Os agentes de AI estão se tornando mais avançados, mais capazes e mais profundamente integrados aos negócios.
Mas existe um problema universal que toda equipe enfrenta:
Seu agente nem sempre responde da forma que você espera — e você não sabe por quê.
Às vezes o raciocínio muda, às vezes o agente ignora uma regra, às vezes a ferramenta não foi usada corretamente e, às vezes, uma instrução sutil foi mal interpretada. Sem visibilidade de como as decisões foram tomadas, melhorar o agente parece um jogo de adivinhação.
É exatamente por isso que criamos as Avaliações de Agentes — um novo sistema dentro do AgentX que permite testar, medir e analisar profundamente como seu agente se comporta em múltiplas execuções da mesma pergunta.
É a primeira vez que você pode ver por dentro da tomada de decisão do seu agente, encontrar inconsistências e entender com precisão onde melhorias são necessárias.
Por que as Avaliações Importam
Modelos de AI são probabilísticos.
Mesmo com o mesmo prompt, contexto e regras, o modelo pode:
produzir caminhos de raciocínio ligeiramente diferentes
omitir um detalhe obrigatório
interpretar incorretamente uma política
pular uma consulta a uma ferramenta
dar respostas incertas em vez da resposta definitiva esperada
delegar de forma inconsistente dentro de uma equipe
De fora, você só vê a resposta final.
Você não vê:
se o agente seguiu suas instruções
se usou as ferramentas certas
se raciocinou corretamente
por que uma versão da resposta foi mais fraca do que outra
por que às vezes ele acerta — e às vezes erra
Avaliações resolvem isso ao oferecer estrutura, pontuação e transparência.
Como um Teste Funciona
Criar uma avaliação é simples:
0. Selecione o Agente ou a equipe que você deseja avaliar.
1. Pergunta de Teste
Esta é a pergunta do mundo real que você quer validar.
Ela simula uma dúvida de cliente ou uma solicitação de fluxo de trabalho interno.
Exemplo:
“Posso devolver um item de Venda Final se não servir?”
Isso forma o núcleo da avaliação.
2. Resultados Esperados (Obrigatório)
Esta é a parte mais importante da configuração.
Aqui você define o que o agente DEVE dizer ou incluir para que a resposta seja considerada correta.
Pode conter:
fatos-chave
frases obrigatórias
etapas de raciocínio obrigatórias
regras de compliance
tom específico ou declarações de política
Exemplo:
“Deve dizer: Não, itens de Venda Final não podem ser devolvidos nem trocados.”
Os Resultados Esperados se tornam a rubrica de pontuação para todas as execuções de teste.
3. Capacidades Esperadas (Opcional, mas Poderoso)
Você pode informar ao sistema de avaliação quais ferramentas, documentos ou fontes de conhecimento o agente deve usar.
No seu exemplo, você selecionou:
Documents → store_policy_kb_v1.xlsx
Built-in Functions
Isso significa:
O agente deveria recuperar informações da KB de políticas.
Se ele não usar a KB corretamente, a avaliação vai detectar isso.
Isso é perfeito para:
agentes de políticas
agentes de atendimento ao cliente
fluxos de trabalho de compliance
modelagem financeira
raciocínio baseado em dados
4. Configurações de Avaliação
Esta seção define quão rigorosa e quão profunda sua avaliação deve ser.
Número de Execuções de Teste
A mesma pergunta é executada várias vezes (Recomendado: 5 execuções).
Por quê?
Porque modelos de AI não são determinísticos. Múltiplas execuções permitem verificar:
consistência
estabilidade
confiabilidade do raciocínio
se o agente segue o mesmo processo a cada vez
Se o agente produzir uma boa resposta e quatro falhas, você verá isso instantaneamente.
Critérios de Aceitação
Este controle deslizante define quão estritamente a resposta deve corresponder aos seus Resultados Esperados.
Você está escolhendo um ponto entre:
Tolerante → o agente pode se desviar das suas expectativas; a resposta não precisa ser perfeita.
Exato → a resposta deve seguir suas expectativas muito de perto, com quase nenhuma margem para variação.
Ele simplesmente controla o quão exata a resposta precisa ser para passar na avaliação.
Critérios de Rejeição (Opcional)
Regras para falha automática.
Exemplos:
“A resposta não deve mencionar concorrentes.”
“Não ofereça reembolsos quando a política proibir.”
“A resposta não deve pedir ao usuário para fornecer informações pessoais.”
Estas são restrições rígidas.
Critérios de Avaliação (Opcional)
Orientações adicionais de pontuação, frequentemente usadas para qualidade ou tom.
Exemplos:
“A resposta deve ser amigável e profissional.”
“A resposta deve conter uma explicação curta, não apenas um sim/não.”
“Use fatos da KB antes de suposições.”
Esses não são requisitos rígidos, mas ajudam a moldar como a AI pontua o agente.
5. Criar Avaliação
Depois de configurado, clicar em Create Evaluation inicia o processo:
a pergunta é executada várias vezes
cada resposta é pontuada
uma análise detalhada é gerada
delegação e uso de ferramentas são inspecionados
inconsistências são evidenciadas
E você recebe um relatório completo de desempenho.
O que Você Obtém Após Executar a Avaliação
Após várias execuções, o AgentX fornece duas camadas de saída:
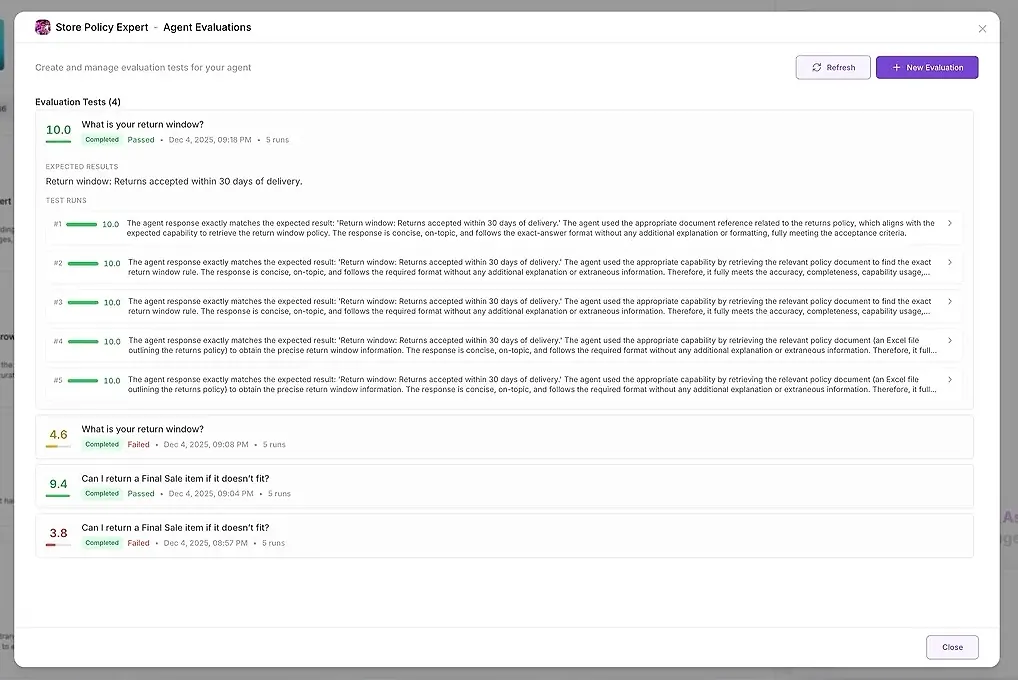
1. Resultados do Teste
Para cada execução, você vê:
uma pontuação numérica
um resumo de quão bem correspondeu às suas expectativas
a resposta completa
quais ferramentas foram usadas
quais agentes participaram
onde o agente falhou ou se desviou
Isso permite comparar respostas lado a lado e identificar padrões.
2. Análise Profunda de AI
É aqui que a verdadeira mágica acontece.
O AgentX analisa automaticamente todas as execuções e gera um relatório estruturado em múltiplas categorias:
• Aderência às Instruções
O agente seguiu suas regras?
• Padrões de Resposta
Quão semelhantes ou diferentes foram as respostas?
Existem outliers?
• Análise de Raciocínio
As etapas de raciocínio estavam corretas, completas e alinhadas às expectativas?
• Uso de Ferramentas
O agente usou a ferramenta correta?
Ele pulou uma consulta?
Ele se baseou em suposições em vez de fatos verificados?
• Recomendações
Sugestões concretas e acionáveis para melhorar seu agente.
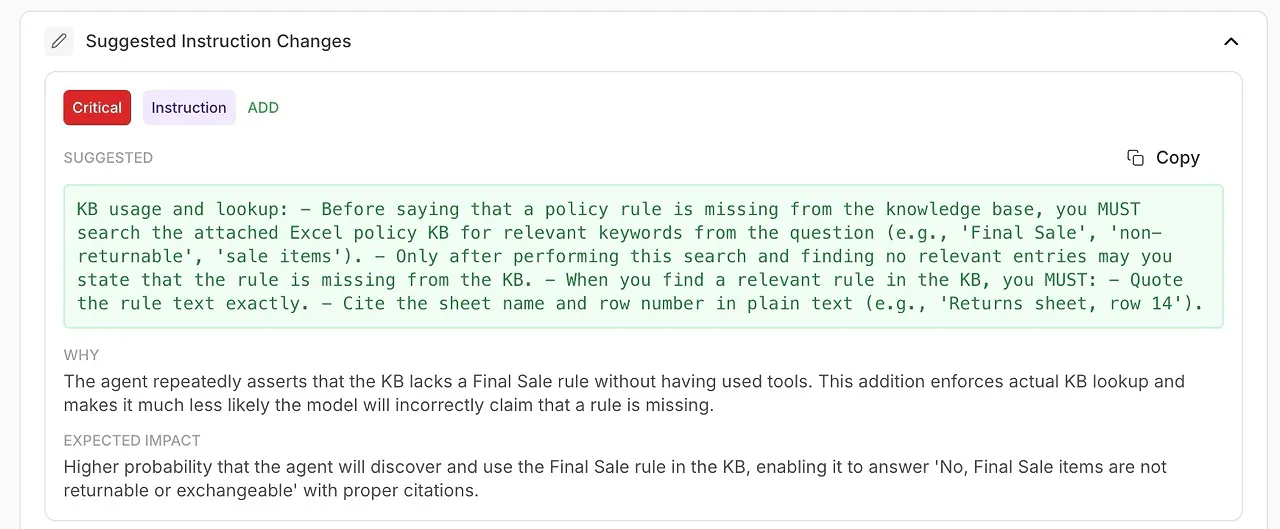
• Mudanças Sugeridas nas Instruções
Melhorias geradas automaticamente para o seu system prompt ou configuração do agente.
• Avaliação Geral
Um resumo de pontos fortes, pontos fracos e nível de confiança.
Isso transforma o debug de um jogo de adivinhação em um processo científico e repetível.
O que Este Recurso Permite
As Avaliações introduzem um novo nível de transparência e confiabilidade em como seus agentes operam. Em vez de adivinhar por que uma resposta estava errada ou inconsistente, agora você tem uma forma estruturada e mensurável de entender o comportamento, diagnosticar problemas e melhorar continuamente o desempenho.
Aqui está o que se torna possível:
🔍 Validar seu agente antes de lançá-lo para clientes
Antes de colocar um agente em produção, você pode executar testes realistas que revelam se ele realmente entende suas regras, base de conhecimento e tom desejado. Chega de surpresas após o deploy — você sabe exatamente o que os usuários vão vivenciar.
🤖 Testar toda a sua equipe de agentes e a lógica de delegação
Para configurações multiagente, as Avaliações mostram como seu manager delega tarefas, quais subagentes participam e se eles seguem o fluxo de trabalho esperado. Você pode detectar rapidamente:
delegações desnecessárias
delegações ausentes
agentes em conflito
comportamento incorreto de função
Isso é essencial para um trabalho em equipe confiável dentro da sua força de trabalho de AI.
📚 Detectar pontos fracos na sua base de conhecimento
Se uma avaliação mostrar falhas repetidas em um tópico específico, você sabe que o problema não é o agente — é conteúdo ausente ou pouco claro. As Avaliações ajudam você a refinar sua KB de forma direcionada e orientada por dados, em vez de adicionar mais material às cegas.
🚨 Detectar alucinações e inconsistência cedo
Como cada pergunta é testada várias vezes, as Avaliações evidenciam problemas sutis como:
respostas mudando de forma imprevisível
raciocínio se desviando
chutes factuais substituindo o uso de ferramentas
contradições entre execuções
Esses são problemas que você nunca identificaria testando manualmente uma ou duas vezes.
A análise não apenas mostra o que deu errado — ela diz como corrigir.
Você recebe recomendações acionáveis respaldadas pelos próprios diagnósticos do modelo:
melhor redação
regras mais rígidas
uso obrigatório de ferramentas
políticas de delegação mais claras
tom e estrutura mais precisos
Isso é prompt engineering automatizado incorporado diretamente ao seu fluxo de trabalho.
📈 Medir progresso sempre que você atualizar seu agente
Sempre que você mudar:
um system prompt
uma entrada da base de conhecimento
uma ferramenta
uma regra de delegação
uma política de raciocínio
…você pode executar novamente a mesma avaliação e comparar pontuações. Você vê exatamente como sua atualização afetou o desempenho — positiva ou negativamente.
As Avaliações se tornam seu ciclo de melhoria contínua.
✔ Garantir respostas de alta qualidade e em conformidade em toda a sua organização
Seja lidando com suporte, análise financeira, cenários de saúde ou conteúdo sensível do ponto de vista jurídico, as Avaliações permitem garantir que:
políticas sejam seguidas
diretrizes de tom sejam respeitadas
lacunas perigosas sejam sinalizadas
raciocínio incorreto seja evidenciado
padrões de compliance sejam atendidos
Isso é especialmente crítico para AI corporativa e voltada ao cliente.
Uso e Custos
As Avaliações de Agentes usam exatamente o mesmo modelo de créditos que o resto do AgentX. Cada execução de teste simplesmente consome créditos da mesma forma que uma mensagem normal do agente — sem taxas extras, sem preços ocultos. Você sempre sabe exatamente quanto está gastando, porque as Avaliações seguem os limites do seu plano existente e o saldo de créditos.
Sua Camada de Controle de Qualidade para AI
Em software tradicional, QA garante confiabilidade.
No AgentX, Avaliações são seu QA para agentes.
Você define como é o “bom”.
O AgentX verifica se seus agentes conseguem entregar isso de forma consistente — e mostra exatamente o que melhorar quando eles não conseguem.
As Avaliações transformam a AI de uma caixa-preta em um sistema transparente, mensurável e aprimorável.