Valutazione degli agenti AIIntroduzione alle Agent Evaluations: il modo più affidabile per comprendere e migliorare i tuoi agenti AI
Gli agenti AI stanno diventando più avanzati, più capaci e sempre più integrati nei business.
Ma c’è un problema universale che ogni team deve affrontare:
Il tuo agente non risponde sempre come ti aspetti — e non sai perché.
A volte cambia il ragionamento, a volte l’agente ignora una regola, a volte lo strumento non è stato usato correttamente e a volte una sottile istruzione è stata fraintesa. Senza visibilità su come sono state prese le decisioni, migliorare l’agente sembra un tiro a indovinare.
È esattamente per questo che abbiamo creato Agent Evaluations — un nuovo sistema all’interno di AgentX che ti permette di testare, misurare e analizzare in profondità come si comporta il tuo agente su più esecuzioni della stessa domanda.
È la prima volta che puoi vedere dentro il processo decisionale del tuo agente, trovare incoerenze e capire con precisione dove sono necessari miglioramenti.
Perché le valutazioni contano
I modelli AI sono probabilistici.
Anche con lo stesso prompt, contesto e regole, il modello può:
produrre percorsi di ragionamento leggermente diversi
omettere un dettaglio richiesto
interpretare male una policy
saltare una consultazione di uno strumento
dare risposte incerte invece di quella definitiva attesa
delegare in modo incoerente all’interno di un team
Dall’esterno, vedi solo la risposta finale.
Non vedi:
se l’agente ha seguito le tue istruzioni
se ha usato gli strumenti giusti
se ha ragionato correttamente
perché una versione della risposta era più debole di un’altra
perché a volte fa le cose giuste — e a volte sbaglia
Le valutazioni risolvono questo problema fornendoti struttura, punteggi e trasparenza.
Come funziona un test
Creare una valutazione è semplice:
0. Seleziona l’agente o il team che vuoi valutare.
1. Domanda di test
Questa è la domanda reale che vuoi validare.
Simula una richiesta di un cliente o una richiesta di workflow interno.
Esempio:
“Posso restituire un articolo Final Sale se non mi va bene?”
Questo costituisce il nucleo della valutazione.
2. Risultati attesi (Obbligatorio)
Questa è la parte più importante della configurazione.
Qui definisci cosa l’agente DEVE dire o includere affinché la risposta sia considerata corretta.
Può contenere:
fatti chiave
frasi obbligatorie
passaggi di ragionamento richiesti
regole di compliance
tono specifico o dichiarazioni di policy
Esempio:
“Deve dire: No, gli articoli Final Sale non sono restituibili né sostituibili.”
I Risultati attesi diventano la rubrica di valutazione per tutte le esecuzioni del test.
3. Capacità attese (Opzionale ma potente)
Puoi indicare al sistema di valutazione quali strumenti, documenti o fonti di conoscenza l’agente dovrebbe usare.
Nel tuo esempio, hai selezionato:
Documents → store_policy_kb_v1.xlsx
Built-in Functions
Questo significa:
L’agente dovrebbe recuperare informazioni dalla policy KB.
Se non usa correttamente la KB, la valutazione lo rileverà.
Questo è perfetto per:
agenti di policy
agenti di customer service
workflow di compliance
modellazione finanziaria
ragionamento basato sui dati
4. Impostazioni di valutazione
Questa sezione definisce quanto rigorosa e quanto approfondita deve essere la tua valutazione.
Numero di esecuzioni del test
La stessa domanda viene eseguita più volte (Consigliato: 5 esecuzioni).
Perché?
Perché i modelli AI non sono deterministici. Esecuzioni multiple ti permettono di verificare:
coerenza
stabilità
affidabilità del ragionamento
se l’agente segue lo stesso processo ogni volta
Se l’agente produce una buona risposta e quattro fallimenti, lo vedrai subito.
Criteri di accettazione
Questo slider definisce quanto rigidamente la risposta deve corrispondere ai tuoi Risultati attesi.
Stai scegliendo un punto tra:
Lenient → l’agente può discostarsi dalle tue aspettative; la risposta non deve essere perfetta.
Exact → la risposta deve seguire le tue aspettative molto da vicino, con quasi nessuno spazio per variazioni.
Controlla semplicemente quanto esatta deve essere la risposta per superare la valutazione.
Criteri di rifiuto (Opzionale)
Regole per il fallimento automatico.
Esempi:
“La risposta non deve menzionare i competitor.”
“Non offrire rimborsi quando la policy lo vieta.”
“La risposta non deve chiedere all’utente di fornire informazioni personali.”
Questi sono vincoli rigidi.
Criteri di valutazione (Opzionale)
Linee guida aggiuntive per il punteggio, spesso usate per qualità o tono.
Esempi:
“La risposta dovrebbe essere cordiale e professionale.”
“La risposta deve contenere una breve spiegazione, non solo un sì/no.”
“Usa i fatti della KB prima delle supposizioni.”
Questi non sono requisiti rigidi, ma aiutano a orientare come l’AI assegna il punteggio all’agente.
5. Crea valutazione
Una volta configurata, facendo clic su Create Evaluation si avvia il processo:
la domanda viene eseguita più volte
ogni risposta viene valutata
viene generata un’analisi dettagliata
deleghe e uso degli strumenti vengono ispezionati
le incoerenze vengono messe in evidenza
E ricevi un report completo delle prestazioni.
Cosa ottieni dopo aver eseguito la valutazione
Dopo diverse esecuzioni, AgentX fornisce due livelli di output:
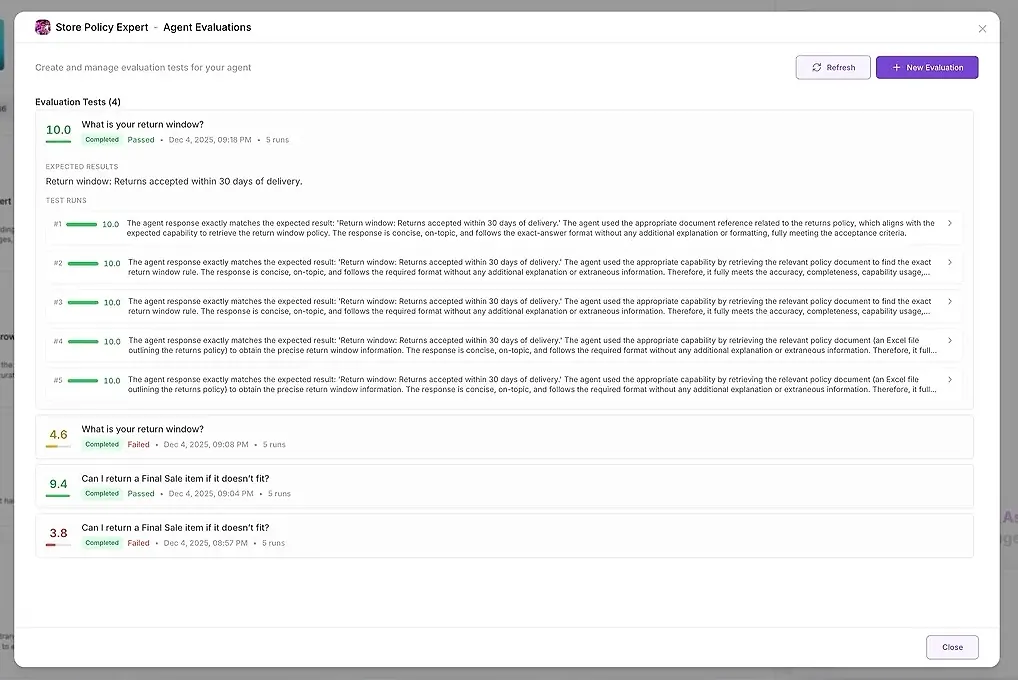
1. Risultati del test
Per ogni esecuzione, vedi:
un punteggio numerico
un riepilogo di quanto ha rispettato le tue aspettative
la risposta completa
quali strumenti sono stati usati
quali agenti hanno partecipato
dove l’agente ha fallito o si è discostato
Questo ti consente di confrontare le risposte affiancate e identificare pattern.
2. Analisi AI approfondita
È qui che avviene la vera magia.
AgentX analizza automaticamente tutte le esecuzioni e genera un report strutturato su più categorie:
• Aderenza alle istruzioni
L’agente ha seguito le tue regole?
• Pattern di risposta
Quanto erano simili o diverse le risposte?
Ci sono outlier?
• Analisi del ragionamento
I passaggi di ragionamento erano corretti, completi e allineati alle aspettative?
• Uso degli strumenti
L’agente ha usato lo strumento corretto?
Ha saltato una consultazione?
Si è basato su supposizioni invece che su fatti verificati?
• Raccomandazioni
Suggerimenti concreti e attuabili per migliorare il tuo agente.
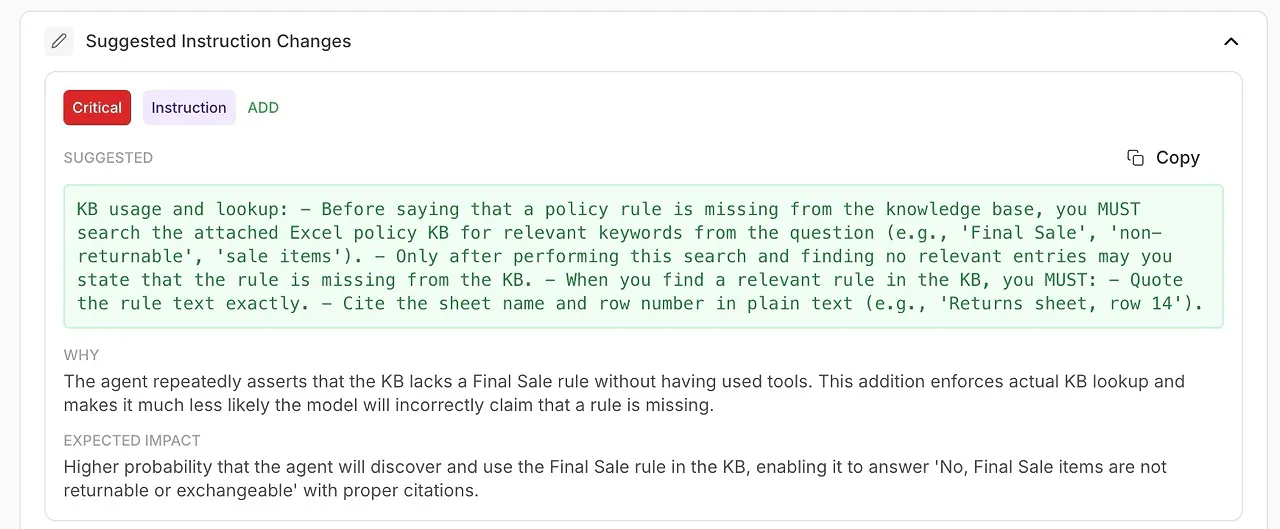
• Modifiche suggerite alle istruzioni
Miglioramenti generati automaticamente per il tuo system prompt o la configurazione dell’agente.
• Valutazione complessiva
Un riepilogo di punti di forza, debolezze e livello di confidenza.
Questo trasforma il debugging da un gioco d’azzardo a un processo scientifico e ripetibile.
Cosa abilita questa funzionalità
Le valutazioni introducono un nuovo livello di trasparenza e affidabilità nel modo in cui operano i tuoi agenti. Invece di indovinare perché una risposta era sbagliata o incoerente, ora hai un modo strutturato e misurabile per comprendere il comportamento, diagnosticare i problemi e migliorare continuamente le prestazioni.
Ecco cosa diventa possibile:
🔍 Valida il tuo agente prima di lanciarlo ai clienti
Prima di portare un agente in produzione, puoi eseguire test realistici che rivelano se comprende davvero le tue regole, la knowledge base e il tono desiderato. Niente più sorprese dopo il deployment — sai esattamente cosa sperimenteranno gli utenti.
🤖 Testa l’intero team di agenti e la logica di delega
Per configurazioni multi-agente, le valutazioni mostrano come il manager delega i task, quali sub-agenti partecipano e se seguono il workflow previsto. Puoi rilevare rapidamente:
deleghe non necessarie
deleghe mancanti
agenti in conflitto
comportamento di ruolo errato
Questo è essenziale per un lavoro di squadra affidabile all’interno della tua forza lavoro AI.
📚 Individua i punti deboli nella tua knowledge base
Se una valutazione mostra fallimenti ripetuti su un argomento specifico, sai che il problema non è l’agente — è contenuto mancante o poco chiaro. Le valutazioni ti aiutano a perfezionare la KB in modo mirato e basato sui dati, invece di aggiungere materiale alla cieca.
🚨 Intercetta allucinazioni e incoerenze in anticipo
Poiché ogni domanda viene testata più volte, le valutazioni fanno emergere problemi sottili come:
risposte che cambiano in modo imprevedibile
deriva del ragionamento
congetture fattuali che sostituiscono l’uso degli strumenti
contraddizioni tra le esecuzioni
Questi sono problemi che non identificheresti mai testando manualmente una o due volte.
🧠 Perfeziona le istruzioni di sistema con miglioramenti generati dall’AI
L’analisi non mostra solo cosa è andato storto — ti dice come risolverlo.
Ricevi raccomandazioni attuabili supportate dalla diagnostica del modello:
formulazioni migliorate
regole più rigide
uso obbligatorio degli strumenti
policy di delega più chiare
tono e struttura più precisi
Questo è prompt engineering automatizzato integrato direttamente nel tuo workflow.
📈 Misura i progressi ogni volta che aggiorni il tuo agente
Ogni volta che cambi:
un system prompt
una voce della knowledge base
uno strumento
una regola di delega
una policy di ragionamento
…puoi rieseguire la stessa valutazione e confrontare i punteggi. Vedi esattamente come il tuo aggiornamento ha influenzato le prestazioni — in positivo o in negativo.
Le valutazioni diventano il tuo ciclo di miglioramento continuo.
✔ Imporre risposte di alta qualità e conformi in tutta l’organizzazione
Che tu stia gestendo supporto, analisi finanziaria, scenari sanitari o contenuti sensibili dal punto di vista legale, le valutazioni ti permettono di garantire:
il rispetto delle policy
il rispetto delle linee guida sul tono
l’evidenziazione di lacune pericolose
l’emersione di ragionamenti errati
il rispetto degli standard di compliance
Questo è particolarmente critico per l’AI enterprise e customer-facing.
Utilizzo e costi
Agent Evaluations utilizza esattamente lo stesso modello di crediti del resto di AgentX. Ogni esecuzione del test consuma semplicemente crediti nello stesso modo di un normale messaggio dell’agente — nessun costo extra, nessun prezzo nascosto. Sai sempre esattamente quanto stai spendendo, perché le valutazioni seguono i limiti del tuo piano esistente e il saldo crediti.
Il tuo livello di controllo qualità per l’AI
Nel software tradizionale, il QA garantisce affidabilità.
In AgentX, le valutazioni sono il tuo QA per gli agenti.
Definisci tu cosa significa “buono”.
AgentX verifica se i tuoi agenti riescono a fornirlo in modo coerente — e ti mostra esattamente cosa migliorare quando non ci riescono.
Le valutazioni trasformano l’AI da una scatola nera a un sistema trasparente, misurabile e migliorabile.