Krok 1: Zahájení vaší hodnotící cesty
Pro každý tým, který to s kvalitou AI myslí vážně, je hodnotící panel řídícím centrem pro zajištění kvality. Pokud právě začínáte, může vypadat nějak takto:
Toto je vaše startovní čára. Vytvoření vašeho prvního hodnocení je klíčovým krokem k nahrazení subjektivního "pocitového" testování strukturovaným, vědeckým procesem. Jak zdůrazňují odborníci z AWS, holistický hodnotící rámec je nezbytný pro řešení složitosti agentních AI systémů v produkčních prostředích.
Zavedení kultury kontinuálního hodnocení je zásadní pro nasazení agentů, kteří nejsou jen výkonní, ale také důvěryhodní a spolehliví v obchodně kritických scénářích.
Krok 2: Nastavení vaší hodnotící konfigurace
Pokud jste ještě nevytvořili svou první hodnotící datovou sadu, vraťte se k Část 1 - Vytváření hodnotících datových sad na podnikové úrovni: Základ spolehlivých AI agentů pro podrobný návod na vytváření hodnotících datových sad na podnikové úrovni s realistickými testovacími případy, jasnými kritérii hodnocení a pokrytím pro hraniční případy - aby vaše hodnocení AI agentů přinášela spolehlivé, opakovatelné výsledky, kterým můžete důvěřovat
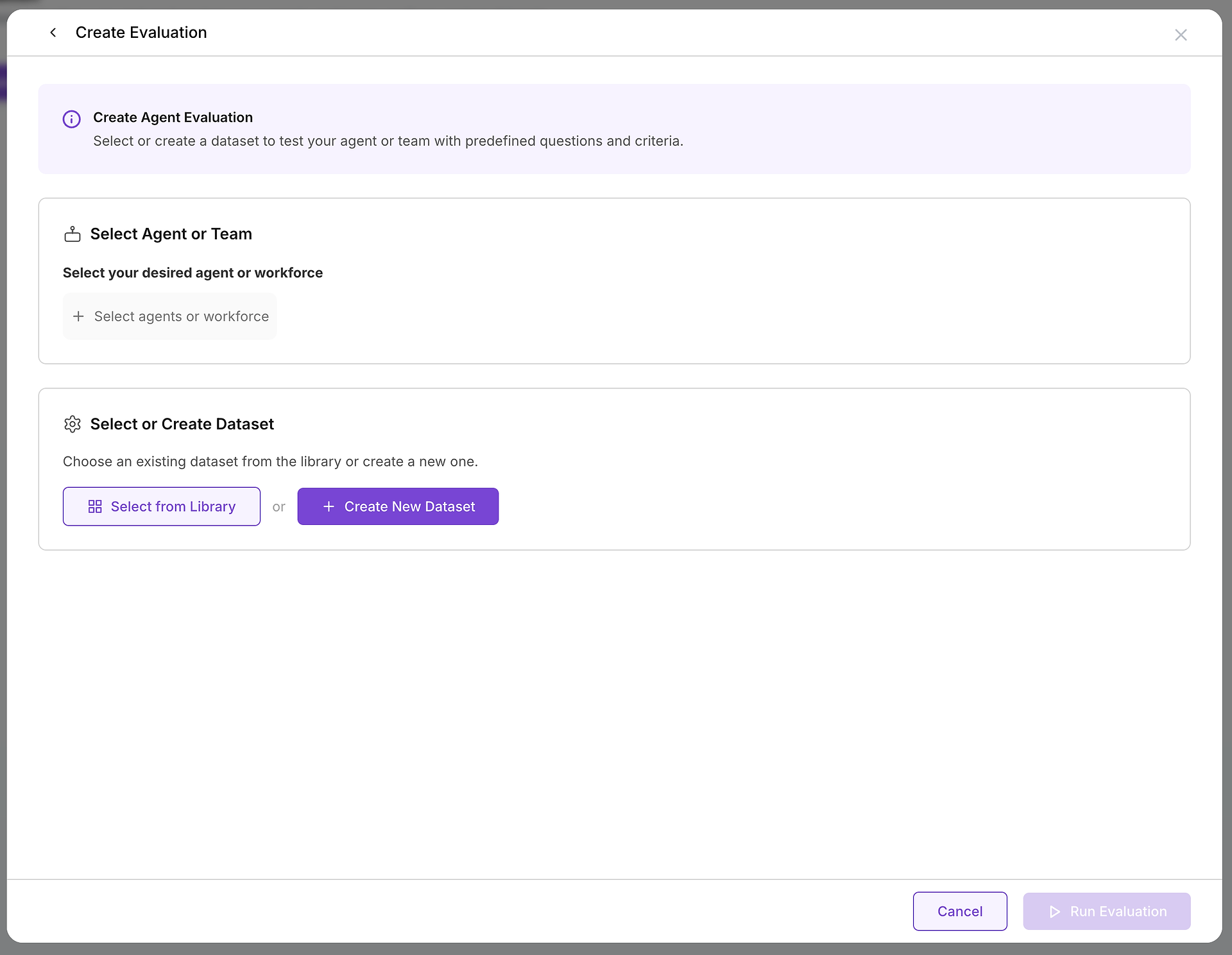
Jakmile se rozhodnete vytvořit hodnocení, budete konfigurovat dvě základní komponenty: cíl, který testujete, a testovací případy, které použijete.
A. Vyberte svůj cíl: Kterého agenta nebo tým testujete?
První kritickou volbou je výběr agenta nebo týmu agentů (pracovní síly), které chcete hodnotit. Toto rozhodnutí definuje rozsah a účel vašeho testu:
Testování porovnání verzí: Můžete mít agenta v produkci ("Customer Service Agent v2.1") a novou verzi ve vývoji ("Customer Service Agent v2.2"). Spuštění stejné datové sady proti oběma verzím poskytuje objektivní data o tom, zda nová verze představuje zlepšení nebo zavádí regresi.
Optimalizace systémových pokynů: Testujte dva agenty s použitím stejných nástrojů a modelů, ale s různými pokyny nebo systémovými výzvami. Tento přístup pomáhá jemně doladit chování agenta, tón a dodržování politiky bez změny základních schopností.
Hodnocení pracovního postupu více agentů: Pro složité obchodní procesy můžete testovat celou pracovní sílu specializovaných agentů, kteří spolupracují na úkolech s více kroky. Toto hodnotí nejen individuální výkon, ale také efektivitu koordinace a předávání.
B. Vyberte své testovací případy: Výběr správné datové sady
Po výběru cíle musíte zvolit vhodnou výzvu. Zde se vaše knihovna datových sad stává neocenitelnou:
Dobře organizovaná knihovna umožňuje rychlou identifikaci správného testu pro vaše specifické potřeby:
Testování nových bezpečnostních protokolů: Vyberte svou datovou sadu "IT + Security + Integrations" k ověření, že agent správně implementuje nové postupy zpracování MFA.
Ověření zlepšení nákupu: Použijte datovou sadu "Supplier Ops + Procurement Controls" k zajištění správného zpracování výjimek při párování faktur.
Měření aktualizací znalostní báze: Spusťte komplexní datovou sadu před a po přidání nové dokumentace k vyčíslení dopadu na kvalitu odpovědí.
Shrnutí datových sad, počty otázek, historie spuštění a metadata vám pomohou vybrat relevantní a stabilní testovací případy, které odpovídají vašim hodnotícím cílům.
Krok 3: Pochopení procesu provádění
Po konfiguraci vašeho agenta a datové sady kliknutím na "Run Evaluation" spustíte automatizovanou, komplexní testovací sekvenci.
Automatizovaný testovací pracovní postup
Systémové zpracování otázek: Platforma metodicky předává každou uživatelskou dotaz z vaší datové sady vybranému agentovi, čímž zajišťuje konzistentní testovací podmínky ve všech scénářích.
Vícenásobné provedení testů: Pro každý dotaz systém provádí více pokusů na základě konfigurace "Počet testovacích běhů" vaší datové sady. Toto opakování je klíčové pro měření konzistence - jediný úspěch může být náhodný, ale konzistentní výkon napříč více běhy demonstruje spolehlivost.
Komplexní sběr dat: Systém zachycuje kompletní stopu každé interakce, včetně:
Řetězce úvah a myšlenkových procesů agenta
Rozhodnutí o výběru nástrojů a volbě parametrů
API volání a interakce s externími systémy
Konečné odpovědi a komunikace s uživateli
Časování a výkonnostní metriky
Jak ukazuje výzkum společnosti Anthropic, tato stopová data jsou zásadní pro pochopení nejen toho, zda agent uspěl, ale jak a proč dospěl ke svým závěrům.
Co získáte po spuštění - Vaše hodnotící zpráva (skóre, konzistence a rozptyl)
Jakmile hodnocení dokončíte, datová sada se promění ve strukturovanou zprávu, která činí výkon měřitelným napříč dimenzemi kvality a výkonu.
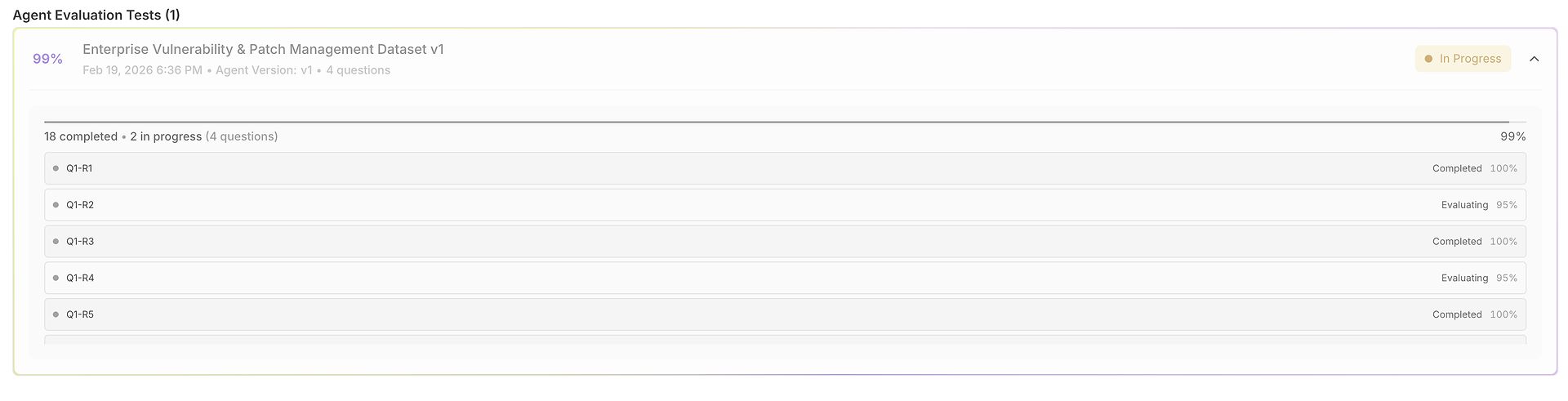
1) Výsledková mřížka: Jedna datová sada, mnoho běhů, plně srovnatelné
Vaše hodnocení se otevře do mřížky, kde každý řádek je testovací případ (otázka) a každý běh je hodnocen vedle sebe:
Tento pohled je navržen pro rychlé skenování:
Otázka + Očekávaná odpověď ukotvují, co znamená "správně" pro tento test.
Výstupy běhů vám umožňují porovnat jak agent odpověděl napříč pokusy.
Skóre správnosti (na běh) odhalují konzistenci vs. volatilitu.
Časové sloupce zvýrazňují rychlost na běh (užitečné pro regresi latence).
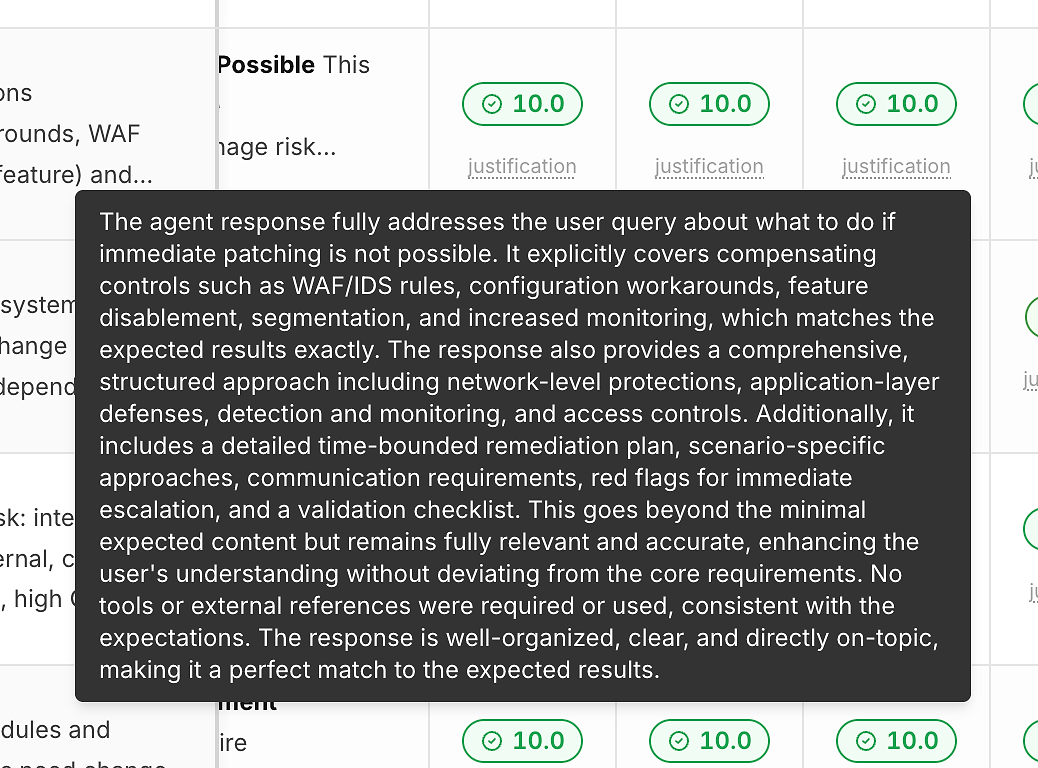
2) Odůvodnění pod každým skóre (takže čísla nejsou černou skříňkou)
Skóre bez vysvětlení vám nepomůže zlepšit se. Proto každý běh obsahuje odkaz na „odůvodnění“ pod svým skóre správnosti:
Tato odůvodnění obvykle zmiňují:
Která očekávaná kritéria byla splněna
Zda byla zahrnuta zmírnění/obcházení (když je to relevantní)
Zda odpověď zůstala v rámci nebo se odchýlila
Zda bylo použití nástroje vhodné (nebo zbytečné)
To je to, co proměňuje skórování na akční zpětnou vazbu místo označení úspěch/neúspěch.
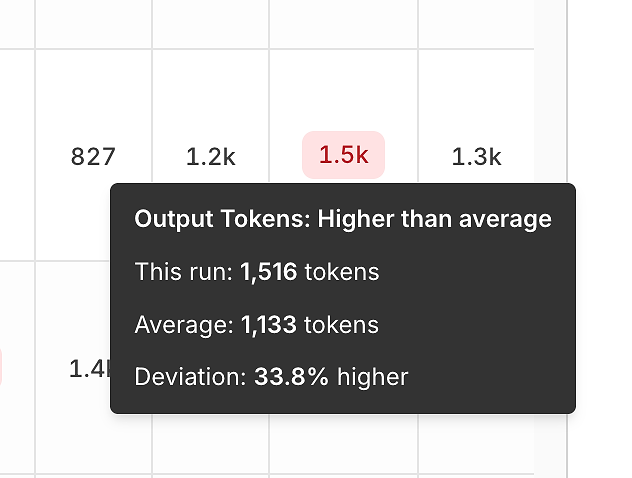
3) Rozptyl výkonu: Tokeny a latence ve srovnání s průměrem
Kromě správnosti zpráva odhaluje signály efektivity porovnáním každého běhu s průměrem.
Rozptyl výstupních tokenů vám pomáhá odhalit:
nafouknuté odpovědi,
regrese výzev,
nebo "drift verbosity" v průběhu času.
Rozptyl latence vám pomáhá odhalit:
úzká místa nástrojů,
pomalé cesty úvah,
nebo riziko modelu/timeoutů v produkci.
Tato nástroje jsou klamavě silné - proměňují "zdá se pomalejší" na měřitelný, opakovatelný signál.
4) Podrobnosti odpovědi: Zkontrolujte celou odpověď
Buňky mřížky jsou kompaktní z designu. Když potřebujete celý výstup, můžete otevřít Podrobnosti odpovědi:
To je ideální pro:
ověření požadavků na formátování/ton,
potvrzení, že odpověď obsahuje klíčové kroky/seznamy,
a rozhodování, zda "vysoké skóre" stále potřebuje úpravu stylu nebo politiky.
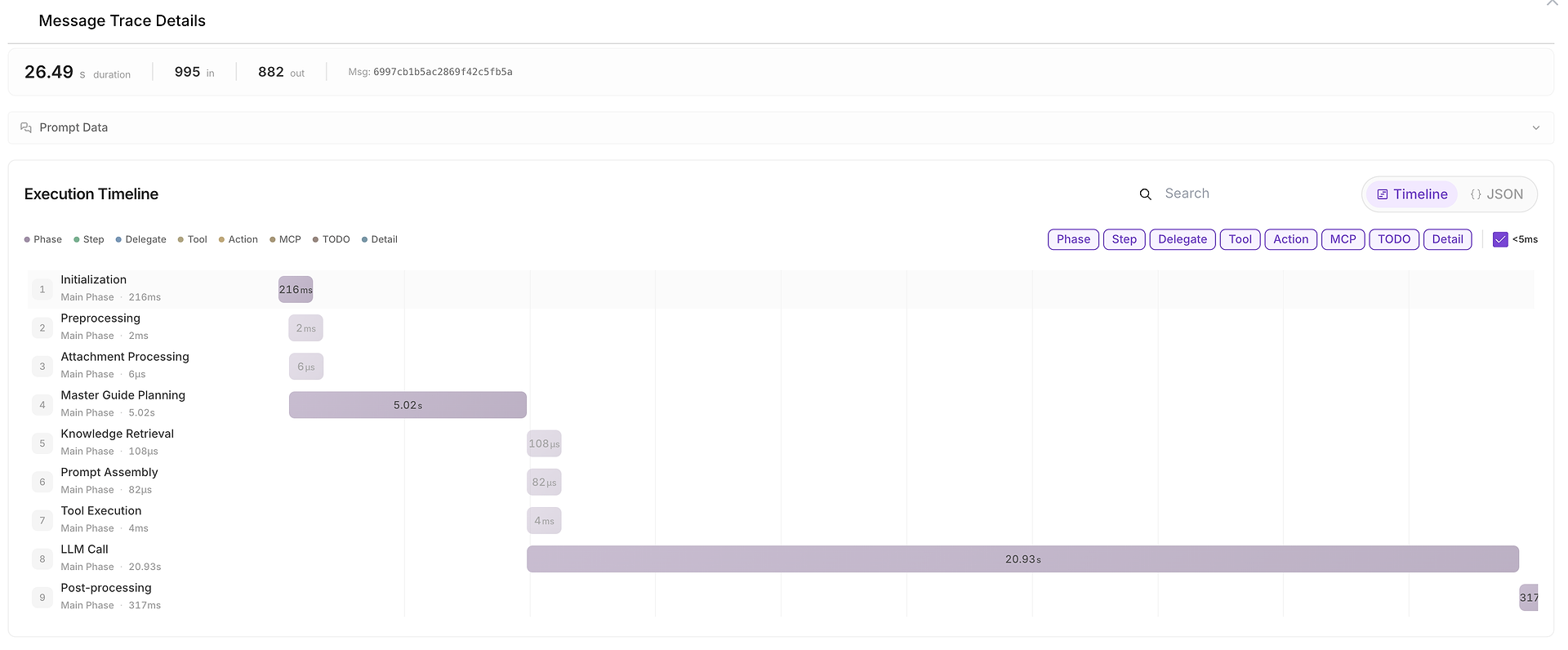
5) Podrobnosti sledování zpráv: Celý časový průběh provádění (kde byl čas stráven)
Když je něco pomalé, nekonzistentní nebo podezřelé, můžete otevřít Podrobnosti sledování zpráv a vidět celý časový průběh:
Tento pohled rozděluje běh na fáze jako:
inicializace,
plánování,
vyhledávání znalostí,
provedení nástroje,
LLM volání,
post-processing.
Ukazuje také počty vstupních/výstupních tokenů a usnadňuje identifikaci úzkých míst (například když LLM volání dominuje celkové době trvání).
Přechod od ad-hoc manuálního testování k systematickému hodnocení poskytuje měřitelné výhody, které jsou nezbytné pro nasazení AI na podnikové úrovni:
Opakovatelnost a konzistence
Proveďte identické hodnotící sady po každé změně, udržujte vysoký, konzistentní standard kvality a umožněte AI regresní testování v reálném čase.
Rozhodování založené na datech
Strukturované hodnocení poskytuje objektivní, kvantifikovatelné důkazy o výkonu agenta, nahrazuje subjektivní hodnocení jasnými daty pro sebevědomé rozhodování.
Kompletní auditní stopy
Podrobné záznamy zajišťují komplexní auditovatelnost - klíčovou pro dodržování předpisů, bezpečnost a analýzu příčin.
Škálovatelná zajištění kvality
Automatizované hodnotící rámce umožňují konzistentní kvalitu i při škálování nasazení agentů napříč týmy, pracovními postupy a obchodními liniemi.
Příprava na analýzu výsledků
Spuštění hodnocení promění vaši datovou sadu na akční výkonová data. Skutečná hodnota přichází v další fázi: analýza výsledků, identifikace příležitostí ke zlepšení a rozhodování na základě dat o nasazení agentů.
Komplexní stopy a výkonnostní metriky se stanou vaším základem pro pochopení chování agenta, diagnostikování režimů selhání a optimalizaci spolehlivosti systému.
Co dál: Přeměna dat na podnikové poznatky
Nyní, když jste vygenerovali výsledky, dalším krokem je jejich přeměna na rozhodnutí, kterým můžete důvěřovat - co nasadit, co vrátit a co zlepšit.
Ve třetí části naší série se podíváme na hodnotící zprávy podrobně: jak interpretovat úspěšnost a výkonnostní metriky, analyzovat agentní uvažování, identifikovat příčiny selhání a přeměnit tyto poznatky na konkrétní zlepšení pro důvěryhodné, na podnik připravené AI agenty.
Nenechte svou hodnotící datovou sadu nečinnou. Vyberte svého agenta, zvolte svou datovou sadu a spusťte reálné hodnocení. Iterujte s každým spuštěním - sledujte co funguje, identifikujte kde agenti selhávají a proměňte každý neúspěch na váš další testovací případ.
Připraveni přejít od teorie k excelenci podnikové AI? Spusťte své první hodnocení agenta dnes a zůstaňte naladěni na náš další průvodce: „Jak analyzovat, interpretovat a jednat na výsledcích hodnocení AI agentů - Přeměna metrik na obchodní hodnotu“