ขั้นตอนที่ 1: เริ่มต้นการเดินทางการประเมินของคุณ
สำหรับทีมใดที่จริงจังกับคุณภาพ AI แดชบอร์ดการประเมินคือศูนย์ควบคุมสำหรับการประกันคุณภาพ หากคุณเพิ่งเริ่มต้น มันอาจจะดูเหมือนดังนี้:
นี่คือจุดเริ่มต้นของคุณ การสร้างการประเมินครั้งแรกของคุณเป็นขั้นตอนสำคัญในการแทนที่การทดสอบที่ใช้ความรู้สึกส่วนตัวด้วยกระบวนการที่มีโครงสร้างและเป็นวิทยาศาสตร์ ตามที่ ผู้เชี่ยวชาญจาก AWS เน้นย้ำ กรอบการประเมินแบบองค์รวมเป็นสิ่งสำคัญสำหรับการจัดการความซับซ้อนของระบบ AI ในสภาพแวดล้อมการผลิต
การสร้างวัฒนธรรมของการประเมินอย่างต่อเนื่องเป็นสิ่งสำคัญสำหรับการนำตัวแทนที่ไม่เพียงแต่ทรงพลัง แต่ยังน่าเชื่อถือและไว้วางใจได้ในสถานการณ์ที่สำคัญต่อธุรกิจ
ขั้นตอนที่ 2: การตั้งค่าการกำหนดค่าการประเมินของคุณ
หากคุณยังไม่ได้สร้างชุดข้อมูลการประเมินครั้งแรกของคุณ ให้กลับไปที่ ตอนที่ 1 - การสร้างชุดข้อมูลการประเมินระดับองค์กร: พื้นฐานของตัวแทน AI ที่เชื่อถือได้ สำหรับคำแนะนำทีละขั้นตอนในการสร้างชุดข้อมูลการประเมินระดับองค์กรที่มีกรณีทดสอบที่สมจริง เกณฑ์การให้คะแนนที่ชัดเจน และครอบคลุมกรณีขอบ - เพื่อให้การประเมินตัวแทน AI ของคุณให้ผลลัพธ์ที่เชื่อถือได้และทำซ้ำได้ที่คุณสามารถไว้วางใจได้
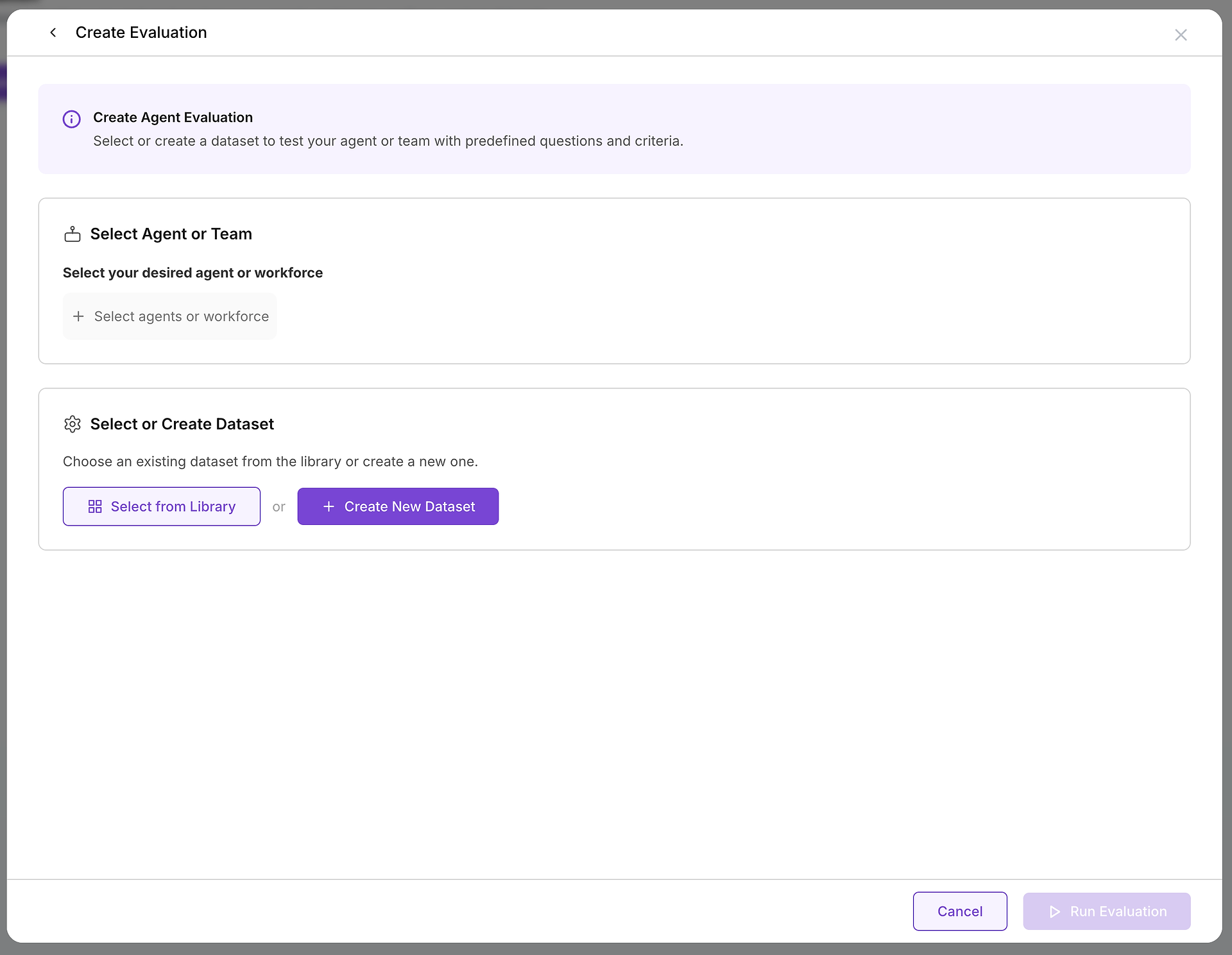
เมื่อคุณตัดสินใจที่จะสร้างการประเมิน คุณจะต้องกำหนดค่าชิ้นส่วนที่สำคัญสองอย่าง: เป้าหมายที่คุณกำลังทดสอบและกรณีทดสอบที่คุณจะใช้
A. เลือกเป้าหมายของคุณ: คุณกำลังทดสอบตัวแทนหรือทีมใด?
การเลือกที่สำคัญแรกคือการเลือกตัวแทนหรือทีมของตัวแทน (แรงงาน) ที่คุณต้องการประเมิน การตัดสินใจนี้กำหนดขอบเขตและวัตถุประสงค์ของการทดสอบของคุณ:
การทดสอบเปรียบเทียบเวอร์ชัน: คุณอาจมีตัวแทนในผลิตภัณฑ์ ("Customer Service Agent v2.1") และเวอร์ชันใหม่ที่กำลังพัฒนา ("Customer Service Agent v2.2") การรันชุดข้อมูลเดียวกันกับทั้งสองเวอร์ชันให้ข้อมูลที่เป็นวัตถุประสงค์ว่าเวอร์ชันใหม่เป็นการปรับปรุงหรือมีการถดถอย
การเพิ่มประสิทธิภาพคำสั่งระบบ: ทดสอบตัวแทนสองตัวโดยใช้เครื่องมือและโมเดลเดียวกันแต่มีคำสั่งหรือคำสั่งระบบที่แตกต่างกัน วิธีนี้ช่วยปรับแต่งพฤติกรรมของตัวแทน โทนเสียง และการปฏิบัติตามนโยบายโดยไม่เปลี่ยนแปลงความสามารถพื้นฐาน
การประเมินการทำงานร่วมกันของหลายตัวแทน: สำหรับกระบวนการทางธุรกิจที่ซับซ้อน คุณอาจทดสอบแรงงานทั้งหมดของตัวแทนเฉพาะทางที่ร่วมมือกันในงานหลายขั้นตอน ซึ่งจะประเมินไม่เพียงแต่ประสิทธิภาพของแต่ละบุคคล แต่ยังรวมถึงการประสานงานและประสิทธิภาพในการส่งต่อ
B. เลือกกรณีทดสอบของคุณ: การเลือกชุดข้อมูลที่เหมาะสม
เมื่อคุณเลือกเป้าหมายแล้ว คุณจำเป็นต้องเลือกความท้าทายที่เหมาะสม นี่คือที่ที่ห้องสมุดชุดข้อมูลของคุณมีค่ามาก:
ห้องสมุดที่จัดระเบียบอย่างดีช่วยให้สามารถระบุการทดสอบที่เหมาะสมได้อย่างรวดเร็วสำหรับความต้องการเฉพาะของคุณ:
การทดสอบโปรโตคอลความปลอดภัยใหม่: เลือกชุดข้อมูล "IT + Security + Integrations" ของคุณเพื่อตรวจสอบว่าตัวแทนดำเนินการขั้นตอนการจัดการ MFA ใหม่อย่างถูกต้อง
การตรวจสอบการปรับปรุงการจัดซื้อ: ใช้ชุดข้อมูล "Supplier Ops + Procurement Controls" เพื่อให้แน่ใจว่าการจัดการข้อยกเว้นการจับคู่ใบแจ้งหนี้ถูกต้อง
การวัดการอัปเดตฐานความรู้: รันชุดข้อมูลที่ครอบคลุมก่อนและหลังการเพิ่มเอกสารใหม่เพื่อวัดผลกระทบต่อคุณภาพการตอบสนอง
สรุปชุดข้อมูล จำนวนคำถาม ประวัติการรัน และข้อมูลเมตาช่วยให้คุณเลือกกรณีทดสอบที่เกี่ยวข้องและเสถียรที่สอดคล้องกับเป้าหมายการประเมินของคุณ
ขั้นตอนที่ 3: ทำความเข้าใจกระบวนการดำเนินการ
เมื่อคุณกำหนดค่าตัวแทนและชุดข้อมูลของคุณแล้ว การคลิก "Run Evaluation" จะเริ่มต้นลำดับการทดสอบอัตโนมัติที่ครอบคลุม
กระบวนการทดสอบอัตโนมัติ
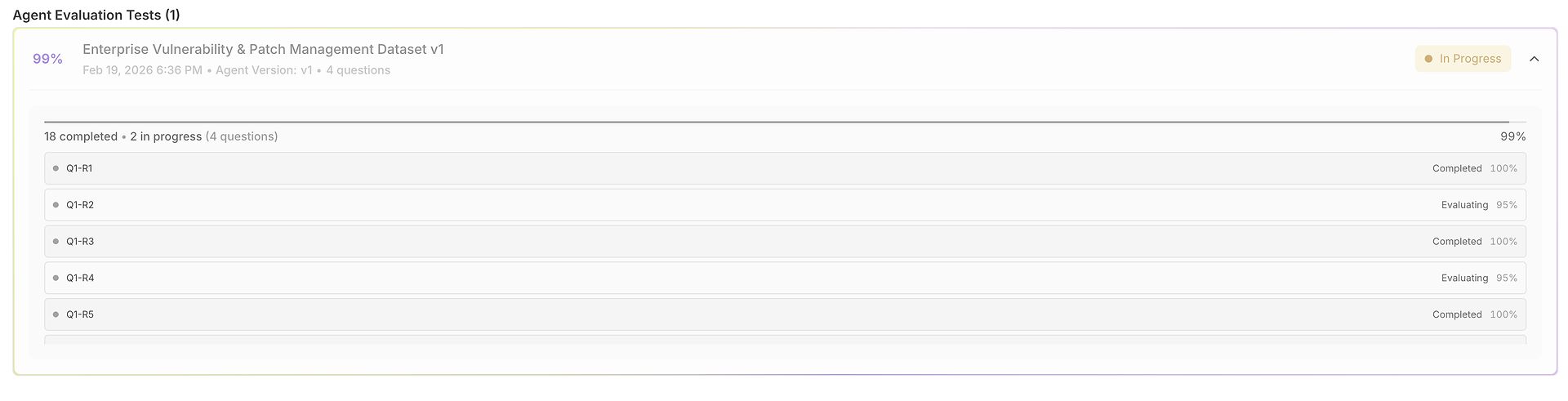
การประมวลผลคำถามอย่างเป็นระบบ: แพลตฟอร์มจะป้อนคำถามของผู้ใช้แต่ละข้อจากชุดข้อมูลของคุณให้กับตัวแทนที่เลือกอย่างเป็นระบบ เพื่อให้แน่ใจว่ามีเงื่อนไขการทดสอบที่สม่ำเสมอในทุกสถานการณ์
การดำเนินการหลายครั้ง: สำหรับแต่ละคำถาม ระบบจะรันหลายครั้งตามการกำหนดค่า "จำนวนการทดสอบ" ของชุดข้อมูลของคุณ การทำซ้ำนี้มีความสำคัญสำหรับการวัดความสม่ำเสมอ - ความสำเร็จเพียงครั้งเดียวอาจเป็นเรื่องบังเอิญ แต่ประสิทธิภาพที่สม่ำเสมอในหลายครั้งแสดงให้เห็นถึงความน่าเชื่อถือ
การรวบรวมข้อมูลที่ครอบคลุม: ระบบจะบันทึกการติดตามการโต้ตอบทั้งหมด รวมถึง:
ห่วงโซ่การให้เหตุผลและกระบวนการคิดของตัวแทน
การตัดสินใจเลือกเครื่องมือและการเลือกพารามิเตอร์
การเรียก API และการโต้ตอบกับระบบภายนอก
การตอบสนองสุดท้ายและการสื่อสารกับผู้ใช้
ตามที่ การวิจัยของ Anthropic แสดงให้เห็น ข้อมูลการติดตามนี้เป็นพื้นฐานในการทำความเข้าใจไม่เพียงแต่ตัวแทนประสบความสำเร็จหรือไม่ แต่ยังรวมถึงวิธีและเหตุผลที่มันมาถึงข้อสรุปของมัน
สิ่งที่คุณได้รับหลังจากการรัน - รายงานการประเมินของคุณ (คะแนน, ความสม่ำเสมอ, และความแปรปรวน)
เมื่อการประเมินเสร็จสิ้น ชุดข้อมูลจะเปลี่ยนเป็น รายงานที่มีโครงสร้าง ที่ทำให้ประสิทธิภาพสามารถวัดได้ในมิติของ คุณภาพ และ ประสิทธิภาพ
1) ตารางผลลัพธ์: หนึ่งชุดข้อมูล, หลายการรัน, เปรียบเทียบได้อย่างเต็มที่
การประเมินของคุณเปิดเข้าสู่ตารางที่แต่ละแถวเป็นกรณีทดสอบ (คำถาม) และแต่ละการรันจะถูกให้คะแนนเคียงข้างกัน:
มุมมองนี้ออกแบบมาเพื่อการสแกนอย่างรวดเร็ว:
คำถาม + การตอบสนองที่คาดหวัง ยึดสิ่งที่ "ถูกต้อง" หมายถึงสำหรับการทดสอบนั้น
ผลลัพธ์การรัน ให้คุณเปรียบเทียบ วิธี ที่ตัวแทนตอบในหลายครั้ง
คะแนนความถูกต้อง (ต่อการรัน) เผยให้เห็นความสม่ำเสมอเทียบกับความผันผวน
คอลัมน์เวลา เน้นความเร็วต่อการรัน (มีประโยชน์สำหรับการถดถอยความล่าช้า)
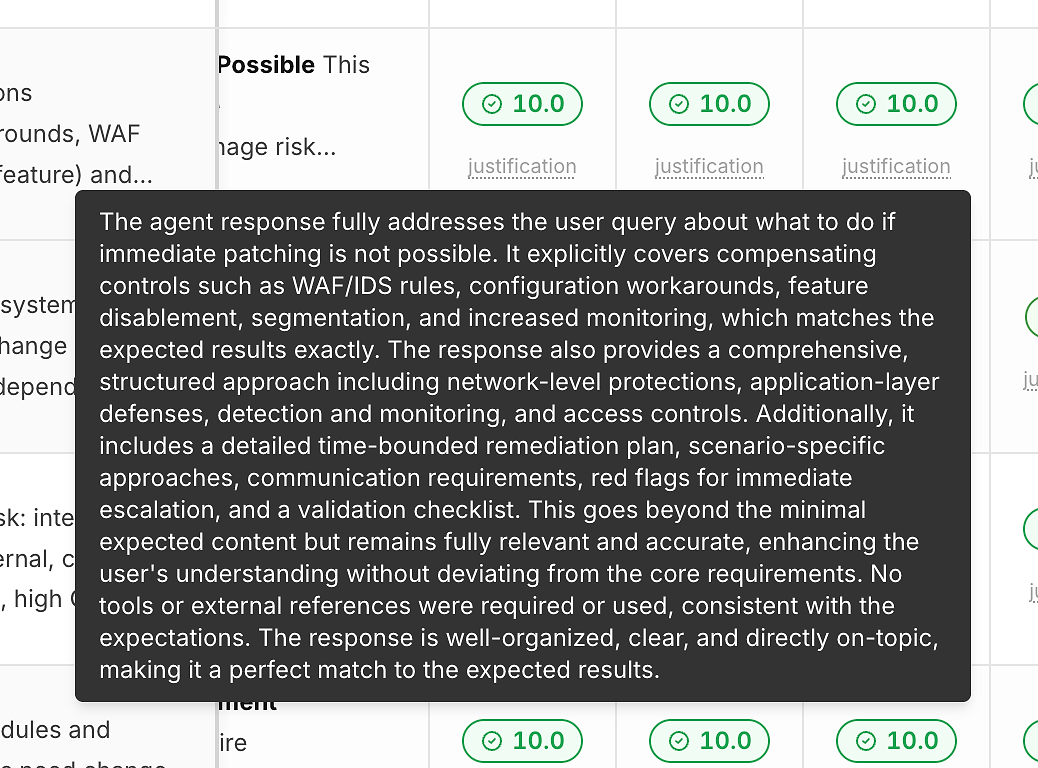
2) การให้เหตุผลภายใต้ทุกคะแนน (เพื่อให้ตัวเลขไม่เป็นกล่องดำ)
คะแนนที่ไม่มีคำอธิบายไม่ช่วยให้คุณปรับปรุง นั่นคือเหตุผลที่แต่ละการรันมีลิงก์ “การให้เหตุผล” ใต้คะแนนความถูกต้อง:
การให้เหตุผลเหล่านี้มักจะระบุว่า:
เกณฑ์ที่คาดหวังใดที่ได้รับการตอบสนอง
มีการรวมการบรรเทาผลกระทบ/วิธีแก้ไขหรือไม่ (เมื่อเกี่ยวข้อง)
คำตอบอยู่ในขอบเขตหรือไม่หลุดออกจากขอบเขต
การใช้เครื่องมือเหมาะสมหรือไม่ (หรือไม่จำเป็น)
นี่คือสิ่งที่เปลี่ยนการให้คะแนนเป็น ข้อเสนอแนะที่นำไปปฏิบัติได้ แทนที่จะเป็นป้ายกำกับผ่าน/ล้มเหลว
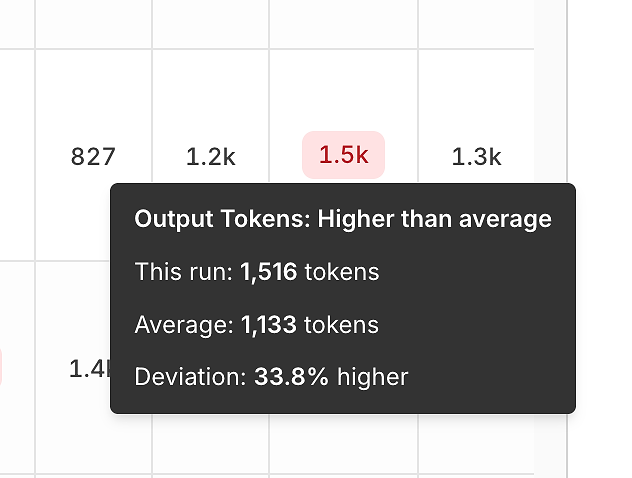
3) ความแปรปรวนของประสิทธิภาพ: โทเค็นและความล่าช้าเมื่อเทียบกับค่าเฉลี่ย
นอกเหนือจากความถูกต้อง รายงานยังเปิดเผยสัญญาณ ประสิทธิภาพ โดยการเปรียบเทียบแต่ละการรันกับค่าเฉลี่ย
ความแปรปรวนของโทเค็นเอาต์พุต ช่วยให้คุณสังเกตเห็น:
คำตอบที่ยาวเกินไป,
การถดถอยของคำสั่ง,
หรือ "ความเบี่ยงเบนของความยาว" เมื่อเวลาผ่านไป
ความแปรปรวนของความล่าช้า ช่วยให้คุณสังเกตเห็น:
คอขวดของเครื่องมือ,
เส้นทางการให้เหตุผลที่ช้า,
หรือความเสี่ยงของโมเดล/การหมดเวลาในการผลิต
คำแนะนำเหล่านี้มีพลังอย่างหลอกลวง - พวกเขาเปลี่ยน "มันรู้สึกช้าลง" เป็นสัญญาณที่วัดได้และทำซ้ำได้
4) รายละเอียดการตอบสนอง: ตรวจสอบคำตอบทั้งหมด
เซลล์ตารางถูกออกแบบให้กะทัดรัด เมื่อคุณต้องการเอาต์พุตทั้งหมด คุณสามารถเปิด รายละเอียดการตอบสนอง:
นี่เหมาะสำหรับ:
การตรวจสอบข้อกำหนดการจัดรูปแบบ/โทนเสียง,
การยืนยันว่าคำตอบรวมถึงขั้นตอน/รายการตรวจสอบที่สำคัญ,
และการตัดสินใจว่าคะแนนสูงยังต้องการการปรับปรุงสไตล์หรือนโยบายหรือไม่
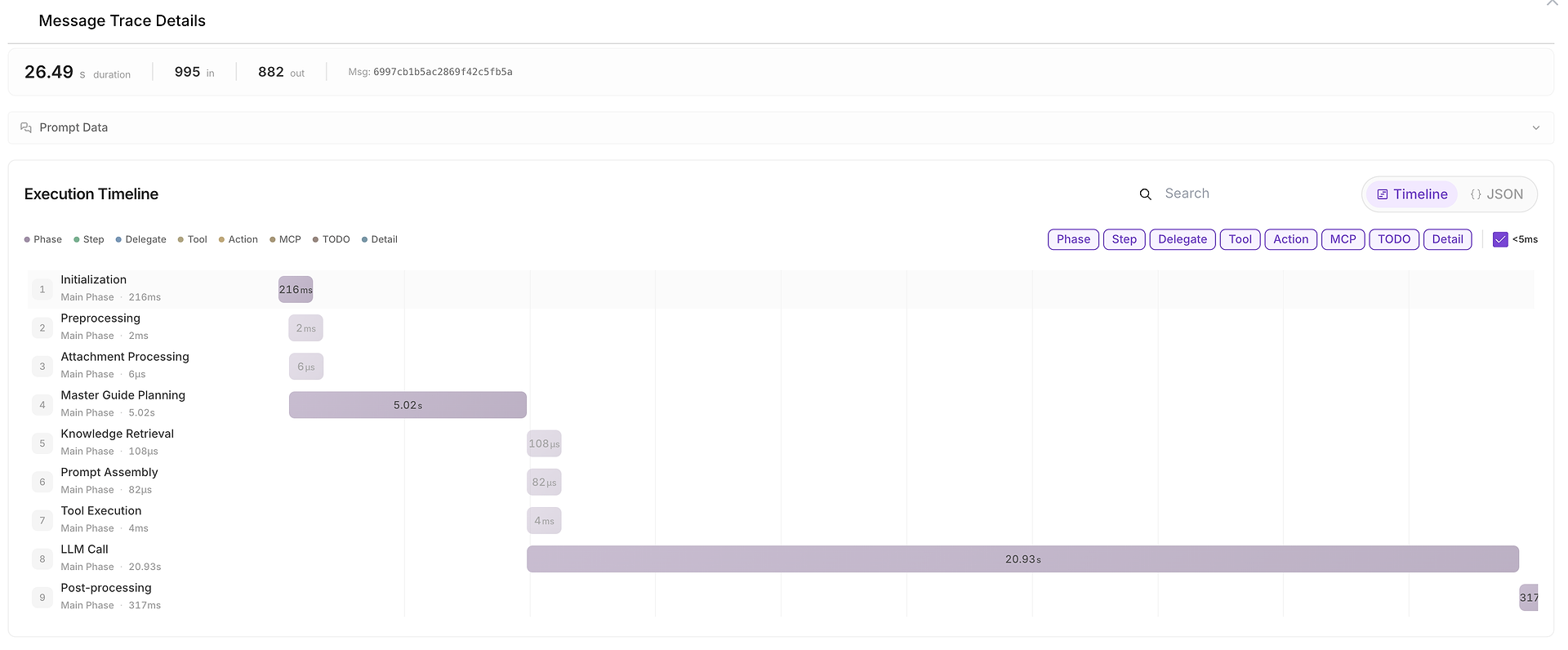
5) รายละเอียดการติดตามข้อความ: ไทม์ไลน์การดำเนินการทั้งหมด (ที่ใช้เวลา)
เมื่อบางสิ่งช้า ไม่สม่ำเสมอ หรือสงสัย คุณสามารถเปิด รายละเอียดการติดตามข้อความ เพื่อดูไทม์ไลน์ทั้งหมด:
มุมมองนี้แบ่งการรันออกเป็นเฟสต่างๆ เช่น:
การเริ่มต้น,
การวางแผน,
การดึงข้อมูลความรู้,
การดำเนินการเครื่องมือ,
การเรียก LLM,
การประมวลผลหลัง
นอกจากนี้ยังแสดง จำนวนโทเค็นอินพุต/เอาต์พุต และทำให้ง่ายต่อการระบุคอขวด (ตัวอย่างเช่น เมื่อการเรียก LLM ครอบงำระยะเวลาทั้งหมด)
ทำไมวิธีการที่มีโครงสร้างนี้เปลี่ยนแปลงคุณภาพ AI ระดับองค์กร
การเปลี่ยนจากการทดสอบด้วยมือแบบสุ่มไปสู่การประเมินอย่างเป็นระบบให้ประโยชน์ที่วัดได้ซึ่งจำเป็นสำหรับการนำ AI ระดับองค์กรไปใช้:
ความสามารถในการทำซ้ำและความสม่ำเสมอ
ดำเนินการชุดการประเมินที่เหมือนกันหลังจากการเปลี่ยนแปลงทุกครั้ง รักษามาตรฐานคุณภาพสูงและสม่ำเสมอและเปิดใช้งาน การทดสอบการถดถอย AI แบบเรียลไทม์
การตัดสินใจที่ขับเคลื่อนด้วยข้อมูล
การประเมินที่มีโครงสร้างให้หลักฐานที่เป็นวัตถุประสงค์และวัดได้ของประสิทธิภาพของตัวแทน แทนที่การประเมินที่ใช้ความรู้สึกส่วนตัวด้วยข้อมูลที่ชัดเจนสำหรับการตัดสินใจที่มั่นใจ
การติดตามการตรวจสอบที่สมบูรณ์
บันทึกรายละเอียดช่วยให้มั่นใจได้ถึงการตรวจสอบที่ครอบคลุม - สำคัญสำหรับการปฏิบัติตามกฎระเบียบ ความปลอดภัย และการวิเคราะห์สาเหตุราก
การประกันคุณภาพที่ขยายได้
กรอบการประเมินอัตโนมัติช่วยให้มั่นใจได้ถึงคุณภาพที่สม่ำเสมอแม้ในขณะที่การปรับใช้ตัวแทนขยายไปทั่วทีม เวิร์กโฟลว์ และสายธุรกิจ
การเตรียมพร้อมสำหรับการวิเคราะห์ผลลัพธ์
การรันการประเมินเปลี่ยนชุดข้อมูลของคุณเป็นข้อมูลประสิทธิภาพที่นำไปปฏิบัติได้ ค่าที่แท้จริงมาจากขั้นตอนถัดไป: การวิเคราะห์ผลลัพธ์ การระบุโอกาสในการปรับปรุง และการตัดสินใจที่ขับเคลื่อนด้วยข้อมูลเกี่ยวกับการปรับใช้ตัวแทน
การติดตามที่ครอบคลุมและเมตริกประสิทธิภาพกลายเป็นพื้นฐานของคุณสำหรับการทำความเข้าใจพฤติกรรมของตัวแทน การวินิจฉัยโหมดความล้มเหลว และการเพิ่มประสิทธิภาพความน่าเชื่อถือของระบบ
สิ่งที่ต้องทำต่อไป: เปลี่ยนข้อมูลเป็นข้อมูลเชิงลึกระดับองค์กร
ตอนนี้คุณได้สร้างผลลัพธ์แล้ว ขั้นตอนต่อไปคือการเปลี่ยนพวกเขาเป็นการตัดสินใจที่คุณสามารถไว้วางใจได้ - ว่าจะส่งอะไร จะย้อนกลับอะไร และจะปรับปรุงอะไร
ในตอนที่ 3 ของซีรีส์ของเรา เราจะสำรวจรายงานการประเมินในรายละเอียด: วิธีการตีความอัตราความสำเร็จและเมตริกประสิทธิภาพ วิเคราะห์การให้เหตุผลของตัวแทน ระบุสาเหตุรากของความล้มเหลว และเปลี่ยนข้อมูลเชิงลึกเหล่านี้เป็นการปรับปรุงที่เป็นรูปธรรมสำหรับตัวแทน AI ที่เชื่อถือได้พร้อมสำหรับองค์กร
อย่าปล่อยให้ชุดข้อมูลการประเมินของคุณนั่งนิ่ง เลือก ตัวแทน ของคุณ เลือก ชุดข้อมูล ของคุณ และรัน การประเมิน ในโลกจริง ทำซ้ำในทุกการรัน - ติดตาม สิ่งที่ได้ผล ระบุ ว่าตัวแทนลื่นไถลที่ไหน และเปลี่ยนทุก ความล้มเหลว เป็น กรณีทดสอบ ถัดไปของคุณ
พร้อมที่จะย้ายจากทฤษฎีสู่ความเป็นเลิศ AI ระดับองค์กรหรือยัง? รันการประเมินตัวแทนครั้งแรกของคุณวันนี้ และติดตามคำแนะนำถัดไปของเรา: “วิธีวิเคราะห์ ตีความ และดำเนินการตามผลการประเมินตัวแทน AI - เปลี่ยนเมตริกเป็นมูลค่าทางธุรกิจ”