kvalitet eller ton.
Exempel:
“Svaret bör vara vänligt och professionellt.”
“Svaret måste innehålla en kort förklaring, inte bara ett ja/nej.”
“Använd KB-fakta före antaganden.”
Dessa är inte strikta krav men hjälper till att forma hur AI poängsätter agenten.
5. Skapa utvärdering
När det är konfigurerat, startar processen genom att klicka på Skapa utvärdering:
frågan körs flera gånger
varje svar poängsätts
en detaljerad analys genereras
delegering och verktygsanvändning inspekteras
inkonsekvenser lyfts fram
Och du får tillbaka en komplett prestationsrapport.
Vad du får efter att ha kört utvärderingen
Efter flera körningar ger AgentX två lager av output:
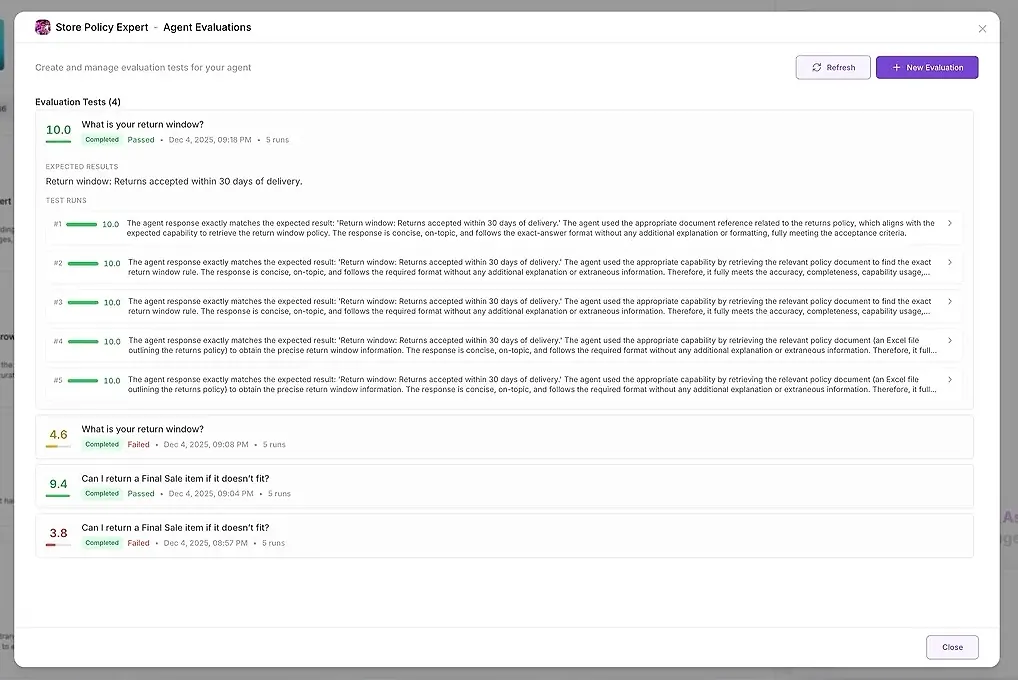
1. Testresultat
För varje körning ser du:
en numerisk poäng
en sammanfattning av hur väl det matchade dina förväntningar
det fullständiga svaret
vilka verktyg som användes
vilka agenter som deltog
var agenten misslyckades eller avvek
Detta låter dig jämföra svar sida vid sida och identifiera mönster.
2. Djup AI-analys
Detta är där den verkliga magin händer.
AgentX analyserar automatiskt alla körningar och genererar en strukturerad rapport över flera kategorier:
• Instruktionsföljsamhet
Följde agenten dina regler?
• Svarsmönster
Hur lika eller olika var svaren?
Finns det avvikare?
• Resonemangsanalys
Var resonemangsstegen korrekta, kompletta och i linje med förväntningarna?
• Verktygsanvändning
Använde agenten rätt verktyg?
Hoppade den över en uppslagning?
Lutade den sig på antaganden istället för verifierade fakta?
• Rekommendationer
Konkreta, handlingsbara förslag för att förbättra din agent.
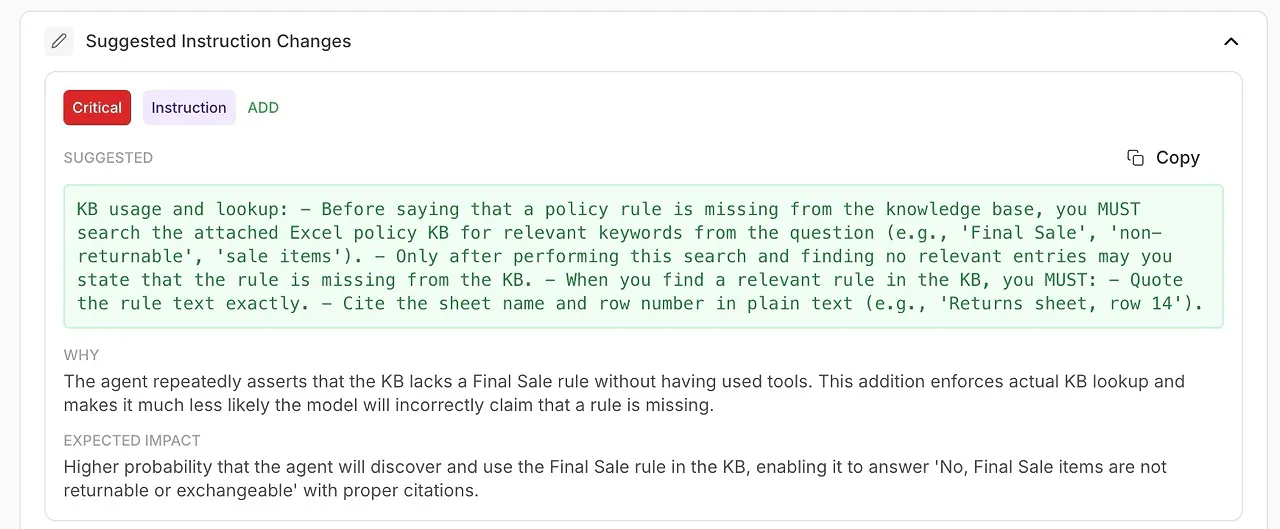
• Föreslagna instruktionsändringar
Automatiskt genererade förbättringar av ditt systemprompt eller agentkonfiguration.
• Övergripande bedömning
En sammanfattning av styrkor, svagheter och förtroendenivå.
Detta förvandlar felsökning från en gissningslek till en vetenskaplig, upprepbar process.
Vad denna funktion möjliggör
Utvärderingar introducerar en ny nivå av transparens och tillförlitlighet i hur dina agenter fungerar. Istället för att gissa varför ett svar var fel eller inkonsekvent, har du nu ett strukturerat, mätbart sätt att förstå beteende, diagnostisera problem och kontinuerligt förbättra prestanda.
Här är vad som blir möjligt:
🔍 Validera din agent innan du lanserar den till kunder
Innan du skickar en agent i produktion kan du köra realistiska tester som avslöjar om den fullt ut förstår dina regler, kunskapsbas och önskad ton. Inga fler överraskningar efter implementering — du vet exakt vad användarna kommer att uppleva.
🤖 Testa hela ditt agentteam och delegeringslogik
För multi-agentuppsättningar visar utvärderingar hur din chef delegerar uppgifter, vilka underagenter som deltar och om de följer det förväntade arbetsflödet. Du kan snabbt upptäcka:
onödiga delegeringar
saknade delegeringar
konfliktagenter
felaktigt rollbeteende
Detta är avgörande för tillförlitligt teamwork inom din AI-arbetsstyrka.
📚 Upptäck svaga punkter i din kunskapsbas
Om en utvärdering visar upprepade misslyckanden inom ett specifikt ämne, vet du att problemet inte är agenten — det är saknad eller oklar information. Utvärderingar hjälper dig att förfina din KB på ett riktat, datadrivet sätt, istället för att blint lägga till mer material.
🚨 Fånga hallucinationer och inkonsekvens tidigt
Eftersom varje fråga testas flera gånger, lyfter utvärderingar fram subtila problem som:
svar som ändras oförutsägbart
resonemang som driver iväg
faktuell gissning som ersätter verktygsanvändning
motsägelser över körningar
Dessa är problem du aldrig skulle identifiera genom att testa manuellt en eller två gånger.
🧠 Förfina systeminstruktioner med AI-genererade förbättringar
Analysen visar inte bara vad som gick fel — den berättar hur man fixar det.
Du får handlingsbara rekommendationer stödda av modellens egna diagnostik:
förbättrad formulering
strängare regler
obligatorisk verktygsanvändning
tydligare delegeringspolicyer
mer exakt ton och struktur
Detta är automatiserad prompt engineering direkt inbyggd i ditt arbetsflöde.
📈 Mät framsteg varje gång du uppdaterar din agent
Närhelst du ändrar:
en systemprompt
en kunskapsbaspost
ett verktyg
en delegeringsregel
en resonemangspolicy
…du kan köra om samma utvärdering och jämföra poäng. Du ser exakt hur din uppdatering påverkade prestanda — positivt eller negativt.
Utvärderingar blir din kontinuerliga förbättringsloop.
✔ Säkerställ högkvalitativa, efterlevnadskompatibla svar över hela din organisation
Oavsett om du hanterar support, finansiell analys, vårdscenarier eller juridiskt känsligt innehåll, låter utvärderingar dig säkerställa:
policys följs
tonriktlinjer respekteras
farliga luckor flaggas
felaktigt resonemang lyfts fram
efterlevnadsstandarder uppfylls
Detta är särskilt kritiskt för företags- och kundorienterad AI.
Användning och kostnader
Agentutvärderingar använder exakt samma kreditmodell som resten av AgentX. Varje testrunda förbrukar helt enkelt krediter på samma sätt som ett vanligt agentmeddelande gör - inga extra avgifter, inga dolda priser. Du vet alltid exakt vad du spenderar, eftersom utvärderingar följer dina befintliga planbegränsningar och kreditbalans.
Din kvalitetskontrollager för AI
I traditionell programvara säkerställer QA tillförlitlighet.
I AgentX, är utvärderingar din QA för agenter.
Du definierar vad "bra" ser ut som.
AgentX kontrollerar om dina agenter kan leverera det konsekvent — och visar dig exakt vad du ska förbättra när de inte gör det.
Utvärderingar förvandlar AI från en svart låda till ett transparent, mätbart, förbättringsbart system.