Hodnocení AI agentů: Představujeme hodnocení agentů: Nejspolehlivější způsob, jak porozumět a zlepšit vaše AI agenty
AI agenti se stávají pokročilejšími, schopnějšími a hlouběji integrovanými do podnikání.
Existuje však jeden univerzální problém, kterému čelí každý tým:
Váš agent ne vždy odpovídá tak, jak očekáváte - a nevíte proč.
Někdy se mění uvažování, někdy agent ignoruje pravidlo, někdy nebyl nástroj použit správně a někdy byla jemná instrukce špatně pochopena. Bez viditelnosti do toho, jak byla rozhodnutí učiněna, se zlepšování agenta zdá jako hádání.
Přesně proto jsme vytvořili Hodnocení agentů - nový systém uvnitř AgentX, který vám umožňuje testovat, měřit a hluboce analyzovat, jak se váš agent chová napříč více běhy stejné otázky.
Je to poprvé, kdy můžete vidět do rozhodovacího procesu vašeho agenta, najít nekonzistence a přesně pochopit, kde jsou potřeba zlepšení.
Proč na hodnoceních záleží
AI modely jsou pravděpodobnostní.
I se stejným podnětem, kontextem a pravidly může model:
vytvořit mírně odlišné cesty uvažování
vynechat požadovaný detail
špatně interpretovat politiku
přeskočit vyhledání nástroje
poskytnout nejisté odpovědi místo očekávané definitivní
nekonzistentně delegovat uvnitř týmu
Zvenčí vidíte pouze konečnou odpověď.
Nevidíte:
zda agent dodržel vaše instrukce
zda použil správné nástroje
zda uvažoval správně
proč byla jedna verze odpovědi slabší než jiná
proč někdy dostane věci správně — a někdy špatně
Hodnocení to řeší tím, že vám poskytuje strukturu, hodnocení a transparentnost.
Jak funguje test
Vytvoření hodnocení je jednoduché:
0. Vyberte agenta nebo tým, který chcete hodnotit.
1. Testovací otázka
Toto je reálná otázka, kterou chcete ověřit.
Simuluje dotaz zákazníka nebo interní požadavek na pracovní postup.
Příklad:
„Mohu vrátit položku z konečného prodeje, pokud mi nesedí?“
Toto tvoří jádro hodnocení.
2. Očekávané výsledky (Povinné)
Toto je nejdůležitější část konfigurace.
Zde definujete, co musí agent říci nebo zahrnout, aby byla odpověď považována za správnou.
Může obsahovat:
klíčová fakta
povinné fráze
požadované kroky uvažování
pravidla shody
specifický tón nebo prohlášení o politice
Příklad:
„Musí říci: Ne, položky z konečného prodeje nelze vrátit ani vyměnit.“
Očekávané výsledky se stávají hodnotícím rubrikou pro všechny testovací běhy.
3. Očekávané schopnosti (Volitelné, ale silné)
Můžete říci hodnotícímu systému, které nástroje, dokumenty nebo zdroje znalostí by měl agent použít.
Ve vašem příkladu jste vybrali:
Documents → store_policy_kb_v1.xlsx
Vestavěné funkce
To znamená:
Agent by měl získat informace z KB politiky.
Pokud KB nepoužije správně, hodnocení to zachytí.
To je ideální pro:
politické agenty
agenty zákaznického servisu
pracovní postupy shody
finanční modelování
uvažování podložené daty
4. Nastavení hodnocení
Tato sekce definuje jak přísné a jak hluboké by mělo být vaše hodnocení.
Počet testovacích běhů
Stejná otázka je provedena několikrát (Doporučeno: 5 běhů).
Proč?
Protože AI modely nejsou deterministické. Více běhů vám umožňuje zkontrolovat:
konzistenci
stabilitu
spolehlivost uvažování
zda agent dodržuje stejný proces pokaždé
Pokud agent vytvoří jednu dobrou odpověď a čtyři selhání, okamžitě to uvidíte.
Kritéria přijetí
Tento posuvník definuje jak přísně musí odpověď odpovídat vašim očekávaným výsledkům.
Volíte bod mezi:
Shovívavý → agent se může odchýlit od vašich očekávání; odpověď nemusí být dokonalá.
Přesný → odpověď musí velmi těsně odpovídat vašim očekáváním, s téměř žádným prostorem pro variaci.
Jednoduše kontroluje jak přesná musí být odpověď, aby prošla hodnocením.
Kritéria odmítnutí (Volitelné)
Pravidla pro automatické selhání.
Příklady:
„Odpověď by neměla zmiňovat konkurenty.“
„Nenabízejte vrácení peněz, když to politika zakazuje.“
„Odpověď by neměla žádat uživatele o poskytnutí osobních údajů.“
Toto jsou tvrdá omezení.
Kritéria hodnocení (Volitelné)
Další pokyny pro hodnocení, často používané pro kvalitu nebo tón.
Příklady:
„Odpověď by měla být přátelská a profesionální.“
„Odpověď musí obsahovat krátké vysvětlení, ne jen ano/ne.“
„Použijte fakta z KB před domněnkami.“
Nejsou to přísné požadavky, ale pomáhají formovat, jak AI hodnotí agenta.
5. Vytvořit hodnocení
Jakmile je vše nakonfigurováno, kliknutím na Vytvořit hodnocení zahájíte proces:
otázka je provedena několikrát
každá odpověď je hodnocena
je generována podrobná analýza
delegace a použití nástrojů jsou zkontrolovány
nekonzistence jsou odhaleny
A dostanete zpět kompletní zprávu o výkonu.
Co získáte po spuštění hodnocení
Po několika bězích poskytuje AgentX dvě vrstvy výstupu:
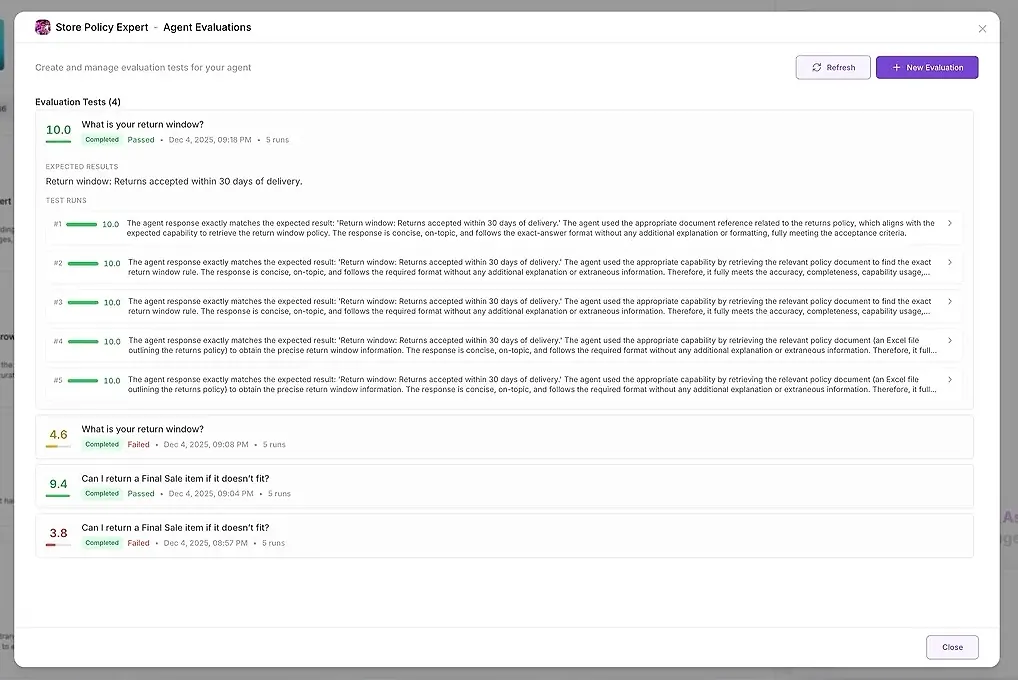
1. Výsledky testu
Pro každý běh vidíte:
číselné skóre
souhrn toho, jak dobře odpovídal vašim očekáváním
celou odpověď
které nástroje byly použity
kteří agenti se účastnili
kde agent selhal nebo se odchýlil
To vám umožňuje porovnávat odpovědi vedle sebe a identifikovat vzory.
2. Hluboká AI analýza
Zde se děje skutečná magie.
AgentX automaticky analyzuje všechny běhy a generuje strukturovanou zprávu napříč několika kategoriemi:
• Dodržování instrukcí
Dodržel agent vaše pravidla?
• Vzory odpovědí
Jak podobné nebo odlišné byly odpovědi?
Existují odlehlé hodnoty?
• Analýza uvažování
Byly kroky uvažování správné, kompletní a v souladu s očekáváními?
• Použití nástrojů
Použil agent správný nástroj?
Přeskočil vyhledání?
Spoléhal se na domněnky místo ověřených faktů?
• Doporučení
Konkrétní, akční návrhy na zlepšení vašeho agenta.
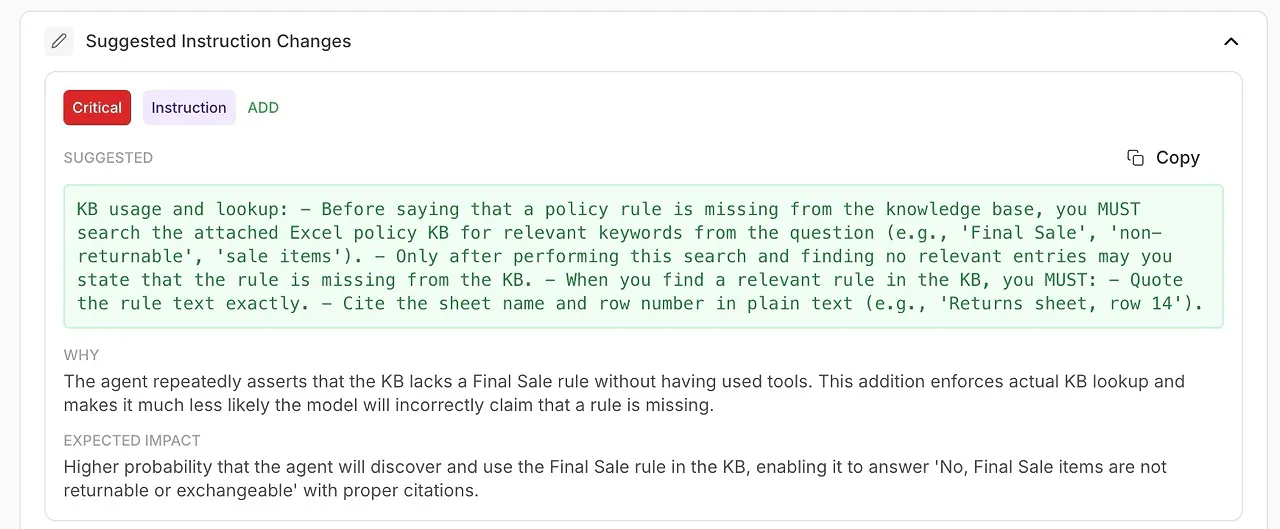
• Navrhované změny instrukcí
Automaticky generovaná vylepšení vašeho systémového podnětu nebo konfigurace agenta.
• Celkové hodnocení
Souhrn silných stránek, slabin a úrovně důvěry.
To přeměňuje ladění z hádání na vědecký, opakovatelný proces.
Co tato funkce umožňuje
Hodnocení zavádí novou úroveň transparentnosti a spolehlivosti do toho, jak vaši agenti fungují. Místo hádání, proč byla odpověď špatná nebo nekonzistentní, nyní máte strukturovaný, měřitelný způsob, jak porozumět chování, diagnostikovat problémy a neustále zlepšovat výkon.
Zde je, co se stává možným:
🔍 Ověřte svého agenta před jeho spuštěním pro zákazníky
Než nasadíte agenta do produkce, můžete provést realistické testy, které odhalí, zda plně rozumí vašim pravidlům, znalostní bázi a požadovanému tónu. Žádná překvapení po nasazení — přesně víte, co uživatelé zažijí.
🤖 Testujte celý tým agentů a logiku delegace
Pro víceagentní nastavení ukazují hodnocení, jak váš manažer deleguje úkoly, kteří sub-agenti se účastní a zda dodržují očekávaný pracovní postup. Můžete rychle zjistit:
zbytečné delegace
chybějící delegace
konfliktní agenty
nesprávné chování role
To je nezbytné pro spolehlivou týmovou práci uvnitř vaší AI pracovní síly.
📚 Detekujte slabá místa ve vaší znalostní bázi
Pokud hodnocení ukazuje opakovaná selhání v konkrétním tématu, víte, že problém není agent — je to chybějící nebo nejasný obsah. Hodnocení vám pomohou zlepšit vaši KB cíleným, datově řízeným způsobem, místo slepého přidávání dalšího materiálu.
🚨 Zachyťte halucinace a nekonzistenci včas
Protože každá otázka je testována několikrát, hodnocení odhalují jemné problémy jako:
odpovědi se mění nepředvídatelně
uvažování se odchyluje
faktické hádání nahrazuje použití nástrojů
rozpory napříč běhy
Toto jsou problémy, které byste nikdy neidentifikovali testováním ručně jednou nebo dvakrát.
🧠 Zjemněte systémové instrukce pomocí AI generovaných vylepšení
Analýza neukazuje jen to, co se pokazilo — říká vám jak to opravit.
Dostanete akční doporučení podložená vlastní diagnostikou modelu:
vylepšené formulace
přísnější pravidla
povinné použití nástrojů
jasnější politiky delegace
přesnější tón a struktura
Toto je automatizované inženýrství podnětů přímo integrované do vašeho pracovního postupu.
📈 Měřte pokrok pokaždé, když aktualizujete svého agenta
Kdykoli změníte:
systémový podnět
záznam ve znalostní bázi
nástroj
pravidlo delegace
politiku uvažování
…můžete znovu spustit stejné hodnocení a porovnat skóre. Vidíte přesně, jak vaše aktualizace ovlivnila výkon — pozitivně nebo negativně.
Hodnocení se stávají vaším cyklem neustálého zlepšování.
✔ Prosazujte vysoce kvalitní, shodné odpovědi napříč vaší organizací
Ať už se zabýváte podporou, finanční analýzou, zdravotnickými scénáři nebo obsahem citlivým na právní záležitosti, hodnocení vám umožňují zajistit:
pravidla jsou dodržována
pokyny pro tón jsou respektovány
nebezpečné mezery jsou označeny
nesprávné uvažování je odhaleno
jsou splněny standardy shody
To je obzvláště důležité pro podnikové a zákaznicky orientované AI.
Použití a náklady
Hodnocení agentů používají stejný kreditní model jako zbytek AgentX. Každý testovací běh jednoduše spotřebovává kredity stejným způsobem jako běžná zpráva agenta - žádné další poplatky, žádné skryté ceny. Vždy víte přesně, co utrácíte, protože hodnocení sledují vaše stávající limity plánu a zůstatek kreditů.
Vaše vrstva kontroly kvality pro AI
V tradičním softwaru zajišťuje QA spolehlivost.
V AgentX, hodnocení jsou vaše QA pro agenty.
Definujete, jak vypadá „dobré“.
AgentX kontroluje, zda vaši agenti mohou to dodávat konzistentně — a ukazuje vám přesně, co zlepšit, když to nedělají.
Hodnocení přeměňují AI z černé skříňky na transparentní, měřitelný, zlepšitelný systém.