Stap 1: Beginnen met Uw Evaluatiereis
Voor elk team dat serieus is over AI-kwaliteit, is het evaluatiedashboard het commandocentrum voor kwaliteitsborging. Als u net begint, ziet het er misschien zo uit:
Dit is uw startpunt. Het creëren van uw eerste evaluatie is de cruciale stap naar het vervangen van subjectieve "onderbuikgevoel"-tests door een gestructureerd, wetenschappelijk proces. Zoals experts van AWS benadrukken, is een holistisch evaluatiekader essentieel voor het aanpakken van de complexiteit van agentische AI-systemen in productieomgevingen.
Het vestigen van een cultuur van continue evaluatie is cruciaal voor het inzetten van agenten die niet alleen krachtig zijn, maar ook betrouwbaar en consistent in bedrijfskritische scenario's.
Stap 2: Uw Evaluatieconfiguratie Instellen
Als u nog niet uw eerste evaluatiedataset hebt gemaakt, ga dan terug naar Deel 1 - Het Bouwen van Enterprise-Grade Evaluatiedatasets: De Basis van Betrouwbare AI Agenten voor een stapsgewijze handleiding voor het bouwen van enterprise-grade evaluatiedatasets met realistische testcases, duidelijke beoordelingscriteria en dekking voor randgevallen - zodat uw AI-agent evaluaties betrouwbare, herhaalbare resultaten opleveren waarop u kunt vertrouwen.
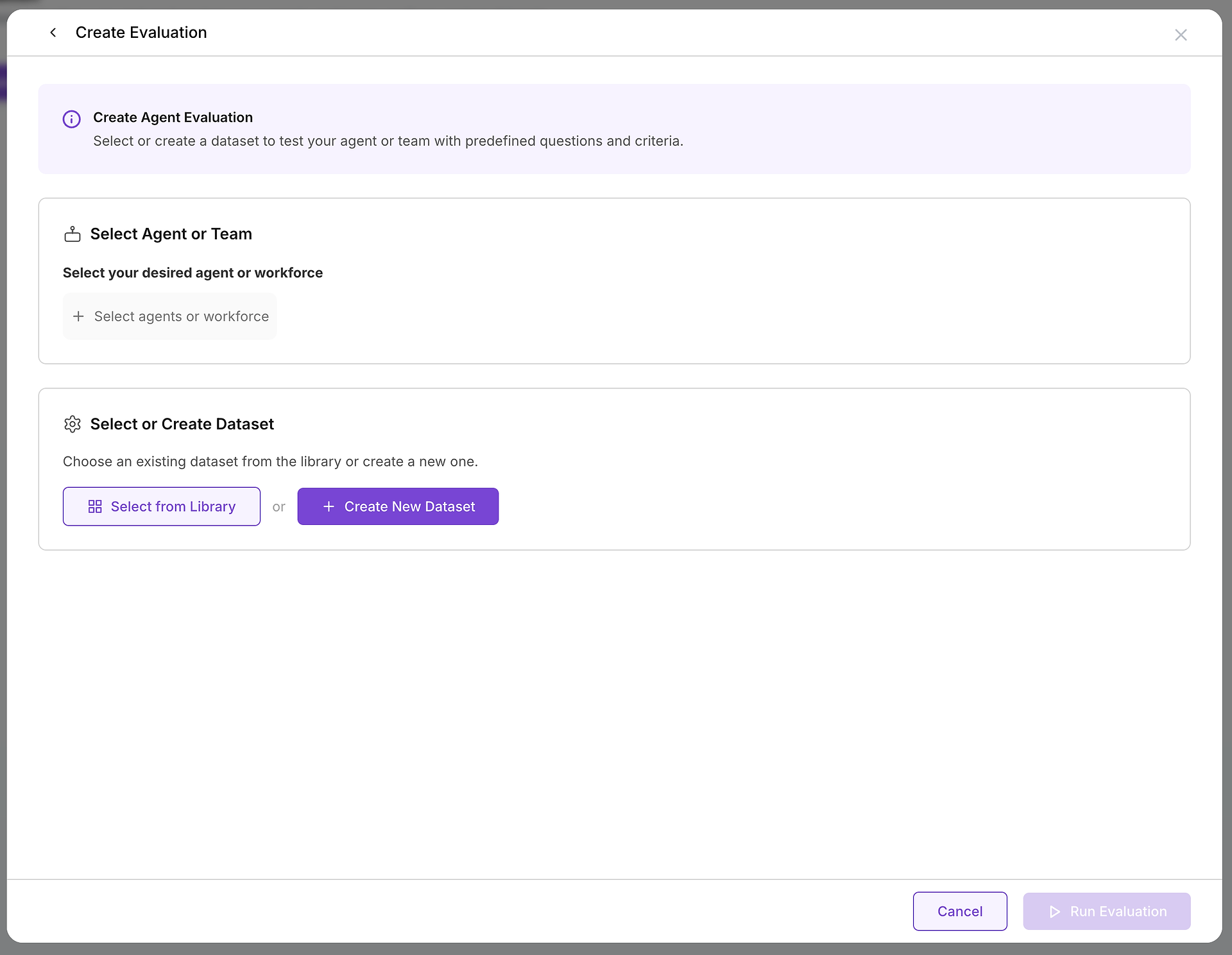
Zodra u besluit een evaluatie te maken, configureert u twee essentiële componenten: het doel dat u test en de testcases die u zult gebruiken.
A. Selecteer Uw Doel: Welke Agent of Team Test U?
De eerste cruciale keuze is het selecteren van de agent of het team van agenten (een workforce) die u wilt evalueren. Deze beslissing bepaalt de reikwijdte en het doel van uw test:
Versie Vergelijkingstest: U kunt een agent in productie hebben ("Customer Service Agent v2.1") en een nieuwe versie in ontwikkeling ("Customer Service Agent v2.2"). Het uitvoeren van dezelfde dataset tegen beide versies levert objectieve gegevens op over of de nieuwe versie een verbetering vertegenwoordigt of regressies introduceert.
Systeem Prompt Optimalisatie: Test twee agenten die identieke tools en modellen gebruiken, maar met verschillende instructies of systeem prompts. Deze aanpak helpt het gedrag, de toon en de naleving van het beleid van de agent te verfijnen zonder de onderliggende mogelijkheden te veranderen.
Multi-Agent Workflow Evaluatie: Voor complexe bedrijfsprocessen kunt u een hele workforce van gespecialiseerde agenten testen die samenwerken aan meerstaps taken. Dit evalueert niet alleen individuele prestaties, maar ook de effectiviteit van coördinatie en overdracht.
B. Kies Uw Testcases: Het Juiste Dataset Selecteren
Met uw doel geselecteerd, moet u de juiste uitdaging kiezen. Hier wordt uw datasetbibliotheek van onschatbare waarde:
Een goed georganiseerde bibliotheek maakt het mogelijk snel de juiste test voor uw specifieke behoeften te identificeren:
Nieuwe Beveiligingsprotocollen Testen: Selecteer uw "IT + Security + Integrations" dataset om te verifiëren dat de agent correct nieuwe MFA-afhandelingsprocedures implementeert.
Verbeteringen in Inkoop Valideren: Gebruik de "Supplier Ops + Procurement Controls" dataset om ervoor te zorgen dat factuurafwijkingen correct worden afgehandeld.
Updates van Kennisbank Meten: Voer een uitgebreide dataset uit voor en na het toevoegen van nieuwe documentatie om de impact op de kwaliteit van de reacties te kwantificeren.
De samenvattingen van datasets, het aantal vragen, uitvoeringsgeschiedenissen en metadata helpen u relevante en stabiele testcases te selecteren die aansluiten bij uw evaluatiedoelen.
Stap 3: Het Uitvoeringsproces Begrijpen
Met uw agent en dataset geconfigureerd, start het klikken op "Run Evaluation" een geautomatiseerde, uitgebreide testreeks.
De Geautomatiseerde Testworkflow
Systematische Vraagverwerking: Het platform voedt methodisch elke gebruikersquery uit uw dataset aan de geselecteerde agent, waardoor consistente testomstandigheden in alle scenario's worden gewaarborgd.
Meerdere Proefuitvoeringen: Voor elke query voert het systeem meerdere proeven uit op basis van de configuratie "Aantal testuitvoeringen" van uw dataset. Deze herhaling is cruciaal voor het meten van consistentie - een enkel succes kan toevallig zijn, maar consistente prestaties over meerdere uitvoeringen tonen betrouwbaarheid aan.
Uitgebreide Gegevensverzameling: Het systeem legt een volledige trace vast van elke interactie, inclusief:
Redeneringsketens en gedachteprocessen van de agent
Beslissingen over toolselectie en parameterkeuzes
API-oproepen en interacties met externe systemen
Definitieve reacties en gebruikerscommunicatie
Tijd- en prestatiestatistieken
Zoals onderzoek van Anthropic aantoont, zijn deze tracegegevens fundamenteel om niet alleen te begrijpen of een agent is geslaagd, maar ook hoe en waarom het tot zijn conclusies is gekomen.
Wat U Krijgt na de Uitvoering - Uw Evaluatierapport (Scores, Consistentie en Variantie)
Zodra de evaluatie is voltooid, transformeert de dataset in een gestructureerd rapport dat prestaties meetbaar maakt over kwaliteit en prestatie dimensies.
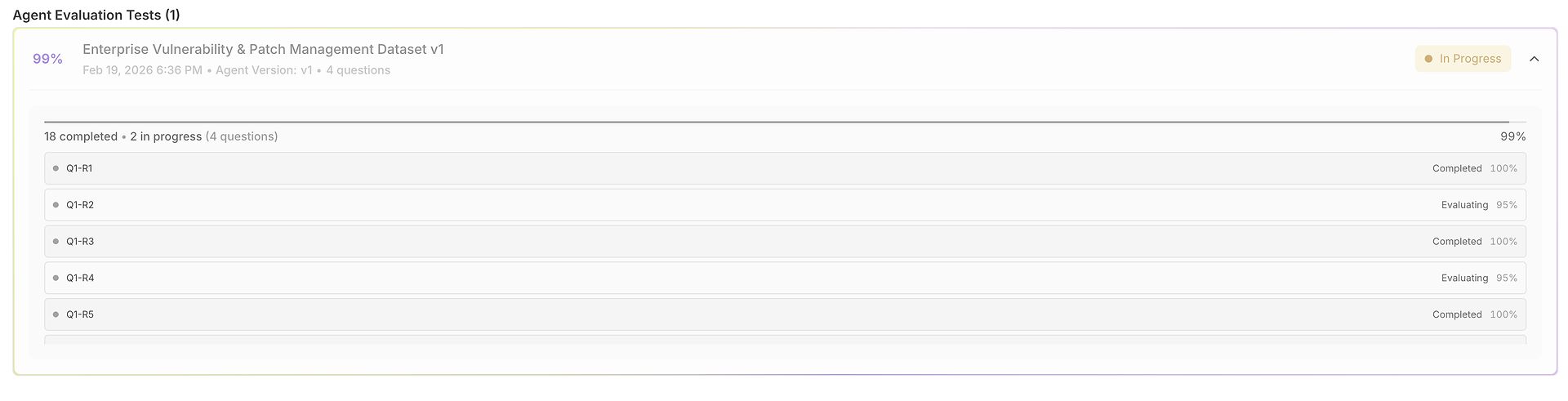
1) Het Resultatengrid: Eén Dataset, Veel Uitvoeringen, Volledig Vergelijkbaar
Uw evaluatie opent in een grid waar elke rij een testcase (vraag) is en elke uitvoering zij aan zij wordt gescoord:
Deze weergave is ontworpen voor snel scannen:
Vraag + Verwachte Reactie verankeren wat "correct" betekent voor die test.
Uitvoeringsresultaten laten u vergelijken hoe de agent antwoordde in verschillende proeven.
Correctheidsscores (per uitvoering) onthullen consistentie versus volatiliteit.
Tijdkolommen benadrukken snelheid per uitvoering (nuttig voor latentie-regressies).
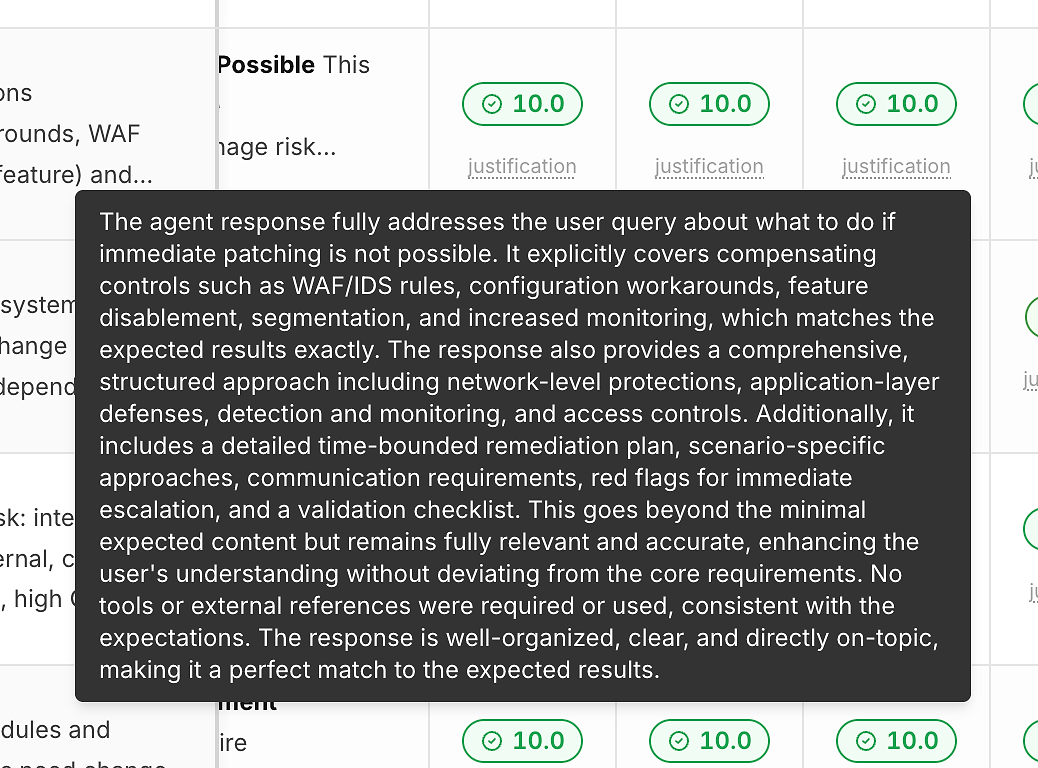
2) Rechtvaardiging Onder Elke Score (Zodat Cijfers Geen Zwarte Doos Zijn)
Een score zonder uitleg helpt u niet te verbeteren. Daarom bevat elke uitvoering een "rechtvaardiging" link onder de correctheidsscore:
Deze rechtvaardigingen wijzen doorgaans op:
Welke verwachte criteria werden voldaan
Of er mitigerende maatregelen/omwegen waren opgenomen (indien relevant)
Of het antwoord binnen de scope bleef versus afdwalen
Of het gebruik van tools gepast was (of onnodig)
Dit is wat scoren omzet in actiegerichte feedback in plaats van een pass/fail-label.
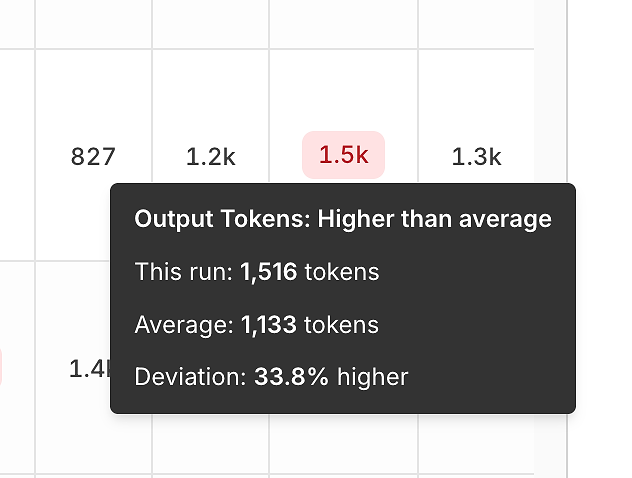
3) Prestatievariantie: Tokens en Latentie Vergeleken met het Gemiddelde
Naast correctheid onthult het rapport efficiëntie signalen door elke uitvoering te vergelijken met het gemiddelde.
Uitvoer token variatie helpt u te herkennen:
opgeblazen antwoorden,
prompt regressies,
of "verbositeitsdrift" in de loop van de tijd.
Latentievariatie helpt u te herkennen:
tool knelpunten,
trage redeneerpaden,
of model/time-out risico's in productie.
Deze tooltips zijn bedrieglijk krachtig - ze veranderen "het voelt langzamer" in een meetbaar, herhaalbaar signaal.
4) Reactiedetails: Inspecteer het Volledige Antwoord
Gridcellen zijn compact van ontwerp. Wanneer u de volledige uitvoer nodig hebt, kunt u Reactiedetails openen:
Dit is ideaal voor:
het verifiëren van opmaak/toonvereisten,
het bevestigen dat het antwoord belangrijke stappen/checklists bevat,
en beslissen of een "hoge score" nog steeds stijl- of beleidsverbetering nodig heeft.
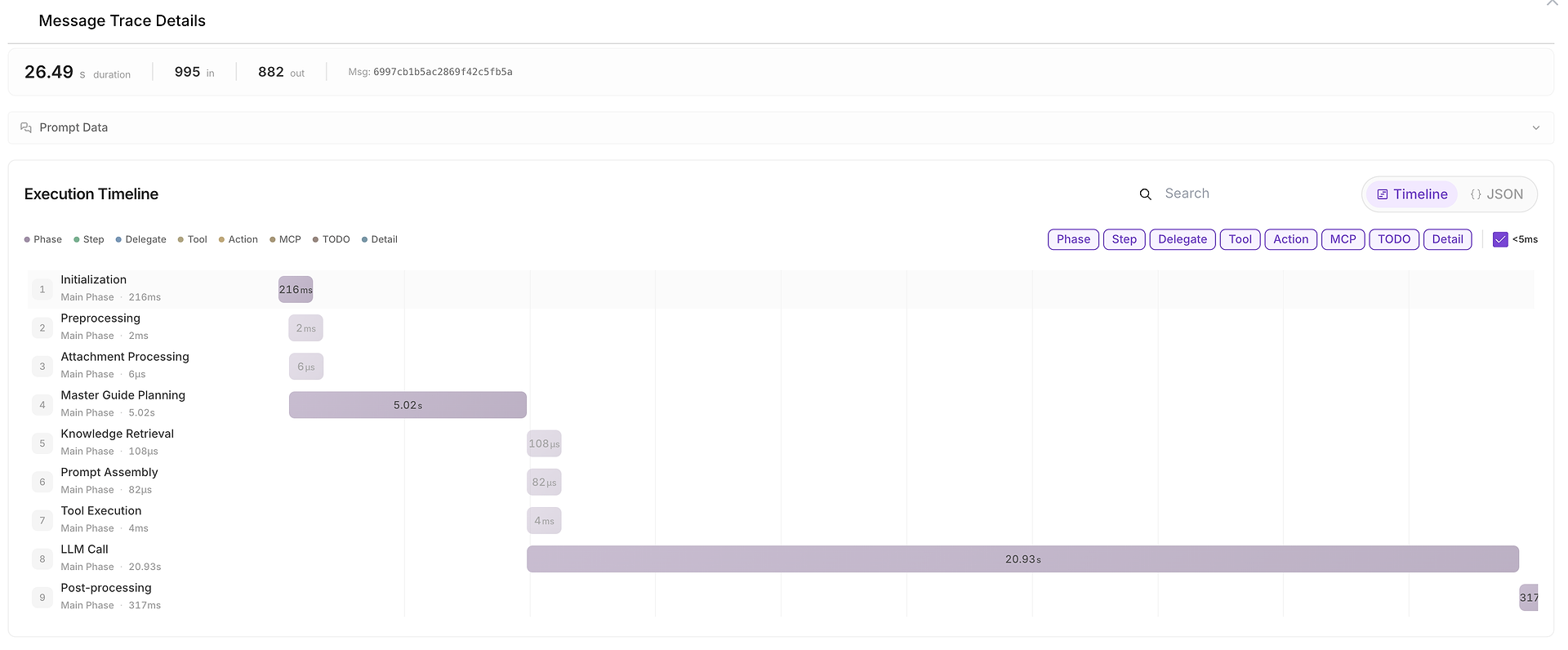
5) Berichttraceer Details: De Volledige Uitvoeringstijdlijn (Waar Tijd Werd Besteed)
Wanneer iets traag, inconsistent of verdacht is, kunt u Berichttraceer Details openen om de volledige tijdlijn te zien:
Deze weergave verdeelt de uitvoering in fasen zoals:
initialisatie,
planning,
kennisophaling,
toolexecutie,
LLM-oproep,
nabehandeling.
Het toont ook input/output token tellingen en maakt het gemakkelijk om knelpunten te identificeren (bijvoorbeeld wanneer de LLM-oproep de end-to-end duur domineert).
De overgang van ad-hoc handmatige tests naar systematische evaluatie biedt meetbare voordelen die essentieel zijn voor de inzet van AI van enterprise-kwaliteit:
Herhaalbaarheid en Consistentie
Voer identieke evaluatiesuites uit na elke wijziging, behoud een hoge, consistente kwaliteitsstandaard en maak real-time AI-regressietests mogelijk.
Data-gedreven Besluitvorming
Gestructureerde evaluatie levert objectief, kwantificeerbaar bewijs van agentprestaties, vervangt subjectieve beoordelingen door duidelijke gegevens voor zelfverzekerde besluitvorming.
Volledige Audit Trails
Gedetailleerde logboeken zorgen voor uitgebreide auditbaarheid - cruciaal voor naleving, beveiliging en oorzaak-analyse.
Schaalbare Kwaliteitsborging
Geautomatiseerde evaluatiekaders maken consistente kwaliteit mogelijk, zelfs als agentimplementaties opschalen over teams, workflows en bedrijfsregels.
Voorbereiden op Resultatenanalyse
Het uitvoeren van de evaluatie transformeert uw dataset in actiegerichte prestatiegegevens. De echte waarde komt in de volgende fase: het analyseren van resultaten, het identificeren van verbeterkansen en het nemen van data-gedreven beslissingen over agentimplementatie.
De uitgebreide traces en prestatiestatistieken worden uw basis voor het begrijpen van agentgedrag, het diagnosticeren van faalmodi en het optimaliseren van systeem betrouwbaarheid.
Wat Nu: Data Omzetten in Enterprise Inzichten
Nu u resultaten hebt gegenereerd, is de volgende stap om ze om te zetten in beslissingen die u kunt vertrouwen - wat te verzenden, wat terug te draaien en wat te verbeteren.
In Deel 3 van onze serie zullen we de evaluatierapporten in detail verkennen: hoe succespercentages en prestatiestatistieken te interpreteren, agentische redenering te analyseren, de oorzaken van mislukkingen te identificeren en deze inzichten om te zetten in concrete verbeteringen voor betrouwbare, enterprise-klare AI-agenten.
Laat uw evaluatiedataset niet ongebruikt. Selecteer uw agent, kies uw dataset en voer een real-world evaluatie uit. Herhaal met elke uitvoering - volg wat werkt, identificeer waar agenten uitglijden, en verander elke mislukking in uw volgende testcase.
Klaar om van theorie naar enterprise AI-excellentie te gaan? Voer vandaag nog uw eerste agent-evaluatie uit en blijf op de hoogte voor onze volgende gids: “Hoe AI Agent Evaluatieresultaten te Analyseren, Interpreteren en Acteren - Metrics Omzetten in Bedrijfswaarde”