Los agentes de AI se están volviendo más avanzados, más capaces y están más profundamente integrados en las empresas.
Pero hay un problema universal al que se enfrenta cada equipo:
Tu agente no siempre responde como esperas, y no sabes por qué.
A veces cambia el razonamiento, a veces el agente ignora una regla, a veces la herramienta no se usó correctamente, y a veces se malinterpretó una instrucción sutil. Sin visibilidad de cómo se tomaron las decisiones, mejorar el agente se siente como adivinar.
Por eso exactamente construimos Agent Evaluations: un nuevo sistema dentro de AgentX que te permite probar, medir y analizar en profundidad cómo se comporta tu agente a lo largo de múltiples ejecuciones de la misma pregunta.
Es la primera vez que puedes ver dentro de la toma de decisiones de tu agente, encontrar inconsistencias y entender con precisión dónde se necesitan mejoras.
Por qué importan las evaluaciones
Los modelos de AI son probabilísticos.
Incluso con el mismo prompt, contexto y reglas, el modelo puede:
producir rutas de razonamiento ligeramente diferentes
omitir un detalle requerido
malinterpretar una política
omitir una consulta a una herramienta
dar respuestas inciertas en lugar de la respuesta definitiva esperada
delegar de forma inconsistente dentro de un equipo
Desde fuera, solo ves la respuesta final.
No ves:
si el agente siguió tus instrucciones
si usó las herramientas correctas
si razonó correctamente
por qué una versión de la respuesta fue más débil que otra
por qué a veces acierta — y a veces se equivoca
Las evaluaciones resuelven esto dándote estructura, puntuación y transparencia.
Cómo funciona una prueba
Crear una evaluación es sencillo:
0. Selecciona el agente o equipo que quieres evaluar.
1. Pregunta de prueba
Esta es la pregunta del mundo real que quieres validar.
Simula una consulta de un cliente o una solicitud de flujo de trabajo interno.
Ejemplo:
“¿Puedo devolver un artículo de Venta Final si no me queda?”
Esto forma el núcleo de la evaluación.
2. Resultados esperados (Obligatorio)
Esta es la parte más importante de la configuración.
Aquí defines lo que el agente DEBE decir o incluir para que la respuesta se considere correcta.
Puede contener:
hechos clave
frases obligatorias
pasos de razonamiento requeridos
reglas de cumplimiento
tono específico o declaraciones de política
Ejemplo:
“Debe decir: No, los artículos de Venta Final no se pueden devolver ni cambiar.”
Los Resultados esperados se convierten en la rúbrica de puntuación para todas las ejecuciones de prueba.
3. Capacidades esperadas (Opcional pero potente)
Puedes indicarle al sistema de evaluación qué herramientas, documentos o fuentes de conocimiento debería usar el agente.
En tu ejemplo, seleccionaste:
Documents → store_policy_kb_v1.xlsx
Built-in Functions
Esto significa:
El agente debería recuperar información desde la KB de políticas.
Si no usa la KB correctamente, la evaluación lo detectará.
Esto es perfecto para:
agentes de políticas
agentes de atención al cliente
flujos de trabajo de cumplimiento
modelado financiero
razonamiento respaldado por datos
4. Configuración de la evaluación
Esta sección define qué tan rigurosa y qué tan profunda debe ser tu evaluación.
Número de ejecuciones de prueba
La misma pregunta se ejecuta varias veces (Recomendado: 5 ejecuciones).
¿Por qué?
Porque los modelos de AI no son deterministas. Varias ejecuciones te permiten comprobar:
consistencia
estabilidad
confiabilidad del razonamiento
si el agente sigue el mismo proceso cada vez
Si el agente produce una buena respuesta y cuatro fallos, lo verás al instante.
Criterios de aceptación
Este control deslizante define qué tan estrictamente debe coincidir la respuesta con tus Resultados esperados.
Estás eligiendo un punto entre:
Flexible → el agente puede desviarse de tus expectativas; la respuesta no necesita ser perfecta.
Exacto → la respuesta debe seguir tus expectativas muy de cerca, con casi ningún margen de variación.
Simplemente controla qué tan exacta debe ser la respuesta para aprobar la evaluación.
Criterios de rechazo (Opcional)
Reglas para fallo automático.
Ejemplos:
“La respuesta no debe mencionar a competidores.”
“No ofrecer reembolsos cuando la política lo prohíbe.”
“La respuesta no debe pedir al usuario que proporcione información personal.”
Estas son restricciones estrictas.
Criterios de evaluación (Opcional)
Guía adicional de puntuación, a menudo usada para calidad o tono.
Ejemplos:
“La respuesta debe ser amable y profesional.”
“La respuesta debe contener una explicación breve, no solo un sí/no.”
“Usar hechos de la KB antes que suposiciones.”
No son requisitos estrictos, pero ayudan a dar forma a cómo la AI puntúa al agente.
5. Crear evaluación
Una vez configurado, al hacer clic en Create Evaluation se inicia el proceso:
la pregunta se ejecuta varias veces
cada respuesta se puntúa
se genera un análisis detallado
se inspeccionan la delegación y el uso de herramientas
se sacan a la luz las inconsistencias
Y recibes un informe completo de rendimiento.
Qué obtienes después de ejecutar la evaluación
Después de varias ejecuciones, AgentX proporciona dos niveles de salida:
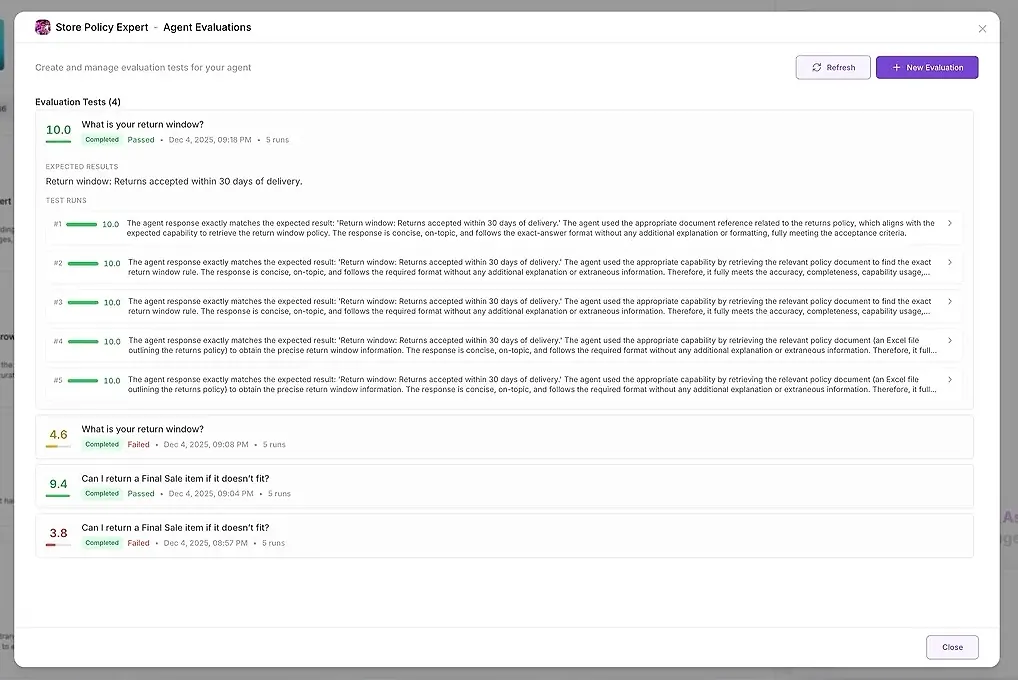
1. Resultados de la prueba
Para cada ejecución, ves:
una puntuación numérica
un resumen de qué tan bien coincidió con tus expectativas
la respuesta completa
qué herramientas se usaron
qué agentes participaron
dónde falló o se desvió el agente
Esto te permite comparar respuestas lado a lado e identificar patrones.
2. Análisis profundo de AI
Aquí es donde ocurre la verdadera magia.
AgentX analiza automáticamente todas las ejecuciones y genera un informe estructurado en múltiples categorías:
• Adherencia a instrucciones
¿El agente siguió tus reglas?
• Patrones de respuesta
¿Qué tan similares o diferentes fueron las respuestas?
¿Hay valores atípicos?
• Análisis de razonamiento
¿Los pasos de razonamiento fueron correctos, completos y alineados con las expectativas?
• Uso de herramientas
¿El agente usó la herramienta correcta?
¿Omitió una consulta?
¿Se basó en suposiciones en lugar de hechos verificados?
• Recomendaciones
Sugerencias concretas y accionables para mejorar tu agente.
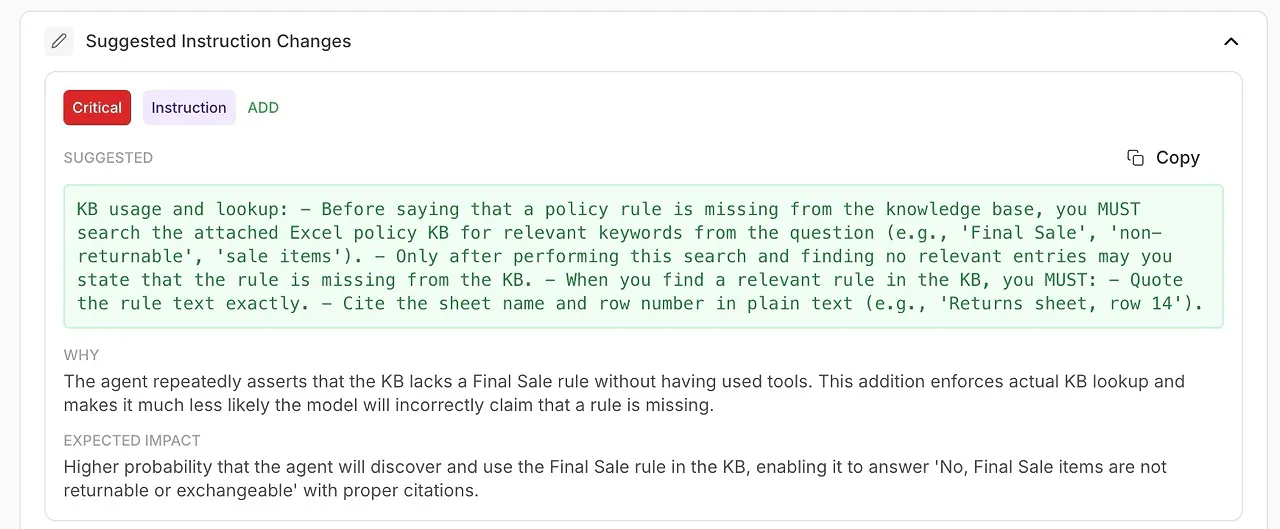
• Cambios sugeridos en instrucciones
Mejoras generadas automáticamente para tu system prompt o la configuración del agente.
• Evaluación general
Un resumen de fortalezas, debilidades y nivel de confianza.
Esto transforma la depuración de un juego de adivinanzas en un proceso científico y repetible.
Lo que habilita esta funcionalidad
Las evaluaciones introducen un nuevo nivel de transparencia y confiabilidad en cómo operan tus agentes. En lugar de adivinar por qué una respuesta fue incorrecta o inconsistente, ahora tienes una forma estructurada y medible de entender el comportamiento, diagnosticar problemas y mejorar continuamente el rendimiento.
Esto es lo que pasa a ser posible:
🔍 Valida tu agente antes de lanzarlo a los clientes
Antes de llevar un agente a producción, puedes ejecutar pruebas realistas que revelen si entiende completamente tus reglas, tu base de conocimiento y el tono deseado. No más sorpresas después del despliegue: sabes exactamente qué experimentarán los usuarios.
🤖 Prueba a todo tu equipo de agentes y la lógica de delegación
Para configuraciones multiagente, las Evaluations muestran cómo tu manager delega tareas, qué subagentes participan y si siguen el flujo de trabajo esperado. Puedes detectar rápidamente:
delegaciones innecesarias
delegaciones faltantes
agentes en conflicto
comportamiento incorrecto del rol
Esto es esencial para un trabajo en equipo confiable dentro de tu fuerza laboral de AI.
📚 Detecta puntos débiles en tu base de conocimiento
Si una evaluación muestra fallos repetidos en un tema específico, sabes que el problema no es el agente: es contenido faltante o poco claro. Las evaluaciones te ayudan a refinar tu KB de forma dirigida y basada en datos, en lugar de añadir más material a ciegas.
🚨 Detecta alucinaciones e inconsistencias temprano
Como cada pregunta se prueba varias veces, las Evaluations sacan a la luz problemas sutiles como:
respuestas que cambian de forma impredecible
deriva del razonamiento
conjeturas factuales que reemplazan el uso de herramientas
contradicciones entre ejecuciones
Estos son problemas que nunca identificarías probando manualmente una o dos veces.
🧠 Refina las instrucciones del sistema con mejoras generadas por AI
El análisis no solo muestra qué salió mal: te dice cómo solucionarlo.
Recibes recomendaciones accionables respaldadas por los propios diagnósticos del modelo:
redacción mejorada
reglas más estrictas
uso obligatorio de herramientas
políticas de delegación más claras
tono y estructura más precisos
Esto es prompt engineering automatizado integrado directamente en tu flujo de trabajo.
📈 Mide el progreso cada vez que actualices tu agente
Cada vez que cambies:
un system prompt
una entrada de la base de conocimiento
una herramienta
una regla de delegación
una política de razonamiento
…puedes volver a ejecutar la misma evaluación y comparar puntuaciones. Ves exactamente cómo tu actualización afectó el rendimiento, para bien o para mal.
Las evaluaciones se convierten en tu bucle de mejora continua.
Ya sea que estés gestionando soporte, análisis financiero, escenarios de salud o contenido legalmente sensible, las Evaluations te permiten asegurar que:
se sigan las políticas
se respeten las guías de tono
se señalen brechas peligrosas
se saque a la luz el razonamiento incorrecto
se cumplan los estándares de cumplimiento
Esto es especialmente crítico para AI empresarial y de cara al cliente.
Uso y costos
Las Agent Evaluations usan exactamente el mismo modelo de créditos que el resto de AgentX. Cada ejecución de prueba simplemente consume créditos de la misma manera que lo hace un mensaje normal del agente: sin cargos extra, sin precios ocultos. Siempre sabes exactamente lo que estás gastando, porque las Evaluations siguen los límites de tu plan actual y tu saldo de créditos.
Tu capa de control de calidad para AI
En el software tradicional, QA garantiza la confiabilidad.
En AgentX, las Evaluations son tu QA para agentes.
Tú defines cómo se ve lo “bueno”.
AgentX comprueba si tus agentes pueden entregarlo de forma consistente y te muestra exactamente qué mejorar cuando no lo hacen.
Las Evaluations convierten la AI de una caja negra en un sistema transparente, medible y mejorable.