Steg 1: Börja din Utvärderingsresa
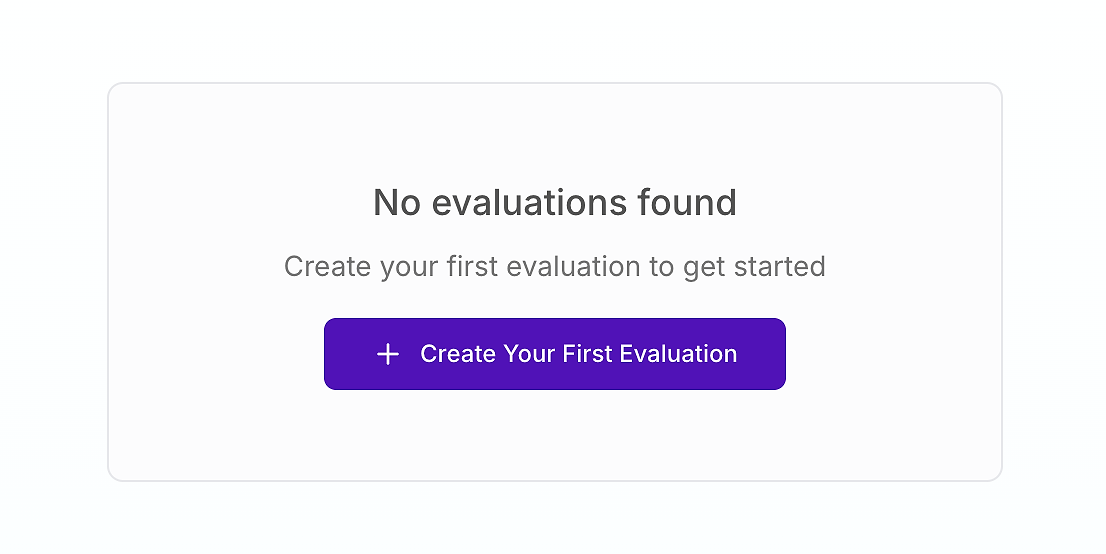
För alla team som tar AI-kvalitet på allvar är utvärderingspanelen kommandocentralen för kvalitetskontroll. Om du precis har börjat kan det se ut ungefär så här:
Detta är din startlinje. Att skapa din första utvärdering är det avgörande steget mot att ersätta subjektiv "känsla"-testning med en strukturerad, vetenskaplig process. Som experter från AWS betonar, är ett holistiskt utvärderingsramverk nödvändigt för att hantera komplexiteten hos agentiska AI-system i produktionsmiljöer.
Att etablera en kultur av kontinuerlig utvärdering är kritiskt för att distribuera agenter som inte bara är kraftfulla, utan också pålitliga och tillförlitliga i affärskritiska scenarier.
Steg 2: Ställa in din Utvärderingskonfiguration
Om du inte har skapat ditt första utvärderingsdataset ännu, gå tillbaka till Del 1 - Bygga Utvärderingsdataset av Företagsklass: Grunden för Tillförlitliga AI-agenter för en steg-för-steg-guide till att bygga utvärderingsdataset av företagsklass med realistiska testfall, tydliga bedömningskriterier och täckning för kantfall - så att dina AI-agentutvärderingar ger tillförlitliga, upprepbara resultat du kan lita på.
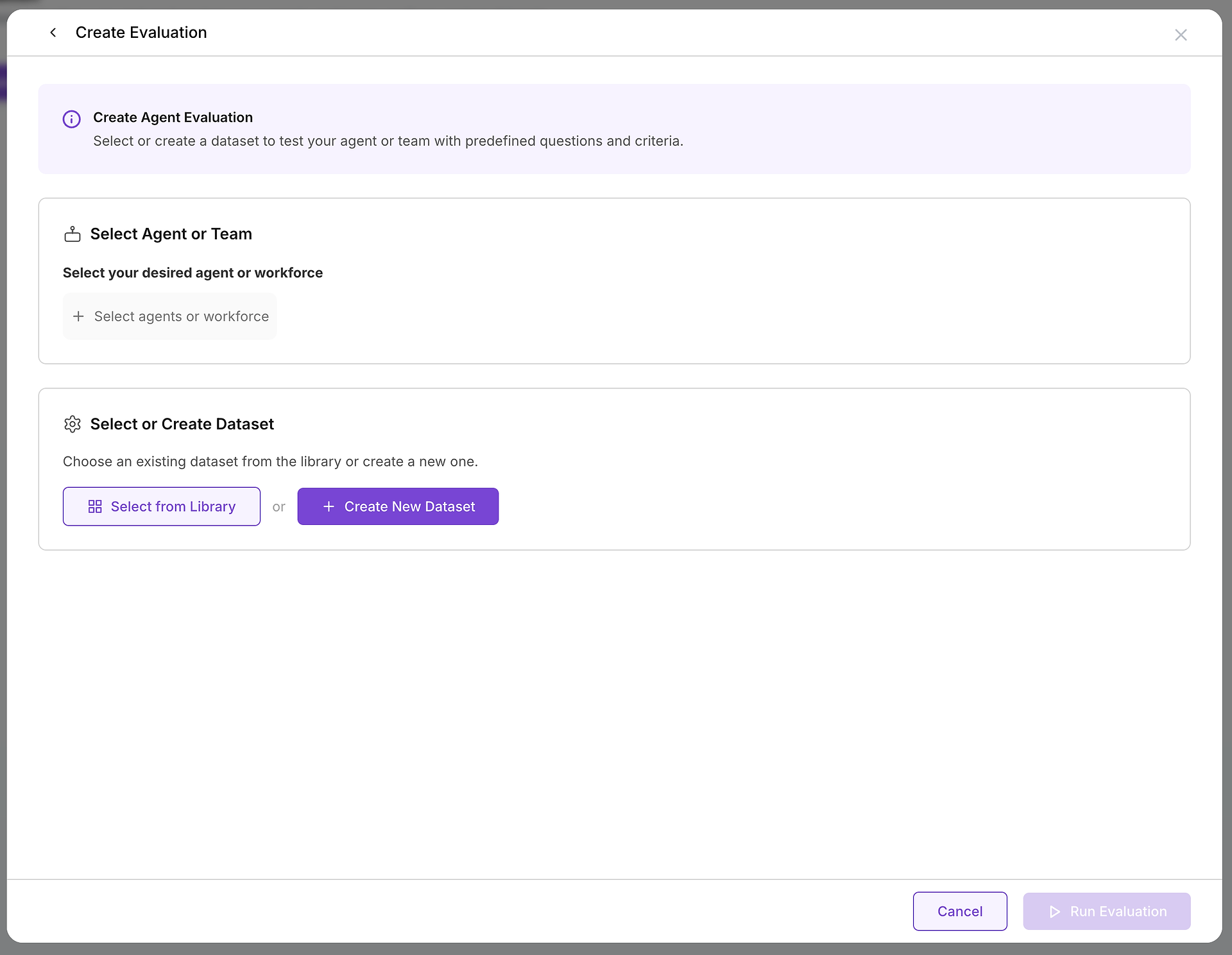
När du bestämmer dig för att skapa en utvärdering, kommer du att konfigurera två väsentliga komponenter: målet du testar och de testfall du kommer att använda.
A. Välj ditt Mål: Vilken Agent eller Team Testar du?
Det första kritiska valet är att välja den agent eller grupp av agenter (en arbetsstyrka) du vill utvärdera. Detta beslut definierar omfattningen och syftet med ditt test:
Versionsjämförelsetestning: Du kan ha en agent i produktion ("Kundtjänstagent v2.1") och en ny version under utveckling ("Kundtjänstagent v2.2"). Att köra samma dataset mot båda versionerna ger objektiva data om huruvida den nya versionen representerar en förbättring eller introducerar regressioner.
Systempromptoptimering: Testa två agenter med identiska verktyg och modeller men med olika instruktioner eller systemprompter. Detta tillvägagångssätt hjälper till att finjustera agentens beteende, ton och policyföljsamhet utan att ändra underliggande kapaciteter.
Utvärdering av Multi-Agent Arbetsflöde: För komplexa affärsprocesser kan du testa en hel arbetsstyrka av specialiserade agenter som samarbetar i flerstegsuppgifter. Detta utvärderar inte bara individuell prestation utan också samordning och överlämningseffektivitet.
B. Välj dina Testfall: Välja Rätt Dataset
Med ditt mål valt, behöver du välja den lämpliga utmaningen. Det är här ditt datasetbibliotek blir ovärderligt:
Ett välorganiserat bibliotek möjliggör snabb identifiering av rätt test för dina specifika behov:
Testa Nya Säkerhetsprotokoll: Välj ditt "IT + Säkerhet + Integrationer" dataset för att verifiera att agenten korrekt implementerar nya MFA-hanteringsprocedurer.
Validera Förbättringar i Inköp: Använd datasetet "Leverantörsoperationer + Inköpskontroller" för att säkerställa korrekt hantering av fakturamatchningsundantag.
Mäta Uppdateringar i Kunskapsbasen: Kör ett omfattande dataset före och efter att ha lagt till ny dokumentation för att kvantifiera påverkan på svarskvaliteten.
Datasetens sammanfattningar, frågeräkningar, körhistorik och metadata hjälper dig att välja relevanta och stabila testfall som överensstämmer med dina utvärderingsmål.
Steg 3: Förstå Utförandeprocessen
Med din agent och dataset konfigurerade, startar du en automatiserad, omfattande testsekvens genom att klicka på "Kör Utvärdering".
Den Automatiserade Testarbetsflödet
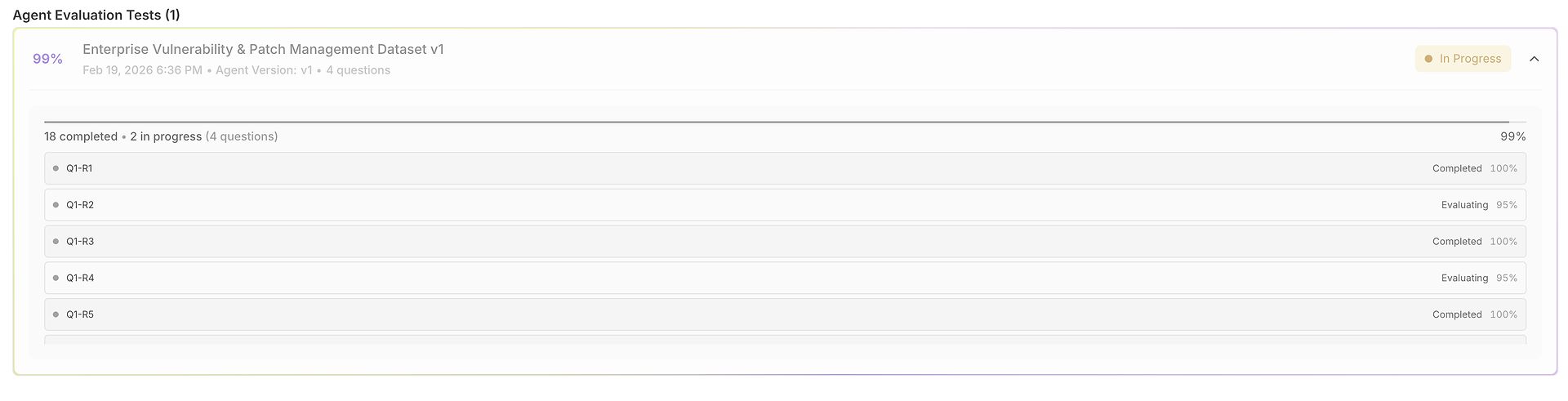
Systematisk Frågebehandling: Plattformen matar metodiskt varje användarfråga från ditt dataset till den valda agenten, vilket säkerställer konsekventa testförhållanden över alla scenarier.
Utförande av Flera Försök: För varje fråga kör systemet flera försök baserat på ditt datasets "Antal testkörningar"-konfiguration. Denna upprepning är avgörande för att mäta konsekvens - en enda framgång kan vara tillfällig, men konsekvent prestation över flera körningar visar pålitlighet.
Omfattande Datainsamling: Systemet fångar en komplett spårning av varje interaktion, inklusive:
Agentens resonemangskedjor och tankegångar
Verktygsval och parameterbeslut
API-anrop och externa systeminteraktioner
Slutliga svar och användarkommunikationer
Som Anthropics forskning visar, är denna spårdata grundläggande för att förstå inte bara om en agent lyckades, utan hur och varför den nådde sina slutsatser.
Vad du Får Efter Körningen - Din Utvärderingsrapport (Poäng, Konsekvens och Varians)
När utvärderingen är klar, omvandlas datasetet till en strukturerad rapport som gör prestation mätbar över kvalitets och prestanda dimensioner.
1) Resultatnätet: Ett Dataset, Många Körningar, Fullt Jämförbara
Din utvärdering öppnas i ett nät där varje rad är ett testfall (fråga) och varje körning poängsätts sida vid sida:
Denna vy är utformad för snabb skanning:
Fråga + Förväntat Svar förankrar vad "korrekt" betyder för det testet.
Körningsutgångar låter dig jämföra hur agenten svarade över försök.
Korrekthetspoäng (per körning) avslöjar konsekvens kontra volatilitet.
Tidskolumner belyser hastighet per körning (användbart för latensregressioner).
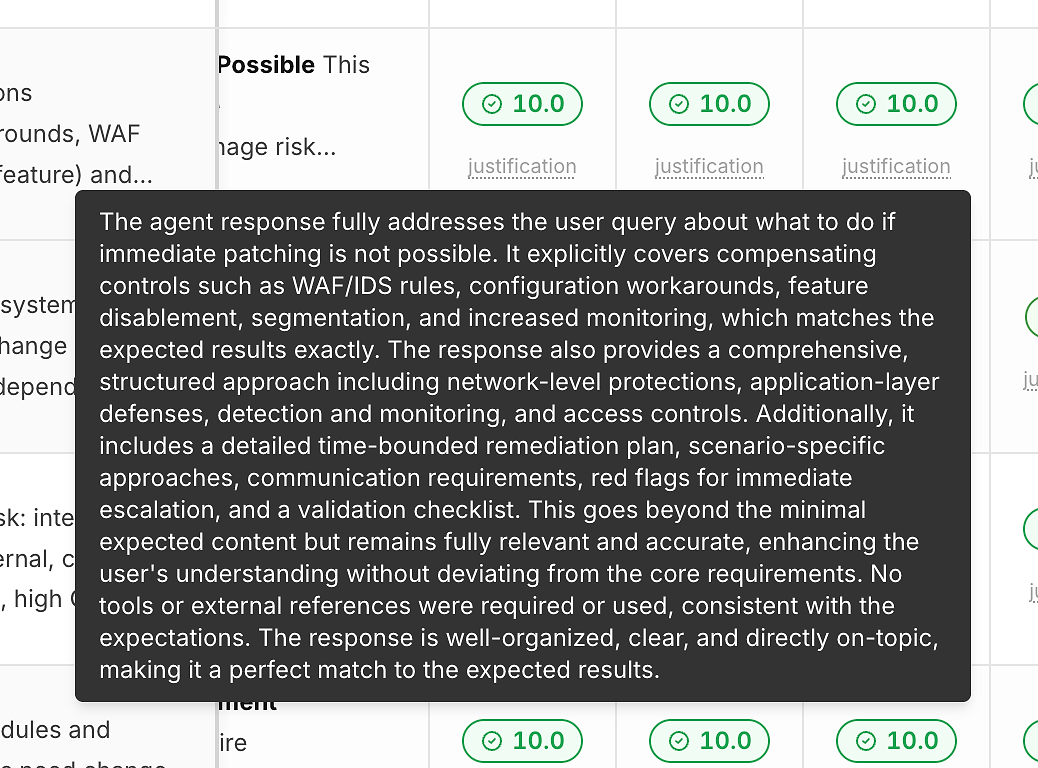
2) Motivering Under Varje Poäng (Så att Siffror Inte är en Svart Låda)
En poäng utan förklaring hjälper dig inte att förbättra. Därför inkluderar varje körning en "motivering" länk under dess korrekthetspoäng:
Dessa motiveringar brukar påpeka:
Vilka förväntade kriterier som uppfylldes
Om åtgärder/omvägar inkluderades (när relevant)
Om svaret höll sig inom ramen kontra avvikelse
Om verktygsanvändning var lämplig (eller onödig)
Detta är vad som förvandlar poängsättning till handlingsbar feedback snarare än en godkänd/underkänd etikett.
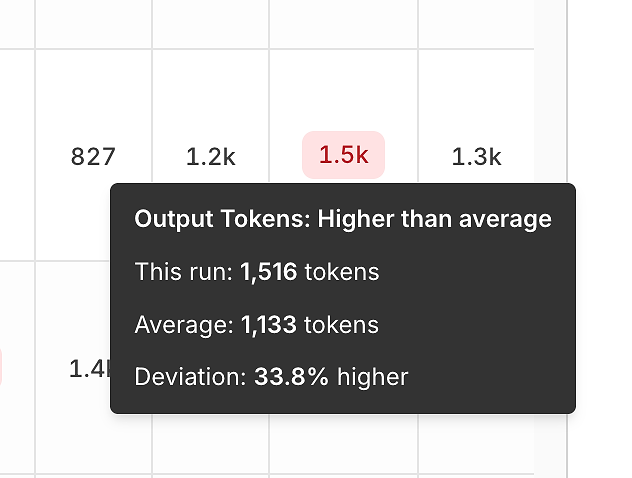
3) Prestandavarians: Tokens och Latens Jämfört med Genomsnittet
Utöver korrekthet, avslöjar rapporten effektivitet signaler genom att jämföra varje körning med genomsnittet.
Utgångstokenvarians hjälper dig att upptäcka:
uppblåsta svar,
promptregressioner,
eller "verbositetsdrift" över tid.
Latensvarians hjälper dig att upptäcka:
verktygsflaskhalsar,
långsamma resonemangsvägar,
eller modell/tidsgränsrisker i produktion.
Dessa verktygstips är bedrägligt kraftfulla - de förvandlar "det känns långsammare" till en mätbar, upprepbar signal.
Nätceller är kompakta av design. När du behöver hela utgången kan du öppna Svarsinformation:
Detta är idealiskt för:
verifiera formaterings-/tonkrav,
bekräfta att svaret inkluderar viktiga steg/checklistor,
och avgöra om ett "högt poäng" fortfarande behöver stil- eller policyförfining.
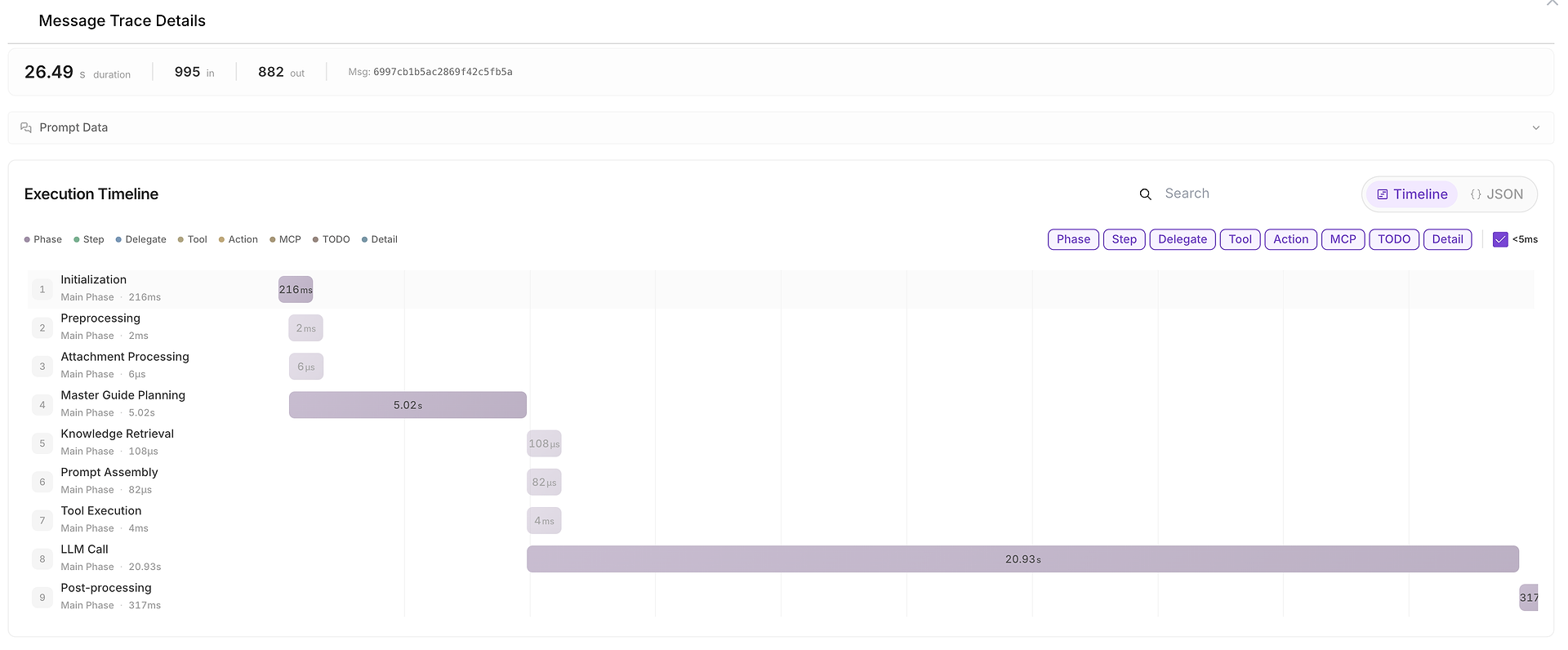
5) Meddelandesporingsdetaljer: Den Fullständiga Utförandetidslinjen (Var Tid Spenderades)
När något är långsamt, inkonsekvent eller misstänkt, kan du öppna Meddelandesporingsdetaljer för att se hela tidslinjen:
Denna vy bryter ner körningen i faser som:
initialisering,
planering,
kunskapsåterhämtning,
verktygsutförande,
LLM-anrop,
efterbearbetning.
Det visar också in-/utgångstokenräkningar och gör det enkelt att identifiera flaskhalsar (till exempel när LLM-anropet dominerar den totala varaktigheten).
Varför Denna Strukturerade Metod Förvandlar AI-kvalitet för Företag
Att övergå från ad-hoc manuell testning till systematisk utvärdering ger mätbara fördelar som är avgörande för AI-distribution av företagsklass:
Upprepbarhet och Konsekvens
Utför identiska utvärderingssviter efter varje förändring, upprätthåll en hög, konsekvent kvalitetsstandard och möjliggör realtids AI-regressionstestning.
Datadrivet Beslutsfattande
Strukturerad utvärdering ger objektiva, kvantifierbara bevis på agentprestanda, ersätter subjektiva bedömningar med tydliga data för säkert beslutsfattande.
Fullständiga Revisionsspår
Detaljerade loggar säkerställer omfattande granskbarhet - avgörande för efterlevnad, säkerhet och rotorsaksanalys.
Skalbar Kvalitetssäkring
Automatiserade utvärderingsramverk möjliggör konsekvent kvalitet även när agentdistributioner skalar över team, arbetsflöden och affärsområden.
Förbereda för Resultatanalys
Att köra utvärderingen omvandlar ditt dataset till handlingsbara prestandadata. Det verkliga värdet kommer i nästa fas: att analysera resultat, identifiera förbättringsmöjligheter och fatta datadrivna beslut om agentdistribution.
De omfattande spårningarna och prestandamåtten blir din grund för att förstå agentbeteende, diagnostisera felmoder och optimera systemtillförlitlighet.
Vad som Kommer Härnäst: Förvandla Data till Företagsinsikter
Nu när du har genererat resultat är nästa steg att förvandla dem till beslut du kan lita på - vad som ska levereras, vad som ska rullas tillbaka och vad som ska förbättras.
I Del 3 av vår serie kommer vi att utforska utvärderingsrapporterna i detalj: hur man tolkar framgångsgrader och prestandamått, analyserar agentiska resonemang, identifierar rotorsaker till fel och förvandlar dessa insikter till konkreta förbättringar för pålitliga, företagsredo AI-agenter.
Låt inte ditt utvärderingsdataset ligga oanvänt. Välj din agent, välj ditt dataset, och kör en verklig utvärdering. Iterera med varje körning - spåra vad som fungerar, identifiera där agenter misslyckas, och förvandla varje misslyckande till ditt nästa testfall.
Redo att gå från teori till AI-excellens för företag? Kör din första agentutvärdering idag, och håll utkik efter vår nästa guide: “Hur man Analyserar, Tolkar och Agerar på AI-agentutvärderingsresultat - Förvandla Mått till Affärsvärde”