
代理评估与AI分析工具
Sebastian Mul
8 min read
EvaluationAI AgentAgentXTesting
AgentX评估让您可以在多次运行中测试您的AI代理,发现不一致之处,分析推理和工具使用,并通过可操作的AI生成的见解来提高性能。
AgentX评估让您可以在多次运行中测试您的AI代理,发现不一致之处,分析推理和工具使用,并通过可操作的AI生成的见解来提高性能。
AI代理变得越来越先进、越来越有能力,并且更深入地融入到企业中。
但每个团队都面临一个普遍的问题:
您的代理并不总是按照您的预期回答——而您不知道为什么。
有时推理会改变,有时代理会忽略规则,有时工具使用不当,有时细微的指令被误解。没有对决策如何做出的可见性,改进代理感觉像是在猜测。
这正是我们构建代理评估的原因——AgentX中的一个新系统,让您可以测试、测量和深入分析您的代理在多次相同问题运行中的表现。
这是您第一次可以看到代理的决策过程,找到不一致之处,并准确了解需要改进的地方。
AI模型是概率性的。
即使在相同的提示、上下文和规则下,模型可能会:
产生略微不同的推理路径
遗漏必要的细节
误解政策
跳过工具查找
给出不确定的答案而不是预期的明确答案
在团队内部不一致地委派
从外部,您只看到最终答案。
您看不到:
代理是否遵循了您的指令
是否使用了正确的工具
是否正确推理
为什么一个版本的答案比另一个版本弱
为什么有时正确——有时错误
评估通过提供结构、评分和透明度来解决这个问题。
创建评估很简单:

这是您想要验证的现实世界问题。
它模拟了客户查询或内部工作流程请求。
示例:
“如果不合适,我可以退回最终销售商品吗?”
这构成了评估的核心。
这是配置中最重要的部分。
在这里,您定义代理必须说什么或包含什么,以便响应被视为正确。
它可以包含:
关键事实
必需短语
必要的推理步骤
合规规则
特定的语气或政策声明
示例:
“必须说:不,最终销售商品不可退换。”
预期结果成为所有测试运行的评分标准。

您可以告诉评估系统代理应该使用哪些工具、文档或知识来源。
在您的示例中,您选择了:
Documents → store_policy_kb_v1.xlsx
内置功能
这意味着:
代理应该从政策知识库中检索信息。
如果没有正确使用知识库,评估将捕捉到这一点。
这非常适合:
政策代理
客户服务代理
合规工作流程
财务建模
数据支持的推理
本节定义了您的评估应该有多严格和多深入。
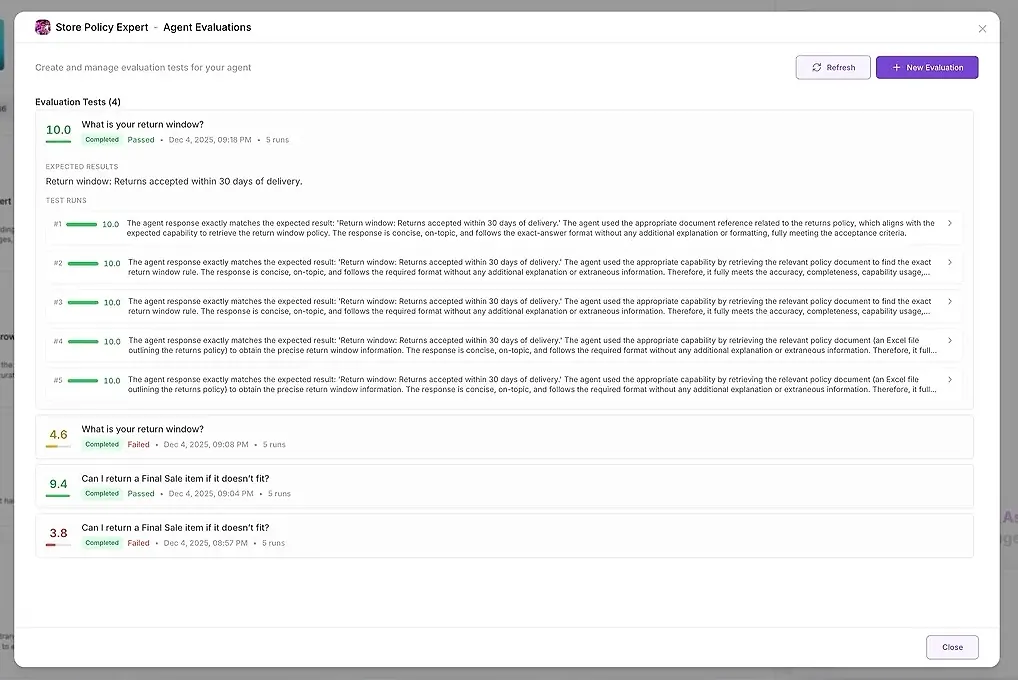
同一个问题被多次执行(推荐:5次运行)。
为什么?
因为AI模型不是确定性的。多次运行允许您检查:
一致性
稳定性
推理可靠性
代理是否每次都遵循相同的过程
如果代理产生一个好的答案和四个失败,您会立即看到。
此滑块定义答案必须与您的预期结果匹配的严格程度。
您在以下之间选择一个点:
宽松 → 代理可以偏离您的期望;答案不需要完美。
精确 → 答案必须非常接近您的期望,几乎没有变化的余地。
它只是控制响应需要多精确才能通过评估。

自动失败的规则。
示例:
“响应不应提及竞争对手。”
“当政策禁止时,不要提供退款。”
“响应不应要求用户提供个人信息。”
这些是硬性约束。
额外的评分指导,通常用于质量或语气。
示例:
“响应应友好且专业。”
“答案必须包含简短的解释,而不仅仅是是/否。”
“在假设之前使用知识库的事实。”
这些不是严格要求,但有助于塑造AI对代理的评分。
配置完成后,点击创建评估开始流程:
问题被多次运行
每个答案都被评分
生成详细分析
检查委派和工具使用
揭示不一致之处
您将获得完整的性能报告。
经过多次运行后,AgentX提供两层输出:
对于每次运行,您会看到:
一个数字评分
总结其与您的期望匹配的程度
完整的响应
使用了哪些工具
参与了哪些代理
代理失败或偏离的地方
这使您可以并排比较答案并识别模式。

这是真正的魔力所在。
AgentX自动分析所有运行并在多个类别中生成结构化报告:
代理是否遵循了您的规则?
答案有多相似或不同?
是否有异常值?

推理步骤是否正确、完整并符合预期?
代理是否使用了正确的工具?
是否跳过了查找?
是否依赖于假设而不是经过验证的事实?
具体的、可操作的建议来改进您的代理。
自动生成的改进建议,用于您的系统提示或代理配置。
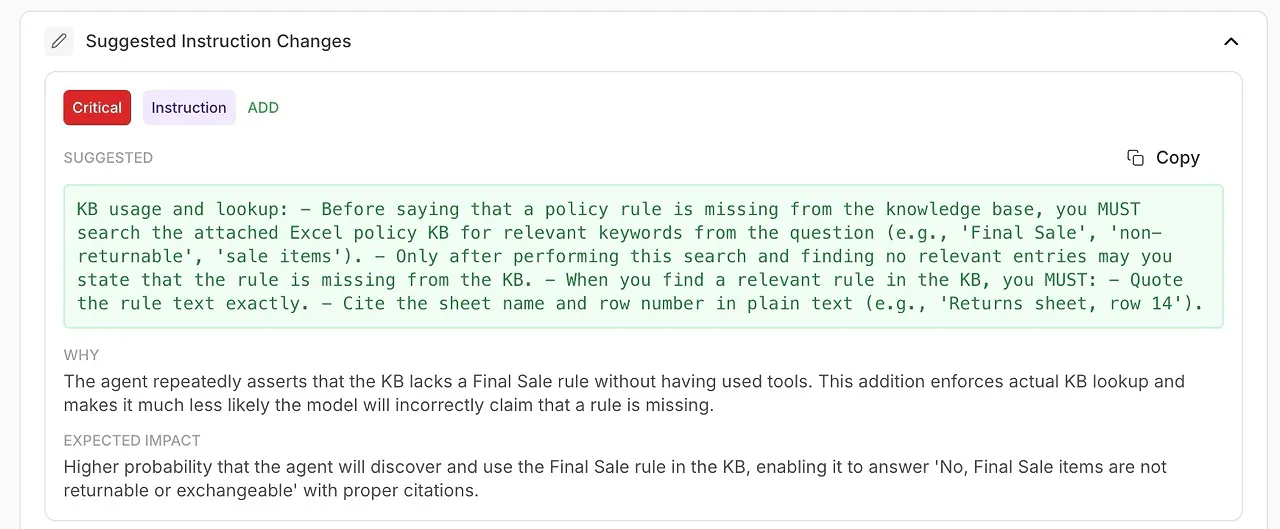
优点、缺点和信心水平的总结。
这将调试从猜测游戏转变为科学的、可重复的过程。

评估为您的代理操作引入了新的透明度和可靠性水平。您不再需要猜测为什么答案错误或不一致,现在您有了一种结构化、可测量的方法来理解行为、诊断问题并持续提高性能。
以下是可以实现的目标:
在将代理投入生产之前,您可以运行现实的测试,以揭示它是否完全理解您的规则、知识库和期望的语气。部署后不再有惊喜——您确切知道用户将体验到什么。
对于多代理设置,评估显示您的经理如何委派任务,哪些子代理参与,以及它们是否遵循预期的工作流程。您可以快速检测到:
不必要的委派
缺失的委派
冲突的代理
不正确的角色行为
这对于确保您的AI团队内部的可靠合作至关重要。
如果评估显示在特定主题上的反复失败,您就知道问题不在于代理,而是缺少或不清晰的内容。评估帮助您以有针对性、数据驱动的方式完善您的知识库,而不是盲目地添加更多材料。
因为每个问题都经过多次测试,评估会揭示出微妙的问题,如:
答案不可预测地变化
推理漂移
用事实猜测替代工具使用
跨运行的矛盾
这些是您通过手动测试一次或两次永远无法识别的问题。
分析不仅显示出了问题所在——它还告诉您如何修复它。
您会收到基于模型自身诊断的可操作建议:
改进的措辞
更严格的规则
强制工具使用
更明确的委派政策
更精确的语气和结构
这是直接嵌入到您的工作流程中的自动化提示工程。
每当您更改:
系统提示
知识库条目
工具
委派规则
推理政策
……您可以重新运行相同的评估并比较分数。您可以准确看到您的更新如何影响性能——是正面还是负面。
评估成为您的持续改进循环。
无论您是在处理支持、财务分析、医疗场景还是法律敏感内容,评估让您确保:
遵循政策
尊重语气指南
标记危险的漏洞
揭示不正确的推理
符合合规标准
这对于企业和面向客户的AI尤为重要。
代理评估使用与AgentX的其他部分完全相同的信用模型。每次测试运行只是像正常的代理消息一样消耗信用——没有额外费用,没有隐藏定价。您始终确切知道您的支出,因为评估遵循您现有的计划限制和信用余额。
在传统软件中,QA确保可靠性。
在AgentX中,评估是您代理的QA。
您定义“好”的标准。
AgentX检查您的代理是否能够始终如一地交付,并在不能时准确显示需要改进的地方。
评估将AI从一个黑盒子转变为一个透明的、可测量的、可改进的系统。
Discover how AgentX can automate, streamline, and elevate your business operations with multi-agent workforces.
AgentX | One-stop AI Agent build platform.
Book a demo© 2026 AgentX Inc

