Krok 1: Rozpoczęcie Podróży Ewaluacyjnej
Dla każdego zespołu poważnie podchodzącego do jakości AI, pulpit ewaluacyjny jest centrum dowodzenia dla zapewnienia jakości. Jeśli dopiero zaczynasz, może wyglądać to tak:
To jest twój punkt startowy. Tworzenie pierwszej ewaluacji to kluczowy krok w kierunku zastąpienia subiektywnego testowania "na wyczucie" ustrukturyzowanym, naukowym procesem. Jak podkreślają eksperci z AWS, holistyczne ramy ewaluacyjne są niezbędne do radzenia sobie ze złożonością systemów agentowych AI w środowiskach produkcyjnych.
Ustanowienie kultury ciągłej ewaluacji jest kluczowe dla wdrażania agentów, którzy są nie tylko potężni, ale także godni zaufania i niezawodni w scenariuszach krytycznych dla biznesu.
Krok 2: Konfiguracja Twojej Ewaluacji
Jeśli jeszcze nie stworzyłeś swojego pierwszego zbioru danych do ewaluacji, wróć do Część 1 - Budowanie Zbiorów Danych do Ewaluacji na Poziomie Przedsiębiorstwa: Fundament Wiarygodnych Agentów AI po przewodnik krok po kroku, jak budować zbiory danych do ewaluacji na poziomie przedsiębiorstwa z realistycznymi przypadkami testowymi, jasnymi kryteriami oceny i pokryciem przypadków brzegowych - aby twoje ewaluacje agentów AI dawały wiarygodne, powtarzalne wyniki, którym możesz zaufać.
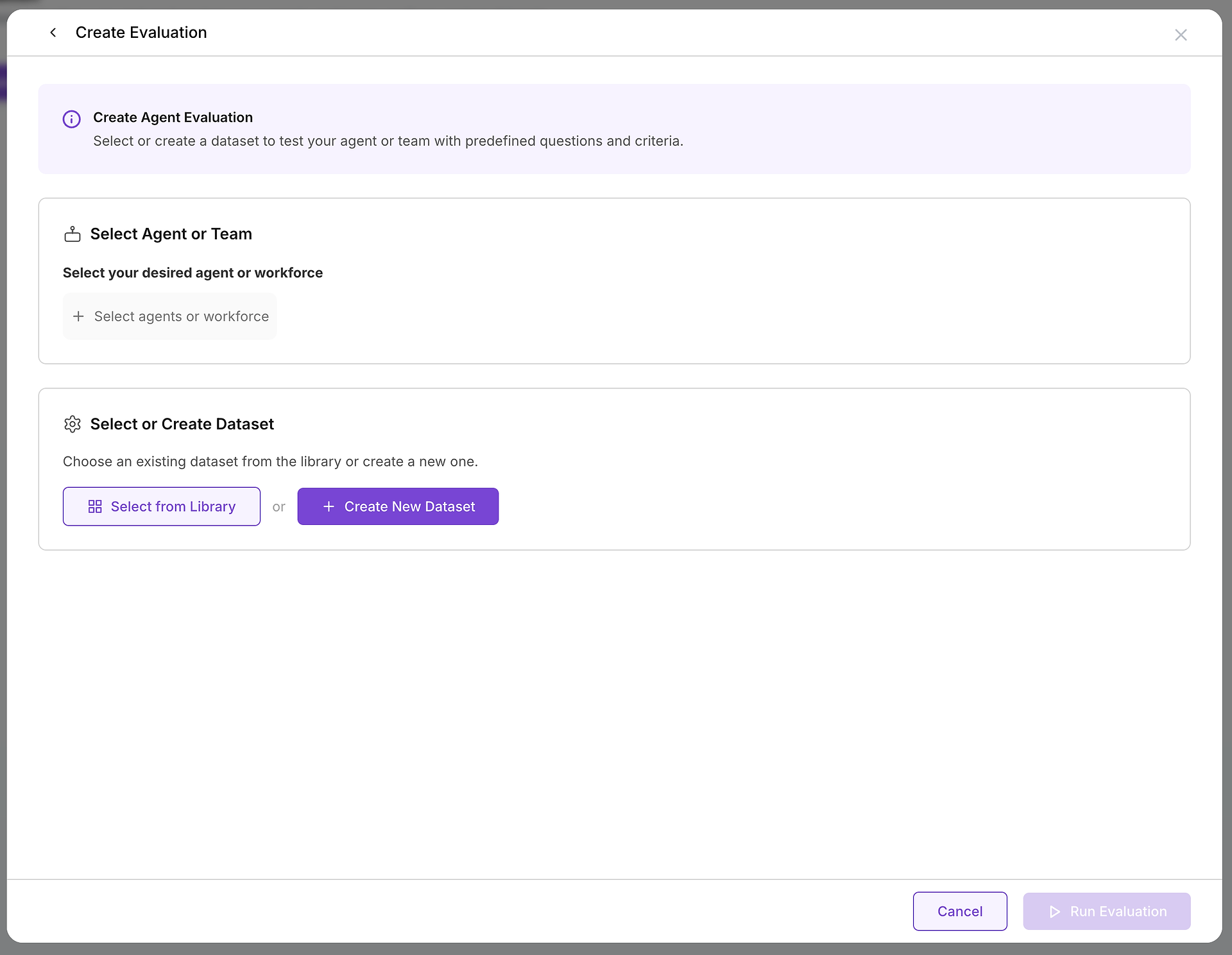
Gdy zdecydujesz się stworzyć ewaluację, skonfigurujesz dwa kluczowe komponenty: cel, który testujesz, oraz przypadki testowe, które użyjesz.
A. Wybierz Swój Cel: Którego Agenta lub Zespół Testujesz?
Pierwszym kluczowym wyborem jest wybranie agenta lub zespołu agentów (siły roboczej), którego chcesz ocenić. Ta decyzja definiuje zakres i cel twojego testu:
Testowanie Porównawcze Wersji: Możesz mieć agenta w produkcji ("Agent Obsługi Klienta v2.1") i nową wersję w rozwoju ("Agent Obsługi Klienta v2.2"). Uruchomienie tego samego zbioru danych dla obu wersji dostarcza obiektywnych danych, czy nowa wersja stanowi poprawę, czy wprowadza regresje.
Optymalizacja Podpowiedzi Systemowych: Przetestuj dwóch agentów używających identycznych narzędzi i modeli, ale z różnymi instrukcjami lub podpowiedziami systemowymi. To podejście pomaga dostroić zachowanie agenta, ton i zgodność z polityką bez zmiany podstawowych możliwości.
Ewaluacja Przepływu Pracy Wieloagentowego: Dla złożonych procesów biznesowych możesz przetestować całą siłę roboczą wyspecjalizowanych agentów, którzy współpracują przy zadaniach wieloetapowych. To ocenia nie tylko indywidualną wydajność, ale także skuteczność koordynacji i przekazywania zadań.
B. Wybierz Swoje Przypadki Testowe: Wybór Odpowiedniego Zbioru Danych
Po wybraniu celu musisz wybrać odpowiednie wyzwanie. Tutaj twoja biblioteka zbiorów danych staje się nieoceniona:
Dobrze zorganizowana biblioteka umożliwia szybkie zidentyfikowanie odpowiedniego testu dla twoich specyficznych potrzeb:
Testowanie Nowych Protokołów Bezpieczeństwa: Wybierz swój zbiór danych "IT + Bezpieczeństwo + Integracje", aby zweryfikować, czy agent poprawnie wdraża nowe procedury obsługi MFA.
Walidacja Ulepszeń Zakupowych: Użyj zbioru danych "Operacje Dostawców + Kontrole Zakupów", aby upewnić się, że poprawnie obsługiwane są wyjątki w dopasowywaniu faktur.
Mierzenie Aktualizacji Bazy Wiedzy: Uruchom kompleksowy zbiór danych przed i po dodaniu nowej dokumentacji, aby zmierzyć wpływ na jakość odpowiedzi.
Podsumowania zbiorów danych, liczby pytań, historie uruchomień i metadane pomagają wybrać odpowiednie i stabilne przypadki testowe, które odpowiadają twoim celom ewaluacyjnym.
Krok 3: Zrozumienie Procesu Wykonania
Po skonfigurowaniu agenta i zbioru danych, kliknięcie "Uruchom Ewaluację" inicjuje zautomatyzowaną, kompleksową sekwencję testową.
Zautomatyzowany Przepływ Testowy
Systematyczne Przetwarzanie Pytań: Platforma metodycznie przekazuje każdą zapytanie użytkownika z twojego zbioru danych do wybranego agenta, zapewniając spójne warunki testowe we wszystkich scenariuszach.
Wykonanie Wielu Prób: Dla każdego zapytania system przeprowadza wiele prób na podstawie konfiguracji "Liczby uruchomień testowych" w twoim zbiorze danych. Ta powtarzalność jest kluczowa dla mierzenia spójności - pojedynczy sukces może być przypadkowy, ale spójna wydajność w wielu próbach świadczy o niezawodności.
Kompleksowe Zbieranie Danych: System rejestruje pełny ślad każdej interakcji, w tym:
Łańcuchy rozumowania i procesy myślowe agenta
Decyzje o wyborze narzędzi i parametrach
Wywołania API i interakcje zewnętrzne
Ostateczne odpowiedzi i komunikacje z użytkownikiem
Metryki czasu i wydajności
Jak pokazują badania Anthropic, te dane śladowe są fundamentalne dla zrozumienia nie tylko, czy agent odniósł sukces, ale jak i dlaczego doszedł do swoich wniosków.
Co Otrzymujesz Po Uruchomieniu - Twój Raport Ewaluacyjny (Wyniki, Spójność i Zmienność)
Po zakończeniu ewaluacji zbiór danych przekształca się w ustrukturyzowany raport, który sprawia, że wydajność jest mierzalna w wymiarach jakości i wydajności.
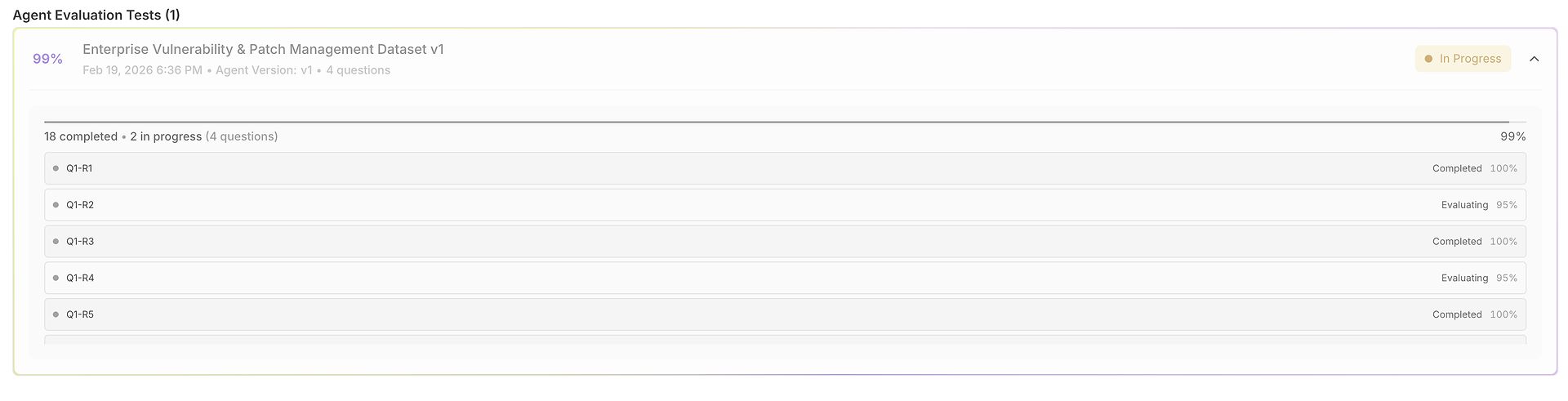
1) Siatka Wyników: Jeden Zbiór Danych, Wiele Uruchomień, W Pełni Porównywalne
Twoja ewaluacja otwiera się w siatce, gdzie każdy wiersz to przypadek testowy (pytanie), a każde uruchomienie jest oceniane obok siebie:
Ten widok jest zaprojektowany do szybkiego skanowania:
Pytanie + Oczekiwana Odpowiedź zakotwicza, co oznacza "poprawne" dla tego testu.
Wyniki uruchomień pozwalają porównać jak agent odpowiedział w różnych próbach.
Oceny poprawności (na uruchomienie) ujawniają spójność vs. zmienność.
Kolumny czasowe podkreślają szybkość na uruchomienie (przydatne dla regresji opóźnień).
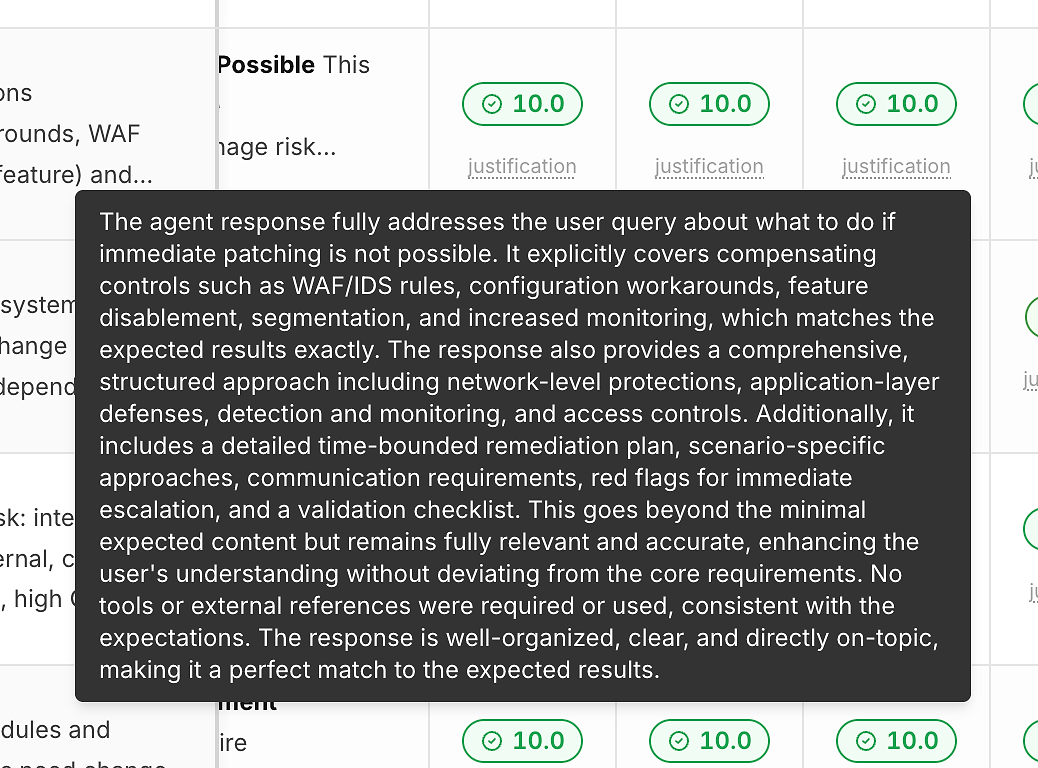
2) Uzasadnienie Pod Każdą Oceną (Aby Liczby Nie Były Czarną Skrzynką)
Ocena bez wyjaśnienia nie pomaga w poprawie. Dlatego każde uruchomienie zawiera link do "uzasadnienia" pod swoją oceną poprawności:
Te uzasadnienia zazwyczaj wskazują:
Które oczekiwane kryteria zostały spełnione
Czy uwzględniono łagodzenia/obejścia (gdy istotne)
Czy odpowiedź pozostała w zakresie vs. dryfowała
Czy użycie narzędzi było odpowiednie (lub niepotrzebne)
To jest to, co zamienia ocenianie w działalną informację zwrotną zamiast etykiety zaliczenia/niezaliczenia.
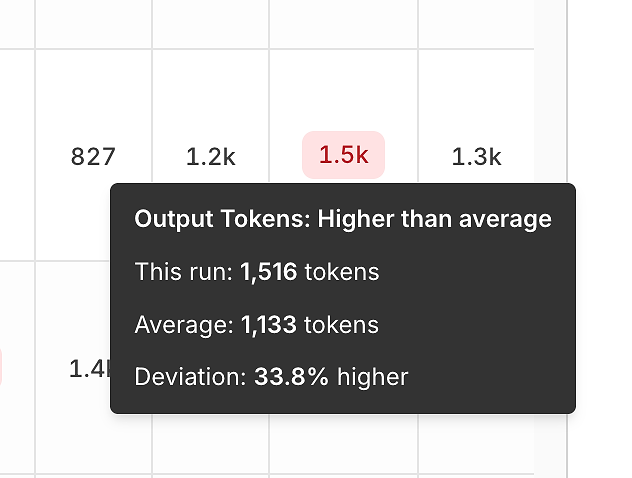
3) Zmienność Wydajności: Tokeny i Opóźnienia w Porównaniu do Średniej
Poza poprawnością, raport ujawnia sygnały efektywności poprzez porównanie każdego uruchomienia do średniej.
Zmienność tokenów wyjściowych pomaga zidentyfikować:
przesadne odpowiedzi,
regresje podpowiedzi,
lub "dryf rozwlekłości" w czasie.
Zmienność opóźnień pomaga zidentyfikować:
wąskie gardła narzędzi,
wolne ścieżki rozumowania,
lub ryzyko modelu/przekroczenia czasu w produkcji.
Te podpowiedzi są zwodniczo potężne - zamieniają "wydaje się wolniejsze" w mierzalny, powtarzalny sygnał.
4) Szczegóły Odpowiedzi: Sprawdź Pełną Odpowiedź
Komórki siatki są kompaktowe z założenia. Kiedy potrzebujesz pełnego wyniku, możesz otworzyć Szczegóły Odpowiedzi:
To jest idealne do:
weryfikacji wymagań dotyczących formatowania/tonu,
potwierdzenia, że odpowiedź zawiera kluczowe kroki/listy kontrolne,
i decydowania, czy "wysoka ocena" nadal wymaga dopracowania stylu lub polityki.
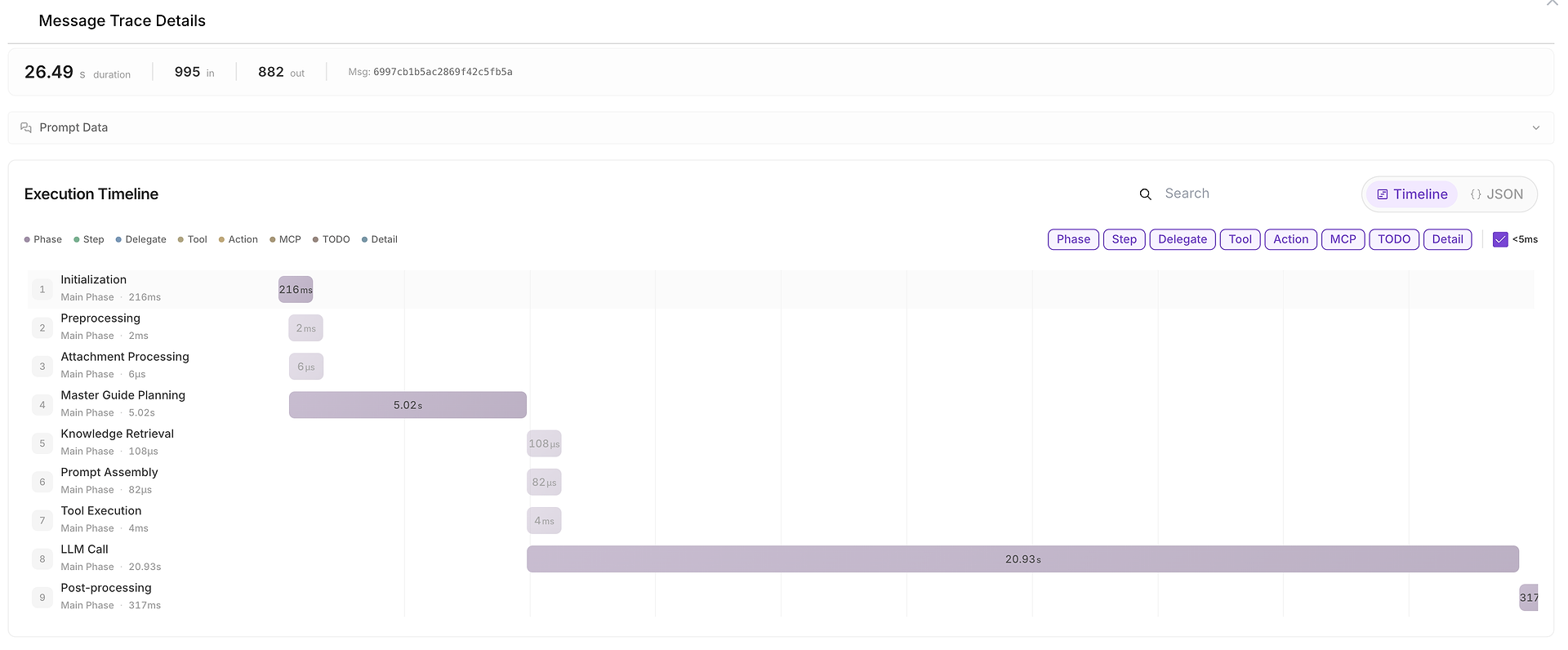
5) Szczegóły Śladu Wiadomości: Pełna Oś Czasu Wykonania (Gdzie Spędzono Czas)
Kiedy coś jest wolne, niespójne lub podejrzane, możesz otworzyć Szczegóły Śladu Wiadomości, aby zobaczyć pełną oś czasu:
Ten widok dzieli uruchomienie na fazy takie jak:
inicjalizacja,
planowanie,
pobieranie wiedzy,
wykonanie narzędzia,
wywołanie LLM,
post-processing.
Pokazuje również liczby tokenów wejściowych/wyjściowych i ułatwia identyfikację wąskich gardeł (na przykład, gdy wywołanie LLM dominuje w całkowitym czasie trwania).
Dlaczego Ta Ustrukturyzowana Podejście Przekształca Jakość AI w Przedsiębiorstwie
Przejście od ad-hoc ręcznego testowania do systematycznej ewaluacji zapewnia mierzalne korzyści, które są niezbędne dla wdrożeń AI na poziomie przedsiębiorstwa:
Powtarzalność i Spójność
Wykonuj identyczne zestawy ewaluacyjne po każdej zmianie, utrzymując wysoki, spójny standard jakości i umożliwiając testowanie regresji AI w czasie rzeczywistym AI regression testing.
Decyzje Oparte na Danych
Ustrukturyzowana ewaluacja dostarcza obiektywnych, ilościowych dowodów na wydajność agenta, zastępując subiektywne oceny jasnymi danymi dla pewnego podejmowania decyzji.
Kompletne Ścieżki Audytu
Szczegółowe logi zapewniają kompleksową audytowalność - kluczową dla zgodności, bezpieczeństwa i analizy przyczyn źródłowych.
Skalowalna Kontrola Jakości
Zautomatyzowane ramy ewaluacyjne umożliwiają spójną jakość, nawet gdy wdrożenia agentów skalują się w zespołach, przepływach pracy i liniach biznesowych.
Przygotowanie do Analizy Wyników
Uruchomienie ewaluacji przekształca twój zbiór danych w dane o wydajności, które można wykorzystać. Prawdziwa wartość pojawia się w następnej fazie: analizie wyników, identyfikacji możliwości poprawy i podejmowaniu decyzji opartych na danych dotyczących wdrożenia agentów.
Kompleksowe ślady i metryki wydajności stają się twoim fundamentem do zrozumienia zachowania agenta, diagnozowania trybów awarii i optymalizacji niezawodności systemu.
Co Dalej: Przekształcanie Danych w Wglądy Przedsiębiorstwa
Teraz, gdy wygenerowałeś wyniki, następnym krokiem jest przekształcenie ich w decyzje, którym możesz zaufać - co wdrożyć, co wycofać i co poprawić.
W Części 3 naszej serii, zbadamy raporty ewaluacyjne w szczegółach: jak interpretować wskaźniki sukcesu i metryki wydajności, analizować rozumowanie agentów, identyfikować przyczyny awarii i przekształcać te wglądy w konkretne ulepszenia dla godnych zaufania, gotowych do wdrożenia agentów AI w przedsiębiorstwie.
Nie pozwól, aby twój zbiór danych do ewaluacji leżał bezczynnie. Wybierz swojego agenta, wybierz swój zbiór danych i uruchom rzeczywistą ewaluację. Iteruj z każdym uruchomieniem - śledź co działa, identyfikuj gdzie agenci się potykają i zamieniaj każdą porażkę w swój następny przypadek testowy.
Gotowy, aby przejść od teorii do doskonałości AI w przedsiębiorstwie? Uruchom swoją pierwszą ewaluację agenta już dziś i śledź nasz następny przewodnik: „Jak Analizować, Interpretować i Działać na Wynikach Ewaluacji Agentów AI - Przekształcanie Metryk w Wartość Biznesową”