
Agent 评估与 AI 分析工具
Sebastian Mul
8 min read
EvaluationAI AgentAgentXTesting
AgentX Evaluations 让你可以在多次运行中测试你的 AI agents,发现不一致之处,分析推理与工具使用情况,并通过可执行的、由 AI 生成的洞察来提升性能。
AgentX Evaluations 让你可以在多次运行中测试你的 AI agents,发现不一致之处,分析推理与工具使用情况,并通过可执行的、由 AI 生成的洞察来提升性能。
AI agents 正变得更先进、更强大,并更深度地融入企业业务。
但每个团队都会遇到一个普遍问题:
你的 agent 并不总是按你预期的方式回答——而你不知道为什么。
有时推理会变化,有时 agent 会忽略一条规则,有时工具没有被正确使用,还有时某个细微的指令被误解了。在无法看清决策是如何做出的情况下,改进 agent 就像在猜。
这正是我们构建 Agent Evaluations 的原因——AgentX 内的一套新系统,让你能够在同一个问题的多次运行中测试、衡量并深度分析你的 agent 的行为表现。
这是你第一次可以看见 agent 的决策过程,找出不一致,并精确理解需要改进的地方。
AI models 是概率性的。
即使使用相同的 prompt、上下文和规则,model 也可能:
产生略有不同的推理路径
遗漏某个必需细节
误解某条 policy
跳过一次工具查询
给出不确定的答案,而不是预期的明确答案
在 team 内部的 delegation 表现不一致
从外部看,你只能看到最终答案。
你看不到:
agent 是否遵循了你的指令
它是否使用了正确的工具
它是否推理正确
为什么某个版本的答案比另一个更弱
为什么它有时做对——有时做错
评估通过提供结构化流程、评分与透明度来解决这个问题。
创建一个 evaluation 很简单:

这是你想要验证的真实世界问题。
它模拟客户提问或内部工作流请求。
示例:
“如果 Final Sale 商品不合身,我可以退货吗?”
这构成了 evaluation 的核心。
这是配置中最重要的部分。
在这里你定义 agent 必须说什么或必须包含什么,响应才会被视为正确。
它可以包含:
关键事实
必需短语
必需的推理步骤
合规规则
特定语气或 policy 声明
示例:
“必须说明:不可以,Final Sale 商品不可退货或换货。”
预期结果会成为所有测试运行的评分标准(scoring rubric)。

你可以告诉 evaluation 系统,agent 应该使用哪些工具、文档或知识来源。
在你的示例中,你选择了:
Documents → store_policy_kb_v1.xlsx
Built-in Functions
这意味着:
agent 应该从 policy KB 中检索信息。
如果它没有正确使用 KB,evaluation 会捕捉到这一点。
这非常适用于:
policy agents
customer service agents
compliance workflows
finance modeling
data-backed reasoning
这一部分定义你的 evaluation 应该有多严格、多深入。
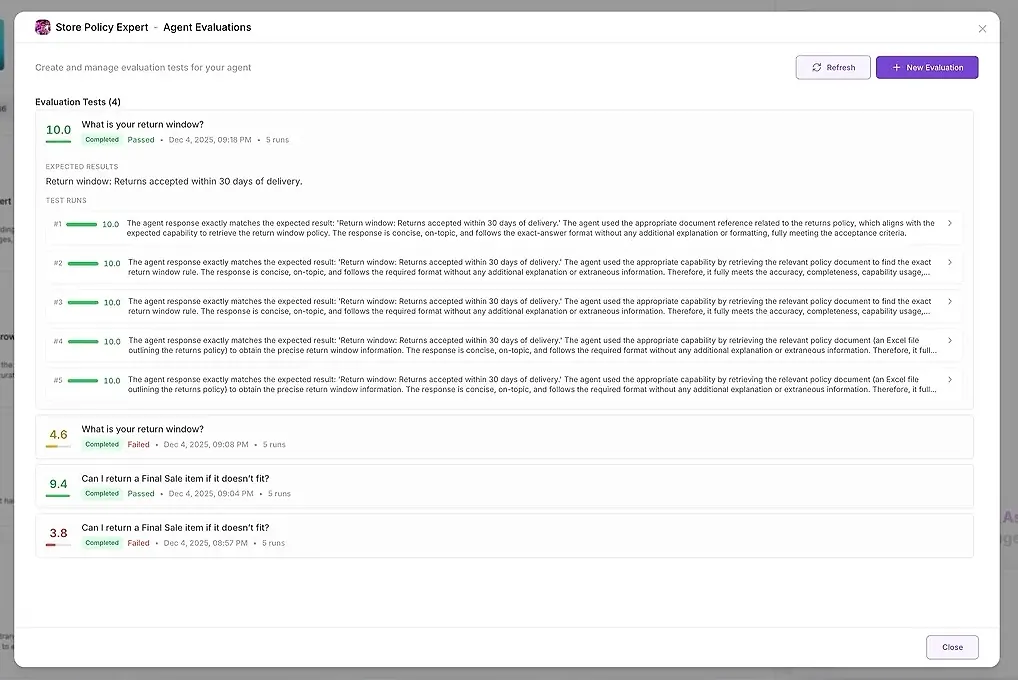
同一个问题会被执行多次(推荐:5 次)。
为什么?
因为 AI models 不是确定性的。多次运行可以让你检查:
一致性
稳定性
推理可靠性
agent 是否每次都遵循相同流程
如果 agent 产出 1 次好答案和 4 次失败,你会立刻看到。
这个滑块定义答案必须多严格地匹配你的预期结果。
你在以下两者之间选择一个点:
宽松(Lenient) → agent 可以偏离你的预期;答案不需要完美。
精确(Exact) → 答案必须非常贴近你的预期,几乎没有变化空间。
它只是控制响应需要多精确才能通过 evaluation。

用于自动判定失败的规则。
示例:
“回复不应提及竞争对手。”
“当 policy 禁止时,不要提供退款。”
“回复不应要求用户提供个人信息。”
这些是硬性约束。
额外的评分指导,通常用于质量或语气。
示例:
“回复应友好且专业。”
“答案必须包含简短解释,而不只是是/否。”
“在假设之前先使用 KB 事实。”
这些不是严格要求,但会帮助 AI 形成对 agent 的评分方式。
配置完成后,点击 Create Evaluation 即开始流程:
问题会被运行多次
每个答案都会被评分
生成详细分析
检查 delegation 与工具使用
暴露不一致之处
然后你会得到一份完整的性能报告。
多次运行后,AgentX 会提供两层输出:
对于每次运行,你会看到:
数值分数
与预期匹配程度的摘要
完整回复
使用了哪些工具
哪些 agents 参与了
agent 在哪里失败或偏离
这让你可以并排对比答案并识别模式。

真正的魔法就在这里发生。
AgentX 会自动分析所有运行,并在多个类别下生成结构化报告:
agent 是否遵循了你的规则?
答案有多相似或多不同?
是否存在离群值?

推理步骤是否正确、完整,并与预期一致?
agent 是否使用了正确的工具?
是否跳过了查询?
是否依赖假设而不是已验证的事实?
用于改进 agent 的具体、可执行建议。
自动生成对 system prompt 或 agent 配置的改进建议。
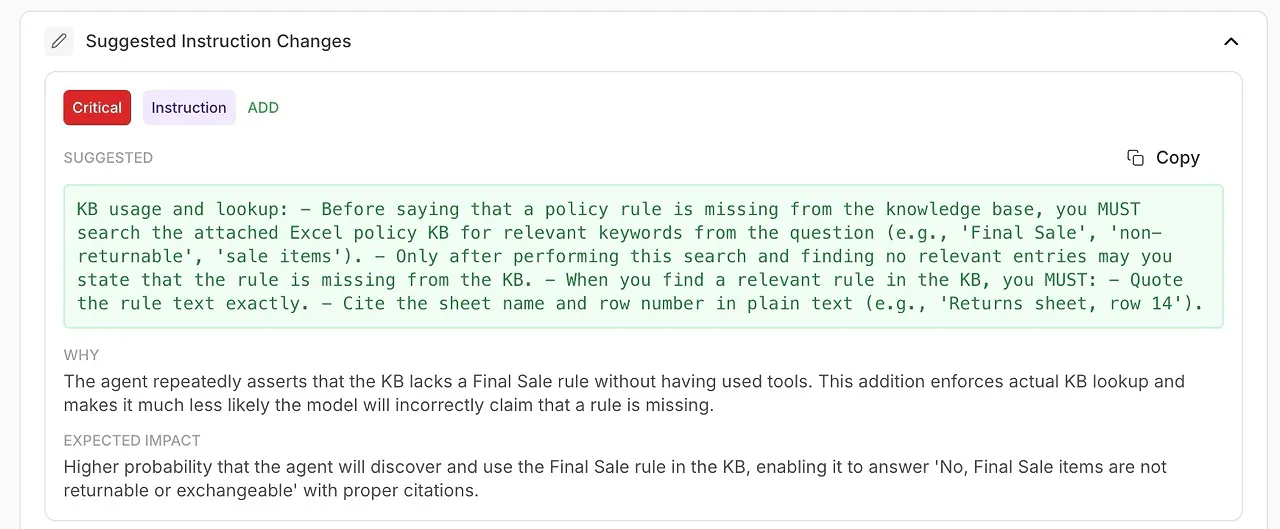
对优势、弱点与置信水平的总结。
这会把调试从猜谜游戏,变成科学、可重复的流程。

Evaluations 为你的 agents 的运行方式引入了新的透明度与可靠性层级。你不再需要猜测为什么答案错误或不一致——现在你有一种结构化、可衡量的方法来理解行为、诊断问题,并持续提升性能。
以下将成为可能:
在将 agent 投入生产之前,你可以运行真实的测试,揭示它是否完全理解你的规则、knowledge base 以及期望的语气。部署后不再有意外——你会清楚用户将体验到什么。
对于 multi-agent 设置,Evaluations 会展示你的 manager 如何分配任务、哪些 sub-agents 参与,以及它们是否遵循预期的 workflow。你可以快速发现:
不必要的 delegation
缺失的 delegation
相互冲突的 agents
不正确的角色行为
这对你的 AI workforce 内部实现可靠协作至关重要。
如果 evaluation 显示在某个主题上反复失败,你就知道问题不在 agent——而在于内容缺失或表述不清。Evaluations 帮助你以有针对性、数据驱动的方式优化 KB,而不是盲目添加更多材料。
因为每个问题会被测试多次,Evaluations 会暴露一些细微问题,例如:
答案不可预测地变化
推理逐渐漂移
用事实猜测替代工具使用
不同运行之间出现矛盾
这些问题仅靠手动测试一两次永远无法识别。
分析不仅告诉你哪里出了问题——还会告诉你如何修复。
你会收到基于 model 自身诊断的可执行建议:
更好的措辞
更严格的规则
强制工具使用
更清晰的 delegation policies
更精确的语气与结构
这就是直接内置在工作流中的自动化 prompt engineering。
每当你修改:
system prompt
knowledge base 条目
工具
delegation 规则
推理 policy
……你都可以重新运行同一个 evaluation 并对比分数。你会清楚看到更新对性能的影响——是提升还是下降。
Evaluations 会成为你的持续改进闭环。
无论你在处理支持、财务分析、医疗场景,还是法律敏感内容,Evaluations 都能确保:
遵循 policies
遵守语气指南
标记危险缺口
暴露错误推理
满足合规标准
这对企业级与面向客户的 AI 尤其关键。
Agent Evaluations 使用与 AgentX 的其他部分完全相同的 credit 计费模型。每次测试运行只会像普通的 agent 消息一样消耗 credits——没有额外费用,没有隐藏定价。你始终清楚自己花了多少,因为 Evaluations 遵循你现有的 plan 限制与 credit 余额。
在传统软件中,QA 确保可靠性。
在 AgentX 中,Evaluations 就是你的 agents QA。
你来定义什么是“好”。
AgentX 会检查你的 agents 是否能持续交付——并在它们做不到时,准确告诉你该改进什么。
Evaluations 将 AI 从黑盒变成透明、可衡量、可改进的系统。
Discover how AgentX can automate, streamline, and elevate your business operations with multi-agent workforces.
AgentX | One-stop AI Agent build platform.
Book a demo© 2026 AgentX Inc

