Schritt 1: Beginn Ihrer Bewertungsreise
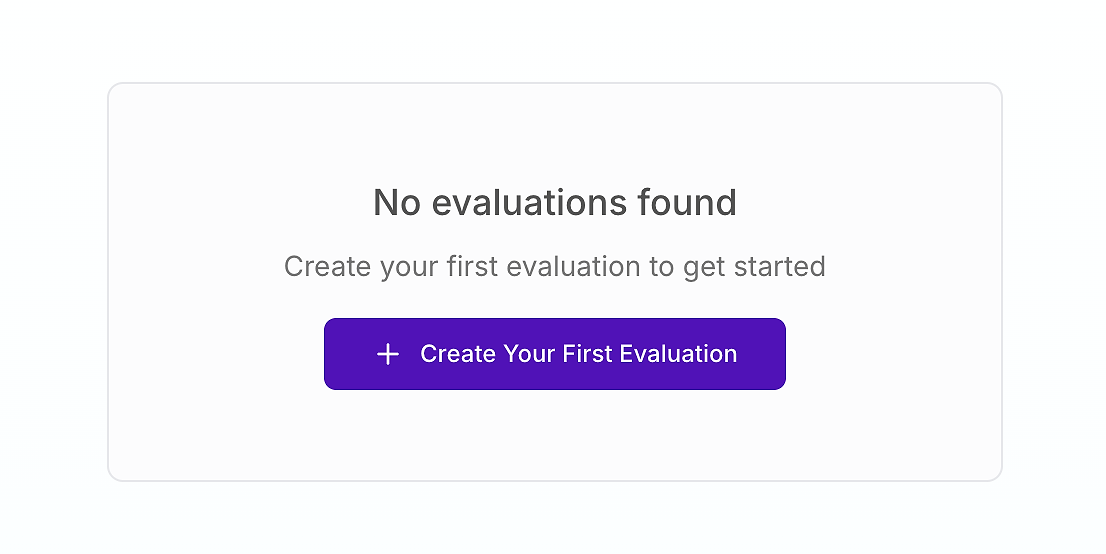
Für jedes Team, das es mit der KI-Qualität ernst meint, ist das Bewertungs-Dashboard das Kommandozentrum für Qualitätssicherung. Wenn Sie gerade erst anfangen, könnte es so aussehen:
Dies ist Ihre Startlinie. Die Erstellung Ihrer ersten Bewertung ist der entscheidende Schritt, um subjektive "Bauchgefühl"-Tests durch einen strukturierten, wissenschaftlichen Prozess zu ersetzen. Wie Experten von AWS betonen, ist ein ganzheitliches Bewertungsrahmenwerk unerlässlich, um die Komplexität agentischer KI-Systeme in Produktionsumgebungen zu adressieren.
Eine Kultur der kontinuierlichen Bewertung zu etablieren, ist entscheidend für die Bereitstellung von Agenten, die nicht nur leistungsstark, sondern auch vertrauenswürdig und zuverlässig in geschäftskritischen Szenarien sind.
Schritt 2: Einrichten Ihrer Bewertungskonfiguration
Wenn Sie noch keinen ersten Bewertungsdatensatz erstellt haben, gehen Sie zurück zu Teil 1 - Aufbau von unternehmensgerechten Bewertungsdatensätzen: Die Grundlage zuverlässiger KI-Agenten für eine Schritt-für-Schritt-Anleitung zum Aufbau von unternehmensgerechten Bewertungsdatensätzen mit realistischen Testfällen, klaren Bewertungskriterien und Abdeckung von Randfällen - damit Ihre KI-Agentenbewertungen zuverlässige, wiederholbare Ergebnisse liefern, denen Sie vertrauen können.
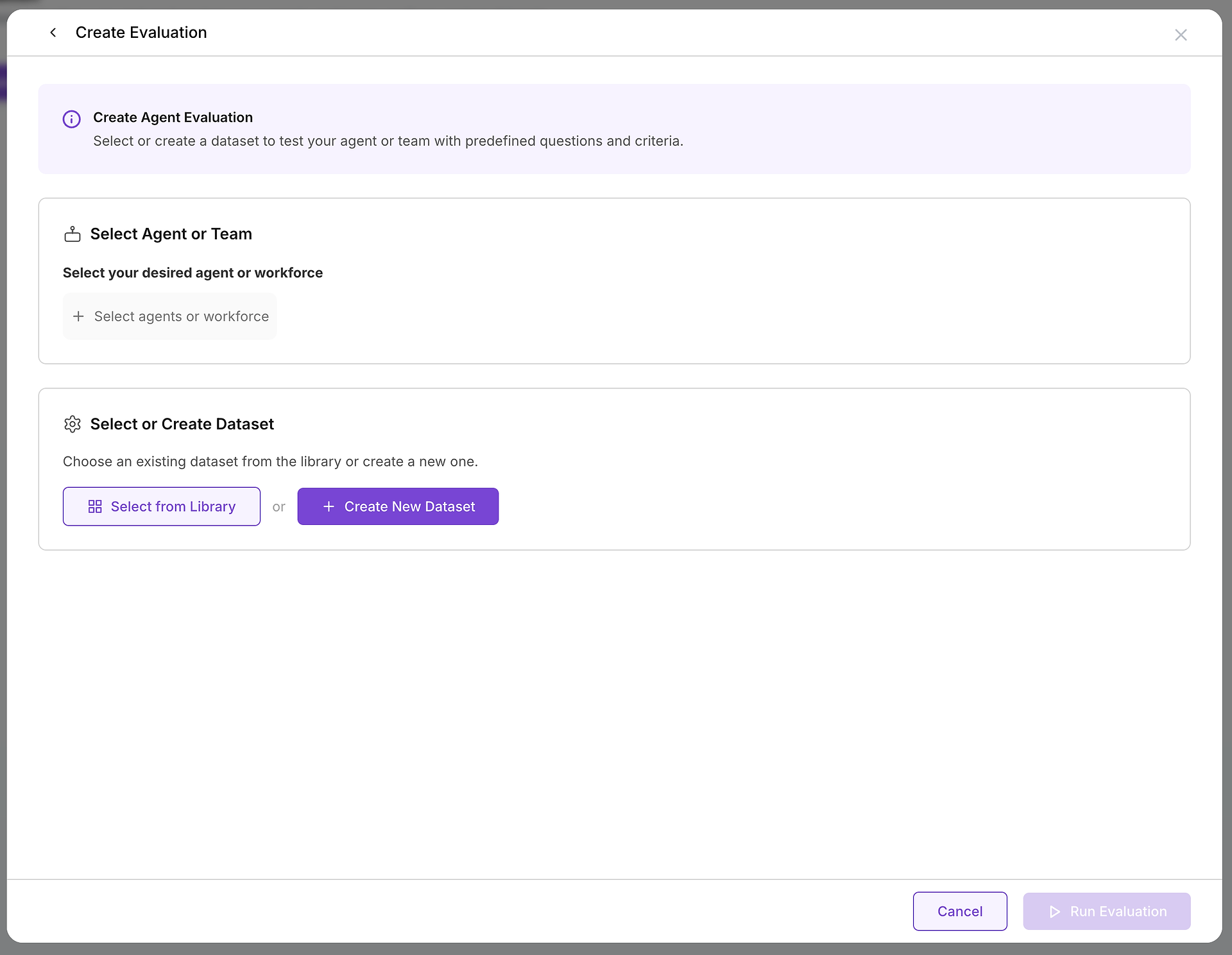
Sobald Sie sich entscheiden, eine Bewertung zu erstellen, konfigurieren Sie zwei wesentliche Komponenten: das Ziel, das Sie testen, und die Testfälle, die Sie verwenden werden.
A. Wählen Sie Ihr Ziel: Welchen Agenten oder welches Team testen Sie?
Die erste entscheidende Wahl ist die Auswahl des Agenten oder des Agententeams (einer Belegschaft), das Sie bewerten möchten. Diese Entscheidung definiert den Umfang und Zweck Ihres Tests:
Version Comparison Testing: Möglicherweise haben Sie einen Agenten in Produktion ("Customer Service Agent v2.1") und eine neue Version in Entwicklung ("Customer Service Agent v2.2"). Wenn Sie denselben Datensatz gegen beide Versionen laufen lassen, erhalten Sie objektive Daten darüber, ob die neue Version eine Verbesserung darstellt oder Rückschritte einführt.
System Prompt Optimization: Testen Sie zwei Agenten, die identische Tools und Modelle verwenden, aber mit unterschiedlichen Anweisungen oder System-Prompts. Dieser Ansatz hilft, das Verhalten, den Ton und die Richtlinieneinhaltung des Agenten zu optimieren, ohne die zugrunde liegenden Fähigkeiten zu ändern.
Multi-Agent Workflow Evaluation: Für komplexe Geschäftsprozesse können Sie eine gesamte Belegschaft spezialisierter Agenten testen, die an mehrstufigen Aufgaben zusammenarbeiten. Dies bewertet nicht nur die individuelle Leistung, sondern auch die Koordination und Effektivität der Übergabe.
B. Wählen Sie Ihre Testfälle: Den richtigen Datensatz auswählen
Mit Ihrem ausgewählten Ziel müssen Sie die passende Herausforderung wählen. Hier wird Ihre Datensatzbibliothek unschätzbar wertvoll:
Eine gut organisierte Bibliothek ermöglicht die schnelle Identifizierung des richtigen Tests für Ihre spezifischen Bedürfnisse:
Testing New Security Protocols: Wählen Sie Ihren "IT + Security + Integrations"-Datensatz, um zu überprüfen, ob der Agent die neuen MFA-Verfahren korrekt implementiert.
Validating Procurement Improvements: Verwenden Sie den "Supplier Ops + Procurement Controls"-Datensatz, um sicherzustellen, dass Ausnahmen bei der Rechnungsabstimmung ordnungsgemäß behandelt werden.
Measuring Knowledge Base Updates: Führen Sie einen umfassenden Datensatz vor und nach der Hinzufügung neuer Dokumentationen aus, um die Auswirkungen auf die Antwortqualität zu quantifizieren.
Die Datensatz-Zusammenfassungen, Frageanzahlen, Laufhistorien und Metadaten helfen Ihnen, relevante und stabile Testfälle auszuwählen, die mit Ihren Bewertungszielen übereinstimmen.
Schritt 3: Den Ausführungsprozess verstehen
Mit Ihrem konfigurierten Agenten und Datensatz startet das Klicken auf "Run Evaluation" eine automatisierte, umfassende Testsequenz.
Der automatisierte Testablauf
Systematische Frageverarbeitung: Die Plattform speist methodisch jede Benutzeranfrage aus Ihrem Datensatz an den ausgewählten Agenten, um konsistente Testbedingungen über alle Szenarien hinweg sicherzustellen.
Mehrfache Testdurchführungen: Für jede Anfrage führt das System mehrere Durchläufe basierend auf der "Anzahl der Testläufe"-Konfiguration Ihres Datensatzes durch. Diese Wiederholung ist entscheidend für die Messung der Konsistenz - ein einzelner Erfolg könnte zufällig sein, aber konsistente Leistung über mehrere Durchläufe hinweg zeigt Zuverlässigkeit.
Umfassende Datenerfassung: Das System erfasst eine vollständige Spur jeder Interaktion, einschließlich:
Agenten-Denkprozesse und Gedankengänge
Tool-Auswahlentscheidungen und Parameterwahl
API-Aufrufe und Interaktionen mit externen Systemen
Endantworten und Benutzerkommunikation
Timing- und Leistungsmetriken
Wie die Forschung von Anthropic zeigt, sind diese Trace-Daten grundlegend, um nicht nur zu verstehen, ob ein Agent erfolgreich war, sondern auch, wie und warum er zu seinen Schlussfolgerungen gelangt ist.
Was Sie nach dem Lauf erhalten - Ihr Bewertungsbericht (Scores, Konsistenz und Varianz)
Sobald die Bewertung abgeschlossen ist, verwandelt sich der Datensatz in einen strukturierten Bericht, der die Leistung über Qualitäts- und Leistungsdimensionen messbar macht.
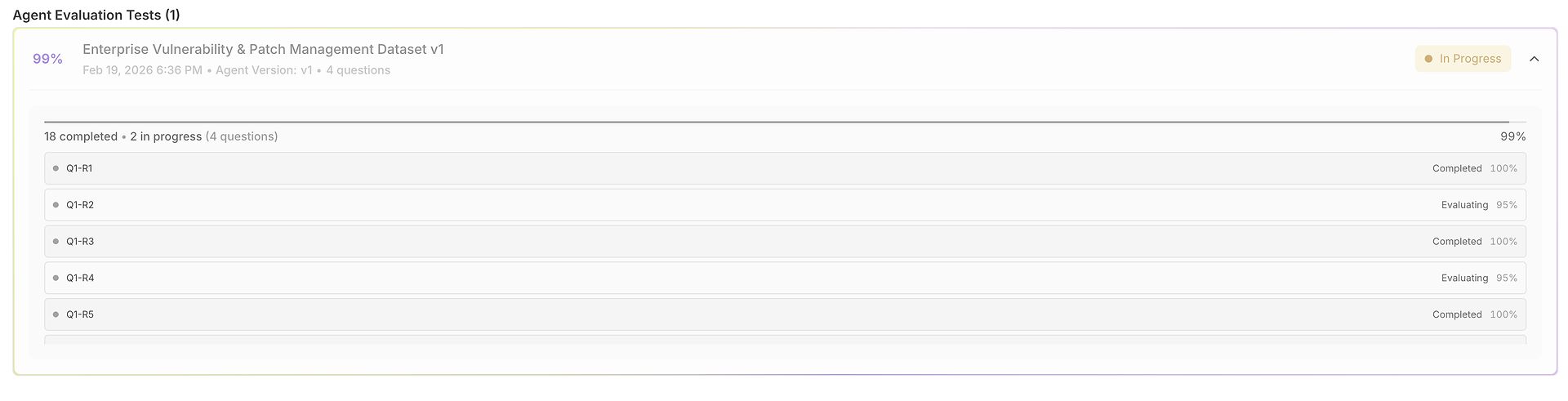
1) Das Ergebnisraster: Ein Datensatz, viele Durchläufe, vollständig vergleichbar
Ihre Bewertung öffnet sich in einem Raster, in dem jede Zeile ein Testfall (Frage) ist und jeder Durchlauf nebeneinander bewertet wird:
Diese Ansicht ist für schnelles Scannen konzipiert:
Frage + Erwartete Antwort verankern, was "korrekt" für diesen Test bedeutet.
Ausgabe der Durchläufe ermöglicht den Vergleich, wie der Agent in den Durchläufen geantwortet hat.
Korrektheitsscores (pro Durchlauf) zeigen Konsistenz vs. Volatilität.
Timing-Spalten heben die Geschwindigkeit pro Durchlauf hervor (nützlich für Latenz-Rückschritte).
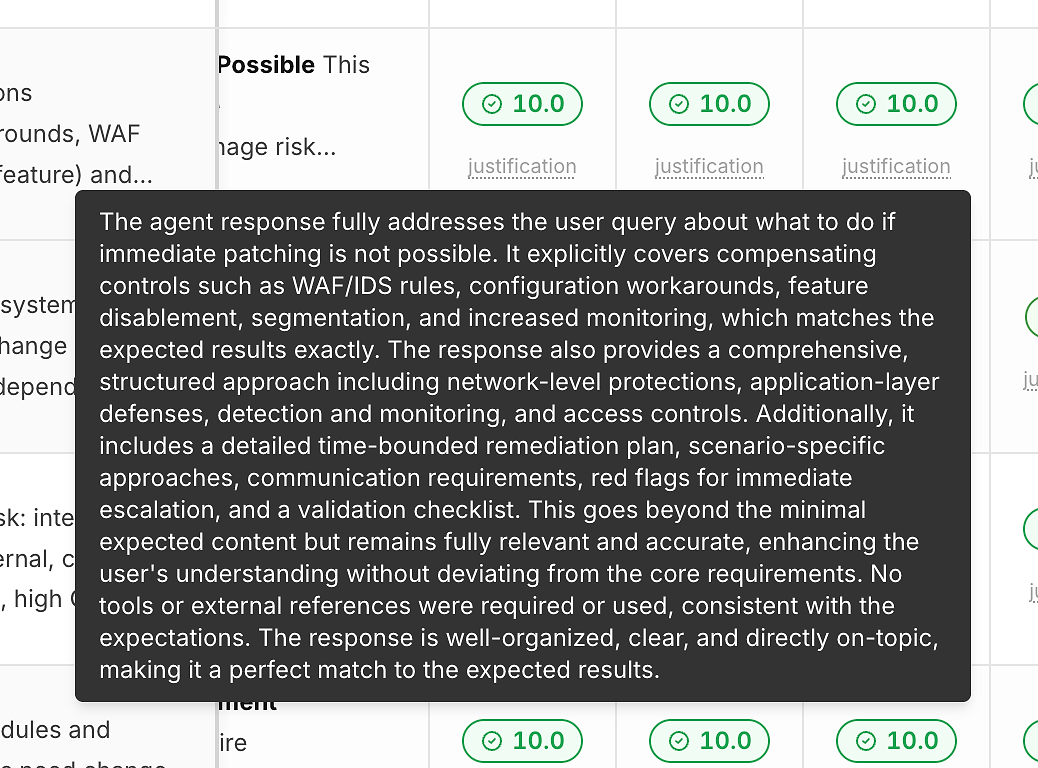
2) Begründung unter jedem Score (damit Zahlen kein Black Box sind)
Ein Score ohne Erklärung hilft nicht bei der Verbesserung. Deshalb enthält jeder Durchlauf einen "Begründungs"-Link unter seinem Korrektheitsscore:
Diese Begründungen heben typischerweise hervor:
Welche erwarteten Kriterien erfüllt wurden
Ob Milderungen/Workarounds enthalten waren (wenn relevant)
Ob die Antwort im Rahmen blieb oder abdriftete
Ob die Tool-Nutzung angemessen (oder unnötig) war
Dies verwandelt die Bewertung in umsetzbares Feedback anstelle eines Pass/Fail-Labels.
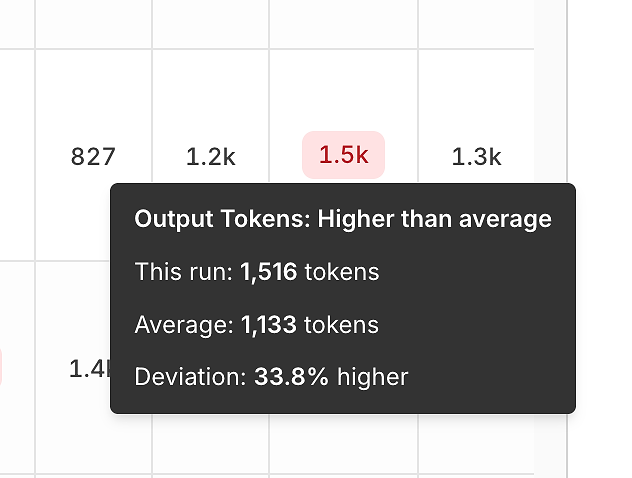
3) Leistungsvarianz: Tokens und Latenz im Vergleich zum Durchschnitt
Über die Korrektheit hinaus zeigt der Bericht Effizienz-Signale, indem er jeden Durchlauf mit dem Durchschnitt vergleicht.
Ausgabe-Token-Varianz hilft Ihnen, zu erkennen:
aufgeblähte Antworten,
Prompt-Rückschritte,
oder "Verbosity Drift" im Laufe der Zeit.
Latenz-Varianz hilft Ihnen, zu erkennen:
Tool-Engpässe,
langsame Denkwege,
oder Modell-/Timeout-Risiken in der Produktion.
Diese Tooltips sind täuschend mächtig - sie verwandeln "es fühlt sich langsamer an" in ein messbares, wiederholbares Signal.
4) Antwortdetails: Die vollständige Antwort inspizieren
Rasterzellen sind kompakt gestaltet. Wenn Sie die vollständige Ausgabe benötigen, können Sie Antwortdetails öffnen:
Dies ist ideal für:
Überprüfung von Formatierungs-/Tonanforderungen,
Bestätigung, dass die Antwort wichtige Schritte/Checklisten enthält,
und Entscheidung, ob ein "hoher Score" dennoch Stil- oder Richtlinienverfeinerung benötigt.
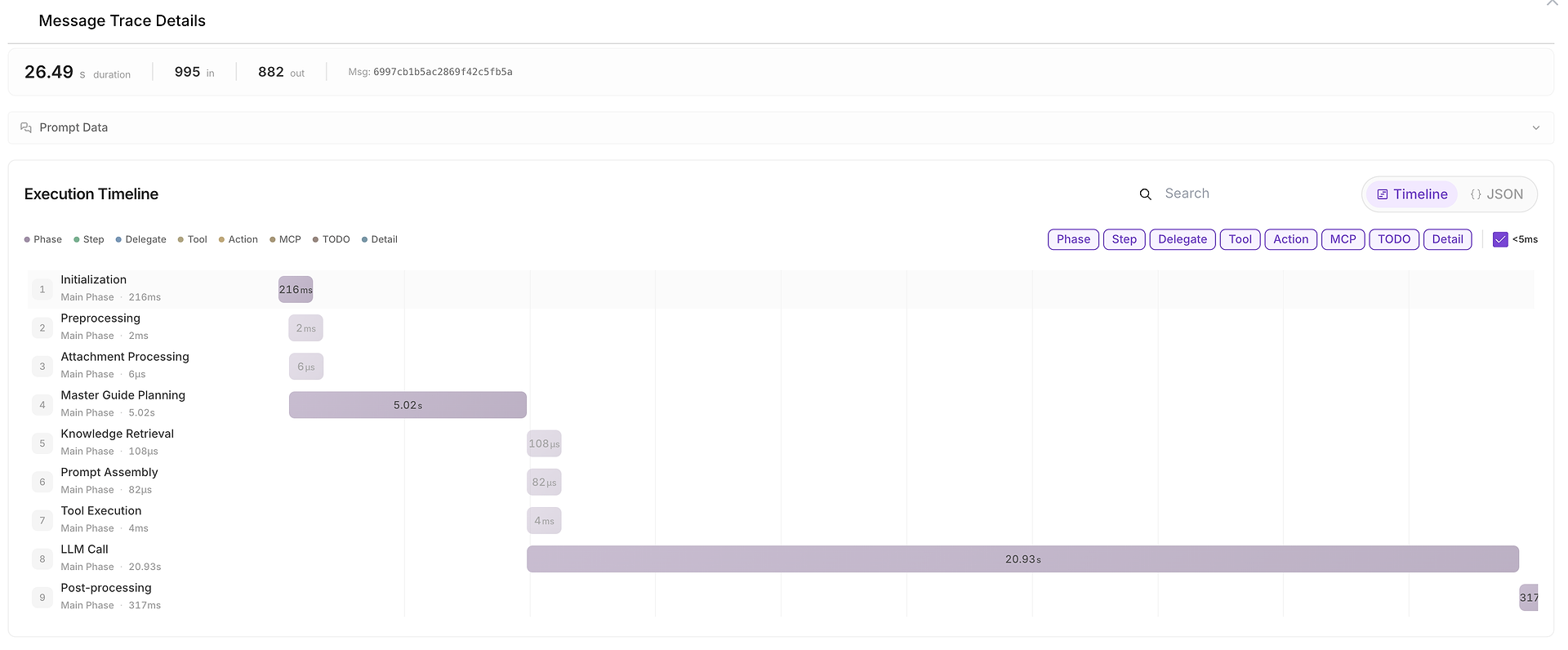
5) Nachrichtenverfolgungsdetails: Der vollständige Ausführungszeitplan (wo Zeit verbracht wurde)
Wenn etwas langsam, inkonsistent oder verdächtig ist, können Sie Nachrichtenverfolgungsdetails öffnen, um den vollständigen Zeitplan zu sehen:
Diese Ansicht unterteilt den Lauf in Phasen wie:
Initialisierung,
Planung,
Wissensabruf,
Tool-Ausführung,
LLM-Aufruf,
Nachbearbeitung.
Es zeigt auch Eingabe-/Ausgabe-Token-Zahlen und macht es einfach, Engpässe zu identifizieren (zum Beispiel, wenn der LLM-Aufruf die End-to-End-Dauer dominiert).
Der Übergang von ad-hoc manuellen Tests zu systematischer Bewertung bietet messbare Vorteile, die für den unternehmensgerechten KI-Einsatz unerlässlich sind:
Wiederholbarkeit und Konsistenz
Führen Sie identische Bewertungssuiten nach jeder Änderung aus, um einen hohen, konsistenten Qualitätsstandard aufrechtzuerhalten und Echtzeit-KI-Regressions-Tests zu ermöglichen.
Datengetriebene Entscheidungsfindung
Strukturierte Bewertung liefert objektive, quantifizierbare Beweise für die Agentenleistung und ersetzt subjektive Einschätzungen durch klare Daten für fundierte Entscheidungen.
Vollständige Prüfpfade
Detaillierte Protokolle gewährleisten umfassende Prüfbarkeit - entscheidend für Compliance, Sicherheit und Ursachenanalyse.
Skalierbare Qualitätssicherung
Automatisierte Bewertungsrahmen ermöglichen konsistente Qualität, selbst wenn Agentenbereitstellungen über Teams, Workflows und Geschäftsbereiche hinweg skaliert werden.
Vorbereitung auf die Ergebnisanalyse
Die Durchführung der Bewertung verwandelt Ihren Datensatz in umsetzbare Leistungsdaten. Der wahre Wert liegt in der nächsten Phase: Ergebnisse analysieren, Verbesserungsmöglichkeiten identifizieren und datengetriebene Entscheidungen über die Agentenbereitstellung treffen.
Die umfassenden Traces und Leistungsmetriken werden Ihre Grundlage, um das Verhalten der Agenten zu verstehen, Ausfallmodi zu diagnostizieren und die Systemzuverlässigkeit zu optimieren.
Was als Nächstes kommt: Daten in Unternehmens-Insights verwandeln
Jetzt, da Sie Ergebnisse generiert haben, besteht der nächste Schritt darin, sie in vertrauenswürdige Entscheidungen umzuwandeln - was ausgeliefert, was zurückgerollt und was verbessert werden soll.
In Teil 3 unserer Serie werden wir die Bewertungsberichte im Detail erkunden: wie man Erfolgsraten und Leistungsmetriken interpretiert, agentisches Denken analysiert, Ursachen von Fehlern identifiziert und diese Erkenntnisse in konkrete Verbesserungen für vertrauenswürdige, unternehmensbereite KI-Agenten umsetzt.
Lassen Sie Ihren Bewertungsdatensatz nicht ungenutzt. Wählen Sie Ihren Agenten, wählen Sie Ihren Datensatz und führen Sie eine echte Bewertung durch. Iterieren Sie mit jedem Lauf - verfolgen Sie, was funktioniert, identifizieren Sie, wo Agenten ausrutschen, und verwandeln Sie jeden Fehler in Ihren nächsten Testfall.
Bereit, von der Theorie zur Exzellenz in der Unternehmens-KI zu wechseln? Führen Sie heute Ihre erste Agentenbewertung durch und bleiben Sie dran für unseren nächsten Leitfaden: „Wie man KI-Agenten-Bewertungsergebnisse analysiert, interpretiert und darauf reagiert - Metriken in Geschäftswert umwandeln“