Bước 1: Bắt Đầu Hành Trình Đánh Giá Của Bạn
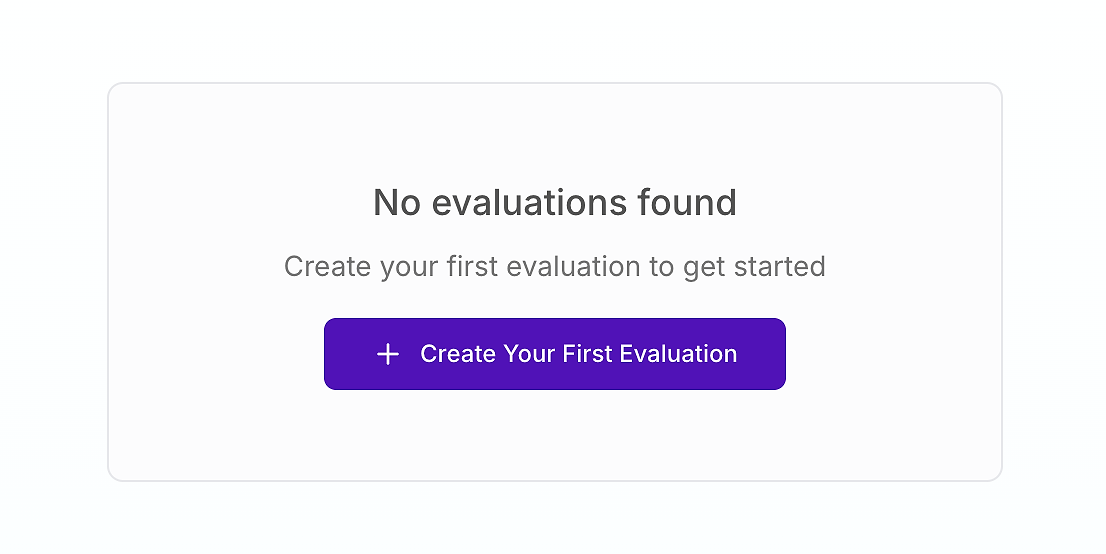
Đối với bất kỳ đội ngũ nào nghiêm túc về chất lượng AI, bảng điều khiển đánh giá là trung tâm chỉ huy cho đảm bảo chất lượng. Nếu bạn mới bắt đầu, nó có thể trông như thế này:
Đây là điểm xuất phát của bạn. Tạo đánh giá đầu tiên của bạn là bước quan trọng để thay thế kiểm tra "cảm giác ruột" chủ quan bằng một quy trình khoa học có cấu trúc. Như các chuyên gia từ AWS nhấn mạnh, một khung đánh giá toàn diện là cần thiết để giải quyết sự phức tạp của các hệ thống AI tác nhân trong môi trường sản xuất.
Thiết lập văn hóa đánh giá liên tục là rất quan trọng để triển khai các tác nhân không chỉ mạnh mẽ mà còn đáng tin cậy và đáng tin cậy trong các kịch bản quan trọng đối với doanh nghiệp.
Bước 2: Thiết Lập Cấu Hình Đánh Giá Của Bạn
Nếu bạn chưa tạo bộ dữ liệu đánh giá đầu tiên của mình, hãy quay lại Phần 1 - Xây Dựng Bộ Dữ Liệu Đánh Giá Cấp Doanh Nghiệp: Nền Tảng của Các Tác Nhân AI Đáng Tin Cậy để có hướng dẫn từng bước xây dựng bộ dữ liệu đánh giá cấp doanh nghiệp với các trường hợp kiểm tra thực tế, tiêu chí chấm điểm rõ ràng và phạm vi cho các trường hợp ngoại lệ - để đánh giá tác nhân AI của bạn tạo ra kết quả đáng tin cậy, có thể lặp lại mà bạn có thể tin tưởng.
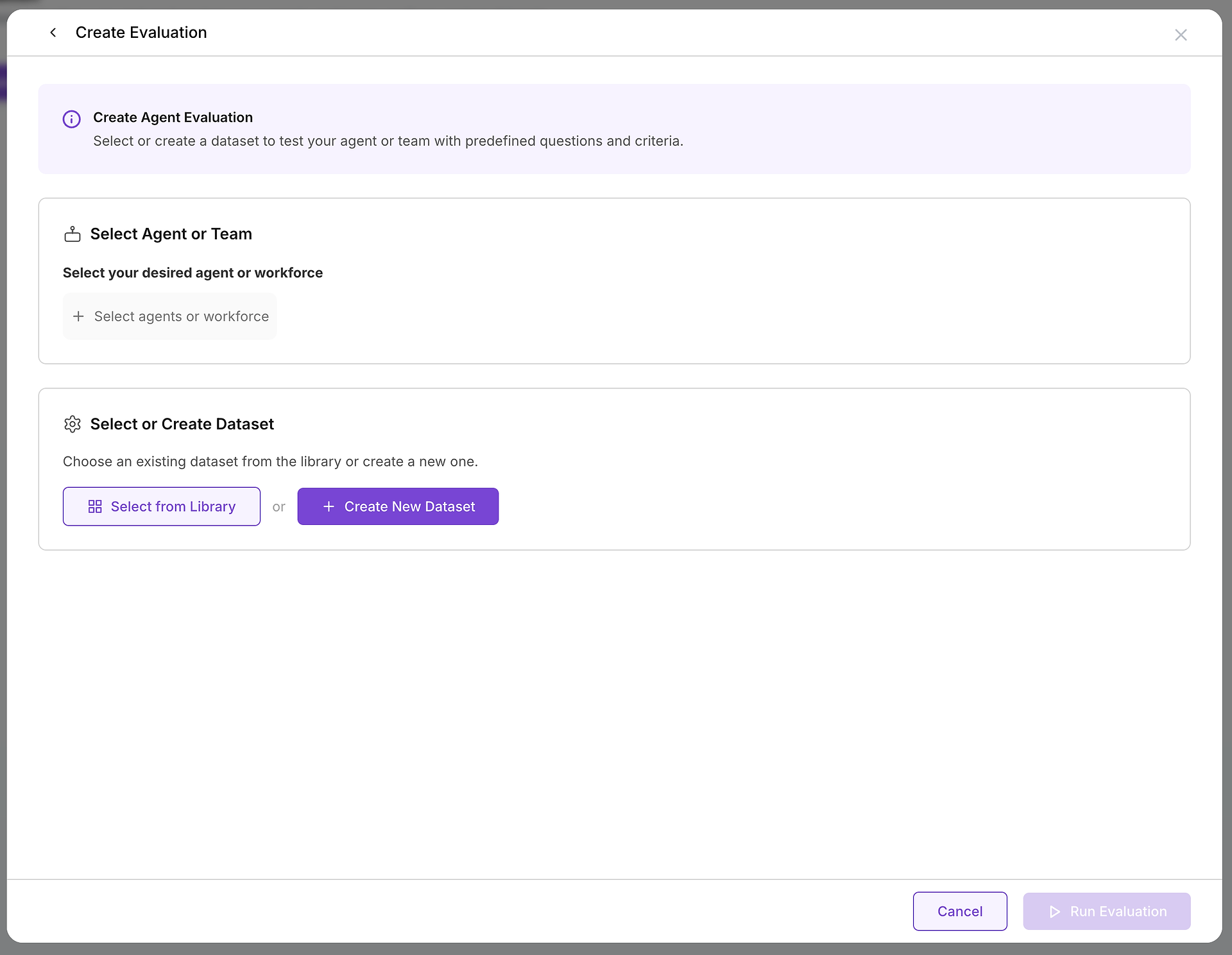
Một khi bạn quyết định tạo một đánh giá, bạn sẽ cấu hình hai thành phần thiết yếu: mục tiêu bạn đang kiểm tra và các trường hợp kiểm tra bạn sẽ sử dụng.
A. Chọn Mục Tiêu Của Bạn: Bạn Đang Kiểm Tra Tác Nhân hoặc Đội Ngũ Nào?
Lựa chọn quan trọng đầu tiên là chọn tác nhân hoặc đội ngũ tác nhân (một lực lượng lao động) mà bạn muốn đánh giá. Quyết định này xác định phạm vi và mục đích của bài kiểm tra của bạn:
Kiểm Tra So Sánh Phiên Bản: Bạn có thể có một tác nhân trong sản xuất ("Customer Service Agent v2.1") và một phiên bản mới đang phát triển ("Customer Service Agent v2.2"). Chạy cùng một bộ dữ liệu trên cả hai phiên bản cung cấp dữ liệu khách quan về việc liệu phiên bản mới có đại diện cho một cải tiến hay không hoặc giới thiệu các lỗi hồi quy.
Tối Ưu Hóa Lời Nhắc Hệ Thống: Kiểm tra hai tác nhân sử dụng cùng công cụ và mô hình nhưng với các hướng dẫn hoặc lời nhắc hệ thống khác nhau. Cách tiếp cận này giúp tinh chỉnh hành vi của tác nhân, giọng điệu và tuân thủ chính sách mà không thay đổi khả năng cơ bản.
Đánh Giá Quy Trình Làm Việc Đa Tác Nhân: Đối với các quy trình kinh doanh phức tạp, bạn có thể kiểm tra toàn bộ lực lượng lao động của các tác nhân chuyên biệt hợp tác trong các nhiệm vụ nhiều bước. Điều này không chỉ đánh giá hiệu suất cá nhân mà còn cả hiệu quả phối hợp và chuyển giao.
B. Chọn Các Trường Hợp Kiểm Tra Của Bạn: Lựa Chọn Bộ Dữ Liệu Phù Hợp
Với mục tiêu đã chọn, bạn cần chọn thách thức phù hợp. Đây là lúc thư viện bộ dữ liệu của bạn trở nên vô giá:
Một thư viện được tổ chức tốt cho phép xác định nhanh chóng bài kiểm tra phù hợp với nhu cầu cụ thể của bạn:
Kiểm Tra Các Giao Thức Bảo Mật Mới: Chọn bộ dữ liệu "IT + Security + Integrations" của bạn để xác minh tác nhân thực hiện đúng các quy trình xử lý MFA mới.
Xác Thực Cải Tiến Mua Sắm: Sử dụng bộ dữ liệu "Supplier Ops + Procurement Controls" để đảm bảo xử lý đúng các ngoại lệ khớp hóa đơn.
Đo Lường Cập Nhật Cơ Sở Kiến Thức: Chạy một bộ dữ liệu toàn diện trước và sau khi thêm tài liệu mới để định lượng tác động đến chất lượng phản hồi.
Tóm tắt bộ dữ liệu, số lượng câu hỏi, lịch sử chạy và siêu dữ liệu giúp bạn chọn các trường hợp kiểm tra phù hợp và ổn định phù hợp với mục tiêu đánh giá của bạn.
Bước 3: Hiểu Quá Trình Thực Thi
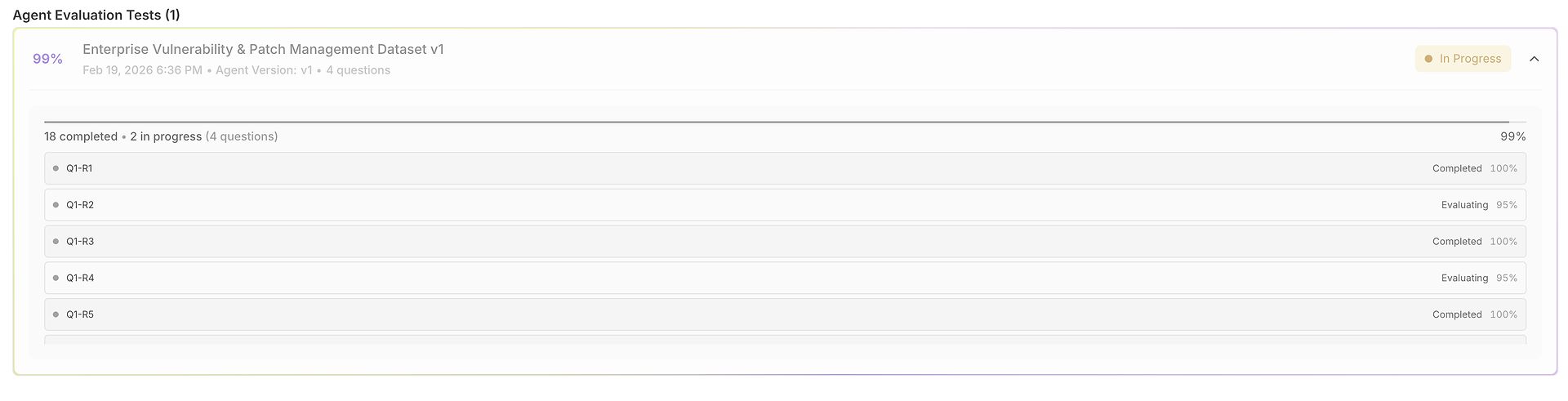
Với tác nhân và bộ dữ liệu của bạn đã được cấu hình, nhấp vào "Run Evaluation" sẽ bắt đầu một chuỗi kiểm tra tự động, toàn diện.
Quy Trình Kiểm Tra Tự Động
Xử Lý Câu Hỏi Hệ Thống: Nền tảng này cung cấp từng câu hỏi của người dùng từ bộ dữ liệu của bạn cho tác nhân đã chọn, đảm bảo điều kiện kiểm tra nhất quán trên tất cả các kịch bản.
Thực Hiện Nhiều Lần Thử: Đối với mỗi câu hỏi, hệ thống thực hiện nhiều lần thử dựa trên cấu hình "Số lần chạy thử nghiệm" của bộ dữ liệu của bạn. Sự lặp lại này rất quan trọng để đo lường tính nhất quán - một thành công đơn lẻ có thể là ngẫu nhiên, nhưng hiệu suất nhất quán trên nhiều lần chạy chứng tỏ độ tin cậy.
Thu Thập Dữ Liệu Toàn Diện: Hệ thống ghi lại toàn bộ dấu vết của mọi tương tác, bao gồm:
Chuỗi lý luận và quá trình suy nghĩ của tác nhân
Quyết định lựa chọn công cụ và lựa chọn tham số
Các cuộc gọi API và tương tác với hệ thống bên ngoài
Các phản hồi cuối cùng và giao tiếp với người dùng
Số liệu thời gian và hiệu suất
Như nghiên cứu của Anthropic chỉ ra, dữ liệu dấu vết này là cơ bản để hiểu không chỉ liệu một tác nhân có thành công hay không, mà còn cách và lý do tại sao nó đạt được kết luận của mình.
Bạn Nhận Được Gì Sau Khi Chạy - Báo Cáo Đánh Giá Của Bạn (Điểm Số, Tính Nhất Quán và Biến Đổi)
Khi đánh giá hoàn tất, bộ dữ liệu biến thành một báo cáo có cấu trúc giúp đo lường hiệu suất trên các khía cạnh chất lượng và hiệu suất.
1) Lưới Kết Quả: Một Bộ Dữ Liệu, Nhiều Lần Chạy, Hoàn Toàn Có Thể So Sánh
Đánh giá của bạn mở ra một lưới mà mỗi hàng là một trường hợp kiểm tra (câu hỏi) và mỗi lần chạy được chấm điểm cạnh nhau:
Chế độ xem này được thiết kế để quét nhanh:
Câu hỏi + Phản hồi Mong đợi neo lại ý nghĩa của "đúng" cho bài kiểm tra đó.
Đầu ra chạy cho phép bạn so sánh cách tác nhân trả lời qua các lần thử.
Điểm đúng (mỗi lần chạy) tiết lộ tính nhất quán so với biến động.
Các cột thời gian làm nổi bật tốc độ mỗi lần chạy (hữu ích cho các lỗi hồi quy độ trễ).
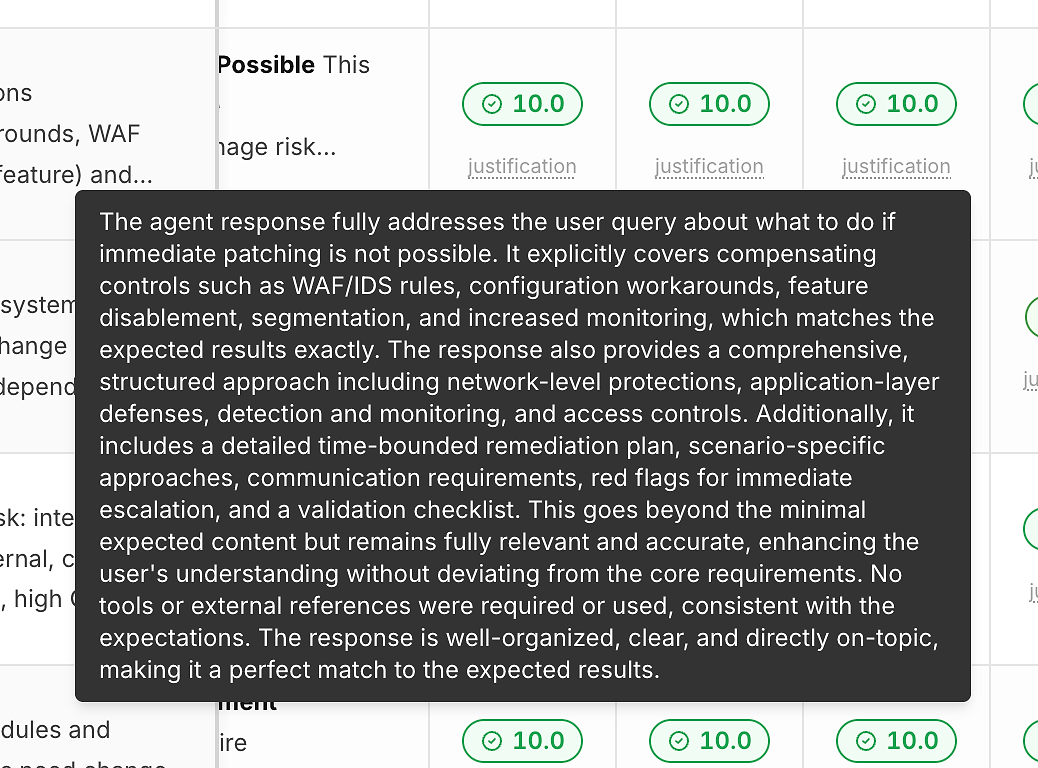
2) Lý Do Dưới Mỗi Điểm Số (Để Các Con Số Không Phải Là Một Hộp Đen)
Một điểm số không có giải thích không giúp bạn cải thiện. Đó là lý do tại sao mỗi lần chạy bao gồm một liên kết “lý do” dưới điểm đúng của nó:
Những lý do này thường chỉ ra:
Tiêu chí mong đợi nào đã được thỏa mãn
Liệu các biện pháp giảm thiểu/giải pháp tạm thời có được bao gồm (khi có liên quan)
Liệu câu trả lời có giữ nguyên phạm vi hay không so với việc đi chệch hướng
Liệu việc sử dụng công cụ có phù hợp (hoặc không cần thiết)
Đây là điều biến việc chấm điểm thành phản hồi có thể hành động thay vì một nhãn đậu đỗ.
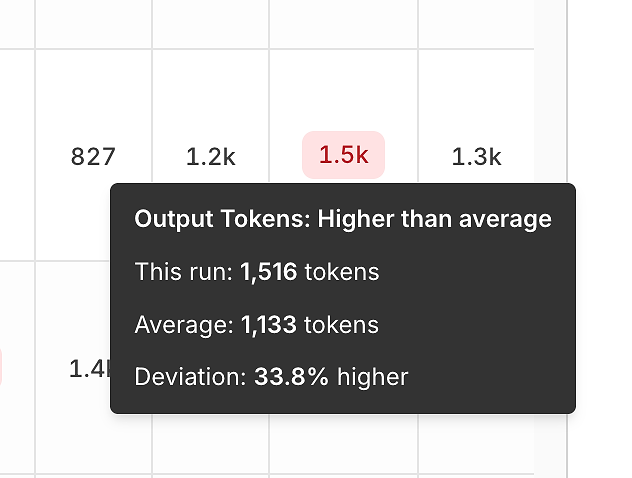
3) Biến Đổi Hiệu Suất: Token và Độ Trễ So Với Trung Bình
Vượt ra ngoài độ chính xác, báo cáo tiết lộ các tín hiệu hiệu quả bằng cách so sánh mỗi lần chạy với trung bình.
Biến đổi token đầu ra giúp bạn phát hiện:
các câu trả lời phồng lên,
các lỗi hồi quy lời nhắc,
hoặc "trôi dạt verbosity" theo thời gian.
Biến đổi độ trễ giúp bạn phát hiện:
các nút cổ chai công cụ,
các đường dẫn suy luận chậm,
hoặc rủi ro mô hình/thời gian chờ trong sản xuất.
Những chú giải công cụ này mạnh mẽ một cách lừa dối - chúng biến "cảm thấy chậm hơn" thành một tín hiệu có thể đo lường, có thể lặp lại.
4) Chi Tiết Phản Hồi: Kiểm Tra Toàn Bộ Câu Trả Lời
Các ô lưới được thiết kế nhỏ gọn. Khi bạn cần toàn bộ đầu ra, bạn có thể mở Chi Tiết Phản Hồi:
Điều này lý tưởng cho:
xác minh các yêu cầu định dạng/giọng điệu,
xác nhận câu trả lời bao gồm các bước/chỉ mục chính,
và quyết định liệu một "điểm cao" vẫn cần cải thiện phong cách hoặc chính sách.
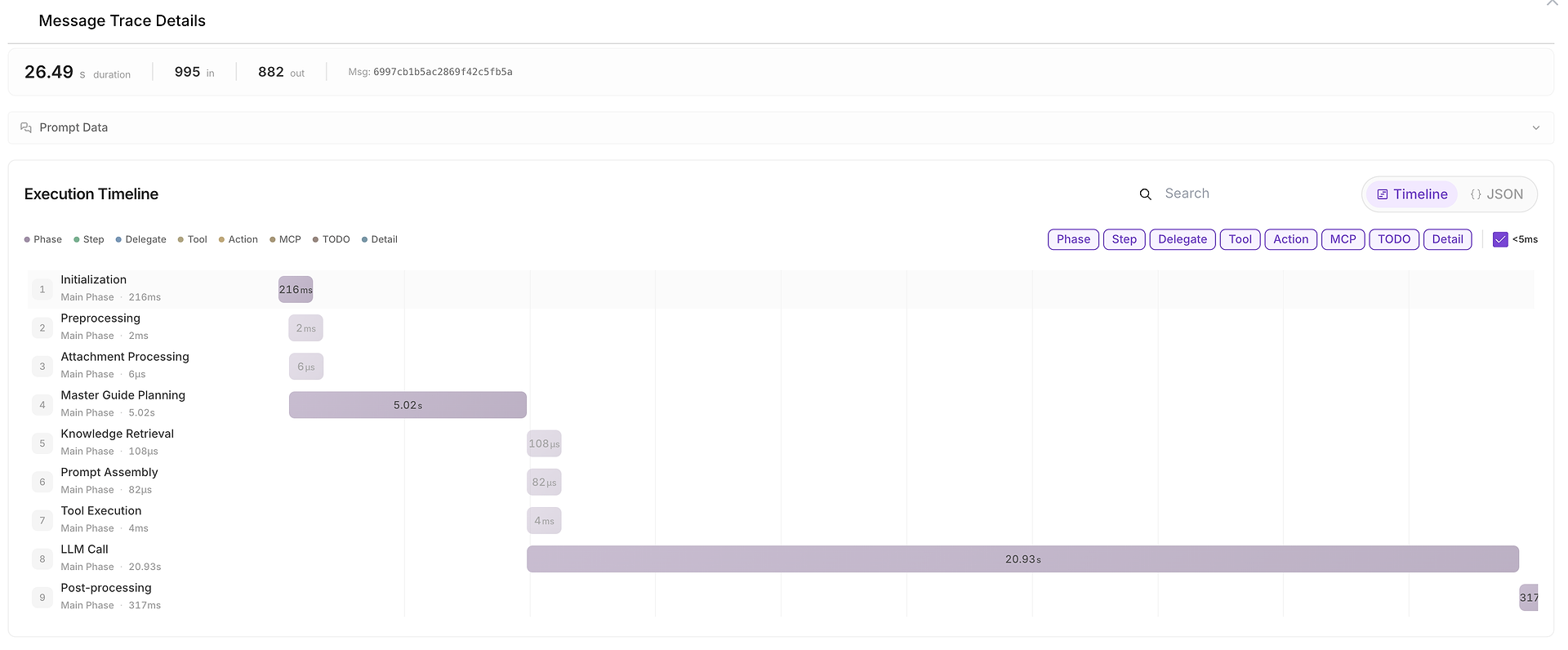
5) Chi Tiết Dấu Vết Tin Nhắn: Dòng Thời Gian Thực Thi Đầy Đủ (Nơi Thời Gian Đã Được Sử Dụng)
Khi điều gì đó chậm, không nhất quán hoặc đáng ngờ, bạn có thể mở Chi Tiết Dấu Vết Tin Nhắn để xem toàn bộ dòng thời gian:
Chế độ xem này chia lần chạy thành các giai đoạn như:
khởi tạo,
lập kế hoạch,
truy xuất kiến thức,
thực thi công cụ,
cuộc gọi LLM,
hậu xử lý.
Nó cũng hiển thị số lượng token đầu vào/đầu ra và giúp dễ dàng xác định các nút cổ chai (ví dụ, khi cuộc gọi LLM chiếm ưu thế về thời gian từ đầu đến cuối).
Tại Sao Cách Tiếp Cận Có Cấu Trúc Này Biến Đổi Chất Lượng AI Doanh Nghiệp
Chuyển từ kiểm tra thủ công ngẫu nhiên sang đánh giá có hệ thống mang lại lợi ích có thể đo lường được, điều cần thiết cho việc triển khai AI cấp doanh nghiệp:
Tính Lặp Lại và Nhất Quán
Thực hiện các bộ đánh giá giống hệt nhau sau mỗi thay đổi, duy trì tiêu chuẩn chất lượng cao, nhất quán và cho phép kiểm tra hồi quy AI theo thời gian thực.
Ra Quyết Định Dựa Trên Dữ Liệu
Đánh giá có cấu trúc cung cấp bằng chứng khách quan, định lượng về hiệu suất tác nhân, thay thế các đánh giá chủ quan bằng dữ liệu rõ ràng để ra quyết định tự tin.
Đường Dẫn Kiểm Toán Hoàn Chỉnh
Nhật ký chi tiết đảm bảo khả năng kiểm tra toàn diện - rất quan trọng cho tuân thủ, bảo mật và phân tích nguyên nhân gốc rễ.
Đảm Bảo Chất Lượng Có Thể Mở Rộng
Các khung đánh giá tự động cho phép chất lượng nhất quán ngay cả khi triển khai tác nhân mở rộng trên các đội ngũ, quy trình làm việc và dòng kinh doanh.
Chuẩn Bị Cho Phân Tích Kết Quả
Chạy đánh giá biến bộ dữ liệu của bạn thành dữ liệu hiệu suất có thể hành động. Giá trị thực sự đến trong giai đoạn tiếp theo: phân tích kết quả, xác định cơ hội cải thiện và đưa ra quyết định dựa trên dữ liệu về triển khai tác nhân.
Các dấu vết toàn diện và số liệu hiệu suất trở thành nền tảng của bạn để hiểu hành vi của tác nhân, chẩn đoán các chế độ thất bại và tối ưu hóa độ tin cậy của hệ thống.
Tiếp Theo: Biến Dữ Liệu Thành Thông Tin Chi Tiết Doanh Nghiệp
Bây giờ bạn đã tạo ra kết quả, bước tiếp theo là biến chúng thành các quyết định bạn có thể tin tưởng - những gì cần triển khai, những gì cần quay lại, và những gì cần cải thiện.
Trong Phần 3 của loạt bài của chúng tôi, chúng tôi sẽ khám phá các báo cáo đánh giá chi tiết: cách diễn giải tỷ lệ thành công và số liệu hiệu suất, phân tích lý luận tác nhân, xác định nguyên nhân gốc rễ của các thất bại, và biến những thông tin chi tiết này thành những cải tiến cụ thể cho các tác nhân AI đáng tin cậy, sẵn sàng cho doanh nghiệp.
Đừng để bộ dữ liệu đánh giá của bạn ngồi không. Chọn tác nhân của bạn, chọn bộ dữ liệu của bạn, và chạy một đánh giá thực tế. Lặp lại với mỗi lần chạy - theo dõi những gì hiệu quả, xác định nơi tác nhân trượt, và biến mỗi thất bại thành trường hợp kiểm tra tiếp theo của bạn.
Sẵn sàng chuyển từ lý thuyết sang xuất sắc AI doanh nghiệp? Chạy đánh giá tác nhân đầu tiên của bạn hôm nay, và đón chờ hướng dẫn tiếp theo của chúng tôi: “Cách Phân Tích, Diễn Giải và Hành Động Dựa Trên Kết Quả Đánh Giá Tác Nhân AI - Biến Số Liệu Thành Giá Trị Kinh Doanh”