Étape 1 : Commencer Votre Parcours d'Évaluation
Pour toute équipe sérieuse au sujet de la qualité AI, le tableau de bord d'évaluation est le centre de commande pour l'assurance qualité. Si vous débutez, cela pourrait ressembler à ceci :
C'est votre ligne de départ. Créer votre première évaluation est l'étape cruciale pour remplacer les tests subjectifs basés sur l'intuition par un processus structuré et scientifique. Comme le soulignent les experts d'AWS, un cadre d'évaluation holistique est essentiel pour aborder la complexité des systèmes AI agentiques dans les environnements de production.
Établir une culture d'évaluation continue est crucial pour déployer des agents qui ne sont pas seulement puissants, mais aussi dignes de confiance et fiables dans des scénarios critiques pour l'entreprise.
Si vous n'avez pas encore créé votre premier jeu de données d'évaluation, retournez à Partie 1 - Construire des Jeux de Données d'Évaluation de Niveau Entreprise : La Fondation des Agents AI Fiables pour un guide étape par étape sur la création de jeux de données d'évaluation de niveau entreprise avec des cas de test réalistes, des critères de notation clairs et une couverture des cas limites - afin que vos évaluations d'agents AI produisent des résultats fiables et reproductibles en lesquels vous pouvez avoir confiance.
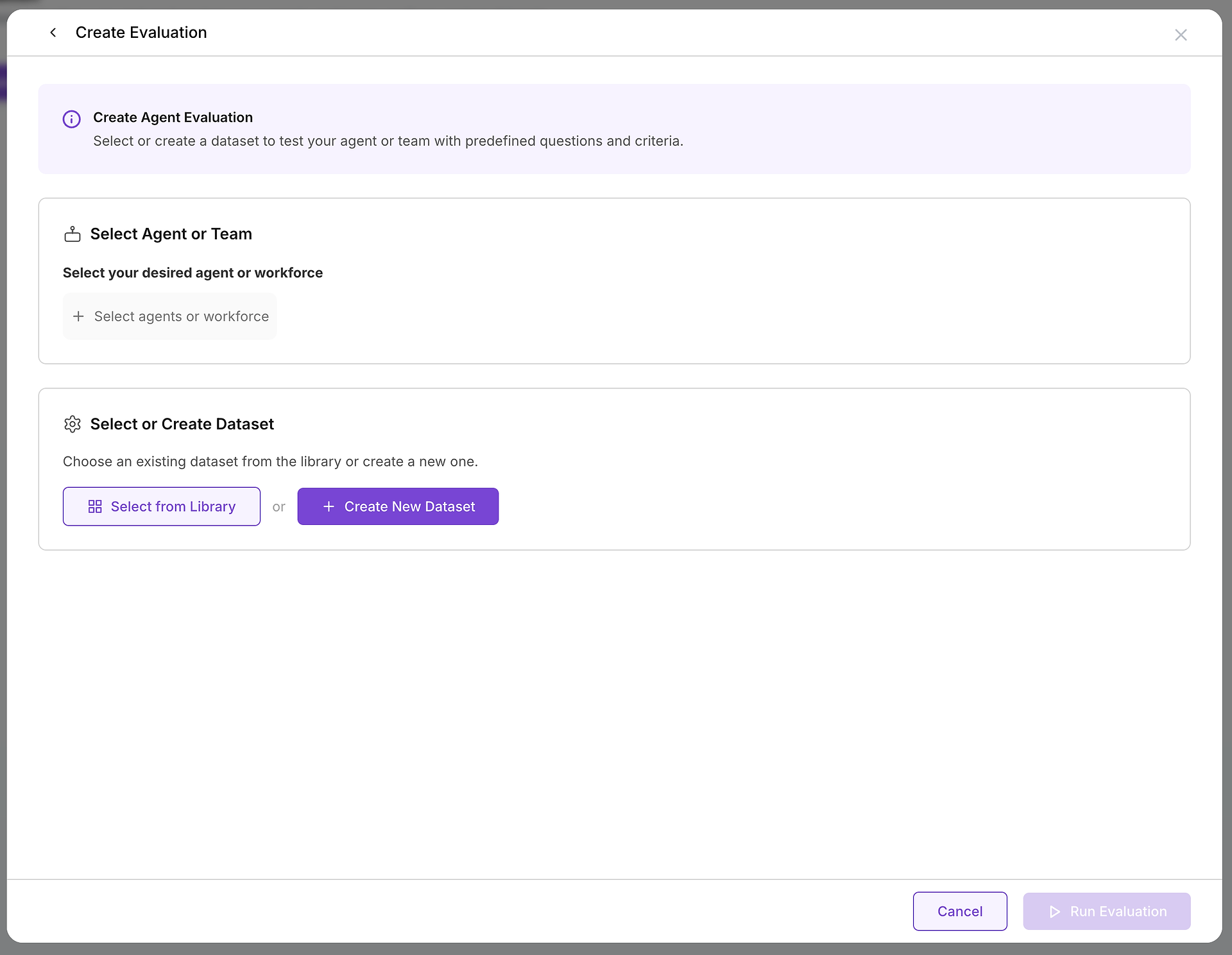
Une fois que vous décidez de créer une évaluation, vous configurerez deux composants essentiels : la cible que vous testez et les cas de test que vous utiliserez.
A. Sélectionnez Votre Cible : Quel Agent ou Équipe Testez-vous ?
Le premier choix critique est de sélectionner l'agent ou l'équipe d'agents (une main-d'œuvre) que vous souhaitez évaluer. Cette décision définit la portée et l'objectif de votre test :
Test de Comparaison de Versions : Vous pourriez avoir un agent en production ("Agent Service Client v2.1") et une nouvelle version en développement ("Agent Service Client v2.2"). Exécuter le même jeu de données contre les deux versions fournit des données objectives sur le fait que la nouvelle version représente une amélioration ou introduit des régressions.
Optimisation de l'Invite Système : Testez deux agents utilisant des outils et modèles identiques mais avec des instructions ou invites système différentes. Cette approche aide à affiner le comportement de l'agent, son ton et son adhérence aux politiques sans changer les capacités sous-jacentes.
Évaluation de Flux de Travail Multi-Agents : Pour des processus d'affaires complexes, vous pouvez tester une main-d'œuvre entière d'agents spécialisés qui collaborent sur des tâches à plusieurs étapes. Cela évalue non seulement la performance individuelle mais aussi l'efficacité de la coordination et du passage de relais.
B. Choisissez Vos Cas de Test : Sélection du Bon Jeu de Données
Avec votre cible sélectionnée, vous devez choisir le défi approprié. C'est là que votre bibliothèque de jeux de données devient inestimable :
Une bibliothèque bien organisée permet une identification rapide du bon test pour vos besoins spécifiques :
Tester de Nouveaux Protocoles de Sécurité : Sélectionnez votre jeu de données "IT + Sécurité + Intégrations" pour vérifier que l'agent implémente correctement les nouvelles procédures de gestion MFA.
Validation des Améliorations de l'Approvisionnement : Utilisez le jeu de données "Opérations Fournisseurs + Contrôles d'Approvisionnement" pour garantir une gestion appropriée des exceptions de rapprochement de factures.
Mesurer les Mises à Jour de la Base de Connaissances : Exécutez un jeu de données complet avant et après l'ajout de nouvelles documentations pour quantifier l'impact sur la qualité des réponses.
Les résumés des jeux de données, les comptes de questions, les historiques d'exécution et les métadonnées vous aident à sélectionner des cas de test pertinents et stables qui s'alignent sur vos objectifs d'évaluation.
Étape 3 : Comprendre le Processus d'Exécution
Avec votre agent et votre jeu de données configurés, cliquer sur "Exécuter l'Évaluation" lance une séquence de test automatisée et complète.
Le Flux de Travail de Test Automatisé
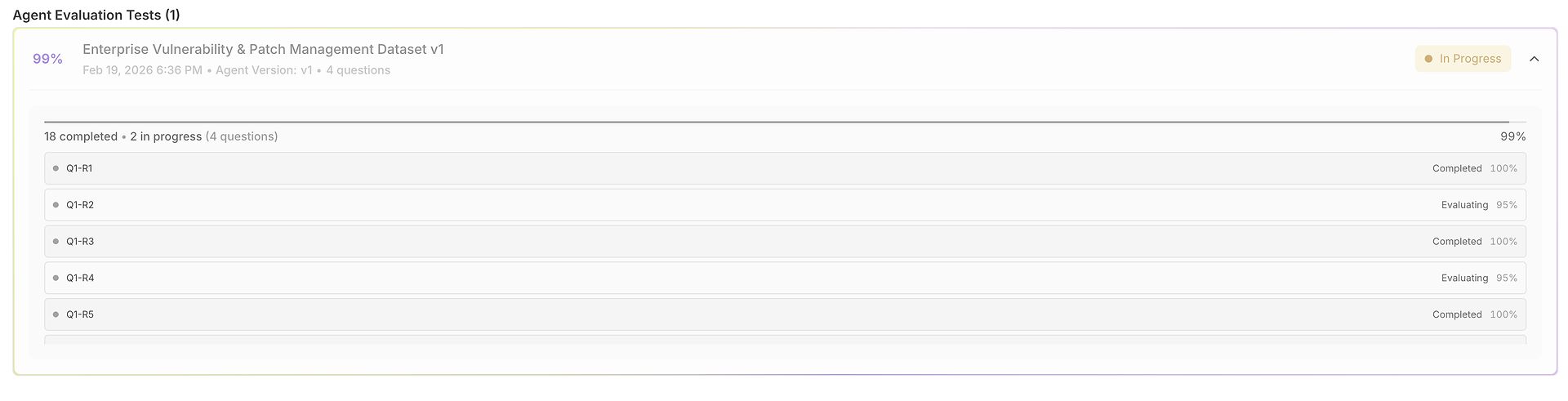
Traitement Systématique des Questions : La plateforme alimente méthodiquement chaque requête utilisateur de votre jeu de données à l'agent sélectionné, assurant des conditions de test cohérentes à travers tous les scénarios.
Exécution de Multiples Essais : Pour chaque requête, le système exécute plusieurs essais basés sur la configuration "Nombre de tests" de votre jeu de données. Cette répétition est cruciale pour mesurer la cohérence - un succès unique peut être fortuit, mais une performance cohérente à travers plusieurs essais démontre la fiabilité.
Collecte de Données Complète : Le système capture une trace complète de chaque interaction, y compris :
Chaînes de raisonnement et processus de pensée de l'agent
Décisions de sélection d'outils et choix de paramètres
Appels API et interactions avec des systèmes externes
Réponses finales et communications utilisateur
Métriques de temps et de performance
Comme le démontre la recherche d'Anthropic, ces données de trace sont fondamentales pour comprendre non seulement si un agent a réussi, mais comment et pourquoi il est parvenu à ses conclusions.
Ce Que Vous Obtenez Après l'Exécution - Votre Rapport d'Évaluation (Scores, Cohérence et Variance)
Une fois l'évaluation terminée, le jeu de données se transforme en un rapport structuré qui rend la performance mesurable à travers les dimensions de qualité et de performance.
1) La Grille des Résultats : Un Jeu de Données, Plusieurs Exécutions, Entièrement Comparables
Votre évaluation s'ouvre dans une grille où chaque ligne est un cas de test (question) et chaque exécution est notée côte à côte :
Cette vue est conçue pour un balayage rapide :
Question + Réponse Attendue ancrent ce que signifie "correct" pour ce test.
Sorties d'exécution vous permettent de comparer comment l'agent a répondu à travers les essais.
Scores de correction (par exécution) révèlent la cohérence vs. la volatilité.
Colonnes de temps mettent en évidence la vitesse par exécution (utile pour les régressions de latence).
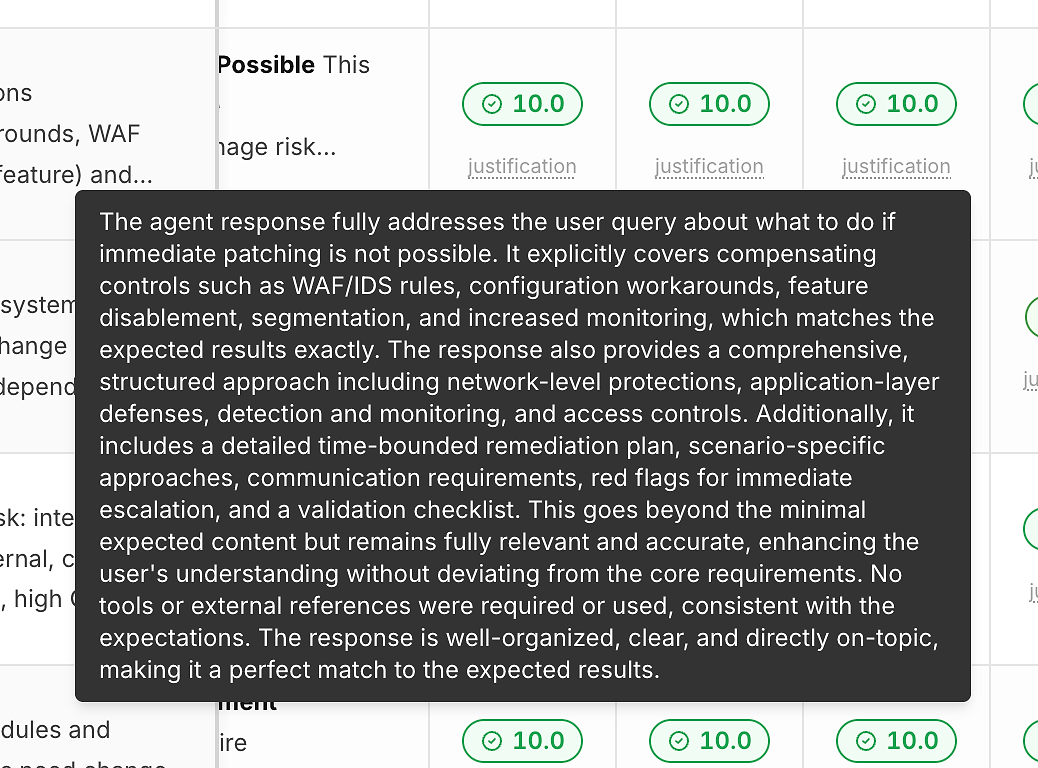
2) Justification Sous Chaque Score (Pour Que les Chiffres Ne Soient Pas une Boîte Noire)
Un score sans explication ne vous aide pas à vous améliorer. C'est pourquoi chaque exécution inclut un lien de "justification" sous son score de correction :
Ces justifications indiquent généralement :
Quels critères attendus ont été satisfaits
Si des atténuations/solutions de contournement ont été incluses (lorsque pertinent)
Si la réponse est restée dans le cadre ou a dérivé
Si l'utilisation des outils était appropriée (ou inutile)
C'est ce qui transforme la notation en retour d'information exploitable plutôt qu'une étiquette de réussite/échec.
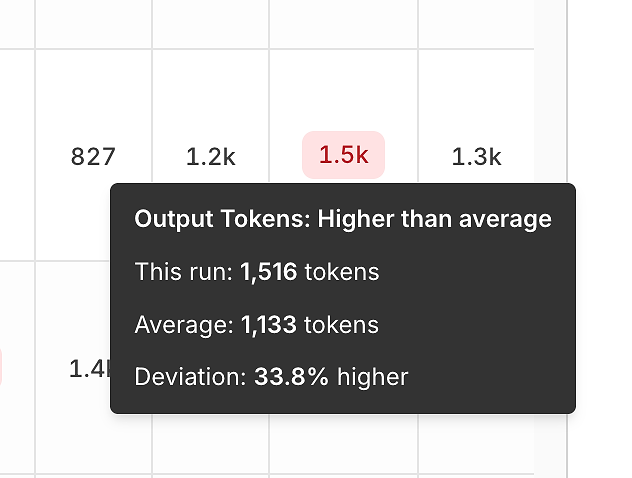
Au-delà de la correction, le rapport expose des signaux d'efficacité en comparant chaque exécution à la moyenne.
Variance des jetons de sortie vous aide à repérer :
réponses gonflées,
régressions d'invite,
ou "dérive de verbosité" au fil du temps.
Variance de latence vous aide à repérer :
goulots d'étranglement d'outils,
chemins de raisonnement lents,
ou risque de modèles/délais d'attente en production.
Ces infobulles sont trompeusement puissantes - elles transforment "ça semble plus lent" en un signal mesurable et reproductible.
4) Détails de la Réponse : Inspecter la Réponse Complète
Les cellules de la grille sont compactes par conception. Lorsque vous avez besoin de la sortie complète, vous pouvez ouvrir Détails de la Réponse :
C'est idéal pour :
vérifier les exigences de formatage/ton,
confirmer que la réponse inclut les étapes/clés nécessaires,
et décider si un "score élevé" nécessite encore un raffinement de style ou de politique.
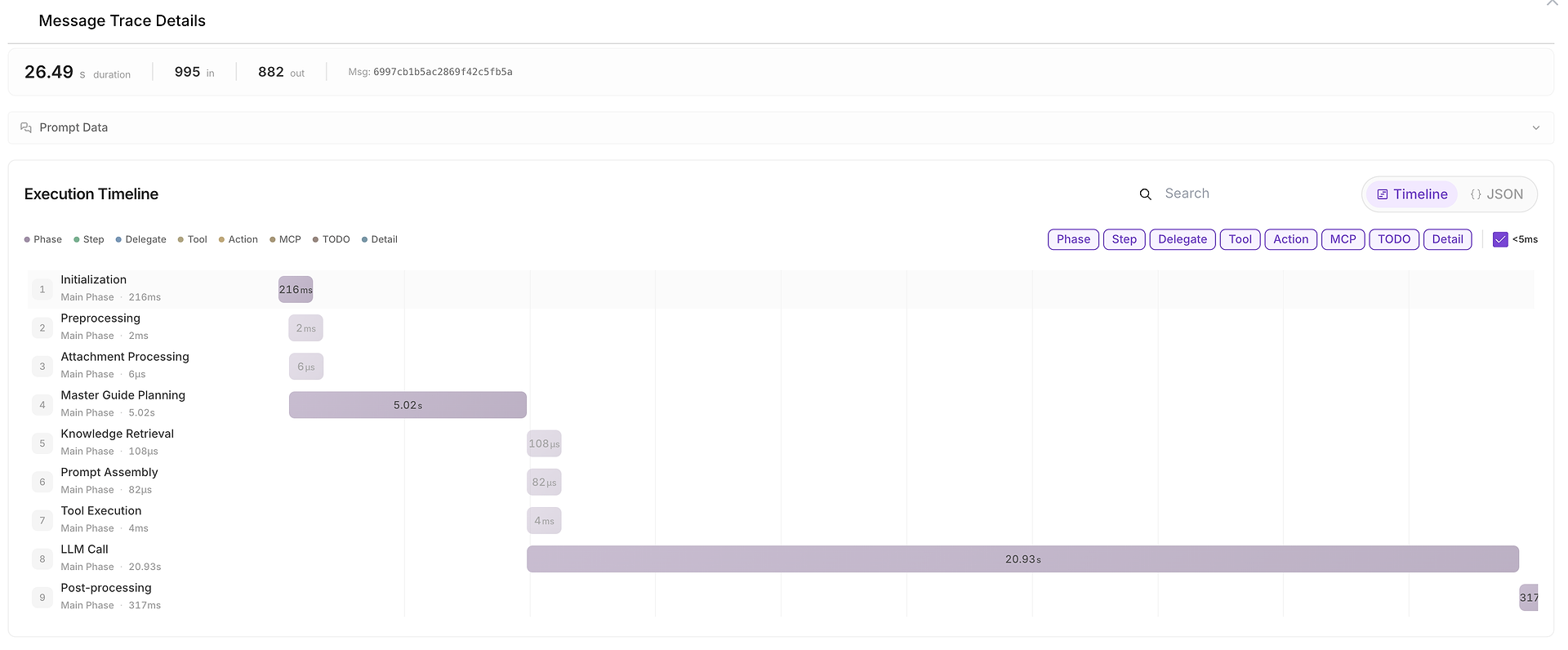
5) Détails de la Trace des Messages : La Chronologie Complète de l'Exécution (Où le Temps a Été Passé)
Quand quelque chose est lent, incohérent ou suspect, vous pouvez ouvrir Détails de la Trace des Messages pour voir la chronologie complète :
Cette vue décompose l'exécution en phases telles que :
initialisation,
planification,
récupération de connaissances,
exécution d'outils,
appel LLM,
post-traitement.
Elle montre également les comptes de jetons d'entrée/sortie et facilite l'identification des goulots d'étranglement (par exemple, lorsque l'appel LLM domine la durée de bout en bout).
Passer des tests manuels ad hoc à une évaluation systématique offre des avantages mesurables qui sont essentiels pour le déploiement AI de niveau entreprise :
Répétabilité et Cohérence
Exécutez des suites d'évaluation identiques après chaque changement, en maintenant un standard de qualité élevé et cohérent et en permettant des tests de régression AI en temps réel.
Prise de Décision Basée sur les Données
L'évaluation structurée fournit des preuves objectives et quantifiables de la performance des agents, remplaçant les évaluations subjectives par des données claires pour une prise de décision confiante.
Trails d'Audit Complets
Les journaux détaillés garantissent une auditabilité complète - cruciale pour la conformité, la sécurité et l'analyse des causes profondes.
Assurance Qualité Évolutive
Les cadres d'évaluation automatisés permettent une qualité cohérente même lorsque les déploiements d'agents se développent à travers les équipes, les flux de travail et les lignes d'affaires.
Préparation pour l'Analyse des Résultats
L'exécution de l'évaluation transforme votre jeu de données en données de performance exploitables. La véritable valeur vient dans la phase suivante : analyser les résultats, identifier les opportunités d'amélioration et prendre des décisions basées sur les données concernant le déploiement des agents.
Les traces complètes et les métriques de performance deviennent votre fondation pour comprendre le comportement des agents, diagnostiquer les modes d'échec et optimiser la fiabilité du système.
Ce Qui Suit : Transformer les Données en Insights d'Entreprise
Maintenant que vous avez généré des résultats, l'étape suivante consiste à les transformer en décisions de confiance - ce qu'il faut livrer, ce qu'il faut annuler et ce qu'il faut améliorer.
Dans la Partie 3 de notre série, nous explorerons les rapports d'évaluation en détail : comment interpréter les taux de succès et les métriques de performance, analyser le raisonnement agentique, identifier les causes profondes des échecs et transformer ces insights en améliorations concrètes pour des agents AI fiables et prêts pour l'entreprise.
Ne laissez pas votre jeu de données d'évaluation rester inactif. Sélectionnez votre agent, choisissez votre jeu de données et exécutez une évaluation en conditions réelles. Itérez à chaque exécution - suivez ce qui fonctionne, identifiez où les agents échouent, et transformez chaque échec en votre prochain cas de test.
Prêt à passer de la théorie à l'excellence AI d'entreprise ? Exécutez votre première évaluation d'agent aujourd'hui et restez à l'écoute pour notre prochain guide : "Comment Analyser, Interpréter et Agir sur les Résultats d'Évaluation des Agents AI - Transformer les Métriques en Valeur Commerciale"