Passo 1: Iniziare il Tuo Viaggio di Valutazione
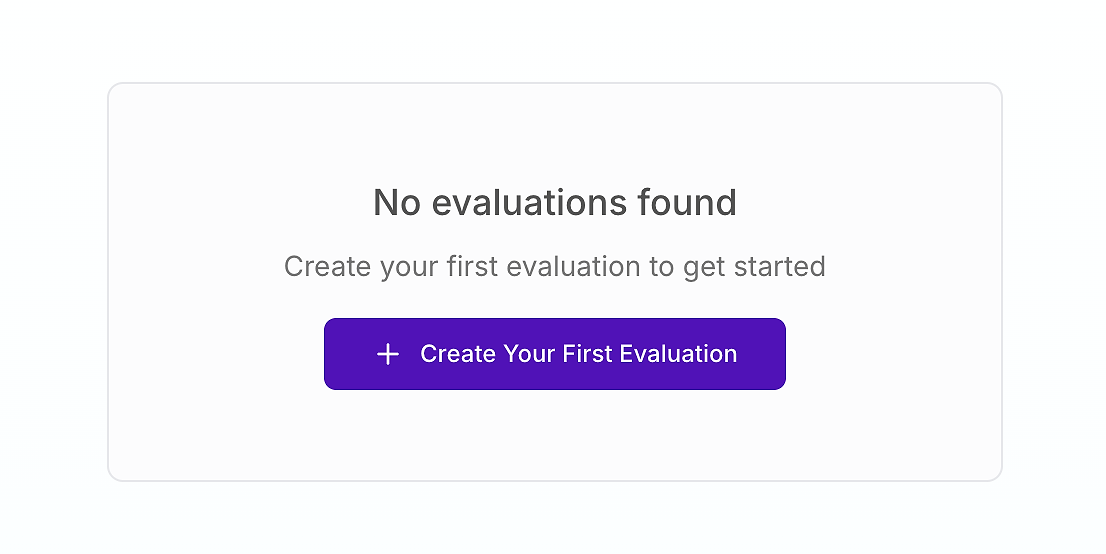
Per qualsiasi team serio sulla qualità dell'AI, il cruscotto di valutazione è il centro di comando per l'assicurazione della qualità. Se stai iniziando, potrebbe apparire qualcosa del genere:
Questa è la tua linea di partenza. Creare la tua prima valutazione è il passo cruciale verso la sostituzione dei test soggettivi "a sensazione" con un processo strutturato e scientifico. Come sottolineano gli esperti di AWS, un quadro di valutazione olistico è essenziale per affrontare la complessità dei sistemi AI agentici negli ambienti di produzione.
Stabilire una cultura di valutazione continua è fondamentale per distribuire agenti che non siano solo potenti, ma anche affidabili e sicuri in scenari critici per il business.
Passo 2: Configurare la Tua Valutazione
Se non hai ancora creato il tuo primo dataset di valutazione, torna a Parte 1 - Costruire Dataset di Valutazione di Livello Aziendale: La Fondazione di Agenti AI Affidabili per una guida passo-passo alla costruzione di dataset di valutazione di livello aziendale con casi di test realistici, criteri di punteggio chiari e copertura per casi limite - in modo che le tue valutazioni degli agenti AI producano risultati affidabili e ripetibili di cui ti puoi fidare.
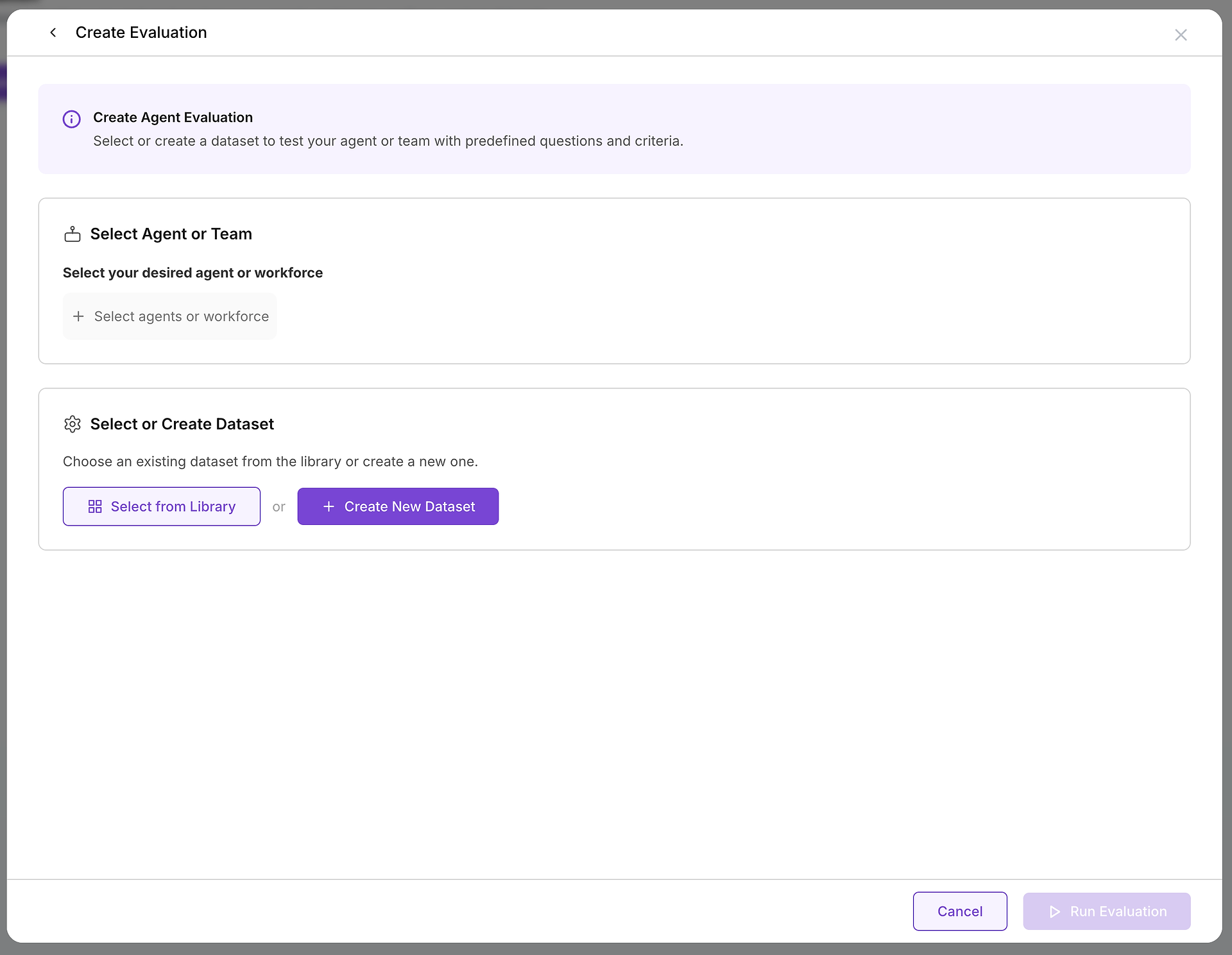
Una volta deciso di creare una valutazione, configurerai due componenti essenziali: l'obiettivo che stai testando e i casi di test che utilizzerai.
A. Seleziona il Tuo Obiettivo: Quale Agente o Team Stai Testando?
La prima scelta critica è selezionare l'agente o il team di agenti (una forza lavoro) che vuoi valutare. Questa decisione definisce l'ambito e lo scopo del tuo test:
Test di Confronto tra Versioni: Potresti avere un agente in produzione ("Agente Servizio Clienti v2.1") e una nuova versione in sviluppo ("Agente Servizio Clienti v2.2"). Eseguire lo stesso dataset su entrambe le versioni fornisce dati oggettivi su se la nuova versione rappresenta un miglioramento o introduce regressioni.
Ottimizzazione del Prompt di Sistema: Testa due agenti utilizzando strumenti e modelli identici ma con istruzioni o prompt di sistema diversi. Questo approccio aiuta a perfezionare il comportamento dell'agente, il tono e l'aderenza alle politiche senza cambiare le capacità sottostanti.
Valutazione del Flusso di Lavoro Multi-Agente: Per processi aziendali complessi, potresti testare un'intera forza lavoro di agenti specializzati che collaborano su compiti a più fasi. Questo valuta non solo le prestazioni individuali ma anche l'efficacia del coordinamento e del passaggio.
B. Scegli i Tuoi Casi di Test: Selezionare il Dataset Giusto
Con il tuo obiettivo selezionato, devi scegliere la sfida appropriata. È qui che la tua libreria di dataset diventa inestimabile:
Una libreria ben organizzata consente di identificare rapidamente il test giusto per le tue esigenze specifiche:
Testare Nuovi Protocolli di Sicurezza: Seleziona il tuo dataset "IT + Sicurezza + Integrazioni" per verificare che l'agente implementi correttamente le nuove procedure di gestione MFA.
Convalidare i Miglioramenti degli Acquisti: Usa il dataset "Operazioni Fornitori + Controlli Acquisti" per garantire la corretta gestione delle eccezioni di abbinamento delle fatture.
Misurare gli Aggiornamenti della Base di Conoscenza: Esegui un dataset completo prima e dopo l'aggiunta di nuova documentazione per quantificare l'impatto sulla qualità delle risposte.
I riassunti dei dataset, i conteggi delle domande, le storie di esecuzione e i metadati ti aiutano a selezionare casi di test rilevanti e stabili che si allineano con i tuoi obiettivi di valutazione.
Passo 3: Comprendere il Processo di Esecuzione
Con il tuo agente e il dataset configurati, cliccare su "Esegui Valutazione" avvia una sequenza di test automatizzata e completa.
Il Flusso di Lavoro di Test Automatizzato
Elaborazione Sistemica delle Domande: La piattaforma alimenta metodicamente ogni query utente dal tuo dataset all'agente selezionato, garantendo condizioni di test coerenti in tutti gli scenari.
Esecuzione di Prove Multiple: Per ogni query, il sistema esegue più prove in base alla configurazione "Numero di esecuzioni di test" del tuo dataset. Questa ripetizione è cruciale per misurare la coerenza: un singolo successo potrebbe essere casuale, ma prestazioni coerenti su più esecuzioni dimostrano affidabilità.
Raccolta Dati Completa: Il sistema cattura una traccia completa di ogni interazione, inclusi:
Catene di ragionamento e processi di pensiero dell'agente
Decisioni di selezione degli strumenti e scelte dei parametri
Chiamate API e interazioni con sistemi esterni
Risposte finali e comunicazioni con l'utente
Metriche di tempo e prestazioni
Come dimostra la ricerca di Anthropic, questi dati di traccia sono fondamentali per comprendere non solo se un agente ha avuto successo, ma come e perché ha raggiunto le sue conclusioni.
Cosa Ottieni Dopo l'Esecuzione - Il Tuo Rapporto di Valutazione (Punteggi, Coerenza e Varianza)
Una volta completata la valutazione, il dataset si trasforma in un rapporto strutturato che rende misurabile la performance su dimensioni di qualità e prestazioni.
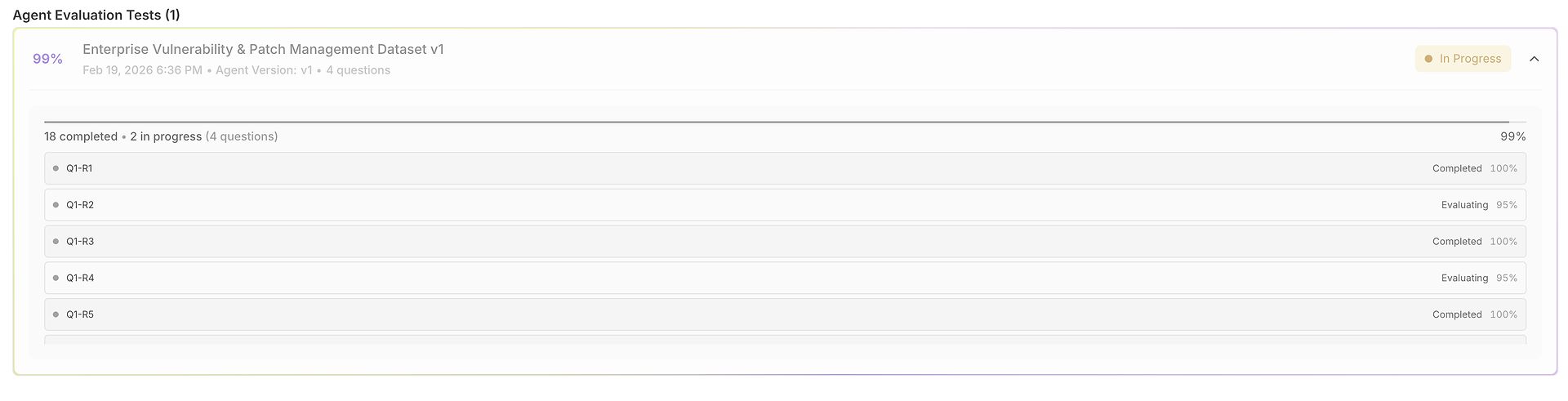
1) La Griglia dei Risultati: Un Dataset, Molte Esecuzioni, Completamente Confrontabili
La tua valutazione si apre in una griglia dove ogni riga è un caso di test (domanda) e ogni esecuzione è valutata fianco a fianco:
Questa vista è progettata per una rapida scansione:
Domanda + Risposta Attesa ancorano cosa significa "corretto" per quel test.
Output delle Esecuzioni ti permettono di confrontare come l'agente ha risposto nelle prove.
Punteggi di Correttezza (per esecuzione) rivelano coerenza vs. volatilità.
Colonne di Tempo evidenziano la velocità per esecuzione (utile per regressioni di latenza).
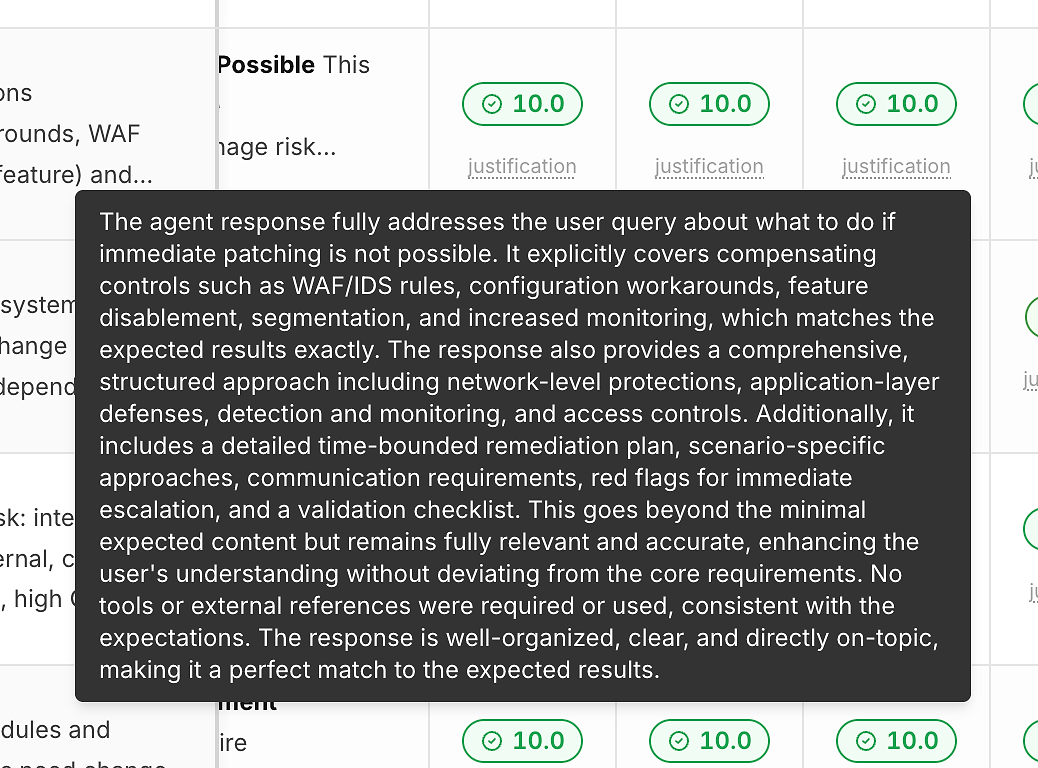
2) Giustificazione Sotto Ogni Punteggio (Così i Numeri Non Sono una Scatola Nera)
Un punteggio senza spiegazione non ti aiuta a migliorare. Ecco perché ogni esecuzione include un link di “giustificazione” sotto il suo punteggio di correttezza:
Queste giustificazioni tipicamente evidenziano:
Quali criteri attesi sono stati soddisfatti
Se sono state incluse mitigazioni/soluzioni alternative (quando rilevanti)
Se la risposta è rimasta nel campo vs. deragliamento
Se l'uso dello strumento era appropriato (o non necessario)
Questo è ciò che trasforma la valutazione in feedback attuabile piuttosto che un'etichetta di passaggio/fallimento.
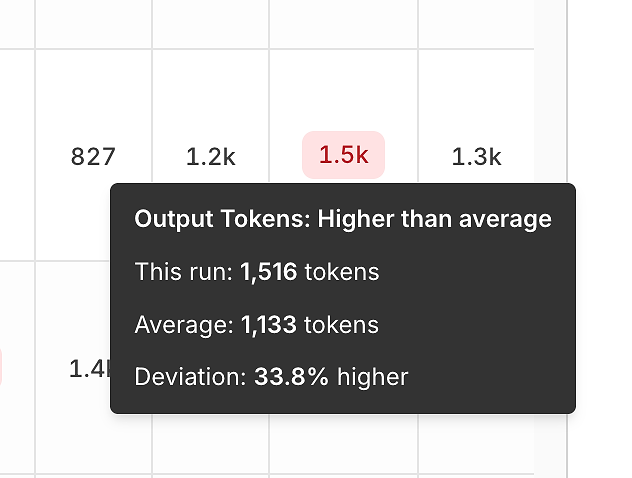
Oltre alla correttezza, il rapporto espone segnali di efficienza confrontando ogni esecuzione con la media.
Varianza dei token di output ti aiuta a individuare:
risposte gonfiate,
regressioni di prompt,
o "deriva di verbosità" nel tempo.
Varianza di latenza ti aiuta a individuare:
colli di bottiglia degli strumenti,
percorsi di ragionamento lenti,
o rischio di timeout del modello in produzione.
Questi tooltip sono ingannevolmente potenti - trasformano "sembra più lento" in un segnale misurabile e ripetibile.
4) Dettagli della Risposta: Ispeziona la Risposta Completa
Le celle della griglia sono compatte per design. Quando hai bisogno dell'output completo, puoi aprire Dettagli della Risposta:
Questo è ideale per:
verificare i requisiti di formattazione/tono,
confermare che la risposta includa passaggi/elenchi di controllo chiave,
e decidere se un "punteggio alto" necessita ancora di rifinitura di stile o politica.
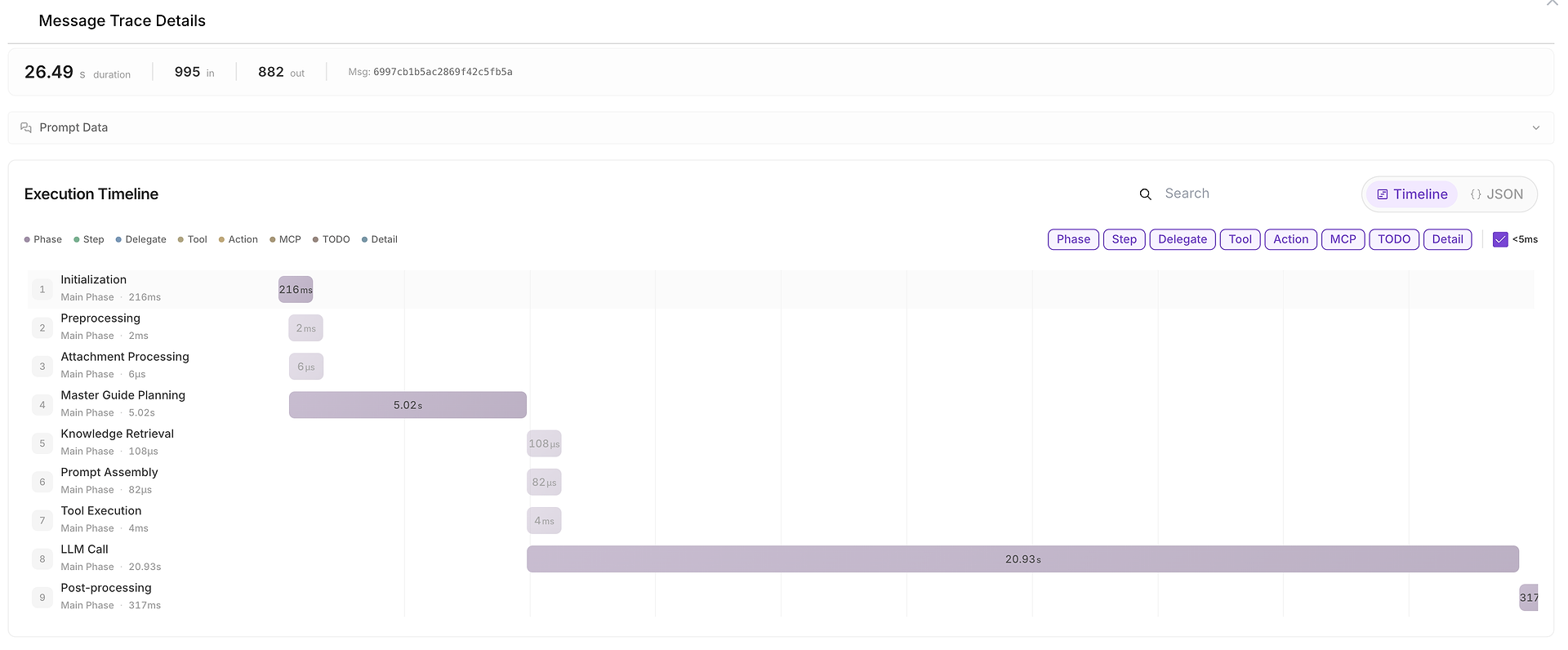
5) Dettagli della Traccia dei Messaggi: La Linea Temporale Completa dell'Esecuzione (Dove è Stato Speso il Tempo)
Quando qualcosa è lento, incoerente o sospetto, puoi aprire Dettagli della Traccia dei Messaggi per vedere la linea temporale completa:
Questa vista suddivide l'esecuzione in fasi come:
inizializzazione,
pianificazione,
recupero della conoscenza,
esecuzione degli strumenti,
chiamata LLM,
post-elaborazione.
Mostra anche conteggi dei token di input/output e rende facile identificare i colli di bottiglia (ad esempio, quando la chiamata LLM domina la durata end-to-end).
Passare da test manuali ad-hoc a valutazioni sistematiche fornisce benefici misurabili che sono essenziali per il deployment AI di livello aziendale:
Ripetibilità e Coerenza
Esegui suite di valutazione identiche dopo ogni cambiamento, mantenendo un alto standard di qualità coerente e abilitando test di regressione AI in tempo reale.
Decisioni Basate sui Dati
La valutazione strutturata fornisce prove oggettive e quantificabili delle prestazioni degli agenti, sostituendo le valutazioni soggettive con dati chiari per decisioni sicure.
Tracce di Audit Complete
Log dettagliati garantiscono un'auditabilità completa - cruciale per conformità, sicurezza e analisi delle cause principali.
Assicurazione della Qualità Scalabile
Framework di valutazione automatizzati consentono una qualità coerente anche quando le distribuzioni degli agenti si espandono tra team, flussi di lavoro e linee di business.
Prepararsi per l'Analisi dei Risultati
Eseguire la valutazione trasforma il tuo dataset in dati di performance attuabili. Il vero valore arriva nella fase successiva: analizzare i risultati, identificare le opportunità di miglioramento e prendere decisioni basate sui dati sul deployment degli agenti.
Le tracce complete e le metriche di prestazione diventano la tua base per comprendere il comportamento degli agenti, diagnosticare i modi di fallimento e ottimizzare l'affidabilità del sistema.
Cosa c'è Dopo: Trasformare i Dati in Intuizioni Aziendali
Ora che hai generato risultati, il passo successivo è trasformarli in decisioni di cui ti puoi fidare - cosa spedire, cosa ritirare e cosa migliorare.
Nella Parte 3 della nostra serie, esploreremo i rapporti di valutazione in dettaglio: come interpretare i tassi di successo e le metriche di prestazione, analizzare il ragionamento agentico, identificare le cause principali dei fallimenti e trasformare queste intuizioni in miglioramenti concreti per agenti AI affidabili e pronti per l'azienda.
Non lasciare che il tuo dataset di valutazione rimanga inattivo. Seleziona il tuo agente, scegli il tuo dataset e esegui una valutazione nel mondo reale. Itera con ogni esecuzione - traccia ciò che funziona, identifica dove gli agenti scivolano, e trasforma ogni fallimento nel tuo prossimo caso di test.
Pronto a passare dalla teoria all'eccellenza AI aziendale? Esegui oggi la tua prima valutazione dell'agente e resta sintonizzato per la nostra prossima guida: "Come Analizzare, Interpretare e Agire sui Risultati della Valutazione degli Agenti AI - Trasformare le Metriche in Valore Aziendale"