Langkah 1: Memulai Perjalanan Evaluasi Anda
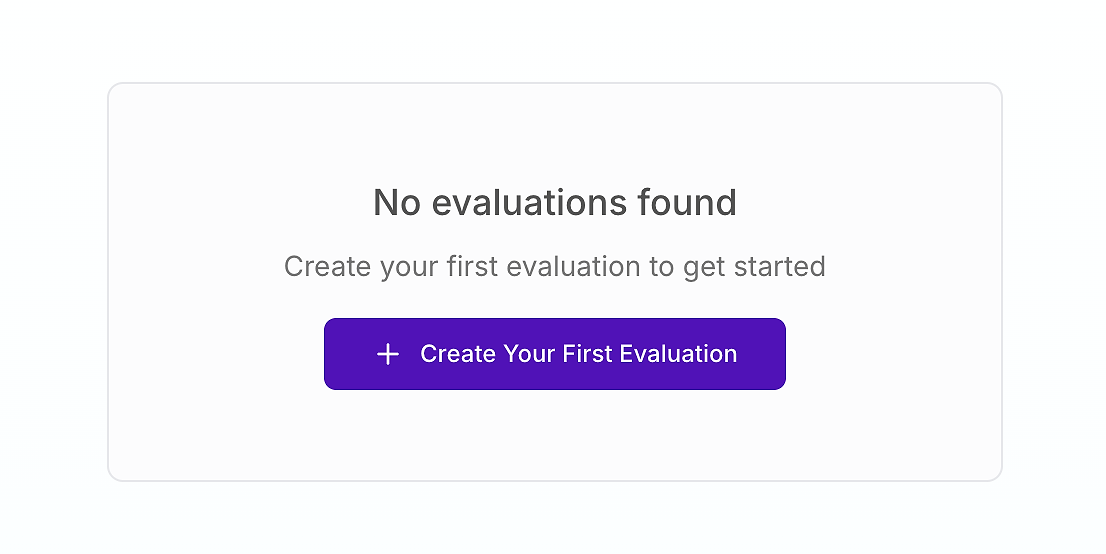
Bagi tim yang serius tentang kualitas AI, dasbor evaluasi adalah pusat komando untuk jaminan kualitas. Jika Anda baru memulai, mungkin terlihat seperti ini:
Ini adalah garis awal Anda. Membuat evaluasi pertama Anda adalah langkah penting menuju menggantikan pengujian "rasa intuisi" subjektif dengan proses ilmiah yang terstruktur. Seperti yang ditekankan oleh para ahli dari AWS, kerangka evaluasi holistik sangat penting untuk mengatasi kompleksitas sistem AI agen dalam lingkungan produksi.
Membangun budaya evaluasi berkelanjutan sangat penting untuk menerapkan agen yang tidak hanya kuat, tetapi juga dapat dipercaya dan andal dalam skenario bisnis yang kritis.
Langkah 2: Menyiapkan Konfigurasi Evaluasi Anda
Jika Anda belum membuat dataset evaluasi pertama Anda, kembali ke Bagian 1 - Membangun Dataset Evaluasi Tingkat Perusahaan: Dasar dari Agen AI yang Andal untuk panduan langkah demi langkah membangun dataset evaluasi tingkat perusahaan dengan kasus uji yang realistis, kriteria penilaian yang jelas, dan cakupan untuk kasus tepi - sehingga evaluasi agen AI Anda menghasilkan hasil yang andal dan dapat diulang yang dapat Anda percayai
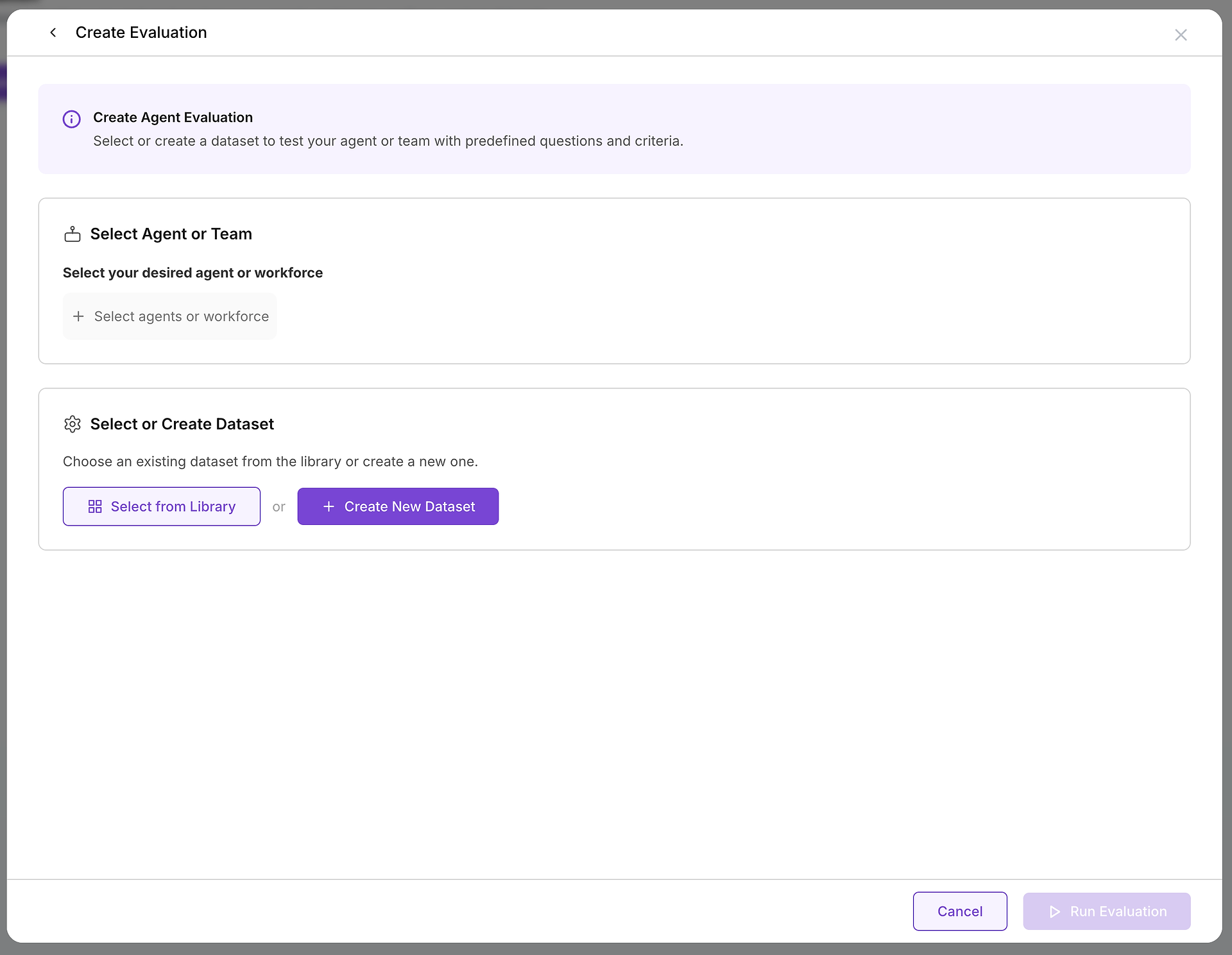
Setelah Anda memutuskan untuk membuat evaluasi, Anda akan mengonfigurasi dua komponen penting: target yang Anda uji dan kasus uji yang akan Anda gunakan.
A. Pilih Target Anda: Agen atau Tim Mana yang Anda Uji?
Pilihan penting pertama adalah memilih agen atau tim agen (sebuah tenaga kerja) yang ingin Anda evaluasi. Keputusan ini menentukan ruang lingkup dan tujuan pengujian Anda:
Pengujian Perbandingan Versi: Anda mungkin memiliki agen dalam produksi ("Customer Service Agent v2.1") dan versi baru dalam pengembangan ("Customer Service Agent v2.2"). Menjalankan dataset yang sama terhadap kedua versi memberikan data objektif tentang apakah versi baru mewakili peningkatan atau memperkenalkan regresi.
Optimasi Prompt Sistem: Uji dua agen menggunakan alat dan model yang identik tetapi dengan instruksi atau prompt sistem yang berbeda. Pendekatan ini membantu menyempurnakan perilaku agen, nada, dan kepatuhan kebijakan tanpa mengubah kemampuan dasar.
Evaluasi Alur Kerja Multi-Agen: Untuk proses bisnis yang kompleks, Anda dapat menguji seluruh tenaga kerja agen khusus yang berkolaborasi dalam tugas multi-langkah. Ini mengevaluasi tidak hanya kinerja individu tetapi juga efektivitas koordinasi dan penyerahan.
B. Pilih Kasus Uji Anda: Memilih Dataset yang Tepat
Dengan target Anda dipilih, Anda perlu memilih tantangan yang sesuai. Di sinilah perpustakaan dataset Anda menjadi sangat berharga:
Perpustakaan yang terorganisir dengan baik memungkinkan identifikasi cepat dari tes yang tepat untuk kebutuhan spesifik Anda:
Menguji Protokol Keamanan Baru: Pilih dataset "IT + Security + Integrations" Anda untuk memverifikasi agen menerapkan prosedur penanganan MFA baru dengan benar.
Memvalidasi Peningkatan Pengadaan: Gunakan dataset "Supplier Ops + Procurement Controls" untuk memastikan penanganan pengecualian pencocokan faktur yang tepat.
Mengukur Pembaruan Basis Pengetahuan: Jalankan dataset komprehensif sebelum dan setelah menambahkan dokumentasi baru untuk mengukur dampaknya pada kualitas respons.
Ringkasan dataset, jumlah pertanyaan, riwayat run, dan metadata membantu Anda memilih kasus uji yang relevan dan stabil yang sesuai dengan tujuan evaluasi Anda.
Langkah 3: Memahami Proses Eksekusi
Dengan agen dan dataset Anda dikonfigurasi, mengklik "Run Evaluation" memulai urutan pengujian otomatis dan komprehensif.
Alur Kerja Pengujian Otomatis
Pemrosesan Pertanyaan Sistematis: Platform secara metodis memasukkan setiap kueri pengguna dari dataset Anda ke agen yang dipilih, memastikan kondisi pengujian yang konsisten di semua skenario.
Eksekusi Uji Coba Ganda: Untuk setiap kueri, sistem menjalankan beberapa uji coba berdasarkan konfigurasi "Jumlah uji coba" dataset Anda. Pengulangan ini penting untuk mengukur konsistensi—kesuksesan tunggal mungkin kebetulan, tetapi kinerja konsisten di beberapa uji coba menunjukkan keandalan.
Pengumpulan Data Komprehensif: Sistem menangkap jejak lengkap dari setiap interaksi, termasuk:
Rantai penalaran agen dan proses berpikir
Keputusan pemilihan alat dan pilihan parameter
Panggilan API dan interaksi sistem eksternal
Respons akhir dan komunikasi pengguna
Seperti yang ditunjukkan oleh penelitian Anthropic, data jejak ini penting untuk memahami tidak hanya apakah agen berhasil, tetapi juga bagaimana dan mengapa ia mencapai kesimpulannya.
Apa yang Anda Dapatkan Setelah Run - Laporan Evaluasi Anda (Skor, Konsistensi, dan Varians)
Setelah evaluasi selesai, dataset berubah menjadi laporan terstruktur yang membuat kinerja dapat diukur di seluruh dimensi kualitas dan kinerja.
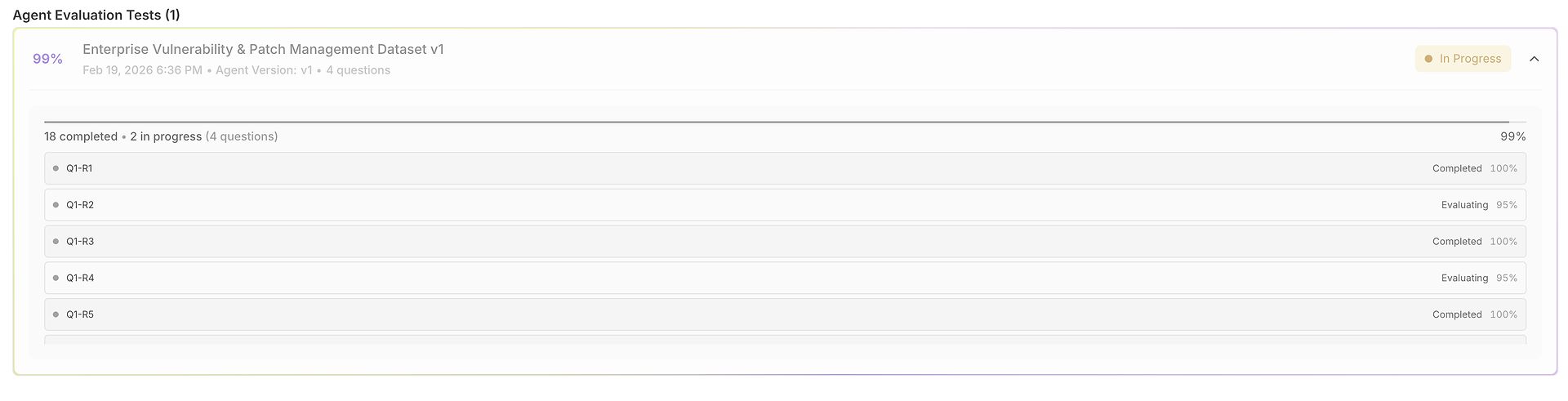
1) Grid Hasil: Satu Dataset, Banyak Run, Sepenuhnya Dapat Dibandingkan
Evaluasi Anda terbuka ke dalam grid di mana setiap baris adalah kasus uji (pertanyaan) dan setiap run dinilai berdampingan:
Tampilan ini dirancang untuk pemindaian cepat:
Pertanyaan + Respons yang Diharapkan menambatkan apa yang dimaksud dengan "benar" untuk tes tersebut.
Output run memungkinkan Anda membandingkan bagaimana agen menjawab di berbagai uji coba.
Skor kebenaran (per run) mengungkapkan konsistensi vs. volatilitas.
Kolom waktu menyoroti kecepatan per run (berguna untuk regresi latensi).
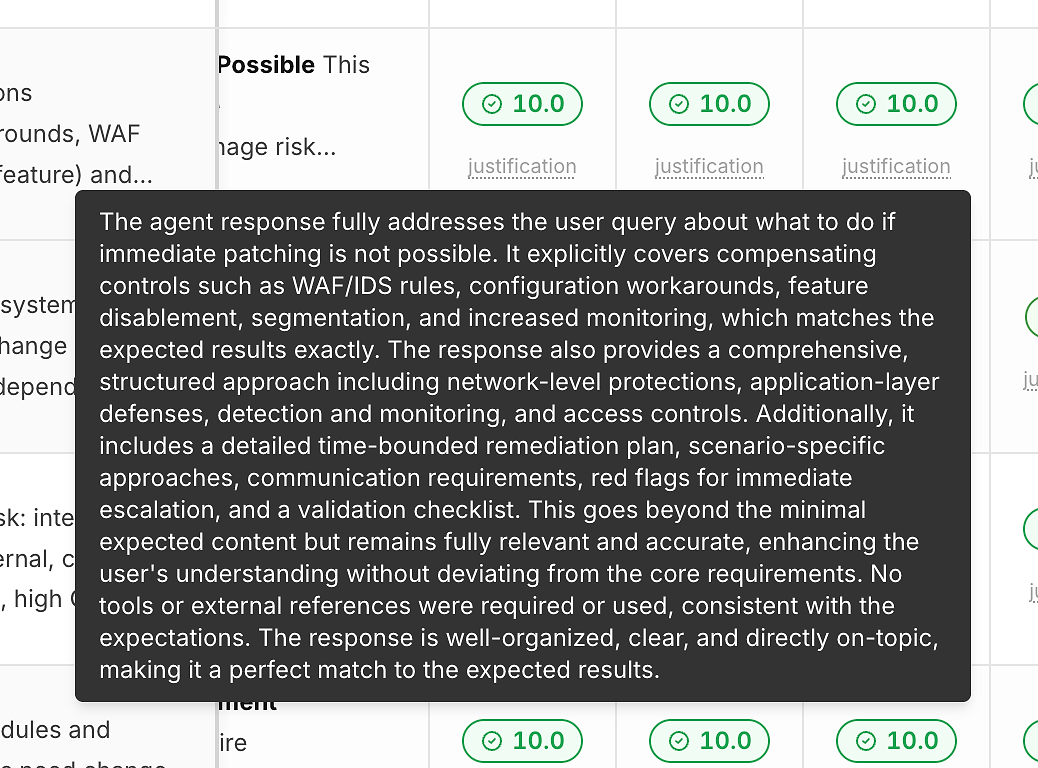
2) Justifikasi di Bawah Setiap Skor (Jadi Angka Bukan Kotak Hitam)
Skor tanpa penjelasan tidak membantu Anda meningkatkan. Itulah mengapa setiap run menyertakan tautan "justifikasi" di bawah skor kebenarannya:
Justifikasi ini biasanya menunjukkan:
Kriteria yang diharapkan mana yang terpenuhi
Apakah mitigasi/solusi sementara disertakan (jika relevan)
Apakah jawaban tetap sesuai atau menyimpang
Apakah penggunaan alat sesuai (atau tidak perlu)
Ini adalah apa yang mengubah penilaian menjadi umpan balik yang dapat ditindaklanjuti daripada label lulus/gagal.
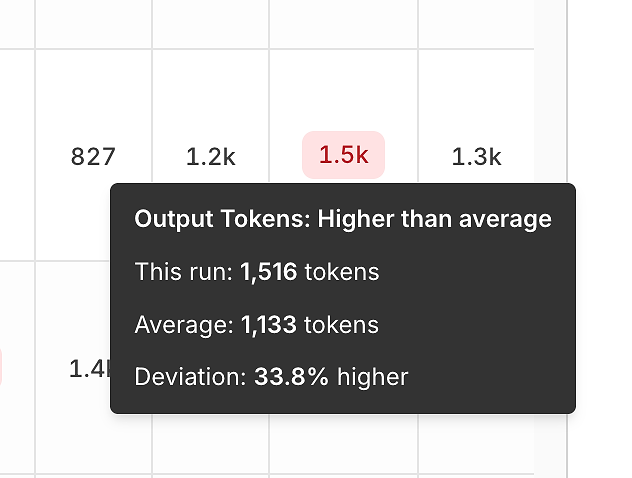
3) Varians Kinerja: Token dan Latensi Dibandingkan dengan Rata-rata
Selain kebenaran, laporan mengungkapkan sinyal efisiensi dengan membandingkan setiap run dengan rata-rata.
Varians token output membantu Anda mengidentifikasi:
jawaban yang berlebihan,
regresi prompt,
atau "pergeseran verbosity" dari waktu ke waktu.
Varians latensi membantu Anda mengidentifikasi:
bottleneck alat,
jalur penalaran yang lambat,
atau risiko model/timeouts dalam produksi.
Tooltip ini tampak kuat - mereka mengubah "terasa lebih lambat" menjadi sinyal yang dapat diukur dan diulang.
4) Detail Respons: Periksa Jawaban Lengkap
Sel grid dirancang kompak. Ketika Anda membutuhkan output lengkap, Anda dapat membuka Detail Respons:
Ini ideal untuk:
memverifikasi persyaratan format/nada,
memastikan jawaban mencakup langkah-langkah/kontrol utama,
dan memutuskan apakah "skor tinggi" masih membutuhkan penyempurnaan gaya atau kebijakan.
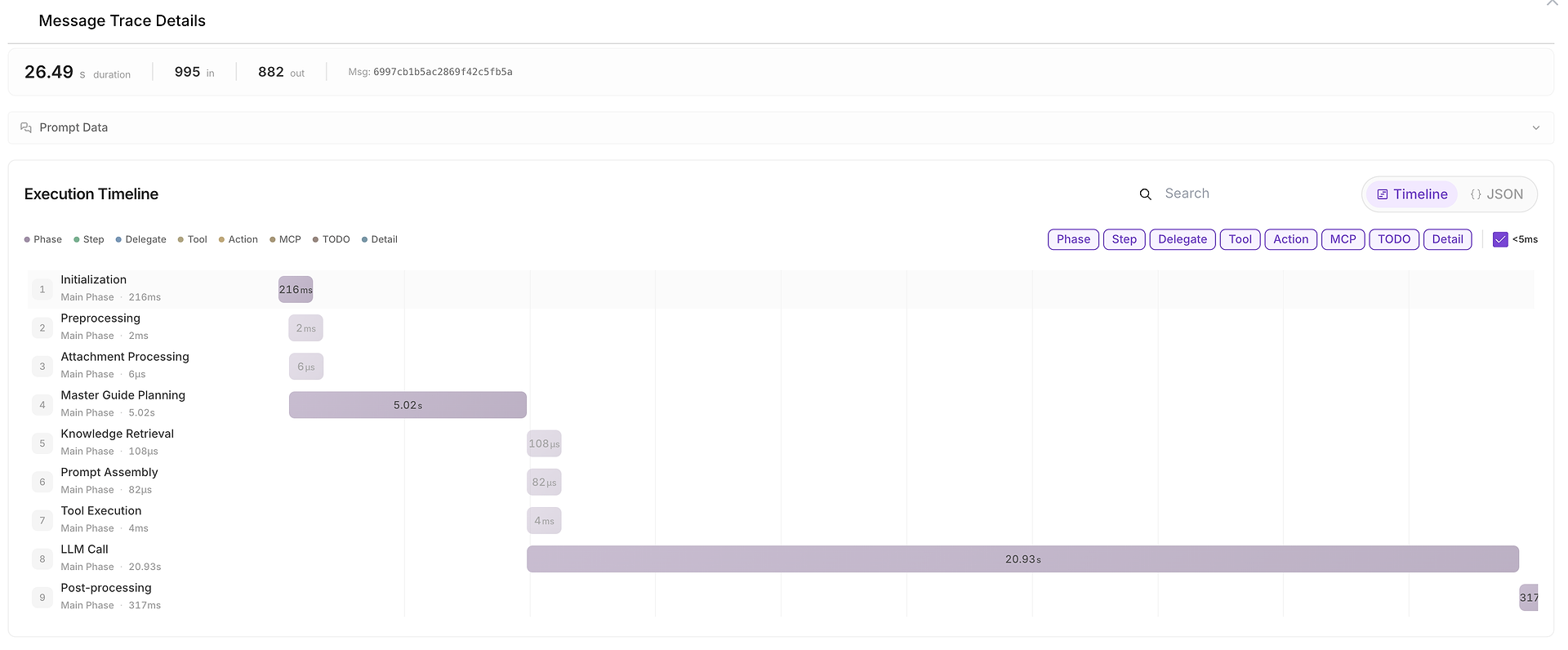
5) Detail Jejak Pesan: Garis Waktu Eksekusi Lengkap (Di Mana Waktu Diambil)
Ketika sesuatu lambat, tidak konsisten, atau mencurigakan, Anda dapat membuka Detail Jejak Pesan untuk melihat garis waktu lengkap:
Tampilan ini memecah run menjadi fase seperti:
inisialisasi,
perencanaan,
pengambilan pengetahuan,
eksekusi alat,
panggilan LLM,
pasca-pemrosesan.
Ini juga menunjukkan jumlah token input/output dan memudahkan untuk mengidentifikasi bottleneck (misalnya, ketika panggilan LLM mendominasi durasi end-to-end).
Mengapa Pendekatan Terstruktur Ini Mengubah Kualitas AI Perusahaan
Berpindah dari pengujian manual ad-hoc ke evaluasi sistematis memberikan manfaat yang dapat diukur yang penting untuk penerapan AI tingkat perusahaan:
Repeatability dan Konsistensi
Jalankan suite evaluasi identik setelah setiap perubahan, mempertahankan standar kualitas tinggi dan konsisten dan memungkinkan pengujian regresi AI secara real-time.
Pembuatan Keputusan Berbasis Data
Evaluasi terstruktur memberikan bukti kinerja agen yang objektif dan dapat diukur, menggantikan penilaian subjektif dengan data yang jelas untuk pembuatan keputusan yang percaya diri.
Jejak Audit Lengkap
Log yang terperinci memastikan auditabilitas yang komprehensif—penting untuk kepatuhan, keamanan, dan analisis akar penyebab.
Jaminan Kualitas yang Dapat Diskalakan
Kerangka evaluasi otomatis memungkinkan kualitas yang konsisten bahkan ketika penerapan agen meningkat di seluruh tim, alur kerja, dan lini bisnis.
Mempersiapkan Analisis Hasil
Menjalankan evaluasi mengubah dataset Anda menjadi data kinerja yang dapat ditindaklanjuti. Nilai sebenarnya datang pada fase berikutnya: menganalisis hasil, mengidentifikasi peluang untuk perbaikan, dan membuat keputusan berbasis data tentang penerapan agen.
Jejak dan metrik kinerja yang komprehensif menjadi dasar Anda untuk memahami perilaku agen, mendiagnosis mode kegagalan, dan mengoptimalkan keandalan sistem.
Apa Selanjutnya: Mengubah Data Menjadi Wawasan Perusahaan
Sekarang setelah Anda menghasilkan hasil, langkah selanjutnya adalah mengubahnya menjadi keputusan yang dapat Anda percayai - apa yang akan dikirim, apa yang akan dibatalkan, dan apa yang akan ditingkatkan.
Dalam Bagian 3 dari seri kami, kami akan mengeksplorasi laporan evaluasi secara detail: bagaimana menafsirkan tingkat keberhasilan dan metrik kinerja, menganalisis penalaran agen, mengidentifikasi akar penyebab kegagalan, dan mengubah wawasan ini menjadi perbaikan konkret untuk agen AI yang dapat dipercaya dan siap untuk perusahaan.
Jangan biarkan dataset evaluasi Anda menganggur. Pilih agen Anda, pilih dataset Anda, dan jalankan evaluasi dunia nyata. Iterasi dengan setiap run - lacak apa yang berhasil, identifikasi di mana agen tergelincir, dan ubah setiap kegagalan menjadi kasus uji berikutnya.
Siap untuk beralih dari teori ke keunggulan AI perusahaan? Jalankan evaluasi agen pertama Anda hari ini, dan tetap disini untuk panduan kami berikutnya: "Cara Menganalisis, Menafsirkan, dan Bertindak Berdasarkan Hasil Evaluasi Agen AI - Mengubah Metrik Menjadi Nilai Bisnis"